20tree.ai is on a mission to help protect the Earth’s forests by providing data-driven and actionable planet intelligence.Read More
How some of AWS’s most innovative customers are using computer vision technologies
From counting fish to identifying touchdowns, AWS customers are utilizing computer vision and pattern recognition technologies to improve business processes and customer experiences.Read More

Improving Speech Representations and Personalized Models Using Self-Supervision
Posted by Joel Shor, Software Engineer and Oran Lang, Software Engineer, Google Research, Israel
There are many tasks within speech processing that are easier to solve by having large amounts of data. For example automatic speech recognition (ASR) translates spoken audio into text. In contrast, “non-semantic” tasks focus on the aspects of human speech other than its meaning, encompassing “paralinguistic” tasks, like speech emotion recognition, as well as other kinds of tasks, such as speaker identification, language identification, and certain kinds of voice-based medical diagnoses. In training systems to accomplish these tasks, one common approach is to utilize the largest datasets possible to help ensure good results. However, machine learning techniques that directly rely on massive datasets are often less successful when trained on small datasets.
One way to bridge the performance gap between large and small datasets is to train a representation model on a large dataset, then transfer it to a setting with less data. Representations can improve performance in two ways: they can make it possible to train small models by transforming high-dimensional data (like images and audio) to a lower dimension, and the representation model can also be used as pre-training. In addition, if the representation model is small enough to be run or trained on-device, it can improve performance in a privacy-preserving way by giving users the benefits of a personalized model where the raw data never leaves their device. While representation learning is commonly used in the text domain (e.g. BERT and ALBERT) and in the images domain (e.g. Inception layers and SimCLR), such approaches are underutilized in the speech domain.
 |
| Bottom:A large speech dataset is used to train a model, which is then rolled out to other environments. Top Left: On-device personalization — personalized, on-device models combine security and privacy. Top Middle: Small model on embeddings — general-use representations transform high-dimensional, few-example datasets to a lower dimension without sacrificing accuracy; smaller models train faster and are regularized. Top Right: Full model fine-tuning — large datasets can use the embedding model as pre-training to improve performance |
Unambiguously improving generally-useful representations, for non-semantic speech tasks in particular, is difficult without a standard benchmark to compare “speech representation usefulness.” While the T5 framework systematically evaluates text embeddings and the Visual Task Adaptation Benchmark (VTAB) standardizes image embedding evaluation, both leading to progress in representation learning in those respective fields, there has been no such benchmark for non-semantic speech embeddings.
In “Towards Learning a Universal Non-Semantic Representation of Speech“, we make three contributions to representation learning for speech-related applications. First, we present a NOn-Semantic Speech (NOSS) benchmark for comparing speech representations, which includes diverse datasets and benchmark tasks, such as speech emotion recognition, language identification, and speaker identification. These datasets are available in the “audio” section of TensorFlow Datasets. Second, we create and open-source TRIpLet Loss network (TRILL), a new model that is small enough to be executed and fine-tuned on-device, while still outperforming other representations. Third, we perform a large-scale study comparing different representations, and open-source the code used to compute the performance on new representations.
A New Benchmark for Speech Embeddings
For a benchmark to usefully guide model development, it must contain tasks that ought to have similar solutions and exclude those that are significantly different. Previous work either dealt with the variety of possible speech-based tasks independently, or lumped semantic and non-semantic tasks together. Our work improves performance on non-semantic speech tasks, in part, by focusing on neural network architectures that perform well specifically on this subset of speech tasks.
The tasks were selected for the NOSS benchmark on the basis of their 1) diversity — they need to cover a range of use-cases; 2) complexity — they should be challenging; and 3) availability, with particular emphasis on those tasks that are open-source. We combined six datasets of different sizes and tasks.
 |
| Datasets for downstream benchmark tasks. *VoxCeleb results in our study were computed using a subset of the dataset that was filtered according to internal policy. |
We also introduce three additional intra-speaker tasks to test performance in the personalization scenario. In some datasets with k speakers, we can create k different tasks consisting of training and testing on just a single speaker. Overall performance is averaged across speakers. These three additional intra-speaker tasks measure the ability of an embedding to adapt to a particular speaker, as would be necessary for personalized, on-device models, which are becoming more important as computation moves to smart phones and the internet of things.
To help enable researchers to compare speech embeddings, we’ve added the six datasets in our benchmark to TensorFlow Datasets (in the “audio” section) and open sourced the evaluation framework.
TRILL: A New State of the Art in Non-semantic Speech Classification
Learning an embedding from one dataset and applying it to other tasks is not as common in speech as in other modalities. However, transfer learning, the more general technique of using data from one task to help another (not necessarily with embeddings), has some compelling applications, such as personalizing speech recognizers and voice imitation text-to-speech from few samples. There have been many previously proposed representations of speech, but most of these have been trained on a smaller and less diverse data, have been tested primarily on speech recognition, or both.
To create a data-derived representation of speech that was useful across environments and tasks, we started with AudioSet, a large and diverse dataset that includes about 2500 hours of speech. We then trained an embedding model on a simple, self-supervised criteria derived from previous work on metric learning — embeddings from the same audio should be closer in embedding space than embeddings from different audio. Like BERT and the other text embeddings, the self-supervised loss function doesn’t require labels and only relies on the structure of the data itself. This form of self-supervision is the most appropriate for non-semantic speech, since non-semantic phenomena are more stable in time than ASR and other sub-second speech characteristics. This simple, self-supervised criteria captures a large number of acoustic properties that are leveraged in downstream tasks.
 |
| TRILL loss: Embeddings from the same audio are closer in embedding space than embeddings from different audio. |
TRILL architecture is based on MobileNet, making it fast enough to run on mobile devices. To achieve high accuracy on this small architecture, we distilled the embedding from a larger ResNet50 model without performance degradation.
