Amazon’s Georgiana Dinu on current challenges in machine translation.Read More
Toward speech recognition for uncommon spoken languages
Automated speech-recognition technology has become more common with the popularity of virtual assistants like Siri, but many of these systems only perform well with the most widely spoken of the world’s roughly 7,000 languages.
Because these systems largely don’t exist for less common languages, the millions of people who speak them are cut off from many technologies that rely on speech, from smart home devices to assistive technologies and translation services.
Recent advances have enabled machine learning models that can learn the world’s uncommon languages, which lack the large amount of transcribed speech needed to train algorithms. However, these solutions are often too complex and expensive to be applied widely.
Researchers at MIT and elsewhere have now tackled this problem by developing a simple technique that reduces the complexity of an advanced speech-learning model, enabling it to run more efficiently and achieve higher performance.
Their technique involves removing unnecessary parts of a common, but complex, speech recognition model and then making minor adjustments so it can recognize a specific language. Because only small tweaks are needed once the larger model is cut down to size, it is much less expensive and time-consuming to teach this model an uncommon language.
This work could help level the playing field and bring automatic speech-recognition systems to many areas of the world where they have yet to be deployed. The systems are important in some academic environments, where they can assist students who are blind or have low vision, and are also being used to improve efficiency in health care settings through medical transcription and in the legal field through court reporting. Automatic speech-recognition can also help users learn new languages and improve their pronunciation skills. This technology could even be used to transcribe and document rare languages that are in danger of vanishing.
“This is an important problem to solve because we have amazing technology in natural language processing and speech recognition, but taking the research in this direction will help us scale the technology to many more underexplored languages in the world,” says Cheng-I Jeff Lai, a PhD student in MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL) and first author of the paper.
Lai wrote the paper with fellow MIT PhD students Alexander H. Liu, Yi-Lun Liao, Sameer Khurana, and Yung-Sung Chuang; his advisor and senior author James Glass, senior research scientist and head of the Spoken Language Systems Group in CSAIL; MIT-IBM Watson AI Lab research scientists Yang Zhang, Shiyu Chang, and Kaizhi Qian; and David Cox, the IBM director of the MIT-IBM Watson AI Lab. The research will be presented at the Conference on Neural Information Processing Systems in December.
Learning speech from audio
The researchers studied a powerful neural network that has been pretrained to learn basic speech from raw audio, called Wave2vec 2.0.
A neural network is a series of algorithms that can learn to recognize patterns in data; modeled loosely off the human brain, neural networks are arranged into layers of interconnected nodes that process data inputs.
Wave2vec 2.0 is a self-supervised learning model, so it learns to recognize a spoken language after it is fed a large amount of unlabeled speech. The training process only requires a few minutes of transcribed speech. This opens the door for speech recognition of uncommon languages that lack large amounts of transcribed speech, like Wolof, which is spoken by 5 million people in West Africa.
However, the neural network has about 300 million individual connections, so it requires a massive amount of computing power to train on a specific language.
The researchers set out to improve the efficiency of this network by pruning it. Just like a gardener cuts off superfluous branches, neural network pruning involves removing connections that aren’t necessary for a specific task, in this case, learning a language. Lai and his collaborators wanted to see how the pruning process would affect this model’s speech recognition performance.
After pruning the full neural network to create a smaller subnetwork, they trained the subnetwork with a small amount of labeled Spanish speech and then again with French speech, a process called finetuning.
“We would expect these two models to be very different because they are finetuned for different languages. But the surprising part is that if we prune these models, they will end up with highly similar pruning patterns. For French and Spanish, they have 97 percent overlap,” Lai says.
They ran experiments using 10 languages, from Romance languages like Italian and Spanish to languages that have completely different alphabets, like Russian and Mandarin. The results were the same — the finetuned models all had a very large overlap.
A simple solution
Drawing on that unique finding, they developed a simple technique to improve the efficiency and boost the performance of the neural network, called PARP (Prune, Adjust, and Re-Prune).
In the first step, a pretrained speech recognition neural network like Wave2vec 2.0 is pruned by removing unnecessary connections. Then in the second step, the resulting subnetwork is adjusted for a specific language, and then pruned again. During this second step, connections that had been removed are allowed to grow back if they are important for that particular language.
Because connections are allowed to grow back during the second step, the model only needs to be finetuned once, rather than over multiple iterations, which vastly reduces the amount of computing power required.
