New track of the 10th Dialog System Technology Challenge (DSTC10) will target noisy speech environments.Read More
August Arrivals: GFN Thursday Brings 34 Games to GeForce NOW This Month
It’s a new month for GFN Thursday, which means a new month full of games on GeForce NOW.
August brings a wealth of great new PC game launches to the cloud gaming service, including King’s Bounty II, Humankind and NARAKA: BLADEPOINT.
In total, 13 titles are available to stream this week. They’re just a portion of the 34 new games coming to the service this month.
Members will also get to stream upcoming content updates for popular free-to-play titles like Apex Legends and Tom Clancy’s Rainbow Six Siege as soon as they release.
Fit for a King
It’s time to save a kingdom. Members will be able to stream King’s Bounty II (Steam) when it releases for PC later this month on GeForce NOW.

Darkness has descended over the world of Nostria in this exciting RPG sequel. Gamers will be able to play as one of three heroes, rescuing and building a personal army in a journey of leadership, survival and sacrifice. Fight for the future and outsmart enemies in turn-based combat. Every action has profound and lasting consequences in the fight to bring peace and order to the land.
Be the kingdom’s last hope and live out an adventure August 24. Preorder on Steam to get some exclusive bonuses.
More Fun for Free This Month
This month also comes with new content for some of the most popular free-to-play titles streaming on GeForce NOW. Members can look forward to experiencing the latest in Apex Legends and Tom Clancy’s Rainbow Six Siege.

“Apex Legends: Emergence,” the latest season of the wildly popular free-to-play game from Respawn and EA, launched on August 3 and brought in a new Legend, weapon and Battle Pass as well as some awesome map updates.
The newest legend, Seer, is here and ready to spot opportunities that others may miss. Players can also enjoy a new midrange weapon, the Rampage LMG, a slower but more powerful variation of the Spitfire. To top it all off, the newest map updates reveal a familiar landscape torn at the seams. Decimated World’s Edge is available now on Apex Legends and streaming on GeForce NOW.
The latest event in Tom Clancy’s Rainbow Six Siege features a new time-limited gameplay mode, a challenge to unlock a free Nomad Hive Mind set, and more. Year 6 Season 2 kicked off with a special “Rainbow Six Siege: Containment” event that sets players in the Consulate map overrun by the Chimera parasite in a new game mode called Nest Destruction. Members will be able to stream the Containment event from August 3 to August 24.
Here This Week

Starting off the month, members can look for the following titles available to stream this GFN Thursday:
- A Plague Tale: Innocence (Free on Epic Games Store, August 5)
- Death Trash (day-and-date release on Steam, August 5)
- Starmancer (day-and-date release on Steam, August 5)
- CyberTaxi (Steam)
- Eldest Souls (Steam)
- Elex (Epic Games Store)
- The Flame in the Flood (Steam)
- GRIME (Steam)
- Hakuoki: Kyoto Winds (Steam)
- MetaMorph: Dungeon Creatures (Steam)
- Super Animal Royale (Steam)
- Tales of the Neon Sea (Steam)
- Zero Hour (Steam)
August’s Newest Additions

This month is packed with more games coming to GeForce NOW over the course of August, including nine new titles:
- Lawn Mowing Simulator (day-and-date release on Steam, August 10)
- NARAKA: BLADEPOINT (day-and-date release on Steam and Epic Games Store, August 12)
- Voidtrain (day-and-date release on Epic Games Store, August 12)
- Greak: Memories of Azur (day-and-date release on Steam, August 17)
- Humankind (day-and-date release on Steam and Epic Games Store, August 17)
- RiMS Racing (day-and-date release on Steam and Epic Games Store, August 19)
- King’s Bounty II (day-and-date release on Steam and Epic Games Store, August 24)
- Arid (Steam)
- Check vs Mate (Steam, North America) / Battle vs Chess (Steam, Europe)
- Before We Leave (Epic Games Store)
- Blood of Steel (Steam)
- Deepest Chamber (Steam and Epic Games Store)
- Hard Truck Apocalypse / Ex Machina (Steam)
- Hello Neighbor (Steam)
- Hello Neighbor: Hide and Seek (Steam)
- Ironclad Tactics (Steam)
- Old World (Epic Games Store)
- Shadow Man Remastered (Steam)
- The Architect Paris (Epic Games Store)
- TIS-100 (Steam)
- Wargame: European Escalation (Steam)
More from July

