New end-to-end approach to zero-shot video classification dramatically outperforms predecessors.Read More
Learning the ropes and throwing lifelines
In March, as her friends and neighbors were scrambling to pack up and leave campus due to the Covid-19 pandemic, Geeticka Chauhan found her world upended in yet another way. Just weeks earlier, she had been elected council president of MIT’s largest graduate residence, Sidney-Pacific. Suddenly the fourth-year PhD student was plunged into rounds of emergency meetings with MIT administrators.
From her apartment in Sidney-Pacific, where she has stayed put due to travel restrictions in her home country of India, Chauhan is still learning the ropes of her new position. With others, she has been busy preparing to meet the future challenge of safely redensifying the living space of more than 1,000 people: how to regulate high-density common areas, handle noise complaints as people spend more time in their rooms, and care for the mental and physical well-being of a community that can only congregate virtually. “It’s just such a crazy time,” she says.
She’s prepared for the challenge. During her time at MIT, while pursuing her research using artificial intelligence to understand human language, Chauhan has worked to strengthen the bonds of her community in numerous ways, often drawing on her experience as an international student to do so.
Adventures in brunching
When Chauhan first came to MIT in 2017, she quickly fell in love with Sidney-Pacific’s thriving and freewheeling “helper culture.” “These are all researchers, but they’re maybe making brownies, doing crazy experiments that they would do in lab, except in the kitchen,” she says. “That was my first introduction to the MIT spirit.”
Next thing she knew, she was teaching Budokon yoga, mashing chickpeas into guacamole, and immersing herself in the complex operations of a monthly brunch attended by hundreds of graduate students, many of whom came to MIT from outside the U.S. In addition to the genuine thrill of cracking 300 eggs in 30 minutes, working on the brunches kept her grounded in a place thousands of miles from her home in New Delhi. “It gave me a sense of community and made me feel like I have a family here,” she says.
Chauhan has found additional ways to address the particular difficulties that international students face. As a member of the Presidential Advisory Council this year, she gathered international student testimonies on visa difficulties and presented them to MIT’s president and the director of the International Students Office. And when a friend from mainland China had to self-quarantine on Valentine’s Day, Chauhan knew she had to act. As brunch chair, she organized food delivery, complete with chocolates and notes, for Sidney-Pacific residents who couldn’t make it to the monthly event. “Initially when you come back to the U.S. from your home country, you really miss your family,” she says. “I thought self-quarantining students should feel their MIT community cares for them.”
Culture shock
Growing up in New Delhi, math was initially one of her weaknesses, Chauhan says, and she was scared and confused by her early introduction to coding. Her mother and grandmother, with stern kindness and chocolates, encouraged her to face these fears. “My mom used to teach me that with hard work, you can make your biggest weakness your biggest strength,” she explains. She soon set her sights on a future in computer science.
However, as Chauhan found her life increasingly dominated by the high-pressure culture of preparing for college, she began to long for a feeling of wholeness, and for the person she left behind on the way. “I used to have a lot of artistic interests but didn’t get to explore them,” she says. She quit her weekend engineering classes, enrolled in a black and white photography class, and after learning about the extracurricular options at American universities, landed a full scholarship to attend Florida International University.
It was a culture shock. She didn’t know many Indian students in Miami and felt herself struggling to reconcile the individualistic mindset around her with the community and family-centered life at home. She says the people she met got her through, including Mark Finlayson, a professor studying the science of narrative from the viewpoint of natural language processing. Under Finlayson’s guidance she developed a fascination with the way AI techniques could be used to better understand the patterns and structures in human narratives. She learned that studying AI wasn’t just a way of imitating human thinking, but rather an approach for deepening our understanding of ourselves as reflected by our language. “It was due to Mark’s mentorship that I got involved in research” and applied to MIT, she says.
The holistic researcher
Chauan now works in the Clinical Decision Making Group led by Peter Szolovits at the Computer Science and Artificial Intelligence Laboratory, where she is focusing on the ways natural language processing can address health care problems. For her master’s project, she worked on the problem of relation extraction and built a tool to digest clinical literature that would, for example, help pharamacologists easily assess negative drug interactions. Now, she’s finishing up a project integrating visual analysis of chest radiographs and textual analysis of radiology reports for quantifying pulmonary edema, to help clinicians manage the fluid status of their patients who have suffered acute heart failure.
“In routine clinical practice, patient care is interweaved with a lot of bureaucratic work,” she says. “The goal of my lab is to assist with clinical decision making and give clinicians the full freedom and time to devote to patient care.”