Testing the technique
The researchers put PARP to the test against other common pruning techniques and found that it outperformed them all for speech recognition. It was especially effective when there was only a very small amount of transcribed speech to train on.
They also showed that PARP can create one smaller subnetwork that can be finetuned for 10 languages at once, eliminating the need to prune separate subnetworks for each language, which could also reduce the expense and time required to train these models.
Moving forward, the researchers would like to apply PARP to text-to-speech models and also see how their technique could improve the efficiency of other deep learning networks.
“There are increasing needs to put large deep-learning models on edge devices. Having more efficient models allows these models to be squeezed onto more primitive systems, like cell phones. Speech technology is very important for cell phones, for instance, but having a smaller model does not necessarily mean it is computing faster. We need additional technology to bring about faster computation, so there is still a long way to go,” Zhang says.
Self-supervised learning (SSL) is changing the field of speech processing, so making SSL models smaller without degrading performance is a crucial research direction, says Hung-yi Lee, associate professor in the Department of Electrical Engineering and the Department of Computer Science and Information Engineering at National Taiwan University, who was not involved in this research.
“PARP trims the SSL models, and at the same time, surprisingly improves the recognition accuracy. Moreover, the paper shows there is a subnet in the SSL model, which is suitable for ASR tasks of many languages. This discovery will stimulate research on language/task agnostic network pruning. In other words, SSL models can be compressed while maintaining their performance on various tasks and languages,” he says.
This work is partially funded by the MIT-IBM Watson AI Lab and the 5k Language Learning Project.
Self-Supervised Reversibility-Aware Reinforcement Learning
Posted by Johan Ferret, Student Researcher, Google Research, Brain Team
An approach commonly used to train agents for a range of applications from robotics to chip design is reinforcement learning (RL). While RL excels at discovering how to solve tasks from scratch, it can struggle in training an agent to understand the reversibility of its actions, which can be crucial to ensure that agents behave in a safe manner within their environment. For instance, robots are generally costly and require maintenance, so one wants to avoid taking actions that might lead to broken components. Estimating if an action is reversible or not (or better, how easily it can be reversed) requires a working knowledge of the physics of the environment in which the agent is operating. However, in the standard RL setting, agents do not possess a model of the environment sufficient to do this.
In “There Is No Turning Back: A Self-Supervised Approach to Reversibility-Aware Reinforcement Learning”, accepted at NeurIPS 2021, we present a novel and practical way of approximating the reversibility of agent actions in the context of RL. This approach, which we call Reversibility-Aware RL, adds a separate reversibility estimation component to the RL procedure that is self-supervised (i.e., it learns from unlabeled data collected by the agents). It can be trained either online (jointly with the RL agent) or offline (from a dataset of interactions). Its role is to guide the RL policy towards reversible behavior. This approach increases the performance of RL agents on several tasks, including the challenging Sokoban puzzle game.
Reversibility-Aware RL
The reversibility component added to the RL procedure is learned from interactions, and crucially, is a model that can be trained separate from the agent itself. The model training is self-supervised and does not require that the data be labeled with the reversibility of the actions. Instead, the model learns about which types of actions tend to be reversible from the context provided by the training data alone.We call the theoretical explanation for this empirical reversibility, a measure of the probability that an event A precedes another event B, knowing that A and B both happen. Precedence is a useful proxy for true reversibility because it can be learned from a dataset of interactions, even without rewards.
Imagine, for example, an experiment where a glass is dropped from table height and when it hits the floor it shatters. In this case, the glass goes from position A (table height) to position B (floor) and regardless of the number of trials, A always precedes B, so when randomly sampling pairs of events, the probability of finding a pair in which A precedes B is 1. This would indicate an irreversible sequence. Assume, instead, a rubber ball was dropped instead of the glass. In this case, the ball would start at A, drop to B, and then (approximately) return to A. So, when sampling pairs of events, the probability of finding a pair in which A precedes B would only be 0.5 (the same as the probability that a random pair showed B preceding A), and would indicate a reversible sequence.
|
| Reversibility estimation relies on the knowledge of the dynamics of the world. A proxy to reversibility is precedence, which establishes which of two events comes first on average,given that both are observed. |
In practice, we sample pairs of events from a collection of interactions, shuffle them, and train the neural network to reconstruct the actual chronological order of the events. The network’s performance is measured and refined by comparing its predictions against the ground truth derived from the timestamps of the actual data. Since events that are temporally distant tend to be either trivial or impossible to order, we sample events in a temporal window of fixed size. We then use the prediction probabilities of this estimator as a proxy for reversibility: if the neural network’s confidence that event A happens before event B is higher than a chosen threshold, then we deem that the transition from event A to B is irreversible.
