Seeger and three coauthors are honored for paper that forged durable links between previously separate domains.Read More
Adversarial training improves product discovery
Method automatically generates negative training examples for deep-learning model.Read More

Sand Safety: Startup’s Lifeguard AI Hits the Beach to Save Lives
A team in Israel is making a splash with AI.
It started as biz school buddies Netanel Eliav and Adam Bismut were looking to solve a problem to change the world. The problem found them: Bismut visited the Dead Sea after a drowning and noticed a lack of tech for lifeguards, who scanned the area with age-old binoculars.
The two aspiring entrepreneurs — recent MBA graduates of Ben-Gurion University, in the country’s south — decided this was their problem to solve with AI.
“I have two little girls, and as a father, I know the feeling that parents have when their children are near the water,” said Eliav, the company’s CEO.
They founded Sightbit in 2018 with BGU classmates Gadi Kovler and Minna Shezaf to help lifeguards see dangerous conditions and prevent drownings.
The startup is seed funded by Cactus Capital, the venture arm of their alma mater.
Sightbit is now in pilot testing at Palmachim Beach, a popular escape for sunbathers and surfers in the Palmachim Kibbutz area along the Mediterranean Sea, south of Tel Aviv. The sand dune-lined destination, with its inviting, warm aquamarine waters, gets packed with thousands of daily summer visitors.
But it’s also a place known for deadly rip currents.
Danger Detectors
Sightbit has developed image detection to help spot dangers to aid lifeguards in their work. In collaboration with the Israel Nature and Parks Authority, the Beersheba-based startup has installed three cameras that feed data into a single NVIDIA Jetson AGX at the lifeguard towers at Palmachim beach. NVIDIA Metropolis is deployed for video analytics.
The system of danger detectors enables lifeguards to keep tabs on a computer monitor that flags potential safety concerns while they scan the beach.
Sightbit has developed models based on convolutional neural networks and image detection to provide lifeguards views of potential dangers. Kovler, the company’s CTO, has trained the company’s danger detectors on tens of thousands of images, processed with NVIDIA GPUs in the cloud.
Training on the images wasn’t easy with sun glare on the ocean, weather conditions, crowds of people, and people partially submerged in the ocean, said Shezaf, the company’s CMO.
But Sightbit’s deep learning and proprietary algorithms have enabled it to identify children alone as well as clusters of people. This allows its system to flag children who have strayed from the pack.
Rip Current Recognition
The system also harnesses optical flow algorithms to detect dangerous rip currents in the ocean for helping lifeguards keep people out of those zones. These algorithms make it possible to identify the speed of every object in an image, using partial differential equations to calculate acceleration vectors of every voxel in the image.
Lifeguards can get updates on ocean conditions so when they start work they have a sense of hazards present that day.
“We spoke with many lifeguards. The lifeguard is trying to avoid the next accident. Many people go too deep and get caught in the rip currents,” said Eliav.
Cameras at lifeguard towers processed on the single compact supercomputing Jetson Xavier and accessing Metropolis can offer split-second inference for alerts, tracking, statistics and risk analysis in real time.
The Israel Nature and Parks Authority is planning to have a structure built on the beach to house more cameras for automated safety, according to Sightbit.
COVID-19 Calls
Palmachim Beach lifeguards have a lot to watch, especially now as people get out of their homes for fresh air after the region begins reopening from COVID-19-related closures.
As part of Sightbit’s beach safety developments, the company had been training its network to spot how far apart people were to help gauge child safety.
This work also directly applies to monitoring social distancing and has attracted the attention of potential customers seeking ways to slow the spread of COVID-19. The Sightbit platform can provide them crowding alerts when a public area is overcrowded and proximity alerts for when individuals are too close to each other, said Shezaf.
The startup has put in extra hours to work with those interested in its tech to help monitor areas for ways to reduce the spread of the pathogen.
“If you want to change the world, you need to do something that is going to affect people immediately without any focus on profit,” said Eliav.
Sightbit is a member of NVIDIA Inception, a virtual accelerator program that helps startups in AI and data science get to market faster.
The post Sand Safety: Startup’s Lifeguard AI Hits the Beach to Save Lives appeared first on The Official NVIDIA Blog.
Amazon at ACL: Old standards and new forays
Amazon researchers coauthor 17 conference papers, participate in seven workshops.Read More
2019 Q4 AWS Machine Learning Research Awards recipients announced
The AWS Machine Learning Research Awards (MLRA) is pleased to announce the 28 recipients of the 2019 Q4 call-for-proposal cycle.Read More

2019 Q4 recipients of AWS Machine Learning Research Awards
The AWS Machine Learning Research Awards (MLRA) aims to advance machine learning (ML) by funding innovative research and open-source projects, training students, and providing researchers with access to the latest technology. Since 2017, MLRA has supported over 180 research projects from 73 schools and research institutes in 13 countries, with topics such as ML algorithms, computer vision, natural language processing, medical research, neuroscience, social science, physics, and robotics.