Benchmark Results
We compared the performance of TRILL against other deep learning representations that are not focused on speech recognition and were trained on similarly diverse datasets. In addition, we compared TRILL to the popular OpenSMILE feature extractor, which uses pre-deep learning techniques (e.g., a fourier transform coefficients, “pitch tracking” using a time-series of pitch measurements, etc.), and randomly initialized networks, which have been shown to be strong baselines. To aggregate the performance across tasks that have different performance characteristics, we first train a small number of simple models, for a given task and embedding. The best result is chosen. Then, to understand the effect that a particular embedding has across all tasks, we calculate a linear regression on the observed accuracies, with both the model and task as the explanatory variables. The effect a model has on the accuracy is the coefficient associated with the model in the regression. For a given task, when changing from one model to another, the resulting change in accuracy is expected to be the difference in y-values in the figure below.
 |
| Effect of model on accuracy. |
TRILL outperforms the other representations in our study. Factors that contribute to TRILL’s success are the diversity of the training dataset, the large context window of the network, and the generality of the TRILL training loss that broadly preserves acoustic characteristics instead of prematurely focusing on certain aspects. Note that representations from intermediate network layers are often more generally useful. The intermediate representations are larger, have finer temporal granularity, and in the case of the classification networks they retain more general information that isn’t as specific to the classes on which they were trained.
Another benefit of a generally-useful model is that it can be used to initialize a model on a new task. When the sample size of a new task is small, fine-tuning an existing model may lead to better results than training the model from scratch. We achieved a new state-of-the-art result on three out of six benchmark tasks using this technique, despite doing no dataset-specific hyperparameter tuning.
To compare our new representation, we also tested it on the mask sub-challenge of the Interspeech 2020 Computational Paralinguistics Challenge (ComParE). In this challenge, models must predict whether a speaker is wearing a mask, which would affect their speech. The mask effects are sometimes subtle, and audio clips are only one second long. A linear model on TRILL outperformed the best baseline model, which was a fusion of many models on different kinds of features including traditional spectral and deep-learned features.
Summary
The code to evaluate NOSS is available on GitHub, the datasets are on TensorFlow Datasets, and the TRILL models are available on AI Hub.
The NOn-Semantic Speech benchmark helps researchers create speech embeddings that are useful in a wide range of contexts, including for personalization and small-dataset problems. We provide the TRILL model to the research community as a baseline embedding to surpass.
Acknowledgements
The core team behind this work includes Joel Shor, Aren Jansen, Ronnie Maor, Oran Lang, Omry Tuval, Felix de Chaumont Quitry, Marco Tagliasacchi, Ira Shavitt, Dotan Emanuel, and Yinnon Haviv. We’d also like to thank Avinatan Hassidim and Yossi Matias for technical guidance.

MIT and Toyota release innovative dataset to accelerate autonomous driving research
The following was issued as a joint release from the MIT AgeLab and Toyota Collaborative Safety Research Center.
How can we train self-driving vehicles to have a deeper awareness of the world around them? Can computers learn from past experiences to recognize future patterns that can help them safely navigate new and unpredictable situations?
These are some of the questions researchers from the AgeLab at the MIT Center for Transportation and Logistics and the Toyota Collaborative Safety Research Center (CSRC) are trying to answer by sharing an innovative new open dataset called DriveSeg.
Through the release of DriveSeg, MIT and Toyota are working to advance research in autonomous driving systems that, much like human perception, perceive the driving environment as a continuous flow of visual information.
“In sharing this dataset, we hope to encourage researchers, the industry, and other innovators to develop new insight and direction into temporal AI modeling that enables the next generation of assisted driving and automotive safety technologies,” says Bryan Reimer, principal researcher. “Our longstanding working relationship with Toyota CSRC has enabled our research efforts to impact future safety technologies.”
“Predictive power is an important part of human intelligence,” says Rini Sherony, Toyota CSRC’s senior principal engineer. “Whenever we drive, we are always tracking the movements of the environment around us to identify potential risks and make safer decisions. By sharing this dataset, we hope to accelerate research into autonomous driving systems and advanced safety features that are more attuned to the complexity of the environment around them.”
To date, self-driving data made available to the research community have primarily consisted of troves of static, single images that can be used to identify and track common objects found in and around the road, such as bicycles, pedestrians, or traffic lights, through the use of “bounding boxes.” By contrast, DriveSeg contains more precise, pixel-level representations of many of these same common road objects, but through the lens of a continuous video driving scene. This type of full-scene segmentation can be particularly helpful for identifying more amorphous objects — such as road construction and vegetation — that do not always have such defined and uniform shapes.
According to Sherony, video-based driving scene perception provides a flow of data that more closely resembles dynamic, real-world driving situations. It also allows researchers to explore data patterns as they play out over time, which could lead to advances in machine learning, scene understanding, and behavioral prediction.
DriveSeg is available for free and can be used by researchers and the academic community for non-commercial purposes at the links below. The data is comprised of two parts. DriveSeg (manual) is 2 minutes and 47 seconds of high-resolution video captured during a daytime trip around the busy streets of Cambridge, Massachusetts. The video’s 5,000 frames are densely annotated manually with per-pixel human labels of 12 classes of road objects.
DriveSeg (Semi-auto) is 20,100 video frames (67 10-second video clips) drawn from MIT Advanced Vehicle Technologies (AVT) Consortium data. DriveSeg (Semi-auto) is labeled with the same pixel-wise semantic annotation as DriveSeg (manual), except annotations were completed through a novel semiautomatic annotation approach developed by MIT. This approach leverages both manual and computational efforts to coarsely annotate data more efficiently at a lower cost than manual annotation. This dataset was created to assess the feasibility of annotating a wide range of real-world driving scenarios and assess the potential of training vehicle perception systems on pixel labels created through AI-based labeling systems.
