Amazon quantum computing scientist recognized for ‘outstanding contributions to physics’.Read More
Self-Supervised Learning Advances Medical Image Classification
Posted by Shekoofeh Azizi, AI Resident, Google Research
In recent years, there has been increasing interest in applying deep learning to medical imaging tasks, with exciting progress in various applications like radiology, pathology and dermatology. Despite the interest, it remains challenging to develop medical imaging models, because high-quality labeled data is often scarce due to the time-consuming effort needed to annotate medical images. Given this, transfer learning is a popular paradigm for building medical imaging models. With this approach, a model is first pre-trained using supervised learning on a large labeled dataset (like ImageNet) and then the learned generic representation is fine-tuned on in-domain medical data.
Other more recent approaches that have proven successful in natural image recognition tasks, especially when labeled examples are scarce, use self-supervised contrastive pre-training, followed by supervised fine-tuning (e.g., SimCLR and MoCo). In pre-training with contrastive learning, generic representations are learned by simultaneously maximizing agreement between differently transformed views of the same image and minimizing agreement between transformed views of different images. Despite their successes, these contrastive learning methods have received limited attention in medical image analysis and their efficacy is yet to be explored.
In “Big Self-Supervised Models Advance Medical Image Classification”, to appear at the International Conference on Computer Vision (ICCV 2021), we study the effectiveness of self-supervised contrastive learning as a pre-training strategy within the domain of medical image classification. We also propose Multi-Instance Contrastive Learning (MICLe), a novel approach that generalizes contrastive learning to leverage special characteristics of medical image datasets. We conduct experiments on two distinct medical image classification tasks: dermatology condition classification from digital camera images (27 categories) and multilabel chest X-ray classification (5 categories). We observe that self-supervised learning on ImageNet, followed by additional self-supervised learning on unlabeled domain-specific medical images, significantly improves the accuracy of medical image classifiers. Specifically, we demonstrate that self-supervised pre-training outperforms supervised pre-training, even when the full ImageNet dataset (14M images and 21.8K classes) is used for supervised pre-training.
SimCLR and Multi Instance Contrastive Learning (MICLe)
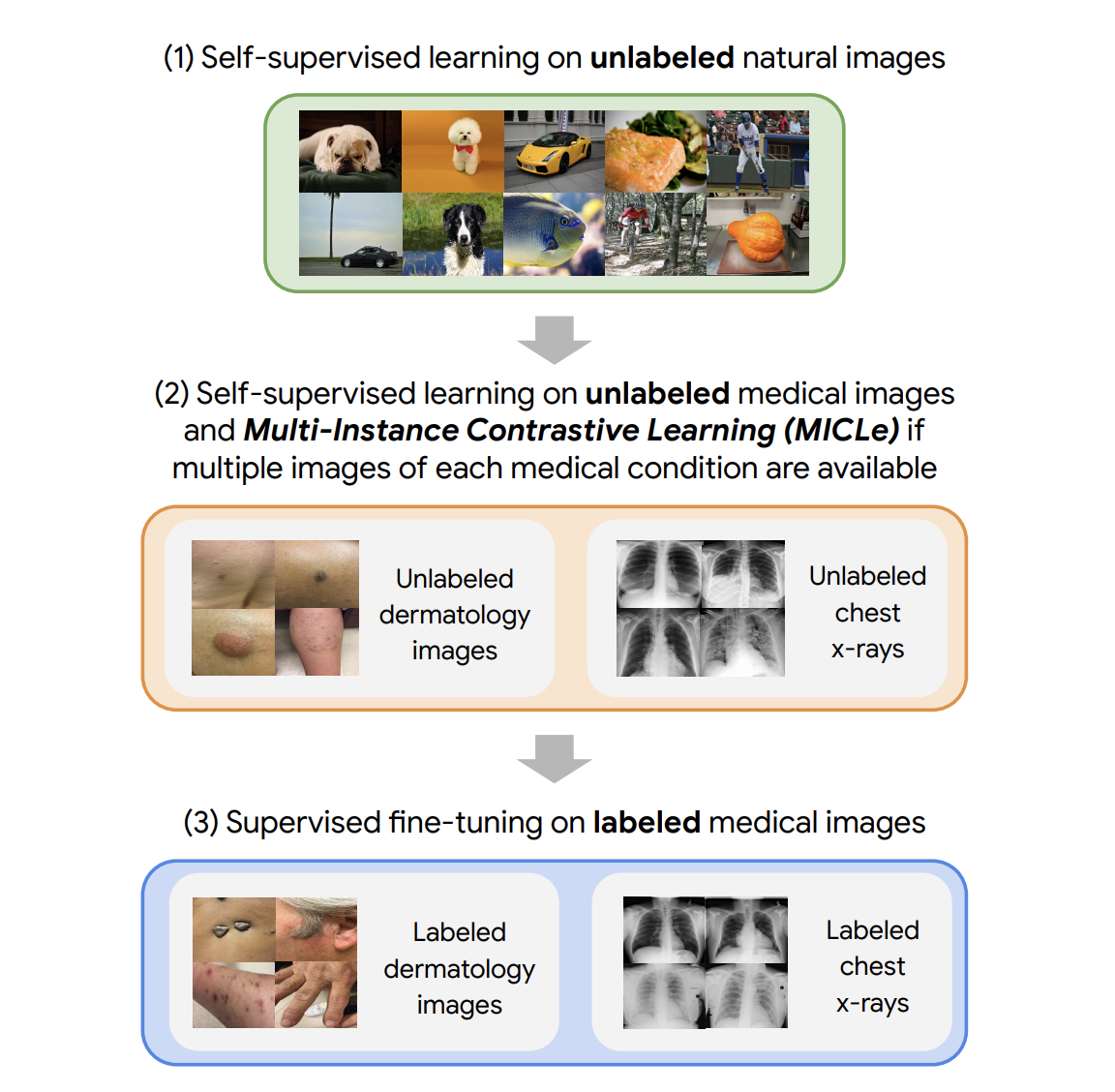
Our approach consists of three steps: (1) self-supervised pre-training on unlabeled natural images (using SimCLR); (2) further self-supervised pre-training using unlabeled medical data (using either SimCLR or MICLe); followed by (3) task-specific supervised fine-tuning using labeled medical data.
|
| Our approach comprises three steps: (1) Self-supervised pre-training on unlabeled ImageNet using SimCLR (2) Additional self-supervised pre-training using unlabeled medical images. If multiple images of each medical condition are available, a novel Multi-Instance Contrastive Learning (MICLe) strategy is used to construct more informative positive pairs based on different images. (3) Supervised fine-tuning on labeled medical images. Note that unlike step (1), steps (2) and (3) are task and dataset specific. |
After the initial pre-training with SimCLR on unlabeled natural images is complete, we train the model to capture the special characteristics of medical image datasets. This, too, can be done with SimCLR, but this method constructs positive pairs only through augmentation and does not readily leverage patients’ meta data for positive pair construction. Alternatively, we use MICLe, which uses multiple images of the underlying pathology for each patient case, when available, to construct more informative positive pairs for self-supervised learning. Such multi-instance data is often available in medical imaging datasets — e.g., frontal and lateral views of mammograms, retinal fundus images from each eye, etc.