On February 18, 2020, we announced the winners of MLRA’s 2019 Q2/Q3 call-for-proposal cycles. We’re now pleased to announce 28 new recipients of MLRA’s 2019 Q4 call-for-proposal cycle. The MLRA recipients represent 26 universities in six countries. The funded projects aim to develop open-source tools and research that benefit the ML community at large, or create impactful research using AWS ML solutions, such as Amazon SageMaker, AWS AI Services, and Apache MXNet on AWS. The following are the 2019 Q4 award recipients:
| Recipient | University | Research Title |
| Anasse Bari | New York University | Predicting the 2020 Elections Using Big Data, Analyzing What the World Wants Using Twitter and Teaching Next Generation of Thinkers How to Apply AI for Social Good |
| Andrew Gordon Wilson | New York University | Scalable Numerical Methods and Probabilistic Deep Learning with Applications to AutoML |
| Bo Li | University of Illinois at Urbana-Champaign | Trustworthy Machine Learning as Services via Robust AutoML and Knowledge Enhanced Logic Inference |
| Dawn Song | University of California, Berkeley | Protecting the Public Against AI-Generated Fakes |
| Dimosthenis Karatzas | Universitat Autónoma de Barcelona | Document Visual Question Answer (DocVQA) for Large-Scale Document Collections |
| Dit-Yan Yeung | Hong Kong University of Science and Technology | Temporally Misaligned Spatiotemporal Sequence Modeling |
| Lantao Liu | Indiana University Bloomington | Environment-Adaptive Sensing and Modeling using Autonomous Robots |
| Leonidas Guibas | Stanford University | Learning Canonical Spaces for Object-Centric 3D Perception |
| Maryam Rahnemoonfar | University of Maryland, Baltimore | Combining Model-Based and Data Driven Approaches to Study Climate Change via Amazon SageMaker |
| Mi Zhang | Michigan State University | DA-NAS: An AutoML Framework for Joint Data Augmentation and Neural Architecture Search |
| Michael P. Kelly | Washington University | Web-Based Machine Learning for Surgeon Benchmarking in Pediatric Spine Surgery |
| Ming Zhao | Arizona State University | Enabling Deep Learning across Edge Devices and Cloud Resources |
| Nianwen Xue | Brandeis University | AMR2KB: Construct a High-Quality Knowledge by Parsing Meaning Representations |
| Nicholas Chia | Mayo Clinic | Massively-Scaled Inverse Reinforcement Learning Approach for Reconstructing the Mutational History of Colorectal Cancer |
| Oswald Lanz | Fondazione Bruno Kessler | Structured Representation Learning for Video Recognition and Question Answering |
| Pierre Gentine | Columbia University | Learning Fires |
| Pratik Chaudhari | University of Pennsylvania | Offline and Off-Policy Reinforcement Learning |
| Pulkit Agrawal | Massachusetts Institute of Technology | Curiosity Baselines for the Reinforcement Learning Community |
| Quanquan Gu | University of California, Los Angeles | Towards Provably Efficient Deep Reinforcement Learning |
| Shayok Chakraborty | Florida State University | Active Learning with Imperfect Oracles |
| Soheil Feizi | University of Maryland, College Park | Explainable Deep Learning: Accuracy, Robustness and Fairness |
| Spyros Makradakis | University of Nicosia | Clustered Ensemble of Specialist Amazon GluonTS Models for Time Series Forecasting |
| Xin Jin | Johns Hopkins University | Making Sense of Network Performance for Distributed Machine Learning |
| Xuan (Sharon) Di | Columbia University | Multi-Autonomous Vehicle Driving Policy Learning for Efficient and Safe Traffic |
| Yi Yang | University of Technology Sydney | Efficient Video Analysis with Limited Supervision |
| Yun Raymond Fu | Northeastern University | Generative Feature Transformation for Multi-Viewed Domain Adaptation |
| Zhangyang (Atlas) Wang | Texas A&M University | Mobile-Captured Wound Image Analysis and Dynamic Modeling for Post-Discharge Monitoring of Surgical Site Infection |
| Zhi-Li Zhang | University of Minnesota | Universal Graph Embedding Neural Networks for Learning Graph-Structured Data |
Congratulations to all MLRA recipients! We look forward to supporting your research.
For more information about MLRA, see AWS Machine Learning Research Awards or send an email to aws-ml-research-awards@amazon.com.
About the Author
 Seo Yeon Shin is a program manager for the AWS AI Academic Programs.
Seo Yeon Shin is a program manager for the AWS AI Academic Programs.