On top of the 36 games that were announced and released in July, an extra 24 titles joined the GeForce NOW library over the month:
- Alan Wake (Epic Games Store)
- Alan Wake’s American Nightmare (Epic Games Store)
- Call to Arms – Gates of Hell: Ostfront (Steam)
- Crowfall (Native Launcher)
- Death’s Door (Steam)
- Edge of Eternity (Epic Games Store)
- Escape from Naraka (Steam)
- Ironcast (Epic Games Store)
- Lost at Sea (Steam)
- Lumberjack’s Dynasty (Epic Games Store)
- Moonlighter (Epic Games Store)
- Obduction (Epic Games Store)
- Pathfinder: Kingmaker – Enhanced Plus Edition (Epic Games Store)
- Rayman: Raving Rabbids (Steam and Ubisoft Connect)
- Siege Survival: Gloria Victis (Epic Games Store)
- Space Colony: Steam Edition (Steam)
- The Immortal Mayor (Steam)
- Vesper (Steam)
- Warframe (Digital Extremes)
- Wildermyth (Steam)
- World of Warplanes (Steam)
- Wushu Chronicles (Steam)
- X3: Albion Prelude (Steam)
- X3: Farnham’s Legacy (Steam)
Finally, here’s a special question from our friends on the GeForce NOW Twitter feed:
𝙒𝙖𝙣𝙩𝙚𝙙: 𝘼 𝙨𝙩𝙧𝙖𝙩𝙚𝙜𝙞𝙘 𝙘𝙝𝙖𝙡𝙡𝙚𝙣𝙜𝙚.
Drop your favorite strategy games below.
—
NVIDIA GeForce NOW (@NVIDIAGFN) August 4, 2021

The post August Arrivals: GFN Thursday Brings 34 Games to GeForce NOW This Month appeared first on The Official NVIDIA Blog.
Reimagine knowledge discovery using Amazon Kendra’s Web Crawler
When you deploy intelligent search in your organization, two important factors to consider are access to the latest and most comprehensive information, and a contextual discovery mechanism. Many companies are still struggling to make their internal documents searchable in a way that allows employees to get relevant information knowledge in a scalable, cost-effective manner. A 2018 International Data Corporation (IDC) study found that data professionals are losing 50% of their time every week—30% searching for, governing, and preparing data, plus 20% duplicating work. Amazon Kendra is purpose-built for addressing these challenges. Amazon Kendra is an intelligent search service that uses deep learning and reading comprehension to deliver more accurate search results.
The intelligent search capabilities of Amazon Kendra improve the search and discovery experience, but enterprises are still faced with the challenge of connecting troves of unstructured data and making that data accessible to search. Content is often unstructured and scattered across intranets and Wikis, making critical information hard to find and costing employees time and effort to track down the right answer.
Enterprises spend a lot of time and effort building complex extract, transform, and load (ETL) jobs that aggregate data sources. Amazon Kendra connectors allow you to quickly aggregate content as part of a single unified searchable index, without needing to copy or move data from an existing location to a new one. This reduces the time and effort typically associated with creating a new search solution.
With the recently launched Amazon Kendra web crawler, it’s now easier than ever to discover information stored within the vast amount of content spread across different websites and internal web portals. You can use the Amazon Kendra web crawler to quickly ingest and search content from your websites.
Sample use case
A common need is to reduce the complexity of searching across multiple data sources present in an organization. Most organizations have multiple departments, each having their own knowledge management and search systems. For example, the HR department may maintain a WordPress-based blog containing news and employee benefits-related articles, a Confluence site could contain internal knowledge bases maintained by engineering, sales may have sales plays stored on a custom content management system (CMS), and corporate office information could be stored in a Microsoft SharePoint Online site.
You can index all these types of webpages for search by using the Amazon web crawler. Specific connectors are also available to index documents directly from individual content data sources.
In this post, you learn how to ingest documents from a WordPress site using its sitemap with the Amazon Kendra web crawler.
Ingest documents with Amazon Kendra web crawler
For this post, we set up a WordPress site with information about AWS AI language services. In order to be able to search the contents of my website, we create a web crawler data source.
- On the Amazon Kendra console, choose Data sources in the navigation pane.

- Under WebCrawler, choose Add connector.

- For Data source name, enter a name for the data source.
- Add an optional description.

- Choose Next.
The web crawler allows you to define a series of source URLs or source sitemaps. WordPress generates a sitemap, which I use for this post.
- For Source, select Source sitemaps.
- For Source sitemaps, enter the sitemap URL.

- Add a web proxy or authentication if your host requires that.
- Create a new AWS Identity and Access Management (IAM) role.
- Choose Next.

- For this post, I set up the web crawler to crawl one page per second, so I modify the Maximum throttling value to 60.
The maximum value that’s allowed is 300.

For this post, I remove a blog entry that contains 2021/06/28/this-post-is-to-be-skipped/ in the URL, and also all the contents that have the term /feed/ in the URL. Keep in mind that the excluded content won’t be ingested into your Amazon Kendra index, so your users won’t be able to search across these documents.
- In the Additional configuration section, add these patterns on the Exclude patterns

- For Sync run schedule, choose Run on demand.
- Choose Next.

- Review the settings and choose Create.
- When the data source creation process is complete, choose Sync now.

When the sync job is complete, I can search on my website.

