Winning teams from the third annual Alexa Prize competition present their research in new video.Read More
Aravind Srinivasan: Amazon Scholar focuses on combinatorial optimization, algorithms, and AI
Srinivasan’s work cuts across multiple sectors, including cloud computing, machine learning, resource allocation, online algorithms, sustainable energy, and epidemiology.Read More
Data lake vs. data warehouse: Why AWS customers are transitioning to data lakes
Mehul Shah, GM for AWS Lake Formation and AWS Glue, explains what data lakes are, the challenges of data lakes, and how technology can help.Read More
Amazon Scholar John Preskill on the AWS quantum computing effort
The noted physicist answers 3 questions about the challenges of quantum computing and why he’s excited to be part of a technology development project.Read More
Machine learning tools increase power of hypothesis testing
Context vectors that capture “side information” can make experiments more informative.Read More
Learning to Summarize with Human Feedback
We’ve applied reinforcement learning from human feedback to train language models that are better at summarization. Our models generate summaries that are better than summaries from 10x larger models trained only with supervised learning. Even though we train our models on the Reddit TL;DR dataset, the same models transfer to generate good summaries of CNN/DailyMail news articles without any further fine-tuning. Our techniques are not specific to summarization; in the long run, our goal is to make aligning AI systems with human preferences a central component of AI research and deployment in many domains.
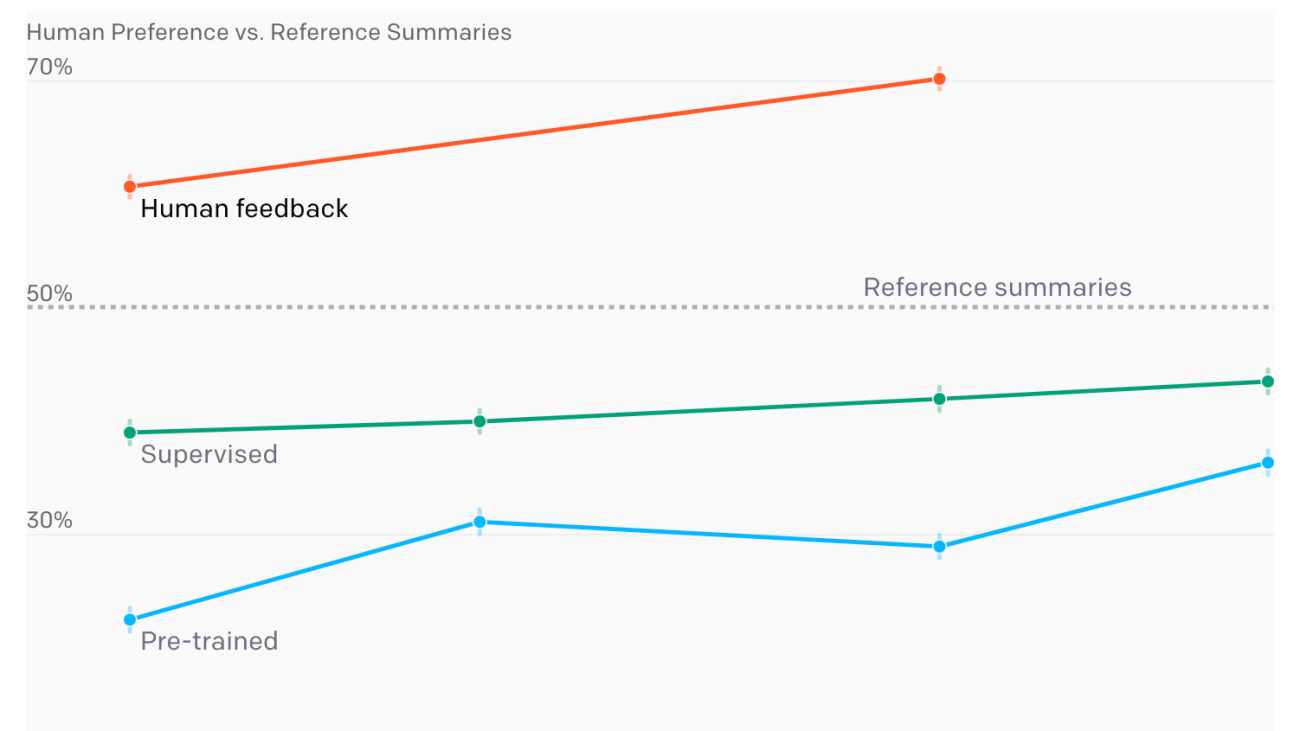
Human feedback models outperform much larger supervised models and reference summaries on TL;DR
Figure 1: The performance of various training procedures for different model sizes. Model performance is measured by how often summaries from that model are preferred to the human-written reference summaries. Our pre-trained models are early versions of GPT-3, our supervised baselines were fine-tuned to predict 117K human-written TL;DRs, and our human feedback models are additionally fine-tuned on a dataset of about 65K summary comparisons.