To learn more about the technical specifications and permitted use-cases for the data, visit the DriveSeg dataset page.
MIT-Takeda program launches
In February, researchers from MIT and Takeda Pharmaceuticals joined together to celebrate the official launch of the MIT-Takeda Program. The MIT-Takeda Program aims to fuel the development and application of artificial intelligence (AI) capabilities to benefit human health and drug development. Centered within the Abdul Latif Jameel Clinic for Machine Learning in Health (Jameel Clinic), the program brings together the MIT School of Engineering and Takeda Pharmaceuticals, to combine knowledge and address challenges of mutual interest.
Following a competitive proposal process, nine inaugural research projects were selected. The program’s flagship research projects include principal investigators from departments and labs spanning the School of Engineering and the Institute. Research includes diagnosis of diseases, prediction of treatment response, development of novel biomarkers, process control and improvement, drug discovery, and clinical trial optimization.
“We were truly impressed by the creativity and breadth of the proposals we received,” says Anantha P. Chandrakasan, dean of the School of Engineering, Vannevar Bush Professor of Electrical Engineering and Computer Science, and co-chair of the MIT-Takeda Program Steering Committee.
Engaging with researchers and industry experts from Takeda, each project team will bring together different disciplines, merging theory and practical implementation, while combining algorithm and platform innovations.
“This is an incredible opportunity to merge the cross-disciplinary and cross-functional expertise of both MIT and Takeda researchers,” says Chandrakasan. “This particular collaboration between academia and industry is of great significance as our world faces enormous challenges pertaining to human health. I look forward to witnessing the evolution of the program and the impact its research aims to have on our society.”
“The shared enthusiasm and combined efforts of researchers from across MIT and Takeda have the opportunity to shape the future of health care,” says Anne Heatherington, senior vice president and head of Data Sciences Institute (DSI) at Takeda, and co-chair of the MIT-Takeda Program Steering Committee. “Together we are building capabilities and addressing challenges through interrogation of multiple data types that we have not been able to solve with the power of humans alone that have the potential to benefit both patients and the greater community.”
The following are the inaugural projects of the MIT-Takeda Program. Included are the MIT teams collaborating with Takeda researchers, who are leveraging AI to positively impact human health.
“AI-enabled, automated inspection of lyophilized products in sterile pharmaceutical manufacturing”: Duane Boning, the Clarence J. LeBel Professor of Electrical Engineering and faculty co-director of the Leaders for Global Operations program; Luca Daniel, professor of electrical engineering and computer science; Sanjay Sarma, the Fred Fort Flowers and Daniel Fort Flowers Professor of Mechanical Engineering and vice president for open learning; and Brian Subirana, research scientist and director MIT Auto-ID Laboratory within the Department of Mechanical Engineering.
“Automating adverse effect assessments and scientific literature review”: Regina Barzilay, the Delta Electronics Professor of Electrical Engineering and Computer Science and Jameel Clinic faculty co-lead; Tommi Jaakkola, the Thomas Siebel Professor of Electrical Engineering and Computer Science and the Institute for Data, Systems, and Society; and Jacob Andreas, assistant professor of electrical engineering and computer science.
“Automated analysis of speech and language deficits for frontotemporal dementia”: James Glass, senior research scientist in the MIT Computer Science and Artificial Intelligence Laboratory; Sanjay Sarma, the Fred Fort Flowers and Daniel Fort Flowers Professor of Mechanical Engineering and vice president for open learning; and Brian Subirana, research scientist and director of the MIT Auto-ID Laboratory within the Department of Mechanical Engineering.
“Discovering human-microbiome protein interactions with continuous distributed representation”: Jim Collins, the Termeer Professor of Medical Engineering and Science in MIT’s Institute for Medical Engineering and Science and Department of Biological Engineering, Jameel Clinic faculty co-lead, and MIT-Takeda Program faculty lead; and Timothy Lu, associate professor of electrical engineering and computer science and of biological engineering.
“Machine learning for early diagnosis, progression risk estimation, and identification of non-responders to conventional therapy for inflammatory bowel disease”: Peter Szolovits, professor of computer science and engineering, and David Sontag, associate professor of electrical engineering and computer science.
“Machine learning for image-based liver phenotyping and drug discovery”: Polina Golland, professor of electrical engineering and computer science; Brian W. Anthony, principal research scientist in the Department of Mechanical Engineering; and Peter Szolovits, professor of computer science and engineering.
“Predictive in silico models for cell culture process development for biologics manufacturing”: Connor W. Coley, assistant professor of chemical engineering, and J. Christopher Love, the Raymond A. (1921) and Helen E. St. Laurent Professor of Chemical Engineering.
“Automated data quality monitoring for clinical trial oversight via probabilistic programming”: Vikash Mansinghka, principal research scientist in the Department of Brain and Cognitive Sciences; Tamara Broderick, associate professor of electrical engineering and computer science; David Sontag, associate professor of electrical engineering and computer science; Ulrich Schaechtle, research scientist in the Department of Brain and Cognitive Sciences; and Veronica Weiner, director of special projects for the MIT Probabilistic Computing Project.
“Time series analysis from video data for optimizing and controlling unit operations in production and manufacturing”: Allan S. Myerson, professor of chemical engineering; George Barbastathis, professor of mechanical engineering; Richard Braatz, the Edwin R. Gilliland Professor of Chemical Engineering; and Bernhardt Trout, the Raymond F. Baddour, ScD, (1949) Professor of Chemical Engineering.
“The flagship research projects of the MIT-Takeda Program offer real promise to the ways we can impact human health,” says Jim Collins. “We are delighted to have the opportunity to collaborate with Takeda researchers on advances that leverage AI and aim to shape health care around the globe.”

