Amazon Research Award recipient Russ Tedrake is teaching robots to manipulate a wide variety of objects in unfamiliar and constantly changing contexts.Read More

Microsoft has demonstrated the underlying physics required to create a new kind of qubit
Quantum computing promises to help us solve some of humanity’s greatest challenges. Yet as an industry, we are still in the early days of discovering what’s possible. Today’s quantum computers are enabling researchers to do interesting work. However, these researchers often find themselves limited by the inadequate scale of these systems and are eager to do more. Today’s quantum computers are based on a variety of qubit types, but none so far have been able to scale to enough qubits to fully realize the promise of quantum.
Microsoft is taking a more challenging, but ultimately more promising approach to scaled quantum computing with topological qubits that are theorized to be inherently more stable than qubits produced with existing methods without sacrificing size or speed. We have discovered that we can produce the topological superconducting phase and its concomitant Majorana zero modes, clearing a significant hurdle toward building a scaled quantum machine. The explanation of our work and methods below shows that the underlying physics behind a topological qubit are sound—the observation of a 30 μeV topological gap is a first in this work, and one that lays groundwork for the potential future of topological quantum computing. While engineering challenges remain, this discovery proves out a fundamental building block for our approach to a scaled quantum computer and puts Microsoft on the path to deliver a quantum machine in Azure that will help solve some of the world’s toughest problems.
Dr. Chetan Nayak and Dr. Sankar Das Sarma recently sat down to discuss these results and why they matter in the video below. Learn more about our journey and visit Azure Quantum to get started with quantum computing today.
Microsoft Quantum team reports observation of a 30 μeV topological gap in indium arsenide-aluminum heterostructures
Topological quantum computation is a route to hardware-level fault tolerance, potentially enabling a quantum computing system with high fidelity qubits, fast gate operations, and a single module architecture. The fidelity, speed, and size of a topological qubit is controlled by a characteristic energy called the topological gap. This path is only open if one can reliably produce a topological phase of matter and experimentally verify that the sub-components of a qubit are in a topological phase (and ready for quantum information processing). Doing so is not trivial because topological phases are characterized by the long-ranged entanglement of their ground states, which is not readily accessible to conventional experimental probes.
This difficulty was addressed by the “topological gap protocol” (TGP), which our team set forth a year ago as a criterion for identifying the topological phase with quantum transport measurements. Topological superconducting wires have Majorana zero modes at their ends. There is a real fermionic operator localized at each end of the wire, analogous to the real fermionic wave equation constructed by Ettore Majorana in 1937.
Consequently, there are two quantum states of opposite fermion parity that can only be measured through a phase-coherent probe coupled to both ends. In electrical measurements, the Majorana zero modes (see Figure 1) cause zero-bias peaks (ZBPs) in the local conductance. However, local Andreev bound states and disorder can also cause zero-bias peaks. Thus, the TGP focuses on ZBPs that are highly stable and, crucially, uses the non-local conductance to detect a bulk phase transition. Such a transition must be present at the boundary between the trivial superconducting phase and the topological phase because these are two distinct phases of matter, as different as water and ice.
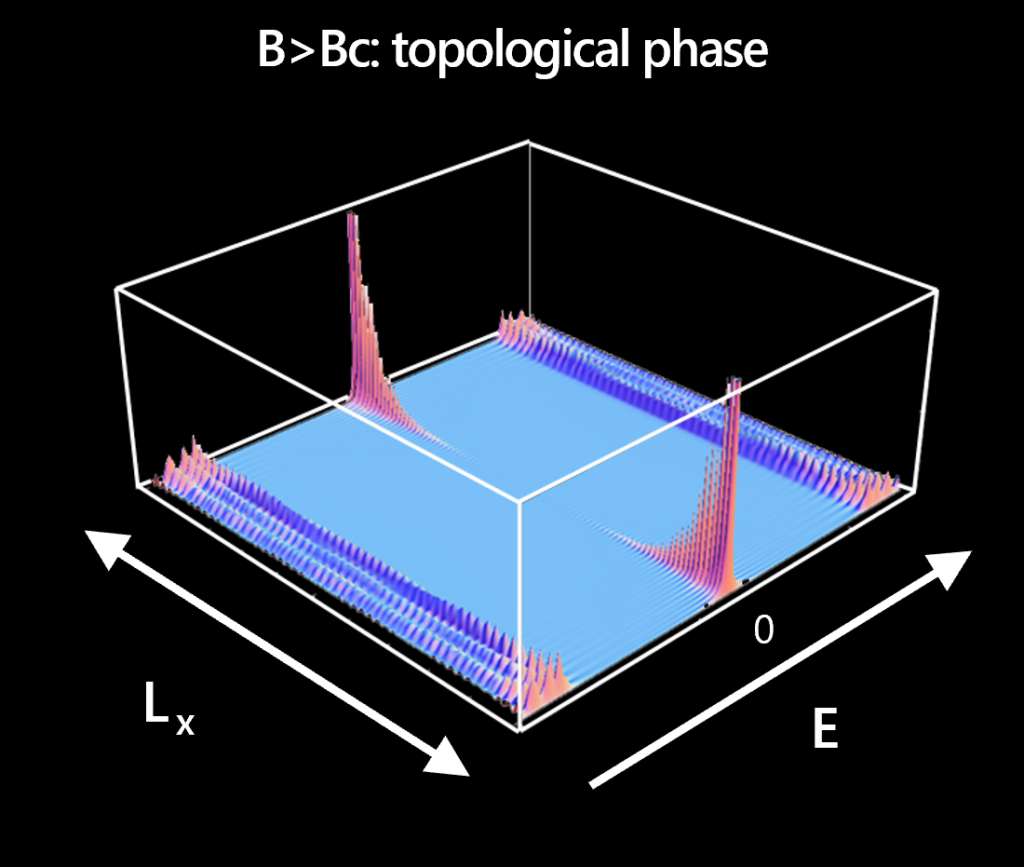