Conclusion
In this post, you saw how to set up the Amazon Kendra web crawler and how easy is to ingest your websites into your Amazon Kendra index. If you’re just getting started with Amazon Kendra, you can build an index, ingest your website, and take advantage of intelligent search to provide better results to your users. To learn more about Amazon Kendra, refer to the Amazon Kendra Essentials workshop and deep dive into the Amazon Kendra blog.
About the Authors

Tapodipta Ghosh is a Senior Architect. He leads the Content And Knowledge Engineering Machine Learning team that focuses on building models related to AWS Technical Content. He also helps our customers with AI/ML strategy and implementation using our AI Language services like Amazon Kendra.
 Vijai Gandikota is a Senior Product Manager at Amazon Web Services for Amazon Kendra.
Vijai Gandikota is a Senior Product Manager at Amazon Web Services for Amazon Kendra.
 Juan Bustos is an AI Services Specialist Solutions Architect at Amazon Web Services, based in Dallas, TX. Outside of work, he loves spending time writing and playing music as well as trying random restaurants with his family.
Juan Bustos is an AI Services Specialist Solutions Architect at Amazon Web Services, based in Dallas, TX. Outside of work, he loves spending time writing and playing music as well as trying random restaurants with his family.
Two New Datasets for Conversational NLP: TimeDial and Disfl-QA
Posted by Aditya Gupta, Software Engineer and Shyam Upadhyay, Research Scientist, Google Assistant
A key challenge in natural language processing (NLP) is building conversational agents that can understand and reason about different language phenomena that are unique to realistic speech. For example, because people do not always premeditate exactly what they are going to say, a natural conversation often includes interruptions to speech, called disfluencies. Such disfluencies can be simple (like interjections, repetitions, restarts, or corrections), which simply break the continuity of a sentence, or more complex semantic disfluencies, in which the underlying meaning of a phrase changes. In addition, understanding a conversation also often requires knowledge of temporal relationships, like whether an event precedes or follows another. However, conversational agents built on today’s NLP models often struggle when confronted with temporal relationships or with disfluencies, and progress on improving their performance has been slow. This is due, in part, to a lack of datasets that involve such interesting conversational and speech phenomena.
To stir interest in this direction within the research community, we are excited to introduce TimeDial, for temporal commonsense reasoning in dialog, and Disfl-QA, which focuses on contextual disfluencies. TimeDial presents a new multiple choice span filling task targeted for temporal understanding, with an annotated test set of over ~1.1k dialogs. Disfl-QA is the first dataset containing contextual disfluencies in an information seeking setting, namely question answering over Wikipedia passages, with ~12k human annotated disfluent questions. These benchmark datasets are the first of their kind and show a significant gap between human performance and current state of the art NLP models.
TimeDial
While people can effortlessly reason about everyday temporal concepts, such as duration, frequency, or relative ordering of events in a dialog, such tasks can be challenging for conversational agents. For example, current NLP models often make a poor selection when tasked with filling in a blank (as shown below) that assumes a basic level of world knowledge for reasoning, or that requires understanding explicit and implicit inter-dependencies between temporal concepts across conversational turns.
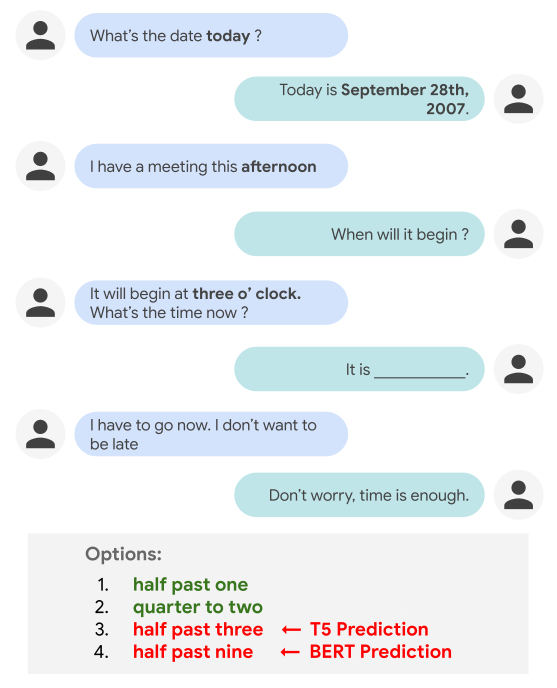
It is easy for a person to judge that “half past one” and “quarter to two” are more plausible options to fill in the blank than “half past three” and “half past nine”. However, performing such temporal reasoning in the context of a dialog is not trivial for NLP models, as it requires appealing to world knowledge (i.e., knowing that the participants are not yet late for the meeting) and understanding the temporal relationship between events (“half past one” is before “three o’clock”, while “half past three” is after it). Indeed, current state-of-the-art models like T5 and BERT end up picking the wrong answers — “half past three” (T5) and “half past nine” (BERT).
The TimeDial benchmark dataset (derived from the DailyDialog multi-turn dialog corpus) measures models’ temporal commonsense reasoning abilities within a dialog context. Each of the ~1.5k dialogs in the dataset is presented in a multiple choice setup, in which one temporal span is masked out and the model is asked to find all correct answers from a list of four options to fill in the blank.
In our experiments we found that while people can easily answer these multiple choice questions (at 97.8% accuracy), state-of-the-art pre-trained language models still struggle on this challenge set. We experiment across three different modeling paradigms: (i) classification over the provided 4 options using BERT, (ii) mask filling for the masked span in the dialog using BERT-MLM, (iii) generative methods using T5. We observe that all the models struggle on this challenge set, with the best variant only scoring 73%.