Large-scale language models are becoming increasingly capable on NLP tasks. These models are usually trained with the objective of next word prediction on a dataset of human-written text. But this objective doesn’t capture exactly what we want; usually, we don’t want our models to imitate humans, we want them to give high-quality answers. This mismatch is clear when a model is trained to imitate low-quality human-written text, but it can also happen in more subtle ways. For example, a model trained to predict what a human would say might make up facts when it is unsure, or generate sentences reflecting harmful social bias, both failure modes that have been well-documented.
As part of our work on safety, we want to develop techniques that align our models’ objectives with the end behavior we really care about. As our models become more powerful, we believe aligning them with our goals will be very important to ensure they are beneficial for humans. In the short term, we wanted to test if human feedback techniques could help our models improve performance on useful tasks.
We focused on English text summarization, as it’s a challenging problem where the notion of what makes a “good summary” is difficult to capture without human input. We apply our method primarily to an existing dataset of posts submitted to the social network Reddit[1] together with human-written “TL;DRs,” which are short summaries written by the original poster.
We first train a reward model via supervised learning to predict which summaries humans will prefer.[2] We then fine-tune a language model with reinforcement learning (RL) to produce summaries that score highly according to that reward model. We find that this significantly improves the quality of the summaries, as evaluated by humans, even on datasets very different from the one used for fine-tuning.
Our approach follows directly from our previous work on learning from human feedback. There has also been other work on using human feedback to train summarization models. We push the technique further by scaling to larger models, collecting more feedback data, closely monitoring researcher-labeler agreement, and providing frequent feedback to labelers. Human feedback has also been used to train models in several other domains, such as dialogue, semantic parsing, translation, story and review generation, evidence extraction, and more traditional RL tasks.
Results
Post from Reddit (r/)
show more
Human-written reference summary
Human feedback 6B model
Supervised 6B model
Pre-trained 6B model
We evaluated several different summarization models—some pre-trained on a broad distribution of text from the internet, some fine-tuned via supervised learning to predict TL;DRs, and some fine-tuned using human feedback.[3] To evaluate each model, we had it summarize posts from the validation set and asked humans to compare their summaries to the human-written TL;DR. The results are shown in Figure 1.
We found that RL fine-tuning with human feedback had a very large effect on quality compared to both supervised fine-tuning and scaling up model size. In particular, our 1.3 billion parameter (1.3B) model trained with human feedback outperforms our 12B model trained only with supervised learning. Summaries from both our 1.3B and 6.7B human feedback models are preferred by our labelers to the original human-written TL;DRs in the dataset.[4]
People make different trade-offs when writing summaries, including between conciseness and coverage of the original text; depending on the purpose of the summary, different summary lengths might be preferred. Our labelers tended to prefer longer summaries, so our models adapted to that preference and converged to the longest allowable length. Controlling for length reduced human preferences for our 6.7B model’s summaries from 70% to 65%, explaining a minority of our gains.[5]
Transfer results
Human feedback models trained on Reddit transfer to generate excellent summaries of CNN/DM news articles without further training
The performance (human-rated summary quality on a 1–7 scale) of various training procedures and model sizes.[6] Note that our human feedback models generate summaries that are significantly shorter than summaries from models trained on CNN/DM.
At a given summary length, our 6.7B human feedback model trained on Reddit performs almost as well as a fine-tuned 11B T5 model, despite not being re-trained on CNN/DM.
Article from CNN/DM ()
show more
Human-written reference summary
Human feedback 6B model (transfer)
Supervised 6B model (transfer)
Pre-trained 6B model
T5 11B model (fine-tuned on CNN/DM)
Supervised 6B model (fine-tuned on CNN/DM)
To test our models’ generalization, we also applied them directly to the popular CNN/DM news dataset. These articles are more than twice as long as Reddit posts and are written in a very different style. Our models have seen news articles during pre-training, but all of our human data and RL fine-tuning was on the Reddit TL;DR dataset.
