Watch the recording of Natarajan’s live interview with Alexa evangelist Jeff Blankenburg.Read More
Inside Uber ATG’s Data Mining Operation: Identifying Real Road Scenarios at Scale for Machine Learning
How did the pedestrian cross the road?
Contrary to popular belief, sometimes the answer isn’t as simple as “to get to the other side.” To bring safe, reliable self-driving vehicles (SDVs) to the streets at Uber Advanced Technologies Group (ATG)…
The post Inside Uber ATG’s Data Mining Operation: Identifying Real Road Scenarios at Scale for Machine Learning appeared first on Uber Engineering Blog.
Amazon Web Services open-sources biological knowledge graph to fight COVID-19
Knowledge graph combines data from six public databases, includes machine learning tools.Read More
Giving soft robots feeling
One of the hottest topics in robotics is the field of soft robots, which utilizes squishy and flexible materials rather than traditional rigid materials. But soft robots have been limited due to their lack of good sensing. A good robotic gripper needs to feel what it is touching (tactile sensing), and it needs to sense the positions of its fingers (proprioception). Such sensing has been missing from most soft robots.
In a new pair of papers, researchers from MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL) came up with new tools to let robots better perceive what they’re interacting with: the ability to see and classify items, and a softer, delicate touch.
“We wish to enable seeing the world by feeling the world. Soft robot hands have sensorized skins that allow them to pick up a range of objects, from delicate, such as potato chips, to heavy, such as milk bottles,” says CSAIL Director Daniela Rus, the Andrew and Erna Viterbi Professor of Electrical Engineering and Computer Science and the deputy dean of research for the MIT Stephen A. Schwarzman College of Computing.
One paper builds off last year’s research from MIT and Harvard University, where a team developed a soft and strong robotic gripper in the form of a cone-shaped origami structure. It collapses in on objects much like a Venus’ flytrap, to pick up items that are as much as 100 times its weight.
To get that newfound versatility and adaptability even closer to that of a human hand, a new team came up with a sensible addition: tactile sensors, made from latex “bladders” (balloons) connected to pressure transducers. The new sensors let the gripper not only pick up objects as delicate as potato chips, but it also classifies them — letting the robot better understand what it’s picking up, while also exhibiting that light touch.
When classifying objects, the sensors correctly identified 10 objects with over 90 percent accuracy, even when an object slipped out of grip.
“Unlike many other soft tactile sensors, ours can be rapidly fabricated, retrofitted into grippers, and show sensitivity and reliability,” says MIT postdoc Josie Hughes, the lead author on a new paper about the sensors. “We hope they provide a new method of soft sensing that can be applied to a wide range of different applications in manufacturing settings, like packing and lifting.”
In a second paper, a group of researchers created a soft robotic finger called “GelFlex” that uses embedded cameras and deep learning to enable high-resolution tactile sensing and “proprioception” (awareness of positions and movements of the body).
The gripper, which looks much like a two-finger cup gripper you might see at a soda station, uses a tendon-driven mechanism to actuate the fingers. When tested on metal objects of various shapes, the system had over 96 percent recognition accuracy.
“Our soft finger can provide high accuracy on proprioception and accurately predict grasped objects, and also withstand considerable impact without harming the interacted environment and itself,” says Yu She, lead author on a new paper on GelFlex. “By constraining soft fingers with a flexible exoskeleton, and performing high-resolution sensing with embedded cameras, we open up a large range of capabilities for soft manipulators.”
Magic ball senses
The magic ball gripper is made from a soft origami structure, encased by a soft balloon. When a vacuum is applied to the balloon, the origami structure closes around the object, and the gripper deforms to its structure.
While this motion lets the gripper grasp a much wider range of objects than ever before, such as soup cans, hammers, wine glasses, drones, and even a single broccoli floret, the greater intricacies of delicacy and understanding were still out of reach — until they added the sensors.
When the sensors experience force or strain, the internal pressure changes, and the team can measure this change in pressure to identify when it will feel that again.
In addition to the latex sensor, the team also developed an algorithm which uses feedback to let the gripper possess a human-like duality of being both strong and precise — and 80 percent of the tested objects were successfully grasped without damage.
The team tested the gripper-sensors on a variety of household items, ranging from heavy bottles to small, delicate objects, including cans, apples, a toothbrush, a water bottle, and a bag of cookies.