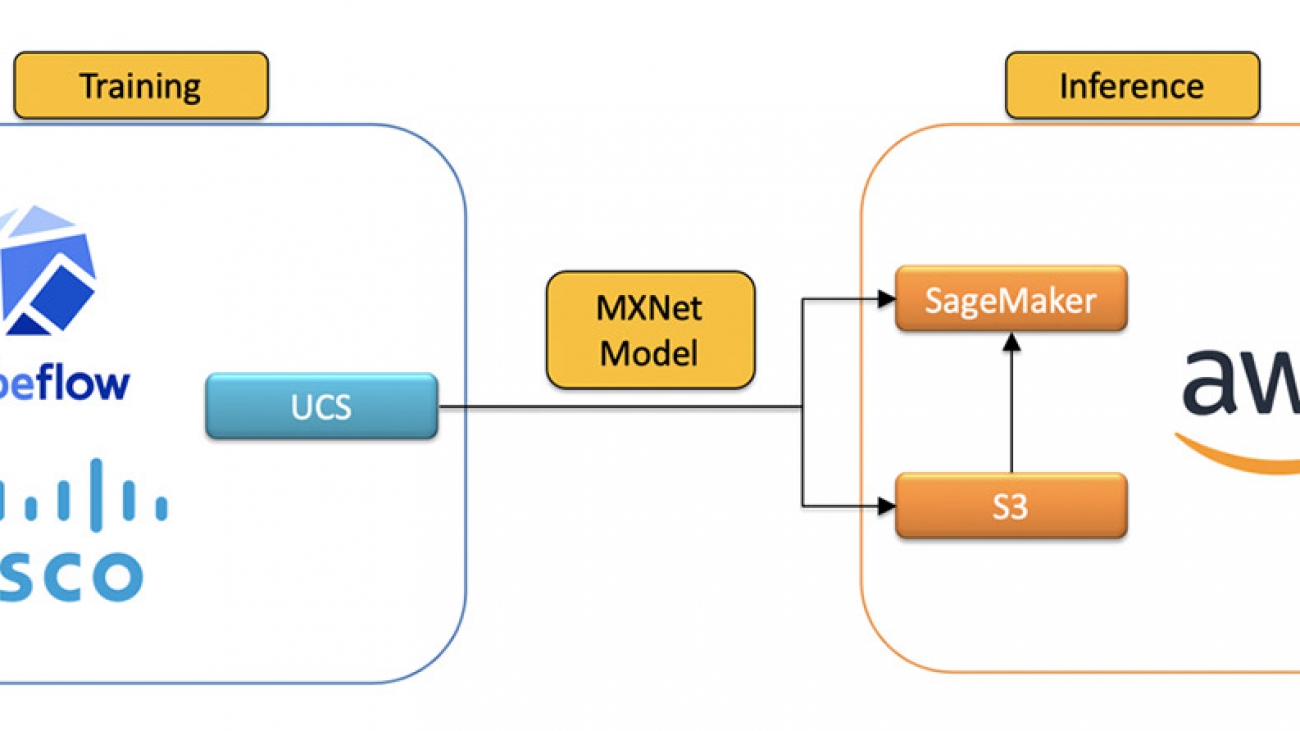
Cisco uses Amazon SageMaker and Kubeflow to create a hybrid machine learning workflow
This is a guest post from members of Cisco’s AI/ML best practices team, including Technical Product Manager Elvira Dzhuraeva, Distinguished Engineer Debo Dutta, and Principal Engineer Amit Saha.
Cisco is a large enterprise company that applies machine learning (ML) and artificial intelligence (AI) across many of its business units. The Cisco AI team in the office of the CTO is responsible for the company’s open source (OSS) AI/ML best practices across the business units that use AI and ML, and is also a major contributor to the Kubeflow open-source project and MLPerf/MLCommons. Our charter is to create artifacts and best practices in ML that both Cisco business units and our customers can use, and we share these solutions as reference architectures.
Due to business needs, such as localized data requirements, Cisco operates a hybrid cloud environment. Model training is done on our own Cisco UCS hardware, but many of our teams leverage the cloud for inference to take advantage of the scalability, geo redundancy, and resiliency. However, such implementations may be challenging to customers, because hybrid integration often requires deep expertise and knowledge to build and support consistent AI/ML workflows.
To address this, we built an ML pipeline using the Cisco Kubeflow starter pack for a hybrid cloud implementation that uses Amazon SageMaker to serve models in the cloud. By providing this reference architecture, we aim to help customers build seamless and consistent ML workloads across their complex infrastructure to satisfy whatever limitations they may face.
Kubeflow is a popular open-source library for ML orchestration on Kubernetes. If you operate in a hybrid cloud environment, you can install the Cisco Kubeflow starter pack to develop, build, train, and deploy ML models on-premises. The starter pack includes the latest version of Kubeflow and an application examples bundle.
Amazon SageMaker is a managed ML service that helps you prepare data, process data, train models, track model experiments, host models, and monitor endpoints. With SageMaker Components for Kubeflow Pipelines, you can orchestrate jobs from Kubeflow Pipelines, which we did for our hybrid ML project. This approach lets us seamlessly use Amazon SageMaker managed services for training and inference from our on-premises Kubeflow cluster. Using Amazon SageMaker provides our hosted models with enterprise features such as automatic scaling, multi-model endpoints, model monitoring, high availability, and security compliance.
To illustrate how our use case works, we recreate the scenario using the publicly available BLE RSSI Dataset for Indoor Localization and Navigation dataset, which contains Bluetooth Low Energy (BLE) Received Signal Strength Indication (RSSI) measurements. The pipeline trains and deploys a model to predict the location of Bluetooth devices. The following steps outline how a Kubernetes cluster can interact with Amazon SageMaker for a hybrid solution. The ML model, written in Apache MXNet, is trained using Kubeflow running on Cisco UCS servers to satisfy our localized data requirements and then deployed to AWS using Amazon SageMaker.
The created and trained model is uploaded to Amazon Simple Storage Service (Amazon S3) and uses Amazon SageMaker endpoints for serving. The following diagram shows our end-to-end workflow.