This time we evaluated our models by asking our labelers to rate them on a scale from 1–7.[7] We discovered that our human feedback models transfer to generate excellent short summaries of news articles without any training. When controlling for summary length, our 6.7B human feedback model generates summaries that are rated higher than the CNN/DM reference summaries written by humans. This suggests that our human feedback models have learned something more general about how to summarize text, and are not specific to Reddit posts.
Approach

A diagram of our method, which is similar to the one used in our previous work.
Our core method consists of four steps: training an initial summarization model, assembling a dataset of human comparisons between summaries, training a reward model to predict the human-preferred summary, and then fine-tuning our summarization models with RL to get a high reward.
We trained several supervised baselines by starting from GPT-style transformer models trained on text from the Internet, and fine-tuning them to predict the human-written TL;DR via supervised learning. We mainly use models with 1.3 and 6.7 billion parameters. As a sanity check, we confirmed that this training procedure led to competitive results[8] on the CNN/DM dataset.
We then collected a dataset of human quality judgments. For each judgment, a human compares two summaries of a given post and picks the one they think is better.[9] We use this data to train a reward model that maps a (post, summary) pair to a reward r. The reward model is trained to predict which summary a human will prefer, using the rewards as logits.
Finally, we optimize the policy against the reward model using RL. We use PPO with 1 million episodes in total, where each episode consists of the policy summarizing a single article and then receiving a reward r. We include a KL penalty that incentivizes the policy to remain close to the supervised initialization.
Collecting data from humans
Any training procedure that uses human feedback is directly influenced by the actual humans labeling the data. In our previous work on fine-tuning language models from human preferences, our labelers often gave high ratings to summaries we thought were average, which was reflected in the quality of our trained models.
In response, in this project we invested heavily in ensuring high data quality. We hired about 80 contractors using third-party vendor sites,[10] and paid them an hourly wage regardless of the number of summaries evaluated.[11] Hiring contractors rather than relying on crowdsourcing websites allowed us to maintain a hands-on relationship with labelers: we created an onboarding process, developed a website with a customizable labeler interface, answered questions in a shared chat room, and had one-on-one video calls with labelers. We also made sure to clearly communicate our definition of summary quality, after spending significant time reading summaries ourselves, and we carefully monitored agreement rates between us and labelers throughout the project.
Optimizing the reward model
Optimizing our reward model eventually leads to sample quality degradation
Starting from the 1.3B supervised baseline (point 0 on the x-axis), we use RL to optimize the policy against the reward model, which results in policies with different “distances” from the baseline (x-axis, measured using the KL divergence from the supervised baseline). Optimizing against the reward model initially improves summaries according to humans, but eventually overfits, giving worse summaries. This graph uses an older version of our reward model, which is why the peak of the reward model is less than 0.5.
Post from Reddit (r/AskReddit)
I’m a 28yo man, and I would like to get into gymnastics for the first time.
Title said just about all of it. I’m 28, very athletic (bike/ surf/ snowboard) and I have always wanted to do gymnastics.
I like to do flips and spins off bridges and on my snowboard, and it seems to me gymnastics would be a great way to do those movements I like, in a controlled environment. The end goal of this is that it would be fun, and make me better at these movements in real life.
But is it too late for me? Should 28 year old guys such as myself be content with just watching those parkour guys on youtube? Or can I learn the ways of the gymnastic jedi? BTW, I live in San Jose CA.
KL = 0
I want to do gymnastics, but I’m 28 yrs old. Is it too late for me to be a gymnaste?!
KL = 9
28yo guy would like to get into gymnastics for the first time. Is it too late for me given I live in San Jose CA?
KL = 260
28yo dude stubbornly postponees start pursuing gymnastics hobby citing logistics reasons despite obvious interest??? negatively effecting long term fitness progress both personally and academically thoght wise? want change this dumbass shitty ass policy pls
Optimizing against our reward model is supposed to make our policy align with human preferences. But the reward model is only a proxy for human preferences, as it only sees a small amount of comparison data from a narrow distribution of summaries. While the reward model performs well on the kinds of summaries it was trained on, we wanted to know how much we could optimize against it until it started giving useless evaluations.
We trained policies at different “optimization strengths” against the reward model, and asked our labelers to evaluate the summaries from these models. We did this by varying the KL coefficient, which trades off the incentive to get a higher reward against the incentive to remain close to the initial supervised policy. We found the best samples had roughly the same predicted reward as the 99th percentile of reference summaries from the dataset. Eventually optimizing the reward model actually makes things worse.