Going forward, the team hopes to make the methodology scalable, using computational design and reconstruction methods to improve the resolution and coverage using this new sensor technology. Eventually, they imagine using the new sensors to create a fluidic sensing skin that shows scalability and sensitivity.
Hughes co-wrote the new paper with Rus, which they will present virtually at the 2020 International Conference on Robotics and Automation.
GelFlex
In the second paper, a CSAIL team looked at giving a soft robotic gripper more nuanced, human-like senses. Soft fingers allow a wide range of deformations, but to be used in a controlled way there must be rich tactile and proprioceptive sensing. The team used embedded cameras with wide-angle “fisheye” lenses that capture the finger’s deformations in great detail.
To create GelFlex, the team used silicone material to fabricate the soft and transparent finger, and put one camera near the fingertip and the other in the middle of the finger. Then, they painted reflective ink on the front and side surface of the finger, and added LED lights on the back. This allows the internal fish-eye camera to observe the status of the front and side surface of the finger.
The team trained neural networks to extract key information from the internal cameras for feedback. One neural net was trained to predict the bending angle of GelFlex, and the other was trained to estimate the shape and size of the objects being grabbed. The gripper could then pick up a variety of items such as a Rubik’s cube, a DVD case, or a block of aluminum.
During testing, the average positional error while gripping was less than 0.77 millimeter, which is better than that of a human finger. In a second set of tests, the gripper was challenged with grasping and recognizing cylinders and boxes of various sizes. Out of 80 trials, only three were classified incorrectly.
In the future, the team hopes to improve the proprioception and tactile sensing algorithms, and utilize vision-based sensors to estimate more complex finger configurations, such as twisting or lateral bending, which are challenging for common sensors, but should be attainable with embedded cameras.
Yu She co-wrote the GelFlex paper with MIT graduate student Sandra Q. Liu, Peiyu Yu of Tsinghua University, and MIT Professor Edward Adelson. They will present the paper virtually at the 2020 International Conference on Robotics and Automation.
Amazon scientists help SK telecom create Korean-based natural language processor
AWS services used to process massive amounts of data needed to develop the sophisticated, open-source artificial language model.Read More
SAIL and Stanford Robotics at ICRA 2020
![]()
The International Conference on Robotics and Automation (ICRA) 2020 is being hosted virtually from May 31 – Jun 4.
We’re excited to share all the work from SAIL that’s being presented, and you’ll find links to papers, videos and blogs below. Feel free to reach out to the contact authors directly to learn more about the work that’s happening at Stanford!
List of Accepted Papers
Design of a Roller-Based Dexterous Hand for Object Grasping and Within-Hand Manipulation

Authors: Shenli Yuan, Austin D. Epps, Jerome B. Nowak, J. Kenneth Salisbury
Contact: shenliy@stanford.edu
Award nominations: Best Paper, Best Student Paper, Best Paper Award in Robot Manipulation, Best Paper in Mechanisms and Design
Links: Paper | Video
Keywords: dexterous manipulation, grasping, grippers and other end-effectors
Distributed Multi-Target Tracking for Autonomous Vehicle Fleets