It’s an exciting moment for Chauhan, who recently submitted a paper she co-first authored with another grad student, and is starting to think about her next project: interpretability, or how to elucidate a decision-making model’s “thought process” by highlighting the data from which it draws its conclusions. She continues to find the intersection of computer vision and natural language processing an exciting area of research. But there have been challenges along the way.
After the initial flurry of excitement her first year, personal and faculty expectations of students’ independence and publishing success grew, and she began to experience uncertainty and imposter syndrome. “I didn’t know what I was capable of,” she says. “That initial period of convincing yourself that you belong is difficult. I am fortunate to have a supportive advisor that understands that.”
Finally, one of her first-year projects showed promise, and she came up with a master’s thesis plan in a month and submitted the project that semester. To get through, she says, she drew on her “survival skills”: allowing herself to be a full person beyond her work as a researcher so that one setback didn’t become a sense of complete failure. For Chauhan, that meant working as a teaching assistant, drawing henna designs, singing, enjoying yoga, and staying involved in student government. “I used to try to separate that part of myself with my work side,” she says. “I needed to give myself some space to learn and grow, rather than compare myself to others.”
Citing a study showing that women are more likely to drop out of STEM disciplines when they receive a B grade in a challenging course, Chauhan says she wishes she could tell her younger self not to compare herself with an ideal version of herself. Dismantling imposter syndrome requires an understanding that qualification and success can come from a broad range of experiences, she says: It’s about “seeing people for who they are holistically, rather than what is seen on the resume.”