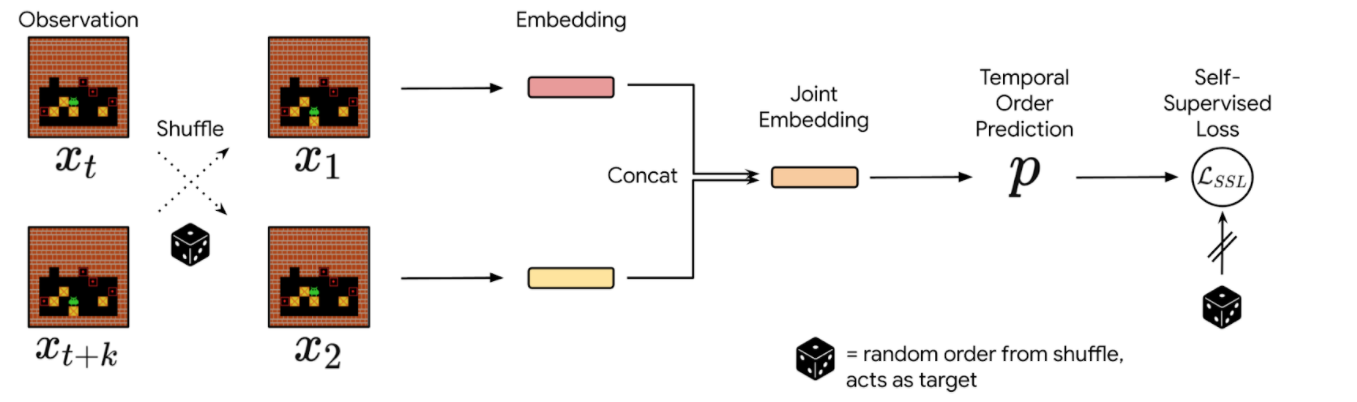 |
| Precedence estimation consists of predicting the temporal order of randomly shuffled events. |
Integrating Reversibility into RL
We propose two concurrent ways of integrating reversibility in RL:
- Reversibility-Aware Exploration (RAE): This approach penalizes irreversible transitions, via a modified reward function. When the agent picks an action that is considered irreversible, it receives a reward corresponding to the environment’s reward minus a positive, fixed penalty, which makes such actions less likely, but does not exclude them.
- Reversibility-Aware Control (RAC): Here, all irreversible actions are filtered out, a process that serves as an intermediate layer between the policy and the environment. When the agent picks an action that is considered irreversible, the action selection process is repeated, until a reversible action is chosen.
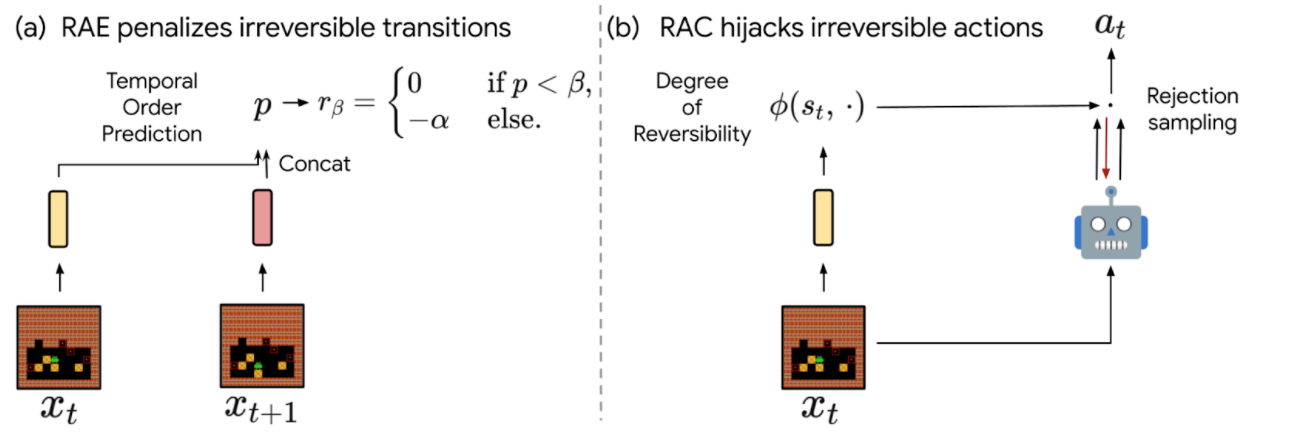 |
| The proposed RAE (left) and RAC (right) methods for reversibility-aware RL. |
An important distinction between RAE and RAC is that RAE only encourages reversible actions, it does not prohibit them, which means that irreversible actions can still be performed when the benefits outweigh costs (as in the Sokoban example below). As a result, RAC is better suited for safe RL where irreversible side-effects induce risks that should be avoided entirely, and RAE is better suited for tasks where it is suspected that irreversible actions are to be avoided most of the time.