![]()
Authors: Ola Shorinwa, Javier Yu, Trevor Halsted, Alex Koufos, and Mac Schwager
Contact: shorinwa@stanford.edu
Award nominations: Best Paper
Links: Paper | Video
Keywords: mulit-target tracking, distributed estimation, multi-robot systems
Efficient Large-Scale Multi-Drone Delivery Using Transit Networks

Authors: Shushman Choudhury, Kiril Solovey, Mykel J. Kochenderfer, Marco Pavone
Contact: shushman@stanford.edu
Award nominations: Best Multi-Robot Systems Paper
Links: Paper | Video
Keywords: multi-robot, optimization, task allocation, route planning
Form2Fit: Learning Shape Priors for Generalizable Assembly from Disassembly
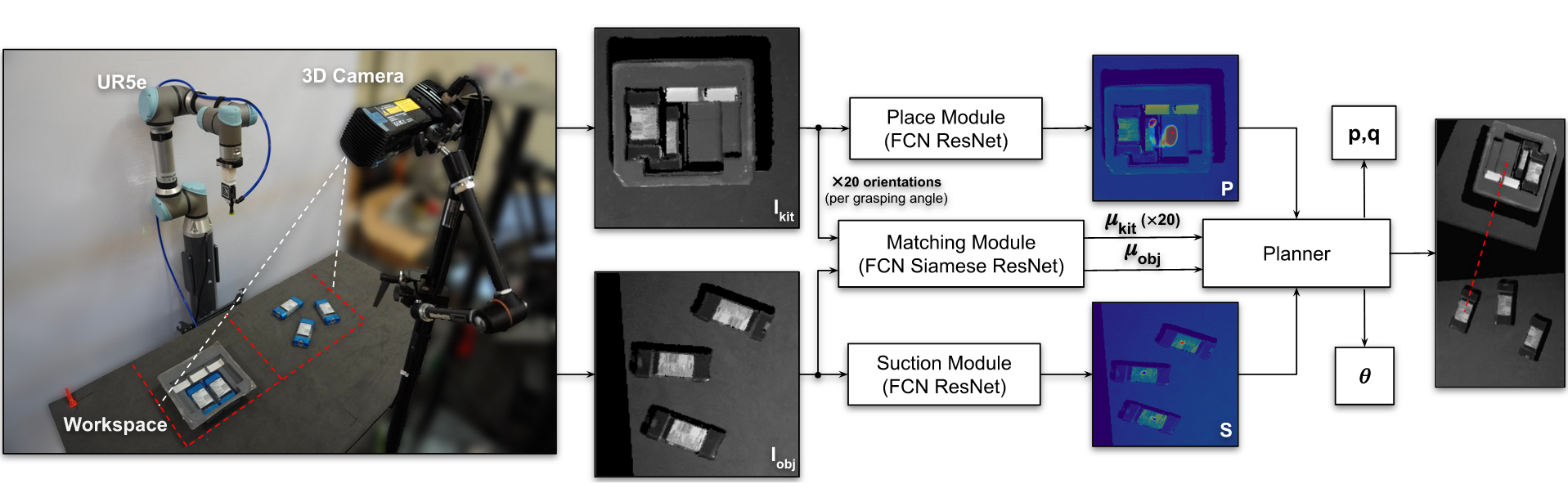
Authors: Kevin Zakka, Andy Zeng, Johnny Lee, Shuran Song
Contact: zakka@cs.stanford.edu
Award nominations: Best Automation Paper
Links: Paper | Blog Post | Video
Keywords: perception for grasping, assembly, robotics
Human Interface for Teleoperated Object Manipulation with a Soft Growing Robot

Authors: Fabio Stroppa, Ming Luo, Kyle Yoshida, Margaret M. Coad, Laura H. Blumenschein, and Allison M. Okamura
Contact: fstroppa@stanford.edu
Award nominations: Best Human-Robot Interaction Paper
Links: Paper | Video
Keywords: soft robot, growing robot, manipulation, interface, teleoperation
6-PACK: Category-level 6D Pose Tracker with Anchor-Based Keypoints
Authors: Chen Wang, Roberto Martín-Martín, Danfei Xu, Jun Lv, Cewu Lu, Li Fei-Fei, Silvio Savarese, Yuke Zhu
Contact: chenwj@stanford.edu
Links: Paper | Blog Post | Video
Keywords: category-level 6d object pose tracking, unsupervised 3d keypoints
A Stretchable Capacitive Sensory Skin for Exploring Cluttered Environments
Authors: Alexander Gruebele, Jean-Philippe Roberge, Andrew Zerbe, Wilson Ruotolo, Tae Myung Huh, Mark R. Cutkosky
Contact: agruebe2@stanford.edu
Links: Paper
Keywords: robot sensing systems , skin , wires , capacitance , grasping
Accurate Vision-based Manipulation through Contact Reasoning
Authors: Alina Kloss, Maria Bauza, Jiajun Wu, Joshua B. Tenenbaum, Alberto Rodriguez, Jeannette Bohg
Contact: alina.kloss@tue.mpg.de
Links: Paper | Video
Keywords: manipulation planning, contact modeling, perception for grasping and manipulation
Assistive Gym: A Physics Simulation Framework for Assistive Robotics
Authors: Zackory Erickson, Vamsee Gangaram, Ariel Kapusta, C. Karen Liu, and Charles C. Kemp
Contact: karenliu@cs.stanford.edu
Links: Paper
Keywords: assistive robotics; physics simulation; reinforcement learning; physical human robot interaction
Controlling Assistive Robots with Learned Latent Actions
Authors: Dylan P. Losey, Krishnan Srinivasan, Ajay Mandlekar, Animesh Garg, Dorsa Sadigh
Contact: dlosey@stanford.edu
Links: Paper | Blog Post | Video
Keywords: human-robot interaction, assistive control
Distal Hyperextension is Handy: High Range of Motion in Cluttered Environments
Authors: Wilson Ruotolo, Rachel Thomasson, Joel Herrera, Alex Gruebele, Mark R. Cutkosky
Contact: wruotolo@stanford.edu
Links: Paper | Video
Keywords: dexterous manipulation, grippers and other end-effectors, multifingered hands
Dynamically Reconfigurable Discrete Distributed Stiffness for Inflated Beam Robots
Authors: Brian H. Do, Valory Banashek, Allison M. Okamura
Contact: brianhdo@stanford.edu
Links: Paper | Video
Keywords: soft robot materials and design; mechanism design; compliant joint/mechanism
Dynamically Reconfigurable Tactile Sensor for Robotic Manipulation
Authors: Tae Myung Huh, Hojung Choi, Simone Willcox, Stephanie Moon, Mark R. Cutkosky