Development environment
To get started, if you don’t currently have Cisco hardware, you can set up Amazon Elastic Kubernetes Service (Amazon EKS) running with Kubeflow. For instructions, see Creating an Amazon EKS cluster and Deploying Kubeflow Pipelines.
If you have an existing UCS machine, the Cisco Kubeflow starter pack offers a quick Kubeflow setup on your Kubernetes cluster (v15.x or later). To install Kubeflow, set the INGRESS_IP variable with the machine’s IP address and run the kubeflowup.bash installation script. See the following code:
export INGRESS_IP=<UCS Machine's IP>
bash kubeflowup.bashFor more information about installation, see Installation Instructions on the GitHub repo.
Preparing the hybrid pipeline
For a seamless ML workflow between Cisco UCS and AWS, we created a hybrid pipeline using the Kubeflow Pipelines component and Amazon SageMaker Kubeflow components.
To start using the components you need to import Kubeflow Pipeline packages, including the AWS package:
import kfp
import kfp.dsl as dsl
from kfp import components
from kfp.aws import use_aws_secretFor the full code to configure and get the pipeline running, see the GitHub repo.
The pipeline describes the workflow and how the components relate to each other in the form of a graph. The pipeline configuration includes the definition of the inputs (parameters) required to run the pipeline and the inputs and outputs of each component. The following screenshot shows the visual representation of the finished pipeline on the Kubeflow UI.
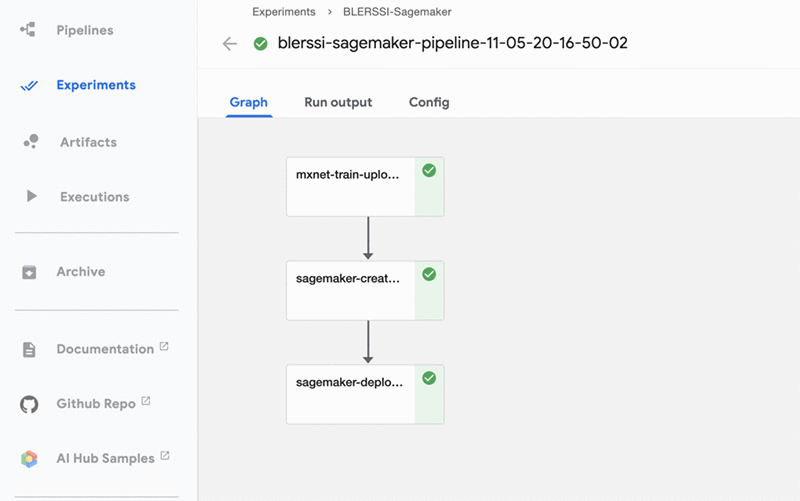
The pipeline runs the following three steps:
- Train the model
- Create the model resource
- Deploy the model
Training the model
You train the model with the BLE data locally, create an image, upload it to the S3 bucket, and register the model to Amazon SageMaker by applying the MXNet model configurations .yaml file.
When the trained model artifacts are uploaded to Amazon S3, Amazon SageMaker uses the model stored in Amazon S3 to deploy the model to a hosting endpoint. Amazon SageMaker endpoints make it easier for downstream applications to consume models and help the team monitor them with Amazon CloudWatch. See the following code:
def blerssi_mxnet_train_upload_op(step_name='mxnet-train'):
return dsl.ContainerOp(
name='mxnet-train-upload-s3',
image='ciscoai/mxnet-blerssi-train-upload:v0.2',
command=['python', '/opt/mx-dnn.py', 'train'],
arguments=['--bucket-name', bucket_name]
).apply(use_aws_secret(secret_name=aws_secret_name, aws_access_key_id_name='AWS_ACCESS_KEY_ID', aws_secret_access_key_name='AWS_SECRET_ACCESS_KEY'))
Creating the model resource
When the MXNet model and artifacts are uploaded to Amazon S3, use the KF Pipeline CreateModel component to create an Amazon SageMaker model resource.
The Amazon SageMaker endpoint API is flexible and offers several options to deploy a trained model to an endpoint. For example, you can let the default Amazon SageMaker runtime manage the model deployment, health check, and model invocation. Amazon SageMaker also allows for customization to the runtime with custom containers and algorithms. For instructions, see Overview of containers for Amazon SageMaker.
For our use case, we wanted some degree of control over the model health check API and the model invocation API. We chose the custom override for the Amazon SageMaker runtime to deploy the trained model. The custom predictor allows for flexibility in how the incoming request is processed and passed along to the model for prediction. See the following code:
sagemaker_model_op = components.load_component_from_url(model)Deploying the model
You deploy the model to an Amazon SageMaker endpoint with the KF Pipeline CreateEndpoint component.
