Tools include optimizations for multicore, multiple-GPU, and distributed-training settings.Read More
“This technology will be transformative in ways we can barely comprehend”
A judge and some of the finalists from the Alexa Prize Grand Challenge 3 talk about the competition, the role of COVID-19, and the future of socialbots.Read More
Emory University team wins Alexa Prize Grand Challenge 3
Team awarded $500,000 prize for performance of its Emora socialbot.Read More
Automated reasoning lightning talks
Amazon automated reasoning scientists showcase verification methods being applied across Amazon during CAV 2020.Read More
How to teach Transformers to care about word order
New position encoding scheme improves state-of-the-art performance on several natural-language-processing tasks.Read More
EC’20: Calibrated forecasts, regret matching, dynamics and equilibria
Hebrew University of Jerusalem Professor Sergiu Hart discusses the research shared in two papers that were awarded the ACM SIGecom Test of Time and Doctoral Dissertation awards.Read More

Closing data gaps with Lacuna Fund
Machine learning has shown enormous promise for social good, whether in helping respond to global health pandemics or reach citizens before natural disasters hit. But even as machine learning technology becomes increasingly accessible, social innovators still face significant barriers in their efforts to use this technology to unlock new solutions. From languages to health and agriculture, there is a lack of relevant, labeled data to represent and address the challenges that face much of the world’s population.
To help close this gap, Google.org is making a $2.5 million grant alongside The Rockefeller Foundation, Canada’s International Development Resource Center (IDRC) and Germany’s GiZ FAIR Forward to launch Lacuna Fund, the world’s first collaborative nonprofit effort to directly address this missing data. The Fund aims to unlock the power of machine learning by providing data scientists, researchers, and social entrepreneurs in low- and middle-income communities around the world with resources to produce labeled datasets that address urgent problems.
Labeled data is a particular type of data that is useful in generating machine learning models: This data provides the “ground truth” that a model can use to guess about cases that it hasn’t yet seen. To create a labeled dataset, example data is systematically “tagged” by knowledgeable humans with one or more concepts or entities each one represents. For example, a researcher might label short videos of insects with their type; images of fungi with whether or not they are harmful to plants around them; or passages of Swahili text with the parts of speech that each word represents. In turn, these datasets could enable biologists to track insect migration; farmers to accurately identify threats to their crops; and Swahili speakers to use an automated text messaging service to get vital health information.
Guided by committees of domain and machine learning experts and facilitated by Meridian Institute, the Fund will provide resources and support to produce new labeled datasets, as well as augment or update existing ones to be more representative, relevant and sustainable. The Fund’s initial work will focus on agriculture and underrepresented languages, but we welcome additional collaborators and anticipate the fund will grow in the years to come. And our work is bigger than just individual datasets: Lacuna Fund will focus explicitly on growing the capacity of local organizations to be data collectors, curators and owners. While following best practices for responsible collection, publication and use, we endeavor to make all datasets as broadly available as possible.
Thanks in part to the rise of cloud computing, in particular services like Cloud AutoML and libraries like TensorFlow, AI is increasingly able to help address society’s most pressing issues. Yet we’ve seen firsthand in our work on the Google AI Impact Challenge the gap between the potential of AI and the ability to successfully implement it. The need for data is quickly becoming one of the most salient barriers to progress. It’s our hope that the Fund provides not only a way for social sector organizations to fund high-impact, immediately-applicable data collection and labeling, but also a foundation from which changemakers can build a better future.
Image at top: A team from AI Challenge Grantee Wadhwani Institute for Artificial Intelligence in India is working with local farmers to manage pest damage to crop.
Using AI to identify the aggressiveness of prostate cancer
Prostate cancer diagnoses are common, with 1 in 9 men developing prostate cancer in their lifetime. A cancer diagnosis relies on specialized doctors, called pathologists, looking at biological tissue samples under the microscope for signs of abnormality in the cells. The difficulty and subjectivity of pathology diagnoses led us to develop an artificial intelligence (AI) system that can identify the aggressiveness of prostate cancer.
Since many prostate tumors are non-aggressive, doctors first obtain small samples (biopsies) to better understand the tumor for the initial cancer diagnosis. If signs of tumor aggressiveness are found, radiation or invasive surgery to remove the whole prostate may be recommended. Because these treatments can have painful side effects, understanding tumor aggressiveness is important to avoid unnecessary treatment.
Grading the biopsies
One of the most crucial factors in this process is to “grade” any cancer in the sample for how abnormal it looks, through a process called Gleason grading. Gleason grading involves first matching each cancerous region to one of three Gleason patterns, followed by assigning an overall “grade group” based on the relative amounts of each Gleason pattern in the whole sample. Gleason grading is a challenging task that relies on subjective visual inspection and estimation, resulting in pathologists disagreeing on the right grade for a tumor as much as 50 percent of the time. To explore whether AI could assist in this grading, we previously developed an algorithm that Gleason grades large samples (i.e. surgically-removed prostates) with high accuracy, a step that confirms the original diagnosis and informs patient prognosis.