Recent Advances in Google Translate
Posted by Isaac Caswell and Bowen Liang, Software Engineers, Google Research
Advances in machine learning (ML) have driven improvements to automated translation, including the GNMT neural translation model introduced in Translate in 2016, that have enabled great improvements to the quality of translation for over 100 languages. Nevertheless, state-of-the-art systems lag significantly behind human performance in all but the most specific translation tasks. And while the research community has developed techniques that are successful for high-resource languages like Spanish and German, for which there exist copious amounts of training data, performance on low-resource languages, like Yoruba or Malayalam, still leaves much to be desired. Many techniques have demonstrated significant gains for low-resource languages in controlled research settings (e.g., the WMT Evaluation Campaign), however these results on smaller, publicly available datasets may not easily transition to large, web-crawled datasets.
In this post, we share some recent progress we have made in translation quality for supported languages, especially for those that are low-resource, by synthesizing and expanding a variety of recent advances, and demonstrate how they can be applied at scale to noisy, web-mined data. These techniques span improvements to model architecture and training, improved treatment of noise in datasets, increased multilingual transfer learning through M4 modeling, and use of monolingual data. The quality improvements, which averaged +5 BLEU score over all 100+ languages, are visualized below.
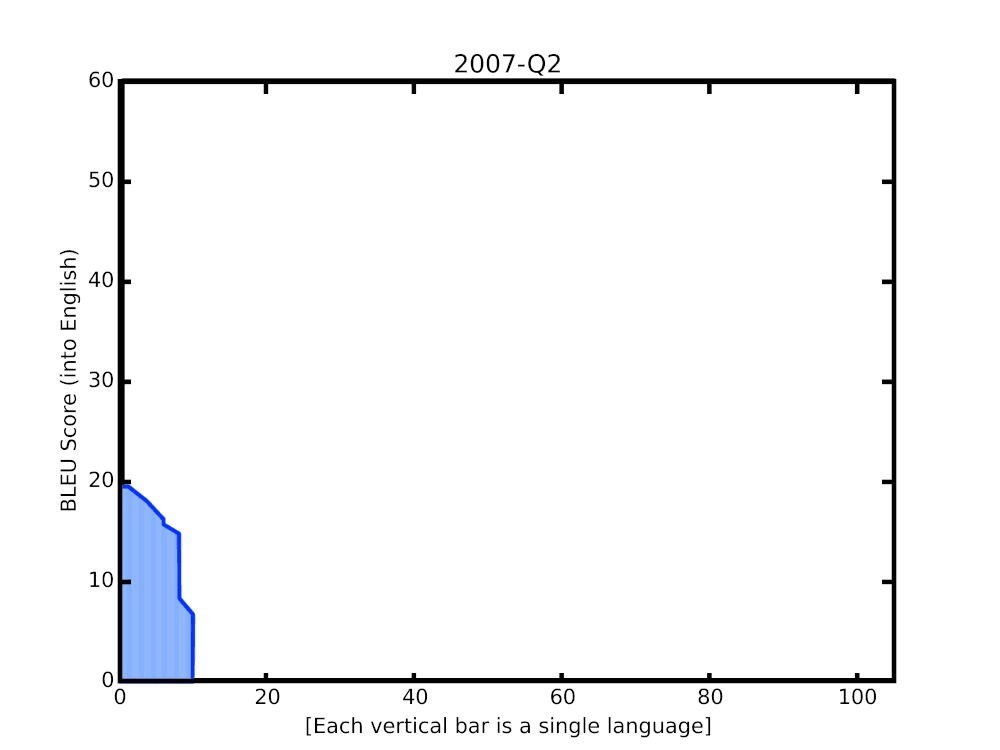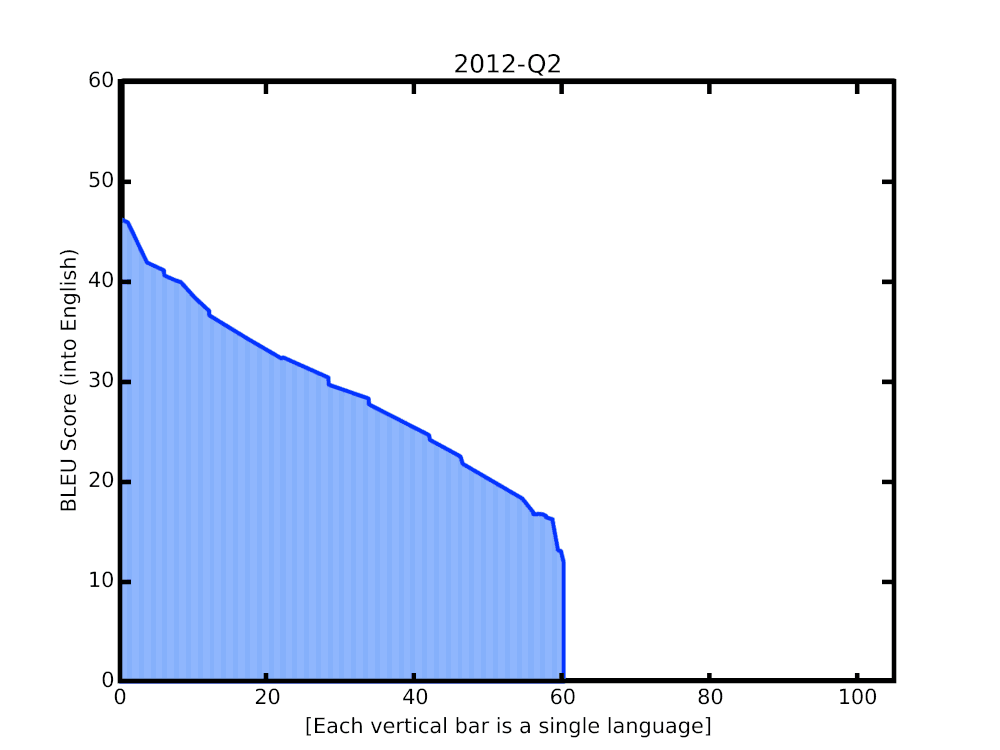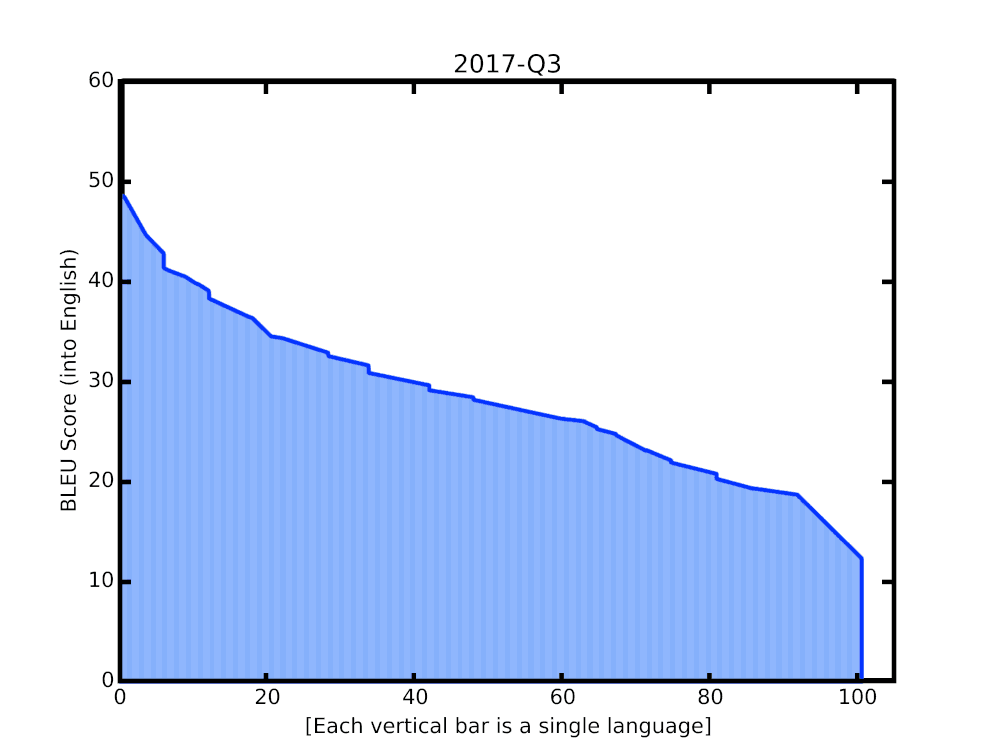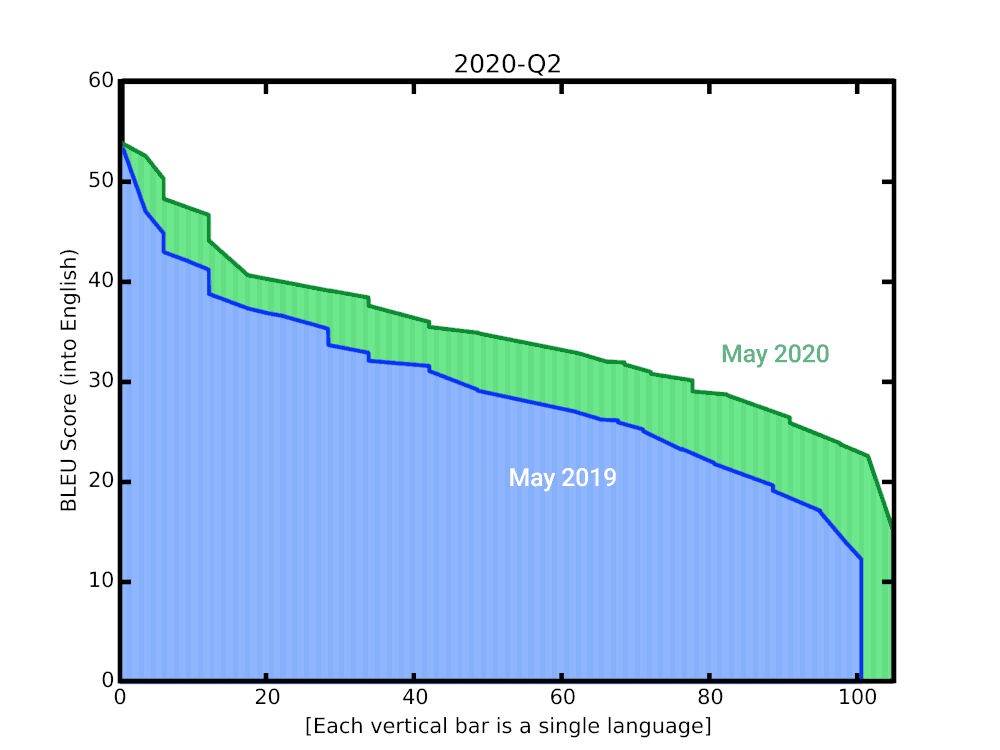 |