The custom container used for inference gives the team maximum flexibility to define custom health checks and invocations to the model. However, the custom container must follow the golden path for APIs prescribed by the Amazon SageMaker runtime. See the following code:
sagemaker_deploy_op = components.load_component_from_url(deploy)Running the pipeline
To run your pipeline, complete the following steps:
- Configure the Python code that defines the hybrid pipeline with Amazon SageMaker components:
@dsl.pipeline( name='MXNet Sagemaker Hybrid Pipeline', description='Pipeline to train BLERSSI model using mxnet and save in aws s3 bucket' ) def mxnet_pipeline( region="", image="", model_name="", endpoint_config_name="", endpoint_name="", model_artifact_url="", instance_type_1="", role="" ): train_upload_model = blerssi_mxnet_train_upload_op() create_model = sagemaker_model_op( region=region, model_name=model_name, image=image, model_artifact_url=model_artifact_url, role=role ).apply(use_aws_secret(secret_name=aws_secret_name, aws_access_key_id_name='AWS_ACCESS_KEY_ID', aws_secret_access_key_name='AWS_SECRET_ACCESS_KEY')) create_model.after(train_upload_model) sagemaker_deploy=sagemaker_deploy_op( region=region, endpoint_config_name=endpoint_config_name, endpoint_name=endpoint_name, model_name_1=create_model.output, instance_type_1=instance_type_1 ).apply(use_aws_secret(secret_name=aws_secret_name, aws_access_key_id_name='AWS_ACCESS_KEY_ID', aws_secret_access_key_name='AWS_SECRET_ACCESS_KEY')) sagemaker_deploy.after(create_model)For more information about configuration, see Pipelines Quickstart. For the full pipeline code, see the GitHub repo.
- Run the pipeline by feeding the following parameters to execute the pipeline:
run = client.run_pipeline(blerssi_hybrid_experiment.id, 'blerssi-sagemaker-pipeline-'+timestamp, pipeline_package_path='mxnet_pipeline.tar.gz', params={ 'region': aws_region, 'image': inference_image, 'model_name': model_name, 'endpoint_config_name': endpoint_config_name, 'endpoint_name': endpoint_name, 'model_artifact_url': model_path, 'instance_type_1': instance_type, 'role': role_arn })
At this point, the BLERSSI Amazon SageMaker pipeline starts executing. After all the components execute successfully, check the logs of the sagemaker-deploy component to verify that the endpoint is created. The following screenshot shows the logs of the last step with the URL to the deployed model.
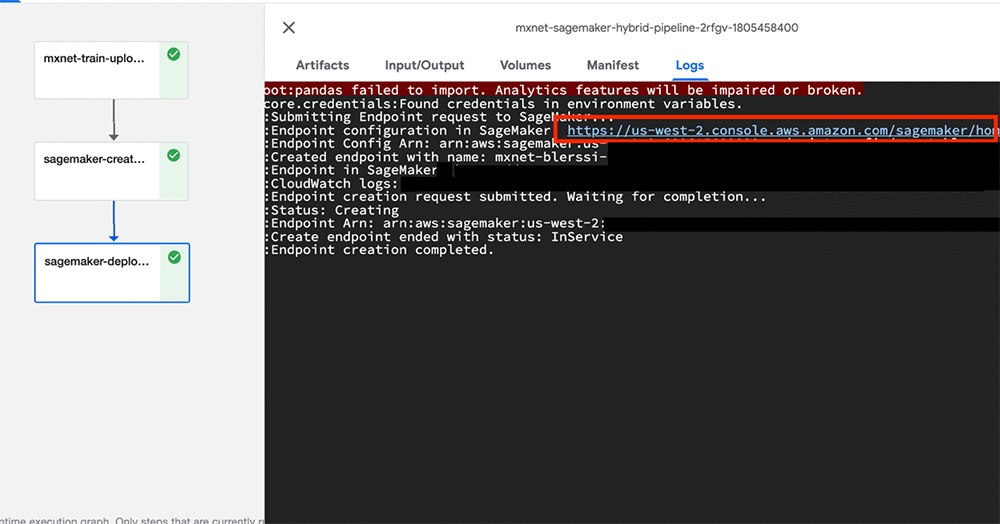
Validating the model
After the model is deployed in AWS, we validate it by submitting sample data to the model via an HTTP request using the endpoint name of the model deployed on AWS. The following screenshot shows a snippet from a sample Jupyter notebook that has a Python client and the corresponding output with location predictions.
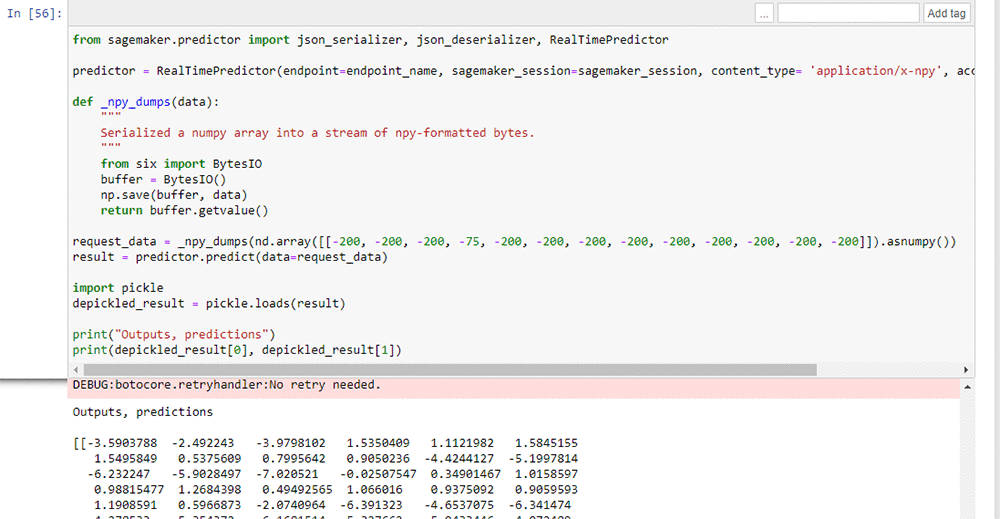
Conclusion
Amazon SageMaker and Kubeflow Pipelines can easily integrate in one single hybrid pipeline. The complete set of blogs and tutorials for Amazon SageMaker makes it easy to create a hybrid pipeline via the Amazon SageMaker components for Kubeflow Pipelines. The API was exhaustive, covered all the key components we needed to use, and allowed for the development of custom algorithms and integration with the Cisco Kubeflow Starter Pack. By uploading a trained ML model to Amazon S3 to serve on AWS with Amazon SageMaker, we reduced the complexity and TCO of managing complex ML lifecycles by about 50%. We comply with the highest standards of enterprise policies in data privacy and serve models in a scalable fashion with redundancy on AWS all over the United States and the world.