Our research
In our recent work, “Development and Validation of a Deep Learning Algorithm for Gleason Grading of Prostate Cancer from Biopsy Specimens”, published in JAMA Oncology, we explored whether an AI system could accurately Gleason grade smaller prostate samples (biopsies). Biopsies are done during the initial part of prostate cancer care to get the initial cancer diagnosis and determine patient treatment, and so are more commonly performed than surgeries. However, biopsies can be more difficult to grade than surgical samples due to the smaller amount of tissue and unintended changes to the sample from tissue extraction and preparation process. The AI system we developed first “grades” each region of biopsy, and then summarizes the region-level classifications into an overall biopsy-level score.
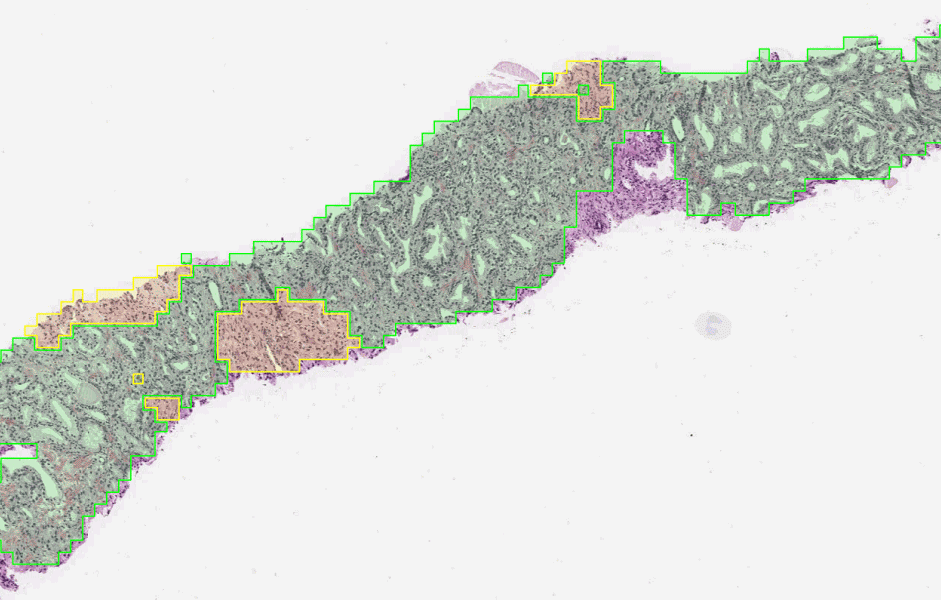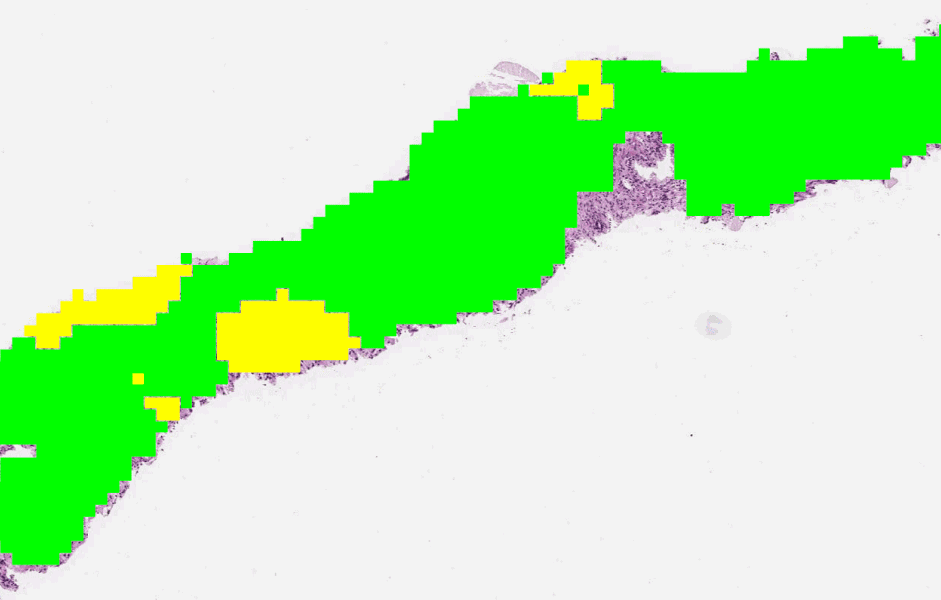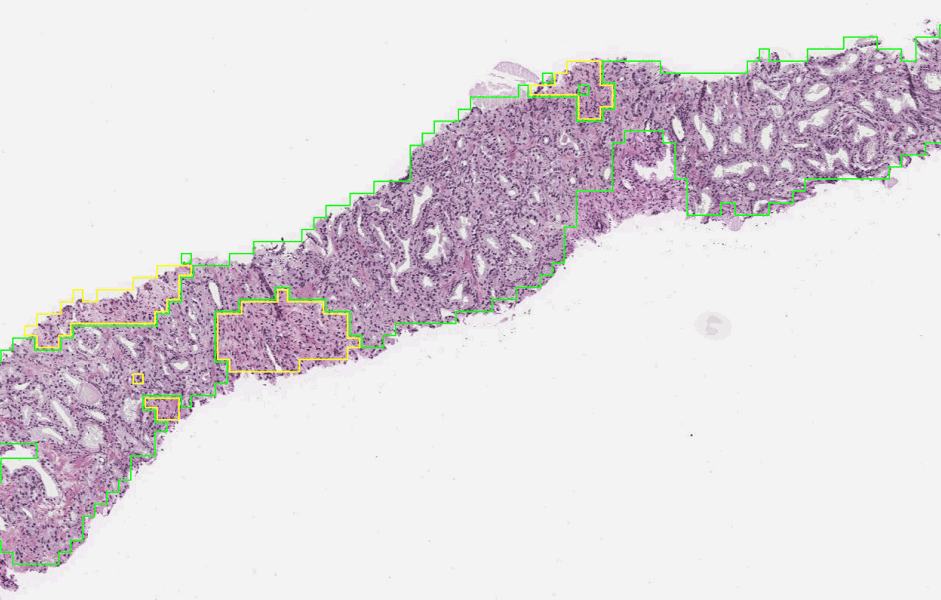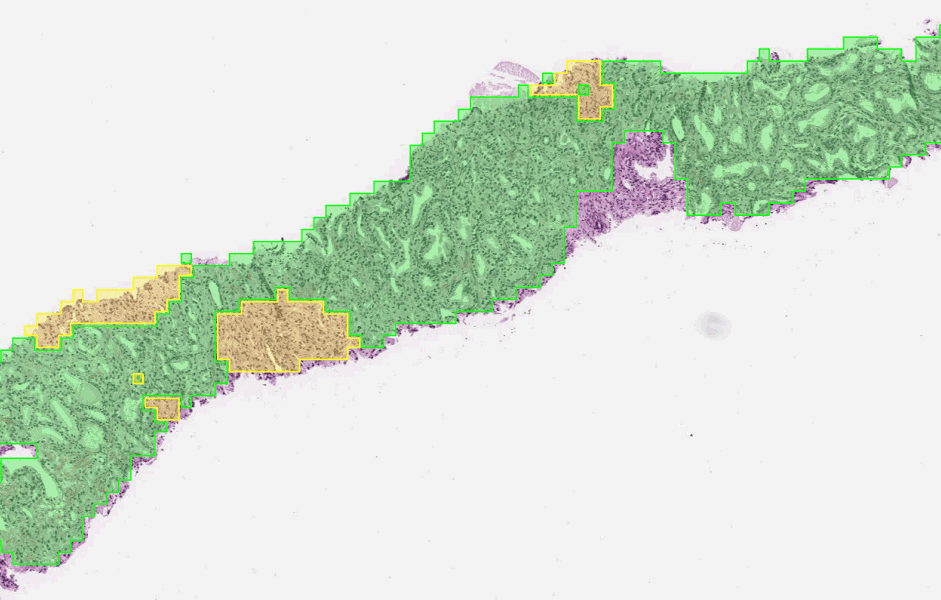
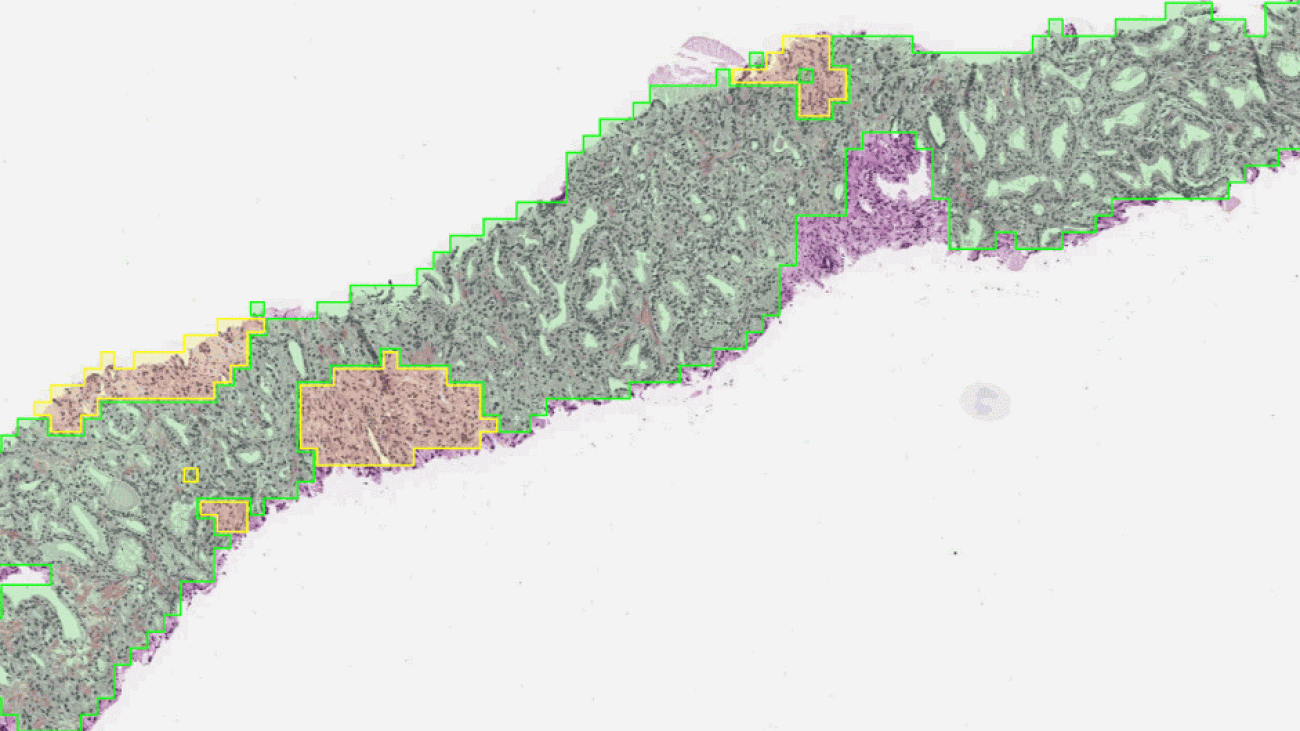
The first stage of the deep learning system Gleason grades every region in a biopsy. In this biopsy, green indicates Gleason pattern 3 while yellow indicates Gleason pattern 4.