We have simulated our devices using models that incorporate the details of the materials stack, geometry, and imperfections. Our simulations have demonstrated that the TGP is a very stringent criterion, rendering it a reliable method for detecting the topological phase in a device. Crucially, the conditions for passing the protocol—the presence of stable ZBPs at both ends of the device over a gapped region with gapless boundary, as established via the non-local conductance—were established before any devices had been measured. Given the subtleties involved in identifying a topological phase, which stem from the absence of a local order parameter, one of the design principles of the TGP was to avoid confirmation bias. In particular, the device is scanned over its entire operating range instead of ‘hunting’ for a specific desired feature, such as a ZBP.
Microsoft’s Station Q, in Santa Barbara, CA, is the birthplace of Microsoft’s quantum program. For the last 16 years, it has been the host of a biannual conference on topological phases and quantum computing. After a two-year hiatus of in-person meetings due to the pandemic, the Station Q meetings resumed in early March. At this meeting with leaders in quantum computing from across industry and academia, we reported that we have multiple devices that have passed the TGP.
Our team has measured topological gaps exceeding 30 μeV. This is more than triple the noise level in the experiment and larger than the temperature by a similar factor. This shows that it is a robust feature. This is both a landmark scientific advance and a crucial step on the journey to topological quantum computation, which relies on the fusion and braiding of anyons (the two primitive operations on topological quasiparticles). The topological gap controls the fault-tolerance that the underlying state of matter affords to these operations. More complex devices enabling these operations require multiple topological wire segments and rely on TGP as part of their initialization procedure. Our success was predicated on very close collaboration between our simulation, growth, fabrication, measurement, and data analysis teams. Every device design was simulated in order to optimize it over 23 different parameters prior to fabrication. This enabled us to determine the device tuning procedure during design.
Our results are backed by exhaustive measurements and rigorous data validation procedures. We obtained the large-scale phase diagram of multiple devices, derived from a combination of local and non-local conductances. Our analysis procedure was validated on simulated data in which we attempted to fool the TGP. This enabled us to rule out various null hypotheses with high confidence. Moreover, data analysis was led by a different team than the one who took the data, as part of our checks and balances between different groups within the team. Additionally, an expert council of independent consultants is vetting our results, and the response to date is overwhelmingly positive.
With the underlying physics demonstrated, the next step is a topological qubit. We hypothesize that the topological qubit will have a favorable combination of speed, size, and stability compared to other qubits. We believe ultimately it will power a fully scalable quantum machine in the future, which will in turn enable us to realize the full promise of quantum to solve the most complex and pressing challenges our society faces.
The post Microsoft has demonstrated the underlying physics required to create a new kind of qubit appeared first on Microsoft Research.
Amazon Science celebrates Pi Day
Times Square display honors scientists, engineers, and mathematicians past, present, and future.Read More

PeopleLens: Using AI to support social interaction between children who are blind and their peers
For children born blind, social interaction can be particularly challenging. A child may have difficulty aiming their voice at the person they’re talking to and put their head on their desk instead. Linguistically advanced young people may struggle with maintaining a topic of conversation, talking only about something of interest to them. Most noticeably, many children and young people who are blind struggle with engaging and befriending those in their age group despite a strong desire to do so. This is often deeply frustrating for the child or young person and can be equally so for their support network of family members and teachers who want to help them forge these important connections.