Using Selective Attention in Reinforcement Learning Agents
Posted by Yujin Tang, Research Software Engineer and David Ha, Staff Research Scientist, Google Research, Tokyo
Inattentional blindness is the psychological phenomenon that causes one to miss things in plain sight, and is a consequence of the selective attention that enables you to remain focused on important parts of the world without distraction from irrelevant details. It is believed that this selective attention mechanism enables people to condense broad sensory information into a form that is compact enough to be used for future decision making. While this may seem to be a limitation, such “bottlenecks” observed in nature can also inspire the design of machine learning systems that hope to mimic the success and efficiency of biological organisms. For example, while most methods presented in the deep reinforcement learning (RL) literature allow an agent to access the entire visual input, and even incorporating modules for predicting future sequences of visual inputs, perhaps reducing an agent’s access to its visual inputs via an attention constraint could be beneficial to an agent’s performance?
In our recent GECCO 2020 paper, “Neuroevolution of Self-Interpretable Agents” (AttentionAgent), we investigate the properties of such agents that employ a self-attention bottleneck. We show that not only are they able to solve challenging vision-based tasks from pixel inputs with 1000x fewer learnable parameters compared to conventional methods, they are also better at generalization to unseen modifications of their tasks, simply due to its ability to “not see details” that can confuse it. Furthermore, looking at where the agent is focusing its attention provides visual interpretability to its decision making process. The following diagram illustrates how the agent learned to deal with its attention bottleneck:
 |
| AttentionAgent learned to attend to task critical regions in its visual inputs. In a car driving task (CarRacing, top row), the agent mostly attends to the road borders, but shifts its focus to the turns before it changes heading directions. In a fireball dodging game (DoomTakeCover, bottom row), the agent focuses on fireballs and enemy monsters. Left: Visual inputs to the agent. Center: Agent’s attention overlaid on the visual inputs, the white patches indicate where the agent focuses its attention. Right: Visual cues based on which the agent makes decisions. |
Agent with Artificial Attention
While there have been several works that explore how constraints such as sparsity may play a role in actually shaping the abilities of reinforcement learning agents, AttentionAgent takes inspiration from concepts related to inattentional blindness — when the brain is involved in effort-demanding tasks, it assigns most of its attention capacity only to task-relevant elements and is temporarily blind to other signals. To achieve this, we segment the input image into several patches and then rely on a modified self-attention architecture to simulate voting between patches to elect a subset to be considered important. The patches of interest are elected at each time step and, once determined, AttentionAgent makes decisions solely on these patches, ignoring the rest.
In addition to extracting key factors from visual inputs, the ability to contextualize these factors as they change in time is just as crucial. For example, a batter in the game of baseball must use visual signals to continuously keep track of the baseball’s location in order to predict its position and be able to hit it. In AttentionAgent, a long short-term memory (LSTM) model accepts information from the important patches and generates an action at each time step. LSTM keeps track of the changes in the input sequence, and can thus utilize the information to track how critical factors evolve over time.
It is conventional to optimize a neural network with backpropagation. However, because AttentionAgent contains non-differentiable operations for the generation of important patches, like sorting and slicing, it is not straightforward to apply such techniques for training. We therefore turn to derivative-free optimization algorithms to overcome this difficulty.
 |
| Overview of our method and illustration of data processing flow in AttentionAgent. Top: Input transformation — A sliding window segments an input image into smaller patches, and then “flattens” them for future processing. Middle: Patch election — The modified self-attention module holds votes between patches to generate a patch importance vector. Bottom: Action generation — AttentionAgent picks the patches of the highest importance, extracts corresponding features and makes decisions based on them. |
Generalization to Unseen Modifications of the Environment
We demonstrate that Attention Agent learned to attend to a variety of regions in the input images. Visualization of the important patches provides a peek into how the agent is making decisions, illustrating that most selections make sense and are consistent with human intuition, and is a powerful tool for analyzing and debugging an agent in development. Furthermore, since the agent learned to ignore information non-critical to the core task, it can generalize to tasks where small environmental modifications are applied.
Here, we show that restricting the agent’s decision-making controller’s access to important patches only while ignoring the rest of the scene can result in better generalization, simply due to how the agent is restricted from “seeing things” that can confuse it. Our agent is trained to survive in the VizDoom TakeCover environment only, but it can also survive in unseen settings with higher walls, different floor textures, or when confronted with a distracting sign.
 |
| DoomTakeCover Generalization: The AttentionAgent is trained in the environment with no modifications (left). It is able to adapt to changes in the environment, such as a higher wall (middle, left), a different floor texture (middle, right), or floating text (right). |
When one learns to drive during a sunny day, one also can transfer those skills (to some extent) to driving at night, on a rainy day, in a different car, or in the presence of bird droppings on the windshield. AttentionAgent is not only able to solve CarRacing-v0, it can also achieve similar performance in unseen conditions, such as brighter or darker scenery, or having its vision modified by artifacts such as side bars or background blobs, while requiring 1000x fewer parameters than conventional methods that fail to generalize.
 |
| CarRacing Generalization: No modification (left); color perturbation (middle, left); vertical bars on left and right (middle, right); added red blob (right). |
Limitations and Future Work
While AttentionAgent is able to cope with various modifications of the environment, there are limitations to this approach, and much more work to be done to further enhance the generalization capabilities of the agent. For example, AttentionAgent does not generalize to cases where dramatic background changes are involved. The agent trained on the original car racing environment with the green grass background fails to generalize when the background is replaced with distracting YouTube videos. When we take this one step further and replace the background with pure uniform noise, we observe that the agent’s attention module breaks down and attends only to random patches of noise, rather than to the road-related patches. If we train an agent from scratch in the noisy background environment, it manages to get around the track, although the performance is mediocre. Interestingly, the agent still attends only to the noise, rather than to the road, it appears to have learned to drive by estimating where the lane is based on the number of selected patches on the left and right of the screen.
 |
| AttentionAgent fails to generalize to drastically modified environments. Left: The background suddenly becomes a cat (Creative Commons video). Middle: The background suddenly becomes an arcade game (Creative Commons video). Right: AttentionAgent learned to drive on pure noise background by avoiding noise patches. |
The simplistic method we use to extract information from important patches may be inadequate for more complicated tasks. How we can learn more meaningful features, and perhaps even extract symbolic information from the visual input will be an exciting future direction. In addition to open sourcing the code to the research community, we have also released CarRacingExtension, a suite of car racing tasks that involve various environmental modifications, as testbeds and benchmark for ML researchers who are interested in agent generalizations.