| BLEU score of Google Translate models since shortly after its inception in 2006. The improvements since the implementation of the new techniques over the last year are highlighted at the end of the animation. |
Advances for Both High- and Low-Resource Languages
Hybrid Model Architecture: Four years ago we introduced the RNN-based GNMT model, which yielded large quality improvements and enabled Translate to cover many more languages. Following our work decoupling different aspects of model performance, we have replaced the original GNMT system, instead training models with a transformer encoder and an RNN decoder, implemented in Lingvo (a TensorFlow framework). Transformer models have been demonstrated to be generally more effective at machine translation than RNN models, but our work suggested that most of these quality gains were from the transformer encoder, and that the transformer decoder was not significantly better than the RNN decoder. Since the RNN decoder is much faster at inference time, we applied a variety of optimizations before coupling it with the transformer encoder. The resulting hybrid models are higher-quality, more stable in training, and exhibit lower latency.
Web Crawl: Neural Machine Translation (NMT) models are trained using examples of translated sentences and documents, which are typically collected from the public web. Compared to phrase-based machine translation, NMT has been found to be more sensitive to data quality. As such, we replaced the previous data collection system with a new data miner that focuses more on precision than recall, which allows the collection of higher quality training data from the public web. Additionally, we switched the web crawler from a dictionary-based model to an embedding based model for 14 large language pairs, which increased the number of sentences collected by an average of 29 percent, without loss of precision.