| Model | 2-best Accuracy | |
| Human | 97.8% | |
| BERT – Classification | 50.0% | |
| BERT – Mask Filling | 68.5% | |
| T5 – Generation | 73.0% |
Qualitative error analyses show that the pre-trained language models often rely on shallow, spurious features (particularly text matching), instead of truly doing reasoning over the context. It is likely that building NLP models capable of performing the kind of temporal commonsense reasoning needed for TimeDial requires rethinking how temporal objects are represented within general text representations.
Disfl-QA
As disfluency is inherently a speech phenomenon, it is most commonly found in text output from speech recognition systems. Understanding such disfluent text is key to building conversational agents that understand human speech. Unfortunately, research in the NLP and speech community has been impeded by the lack of curated datasets containing such disfluencies, and the datasets that are available, like Switchboard, are limited in scale and complexity. As a result, it’s difficult to stress test NLP models in the presence of disfluencies.
| Disfluency | Example | |
| Interjection | “When is, uh, Easter this year?” | |
| Repetition | “When is Eas … Easter this year?” | |
| Correction | “When is Lent, I mean Easter, this year?” | |
| Restart | “How much, no wait, when is Easter this year?” |
| Different kinds of disfluencies. The reparandum (words intended to be corrected or ignored; in red), interregnum (optional discourse cues; in grey) and repair (the corrected words; in blue). |
Disfl-QA is the first dataset containing contextual disfluencies in an information seeking setting, namely question answering over Wikipedia passages from SQuAD. Disfl-QA is a targeted dataset for disfluencies, in which all questions (~12k) contain disfluencies, making for a much larger disfluent test set than prior datasets. Over 90% of the disfluencies in Disfl-QA are corrections or restarts, making it a much more difficult test set for disfluency correction. In addition, compared to earlier disfluency datasets, it contains a wider variety of semantic distractors, i.e., distractors that carry semantic meaning as opposed to simpler speech disfluencies.
| Passage: …The Normans (Norman: Nourmands; French: Normands; Latin: Normanni) were the people who in the 10th and 11th centuries gave their name to Normandy, a region in France. They were descended from Norse (“Norman” comes from “Norseman”) raiders and pirates from Denmark, Iceland and Norway who, under their leader Rollo, … |
| Q1: | In what country is Normandy located? | France ✓ | |
| DQ1: | In what country is Norse found no wait Normandy not Norse? | Denmark X | |
| Q2: | When were the Normans in Normandy? | 10th and 11th centuries ✓ | |
| DQ2: | From which countries no tell me when were the Normans in Normandy? | Denmark, Iceland and Norway X |
| A passage and questions (Qi) from SQuAD dataset, along with their disfluent versions (DQi), consisting of semantic distractors (like “Norse” and “from which countries”) and predictions from a T5 model. |
Here, the first question (Q1) is seeking an answer about the location of Normandy. In the disfluent version (DQ1) Norse is mentioned before the question is corrected. The presence of this correctional disfluency confuses the QA model, which tends to rely on shallow textual cues from the question for making predictions.
Disfl-QA also includes newer phenomena, such as coreference (expression referring to the same entity) between the reparandum and the repair.
| SQuAD | Disfl-QA | |
| Who does BSkyB have an operating license from? | Who removed [BSkyB’s] operating license, no scratch that, who do [they] have [their] operating license from? |
Experiments show that the performance of existing state-of-the-art language model–based question answering systems degrades significantly when tested on Disfl-QA and heuristic disfluencies (presented in the paper) in a zero-shot setting.
| Dataset | F1 | |
| SQuAD | 89.59 | |
| Heuristics | 65.27 (-24.32) | |
| Disfl-QA | 61.64 (-27.95) |
We show that data augmentation methods partially recover the loss in performance and also demonstrate the efficacy of using human-annotated training data for fine-tuning. We argue that researchers need large-scale disfluency datasets in order for NLP models to be robust to disfluencies.
Conclusion
Understanding language phenomena that are unique to human speech, like disfluencies and temporal reasoning, among others, is a key ingredient for enabling more natural human–machine communication in the near future. With TimeDial and Disfl-QA, we aim to fill a major research gap by providing these datasets as testbeds for NLP models, in order to evaluate their robustness to ubiquitous phenomena across different tasks. It is our hope that the broader NLP community will devise generalized few-shot or zero-shot approaches to effectively handle these phenomena, without requiring task-specific human-annotated training datasets, constructed specifically for these challenges.
Acknowledgments
The TimeDial work has been a team effort involving Lianhui Qi, Luheng He, Yenjin Choi, Manaal Faruqui and the authors. The Disfl-QA work has been a collaboration involving Jiacheng Xu, Diyi Yang, Manaal Faruqui.