Given multiple images of a given patient case, MICLe constructs a positive pair for self-supervised contrastive learning by drawing two crops from two distinct images from the same patient case. Such images may be taken from different viewing angles and show different body parts with the same underlying pathology. This presents a great opportunity for self-supervised learning algorithms to learn representations that are robust to changes of viewpoint, imaging conditions, and other confounding factors in a direct way. MICLe does not require class label information and only relies on different images of an underlying pathology, the type of which may be unknown.
 |
| MICLe generalizes contrastive learning to leverage special characteristics of medical image datasets (patient metadata) to create realistic augmentations, yielding further performance boost of image classifiers. |
Combining these self-supervised learning strategies, we show that even in a highly competitive production setting we can achieve a sizable gain of 6.7% in top-1 accuracy on dermatology skin condition classification and an improvement of 1.1% in mean AUC on chest X-ray classification, outperforming strong supervised baselines pre-trained on ImageNet (the prevailing protocol for training medical image analysis models). In addition, we show that self-supervised models are robust to distribution shift and can learn efficiently with only a small number of labeled medical images.
Comparison of Supervised and Self-Supervised Pre-training
Despite its simplicity, we observe that pre-training with MICLe consistently improves the performance of dermatology classification over the original method of pre-training with SimCLR under different pre-training dataset and base network architecture choices. Using MICLe for pre-training, translates to (1.18 ± 0.09)% increase in top-1 accuracy for dermatology classification over using SimCLR. The results demonstrate the benefit accrued from utilizing additional metadata or domain knowledge to construct more semantically meaningful augmentations for contrastive pre-training. In addition, our results suggest that wider and deeper models yield greater performance gains, with ResNet-152 (2x width) models often outperforming ResNet-50 (1x width) models or smaller counterparts.
 |
| Comparison of supervised and self-supervised pre-training, followed by supervised fine-tuning using two architectures on dermatology and chest X-ray classification. Self-supervised learning utilizes unlabeled domain-specific medical images and significantly outperforms supervised ImageNet pre-training. |
Improved Generalization with Self-Supervised Models
For each task we perform pretraining and fine-tuning using the in-domain unlabeled and labeled data respectively. We also use another dataset obtained in a different clinical setting as a shifted dataset to further evaluate the robustness of our method to out-of-domain data. For the chest X-ray task, we note that self-supervised pre-training with either ImageNet or CheXpert data improves generalization, but stacking them both yields further gains. As expected, we also note that when only using ImageNet for self-supervised pre-training, the model performs worse compared to using only in-domain data for pre-training.
To test the performance under distribution shift, for each task, we held out additional labeled datasets for testing that were collected under different clinical settings. We find that the performance improvement in the distribution-shifted dataset (ChestX-ray14) by using self-supervised pre-training (both using ImageNet and CheXpert data) is more pronounced than the original improvement on the CheXpert dataset. This is a valuable finding, as generalization under distribution shift is of paramount importance to clinical applications. On the dermatology task, we observe similar trends for a separate shifted dataset that was collected in skin cancer clinics and had a higher prevalence of malignant conditions. This demonstrates that the robustness of the self-supervised representations to distribution shifts is consistent across tasks.
 |
| Evaluation of models on distribution-shifted datasets for the chest-xray interpretation task. We use the model trained on in-domain data to make predictions on an additional shifted dataset without any further fine-tuning (zero-shot transfer learning). We observe that self-supervised pre-training leads to better representations that are more robust to distribution shifts. |
 |
| Evaluation of models on distribution-shifted datasets for the dermatology task. Our results generally suggest that self-supervised pre-trained models can generalize better to distribution shifts with MICLe pre-training leading to the most gains. |
Improved Label Efficiency
We further investigate the label-efficiency of the self-supervised models for medical image classification by fine-tuning the models on different fractions of labeled training data. We use label fractions ranging from 10% to 90% for both Derm and CheXpert training datasets and examine how the performance varies using the different available label fractions for the dermatology task. First, we observe that pre-training using self-supervised models can compensate for low label efficiency for medical image classification, and across the sampled label fractions, self-supervised models consistently outperform the supervised baseline. These results also suggest that MICLe yields proportionally higher gains when fine-tuning with fewer labeled examples. In fact, MICLe is able to match baselines using only 20% of the training data for ResNet-50 (4x) and 30% of the training data for ResNet152 (2x).
 |
| Top-1 accuracy for dermatology condition classification for MICLe, SimCLR, and supervised models under different unlabeled pre-training datasets and varied sizes of label fractions. MICLe is able to match baselines using only 20% of the training data for ResNet-50 (4x). |
Conclusion
Supervised pre-training on natural image datasets is commonly used to improve medical image classification. We investigate an alternative strategy based on self-supervised pre-training on unlabeled natural and medical images and find that it can significantly improve upon supervised pre-training, the standard paradigm for training medical image analysis models. This approach can lead to models that are more accurate and label efficient and are robust to distribution shifts. In addition, our proposed Multi-Instance Contrastive Learning method (MICLe) enables the use of additional metadata to create realistic augmentations, yielding further performance boost of image classifiers.
Self-supervised pre-training is much more scalable than supervised pre-training because class label annotation is not required. We hope this paper will help popularize the use of self-supervised approaches in medical image analysis yielding label efficient and robust models suited for clinical deployment at scale in the real world.
Acknowledgements
This work involved collaborative efforts from a multidisciplinary team of researchers, software engineers, clinicians, and cross-functional contributors across Google Health and Google Brain. We thank our co-authors: Basil Mustafa, Fiona Ryan, Zach Beaver, Jan Freyberg, Jon Deaton, Aaron Loh, Alan Karthikesalingam, Simon Kornblith, Ting Chen, Vivek Natarajan, and Mohammad Norouzi. We also thank Yuan Liu from Google Health for valuable feedback and our partners for access to the datasets used in the research.

3 questions with Seyed Sajjadi: How to utilize a video analytics platform to automate the process of learning
Sajjadi, a co-founder and CEO of Alexa Fund company nFlux.ai, explains how procedure monitoring can help humans, from astronauts to manufacturers, and even home cooks.Read More
At the crossroads of language, technology, and empathy
Rujul Gandhi’s love of reading blossomed into a love of language at age 6, when she discovered a book at a garage sale called “What’s Behind the Word?” With forays into history, etymology, and language genealogies, the book captivated Gandhi, who as an MIT senior remains fascinated with words and how we use them.
Growing up partially in the U.S. and mostly in India, Gandhi was surrounded by a variety of languages and dialects. When she moved to India at age 8, she could already see how knowing the Marathi language allowed her to connect more easily to her classmates — an early lesson in how language shapes our human experiences.
Initially thinking she might want to study creative writing or theater, Gandhi first learned about linguistics as its own field of study through an online course in ninth grade. Now a linguistics major at MIT, she is studying the structure of language from the syllable to sentence level, and also learning about how we perceive language. She finds the human aspects of how we use language, and the fact that languages are constantly changing, particularly compelling.