To illustrate the distinction between RAE and RAC, we evaluate the capabilities of both proposed methods. A few example scenarios follow:
- Avoiding (but not prohibiting) irreversible side-effects
A general rule for safe RL is to minimize irreversible interactions when possible, as a principle of caution. To test such capabilities, we introduce a synthetic environment where an agent in an open field is tasked with reaching a goal. If the agent follows the established pathway, the environment remains unchanged, but if it departs from the pathway and onto the grass, the path it takes turns to brown. While this changes the environment, no penalty is issued for such behavior.
In this scenario, a typical model-free agent, such as a Proximal Policy Optimization (PPO) agent, tends to follow the shortest path on average and spoils some of the grass, whereas a PPO+RAE agent avoids all irreversible side-effects.
Top-left: The synthetic environment in which the agent (blue) is tasked with reaching a goal (pink). A pathway is shown in grey leading from the agent to the goal, but it does not follow the most direct route between the two. Top-right: An action sequence with irreversible side-effects of an agent’s actions. When the agent departs from the path, it leaves a brown path through the field. Bottom-left: The visitation heatmap for a PPO agent. Agents tend to follow a more direct path than that shown in grey. Bottom-right: The visitation heatmap for a PPO+RAE agent. The irreversibility of going off-path encourages the agent to stay on the established grey path. - Safe interactions by prohibiting irreversibility
We also tested against the classic Cartpole task, in which the agent controls a cart in order to balance a pole standing precariously upright on top of it. We set the maximum number of interactions to 50k steps, instead of the usual 200. On this task, irreversible actions tend to cause the pole to fall, so it is better to avoid such actions at all.
We show that combining RAC with any RL agent (even a random agent) never fails, given that we select an appropriate threshold for the probability that an action is irreversible. Thus, RAC can guarantee safe, reversible interactions from the very first step in the environment.
We show how the Cartpole performance of a random policy equipped with RAC evolves with different threshold values (ꞵ). Standard model-free agents (DQN, M-DQN) typically score less than 3000, compared to 50000 (the maximum score) for an agent governed by a random+RAC policy at a threshold value of β=0.4. - Avoiding deadlocks in Sokoban
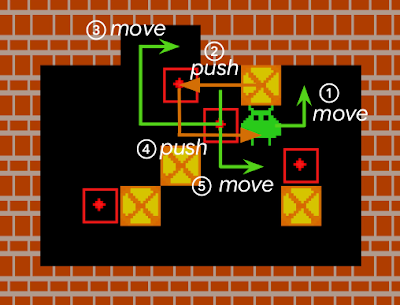
Sokoban is a puzzle game in which the player controls a warehouse keeper and has to push boxes onto target spaces, while avoiding unrecoverable situations (e.g., when a box is in a corner or, in some cases, along a wall).
An action sequence that completes a Sokoban level. Boxes (yellow squares with a red “x”) must be pushed by an agent onto targets (red outlines with a dot in the middle). Because the agent cannot pull the boxes, any box pushed against a wall can be difficult, if not impossible to get away from the wall, i.e., it becomes “deadlocked”. For a standard RL model, early iterations of the agent typically act in a near-random fashion to explore the environment, and consequently, get stuck very often. Such RL agents either fail to solve Sokoban puzzles, or are quite inefficient at it.
Agents that explore randomly quickly engage themselves in deadlocks that prevent them from completing levels (as an example here, pushing the rightmost box on the wall cannot be reversed). We compared the performance in the Sokoban environment of IMPALA, a state-of-the-art model-free RL agent, to that of an IMPALA+RAE agent. We find that the agent with the combined IMPALA+RAE policy is deadlocked less frequently, resulting in superior scores.
The scores of IMPALA and IMPALA+RAE on a set of 1000 Sokoban levels. A new level is sampled at the beginning of each episode.The best score is level dependent and close to 10. In this task, detecting irreversible actions is difficult because it is a highly imbalanced learning problem — only ~1% of actions are indeed irreversible, and many other actions are difficult to flag as reversible, because they can only be reversed through a number of additional steps by the agent.
