Amazon Personalize enables developers to build applications with the same machine learning (ML) technology used by Amazon.com for real-time personalized recommendations—no ML expertise required. Amazon Personalize makes it easy for developers to build applications capable of delivering a wide array of personalization experiences, including specific product recommendations, personalized product re-ranking, and customized direct marketing. Besides applications in retail and ecommerce, other common use cases for Amazon Personalize include recommending videos, blog posts, or newsfeeds based on users’ activity history.
What if you wanted to recommend users of common interest to connect with each other? As the pandemic pushes many of our normal activities virtual, connecting with people is a greater challenge than ever before. This post discusses how 6Connex turned this challenge into an opportunity by harnessing Amazon Personalize to elevate their “user matchmaking” feature.
6Connex and event AI
6Connex is an enterprise virtual venue and hybrid events system. Their cloud-based product portfolio includes virtual environments, learning management, and webinars. Attendee experience is one of the most important metrics for their success.
Attendees have better experiences when they are engaged not only with the event’s content, organizers, and sponsors, but also when making connections with other attendees. Engagement metrics are measured and reported for each attendee activity on the platform, as well as feedback from post-event surveys. The goal is to make the events system more attendee-centric by not only providing personalized content and activity recommendations, but also making matchmaking suggestions for attendees based on similar interests and activity history. By adding event AI features to their platform, 6Connex fosters more meaningful connections between attendees, and keeps their attendees more engaged with a personalized event journey.
Implementation and solution architecture
6Connex built their matchmaking solution using the related items recipe (SIMS) of Amazon Personalize. The SIMS algorithm uses collaborative filtering to recommend items that are similar to a given item. The novelty of 6Connex’s approach lies in the reverse mapping of users and items. In this solution, event attendees are items in Amazon Personalize terms, and content, meeting rooms, and so on are users’ in Amazon Personalize terms.
When a platform user joins a meeting room or views a piece of content, an interaction is created. To increase the accuracy of interaction types, also known as event_type, you can add logic to only count as an interaction when a user stays in a meeting room for at least a certain amount of time. This eliminates accidental clicks and cases when users join but quickly leave a room due to lack of interest.
As many users interact with the platform during a live event, interactions are streamed in real time from the platform via Amazon Kinesis Data Streams. AWS Lambda functions are used for data transformation before streaming data directly to Amazon Personalize through an event tracker. This mechanism also enables Amazon Personalize to adjust to changing user interest over time, allowing recommendations to adapt in real time.
After a model is trained in Amazon Personalize, a fully managed inference endpoint (campaign) is created to serve real-time recommendations for 6Connex’s platform. To answer the question “for each attendee, who are similar attendees?”, 6Connex’s client-side application queries the GetRecommendations API with a current user (represented as an itemId). The API response provides recommended connections because they have been identified as similar by the Amazon Personalize.
Due to its deep learning capabilities, Amazon Personalize requires at least 1,000 interaction data points before training the model. At the start of a live event, there aren’t enough interactions, therefore a rules engine is used at the beginning of an event to provide the initial recommendations prior to gathering 1000 data points. The following table shows the three main phases of an event where connection recommendations are generated.
| Rule-based recommendations |
|
| Amazon Personalize real-time recommendations during live sessions |
|
| Amazon Personalize batch recommendations for on-demand users |
|
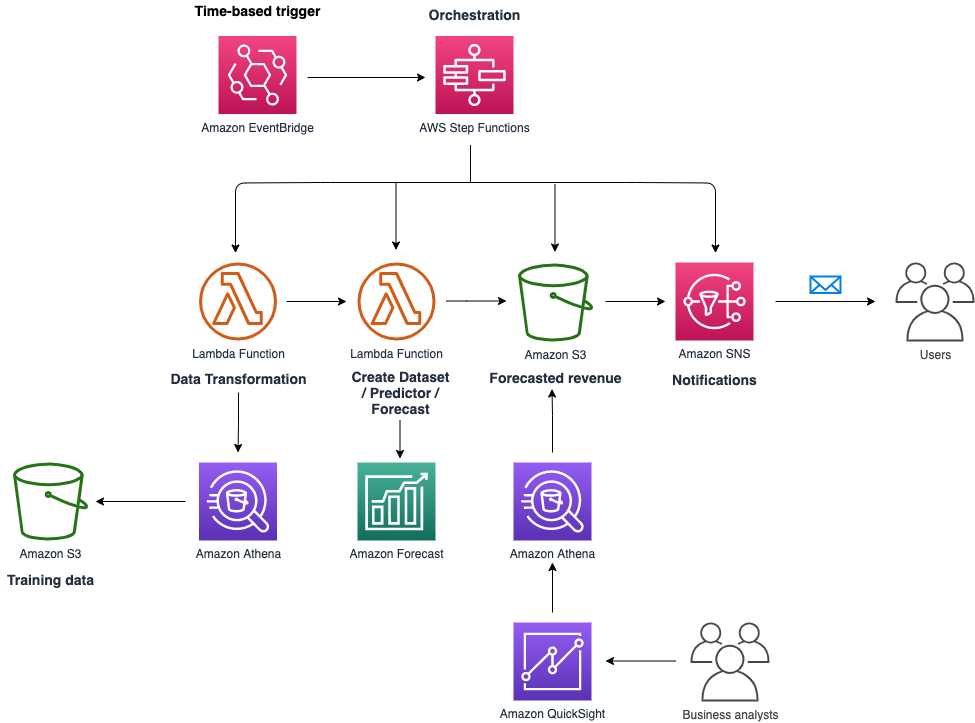
For a high-level example architecture, see the following diagram.