“When you learn to appreciate language, you can then appreciate culture,” she says.
Communicating and connecting, with a technological assist
Taking advantage of MIT’s Global Teaching Labs program, Gandhi traveled to Kazakhstan in January 2020 to teach linguistics and biology to high school students. Lacking a solid grasp of the language, she cautiously navigated conversations with her students and hosts. However, she soon found that working to understand the language, giving culturally relevant examples, and writing her assignments in Russian and Kazakh allowed her to engage more meaningfully with her students.
Technology also helped bridge the communication barrier between Gandhi and her Russian-speaking host father, who spoke no English. With help from Google Translate, they bonded over shared interests, including 1950s and ’60s Bollywood music.
As she began to study computer science at MIT, Gandhi saw more opportunities to connect people through both language and technology, thus leading her to pursue a double major in linguistics and in computer science and electrical engineering.
“The problems I understand through linguistics, I can try to find solutions to through computer science,” she explains.
Energized by ambitious projects
Gandhi is determined to prioritize social impact while looking for those solutions. Through various leadership roles in on-campus organizations during her time at MIT, especially in the student-run Educational Studies Program (ESP), she realized how much working directly with people and being on the logistical side of large projects energizes her. With ESP, she helps organize events that bring thousands of high school and middle school students to campus each year for classes and other activities led by MIT students.
After her second directing program, Spark 2020, was cancelled last March because of the pandemic, Gandhi eventually embraced the virtual experience. She planned and co-directed a virtual program, Splash: 2020, hosting about 1,100 students. “Interacting with the ESP community convinced me that an organization can function efficiently with a strong commitment to its values,” she says.
The pandemic also heightened Gandhi’s appreciation for the MIT community, as many people reached out to her offering a place to stay when campus shut down. She says she sees MIT as home — a place where she not only feels cared for, but also relishes the opportunity to care for others.
Now, she is bridging cultural barriers on campus through performing art. Dance is another one of Gandhi’s loves. When she couldn’t find a group to practice Indian classical dance with, Gandhi took matters into her own hands. In 2019, she and a couple of friends founded Nritya, a student organization at MIT. The group hopes to have its first in-person performance this fall. “Dance is like its own language,” she observes.
Technology born out of empathy
In her academic work, Gandhi relishes researching linguistics problems from a theoretical perspective, and then applying that knowledge through hands-on experiences. “The good thing about MIT is it lets you go out of your comfort zone,” she says.
For example, in IAP 2019 she worked on a geographical dialect survey of her native Marathi language with Deccan College, a center of linguistics in her hometown. And, through the Undergraduate Research Opportunities Program (UROP), she is currently working on a research project focused on phonetics and phonology, focusing her attention on how language “contact,” or interactions, influences the sounds that speakers use.
The following winter, she also worked with Tarjimly, a nonprofit connecting refugees with interpreters through a smartphone app. She notes that translating systems have advanced quickly in terms of allowing people to communicate more effectively, but she also recognizes that there is great potential to improve them to benefit and reach even more people.
“How are people going to advocate for themselves and make use of public infrastructure if they can’t interface with it?” she asks.
Mulling over other ideas, Gandhi says it would be interesting to explore how sign language might be more effectively be interpreted through a smartphone translating app. And, she sees a need for further improving regional translations to better connect with the culture and context of the areas the language is spoken in, accounting for dialectal differences and new developments.
Looking ahead, Gandhi wants to focus on designing systems that better integrate theoretical developments in linguistics and on making language technology widely accessible. She says she finds the work of bringing together technology and linguistics to be most rewarding when it involves people, and that she finds the most meaning in her projects when they are centered around empathy for others’ experiences.
“The technology born out of empathy is the technology that I want to be working on,” she explains. “Language is fundamentally a people thing; you can’t ignore the people when you’re designing technology that relates to language.”
Deep learning helps predict traffic crashes before they happen
Today’s world is one big maze, connected by layers of concrete and asphalt that afford us the luxury of navigation by vehicle. For many of our road-related advancements — GPS lets us fire fewer neurons thanks to map apps, cameras alert us to potentially costly scrapes and scratches, and electric autonomous cars have lower fuel costs — our safety measures haven’t quite caught up. We still rely on a steady diet of traffic signals, trust, and the steel surrounding us to safely get from point A to point B.
To get ahead of the uncertainty inherent to crashes, scientists from MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL) and the Qatar Center for Artificial Intelligence developed a deep learning model that predicts very high-resolution crash risk maps. Fed on a combination of historical crash data, road maps, satellite imagery, and GPS traces, the risk maps describe the expected number of crashes over a period of time in the future, to identify high-risk areas and predict future crashes.
Typically, these types of risk maps are captured at much lower resolutions that hover around hundreds of meters, which means glossing over crucial details since the roads become blurred together. These maps, though, are 5×5 meter grid cells, and the higher resolution brings newfound clarity: The scientists found that a highway road, for example, has a higher risk than nearby residential roads, and ramps merging and exiting the highway have an even higher risk than other roads.
“By capturing the underlying risk distribution that determines the probability of future crashes at all places, and without any historical data, we can find safer routes, enable auto insurance companies to provide customized insurance plans based on driving trajectories of customers, help city planners design safer roads, and even predict future crashes,” says MIT CSAIL PhD student Songtao He, a lead author on a new paper about the research.
Even though car crashes are sparse, they cost about 3 percent of the world’s GDP and are the leading cause of death in children and young adults. This sparsity makes inferring maps at such a high resolution a tricky task. Crashes at this level are thinly scattered — the average annual odds of a crash in a 5×5 grid cell is about one-in-1,000 — and they rarely happen at the same location twice. Previous attempts to predict crash risk have been largely “historical,” as an area would only be considered high-risk if there was a previous nearby crash.
The team’s approach casts a wider net to capture critical data. It identifies high-risk locations using GPS trajectory patterns, which give information about density, speed, and direction of traffic, and satellite imagery that describes road structures, such as the number of lanes, whether there’s a shoulder, or if there’s a large number of pedestrians. Then, even if a high-risk area has no recorded crashes, it can still be identified as high-risk, based on its traffic patterns and topology alone.
To evaluate the model, the scientists used crashes and data from 2017 and 2018, and tested its performance at predicting crashes in 2019 and 2020. Many locations were identified as high-risk, even though they had no recorded crashes, and also experienced crashes during the follow-up years.
“Our model can generalize from one city to another by combining multiple clues from seemingly unrelated data sources. This is a step toward general AI, because our model can predict crash maps in uncharted territories,” says Amin Sadeghi, a lead scientist at Qatar Computing Research Institute (QCRI) and an author on the paper. “The model can be used to infer a useful crash map even in the absence of historical crash data, which could translate to positive use for city planning and policymaking by comparing imaginary scenarios.”
The dataset covered 7,500 square kilometers from Los Angeles, New York City, Chicago and Boston. Among the four cities, L.A. was the most unsafe, since it had the highest crash density, followed by New York City, Chicago, and Boston.
“If people can use the risk map to identify potentially high-risk road segments, they can take action in advance to reduce the risk of trips they take. Apps like Waze and Apple Maps have incident feature tools, but we’re trying to get ahead of the crashes — before they happen,” says He.