About the Authors
Elvira Dzhuraeva is a Technical Product Manager at Cisco where she is responsible for cloud and on-premise machine learning and artificial intelligence strategy. She is also a Community Product Manager at Kubeflow and a member of MLPerf community.
Debo Dutta is a Distinguished Engineer at Cisco where he leads a technology group at the intersection of algorithms, systems and machine learning. While at Cisco, Debo is currently a visiting scholar at Stanford. He got his PhD in Computer Science from University of Southern California, and an undergraduate in Computer Science from IIT Kharagpur, India.
Amit Saha is a Principal Engineer at Cisco where he leads efforts in systems and machine learning. He is a visiting faculty at IIT Kharagpur. He has a PhD in Computer Science from Rice University, Houston and an undergraduate from IIT Kharagpur. He has served on several program committees for top Computer Science conferences.

SmartReply for YouTube Creators
Posted by Rami Al-Rfou, Research Scientist, Google Research
It has been more than 4 years since SmartReply was launched, and since then, it has expanded to more users with the Gmail launch and Android Messages and to more devices with Android Wear. Developers now use SmartReply to respond to reviews within the Play Developer Console and can set up their own versions using APIs offered within MLKit and TFLite. With each launch there has been a unique challenge in modeling and serving that required customizing SmartReply for the task requirements.
We are now excited to share an updated SmartReply built for YouTube and implemented in YouTube Studio that helps creators engage more easily with their viewers. This model learns comment and reply representation through a computationally efficient dilated self-attention network, and represents the first cross-lingual and character byte-based SmartReply model. SmartReply for YouTube is currently available for English and Spanish creators, and this approach simplifies the process of extending the SmartReply feature to many more languages in the future.

YouTube creators receive a large volume of responses to their videos. Moreover, the community of creators and viewers on YouTube is diverse, as reflected by the creativity of their comments, discussions and videos. In comparison to emails, which tend to be long and dominated by formal language, YouTube comments reveal complex patterns of language switching, abbreviated words, slang, inconsistent usage of punctuation, and heavy utilization of emoji. Following is a sample of comments that illustrate this challenge:

Deep Retrieval
The initial release of SmartReply for Inbox encoded input emails word-by-word with a recurrent neural network, and then decoded potential replies with yet another word-level recurrent neural network. Despite the expressivity of this approach, it was computationally expensive. Instead, we found that one can achieve the same ends by designing a system that searches through a predefined list of suggestions for the most appropriate response.
This retrieval system encoded the message and its suggestion independently. First, the text was preprocessed to extract words and short phrases. This preprocessing included, but was not limited to, language identification, tokenization, and normalization. Two neural networks then simultaneously and independently encoded the message and the suggestion. This factorization allowed one to pre-compute the suggestion encodings and then search through the set of suggestions using an efficient maximum inner product search data structure. This deep retrieval approach enabled us to expand SmartReply to Gmail and since then, it has been the foundation for several SmartReply systems including the current YouTube system.
Beyond Words
The previous SmartReply systems described above relied on word level preprocessing that is well tuned for a limited number of languages and narrow genres of writing. Such systems face significant challenges in the YouTube case, where a typical comment might include heterogeneous content, like emoji, ASCII art, language switching, etc. In light of this, and taking inspiration from our recent work on byte and character language modeling, we decided to encode the text without any preprocessing. This approach is supported by research demonstrating that a deep Transformer network is able to model words and phrases from the ground up just by feeding it text as a sequence of characters or bytes, with comparable quality to word-based models.
Although initial results were promising, especially for processing comments with emoji or typos, the inference speed was too slow for production due to the fact that character sequences are longer than word equivalents and the computational complexity of self-attention layers grows quadratically as a function of sequence length. We found that shrinking the sequence length by applying temporal reduction layers at each layer of the network, similar to the dilation technique applied in WaveNet, provides a good trade-off between computation and quality.