-
PUBLICATION
PeopleLens
The PeopleLens is an open-ended AI system that offers people who are blind or who have low vision further resources to make sense of and engage with their immediate social surroundings.
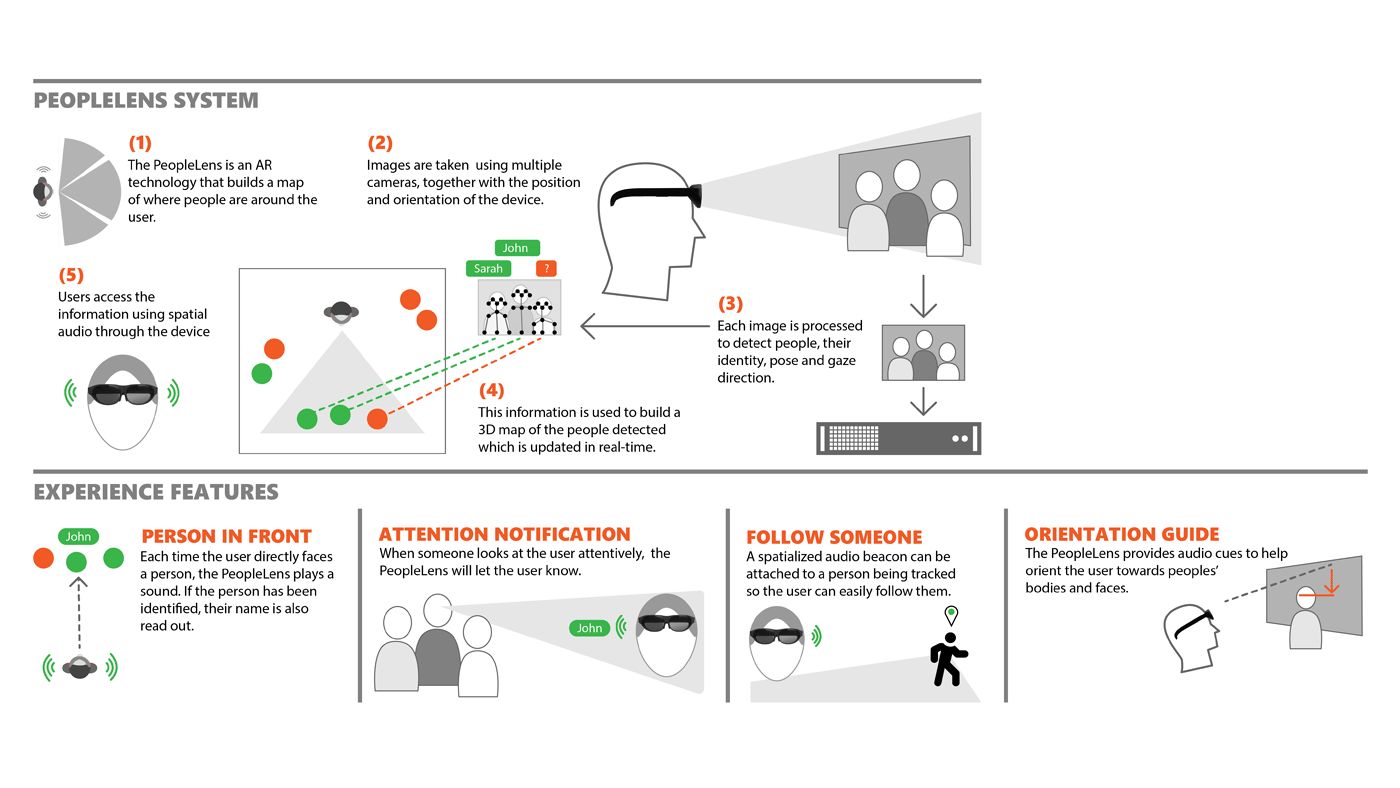
The PeopleLens is a new research technology that we’ve created to help young people who are blind (referred to as learners in our work) and their peers interact more easily. A head-worn device, the PeopleLens reads aloud in spatialized audio the names of known individuals when the learner looks at them. That means the sound comes from the direction of the person, assisting the learner in understanding both the relative position and distance of their peers. The PeopleLens helps learners build a People Map, a mental map of those around them needed to effectively signal communicative intent. The technology, in turn, indicates to the learner’s peers when the peers have been “seen” and can interact—a replacement for the eye contact that usually initiates interaction between people.