Modeling Data Noise: Data with significant noise is not only redundant but also lowers the quality of models trained on it. In order to address data noise, we used our results on denoising NMT training to assign a score to every training example using preliminary models trained on noisy data and fine-tuned on clean data. We then treat training as a curriculum learning problem — the models start out training on all data, and then gradually train on smaller and cleaner subsets.
Advances That Benefited Low-Resource Languages in Particular
Back-Translation: Widely adopted in state-of-the-art machine translation systems, back-translation is especially helpful for low-resource languages, where parallel data is scarce. This technique augments parallel training data (where each sentence in one language is paired with its translation) with synthetic parallel data, where the sentences in one language are written by a human, but their translations have been generated by a neural translation model. By incorporating back-translation into Google Translate, we can make use of the more abundant monolingual text data for low-resource languages on the web for training our models. This is especially helpful in increasing fluency of model output, which is an area in which low-resource translation models underperform.
M4 Modeling: A technique that has been especially helpful for low-resource languages has been M4, which uses a single, giant model to translate between all languages and English. This allows for transfer learning at a massive scale. As an example, a lower-resource language like Yiddish has the benefit of co-training with a wide array of other related Germanic languages (e.g., German, Dutch, Danish, etc.), as well as almost a hundred other languages that may not share a known linguistic connection, but may provide useful signal to the model.
Judging Translation Quality
A popular metric for automatic quality evaluation of machine translation systems is the BLEU score, which is based on the similarity between a system’s translation and reference translations that were generated by people. With these latest updates, we see an average BLEU gain of +5 points over the previous GNMT models, with the 50 lowest-resource languages seeing an average gain of +7 BLEU. This improvement is comparable to the gain observed four years ago when transitioning from phrase-based translation to NMT.
Although BLEU score is a well-known approximate measure, it is known to have various pitfalls for systems that are already high-quality. For instance, several works have demonstrated how the BLEU score can be biased by translationese effects on the source side or target side, a phenomenon where translated text can sound awkward, containing attributes (like word order) from the source language. For this reason, we performed human side-by-side evaluations on all new models, which confirmed the gains in BLEU.
In addition to general quality improvements, the new models show increased robustness to machine translation hallucination, a phenomenon in which models produce strange “translations” when given nonsense input. This is a common problem for models that have been trained on small amounts of data, and affects many low-resource languages. For example, when given the string of Telugu characters “ష ష ష ష ష ష ష ష ష ష ష ష ష ష ష”, the old model produced the nonsensical output “Shenzhen Shenzhen Shaw International Airport (SSH)”, seemingly trying to make sense of the sounds, whereas the new model correctly learns to transliterate this as “Sh sh sh sh sh sh sh sh sh sh sh sh sh sh sh sh sh”.
Conclusion
Although these are impressive strides forward for a machine, one must remember that, especially for low-resource languages, automatic translation quality is far from perfect. These models still fall prey to typical machine translation errors, including poor performance on particular genres of subject matter (“domains”), conflating different dialects of a language, producing overly literal translations, and poor performance on informal and spoken language.
Nonetheless, with this update, we are proud to provide automatic translations that are relatively coherent, even for the lowest-resource of the 108 supported languages. We are grateful for the research that has enabled this from the active community of machine translation researchers in academia and industry.
Acknowledgements
This effort is built on contributions from Tao Yu, Ali Dabirmoghaddam, Klaus Macherey, Pidong Wang, Ye Tian, Jeff Klingner, Jumpei Takeuchi, Yuichiro Sawai, Hideto Kazawa, Apu Shah, Manisha Jain, Keith Stevens, Fangxiaoyu Feng, Chao Tian, John Richardson, Rajat Tibrewal, Orhan Firat, Mia Chen, Ankur Bapna, Naveen Arivazhagan, Dmitry Lepikhin, Wei Wang, Wolfgang Macherey, Katrin Tomanek, Qin Gao, Mengmeng Niu, and Macduff Hughes.

Engineers put tens of thousands of artificial brain synapses on a single chip
MIT engineers have designed a “brain-on-a-chip,” smaller than a piece of confetti, that is made from tens of thousands of artificial brain synapses known as memristors — silicon-based components that mimic the information-transmitting synapses in the human brain.
The researchers borrowed from principles of metallurgy to fabricate each memristor from alloys of silver and copper, along with silicon. When they ran the chip through several visual tasks, the chip was able to “remember” stored images and reproduce them many times over, in versions that were crisper and cleaner compared with existing memristor designs made with unalloyed elements.