Acknowledgements
This research was conducted by Yujin Tang, Duong Nguyen, and David Ha. We would like to thank Yingtao Tian, Lana Sinapayen, Shixin Luo, Krzysztof Choromanski, Sherjil Ozair, Ben Poole, Kai Arulkumaran, Eric Jang, Brian Cheung, Kory Mathewson, Ankur Handa, and Jeff Dean for valuable discussions.
Sizing neural networks to the available hardware
A new approach to determining the “channel configuration” of convolutional neural nets improves accuracy while maintaining runtime efficiency.Read More
Facebook announces award recipients of the Ethics in AI Research Initiative for the Asia Pacific
The development of state-of-the-art AI technologies often brings to light intricate and complex ethical questions that industry, academia, and governments must work together to solve.
To help support thoughtful and groundbreaking academic research in the field of AI ethics in the Asia Pacific, Facebook partnered with the Centre for Civil Society and Governance of The University of Hong Kong and the Privacy Commissioner for Personal Data, Hong Kong (PCPD; esteemed co-chair of the Permanent Working Group on Ethics and Data Protection in AI of the Global Privacy Assembly) to launch the Ethics in AI for the Asia Pacific RFP in December 2019. Today, Facebook is announcing the winners of these research awards.
View RFPSharing the same goal as the Ethics in AI – India RFP announced by Facebook in June 2019, this RFP aimed to support independent AI ethics research that takes local traditional knowledge and regionally diverse perspectives into account. The RFP was open to academic institutions, think tanks, and research organizations registered and operational across Asia Pacific. We were particularly interested in proposals related to the topics of fairness, governance, and diversity.
“AI technologies are increasingly being applied to various industries to enhance business operations, and ethical issues arising from these applications, such as ethical and fair processing of personal data, must be fully addressed,” says Stephen Kai-yi Wong, Privacy Commissioner for Personal Data, Hong Kong. “Commercial and public sectors, academia, and regulatory bodies need to work together to promote a strong ethical culture when it comes to the development and application of AI systems. Besides advocating accountability and data ethics for AI, we as the co-chair of the Permanent Working Group on Ethics and Data Protection in AI of the Global Privacy Assembly also take the lead in working out practical guidance in addressing ethical and data protection issues in AI systems. We hope the winning projects will facilitate better understanding of ethics and data protection in AI, and foster regional efforts in this field.”
“AI has created substantial potential for the attainment of the UN Sustainable Development Goals. To fully materialize the potential, AI’s application needs to be ethical and effectively governed by appropriate rules and mechanisms in multiple arenas,” says Professor Lam, Director of Centre for Civil Society and Governance, The University of Hong Kong. “Our Centre is pleased to collaborate with academia, the AI industry, and the public and business sectors in this initiative to promote research and dialogue on AI ethics in the Asia Pacific region. I look forward to seeing some of the research findings of the winning projects, which will inform policy deliberation and action.”
“The latest advancements in AI bring transformational changes to society, and at the same time bring an array of complex ethical questions that must be closely examined. At Facebook, we believe our understanding of AI should be informed by research conducted in open collaboration with the community,” says Raina Yeung, Head of Privacy and Data Policy, Engagement, APAC at Facebook. “That’s why we’re keen to support independent academic research institutions in APAC in pursuing interdisciplinary research in AI ethics that will enable ongoing dialogue on these important issues in the application of AI technology that has a lot of potential to benefit society and mankind.”
Thank you to everyone who submitted a proposal, and congratulations to the winners.
Research award winners
Principal investigators are listed first unless otherwise noted.
AI decisions with dignity: Promoting interactional justice perceptions
Dr. Sarah Bankins, Prof. Deborah Richards, A/Prof. Paul Formosa, (Macquarie University), Dr. Yannick Griep (Radboud University)
The challenges of implementing AI ethics frameworks in the Asia Pacific
Manju Lasantha Fernando, Ramathi Bandaranayake, Viren Dias, Helani Galpaya, Rohan Samarajiva (LIRNEasia)
Culturally informed pro-social AI regulation and persuasion framework
Dr. Junaid Qadir (Information Technology University of Lahore, Punjab, Pakistan), Dr. Amana Raquib (Institute of Business Administration – Karachi, Pakistan)
Ethical challenges on application of AI for the aged care
Dr. Bo Yan, Dr. Priscilla Song, Dr. Chia-Chin Lin (University of Hong Kong)
Ethical technology assessment on AI and internet of things
Dr. Melvin Jabar, Dr. Ma. Elena Chiong Javier (De La Salle University), Mr. Jun Motomura (Meio University), Dr. Penchan Sherer (Mahidol University)
Operationalizing information fiduciaries for AI governance
Yap Jia Qing, Ong Yuan Zheng Lenon, Elizaveta Shesterneva, Riyanka Roy Choudhury, Rocco Hu (eTPL.Asia)
Respect for rights in the era of automation, using AI and robotics
Emilie Pradichit, Ananya Ramani, Evie van Uden (Manushya Foundation), Henning Glasser, Dr. Duc Quang Ly, Venus Phuangkom (German-Southeast Asian Center of Excellence for Public Policy and Good Governance)
The uses and abuses of black box AI in emergency medicine
Prof. Robert Sparrow, Joshua Hatherley, Mark Howard (Monash University)
The post Facebook announces award recipients of the Ethics in AI Research Initiative for the Asia Pacific appeared first on Facebook Research.