Contact: taemyung@stanford.edu
Links: Paper | Video
Keywords: robot sensing systems , electrodes , force , force measurement , capacitance
Enhancing Game-Theoretic Autonomous Car Racing Using Control Barrier Functions
Authors: Gennaro Notomista, Mingyu Wang, Mac Schwager, Magnus Egerstedt
Contact: mingyuw@stanford.edu
Links: Paper
Keywords: autonomous driving
Evaluation of Non-Collocated Force Feedback Driven by Signal-Independent Noise
Authors: Zonghe Chua, Allison Okamura, Darrel Deo
Contact: chuazh@stanford.edu
Links: Paper | Video
Keywords: haptics and haptic interfaces; prosthetics and exoskeletons; brain-machine interface
From Planes to Corners: Multi-Purpose Primitive Detection in Unorganized 3D Point Clouds
Authors: Christiane Sommer, Yumin Sun, Leonidas Guibas, Daniel Cremers, Tolga Birdal
Contact: tbirdal@stanford.edu
Links: Paper | Code | Video
Keywords: plane detection, corner detection, orthogonal, 3d geometry, computer vision, point pair, slam
Guided Uncertainty-Aware Policy Optimization: Combining Learning and Model-Based Strategies for Sample-Efficient Policy Learning
Authors: Michelle A. Lee, Carlos Florensa, Jonathan Tremblay, Nathan Ratliff, Animesh Garg, Fabio Ramos, Dieter Fox
Contact: mishlee@stanford.edu
Links: Paper | Video
Keywords: deep learning in robotics and automation, perception for grasping and manipulation, learning and adaptive systems
IRIS: Implicit Reinforcement without Interaction at Scale for Learning Control from Offline Robot Manipulation Data
Authors: Ajay Mandlekar, Fabio Ramos, Byron Boots, Silvio Savarese, Li Fei-Fei, Animesh Garg, Dieter Fox
Contact: amandlek@stanford.edu
Links: Paper | Video
Keywords: imitation learning, reinforcement learning, robotics
Interactive Gibson Benchmark: A Benchmark for Interactive Navigation in Cluttered Environments
Authors: Fei Xia, William B. Shen, Chengshu Li, Priya Kasimbeg, Micael Tchapmi, Alexander Toshev, Roberto Martín-Martín, Silvio Savarese
Contact: feixia@stanford.edu
Links: Paper | Video
Keywords: visual navigation, deep learning in robotics, mobile manipulation
KETO: Learning Keypoint Representations for Tool Manipulation
Authors: Zengyi Qin, Kuan Fang, Yuke Zhu, Li Fei-Fei, Silvio Savarese
Contact: qinzy@cs.stanford.edu
Links: Paper | Blog Post | Video
Keywords: manipulation, representation, keypoint, interaction, self-supervised learning
Learning Hierarchical Control for Robust In-Hand Manipulation
Authors: Tingguang Li, Krishnan Srinivasan, Max Qing-Hu Meng, Wenzhen Yuan, Jeannette Bohg
Contact: tgli@link.cuhk.edu.hk
Links: Paper | Blog Post | Video
Keywords: in-hand manipulation, robotics, reinforcement learning, hierarchical
Learning Task-Oriented Grasping from Human Activity Datasets
Authors: Mia Kokic, Danica Kragic, Jeannette Bohg
Contact: mkokic@kth.se
Links: Paper
Keywords: perception, grasping
Learning a Control Policy for Fall Prevention on an Assistive Walking Device
Authors: Visak CV Kumar, Sehoon Ha, Gregory Sawicki, C. Karen Liu
Contact: karenliu@cs.stanford.edu
Links: Paper
Keywords: assistive robotics; human motion modeling; physical human robot interaction; reinforcement learning
Learning an Action-Conditional Model for Haptic Texture Generation
Authors: Negin Heravi, Wenzhen Yuan, Allison M. Okamura, Jeannette Bohg
Contact: nheravi@stanford.edu
Links: Paper | Blog Post | Video
Keywords: haptics and haptic interfaces
Learning to Collaborate from Simulation for Robot-Assisted Dressing
Authors: Alexander Clegg, Zackory Erickson, Patrick Grady, Greg Turk, Charles C. Kemp, C. Karen Liu