Reversing an action is sometimes non-trivial. In the example shown here, a box has been pushed against the wall, but is still reversible. However, reversing the situation takes at least five separate movements comprising 17 distinct actions by the agent (each numbered move being the result of several actions from the agent). We estimate that approximately half of all Sokoban levels require at least one irreversible action to be completed (e.g., because at least one target destination is adjacent to a wall). Since IMPALA+RAE solves virtually all levels, it implies that RAE does not prevent the agent from taking irreversible actions when it is crucial to do so.





Conclusion
We present a method that enables RL agents to predict the reversibility of an action by learning to model the temporal order of randomly sampled trajectory events, which results in better exploration and control. Our proposed method is self-supervised, meaning that it does not necessitate any prior knowledge about the reversibility of actions, making it well suited to a variety of environments. In the future, we are interested in studying further how these ideas could be applied in larger scale and safety-critical applications.
Acknowledgements
We would like to thank our paper co-authors Nathan Grinsztajn, Philippe Preux, Olivier Pietquin and Matthieu Geist. We would also like to thank Bobak Shahriari, Théophane Weber, Damien Vincent, Alexis Jacq, Robert Dadashi, Léonard Hussenot, Nino Vieillard, Lukasz Stafiniak, Nikola Momchev, Sabela Ramos and all those who provided helpful discussion and feedback on this work.

Foiling AI hackers with counterfactual reasoning
Amazon Research Award recipient Yezhou Yang is studying how to make autonomous systems more robust.Read More
3 Questions: Blending computing with other disciplines at MIT
The demand for computing-related training is at an all-time high. At MIT, there has been a remarkable tide of interest in computer science programs, with heavy enrollment from students studying everything from economics to life sciences eager to learn how computational techniques and methodologies can be used and applied within their primary field.
Launched in 2020, the Common Ground for Computing Education was created through the MIT Stephen A. Schwarzman College of Computing to meet the growing need for enhanced curricula that connect computer science and artificial intelligence with different domains. In order to advance this mission, the Common Ground is bringing experts across MIT together and facilitating collaborations among multiple departments to develop new classes and approaches that blend computing topics with other disciplines.
Dan Huttenlocher, dean of the MIT Schwarzman College of Computing, and the chairs of the Common Ground Standing Committee — Jeff Grossman, head of the Department of Materials Science and Engineering and the Morton and Claire Goulder and Family Professor of Environmental Systems; and Asu Ozdaglar, deputy dean of academics for the MIT Schwarzman College of Computing, head of the Department of Electrical Engineering and Computer Science, and the MathWorks Professor of Electrical Engineering and Computer Science — discuss here the objectives of the Common Ground, pilot subjects that are underway, and ways they’re engaging faculty to create new curricula for MIT’s class of “computing bilinguals.”
Q: What are the objectives of the Common Ground and how does it fit into the mission of the MIT Schwarzman College of Computing?
Huttenlocher: One of the core components of the college mission is to educate students who are fluent in both the “language” of computing and that of other disciplines. Machine learning classes, for example, attract a lot of students outside of electrical engineering and computer science (EECS) majors. These students are interested in machine learning for modeling within the context of their fields of interest, rather than inner workings of machine learning itself as taught in Course 6. So, we need new approaches to how we develop computing curricula in order to provide students with a thorough grounding in computing that is relevant to their interests, to not just enable them to use computational tools, but understand conceptually how they can be developed and applied in their primary field, whether it be science, engineering, humanities, business, or design.
The core goals of the Common Ground are to infuse computing education throughout MIT in a coordinated manner, as well as to serve as a platform for multi-departmental collaborations. All classes and curricula developed through the Common Ground are intended to be created and offered jointly by multiple academic departments to meet ‘common’ needs. We’re bringing the forefront of rapidly-changing computer science and artificial intelligence fields together with the problems and methods of other disciplines, so the process has to be collaborative. As much as computing is changing thinking in the disciplines, the disciplines are changing the way people develop new computing approaches. It can’t be a stand-alone effort — otherwise it won’t work.
Q: How is the Common Ground facilitating collaborations and engaging faculty across MIT to develop new curricula?