For children and young people who are blind, the PeopleLens is a way to find their friends; however, for teachers and parents, it’s a way for these children and young people to develop competence and confidence in social interaction. An accompanying scheme of work aims to guide the development of spatial attention skills believed to underpin social interaction through a series of games that learners using the PeopleLens can play with peers. It also sets up situations in which learners can experience agency in social interaction. A child’s realization that they can choose to initiate a conversation because they spot someone first or that they can stop a talkative brother from speaking by looking away is a powerful moment, motivating them to delve deeper into directing their own and others’ attention.
The PeopleLens is an advanced research prototype that works on Nreal Light augmented reality glasses tethered to a phone. While it’s not available for purchase, we are recruiting learners in the United Kingdom aged 5 to 11 who have the support of a teacher to explore the technology as part of a multistage research study. For the study, led by the University of Bristol, learners will be asked to use the PeopleLens for a three-month period beginning in September 2022. For more information, visit the research study information page.
Research foundation
The scheme of work, coauthored by collaborators Professor Linda Pring and Dr. Vasiliki Kladouchou, draws on research and practice from psychology and speech and language therapy in providing activities to do with the technology. The PeopleLens builds on the hypothesis that many social interaction difficulties for children who are blind stem from differences in the ways children with and without vision acquire fundamental attentional processes as babies and young children. For example, growing up, children with vision learn to internalize a joint visual dialogue of attention. A young child points at something in the sky, and the parent says, “Bird.” Through these dialogues, young children learn how to direct the attention of others. However, there isn’t enough research to understand how joint attention manifests in children who are blind. A review of the literature suggests that most research doesn’t account for a missing sense and that research specific to visual impairment doesn’t provide a framework for joint attention beyond the age of 3. We’re carrying out research to better understand how the development of joint attention can be improved in early education and augmented with technology.
How does the PeopleLens work?
The PeopleLens is a sophisticated AI prototype system that is intended to provide people who are blind or have low vision with a better understanding of their immediate social environment. It uses a head-mounted augmented reality device in combination with four state-of-the-art computer vision algorithms to continuously locate, identify, track, and capture the gaze directions of people in the vicinity. It then presents this information to the wearer through spatialized audio—sound that comes from the direction of the person. The real-time nature of the system gives a sense of immersion in the People Map.
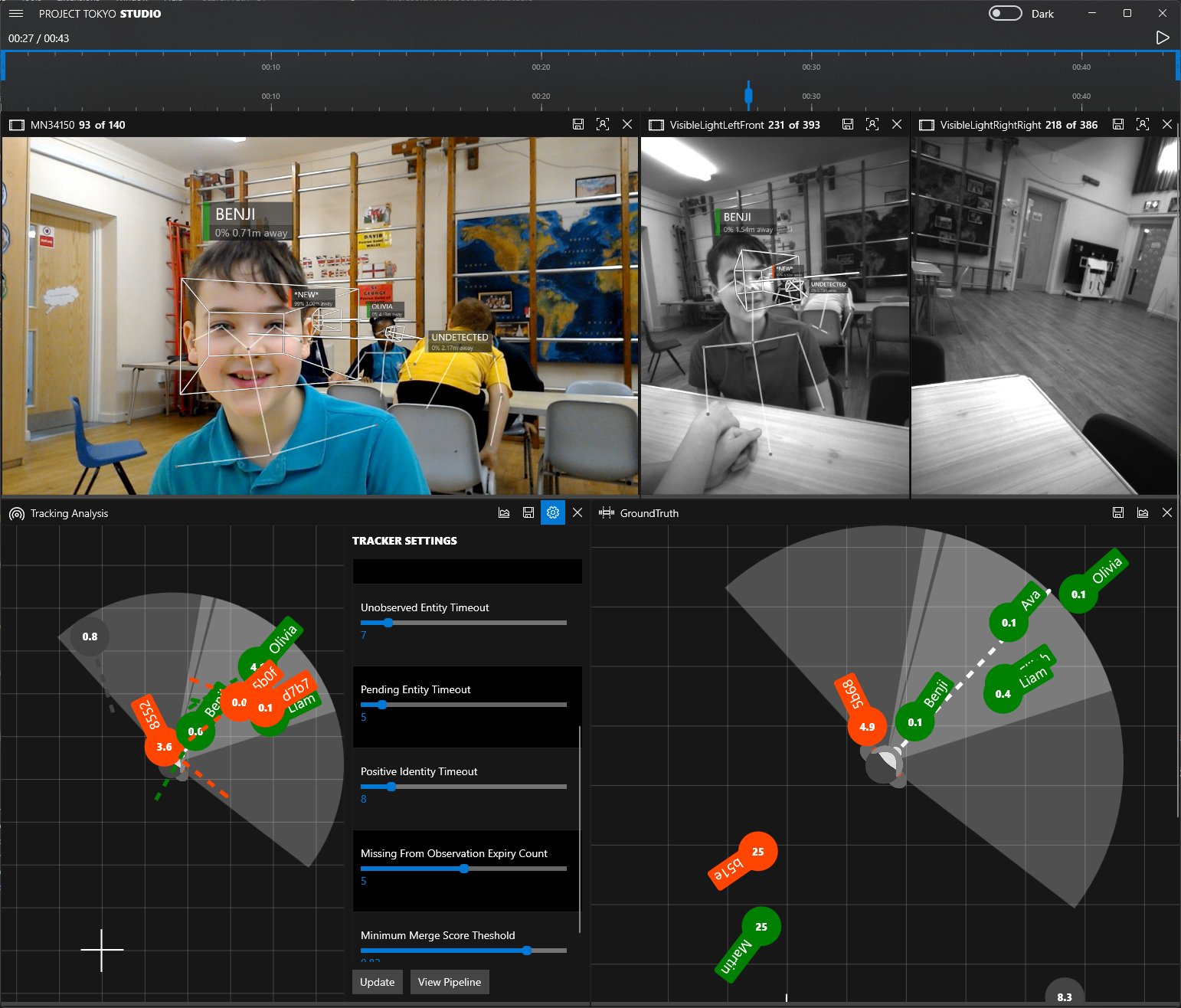
The PeopleLens is a ground-breaking technology that has also been designed to protect privacy. Among the algorithms underpinning the system is facial recognition of people who’ve been registered in the system. A person registers by taking several photographs of themselves with the phone attached to the PeopleLens. Photographs aren’t stored, instead converted into a vector of numbers that represent a face. These differ from any vectors used in other systems, so recognition by the PeopleLens doesn’t lead to recognition by any other system. No video or identifying information is captured by the system, ensuring that the images can’t be maliciously used.