He and Sadeghi wrote the paper alongside Sanjay Chawla, research director at QCRI, and MIT professors of electrical engineering and computer science Mohammad Alizadeh, Hari Balakrishnan, and Sam Madden. They will present the paper at the 2021 International Conference on Computer Vision.
Get Started with TensorFlow Lite Micro on Sony’s Spresense
A guest post by Daniel Sandblom, Sony
Editor’s note: an earlier version of this article appeared on the Sony Developers.

Now you can develop solutions with TensorFlow Lite Micro (TFLM) for the Spresense microcontroller board from Sony. TFLM is designed to run on microcontroller systems where the hardware resources are more limited compared to larger computerized systems. The footprint of TFLM is typically in the order of only 10’s of kBs.
What you get is a combination of a leading machine learning ecosystem with a high performance microcontroller running at super low power consumption. The Spresense board was designed with camera and hi-res audio inputs as core features which open up a substantial set of use cases. Pete Warden, a research engineer on the TensorFlow team, shares his view on that TFLM is now available for use with the Spresense board: “It’s great to see this kind of compute capability tightly integrated into a low power sensor, the combination will help make machine learning accessible to developers in medical, agriculture, industrial monitoring and many other areas where a small form factor and energy are strong constraints.”
The development of TFLM has been a tight collaboration between Google and Arm to optimize functionality while keeping the footprint to a minimum. Fredrik Knutsson, Team Lead at Arm, explains how TFLM has been optimized for the ARM processor architecture: “Arm’s open source CMSIS-NN library provides high performance implementations of common neural network functions for Arm Cortex-M processors. Arm’s engineers have worked closely with the TensorFlow team to develop optimized versions of the TensorFlow Lite kernels in the CMSIS-NN library, delivering extremely fast performance on Arm Cortex-M cores like Spresense.”
How to get started with TensorFlow on Spresense
The easiest and quickest way to get started with TensorFlow on Spresense is to run one of the examples. There is one hello_world example that shows the basic steps and functionality. There is also a micro_speech example using Spresense’s audio abilities, and there’s a person_detection example utilizing the Spresense camera. The latter two examples demonstrate how to link visual and audio sensors to the inputs of TensorFlow models.
Below are the general steps to run the examples:
- Set up the Spresense SDK: Getting started with TensorFlow for Spresense
- Download the Spresense repository including the examples
- Build and Flash the binary into Spresense main board
- Run the example
Heads-up: we will run an upcoming webinar for “TensorFlow on Spresense” on October 14 – register here!
Check out these links for more info:
Cristiana Lara’s journey from a curious student to an Amazon research scientist
Today she’s helping Amazon to better formulate how to more efficiently transport packages through the middle mile of its complex delivery network.Read More
Google at ICCV 2021
Posted by Cat Armato, Program Manager, Google Research
The International Conference on Computer Vision 2021 (ICCV 2021), one of the world’s premier conferences on computer vision, starts this week. A Champion Sponsor and leader in computer vision research, Google will have a strong presence at ICCV 2021 with more than 50 research presentations and involvement in the organization of a number of workshops and tutorials.
If you are attending ICCV this year, we hope you’ll check out the work of our researchers who are actively pursuing the latest innovations in computer vision. Learn more about our research being presented in the list below (Google affilitation in bold).
Organizing Committee
Diversity and Inclusion Chair: Negar Rostamzadeh
Area Chairs: Andrea Tagliasacchi, Boqing Gong, Ce Liu, Dilip Krishnan, Jordi Pont-Tuset, Michael Rubinstein, Michael S. Ryoo, Negar Rostamzadeh, Noah Snavely, Rodrigo Benenson, Tsung-Yi Lin, Vittorio Ferrari
Publications
MosaicOS: A Simple and Effective Use of Object-Centric Images for Long-Tailed Object Detection
Cheng Zhang, Tai-Yu Pan, Yandong Li, Hexiang Hu, Dong Xuan, Soravit Changpinyo, Boqing Gong, Wei-Lun Chao
Learning to Resize Images for Computer Vision Tasks
Hossein Talebi, Peyman Milanfar
Joint Representation Learning and Novel Category Discovery on Single- and Multi-Modal Data
Xuhui Jia, Kai Han, Yukun Zhu, Bradley Green
Explaining in Style: Training a GAN to Explain a Classifier in StyleSpace
Oran Lang, Yossi Gandelsman, Michal Yarom, Yoav Wald, Gal Elidan, Avinatan Hassidim, William T. Freeman, Phillip Isola, Amir Globerson, Michal Irani, Inbar Mosseri
Learning Fast Sample Re-weighting without Reward Data
Zizhao Zhang, Tomas Pfister
Contrastive Multimodal Fusion with TupleInfoNCE
Yunze Liu, Qingnan Fan, Shanghang Zhang, Hao Dong, Thomas Funkhouser, Li Yi
Learning Temporal Dynamics from Cycles in Narrated Video
Dave Epstein*, Jiajun Wu, Cordelia Schmid, Chen Sun
Patch Craft: Video Denoising by Deep Modeling and Patch Matching
Gregory Vaksman, Michael Elad, Peyman Milanfar
How to Train Neural Networks for Flare Removal
Yicheng Wu*, Qiurui He, Tianfan Xue, Rahul Garg, Jiawen Chen, Ashok Veeraraghavan, Jonathan T. Barron
Learning to Reduce Defocus Blur by Realistically Modeling Dual-Pixel Data
Abdullah Abuolaim*, Mauricio Delbracio, Damien Kelly, Michael S. Brown, Peyman Milanfar
Hybrid Neural Fusion for Full-Frame Video Stabilization
Yu-Lun Liu, Wei-Sheng Lai, Ming-Hsuan Yang, Yung-Yu Chuang, Jia-Bin Huang
A Dark Flash Normal Camera
Zhihao Xia*, Jason Lawrence, Supreeth Achar
Efficient Large Scale Inlier Voting for Geometric Vision Problems
Dror Aiger, Simon Lynen, Jan Hosang, Bernhard Zeisl
Big Self-Supervised Models Advance Medical Image Classification
Shekoofeh Azizi, Basil Mustafa, Fiona Ryan*, Zachary Beaver, Jan Freyberg, Jonathan Deaton, Aaron Loh, Alan Karthikesalingam, Simon Kornblith, Ting Chen, Vivek Natarajan, Mohammad Norouzi