Grossman: The Common Ground Standing Committee was formed to oversee the activities of the Common Ground and is charged with evaluating how best to support and advance program objectives. There are 29 members on the committee — all are faculty experts in various computing areas, and they represent 18 academic departments across all five MIT schools and the college. The structure of the committee very much aligns with the mission of the Common Ground in that it draws from all parts of the Institute. Members are organized into subcommittees currently centered on three primary focus areas: fundamentals of computational science and engineering; fundamentals of programming/computational thinking; and machine learning, data science, and algorithms. The subcommittees, with extensive input from departments, framed prototypes for what Common Ground subjects would look like in each area, and a number of classes have already been piloted to date.
It has been wonderful working with colleagues from different departments. The level of commitment that everyone on the committee has put into this effort has truly been amazing to see, and I share their enthusiasm for pursuing opportunities in computing education.
Q: Can you tell us more about the subjects that are already underway?
Ozdaglar: So far, we have four offerings for students to choose from: in the fall, there’s Linear Algebra and Optimization with the Department of Mathematics and EECS, and Programming Skills and Computational Thinking in-Context with the Experimental Study Group and EECS; Modeling with Machine Learning: From Algorithms to Applications in the spring, with disciplinary modules developed by multiple engineering departments and MIT Supply Chain Management; and Introduction to Computational Science and Engineering during both semesters, which is a collaboration between the Department of Aeronautics and Astronautics and the Department of Mathematics.
We have had students from a range of majors take these classes, including mechanical engineering, physics, chemical engineering, economics, and management, among others. The response has been very positive. It is very exciting to see MIT students having access to these unique offerings. Our goal is to enable them to frame disciplinary problems using a rich computational framework, which is one of the objectives of the Common Ground.
We are planning to expand Common Ground offerings in the years to come and welcome ideas for new subjects. Some ideas that we currently have in the works include classes on causal inference, creative programming, and data visualization with communication. In addition, this fall, we put out a call for proposals to develop new subjects. We invited instructors from all across the campus to submit ideas for pilot computing classes that are useful across a range of areas and support the educational mission of individual departments. The selected proposals will receive seed funding from the Common Ground to assist in the design, development, and staffing of new, broadly-applicable computing subjects and revision of existing subjects in alignment with the Common Ground’s objectives. We are looking explicitly to facilitate opportunities in which multiple departments would benefit from coordinated teaching.
AWS team wins best-paper award for work on automated reasoning
SOSP paper describes lightweight formal methods for validating new S3 data storage service.Read More
Reducing city transport emissions with Maps and AI
City transportation is crucial to connecting residents to education, employment and essential services. At the same time, the transportation sector is where global greenhouse gas (GHG) emissions are rising the quickest.
In 2018, we launched the Environmental Insights Explorer (EIE) in collaboration with the Global Covenant of Mayors for Climate & Energy (GCoM). As part of Google’s most ambitious decade of climate action, we’ve committed to helping more than 500 cities and local governments reduce an aggregate of 1 gigaton of carbon emissions per year by 2030 and beyond. With EIE, cities have free access to Google’s unique mapping data and insights so they can make sustainable decisions regarding cleaner transport policies and infrastructure programs. Since launching EIE, we’ve seen more cities and governments set ambitious climate targets. This week, 120 world governments will gather in Glasgow at COP26 to report their progress toward these commitments and set a path forward to address climate change. EIE can help cities and governments translate these targets into concrete action.
In pursuit of helping more cities take action against climate change, we will make transportation insights available in EIE for over 20,000 cities and regional governments by the end of the year, making it one of the largest ever collections of high-quality, globally consistent environmental data sources. This expansion will double the number of geographies represented in EIE, accounting for the majority of the world’s transport emissions.
As the window continues to narrow on implementing policies and plans to reduce emissions, we’re unifying around a single mission: to foster sustainability at scale. To help, we’re partnering with the C40 Cities Climate Leadership Group, a network of megacities committed to addressing climate change. Our work with C40 will help us better support the needs of cities while making data accessible to city projects that are working on climate solutions. Together we can provide higher-quality transportation activity data to measure and track GHG emissions at a global scale, while also giving state and local governments resources to better understand what’s working at a local level.
The need for action is now, and we need to rise to the challenge quickly. Google technology is unlocking our ability to generate climate-related insights and impact at a global scale. Here are a few of the latest ways we’re using AI and Google Maps data in EIE.
Taking inventory of yearly progress
More cities, states and regions are committing to comprehensive climate plans to decarbonize transportation by 2040. These next two decades of ambitious action will require regular progress reports to assess what is and isn’t working.