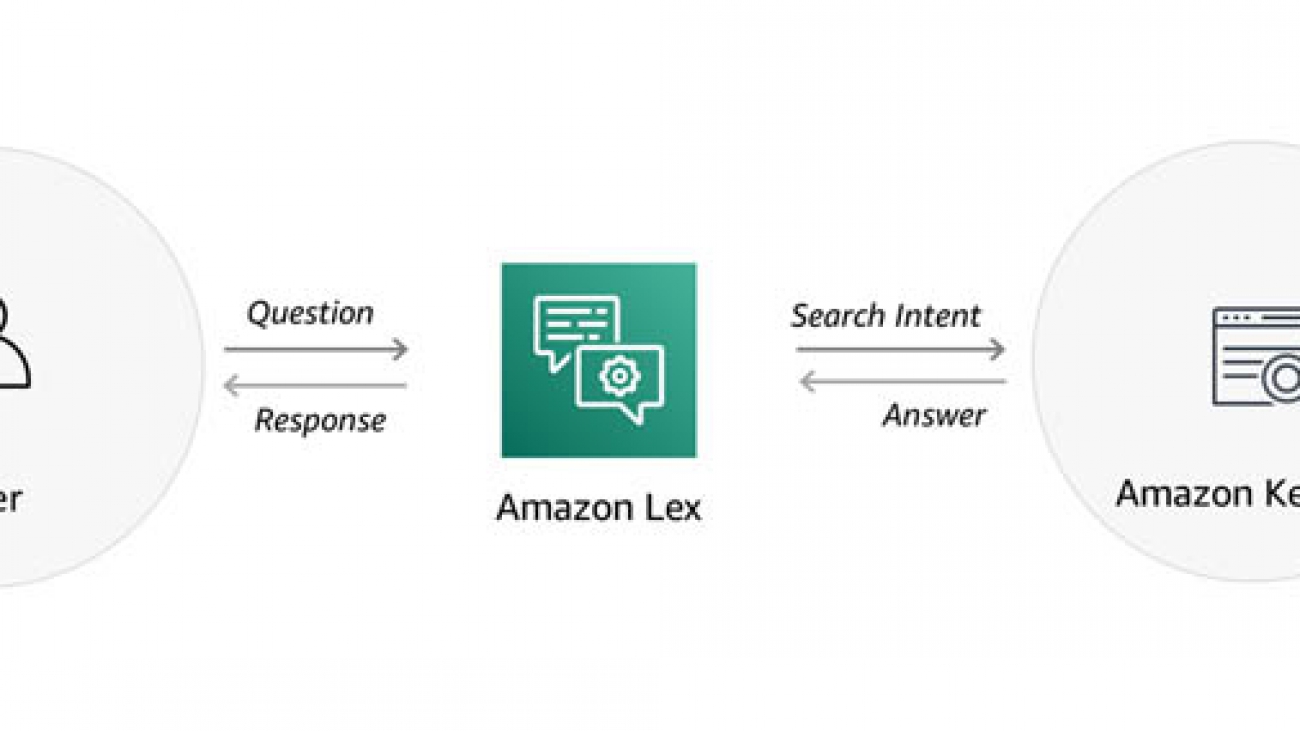
Integrate Amazon Kendra and Amazon Lex using a search intent
Customer service conversations typically revolve around one or more topics and contain related questions. Answering these questions seamlessly is essential for a good conversational experience. For example, as part of a car rental reservation, you have queries such as, “What’s the charge for an additional driver?” or, “Do you have car seats for kids?” Starting today, you can use a search intent in your Amazon Lex bots to integrate with Amazon Kendra, so your bots can surface answers from Kendra.
Amazon Kendra was recently made generally available to all AWS customers, with exciting new features. Amazon Kendra provides you with a highly accurate and easy-to-use enterprise search service powered by machine learning. It offers a more intuitive way to search—using natural language—and returns more accurate answers, so your end-users can discover information stored within your organization’s vast amount of content.
We previously described how you can add an AWS Lambda function in an Amazon Lex bot to integrate with Kendra. For more information, see Smarter FAQ bots with Amazon Kendra. With this approach, you need to write and maintain integration code, and any updates to the configuration require updating this code. Now you can can add a search intent to get the answers you’re looking for from FAQ documents. You simply define the search index parameters in the intent as part of the bot definition. The bot queries the Amazon Kendra search index during the interaction if the user input doesn’t match any of the other configured intents. The search query responses are populated with request attributes that the bot can use in its response. You don’t have to write any Lambda code. The integration is simple, and you can seamlessly deliver natural language answers from Amazon Kendra in your Amazon Lex conversations.
This post shows how you can integrate an Amazon Lex bot with Amazon Kendra using a search intent, so you can quickly build a bot to provide answers in a conversation. The following diagram illustrates this solution.
Building a Lex bot
We will use the same conversation from the previous post to model a bot conversation:
User: Where’s the IT Help Desk?
Agent: 2nd floor; room 201 (two rights after you get out of the elevators).
User: Can I come in at noon?
Agent: Sure. What’s the nature of your problem?
User: I have a cracked laptop screen.
Agent: For verification purposes, can I get the last four digits of your employee ID?
User: 1234.
Agent: Got it, we’ll see you then to take a look at your screen.
User: How long does it take to fix a screen?
Agent: Laptop screen repairs typically take 4 hours.
User: What do I need to bring with me for a screen repair?
Agent: For a laptop screen repair, please bring your employee badge, laptop, and VPN fob.
User: How do I access my documents while my laptop is being repaired?