Physics-Enhanced Machine Learning for Virtual Fluorescence Microscopy
Colin L. Cooke, Fanjie Kong, Amey Chaware, Kevin C. Zhou, Kanghyun Kim, Rong Xu, D. Michael Ando, Samuel J. Yang, Pavan Chandra Konda, Roarke Horstmeyer
Retrieve in Style: Unsupervised Facial Feature Transfer and Retrieval
Min Jin Chong, Wen-Sheng Chu, Abhishek Kumar, David Forsyth
Deep Survival Analysis with Longitudinal X-Rays for COVID-19
Michelle Shu, Richard Strong Bowen, Charles Herrmann, Gengmo Qi, Michele Santacatterina, Ramin Zabih
MUSIQ: Multi-Scale Image Quality Transformer
Junjie Ke, Qifei Wang, Yilin Wang, Peyman Milanfar, Feng Yang
imGHUM: Implicit Generative Models of 3D Human Shape and Articulated Pose
Thiemo Alldieck, Hongyi Xu, Cristian Sminchisescu
Deep Hybrid Self-Prior for Full 3D Mesh Generation
Xingkui Wei, Zhengqing Chen, Yanwei Fu, Zhaopeng Cui, Yinda Zhang
Differentiable Surface Rendering via Non-Differentiable Sampling
Forrester Cole, Kyle Genova, Avneesh Sud, Daniel Vlasic, Zhoutong Zhang
A Lazy Approach to Long-Horizon Gradient-Based Meta-Learning
Muhammad Abdullah Jamal, Liqiang Wang, Boqing Gong
ViViT: A Video Vision Transformer
Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid
The Surprising Impact of Mask-Head Architecture on Novel Class Segmentation (see the blog post)
Vighnesh Birodkar, Zhichao Lu, Siyang Li, Vivek Rathod, Jonathan Huang
Generalize Then Adapt: Source-Free Domain Adaptive Semantic Segmentation
Jogendra Nath Kundu, Akshay Kulkarni, Amit Singh, Varun Jampani, R. Venkatesh Babu
Unified Graph Structured Models for Video Understanding
Anurag Arnab, Chen Sun, Cordelia Schmid
The Many Faces of Robustness: A Critical Analysis of Out-of-Distribution Generalization
Dan Hendrycks, Steven Basart, Norman Mu, Saurav Kadavath, Frank Wang, Evan Dorundo, Rahul Desai, Tyler Zhu, Samyak Parajuli, Mike Guo, Dawn Song, Jacob Steinhardt, Justin Gilmer
Learning Rare Category Classifiers on a Tight Labeling Budget
Ravi Teja Mullapudi, Fait Poms, William R. Mark, Deva Ramanan, Kayvon Fatahalian
Composable Augmentation Encoding for Video Representation Learning
Chen Sun, Arsha Nagrani, Yonglong Tian, Cordelia Schmid
Multi-Task Self-Training for Learning General Representations
Golnaz Ghiasi, Barret Zoph, Ekin D. Cubuk, Quoc V. Le, Tsung-Yi Lin
With a Little Help From My Friends: Nearest-Neighbor Contrastive Learning of Visual Representations
Debidatta Dwibedi, Yusuf Aytar, Jonathan Tompson, Pierre Sermanet, Andrew Zisserman
Understanding Robustness of Transformers for Image Classification
Srinadh Bhojanapalli, Ayan Chakrabarti, Daniel Glasner, Daliang Li, Thomas Unterthiner, Andreas Veit
Impact of Aliasing on Generalization in Deep Convolutional Networks
Cristina Vasconcelos, Hugo Larochelle, Vincent Dumoulin, Rob Romijnders, Nicolas Le Roux, Ross Goroshin
von Mises-Fisher Loss: An Exploration of Embedding Geometries for Supervised Learning
Tyler R. Scott*, Andrew C. Gallagher, Michael C. Mozer
Contrastive Learning for Label Efficient Semantic Segmentation
Xiangyun Zhao*, Raviteja Vemulapalli, Philip Andrew Mansfield, Boqing Gong, Bradley Green, Lior Shapira, Ying Wu
Interacting Two-Hand 3D Pose and Shape Reconstruction from Single Color Image
Baowen Zhang, Yangang Wang, Xiaoming Deng, Yinda Zhang, Ping Tan, Cuixia Ma, Hongan Wang
Telling the What While Pointing to the Where: Multimodal Queries for Image Retrieval
Soravit Changpinyo, Jordi Pont-Tuset, Vittorio Ferrari, Radu Soricut
SO-Pose: Exploiting Self-Occlusion for Direct 6D Pose Estimation
Yan Di, Fabian Manhardt, Gu Wang, Xiangyang Ji, Nassir Navab, Federico Tombari
Patch2CAD: Patchwise Embedding Learning for In-the-Wild Shape Retrieval from a Single Image
Weicheng Kuo, Anelia Angelova, Tsung-Yi Lin, Angela Dai
NeRD: Neural Reflectance Decomposition From Image Collections
Mark Boss, Raphael Braun, Varun Jampani, Jonathan T. Barron, Ce Liu, Hendrik P.A. Lensch
THUNDR: Transformer-Based 3D Human Reconstruction with Markers
Mihai Zanfir, Andrei Zanfir, Eduard Gabriel Bazavan, William T. Freeman, Rahul Sukthankar, Cristian Sminchisescu
Discovering 3D Parts from Image Collections
Chun-Han Yao, Wei-Chih Hung, Varun Jampani, Ming-Hsuan Yang
Multiresolution Deep Implicit Functions for 3D Shape Representation
Zhang Chen*, Yinda Zhang, Kyle Genova, Sean Fanello, Sofien Bouaziz, Christian Hane, Ruofei Du, Cem Keskin, Thomas Funkhouser, Danhang Tang
AI Choreographer: Music Conditioned 3D Dance Generation With AIST++ (see the blog post)
Ruilong Li*, Shan Yang, David A. Ross, Angjoo Kanazawa
Learning Object-Compositional Neural Radiance Field for Editable Scene Rendering
Bangbang Yang, Han Zhou, Yinda Zhang, Hujun Bao, Yinghao Xu, Guofeng Zhang, Yijin Li, Zhaopeng Cui
VariTex: Variational Neural Face Textures
Marcel C. Buhler, Abhimitra Meka, Gengyan Li, Thabo Beeler, Otmar Hilliges
Pathdreamer: A World Model for Indoor Navigation (see the blog post)
Jing Yu Koh, Honglak Lee, Yinfei Yang, Jason Baldridge, Peter Anderson
4D-Net for Learned Multi-Modal Alignment
AJ Piergiovanni, Vincent Casser, Michael S. Ryoo, Anelia Angelova
Episodic Transformer for Vision-and-Language Navigation
Alexander Pashevich*, Cordelia Schmid, Chen Sun
Graph-to-3D: End-to-End Generation and Manipulation of 3D Scenes Using Scene Graphs
Helisa Dhamo, Fabian Manhardt, Nassir Navab, Federico Tombari
Unconditional Scene Graph Generation
Sarthak Garg, Helisa Dhamo, Azade Farshad, Sabrina Musatian, Nassir Navab, Federico Tombari
Panoptic Narrative Grounding
Cristina González, Nicolás Ayobi, Isabela Hernández, José Hernández, Jordi Pont-Tuset, Pablo Arbeláez
Cross-Camera Convolutional Color Constancy
Mahmoud Afifi*, Jonathan T. Barron, Chloe LeGendre, Yun-Ta Tsai, Francois Bleibel
Defocus Map Estimation and Deblurring from a Single Dual-Pixel Image
Shumian Xin*, Neal Wadhwa, Tianfan Xue, Jonathan T. Barron, Pratul P. Srinivasan, Jiawen Chen, Ioannis Gkioulekas, Rahul Garg
COMISR: Compression-Informed Video Super-Resolution
Yinxiao Li, Pengchong Jin, Feng Yang, Ce Liu, Ming-Hsuan Yang, Peyman Milanfar