Using AI, our systems analyze transportation trends in a city by mode, helping local governments take stock of their progress in tackling GHG emissions. GHG inventory processes traditionally take months and multiple data sources to compile, and are now streamlined, allowing government staff to reduce the cost and personnel burden of reporting.
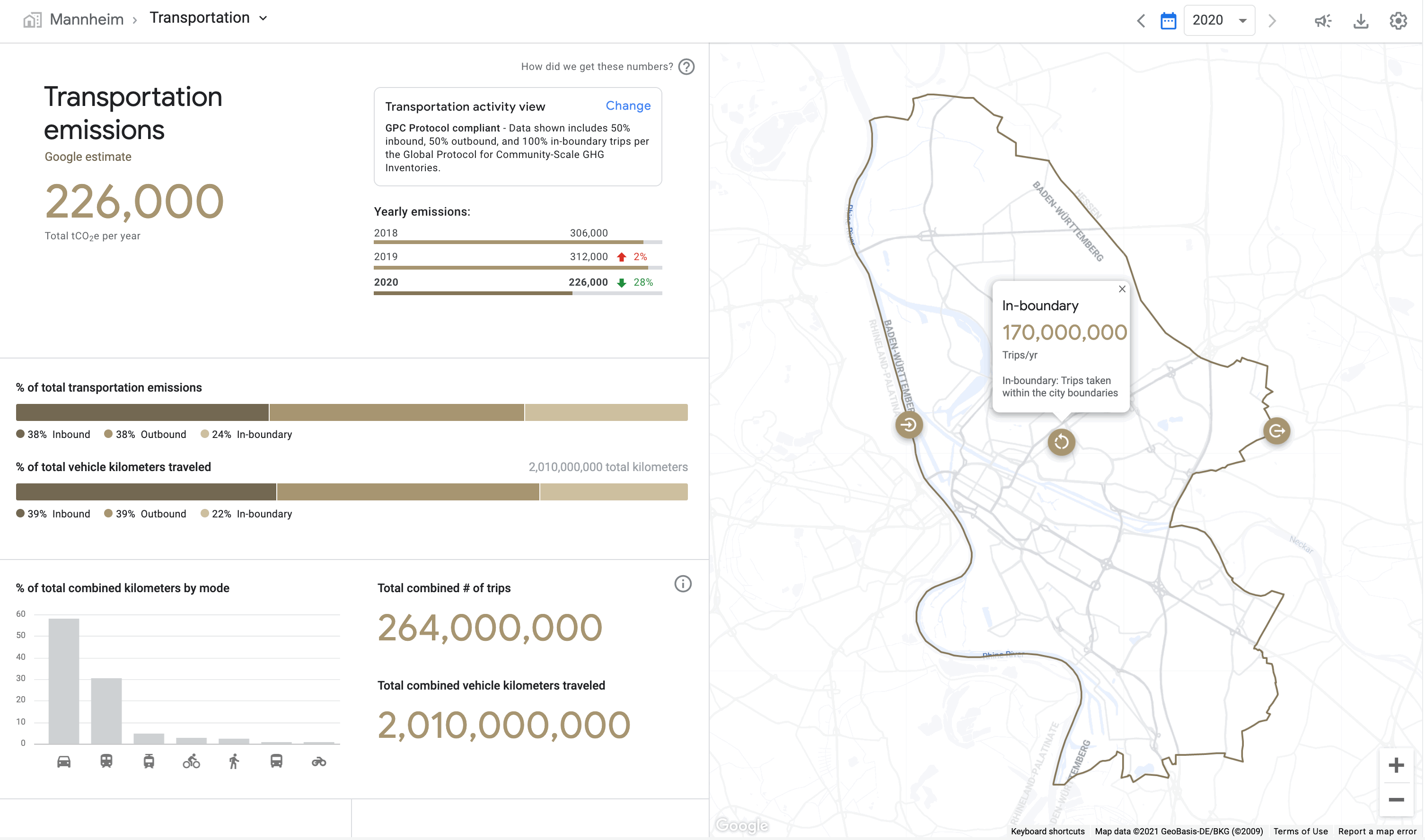
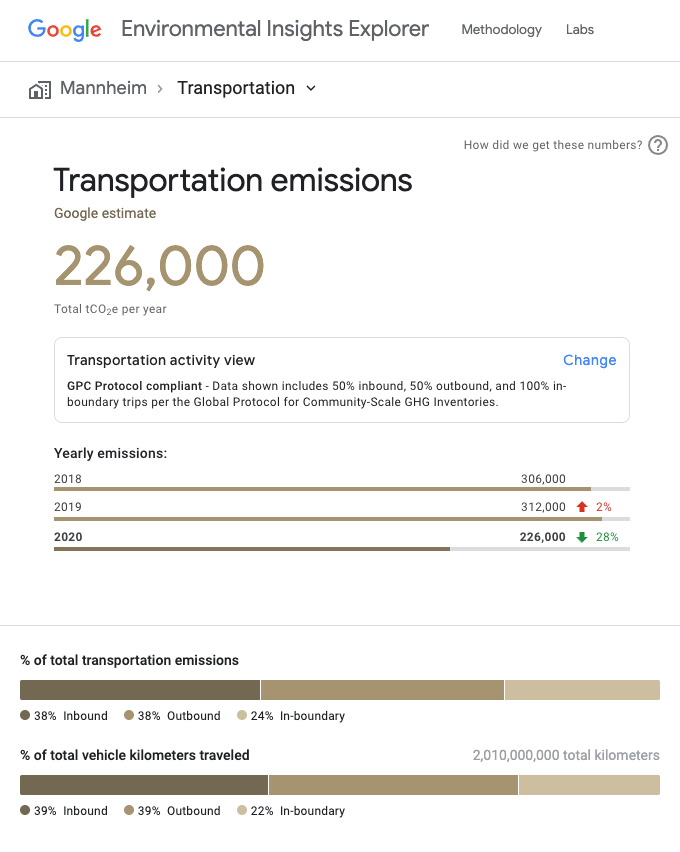
Plan eco-friendly mobility interventions
To accelerate data-driven decisions aimed at reducing transportation emissions and boosting infrastructure investments, EIE summarizes critical insights across which modes of transport to tackle. EIE characterizes trips traveled within and across city boundaries and applies city-specific scaling factors based on overall population. EIE’s multimodal insights allow