Contact: karenliu@cs.stanford.edu
Links: Paper
Keywords: assistive robotics; physical human robot interaction; reinforcement learning; physics simulation; cloth manipulation
Learning to Scaffold the Development of Robotic Manipulation Skills
Authors: Lin Shao, Toki Migimatsu, Jeannette Bohg
Contact: lins2@stanford.edu
Links: Paper | Video
Keywords: learning and adaptive systems, deep learning in robotics and automation, intelligent and flexible manufacturing
Map-Predictive Motion Planning in Unknown Environments
Authors: Amine Elhafsi, Boris Ivanovic, Lucas Janson, Marco Pavone
Contact: amine@stanford.edu
Links: Paper
Keywords: motion planning deep learning robotics
Motion Reasoning for Goal-Based Imitation Learning
Authors: De-An Huang, Yu-Wei Chao, Chris Paxton, Xinke Deng, Li Fei-Fei, Juan Carlos Niebles, Animesh Garg, Dieter Fox
Contact: dahuang@stanford.edu
Links: Paper | Video
Keywords: imitation learning, goal inference
Object-Centric Task and Motion Planning in Dynamic Environments
Authors: Toki Migimatsu, Jeannette Bohg
Contact: takatoki@cs.stanford.edu
Links: Paper | Blog Post | Video
Keywords: control of systems integrating logic, dynamics, and constraints
Optimal Sequential Task Assignment and Path Finding for Multi-Agent Robotic Assembly Planning
Authors: Kyle Brown, Oriana Peltzer, Martin Sehr, Mac Schwager, Mykel Kochenderfer
Contact: kjbrown7@stanford.edu
Links: Paper | Video
Keywords: multi robot systems, multi agent path finding, mixed integer programming, automated manufacturing, sequential task assignment
Refined Analysis of Asymptotically-Optimal Kinodynamic Planning in the State-Cost Space
Authors: Michal Kleinbort, Edgar Granados, Kiril Solovey, Riccardo Bonalli, Kostas E. Bekris, Dan Halperin
Contact: kirilsol@stanford.edu
Links: Paper
Keywords: motion planning, sampling-based planning, rrt, optimality
Retraction of Soft Growing Robots without Buckling
Authors: Margaret M. Coad, Rachel P. Thomasson, Laura H. Blumenschein, Nathan S. Usevitch, Elliot W. Hawkes, and Allison M. Okamura
Contact: mmcoad@stanford.edu
Links: Paper | Video
Keywords: soft robot materials and design; modeling, control, and learning for soft robots
Revisiting the Asymptotic Optimality of RRT*
Authors: Kiril Solovey, Lucas Janson, Edward Schmerling, Emilio Frazzoli, and Marco Pavone
Contact: kirilsol@stanford.edu
Links: Paper | Video
Keywords: motion planning, rapidly-exploring random trees, rrt*, sampling-based planning
Sample Complexity of Probabilistic Roadmaps via Epsilon Nets
Authors: Matthew Tsao, Kiril Solovey, Marco Pavone
Contact: mwtsao@stanford.edu
Links: Paper | Video
Keywords: motion planning, sampling-based planning, probabilistic roadmaps, epsilon nets
Self-Supervised Learning of State Estimation for Manipulating Deformable Linear Objects
Authors: Mengyuan Yan, Yilin Zhu, Ning Jin, Jeannette Bohg
Contact: myyan92@gmail.com, bohg@stanford.edu
Links: Paper | Video
Keywords: self-supervision, deformable objects
Spatial Scheduling of Informative Meetings for Multi-Agent Persistent Coverage
Authors: Ravi Haksar, Sebastian Trimpe, Mac Schwager
Contact: rhaksar@stanford.edu
Links: Paper | Video
Keywords: distributed systems, multi-robot systems, multi-robot path planning
Spatiotemporal Relationship Reasoning for Pedestrian Intent Prediction
Authors: Bingbin Liu, Ehsan Adeli, Zhangjie Cao, Kuan-Hui Lee, Abhijeet Shenoi, Adrien Gaidon, Juan Carlos Niebles
Contact: eadeli@stanford.edu
Links: Paper | Video
Keywords: spatiotemporal graphs, forecasting, graph neural networks, autonomous-driving.