The following are the steps involved in the solution architecture:
- 6Connex web application calls the
GetRecommendationsAPI to retrieve recommended connections. - A matchmaking Lambda function retrieves recommendations.
- Until the training threshold of 1,000 interaction data points is reached, the matchmaking function uses a simple rules engine to provide recommendations.
- Recommendations are generated from Amazon Personalize and stored in Amazon ElastiCache. The reason for caching recommendations is to improve response performance while reducing the number of queries on the Amazon Personalize API. When new recommendations are requested, or when the cache expires (expiration is set to every 15 minutes), recommendations are pulled from Amazon Personalize.
- New user interactions are ingested in real time via Kinesis Data Streams.
- A Lambda function consumes data from the data stream, performs data transformation, persists the transformed data to Amazon Simple Storage Service (Amazon S3) and related metadata to Amazon DynamoDB, and sends the records to Amazon Personalize via the
PutEventsAPI. - AWS Step Functions orchestrates the process for creating solutions, training, retraining, and several other workflows. More details on the Step Functions workflow are in the next section.
- Amazon EventBridge schedules regular retraining events during the virtual events. We also use EventBridge to trigger batch recommendations after the virtual events are over and when the contents are served to end users on demand.
- Recommendations are stored in DynamoDB for use during the on-demand period and also for future analysis.
Adoption of MLOps
It was crucial for 6Connex to quickly shift from a rules-based recommender engine to personalized recommendations using Amazon Personalize. To accelerate this shift and hydrate the interactions dataset, 6Connex infers interactions not only from content engagement, but also from other sources such as pre-events questionnaires. This is an important development that increased the speed to when users start receiving ML-based recommendations.
More importantly, the adoption of Amazon Personalize MLOps enabled 6Connex to automate and accelerate the transition from rule-based recommendations to personalized recommendations using Amazon Personalize. After the minimum threshold for data is met, Step Functions loads data into Amazon Personalize and manages the training process.
The following diagram shows the MLOps pipeline for the initial loading of data, training solutions, and deploying campaigns.
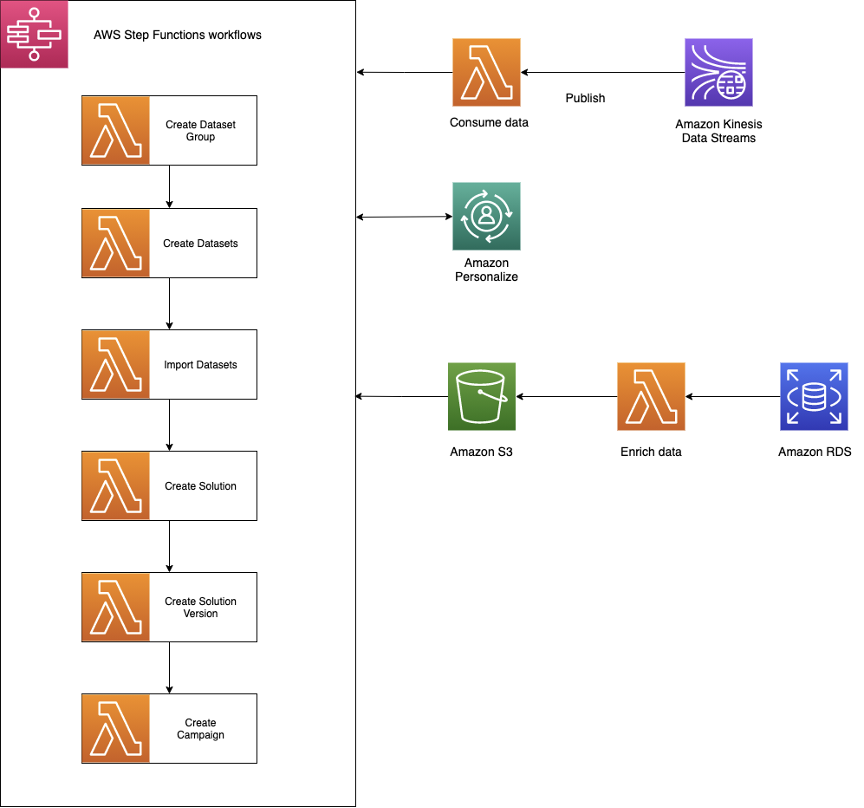
6Connex created their MLOps solution based on the Amazon Personalize MLOps reference solution to automate this process. There are several Step Functions workflows that offload long-running processes such loading batch recommendations in DynamoDB, retraining Amazon Personalize solutions, and cleaning up after an event is complete.