Their results, published today in the journal Nature Nanotechnology, demonstrate a promising new memristor design for neuromorphic devices — electronics that are based on a new type of circuit that processes information in a way that mimics the brain’s neural architecture. Such brain-inspired circuits could be built into small, portable devices, and would carry out complex computational tasks that only today’s supercomputers can handle.
“So far, artificial synapse networks exist as software. We’re trying to build real neural network hardware for portable artificial intelligence systems,” says Jeehwan Kim, associate professor of mechanical engineering at MIT. “Imagine connecting a neuromorphic device to a camera on your car, and having it recognize lights and objects and make a decision immediately, without having to connect to the internet. We hope to use energy-efficient memristors to do those tasks on-site, in real-time.”
Wandering ions
Memristors, or memory transistors, are an essential element in neuromorphic computing. In a neuromorphic device, a memristor would serve as the transistor in a circuit, though its workings would more closely resemble a brain synapse — the junction between two neurons. The synapse receives signals from one neuron, in the form of ions, and sends a corresponding signal to the next neuron.
A transistor in a conventional circuit transmits information by switching between one of only two values, 0 and 1, and doing so only when the signal it receives, in the form of an electric current, is of a particular strength. In contrast, a memristor would work along a gradient, much like a synapse in the brain. The signal it produces would vary depending on the strength of the signal that it receives. This would enable a single memristor to have many values, and therefore carry out a far wider range of operations than binary transistors.
Like a brain synapse, a memristor would also be able to “remember” the value associated with a given current strength, and produce the exact same signal the next time it receives a similar current. This could ensure that the answer to a complex equation, or the visual classification of an object, is reliable — a feat that normally involves multiple transistors and capacitors.
Ultimately, scientists envision that memristors would require far less chip real estate than conventional transistors, enabling powerful, portable computing devices that do not rely on supercomputers, or even connections to the Internet.
Existing memristor designs, however, are limited in their performance. A single memristor is made of a positive and negative electrode, separated by a “switching medium,” or space between the electrodes. When a voltage is applied to one electrode, ions from that electrode flow through the medium, forming a “conduction channel” to the other electrode. The received ions make up the electrical signal that the memristor transmits through the circuit. The size of the ion channel (and the signal that the memristor ultimately produces) should be proportional to the strength of the stimulating voltage.
Kim says that existing memristor designs work pretty well in cases where voltage stimulates a large conduction channel, or a heavy flow of ions from one electrode to the other. But these designs are less reliable when memristors need to generate subtler signals, via thinner conduction channels.
The thinner a conduction channel, and the lighter the flow of ions from one electrode to the other, the harder it is for individual ions to stay together. Instead, they tend to wander from the group, disbanding within the medium. As a result, it’s difficult for the receiving electrode to reliably capture the same number of ions, and therefore transmit the same signal, when stimulated with a certain low range of current.
Borrowing from metallurgy
Kim and his colleagues found a way around this limitation by borrowing a technique from metallurgy, the science of melding metals into alloys and studying their combined properties.
“Traditionally, metallurgists try to add different atoms into a bulk matrix to strengthen materials, and we thought, why not tweak the atomic interactions in our memristor, and add some alloying element to control the movement of ions in our medium,” Kim says.
Engineers typically use silver as the material for a memristor’s positive electrode. Kim’s team looked through the literature to find an element that they could combine with silver to effectively hold silver ions together, while allowing them to flow quickly through to the other electrode.
The team landed on copper as the ideal alloying element, as it is able to bind both with silver, and with silicon.
“It acts as a sort of bridge, and stabilizes the silver-silicon interface,” Kim says.
To make memristors using their new alloy, the group first fabricated a negative electrode out of silicon, then made a positive electrode by depositing a slight amount of copper, followed by a layer of silver. They sandwiched the two electrodes around an amorphous silicon medium. In this way, they patterned a millimeter-square silicon chip with tens of thousands of memristors.
As a first test of the chip, they recreated a gray-scale image of the Captain America shield. They equated each pixel in the image to a corresponding memristor in the chip. They then modulated the conductance of each memristor that was relative in strength to the color in the corresponding pixel.
The chip produced the same crisp image of the shield, and was able to “remember” the image and reproduce it many times, compared with chips made of other materials.
The team also ran the chip through an image processing task, programming the memristors to alter an image, in this case of MIT’s Killian Court, in several specific ways, including sharpening and blurring the original image. Again, their design produced the reprogrammed images more reliably than existing memristor designs.