TRASS: Time Reversal as Self-Supervision
Authors: Suraj Nair, Mohammad Babaeizadeh, Chelsea Finn, Sergey Levine, Vikash Kumar
Contact: surajn@stanford.edu
Links: Paper | Blog Post | Video
Keywords: visual planning; reinforcement learning; self-supervision
UniGrasp: Learning a Unified Model to Grasp with Multifingered Robotic Hands
Authors: Lin Shao, Fabio Ferreira, Mikael Jorda, Varun Nambiar, Jianlan Luo, Eugen Solowjow, Juan Aparicio Ojea, Oussama Khatib, Jeannette Bohg
Contact: lins2@stanford.edu
Links: Paper | Video
Keywords: deep learning in robotics and automation; grasping; multifingered hands
Vine Robots: Design, Teleoperation, and Deployment for Navigation and Exploration
Authors: Margaret M. Coad, Laura H. Blumenschein, Sadie Cutler, Javier A. Reyna Zepeda, Nicholas D. Naclerio, Haitham El-Hussieny, Usman Mehmood, Jee-Hwan Ryu, Elliot W. Hawkes, and Allison M. Okamura
Contact: mmcoad@stanford.edu
Links: Paper | Video
Keywords: soft robot applications; field robots
We look forward to seeing you at ICRA!

DADS: Unsupervised Reinforcement Learning for Skill Discovery
Posted by Archit Sharma, AI Resident, Google Research
Recent research has demonstrated that supervised reinforcement learning (RL) is capable of going beyond simulation scenarios to synthesize complex behaviors in the real world, such as grasping arbitrary objects or learning agile locomotion. However, the limitations of teaching an agent to perform complex behaviors using well-designed task-specific reward functions are also becoming apparent. Designing reward functions can require significant engineering effort, which becomes untenable for a large number of tasks. For many practical scenarios, designing a reward function can be complicated, for example, requiring additional instrumentation for the environment (e.g., sensors to detect the orientation of doors) or manual-labelling of “goal” states. Considering that the ability to generate complex behaviors is limited by this form of reward-engineering, unsupervised learning presents itself as an interesting direction for RL.
In supervised RL, the extrinsic reward function from the environment guides the agent towards the desired behaviors, reinforcing the actions which bring the desired changes in the environment. With unsupervised RL, the agent uses an intrinsic reward function (such as curiosity to try different things in the environment) to generate its own training signals to acquire a broad set of task-agnostic behaviors. The intrinsic reward functions can bypass the problems of the engineering extrinsic reward functions, while being generic and broadly applicable to several agents and problems without any additional design. While much research has recently focused on different approaches to unsupervised reinforcement learning, it is still a severely under-constrained problem — without the guidance of rewards from the environment, it can be hard to learn behaviors which will be useful. Are there meaningful properties of the agent-environment interaction that can help discover better behaviors (“skills”) for the agents?