The figure below presents a dual encoder network that encodes both the comment and the reply to maximize the mutual information between their latent representations by training the network with a contrastive objective. The encoding starts with feeding the transformer a sequence of bytes after they have been embedded. The input for each subsequent layer will be reduced by dropping a percentage of characters at equal offsets. After applying several transformer layers the sequence length is greatly truncated, significantly reducing the computational complexity. This sequence compression scheme could be substituted by other operators such as average pooling, though we did not notice any gains from more sophisticated methods, and therefore, opted to use dilation for simplicity.
 |
| A dual encoder network that maximizes the mutual information between the comments and their replies through a contrastive objective. Each encoder is fed a sequence of bytes and is implemented as a computationally efficient dilated transformer network. |
A Model to Learn Them All
Instead of training a separate model for each language, we opted to train a single cross-lingual model for all supported languages. This allows the support of mixed-language usage in the comments, and enables the model to utilize the learning of common elements in one language for understanding another, such as emoji and numbers. Moreover, having a single model simplifies the logistics of maintenance and updates. While the model has been rolled out to English and Spanish, the flexibility inherent in this approach will enable it to be expanded to other languages in the future.
Inspecting the encodings of a multilingual set of suggestions produced by the model reveals that the model clusters appropriate replies, regardless of the language to which they belong. This cross-lingual capability emerged without exposing the model during training to any parallel corpus. We demonstrate in the figure below for three languages how the replies are clustered by their meaning when the model is probed with an input comment. For example, the English comment “This is a great video,” is surrounded by appropriate replies, such as “Thanks!” Moreover, inspection of the nearest replies in other languages reveal them also to be appropriate and similar in meaning to the English reply. The 2D projection also shows several other cross-lingual clusters that consist of replies of similar meaning. This clustering demonstrates how the model can support a rich cross-lingual user experience in the supported languages.
 |
| A 2D projection of the model encodings when presented with a hypothetical comment and a small list of potential replies. The neighborhood surrounding English comments (black color) consists of appropriate replies in English and their counterparts in Spanish and Arabic. Note that the network learned to align English replies with their translations without access to any parallel corpus. |
When to Suggest?
Our goal is to help creators, so we have to make sure that SmartReply only makes suggestions when it is very likely to be useful. Ideally, suggestions would only be displayed when it is likely that the creator would reply to the comment and when the model has a high chance of providing a sensible and specific response. To accomplish this, we trained auxiliary models to identify which comments should trigger the SmartReply feature.
Conclusion
We’ve launched YouTube SmartReply, starting with English and Spanish comments, the first cross-lingual and character byte-based SmartReply. YouTube is a global product with a diverse user base that generates heterogeneous content. Consequently, it is important that we continuously improve comments for this global audience, and SmartReply represents a strong step in this direction.
Acknowledgements
SmartReply for YouTube creators was developed by Golnaz Farhadi, Ezequiel Baril, Cheng Lee, Claire Yuan, Coty Morrison, Joe Simunic, Rachel Bransom, Rajvi Mehta, Jorge Gonzalez, Mark Williams, Uma Roy and many more. We are grateful for the leadership support from Nikhil Dandekar, Eileen Long, Siobhan Quinn, Yun-hsuan Sung, Rachel Bernstein, and Ray Kurzweil.


Introducing neural supersampling for real-time rendering
Real-time rendering in virtual reality presents a unique set of challenges — chief among them being the need to support photorealistic effects, achieve higher resolutions, and reach higher refresh rates than ever before. To address this challenge, researchers at Facebook Reality Labs developed DeepFocus, a rendering system we introduced in December 2018 that uses AI to create ultra-realistic visuals in varifocal headsets. This year at the virtual SIGGRAPH Conference, we’re introducing the next chapter of this work, which unlocks a new milestone on our path to create future high-fidelity displays for VR.
Our SIGGRAPH technical paper, entitled “Neural Supersampling for Real-time Rendering,” introduces a machine learning approach that converts low-resolution input images to high-resolution outputs for real-time rendering. This upsampling process uses neural networks, training on the scene statistics, to restore sharp details while saving the computational overhead of rendering these details directly in real-time applications.
Our approach is the first learned supersampling method that achieves significant 16x supersampling of rendered content with high spatial and temporal fidelity, outperforming prior work by a large margin.

Animation comparing the rendered low-resolution color input to the 16x supersampling output produced by the introduced neural supersampling method.
What’s the research about?
To reduce the rendering cost for high-resolution displays, our method works from an input image that has 16 times fewer pixels than the desired output. For example, if the target display has a resolution of 3840×2160, then our network starts with a 960×540 input image rendered by game engines, and upsamples it to the target display resolution as a post-process in real-time.
While there has been a tremendous amount of research on learned upsampling for photographic images, none of it speaks directly to the unique needs of rendered content such as images produced by video game engines. This is due to the fundamental differences in image formation between rendered and photographic images. In real-time rendering, each sample is a point in both space and time. That is why the rendered content is typically highly aliased, producing jagged lines and other sampling artifacts seen in the low-resolution input examples in this post. This makes upsampling for rendered content both an antialiasing and interpolation problem, in contrast to the denoising and deblurring problem that is well-studied in existing superresolution research by the computer vision community. The fact that the input images are highly aliased and that information is completely missing at the pixels to be interpolated presents significant challenges for producing high-fidelity and temporally-coherent reconstruction for rendered content.

Example rendering attributes used as input to the neural supersampling method — color, depth, and dense motion vectors — rendered at a low resolution.