“We’re using artificial synapses to do real inference tests,” Kim says. “We would like to develop this technology further to have larger-scale arrays to do image recognition tasks. And some day, you might be able to carry around artificial brains to do these kinds of tasks, without connecting to supercomputers, the internet, or the cloud.”
This research was funded, in part, by the MIT Research Support Committee funds, the MIT-IBM Watson AI Lab, Samsung Global Research Laboratory, and the National Science Foundation.
Introducing Neuropod, Uber ATG’s Open Source Deep Learning Inference Engine
At Uber Advanced Technologies Group (ATG), we leverage deep learning to provide safe and reliable self-driving technology. Using deep learning, we can build and train models to handle tasks such as processing sensor input, identifying objects, and predicting where …
The post Introducing Neuropod, Uber ATG’s Open Source Deep Learning Inference Engine appeared first on Uber Engineering Blog.
Announcing the winners of the Measuring Economic Impact in the Digital Economy research awards
In January 2020, Facebook launched a request for research proposals that address the economic impact of digital technologies. For this RFP, we pledged $1 million in research award funding as part of Facebook’s continued goal of supporting independent research that helps us better understand and measure the impact of the digital economy. Today, we are announcing the winners of these research awards.
“The survival of small and medium-sized businesses hinges on their being able to operate and reach as many customers as possible during the COVID-19 pandemic,” says Arturo Gonzalez, Director of Advocacy and Research at Facebook. “Part of the solution is being online to the fullest extent possible.
“Facebook believes that research and the academic community play an important role in analyzing the impact of digital tools for small and medium-sized businesses. Our goal for this RFP was to foster further innovation in academia in this space, to accelerate the production of high-quality, independent, and data-driven research that, when all is said and done, advances the goal of helping small businesses.”
We were especially interested in proposals that addressed the economic consequences and implications of developing digital technologies for small businesses. We were additionally interested in research projects in the following topics, although we encouraged creative approaches beyond these areas:
- A taxonomy of the digital economy, including subsectors within the digital economy
- The demarcations between the analog and digital economies
- Shortcomings (if any) of national accounts and other official statistics of GDP
- Theoretical models of economic impact of the digital economy
- How to obtain causal impacts and/or identify biases found in noncausal estimates
- Incorporate the feedback effects due to the multisided nature of platforms
- What needs to be solved for in order to estimate the model
- Empirical application of theoretical models of causal economic impact
- The biases (if any) present in reduced-form empirical model
- Limitations of the model and results, including in scope (geographic, size of business), due to data availability or other issues
We received 57 proposals from 16 countries. Thank you to all the researchers who took the time to submit a proposal, and congratulations to the award recipients. For more information about areas of interest, eligibility, requirements, and more, visit the application page.
Research award winners
Digital economy and regional inequalities in the UK
Raquel Ortega-Artiles, Emmanouil Tranos, Giulia Occhini, Levi Wolf, Tasos Kitsos (University of Birmingham)
The expansion of the internet and economic growth worldwide
Paul Raschky, Klaus Ackermann, Simon Angus (Monash University)
GDP-B: A new well-being metric in the era of the digital economy
Erik Brynjolfsson, Avinash Collis, Jae Joon Lee (Massachusetts Institute of Technology)
The impact of online listings on small business performance
Abhishek Nagaraj, Gauri Subramani, Michael Luca (University of California, Berkeley)
Measuring the impact of the digital economy in Canada
Sarah Doyle, David Wolfe (Ryerson University)
Modeling and measuring the economic impacts of digital platform innovation
Johannes M. Bauer, Steven S. Wildman, Tiago Sousa Prado (Michigan State University)
Social sharing and the growth of small businesses: Measurement and strategy
Tianshu Sun (University of Southern California)
The post Announcing the winners of the Measuring Economic Impact in the Digital Economy research awards appeared first on Facebook Research.
If transistors can’t get smaller, then coders have to get smarter
In 1965, Intel co-founder Gordon Moore predicted that the number of transistors that could fit on a computer chip would grow exponentially — and they did, doubling about every two years. For half a century, Moore’s Law has endured: Computers have gotten smaller, faster, cheaper, and more efficient, enabling the rapid worldwide adoption of PCs, smartphones, high-speed internet, and more.
This miniaturization trend has led to silicon chips today that have almost unimaginably small circuitry. Transistors, the tiny switches that implement computer microprocessors, are so small that 1,000 of them laid end-to-end are no wider than a human hair. And for a long time, the smaller the transistors were, the faster they could switch. But today, we’re approaching the limit of how small transistors can get. As a result, over the past decade researchers have been scratching their heads to find other ways to improve performance so that the computer industry can continue to innovate.