The system employs a series of sounds to assist the wearer in placing people in the surrounding space: A percussive bump indicates when their gaze has crossed a person up to 10 meters away. The bump is followed by the person’s name if the person is registered in the system, is within 4 meters of the wearer, and both the person’s ears can be detected. The sound of woodblocks guides the wearer in finding and centering the face of a person the system has seen for 1 second but hasn’t identified, changing in pitch to help the wearer adjust their gaze accordingly. (Those people who are unregistered are acknowledged with a click sound.) Gaze notification can alert the wearer to when they’re being looked at.
Community collaboration
The success of the PeopleLens, as well as systems like it, is dependent on a prototyping process that includes close collaboration with the people it is intended to serve. Our work with children who are blind and their support systems has put us on a path toward building a tool that can have practical value and empower those using it. We encourage those interested in the PeopleLens to reach out about participating in our study and help us further evolve the technology.
To learn more about the PeopleLens and its development, check out the Innovation Stories blog about the technology.
The post PeopleLens: Using AI to support social interaction between children who are blind and their peers appeared first on Microsoft Research.
Synthetic Defect Generation for Display Front-of-Screen Quality Inspection: A Survey
Display front-of-screen (FOS) quality inspection is essential for the mass production of displays in the manufacturing process. However, the severe imbalanced data, especially the limited number of defective samples, has been a long-standing problem that hinders the successful application of deep learning algorithms. Synthetic defect data generation can help address this issue. This paper reviews the state-of-the-art synthetic data generation methods and the evaluation metrics that can potentially be applied to display FOS quality inspection tasks.Apple Machine Learning Research
Bringing practical applications of quantum computing closer
New phase estimation technique reduces qubit count, while learning framework enables characterization of noisy quantum systems.Read More
25 years of QIP
As the major quantum computing conference celebrates its anniversary, we ask the conference chair and the head of Amazon’s quantum computing program to take stock.Read More
Amazon and Virginia Tech launch AI and ML research initiative
Initiative will be led by the Virginia Tech College of Engineering and directed by Thomas L. Phillips Professor of Engineering Naren Ramakrishnan.Read More
Amazon and Energy Dept. team up to change how we recycle plastic
Amazon joins the US DOE’s Bio-Optimized Technologies to keep Thermoplastics out of Landfills and the Environment (BOTTLE™) Consortium, focusing on materials and recycling innovation.Read More
µTransfer: A technique for hyperparameter tuning of enormous neural networks
Great scientific achievements cannot be made by trial and error alone. Every launch in the space program is underpinned by centuries of fundamental research in aerodynamics, propulsion, and celestial bodies. In the same way, when it comes to building large-scale AI systems, fundamental research forms the theoretical insights that drastically reduce the amount of trial and error necessary and can prove very cost-effective.