Zero Waste with Taste: Startup Uses AI to Drive Sustainable Fashion
Sustainability isn’t just a choice for consumers to make. It’s an opportunity for companies to lead.
AI startup Heartdub seams together fashion and technology to let designers and creators display physical fabrics and garments virtually — and help clothing companies achieve zero-waste manufacturing.
The company’s software digitizes textiles and then simulates how clothes look on the human body. This virtual design verification lessens the amount of physical samples needed, reducing waste from excess fabric, and helps minimize unsold inventory.
Based in Beijing, Heartdub is a member of NVIDIA Inception, a program designed to nurture startups revolutionizing industries with advancements in AI and data sciences. NVIDIA Inception helps startups during critical stages of product development, prototyping and deployment by providing free benefits such as go-to-market support and access to technology expertise.
“As a member of NVIDIA Inception, Heartdub hopes to leverage the resources, support and platform provided by NVIDIA to accelerate the implementation and extension of design verification and virtual showrooms,” said Li Ruohao, chief technology officer at Heartdub.
Zipping Up a Solution to Fabric Waste
Sampling fabrics and other materials is a costly, involved process for brand owners. It can slow the distribution of fashion information throughout the supply chain. And finished products may not look or perform the way consumers want, or may arrive too late to meet the latest trends.
Heartdub offers its customers Heartdub Materials, a physics engine comprising a large set of laboratory-grade textiles data which replicates the physical properties of materials. Inside the application, digitized material behaves as it would in the real world by accounting for texture, weight and movement.
The engine can reduce R&D costs by half, marketing costs by 70 percent and lead times by 90 percent for fabric manufacturers and brand owners, according to Li.
By verifying designs at near zero cost, Heartdub Materials can produce digital, ready-to-wear garments based on clothing patterns. Designers are able to select the texture, pattern and design online, allowing fabric manufacturers to complete preorder presentations at no cost.
These pieces can be showcased and purchased directly through virtual demos and fashion shows hosted by Heartdub One, the company’s database of clothing and avatars.
With Heartdub One, consumers can see how clothes fit on their specific size and shape by building their own digital human based on their particular measurements.