With Amazon Personalize and MLOps pipelines, 6Connex brought an AI solution to market in less than half the time it would have taken to develop and deploy their own ML infrastructure. Moreover, these solutions reduced the cost of acquiring data science and ML expertise. As a result, 6Connex realized a competitive advantage through AI-based personalized recommendations for each individual user.
Based on the success of this engagement, 6Connex plans to expand its usage of Amazon Personalize to provide content-based recommendations in the near future. 6Connex is looking forward to expanding the partnership not only in ML, but also in data analytics and business intelligence to serve the fast-growing hybrid event market.
Conclusion
With a well-designed MLOps pipeline and some creativity, 6Connex built a robust recommendation engine using Amazon Personalize in a short amount of time.
Do you have a use case for a recommendation engine but are short on time or ML expertise? You can get started with Amazon Personalize using the Developer Guide, as well as a myriad of hands-on resources such as the Amazon Personalize Samples GitHub repo.
If you have any questions on this matchmaking solution, please leave a comment!
About the Author
 Shu Jackson is a Senior Solutions Architect with AWS. Shu works with startup customers helping them design and build solutions in the cloud, with a focus on AI/ML.
Shu Jackson is a Senior Solutions Architect with AWS. Shu works with startup customers helping them design and build solutions in the cloud, with a focus on AI/ML.
 Luis Lopez Soria is a Sr AI/ML specialist solutions architect working with the Amazon Machine Learning team. He works with AWS customers to help them adopt machine learning on a large scale. He enjoys playing sports, traveling around the world, and exploring new foods and cultures.
Luis Lopez Soria is a Sr AI/ML specialist solutions architect working with the Amazon Machine Learning team. He works with AWS customers to help them adopt machine learning on a large scale. He enjoys playing sports, traveling around the world, and exploring new foods and cultures.







 Prem Ranga is an Enterprise Solutions Architect based out of Houston, Texas. He is part of the Machine Learning Technical Field Community and loves working with customers on their ML and AI journey. Prem is passionate about robotics, is an Autonomous Vehicles researcher, and also built the Alexa-controlled Beer Pours in Houston and other locations.
Prem Ranga is an Enterprise Solutions Architect based out of Houston, Texas. He is part of the Machine Learning Technical Field Community and loves working with customers on their ML and AI journey. Prem is passionate about robotics, is an Autonomous Vehicles researcher, and also built the Alexa-controlled Beer Pours in Houston and other locations. Chethan Krishna is a Senior Partner Solutions Architect in India. He works with Strategic AWS Partners for establishing a robust cloud competency, adopting AWS best practices and solving customer challenges. He is a builder and enjoys experimenting with AI/ML, IoT and Analytics.
Chethan Krishna is a Senior Partner Solutions Architect in India. He works with Strategic AWS Partners for establishing a robust cloud competency, adopting AWS best practices and solving customer challenges. He is a builder and enjoys experimenting with AI/ML, IoT and Analytics. Mona Mona is an AI/ML Specialist Solutions Architect based out of Arlington, VA. She helps customers adopt machine learning on a large scale. She is passionate about NLP and ML Explainability areas in AI/ML.
Mona Mona is an AI/ML Specialist Solutions Architect based out of Arlington, VA. She helps customers adopt machine learning on a large scale. She is passionate about NLP and ML Explainability areas in AI/ML.