Limitations
If we have a well-defined notion of the desired behavior for a model, our method of training from human feedback allows us to optimize for this behavior. However, this is not a method for determining what the desired model behavior should be. Deciding what makes a good summary is fairly straightforward, but doing this for tasks with more complex objectives, where different humans might disagree on the correct model behavior, will require significant care. In these cases, it is likely not appropriate to use researcher labels as the “gold standard”; rather, individuals from groups that will be impacted by the technology should be included in the process to define “good” behavior, and hired as labelers to reinforce this behavior in the model.
We trained on the Reddit TL;DR dataset because the summarization task is significantly more challenging than on CNN/DM. However, since the dataset consists of user-submitted posts with minimal moderation, they sometimes contain content that is offensive or reflects harmful social biases. This means our models can generate biased or offensive summaries, as they have been trained to summarize such content.
Part of our success involves scaling up our reward model and policy size. This requires a large amount of compute, which is not available to all researchers: notably, fine-tuning our 6.7B model with RL required about 320 GPU-days. However, since smaller models trained with human feedback can exceed the performance of much larger models, our procedure is more cost-effective than simply scaling up for training high-quality models on specific tasks.
Though we outperform the human-written reference summaries on TL;DR, our models have likely not reached human-level performance, as the reference summary baselines for TL;DR and CNN/DM are not the highest possible quality. When evaluating our model’s TL;DR summaries on a 7-point scale along several axes of quality (accuracy, coverage, coherence, and overall), labelers find our models can still generate inaccurate summaries, and give a perfect overall score 45% of the time.[12] For cost reasons, we also do not directly compare to using a similar budget to collect high-quality demonstrations, and training on those using standard supervised fine-tuning.
Future directions
We’re interested in scaling human feedback to tasks where humans can’t easily evaluate the quality of model outputs. For example, we might want our models to answer questions that would take humans a lot of research to verify; getting enough human evaluations to train our models this way would take a long time. One approach to tackle this problem is to give humans tools to help them evaluate more quickly and accurately. If these tools use ML, we can also improve them with human feedback, which could allow humans to accurately evaluate model outputs for increasingly complicated tasks.
In addition to tackling harder problems, we’re also exploring different types of feedback beyond binary comparisons: we can ask humans to provide demonstrations, edit model outputs to make them better, or give explanations as to why one model output is better than another. We’d like to figure out which kinds of feedback are most effective for training models that are aligned with human preferences.
If you are interested in working on these research questions, we’re hiring!
OpenAI
Amazon team adds key programming frameworks to Dive into Deep Learning book
With PyTorch and TensorFlow incorporated, the authors hope to gain a wider audience.Read More
Amazon helps fund NSF high-priority AI research initiative
Company supports research theme related to human-AI interaction and collaboration.Read More
Partnering with NSF on human-AI collaboration
Today, in partnership with the U.S. National Science Foundation (NSF), we are announcing a National AI Research Institute for Human-AI Interaction and Collaboration. Google will provide $5 million in funding to support the Institute. We will also offer AI expertise, research collaborations, and Cloud support for Institute researchers and educators as they advance knowledge and progress in the field of AI.
Studies have shown that humans and AI systems operating together can make smarter decisions than either acting alone. In the past few years we’ve seen the increasing use of AI to support people and their decision making in sectors like medicine, education, transportation and agriculture. Conversely, people also support AI systems and their decision making through training data and model design, testing and operation, and continued feedback and iteration on system performance. People and AI systems shape each other, and in order to realize the full potential of AI for social benefit, positive and productive human-AI interaction and collaboration is critical.
Google has been working in this area over the last several years, publishing hundreds of research papers in human-computer interaction and visualization; bringing industry and academic experts together at events like the PAIR Symposium and top research conferences; designing tools like Facets, the What-If Tool, and the Language Interpretability Tool to better understand datasets and models; creating the Model Card Toolkit for model transparency and a People + AI guidebookto support human-centered AI development; building better human-AI interfaces in our products like smart predictions in Gboard and auto-captioning with the Live Transcribe app; and enabling anyone to help make AI-powered products more useful through efforts like Crowdsource and Translate Community.