Fashionably Early
Powered by NVIDIA HDR InfiniBand networking, the Heartdub Materials physics engine boasts a speed of 200 Gbps, improving data transmission efficiency nearly 100-fold.
Taking advantage of NVIDIA Quadro RTX 8000 GPUs and high-speed interconnect technology, Heartdub Materials can easily simulate complex virtual world environments and efficiently process complex ray-tracing and visual computing workloads.
This enables collaboration across the industry, making it possible to complete the process from fabric selection, ready-to-wear design and review to pattern making and production, all virtually.
“AI will revolutionize the fashion industry, and Heartdub Materials is just the beginning,” said Li. “NVIDIA solutions have solved the technical challenges in graphics, allowing us to continue to provide new experiences and create more application scenarios for the fashion industry and its customers.”
Apply to join NVIDIA Inception.
The post Zero Waste with Taste: Startup Uses AI to Drive Sustainable Fashion appeared first on The Official NVIDIA Blog.
Ensuring that new language-processing models don’t backslide
New approach corrects for cases when average improvements are accompanied by specific regressions.Read More
Enghouse EspialTV enables TV accessibility with Amazon Polly
This is a guest post by Mick McCluskey, the VP of Product Management at Enghouse EspialTV. Enghouse provides software solutions that power digital transformation for communications service operators. EspialTV is an Enghouse SaaS solution that transforms the delivery of TV services for these operators across Set Top Boxes (STBs), media players, and mobile devices.
A large audience of consumers use TV services, and several of these groups may have disabilities that make it more difficult for them to access these services. To ensure that TV services are accessible to the broadest possible audience, we need to consider accessibility as a key element of the user experience (UX) for the service. Additionally, because TV is viewed as a key service by governments, it’s often subject to regulatory requirements for accessibility, including talking interfaces for the visually impaired. In the US, the Twenty-First Century Communications and Video Accessibility Act (CVAA) mandates improved accessibility for visual interfaces for users with limited hearing and vision in the US. The CVAA ensures accessibility laws from the 1980s and 1990s are brought up to date with modern technologies, including new digital, broadband, and mobile innovations.
This post describes how Enghouse uses Amazon Polly to significantly improve accessibility for EspialTV through talking interactive menu guides for visually impaired users while meeting regulatory requirements.
Challenges
A key challenge for visually impaired users is navigating TV menus to find the content they want to view. Most TV menus are designed for a 10-foot viewing experience, meaning that a consumer sitting 10 feet from the screen can easily see the menu items. For the visually impaired, these menu items aren’t easy to see and are therefore hard to navigate. To improve our UX for subscribers with limited vision, we sought to develop a mechanism to provide audible descriptions of the menu, allowing easier navigation of key functions such as the following:
- Channel and program selection
- Channel and program information
- Setup configuration, closed-caption control and options, and video description control
- Configuration information
- Playback
Overview of the AWS talking menu solution
Hosted on AWS, EspialTV is offered to communications service providers in a software as a service (SaaS) model. It was important for Enghouse to have a solution that not only supported the navigation currently offered at the time of launch, but was highly flexible to support changes and enhancements over time. This way, the voice assistance continuously evolved and improved to accommodate new capabilities as new services and features were added to the menu. For this reason, the solution had to be driven by real-time APIs calls as opposed to hardcoded text-to-speech menu configurations.
To ensure CVAA compliance and accelerate deployment, Enghouse chose to use Amazon Polly to implement this talking menu solution for the following reasons:
- We wanted a reliable and robust solution within minimal operational and management overhead
- It permitted faster time to market by using ready-made text-to-speech APIs
- The real-time API approach offered greater flexibility as we evolved the service over time
The following diagram illustrates the architecture of the talking menu solution.
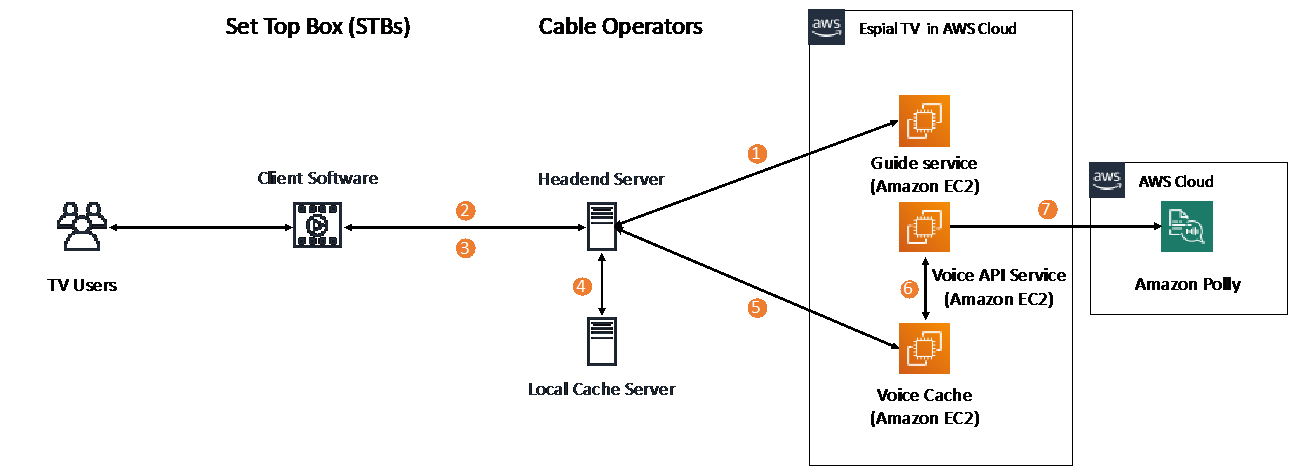
Using the Amazon Polly text-to-speech API allowed us to build a simple solution that integrated with our current infrastructure and followed this flow:
- Steps 1 and 2 – When TV users open the menu guide service, the client software running on the Set Top Box (STB) makes a call via the internet or Data Over Cable Service Interface Specification (DOCSIS) cable modem, which is routed through the cable operators headend server to the Espial Guide service running on the AWS Cloud.
- Step 3 – As TV users interact with the menu guide on the STBs, the client software running on the STBs sends the string containing the specific menu description highlighted by the customer.