On the other hand, in real-time rendering, we can have more than the color imagery produced by a camera. As we showed in DeepFocus, modern rendering engines also give auxiliary information, such as depth values. We observed that, for neural supersampling, the additional auxiliary information provided by motion vectors proved particularly impactful. The motion vectors define geometric correspondences between pixels in sequential frames. In other words, each motion vector points to a subpixel location where a surface point visible in one frame could have appeared in the previous frame. These values are normally estimated by computer vision methods for photographic images, but such optical flow estimation algorithms are prone to errors. In contrast, the rendering engine can produce dense motion vectors directly, thereby giving a reliable, rich input for neural supersampling applied to rendered content.
Our method is built upon the above observations, and combines the additional auxiliary information with a novel spatio-temporal neural network design that is aimed at maximizing the image and video quality while delivering real-time performance.
At inference time, our neural network takes as input the rendering attributes (color, depth map and dense motion vectors per frame) of both current and multiple previous frames, rendered at a low resolution. The output of the network is a high-resolution color image corresponding to the current frame. The network is trained with supervised learning. At training time, a reference image that is rendered at the high resolution with anti-aliasing methods, paired with each low-resolution input frame, is provided as the target image for training optimization.

Example results. From top to bottom shows the rendered low-resolution color input, the 16x supersampling result by the introduced method, and the target high-resolution image rendered offline.

Example results. From top to bottom shows the rendered low-resolution color input, the 16x supersampling result by the introduced method, and the target high-resolution image rendered offline.

Example results. From left to right shows the rendered low-resolution color input, the 16x supersampling result by the introduced method, and the target high-resolution image rendered offline.
What’s next?
Neural rendering has great potential for AR/VR. While the problem is challenging, we would like to encourage more researchers to work on this topic. As AR/VR displays reach toward higher resolutions, faster frame rates, and enhanced photorealism, neural supersampling methods may be key for reproducing sharp details by inferring them from scene data, rather than directly rendering them. This work points toward a future for high-resolution VR that isn’t just about the displays, but also the algorithms required to practically drive them.
Read the full paper: Neural Supersampling for Real-time Rendering, Lei Xiao, Salah Nouri, Matt Chapman, Alexander Fix, Douglas Lanman, Anton Kaplanyan, ACM SIGGRAPH 2020.
The post Introducing neural supersampling for real-time rendering appeared first on Facebook Research.

Floating on Creativity: SuperBlimp Speeds Rendering Workflows with NVIDIA RTX GPUs
Rendering is a critical part of the design workflow. But as audiences and clients expect ever higher-quality graphics, agencies and studios must tap into the latest technology to keep up with rendering needs.
SuperBlimp, a creative production studio based just outside of London, knew there had to be a better way to achieve the highest levels of quality in the least amount of time. They’re leaving CPU rendering behind and moving to NVIDIA RTX GPUs, bringing significant acceleration to the rendering workflows for their unique productions.
After migrating to full GPU rendering, SuperBlimp experienced accelerated render times, making it easier to complete more iterations on their projects and develop creative visuals faster than before.
Blimping Ahead of Rendering With RTX
Because SuperBlimp is a small production studio, they needed the best performance at a low cost, so they turned to NVIDIA GeForce RTX 2080 Ti GPUs.
SuperBlimp had been using NVIDIA GPUs for the past few years, so they were already familiar with the power and performance of GPU acceleration. But they always had one foot in the CPU camp and needed to constantly switch between CPU and GPU rendering.
However, CPU render farms required too much storage space and took too much time. When SuperBlimp finally embraced full GPU rendering, they found RTX GPUs delivered the level of computing power they needed to create 3D graphics and animations on their laptops at a much quicker rate.
Powered by NVIDIA Turing, the most advanced GPU architecture for creators, RTX GPUs provide dedicated ray-tracing cores to help users speed up rendering performance and produce stunning visuals with photorealistic details.
And with NVIDIA Studio Drivers, the artists at SuperBlimp are achieving the best performance on their creative applications. NVIDIA Studio Drivers undergo extensive testing against multi-app creator workflows and multiple revisions of top creative applications, including Adobe Creative Cloud, Autodesk and more.
For one of their recent projects, an award-winning short film titled Playgrounds, SuperBlimp used Autodesk Maya for 3D modeling and Chaos Group’s V-Ray GPU software for rendering. V-Ray enabled the artists to create details that helped produce realistic surfaces, from metallic finishes to plastic materials.
“With NVIDIA GPUs, we saw render times reduce from 3 hours to 15 minutes. This puts us a great position to create compelling work,” said Antonio Milo, director at SuperBlimp. “GPU rendering opened the door for a tiny studio like us to design and produce even more eye-catching content than before.”

Now, SuperBlimp renders their projects using NVIDIA GeForce RTX 2080 Ti and GTX 1080 Ti GPUs to bring incredible speeds for rendering, so their artists can complete creative projects with the powerful, flexible and high-quality performance they need.
Learn how NVIDIA GPUs are powering the future of creativity.
The post Floating on Creativity: SuperBlimp Speeds Rendering Workflows with NVIDIA RTX GPUs appeared first on The Official NVIDIA Blog.