The Institute we are announcing with NSF will support interdisciplinary research on a variety of modes of interaction between people and AI—like speech, written language, visuals and gestures—and how to make these interactions more effective. Importantly, the research, tools and techniques from the Institute will be developed with human-centered principles in mind: social benefit, inclusive design, safety and robustness, privacy, and high standards of scientific excellence, consistent with the Google AI Principles. Research projects in the Institute will engage a diverse set of experts, educate the next generation and promote workforce development, and broaden participation from underrepresented groups and institutions across the country. All research outcomes will be published to advance knowledge and progress in the field.
U.S. universities and research institutions, individually and in collaboration, are welcome to apply. We are proud to partner with NSF in our ongoing efforts to promote innovation and technology leadership, and look forward to supporting many brilliant and creative ideas.
A big step for flood forecasts in India and Bangladesh
For several years, the Google Flood Forecasting Initiative has been working with governments to develop systems that predict when and where flooding will occur—and keep people safe and informed.
Much of this work is centered on India, where floods are a serious risk for hundreds of millions of people. Today, we’re providing an update on how we’re expanding and improving these efforts, as well as a new partnership we’ve formed with the International Federation of the Red Cross and Red Crescent Societies.
Expanding our forecasting reach
In recent months, we’ve been expanding our forecasting models and services in partnership with the Indian Central Water Commission. In June, just in time for the monsoon season, we reached an important milestone: our systems now extend to the whole of India, with Google technology being used to improve the targeting of every alert the government sends. This means we can help better protect more than 200 million people across more than 250,000 square kilometers—more than 20 times our coverage last year. To date, we’ve sent out around 30 million notifications to people in flood-affected areas.
In addition to expanding in India, we’ve partnered with the Bangladesh Water Development Board to bring our warnings and services to Bangladesh, which experiences more flooding than any other country in the world. We currently cover more than 40 million people in Bangladesh, and we’re working to extend this to the whole country.
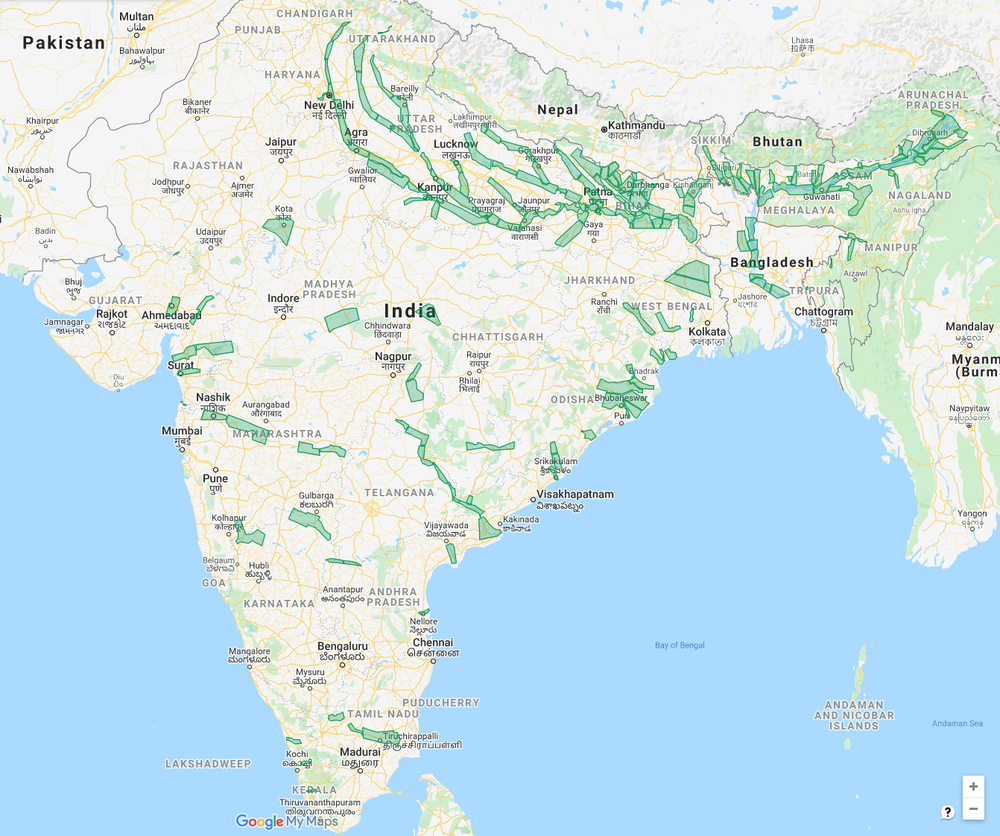
Coverage areas of our current operational flood forecasting systems. In these areas we use our models to help government alerts reach the right people. In some areas we have also increased lead time and spatial accuracy.