- Step 4 – The cable operators headend server routes the request to a local cache to verify whether the requested string’s text-to-speech is cached locally. If it is, the corresponding text-to-speech is sent back to the STB to be read out loud to the TV user.
- Step 5 – Each unique cable operator has a local cache. If the requested string isn’t cached locally in the cable operator’s environment, the requested string is sent to the EspialTV service in AWS, where it’s met by a secondary caching server to respond to the request. This secondary layer of caching hosted in the Espial environment ensures high availability and increases cache hit rates. For example, if the caching servers on the cable operator environment is unavailable, the cache request can be resolved by the secondary caching system hosted in the Espial environment.
- Steps 6 and 7 – If the requested string isn’t found in the caching server in the EspialTV service, it’s routed to the Amazon Polly API to be converted to text-to-speech, which is routed back to the cable operator headend server and then to the TV user’s STB to be read out loud to the user.
This architecture has several key considerations. Firstly, there are several layers of caching implemented to minimize latency for the end user. This also supports the spikey nature of this workload to ensure that only requests not found in the respective caches are made to Amazon Polly.
The ready-made text-to-speech APIs provided by Amazon Polly enables us able to implement the service with just one engineer. We also reduced the expected delivery time by 75% compared to our estimates for building an in-house custom solution. The Amazon Polly documentation was very clear, and the ramp-up time was limited. Since implementation, this solution is reliably supporting 40 cable operators, which each have between 1,000–100,000 STBs.
Conclusion
EspialTV offers operators a TV solution that provides fast time to revenue, low startup costs, and scalability from small to very large operators. EspialTV offers providers and consumers a compelling and always relevant experience for their TV services. With Amazon Polly, we have ensured operators can offer a TV service to the broadest possible range of consumers and align with regulatory requirements for accessibility. To learn more about Amazon Polly, visit the product page.
The content and opinions in this post are those of the third-party author and AWS is not responsible for the content or accuracy of this post.
About the Author
 Mick McCluskey is VP of Product Management at Enghouse, a leading provider of software solutions helping operators use digital transformation to drive profitability in fast-changing and emerging markets. In the area of video solutions, Mick has been pivotal in creating the EspialTV solution—a truly disruptive TVaaS solution run on the AWS Cloud that permits pay TV operators to manage transition while maintaining profitability in a rapidly changing market. He is currently working on solutions that help operators take advantage of key technology and industry trends like OTT video, IoT, and 5G. In addition to delivering cloud-based solutions, he continues his journey of learning how to play golf.
Mick McCluskey is VP of Product Management at Enghouse, a leading provider of software solutions helping operators use digital transformation to drive profitability in fast-changing and emerging markets. In the area of video solutions, Mick has been pivotal in creating the EspialTV solution—a truly disruptive TVaaS solution run on the AWS Cloud that permits pay TV operators to manage transition while maintaining profitability in a rapidly changing market. He is currently working on solutions that help operators take advantage of key technology and industry trends like OTT video, IoT, and 5G. In addition to delivering cloud-based solutions, he continues his journey of learning how to play golf.
Soar into the Hybrid-Cloud: Project Monterey Early Access Program Now Available to Enterprises
Modern workloads such as AI and machine learning are putting tremendous pressure on traditional IT infrastructure.
Enterprises that want to stay ahead of these changes can now register to participate in an early access of Project Monterey, an initiative to dramatically improve the performance, manageability and security of their environments.
VMware, Dell Technologies and NVIDIA are collaborating on this project to evolve the architecture for the data center, cloud and edge to one that is software-defined and hardware-accelerated to address the changing application requirements.
AI and other compute-intensive workloads require real-time data streaming analysis, which, along with growing security threats, puts a heavy load on server CPUs. The increased load significantly increases the percentage of processing power required to run tasks that aren’t an integral part of application workloads. This reduces data center efficiency and can prevent IT from meeting its service-level agreements.
Project Monterey is leading the shift to advanced hybrid-cloud data center architectures, which benefit from hypervisor and accelerated software-defined networking, security and storage.
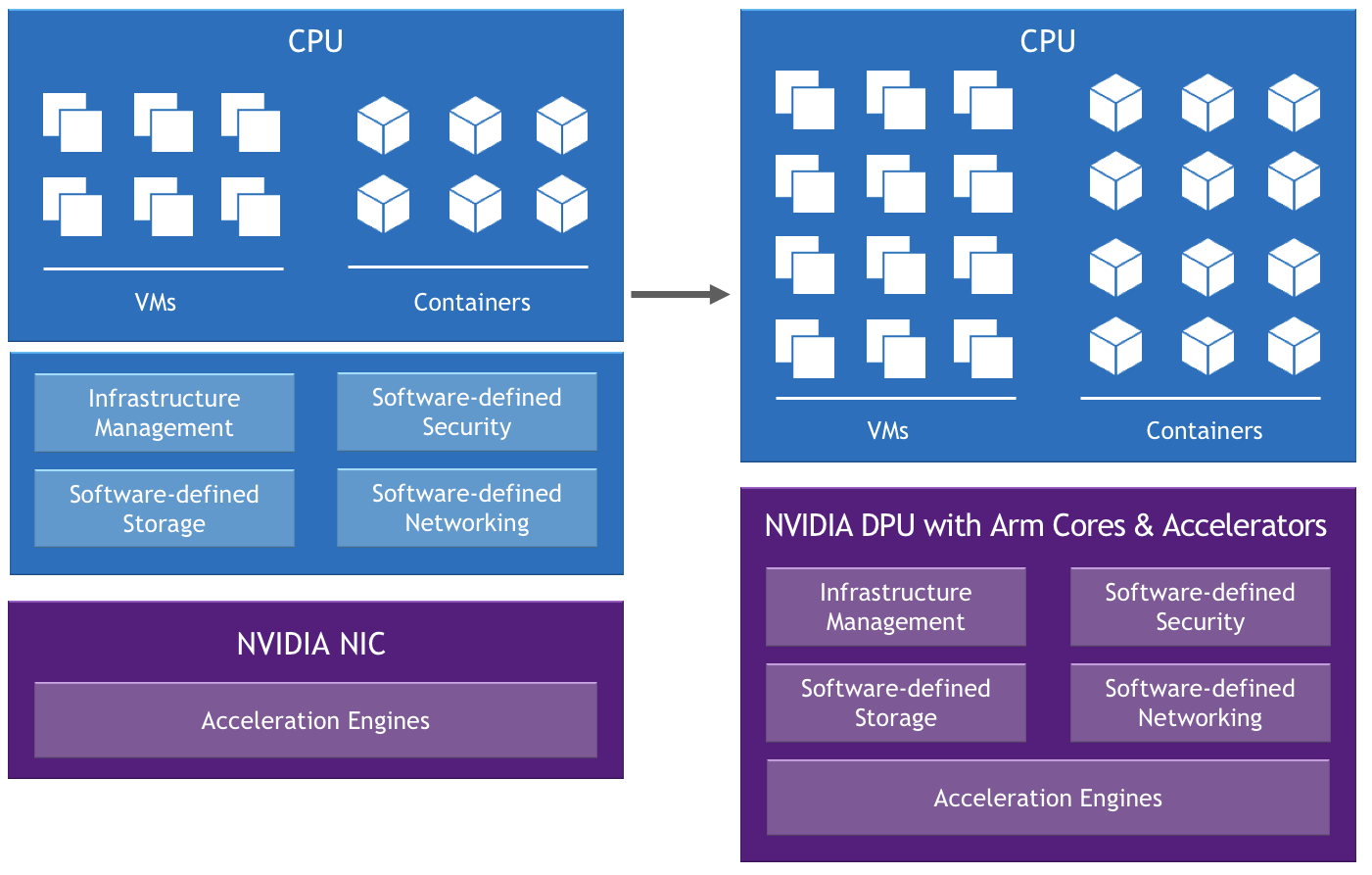
With access to Project Monterey’s preconfigured clusters, enterprises can explore the evolution of VMware Cloud Foundation and take advantage of the disruptive hardware capabilities of the Dell EMC PowerEdge R750 server equipped with NVIDIA BlueField-2 DPU (data processing unit).