government data practitioners to ask questions that inform transportation decisions, such as the extent to which city investments in different modes of transportation can shift behaviors.
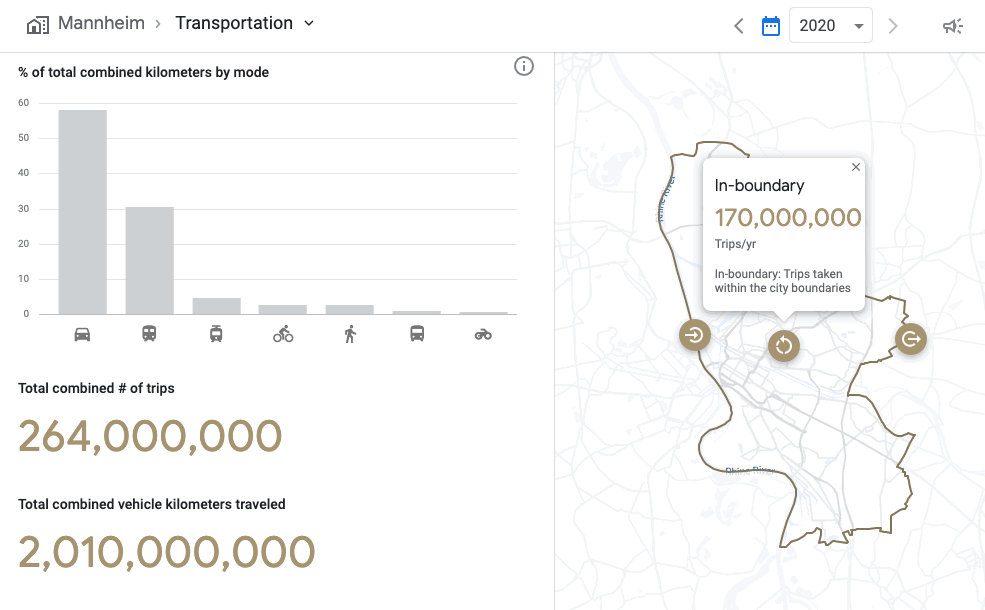
Looking forward
Modeling transportation flows is complex. With EIE, cities, states, regional policymakers, consultants can better understand the impact sustainable changes are making on global greenhouse gas emissions.
To learn more about how cities are using EIE, view our EIE 2021 City Impact report. If you’re part of a local government and interested in what EIE can do for your community, fill out this form to get in touch with our team.
Amazon SCOT employees participate in innovation and diversity panel discussion
Watch the replay of the October 28 discussion featuring four Amazon leaders.Read More