Agent: You can use Amazon Workdocs to access your documents.
User: Can I use WorkDocs on my tablet?
Agent: Yes. Users can access Amazon WorkDocs using free applications for iPad, Kindle Fire, and Android tablets that you can download from iTunes, Amazon Appstore for Android, and Google Play. Users can also access Amazon WorkDocs using the web browser on any mobile device.
User: When does the help desk close?
Agent: Our hours are from 11 AM to 2 PM.
User: Is there a coffee shop nearby?
Agent: There is one on the third floor and it’s open from 8 AM to 4 PM daily.
The first step is to build an Amazon Lex bot with intents to book an appointment and check appointment status. The MakeAppointment intent elicits the information required to make an appointment, such as the date, time, employee ID, and the nature of the issue. The CheckAppointmentStatus intent provides the status of the appointment. When a user asks a question that the Lex bot can’t answer with these intents, it uses the built-in KendraSearchIntent intent to connect to Amazon Kendra to search for an appropriate answer.
Deploying the sample bot
To create the sample bot, complete the following steps. This creates an Amazon Lex bot called help_desk_bot and a Lambda fulfillment function called help_desk_bot_handler.
- Download the Amazon Lex definition and Lambda code.
- In the AWS Lambda console, choose Create function.
- Enter the function name
help_desk_bot_handler. - Choose the latest Python runtime (for example, Python 3.8).
- For Permissions, choose Create a new role with basic Lambda permissions.
- Choose Create function.
- Once your new Lambda function is available, in the Function code section, choose Actions, choose Upload a .zip file, choose Upload, and select the
help_desk_bot_lambda_handler.zipfile that you downloaded. - Choose Save.
- On the Amazon Lex console, choose Actions, and then Import.
- Choose the file
help_desk_bot.zipthat you downloaded, and choose Import. - On the Amazon Lex console, choose the bot
help_desk_bot. - For each of the intents, choose AWS Lambda function in the Fulfillment section, and select the
help_desk_bot_handlerfunction in the dropdown list. If you are prompted “You are about to give Amazon Lex permission to invoke your Lambda Function”, choose OK. - When all the intents are updated, choose Build.
At this point, you should have a working bot that is not yet connected to Amazon Kendra.
Creating an Amazon Kendra index
You’re now ready to create an Amazon Kendra index for your documents and FAQ. Complete the following steps:
- On the Amazon Kendra console, choose Launch Amazon Kendra.
- If you have existing Amazon Kendra indexes, choose Create index.
- For Index name, enter a name, such as
it-helpdesk. - For Description, enter an optional description, such as
IT Help Desk FAQs. - For IAM role, choose Create a new role to create a role to allow Amazon Kendra to access Amazon CloudWatch Logs.
- For Role name, enter a name, such as
cloudwatch-logs. Kendra will prefix the name withAmazonKendraand the AWS region. - Choose Next.

- For Provisioning editions, choose Developer edition.

- Choose Create.
Adding your FAQ content
While Amazon Kendra creates your new index, upload your content to an Amazon Simple Storage Service (Amazon S3) bucket.
- On the Amazon S3 console, create a new bucket, such as
kendra-it-helpdesk-docs-<your-account#>. - Keep the default settings and choose Create bucket.
- Download the following sample files and upload them to your new S3 bucket:
When the index creation is complete, you can add your FAQ content.
- On the Amazon Kendra console, choose your index, then choose FAQs, and Add FAQ.
- For FAQ name, enter a name, such as
it-helpdesk-faq. - For Description, enter an optional description, such as
FAQ for the IT Help Desk. - For S3, browse Amazon S3 to find your bucket, and choose help-desk-faq.csv.
- For IAM role, choose Create a new role to allow Amazon Kendra to access your S3 bucket.
- For Role name, enter a name, such as
s3-access. Kendra will prefix your role name withAmazonKendra-. - Choose Add.

- Stay on the page while Amazon Kendra creates your FAQ.
- When the FAQ is complete, choose Add FAQ to add another FAQ.
- For FAQ name, enter a name, such as
workdocs-faq. - For Description, enter a description, such as
FAQ for Amazon WorkDocsmobile and web access. - For S3, browse Amazon S3 to find your bucket, and choose workdocs-faq.csv.
- For IAM role, choose the same role you created in step 9.
- Choose Add.

After you create your FAQs, you can try some Kendra searches by choosing Search console. For example:
- When is the help desk open?
- When does the help desk close?
- Where is the help desk?
- Can I access WorkDocs from my phone?
Adding a search intent
Now that you have a working Amazon Kendra index, you need to add a search intent.
- On the Amazon Lex console, choose
help_desk_bot. - Under Intents, choose the + icon next to add an intent.
- Choose Search existing intents.
- Under Built-in intents, choose KendraSearchIntent.
- Enter a name for your intent, such as
help_desk_kendra_search. - Choose Add.
- Under Amazon Kendra query, choose the index you created (
it-helpdesk). - For IAM role, choose Add Amazon Kendra permissions.
- For Fulfillment, leave the default value Return parameters to client selected.

- For Response, choose Message, enter the following message value and choose + to add it:
((x-amz-lex:kendra-search-response-question_answer-answer-1)) - Choose Save intent.
- Choose Build.
The message value you used in step 10 is a request attribute, which is set automatically by the Amazon Kendra search intent. This response is only selected if Kendra surfaces an answer. For more information on request attributes, see the AMAZON.KendraSearchIntent documentation.
Your bot can now execute Amazon Kendra queries. You can test this on the Amazon Lex console. For example, you can try the sample conversation from the beginning of this post.
Deploying on a Slack channel
You can put this solution in a real chat environment, such as Slack, so that users can easily get information. To create a Slack channel association with your bot, complete the following steps:
- On the Amazon Lex console, choose Settings.
- Choose Publish.