Selected functions that used to run on the core CPU are offloaded, isolated and accelerated on the DPU to support new possibilities, including:
- Improved performance for application and infrastructure services
- Enhanced visibility, application security and observability
- Offloaded firewall capabilities
- Improved data center efficiency and cost for enterprise, edge and cloud.
Interested organizations can register for the NVIDIA Project Monterey early access program. Learn more about NVIDIA and VMware’s collaboration to modernize the data center.
The post Soar into the Hybrid-Cloud: Project Monterey Early Access Program Now Available to Enterprises appeared first on The Official NVIDIA Blog.
Upgrade your Amazon Polly voices to neural with one line of code
In 2019, Amazon Polly launched neural text-to-speech (NTTS) voices in US English and UK English. Neural voices use machine learning and provide a richer, more lifelike speech quality. Since the initial launch of NTTS, Amazon Polly has extended its neural offering by adding new voices in US Spanish, Brazilian Portuguese, Australian English, Canadian French, German and Korean. Some of them also are available in a Newscaster speaking style tailored to the specific needs of publishers.
If you’ve been using the standard voices in Amazon Polly, upgrading to neural voices is easy. No matter which programming language you use, the upgrade process only requires a simple addition or modification of the Engine parameter wherever you use the SynthesizeSpeech and StartSynthesizeSpeechTask method in your code. In this post, you’ll learn about the benefits of neural voices and how to migrate your voices to NTTS.
Benefits of neural vs. standard
Because neural voices provide a more expressive, natural-sounding quality than standard, migrating to neural improves the user experience and boosts engagement.
“We rely on speech synthesis to drive dynamic narrations for our educational content,” says Paul S. Ziegler, Chief Executive Officer at Reflare. “The switch from Amazon Polly’s standard to neural voices has allowed us to create narrations that are so good as to consistently be indistinguishable from human speech to non-native speakers and to occasionally even fool native speakers.”
The following is an example of Joanna’s standard voice.
The following is an example of the same words, but using Joanna’s neural voice.
“Switching to neural voices is as easy as switching to other non-neural voices,” Ziegler says. “Since our systems were already set up to automatically generate voiceovers on the fly, implementing the changes took less than 5 minutes.”
Quick migration checklist
Not all SSML tags, Regions, and languages support neural voices. Before making the switch, use this checklist to verify that NTTS is available for your specific business needs:
- Regional support – Verify that you’re making requests in Regions that support NTTS
- Language and voice support – Verify that you’re making requests to voices and languages that support NTTS by checking the current list of voices and languages
- SSML tag support – Verify that the SSML tags in your requests are supported by NTTS by checking SSML tag compatibility
Additional considerations
The following table summarizes additional considerations before you switch to NTTS.
| Standard | Neural | |
| Cost | $4 per million characters | $16 per million characters |
| Free Tier | 5 million characters per month | 1 million characters per month |
| Default Sample Rate | 22 kHz | 24 kHz |
| Usage Quota | Quotas in Amazon Polly | |
Code samples
If you’re already using Amazon Polly standard, the following samples demonstrate how to switch to neural for all SDKs. The required change is highlighted in bold.
Go:
input := &polly.SynthesizeSpeechInput{
OutputFormat: aws.String("mp3"),
Text: aws.String(“Hello World!”),
VoiceId: aws.String("Joanna"),
Engine: “neural”}Java:
SynthesizeSpeechRequest synthReq = SynthesizeSpeechRequest.builder()
.text('Hello World!')
.voiceId('Joanna')
.outputFormat('mp3')
.engine('neural')
.build();
ResponseInputStream<SynthesizeSpeechResponse> synthRes = polly.synthesizeSpeech(synthReq);Javascript:
polly.synthesizeSpeech({
Text: “Hello World!”,
OutputFormat: "mp3",
VoiceId: "Joanna",
TextType: "text",
Engine: “neural”});.NET:
var response = client.SynthesizeSpeech(new SynthesizeSpeechRequest
{
Text = "Hello World!",
OutputFormat = "mp3",
VoiceId = "Joanna"
Engine = “neural”
});PHP:
$result = $client->synthesizeSpeech([
'Text' => ‘Hello world!’,
'OutputFormat' => ‘mp3,
'VoiceId' => ‘Joanna’,
'Engine' => ‘neural’]);Python:
polly.synthesize_speech(
Text="Hello world!",
OutputFormat="mp3",
VoiceId="Joanna",
Engine=”neural”)Ruby:
resp = polly.synthesize_speech({
text: “Hello World!”,
output_format: "mp3",
voice_id: "Joanna",
engine: “neural”
})Conclusion
You can start playing with neural voices immediately on the Amazon Polly console. If you have any questions or concerns, please post it to the AWS Forum for Amazon Polly, or contact your AWS Support team.
About the Author
 Marta Smolarek is a Senior Program Manager in the Amazon Text-to-Speech team. Outside of work, she loves to go camping with her family
Marta Smolarek is a Senior Program Manager in the Amazon Text-to-Speech team. Outside of work, she loves to go camping with her family