In this post, we relay how our fundamental research enabled us, for the first time, to tune enormous neural networks that are too expensive to train more than once. We achieved this by showing that a particular parameterization preserves optimal hyperparameters across different model sizes. This is the µ-Parametrization (or µP, pronounced “myu-P”) that we introduced in a previous paper, where we showed that it uniquely enables maximal feature learning in the infinite-width limit. In collaboration with researchers at OpenAI, we verified its practical advantage on a range of realistic scenarios, which we describe in our new paper, “Tensor Programs V: Tuning Large Neural Networks via Zero-Shot Hyperparameter Transfer.”
By greatly reducing the need to guess which training hyperparameters to use, this technique can accelerate research on enormous neural networks, such as GPT-3 and potentially larger successors in the future. We also released a PyTorch package that facilitates the integration of our technique in existing models, available on the project GitHub page or by simply running (texttt{pip install mup}).
“µP provides an impressive step toward removing some of the black magic from scaling up neural networks. It also provides a theoretically backed explanation of some tricks used by past work, like the T5 model. I believe both practitioners and researchers alike will find this work valuable.”
— Colin Raffel, Assistant Professor of Computer Science, University of North Carolina at Chapel Hill and co-creator of T5
Scaling the initialization is easy, but scaling training is hard
Large neural networks are hard to train partly because we don’t understand how their behavior changes as their size increases. Early work on deep learning, such as by Glorot & Bengio and He et al., generated useful heuristics that deep learning practitioners widely use today. In general, these heuristics try to keep the activation scales consistent at initialization. However, as training starts, this consistency breaks at different model widths, as illustrated on the left in Figure 1.
Unlike at random initialization, behavior during training is much harder to mathematically analyze. Our goal is to obtain a similar consistency so that as model width increases, the change in activation scales during training stay consistent and similar to initialization to avoid numerical overflow and underflow. Our solution, µP, achieves this goal, as seen on the right in Figure 1, which shows the stability of network activation scales for the first few steps of training across increasing model width.

Our parameterization, which maintains this consistency during training, follows two pieces of crucial insight. First, gradient updates behave differently from random weights when the width is large. This is because gradient updates are derived from data and contain correlations, whereas random initializations do not. Therefore, they need to be scaled differently. Second, parameters of different shapes also behave differently when the width is large. While we typically divide parameters into weights and biases, with the former being matrices and the latter vectors, some weights behave like vectors in the large-width setting. For example, the embedding matrix in a language model is of size vocabsize x width. While the width tends to infinity, vocabsize stays constant and finite. During matrix multiplication, the difference in behavior between summing along a finite dimension and an infinite one cannot be more different.
These insights, which we discuss in detail in a previous blog post, motivated us to develop µP. In fact, beyond just keeping the activation scale consistent throughout training, µP ensures that neural networks of different and sufficiently large widths behave similarly during training such that they converge to a desirable limit, which we call the feature learning limit.
A theory-guided approach to scaling width
Our theory of scaling enables a procedure to transfer training hyperparameters across model sizes. If, as discussed above, µP networks of different widths share similar training dynamics, they likely also share similar optimal hyperparameters. Consequently, we can simply apply the optimal hyperparameters of a small model directly onto a scaled-up version. We call this practical procedure µTransfer. If our hypothesis is correct, the training loss-hyperparameter curves for µP models of different widths would share a similar minimum.
Conversely, our reasoning suggests that no scaling rule of initialization and learning rate other than µP can achieve the same result. This is supported by the animation below. Here, we vary the parameterization by interpolating the initialization scaling and the learning rate scaling between PyTorch default and µP. As shown, µP is the only parameterization that preserves the optimal learning rate across width, achieves the best performance for the model with width 213 = 8192, and where wider models always do better for a given learning rate—that is, graphically, the curves don’t intersect.
Building on the theoretical foundation of Tensor Programs, µTransfer works automatically for advanced architectures, such as Transformer and ResNet. It can also simultaneously transfer a wide range of hyperparameters. Using Transformer as an example, we demonstrate in Figure 3 how the optima of key hyperparameters are stable across widths.