Mip-NeRF: A Multiscale Representation for Anti-Aliasing Neural Radiance Fields
Jonathan T. Barron, Ben Mildenhall, Matthew Tancik, Peter Hedman, Ricardo Martin-Brualla, Pratul P. Srinivasan
Nerfies: Deformable Neural Radiance Fields
Keunhong Park*, Utkarsh Sinha, Jonathan T. Barron, Sofien Bouaziz, Dan B Goldman, Steven M. Seitz, Ricardo Martin-Brualla
Baking Neural Radiance Fields for Real-Time View Synthesis
Peter Hedman, Pratul P. Srinivasan, Ben Mildenhall, Jonathan T. Barron, Paul Debevec
Stacked Homography Transformations for Multi-View Pedestrian Detection
Liangchen Song, Jialian Wu, Ming Yang, Qian Zhang, Yuan Li, Junsong Yuan
COTR: Correspondence Transformer for Matching Across Images
Wei Jiang, Eduard Trulls, Jan Hosang, Andrea Tagliasacchi, Kwang Moo Yi
Large Scale Interactive Motion Forecasting for Autonomous Driving: The Waymo Open Motion Dataset
Scott Ettinger, Shuyang Cheng, Benjamin Caine, Chenxi Liu, Hang Zhao, Sabeek Pradhan, Yuning Chai, Ben Sapp, Charles R. Qi, Yin Zhou, Zoey Yang, Aurélien Chouard, Pei Sun, Jiquan Ngiam, Vijay Vasudevan, Alexander McCauley, Jonathon Shlens, Dragomir Anguelov
Low-Shot Validation: Active Importance Sampling for Estimating Classifier Performance on Rare Categories
Fait Poms, Vishnu Sarukkai, Ravi Teja Mullapudi, Nimit S. Sohoni, William R. Mark, Deva Ramanan, Kayvon Fatahalian
Vector Neurons: A General Framework for SO(3)-Equivariant Networks
Congyue Deng, Or Litany, Yueqi Duan, Adrien Poulenard, Andrea Tagliasacchi, Leonidas J. Guibas
SLIDE: Single Image 3D Photography with Soft Layering and Depth-Aware Inpainting
Varun Jampani, Huiwen Chang, Kyle Sargent, Abhishek Kar, Richard Tucker, Michael Krainin, Dominik Kaeser, William T. Freeman, David Salesin, Brian Curless, Ce Liu
DeepPanoContext: Panoramic 3D Scene Understanding with Holistic Scene Context Graph and Relation-Based Optimization
Cheng Zhang, Zhaopeng Cui, Cai Chen, Shuaicheng Liu, Bing Zeng, Hujun Bao, Yinda Zhang
Infinite Nature: Perpetual View Generation of Natural Scenes from a Single Image
Andrew Liu, Richard Tucker, Varun Jampani, Ameesh Makadia, Noah Snavely, Angjoo Kanazawa
Workshops (only Google affiliations are noted)
Visual Inductive Priors for Data-Efficient Deep Learning Workshop
Speakers: Ekin Dogus Cubuk, Chelsea Finn
Instance-Level Recognition Workshop
Organizers: Andre Araujo, Cam Askew, Bingyi Cao, Jack Sim, Tobias Weyand
Unsup3D: Unsupervised 3D Learning in the Wild
Speakers: Adel Ahmadyan, Noah Snavely, Tali Dekel
Embedded and Real-World Computer Vision in Autonomous Driving (ERCVAD 2021)
Speakers: Mingxing Tan
Adversarial Robustness in the Real World
Speakers: Nicholas Carlini
Neural Architectures: Past, Present and Future
Speakers: Been Kim, Hanxiao Liu Organizers: Azade Nazi, Mingxing Tan, Quoc V. Le
Computational Challenges in Digital Pathology
Organizers: Craig Mermel, Po-Hsuan Cameron Chen
Interactive Labeling and Data Augmentation for Vision
Speakers: Vittorio Ferrari
Map-Based Localization for Autonomous Driving
Speakers: Simon Lynen
DeeperAction: Challenge and Workshop on Localized and Detailed Understanding of Human Actions in Videos
Speakers: Chen Sun Advisors: Rahul Sukthankar
Differentiable 3D Vision and Graphics
Speakers: Angjoo Kanazawa
Deep Multi-Task Learning in Computer Vision
Speakers: Chelsea Finn
Computer Vision for AR/VR
Speakers: Matthias Grundmann, Ira Kemelmacher-Shlizerman
GigaVision: When Gigapixel Videography Meets Computer Vision
Organizers: Feng Yang
Human Interaction for Robotic Navigation
Speakers: Peter Anderson
Advances in Image Manipulation Workshop and Challenges
Organizers: Ming-Hsuan Yang
More Exploration, Less Exploitation (MELEX)
Speakers: Angjoo Kanazawa
Structural and Compositional Learning on 3D Data
Speakers: Thomas Funkhouser, Kyle Genova Organizers: Fei Xia
Simulation Technology for Embodied AI
Organizers: Li Yi
Video Scene Parsing in the Wild Challenge Workshop
Speakers: Liang-Chieh (Jay) Chen
Structured Representations for Video Understanding
Organizers: Cordelia Schmid
Closing the Loop Between Vision and Language
Speakers: Cordelia Schmid
Segmenting and Tracking Every Point and Pixel: 6th Workshop on Benchmarking Multi-Target Tracking
Organizers: Jun Xie, Liang-Chieh Chen
AI for Creative Video Editing and Understanding
Speakers: Angjoo Kanazawa, Irfan Essa
BEHAVIOR: Benchmark for Everyday Household Activities in Virtual, Interactive, and Ecological Environments
Speakers: Chelsea Finn Organizers: Fei Xia
Computer Vision for Automated Medical Diagnosis
Organizers: Maithra Raghu
Computer Vision for the Factory Floor
Speakers: Cordelia Schmid
Tutorials (only Google affiliations are noted)
Towards Robust, Trustworthy, and Explainable Computer Vision
Speakers: Sara Hooker
Multi-Modality Learning from Videos and Beyond
Organizers: Arsha Nagrani
Tutorial on Large Scale Holistic Video Understanding
Organizers: David Ross
Efficient Video Understanding: State of the Art, Challenges, and Opportunities
Organizers: Arsha Nagrani
* Indicates work done while at Google
How DermAssist uses TensorFlow.js for on-device image quality checks
Posted by Miles Hutson and Aaron Loh, Google Health
At Google I/O in May, we previewed our DermAssist web application designed to help people understand issues related to their skin. The tool is designed to be easy to use. Upon opening it, users are expected to take three images of their skin, hair, or nail concern from multiple angles, and provide some additional information about themselves and their condition.
 |
| This product has been CE marked as a Class I medical device in the EU. It is not available in the United States. |
We recognize that when users take pictures on their phone, some images could be blurry or have poor lighting. To address this, we initially added a “quality check” after images had been uploaded, which would prompt people to retake an image when necessary. However, these prompts could be a frustrating experience for them, depending on their upload speed, how long they took to acquire the image, and the multiple retakes it might require to pass the quality check.