- For Create an alias, enter an alias name, such as
test. - Choose Publish.
- When your alias is published, choose the Channels
- Under Channels, choose Slack.
- Enter a Channel Name, such as
slack_help_desk_bot. - For Channel Description, add an optional description.
- From the KMS Key drop-down menu, leave aws/lex selected.
- For Alias, choose
test. - Provide the Client Id, Client Secret, and Verification Token for your Slack application.

- Choose Activate to generate the OAuth URL and Postback URL.
Use the OAuth URL and Postback URL on the Slack application portal to complete the integration. For more information about setting up a Slack application and integrating with Amazon Lex, see Integrating an Amazon Lex Bot with Slack.
Conclusion
This post demonstrates how to integrate Amazon Lex and Amazon Kendra using a search intent. Amazon Kendra can extract specific answers from unstructured data. No pre-training is required; you simply point Amazon Kendra at your content, and it provides specific answers to natural language queries. For more information about incorporating these techniques into your bots, please see the AMAZON.KendraSearchIntent documentation.
About the authors
 Brian Yost is a Senior Consultant with the AWS Professional Services Conversational AI team. In his spare time, he enjoys mountain biking, home brewing, and tinkering with technology.
Brian Yost is a Senior Consultant with the AWS Professional Services Conversational AI team. In his spare time, he enjoys mountain biking, home brewing, and tinkering with technology.
 As a Product Manager on the Amazon Lex team, Harshal Pimpalkhute spends his time trying to get machines to engage (nicely) with humans.
As a Product Manager on the Amazon Lex team, Harshal Pimpalkhute spends his time trying to get machines to engage (nicely) with humans.
What jumps out in a photo changes the longer we look
What seizes your attention at first glance might change with a closer look. That elephant dressed in red wallpaper might initially grab your eye until your gaze moves to the woman on the living room couch and the surprising realization that the pair appear to be sharing a quiet moment together.
In a study being presented at the virtual Computer Vision and Pattern Recognition conference this week, researchers show that our attention moves in distinctive ways the longer we stare at an image, and that these viewing patterns can be replicated by artificial intelligence models. The work suggests immediate ways of improving how visual content is teased and eventually displayed online. For example, an automated cropping tool might zoom in on the elephant for a thumbnail preview or zoom out to include the intriguing details that become visible once a reader clicks on the story.
“In the real world, we look at the scenes around us and our attention also moves,” says Anelise Newman, the study’s co-lead author and a master’s student at MIT. “What captures our interest over time varies.” The study’s senior authors are Zoya Bylinskii PhD ’18, a research scientist at Adobe Research, and Aude Oliva, co-director of the MIT Quest for Intelligence and a senior research scientist at MIT’s Computer Science and Artificial Intelligence Laboratory.
What researchers know about saliency, and how humans perceive images, comes from experiments in which participants are shown pictures for a fixed period of time. But in the real world, human attention often shifts abruptly. To simulate this variability, the researchers used a crowdsourcing user interface called CodeCharts to show participants photos at three durations — half a second, 3 seconds, and 5 seconds — in a set of online experiments.
When the image disappeared, participants were asked to report where they had last looked by typing in a three-digit code on a gridded map corresponding to the image. In the end, the researchers were able to gather heat maps of where in a given image participants had collectively focused their gaze at different moments in time.
At the split-second interval, viewers focused on faces or a visually dominant animal or object. By 3 seconds, their gaze had shifted to action-oriented features, like a dog on a leash, an archery target, or an airborne frisbee. At 5 seconds, their gaze either shot back, boomerang-like, to the main subject, or it lingered on the suggestive details.
“We were surprised at just how consistent these viewing patterns were at different durations,” says the study’s other lead author, Camilo Fosco, a PhD student at MIT.
With real-world data in hand, the researchers next trained a deep learning model to predict the focal points of images it had never seen before, at different viewing durations. To reduce the size of their model, they included a recurrent module that works on compressed representations of the input image, mimicking the human gaze as it explores an image at varying durations. When tested, their model outperformed the state of the art at predicting saliency across viewing durations.
The model has potential applications for editing and rendering compressed images and even improving the accuracy of automated image captioning. In addition to guiding an editing tool to crop an image for shorter or longer viewing durations, it could prioritize which elements in a compressed image to render first for viewers. By clearing away the visual clutter in a scene, it could improve the overall accuracy of current photo-captioning techniques. It could also generate captions for images meant for split-second viewing only.
“The content that you consider most important depends on the time you have to look at it,” says Bylinskii. “If you see the full image at once, you may not have time to absorb it all.”
As more images and videos are shared online, the need for better tools to find and make sense of relevant content is growing. Research on human attention offers insights for technologists. Just as computers and camera-equipped mobile phones helped create the data overload, they are also giving researchers new platforms for studying human attention and designing better tools to help us cut through the noise.
In a related study accepted to the ACM Conference on Human Factors in Computing Systems, researchers outline the relative benefits of four web-based user interfaces, including CodeCharts, for gathering human attention data at scale. All four tools capture attention without relying on traditional eye-tracking hardware in a lab, either by collecting self-reported gaze data, as CodeCharts does, or by recording where subjects click their mouse or zoom in on an image.
“There’s no one-size-fits-all interface that works for all use cases, and our paper focuses on teasing apart these trade-offs,” says Newman, lead author of the study.
By making it faster and cheaper to gather human attention data, the platforms may help to generate new knowledge on human vision and cognition. “The more we learn about how humans see and understand the world, the more we can build these insights into our AI tools to make them more useful,” says Oliva.
Other authors of the CVPR paper are Pat Sukhum, Yun Bin Zhang, and Nanxuan Zhao. The research was supported by the Vannevar Bush Faculty Fellowship program, an Ignite grant from the SystemsThatLearn@CSAIL, and cloud computing services from MIT Quest.