Our results
Given the complexity of Gleason grading, we worked with six experienced expert pathologists to evaluate the AI system. These experts, who have specialized training in prostate cancer and an average of 25 years of experience, determined the Gleason grades of 498 tumor samples. Highlighting how difficult Gleason grading is, a cohort of 19 “general” pathologists (without specialist training in prostate cancer) achieved an average accuracy of 58 percent on these samples. By contrast, our AI system’s accuracy was substantially higher at 72 percent. Finally, some prostate cancers have ambiguous appearances, resulting in disagreements even amongst experts. Taking this uncertainty into account, the deep learning system’s agreement rate with experts was comparable to the agreement rate between the experts themselves.
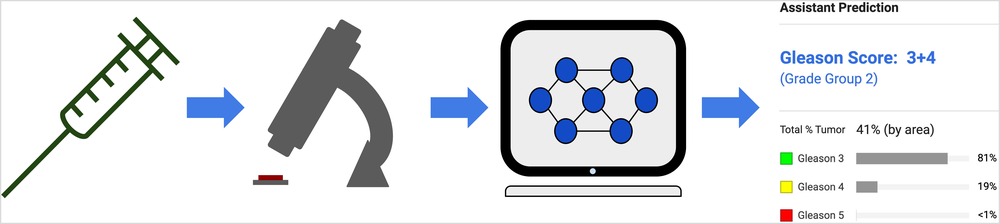
Potential cancer pathology workflow augmented with AI-based assistive tools: a tumor sample is first collected and digitized using a high-magnification scanner. Next, the AI system provides a grade group for each sample.
These promising results indicate that the deep learning system has the potential to support expert-level diagnoses and expand access to high-quality cancer care. To evaluate if it could improve the accuracy and consistency of prostate cancer diagnoses, this technology needs to be validated as an assistive tool in further clinical studies and on larger and more diverse patient groups. However, we believe that AI-based tools could help pathologists in their work, particularly in situations where specialist expertise is limited.
Our research advancements in both prostate and breast cancer were the result of collaborations with the Naval Medical Center San Diego and support from Verily. Our appreciation also goes to several institutions that provided access to de-identified data, and many pathologists who provided advice or reviewed prostate cancer samples. We look forward to future research and investigation into how our technology can be best validated, designed and used to improve patient care and cancer outcomes.