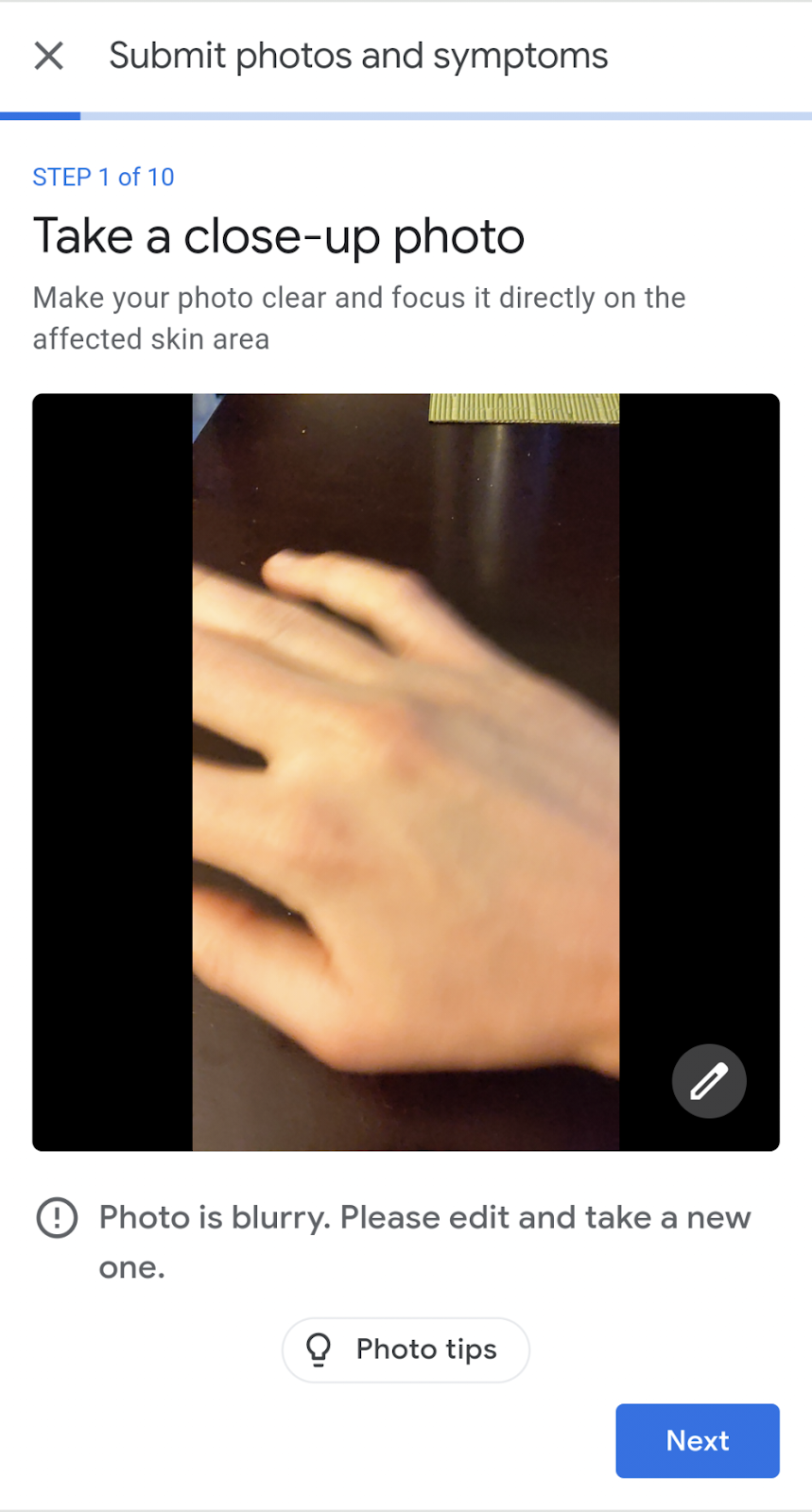 |
| Letting the user know they uploaded an image with insufficient quality and advising them to retake it before they proceed. |
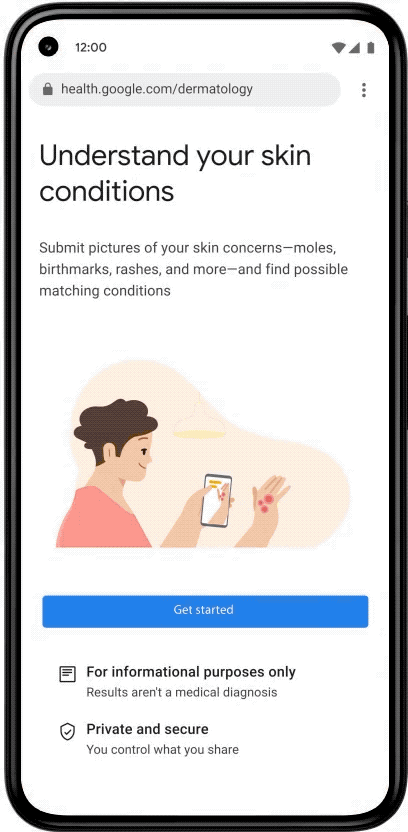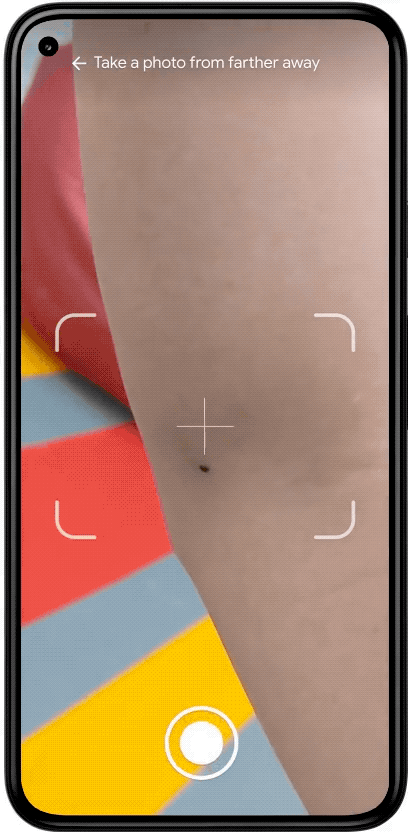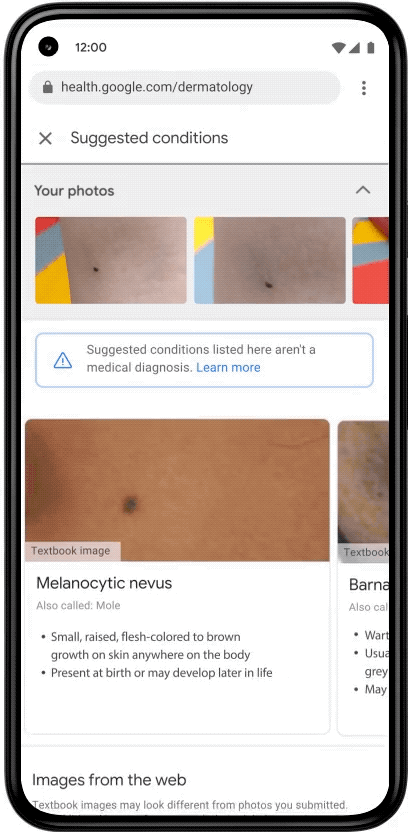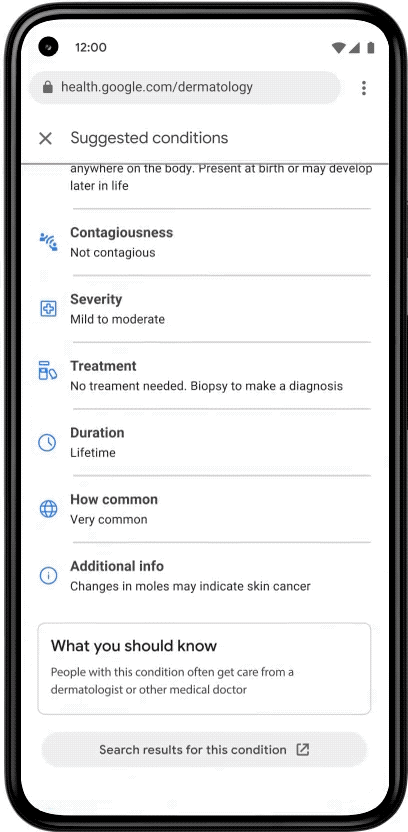
To improve their experience, we decided to give users image quality feedback both on-device as they line up a photo, and when they review the photo before uploading. The way this feature works can be seen below. As the user lines up their camera for a shot, they may get a notification that their environment has a lighting issue (right image). Or, they may be notified that they took a blurry photo as they moved their camera (left image); the model helpfully lets them know their image is blurred before they go to the trouble of uploading it. They can decide to go back and correct the issue without the need to upload the image.