While we wait for the maturation of new computing technologies like quantum, carbon nanotubes, or photonics (which may take a while), other approaches will be needed to get performance as Moore’s Law comes to an end. In a recent journal article published in Science, a team from MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL) identifies three key areas to prioritize to continue to deliver computing speed-ups: better software, new algorithms, and more streamlined hardware.
Senior author Charles E. Leiserson says that the performance benefits from miniaturization have been so great that, for decades, programmers have been able to prioritize making code-writing easier rather than making the code itself run faster. The inefficiency that this tendency introduces has been acceptable, because faster computer chips have always been able to pick up the slack.
“But nowadays, being able to make further advances in fields like machine learning, robotics, and virtual reality will require huge amounts of computational power that miniaturization can no longer provide,” says Leiserson, the Edwin Sibley Webster Professor in MIT’s Department of Electrical Engineering and Computer Science. “If we want to harness the full potential of these technologies, we must change our approach to computing.”
Leiserson co-wrote the paper, published this week, with Research Scientist Neil Thompson, Professor Daniel Sanchez, Adjunct Professor Butler Lampson, and research scientists Joel Emer, Bradley Kuszmaul, and Tao Schardl.
No more Moore
The authors make recommendations about three areas of computing: software, algorithms, and hardware architecture.
With software, they say that programmers’ previous prioritization of productivity over performance has led to problematic strategies like “reduction”: taking code that worked on problem A and using it to solve problem B. For example, if someone has to create a system to recognize yes-or-no voice commands, but doesn’t want to code a whole new custom program, they could take an existing program that recognizes a wide range of words and tweak it to respond only to yes-or-no answers.
While this approach reduces coding time, the inefficiencies it creates quickly compound: if a single reduction is 80 percent as efficient as a custom solution, and you then add 20 layers of reduction, the code will ultimately be 100 times less efficient than it could be.
“These are the kinds of strategies that programmers have to rethink as hardware improvements slow down,” says Thompson. “We can’t keep doing ‘business as usual’ if we want to continue to get the speed-ups we’ve grown accustomed to.”
Instead, the researchers recommend techniques like parallelizing code. Much existing software has been designed using ancient assumptions that processors can only do only one operation at a time. But in recent years multicore technology has enabled complex tasks to be completed thousands of times faster and in a much more energy-efficient way.
“Since Moore’s Law will not be handing us improved performance on a silver platter, we will have to deliver performance the hard way,” says Moshe Vardi, a professor in computational engineering at Rice University. “This is a great opportunity for computing research, and the [MIT CSAIL] report provides a road map for such research.”
As for algorithms, the team suggests a three-pronged approach that includes exploring new problem areas, addressing concerns about how algorithms scale, and tailoring them to better take advantage of modern hardware.
Lastly, in terms of hardware architecture, the team advocates that hardware be streamlined so that problems can be solved with fewer transistors and less silicon. Streamlining includes using simpler processors and creating hardware tailored to specific applications, like the graphics-processing unit is tailored for computer graphics.
“Hardware customized for particular domains can be much more efficient and use far fewer transistors, enabling applications to run tens to hundreds of times faster,” says Schardl. “More generally, hardware streamlining would further encourage parallel programming, creating additional chip area to be used for more circuitry that can operate in parallel.”
While these approaches may be the best path forward, the researchers say that it won’t always be an easy one. Organizations that use such techniques may not know the benefits of their efforts until after they’ve invested a lot of engineering time. Plus, the speed-ups won’t be as consistent as they were with Moore’s Law: they may be dramatic at first, and then require large amounts of effort for smaller improvements.
Certain companies have already gotten the memo.
“For tech giants like Google and Amazon, the huge scale of their data centers means that even small improvements in software performance can result in large financial returns,” says Thompson. “But while these firms may be leading the charge, many others will need to take these issues seriously if they want to stay competitive.”
Getting improvements in the areas identified by the team will also require building up the infrastructure and workforce that make them possible.
“Performance growth will require new tools, programming languages, and hardware to facilitate more and better performance engineering,” says Leiserson. “It also means computer scientists being better educated about how we can make software, algorithms, and hardware work together, instead of putting them in different silos.”
This work was supported, in part, by the National Science Foundation.
Predicting what Amazon’s customers will need tomorrow, next week, and beyond
Ping Xu, forecasting science director within Amazon’s Supply Chain Optimization Technologies (SCOT) organization, talks about the importance of using science to forecast the future.Read More
Amazon to host 8,000 virtual interns this year
More than eight percent of interns will have applied research, and data science roles.Read More
How computer vision will help Amazon customers shop online
Three papers at CVPR present complementary methods to improve product discovery.Read More