In this post, we present two recent publications that develop novel unsupervised RL methods for skill discovery. In “Dynamics-Aware Unsupervised Discovery of Skills” (DADS), we introduce the notion of “predictability” to the optimization objective for unsupervised learning. In this work we posit that a fundamental attribute of skills is that they bring about a predictable change in the environment. We capture this idea in our unsupervised skill discovery algorithm, and show applicability in a broad range of simulated robotic setups. In our follow-up work “Emergent Real-World Robotic Skills via Unsupervised Off-Policy Reinforcement Learning”, we improve the sample-efficiency of DADS to demonstrate that unsupervised skill discovery is feasible in the real world.
 |
| The behavior on the left is random and unpredictable, while the behavior on the right demonstrates systematic motion with predictable changes in the environment. Our goal is to learn potentially useful behaviors such as those on the right, without engineered reward functions. |
Overview of DADS
DADS designs an intrinsic reward function that encourages discovery of “predictable” and “diverse” skills. The intrinsic reward function is high if (a) the changes in the environment are different for different skills (encouraging diversity) and (b) changes in the environment for a given skill are predictable (predictability). Since DADS does not obtain any rewards from the environment, optimizing the skills to be diverse enables the agent to capture as many potentially useful behaviors as possible.
In order to determine if a skill is predictable, we train another neural network, called the skill-dynamics network, to predict the changes in the environment state when given the current state and the skill being executed. The better the skill-dynamics network can predict the change of state in the environment, the more “predictable” the skill is. The intrinsic reward defined by DADS can be maximized using any conventional reinforcement learning algorithm.
 |
| An overview of DADS. |
The algorithm enables several different agents to discover predictable skills purely from reward-free interaction with the environment. DADS, unlike prior work, can scale to high-dimensional continuous control environments such as Humanoid, a simulated bipedal robot. Since DADS is environment agnostic, it can be applied to both locomotion and manipulation oriented environments. We show some of the skills discovered by different continuous control agents.
 |
| Ant discovers galloping (top left) and skipping (bottom left), Humanoid discovers different locomotive gaits (middle, sped up 2x), and D’Claw from ROBEL (right) discovers different ways to rotate an object, all using DADS. More sample videos are available here. |
Model-Based Control Using Skill-Dynamics
Not only does DADS enable the discovery of predictable and potentially useful skills, it allows for an efficient approach to apply the learned skills to downstream tasks. We can leverage the learned skill-dynamics to predict the state-transitions for each skill. The predicted state-transitions can be chained together to simulate the complete trajectory of states for any learned skill without executing it in the environment. Therefore, we can simulate the trajectory for different skills and choose the skill which gets the highest reward for the given task. The model-based planning approach described here can be very sample-efficient as no additional training is required for the skills. This is a significant step up from the prior approaches, which require additional training on the environment to combine the learned skills.
 |
 |
| Using the skills discovered by the agents, we can traverse an arbitrary sequence of checkpoints without any additional training. The plot on the right follows the agent’s traversal from one checkpoint to another. |
Real-World Results
The demonstration of unsupervised learning in real-world robotics has been fairly limited, with results being restricted to simulation environments. In “Emergent Real-World Robotic Skills via Unsupervised Off-Policy Reinforcement Learning”, we develop a sample-efficient version of our earlier algorithm, called off-DADS, through algorithmic and systematic improvements in an off-policy learning setup. Off-policy learning enables the use of data collected from different policies to improve the current policy. In particular, reusing the previously collected data can dramatically improve the sample-efficiency of reinforcement learning algorithms. Leveraging the improvement from off-policy learning, we train D’Kitty (a quadruped from ROBEL) in the real-world starting from random policy initialization without any rewards from the environment or hand-crafted exploration strategies. We observe the emergence of complex behaviors with diverse gaits and directions by optimizing the intrinsic reward defined by DADS.
 |
 |
| Using off-DADS, we train D’Kitty from ROBEL to acquire diverse locomotion behaviors, which can then be used for goal-navigation through model-based control. |
Future Work
We have contributed a novel unsupervised skill discovery algorithm with broad applicability that is feasible to be executed in the real-world. This work provides a foundation for future work, where robots can solve a broad range of tasks with minimal human effort. One possibility is to study the relationship between the state-representation and the skills discovered by DADS in order to learn a state-representation that encourages discovery of skills for a known distribution of downstream tasks. Another interesting direction for exploration is provided by the formulation of skill-dynamics that separates high-level planning and low-level control, and study its general applicability to reinforcement learning problems.
Acknowledgements
We would like to thank our coauthors, Michael Ahn, Sergey Levine, Vikash Kumar, Shixiang Gu and Karol Hausman. We would also like to acknowledge the support and feedback provided by various members of the Google Brain team and the Robotics at Google team.