 |
 |
Examples of poor lighting or blurry images that obtain real time feedback so the user knows to take a new photo
Developing the Model
When developing the model, it was important to ensure that the model could comfortably run on-device. One such architecture designed for that purpose is MobileNetV2, which we selected as the backbone for the model.
Our discussions with dermatologists highlighted recurrent issues with image quality, such as the image being too blurry, too badly lit, or inappropriate for interpreting skin diseases. We curated several datasets to tackle those issues, which also informed the outputs of the model. The datasets included a crowdsourced data collection, public datasets, data obtained from tele-dermatology services, and synthetically generated images, many of which were further labeled by trained human graders. Combined, we trained the model on more than 30k images.
We trained the model with multiple binary heads, one for each quality issue. In the diagram below, we see how the input image is fed into a MobileNet feature extractor. This feature embedding is then fed to multiple distinct fully connected layers, producing a binary output (yes/no), each corresponding to a certain quality issue.

The infrastructure we used to train the model was built using TensorFlow, and exported models in the standard SavedModel format.
Translating the model to TensorFlow.js
Our team’s infrastructure for training models makes use of TensorFlow examples, which meant that the exported SavedModel had nodes for loading and preprocessing TensorFlow Examples.
TensorFlow.js at present does not support such preprocessing nodes. Therefore, we modified the signature of the SavedModel to use the image input node after the preprocessing nodes as input to the model. We re-implemented the processing in our Angular integration below.
Having rebuilt the SavedModel in the correct format for conversion, we employed the TensorFlow.js converter to convert it to the TensorFlow.js model format, which consists of a JSON file identifying the model topology, as well as the weights in sharded bin files.
tensorflowjs_converter --input_format=keras /path/to/tfjs/signature/ /path/to/write/tfjs_modelIntegrating TensorFlow.js with Observables and the Image Capture API
With the model trained, serialized, and made available for TensorFlow.js, it might feel like the job is pretty much done. However, we still had to integrate the TensorFlow.js model into our Angular 2 web application. While doing that, we had the goal that the model would ultimately be exposed as an API similar to other components. A good abstraction would allow frontend engineers to work with the TensorFlow.js model as they would work with any other part of the application, rather than as a unique component.
To begin, we created a wrapper class around the model ImageQualityPredictor. This Typescript class exposed only two methods:
- A static method
createImageQualityPredictorthat, given a URL for the model, returns a promise for anImageQualityPredictor. - A
makePredictionmethod that takes ImageData and returns an array of quality predictions above a given threshold.
We found that the implementation of makePrediction was key for abstracting the inner workings of our model. The result of calling execute on our model was an array of Tensors representing yes/no probabilities for each binary head. But we didn’t want the downstream application code to be responsible for the delicate task of thresholding these tensors and connecting them back to the heads’ descriptions. Instead, we moved these details inside of our wrapper class. The final return value to the caller was instead an interface ImageQualityPrediction.
export interface ImageQualityPrediction {
score: number;
qualityIssue: QualityIssue;
}
In order to make sure that a single ImageQualityPredictor was shared across the application, we in turn wrapped ImageQualityPredictor in a singleton ImageQualityModelService. This service handled the initialization of the predictor and tracked if the predictor already had a request in progress. It also contained helper methods for extracting frames from the ImageCapture API that our camera feature is built on and translating QualityIssue to plain English strings.
Finally, we combined the CameraService and our ImageQualityModelService in an ImageQualityService. The final product exposed for use in any given front end component is a simple observable that provides text describing any quality issues.
@Injectable()
export class ImageQualityService {
readonly realTimeImageQualityText$: Observable;
constructor(
private readonly cameraService: CameraService,
private readonly imageQualityModelService: ImageQualityModelService) {
const retrieveText = () =>
this.imageQualityModelService.runModel(this.cameraService.grabFrame());
this.realTimeImageQualityText$ =
interval(REFRESH_INTERVAL_MS)
.pipe(
filter(() => !imageQualityModelService.requestInProgress),
mergeMap(retrieveText),
);
}
// ...
}
This lends itself well to Angular’s normal templating system, accomplishing our goal of making a TensorFlow.js model in Angular as easy to work with as any other component for front end engineers. For example, a suggestion chip can be as easy to include in a component as
<suggestive-chip *ngIf="(imageQualityText$ | async) as text"
>{{text}}</suggestive-chip>Looking Ahead
With helping users to capture better pictures in mind, we developed an on-device image quality check for the DermAssist app to provide real-time guidance on image intake. Part of making users’ lives easier is making sure that this model works fast enough such that we can show a notification as quickly as possible while they’re taking a picture. For us, this means finding ways to reduce the model size in order to reduce the time it takes to load on a user’s device. Possible techniques to further advance this goal may be model quantization, or attempts at model distillation into smaller architectures.
To learn more about the DermAssist application, check out our blog post from Google I/O.
To learn more about TensorFlow.js, you can visit the main site here, also be sure to check out the tutorials and guide.
How the second-gen Echo Buds got smaller and better
Take a behind-the-scenes look at the unique challenges the engineering teams faced, and how they used scientific research to drive fundamental innovation.Read More