Better protection for vulnerable communities
In collaboration with Yale, we’ve been visiting flood-affected areas and doing research to better understand what information people need, how they use it to protect themselves, and what we can do to make that information more accessible. One survey we conducted found that 65 percent of people who receive flood warnings before the flooding begins take action to protect themselves or their assets (such as evacuating or moving their belongings). But we’ve also found there’s a lot more we could be doing to help—including getting alerts to people faster, and providing additional information about the severity of floods.

Checking how our flood warnings match conditions on the ground. This photo was taken during a field survey in Bihar during monsoon 2019.
This year, we’ve launched a new forecasting model that will allow us to double the lead time of many of our alerts—providing more notice to governments and giving tens of millions of people an extra day or so to prepare.
We’re providing people with information about flood depth: when and how much flood waters are likely to rise. And in areas where we can produce depth maps throughout the floodplain, we’re sharing information about depth in the user’s village or area.
We’ve also overhauled the way our alerts look and function to make sure they’re useful and accessible for everyone. We now provide the information in different formats, so that people can both read their alerts and see them presented visually; we’ve added support for Hindi, Bengali and seven other local languages; we’ve made the alert more localized and accurate; and we now allow for easy changes to language or location.
The technology behind some of these improvements is explained in more detail at the Google AI Blog.
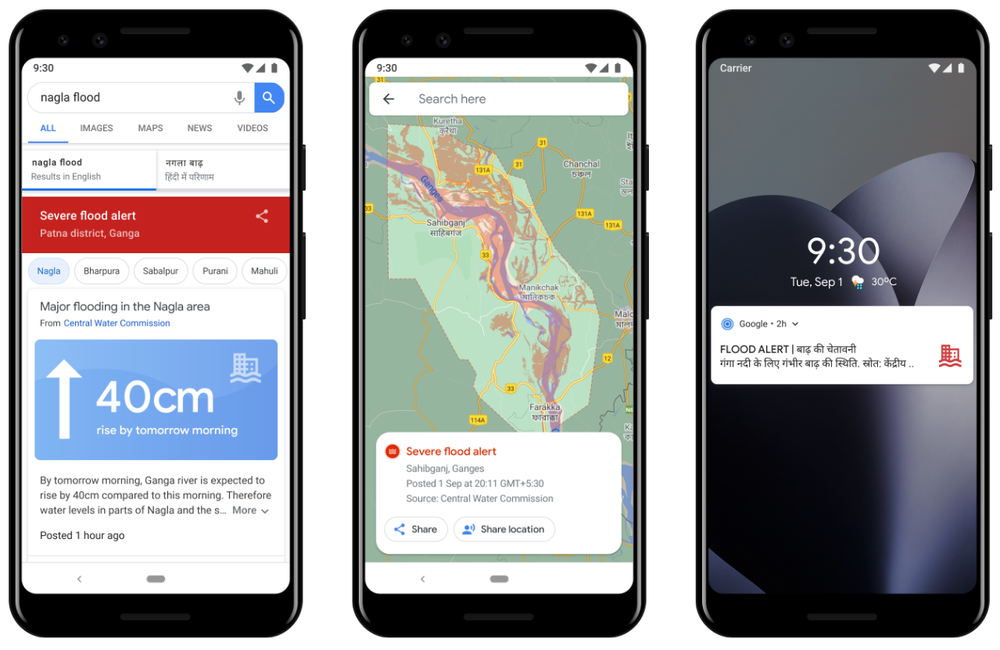
Alerts for flood forecasting
Partnering for greater impact
In addition to improving our alerts, Google.org has started a collaboration with the International Federation of Red Cross and Red Crescent Societies. This partnership aims to build local networks that can get disaster alert information to people who wouldn’t otherwise receive smartphone alerts directly.
Of course, for all the progress we’ve made with alert technology, there are still a lot of challenges to overcome. With the flood season still in full swing in India and Bangladesh, COVID-19 has delayed critical infrastructure work, added to the immense pressure on first responders and medical authorities, and disrupted the in-person networks that many people still rely on for advance notice when a flood is on the way.
There’s much more work ahead to strengthen the systems that so many vulnerable people rely on—and expand them to reach more people in flood-affected areas. Along with our partners around the world, we will continue developing, maintaining and improving technologies and digital tools to help protect communities and save lives.