Meta-Graph: Few-Shot Link Prediction Using Meta-Learning
This article is based on the paper “Meta-Graph: Few Shot Link Prediction via Meta Learning” by Joey Bose, Ankit Jain, Piero Molino, and William L. Hamilton
Many real-world data sets are structured as graphs, and as such, machine …
The post Meta-Graph: Few-Shot Link Prediction Using Meta-Learning appeared first on Uber Engineering Blog.
Responding to the European Commission’s AI white paper
In January, our CEO Sundar Pichai visited Brussels to talk about artificial intelligence and how Google could help people and businesses succeed in the digital age through partnership. Much has changed since then due to COVID-19, but one thing hasn’t—our commitment to the potential of partnership with Europe on AI, especially to tackle the pandemic and help people and the economy recover.
As part of that effort, we earlier today filed our response to the European Commission’s Consultation on Artificial Intelligence, giving our feedback on the Commission’s initial proposal for how to regulate and accelerate the adoption of AI.
Excellence, skills, trust
Our filing applauds the Commission’s focus on building out the European “ecosystem of excellence.” European universities already boast renowned leaders in dozens of areas of AI research—Google partners with some of them via our machine learning research hubs in Zurich, Amsterdam, Berlin, Paris and London—and many of their students go on to make important contributions to European businesses.
We support the Commission’s plans to help businesses develop the AI skills they need to thrive in the new digital economy. Next month, we’ll contribute to those efforts by extending our machine learning check-up tool to 11 European countries to help small businesses implement AI and grow their businesses. Google Cloud already works closely with scores of businesses across Europe to help them innovate using AI.
We also support the Commission’s goal of building a framework for AI innovation that will create trust and guide ethical development and use of this widely applicable technology. We appreciate the Commission’s proportionate, risk-based approach. It’s important that AI applications in sensitive fields—such as medicine or transportation—are held to the appropriate standards.
Based on our experience working with AI, we also offered a couple of suggestions for making future regulation more effective. We want to be a helpful and engaged partner to policymakers, and we have provided more details in our formal response to the consultation.
Definition of high-risk AI applications
AI has a broad range of current and future applications, including some that involve significant benefits and risks. We think any future regulation would benefit from a more carefully nuanced definition of “high-risk” applications of AI. We agree that some uses warrant extra scrutiny and safeguards to address genuine and complex challenges around safety, fairness, explainability, accountability, and human interactions.
Assessment of AI applications
When thinking about how to assess high-risk AI applications, it’s important to strike a balance. While AI won’t always be perfect, it has great potential to help us improve over the performance of existing systems and processes. But the development process for AI must give people confidence that the AI system they’re using is reliable and safe. That’s especially true for applications like new medical diagnostic techniques, which potentially allow skilled medical practitioners to offer more accurate diagnoses, earlier interventions, and better patient outcomes. But the requirements need to be proportionate to the risk, and shouldn’t unduly limit innovation, adoption, and impact.
This is not an easy needle to thread. The Commission’s proposal suggests “ex ante” assessment of AI applications (i.e., upfront assessment, based on forecasted rather than actual use cases). Our contribution recommends having established due diligence and regulatory review processes expand to include the assessment of AI applications. This would avoid unnecessary duplication of efforts and likely speed up implementation.
For the (probably) rare instances when high-risk applications of AI are not obviously covered by existing regulations, we would encourage clear guidance on the “due diligence” criteria companies should use in their development processes. This would enable robust upfront self-assessment and documentation of any risks and their mitigations, and could also include further scrutiny after launch.
This approach would give European citizens confidence about the trustworthiness of AI applications, while also fostering innovation across the region. And it would encourage companies—especially smaller ones—to launch a range of valuable new services.
Principles and process
Responsible development of AI presents new challenges and critical questions for all of us. In 2018 we published our own AI Principles to help guide our ethical development and use of AI, and also established internal review processes to help us avoid bias, test rigorously for safety, design with privacy top of mind. Our principles also specify areas where we will not design or deploy AI, such as to support mass surveillance or violate human rights. Look out for an update on our work around these principles in the coming weeks.
AI is an important part of Google’s business and our aspirations for the future. We share a common goal with policymakers—a desire to build trust in AI through responsible innovation and thoughtful regulation, so that European citizens can safely enjoy the full social and economic benefits of AI. We hope that our contribution to the consultation is useful, and we look forward to participating in the discussion in coming months.
Speeding training of decision trees
New method reduces training time by up to 99%, with no loss in accuracy.Read More