“I am excited about µP advancing our understanding of large models. µP’s principled way of parameterizing the model and selecting the learning rate make it easier for anybody to scale the training of deep neural networks. Such an elegant combination of beautiful theory and practical impact.”
— Johannes Gehrke, Technical Fellow, Lab Director of Research at Redmond, and CTO and Head of Machine Learning for the Intelligent Communications and Conversations Cloud (IC3)
Beyond width: Empirical scaling of model depth and more
Modern neural network scaling involves many more dimensions than just width. In our work, we also explore how µP can be applied to realistic training scenarios by combining it with simple heuristics for nonwidth dimensions. In Figure 4, we use the same transformer setup to show how the optimal learning rate remains stable within reasonable ranges of nonwidth dimensions. For hyperparameters other than learning rate, see Figure 19 in our paper.

Testing µTransfer
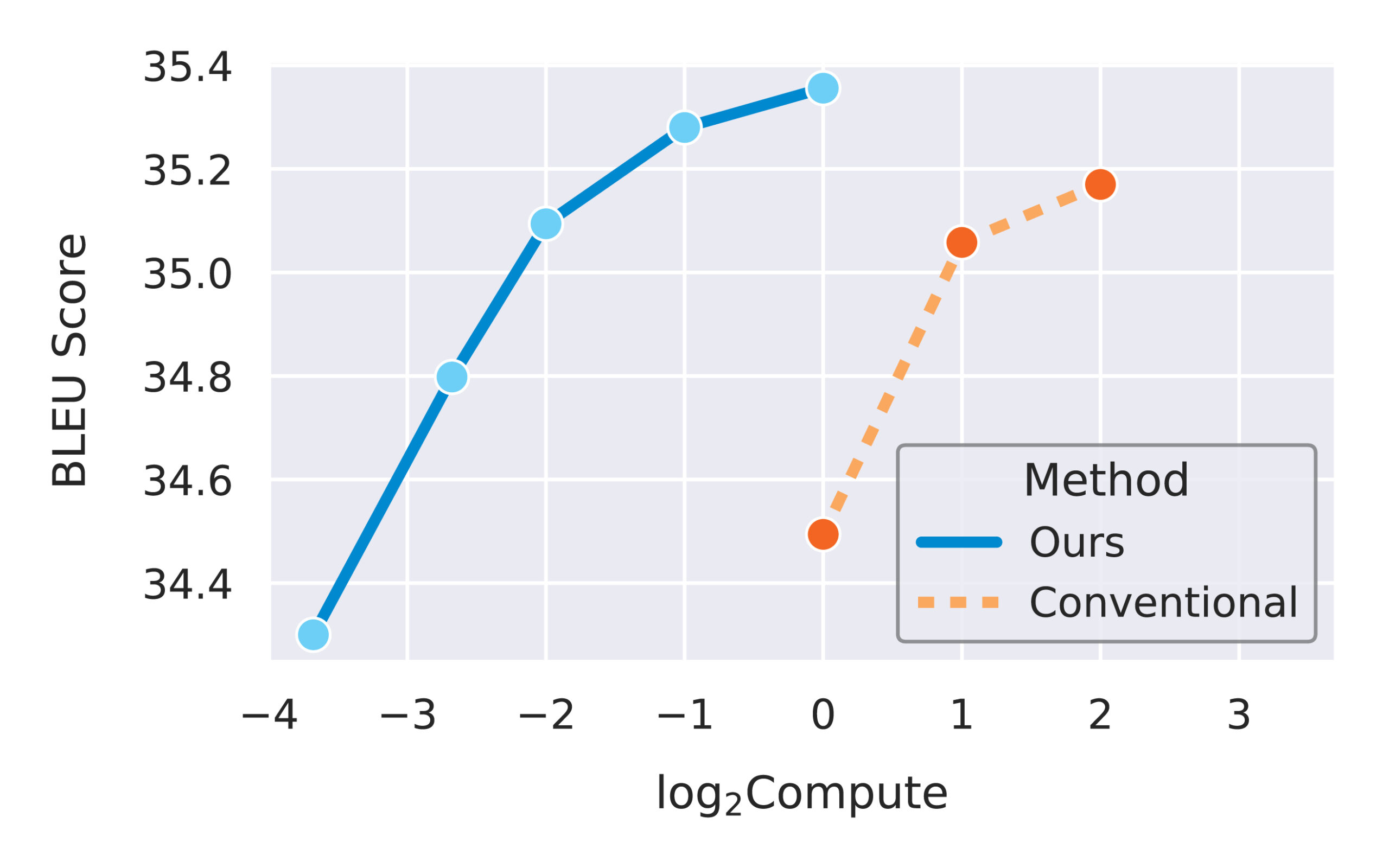
Now that we have verified the transfer of individual hyperparameters, it is time to combine them in a more realistic scenario. In Figure 5, we compare µTransfer, which transfers tuned hyperparameters from a small proxy model, with directly tuning the large target model. In both cases, the tuning is done via random search. Figure 5 illustrates a Pareto frontier of the relative tuning compute budget compared with the tuned model quality (BLEU score) on IWSLT14 De-En, a machine translation dataset. Across all compute budget levels, µTransfer is about an order of magnitude (in base 10) more compute-efficient for tuning. We expect this efficiency gap to dramatically grow as we move to larger target model sizes.
A glimpse of the future: µP + GPT-3
Before this work, the larger a model was, the less well-tuned we expected it to be due to the high cost of tuning. Therefore, we expected that the largest models could benefit the most from µTransfer, which is why we partnered with OpenAI to evaluate it on GPT-3.
After parameterizing a version of GPT-3 with relative attention in µP, we tuned a small proxy model with 40 million parameters before copying the best hyperparameter combination to the 6.7-billion parameter variant of GPT-3, as prescribed by µTransfer. The total compute used during this tuning stage was only 7 percent of the compute used in the pretraining of the final 6.7-billion model. This µTransferred model outperformed the model of the same size (with absolute attention) in the original GPT-3 paper. In fact, it performs similarly to the model (with absolute attention) with double the parameter count from the same paper, as shown in Figure 6.

Implications for deep learning theory
As shown previously, µP gives a scaling rule which uniquely preserves the optimal hyperparameter combination across models of different widths in terms of training loss. Conversely, other scaling rules, like the default in PyTorch or the NTK parameterization studied in the theoretical literature, are looking at regions in the hyperparameter space farther and farther from the optimum as the network gets wider. In that regard, we believe that the feature learning limit of µP, rather than the NTK limit, is the most natural limit to study if our goal is to derive insights that are applicable to feature learning neural networks used in practice. As a result, more advanced theories on overparameterized neural networks should reproduce the feature learning limit of µP in the large width setting.
Theory of Tensor Programs
The advances described above are made possible by the theory of Tensor Programs (TPs) developed over the last several years. Just as autograd helps practitioners compute the gradient of any general computation graph, TP theory enables researchers to compute the limit of any general computation graph when its matrix dimensions become large. Applied to the underlying graphs for neural network initialization, training, and inference, the TP technique yields fundamental theoretical results, such as the architectural universality of the Neural Network-Gaussian Process correspondence and the Dynamical Dichotomy theorem, in addition to deriving µP and the feature learning limit that led to µTransfer. Looking ahead, we believe extensions of TP theory to depth, batch size, and other scale dimensions hold the key to the reliable scaling of large models beyond width.
Applying µTransfer to your own models
Even though the math can be intuitive, we found that implementing µP (which enables µTransfer) from scratch can be error prone. This is similar to how autograd is tricky to implement from scratch even though the chain rule for taking derivatives is very straightforward. For this reason, we created the mup package to enable practitioners to easily implement µP in their own PyTorch models, just as how frameworks like PyTorch, TensorFlow, and JAX have enabled us to take autograd for granted. Please note that µTransfer works for models of any size, not just those with billions of parameters.
The journey has just begun
While our theory explains why models of different widths behave differently, more investigation is needed to build a theoretical understanding of the scaling of network depth and other scale dimensions. Many works have addressed the latter, such as the research on batch size by Shallue et al., Smith et al., and McCandlish et al., as well as research on neural language models in general by Rosenfield et al. and Kaplan et al. We believe µP can remove a confounding variable for such investigations. Furthermore, recent large-scale architectures often involve scale dimensions beyond those we have talked about in our work, such as the number of experts in a mixture-of-experts system. Another high-impact domain to which µP and µTransfer have not been applied is fine tuning a pretrained model. While feature learning is crucial in that domain, the need for regularization and the finite-width effect prove to be interesting challenges.
We firmly believe in fundamental research as a cost-effective complement to trial and error and plan to continue our work to derive more principled approaches to large-scale machine learning. To learn about our other deep learning projects or opportunities to work with us and even help us expand µP, please go to our Deep Learning Group page.
The post µTransfer: A technique for hyperparameter tuning of enormous neural networks appeared first on Microsoft Research.