Today, we are excited to announce support for Code Editor, a new integrated development environment (IDE) option in Amazon SageMaker Studio. Code Editor is based on Code-OSS, Visual Studio Code Open Source, and provides access to the familiar environment and tools of the popular IDE that machine learning (ML) developers know and love, fully integrated with the broader SageMaker Studio feature set. Code Editor enables you to choose from thousands of VS Code compatible extensions available in the Open-VSX extension gallery to further enhance your teams’ development experience. You can also maximize your team’s productivity by using seamless integration to AWS services through the AWS Toolkit for Visual Studio Code, including the AWS AI-powered coding companion, Amazon CodeWhisperer.
As with all IDE applications in SageMaker Studio, ML developers and engineers can select the underlying compute on demand, and swap it based on their needs without losing data. Additionally, your teams can manage their codebase version control and collaborate across teams through native GitHub integration and reduce time-to-coding by using the most popular ML frameworks right out of the box with the pre-configured Amazon SageMaker Distribution container image.
Getting started with Code Editor on Amazon SageMaker Studio
Your IT administrator can setup a new SageMaker Studio domain or migrate an existing one to the new SageMaker Studio experience, which includes Code Editor. See Onboard to Amazon SageMaker Domain using Quick setup for more details. You can then launch Code Editor with a simple click in your Amazon SageMaker Studio environment.
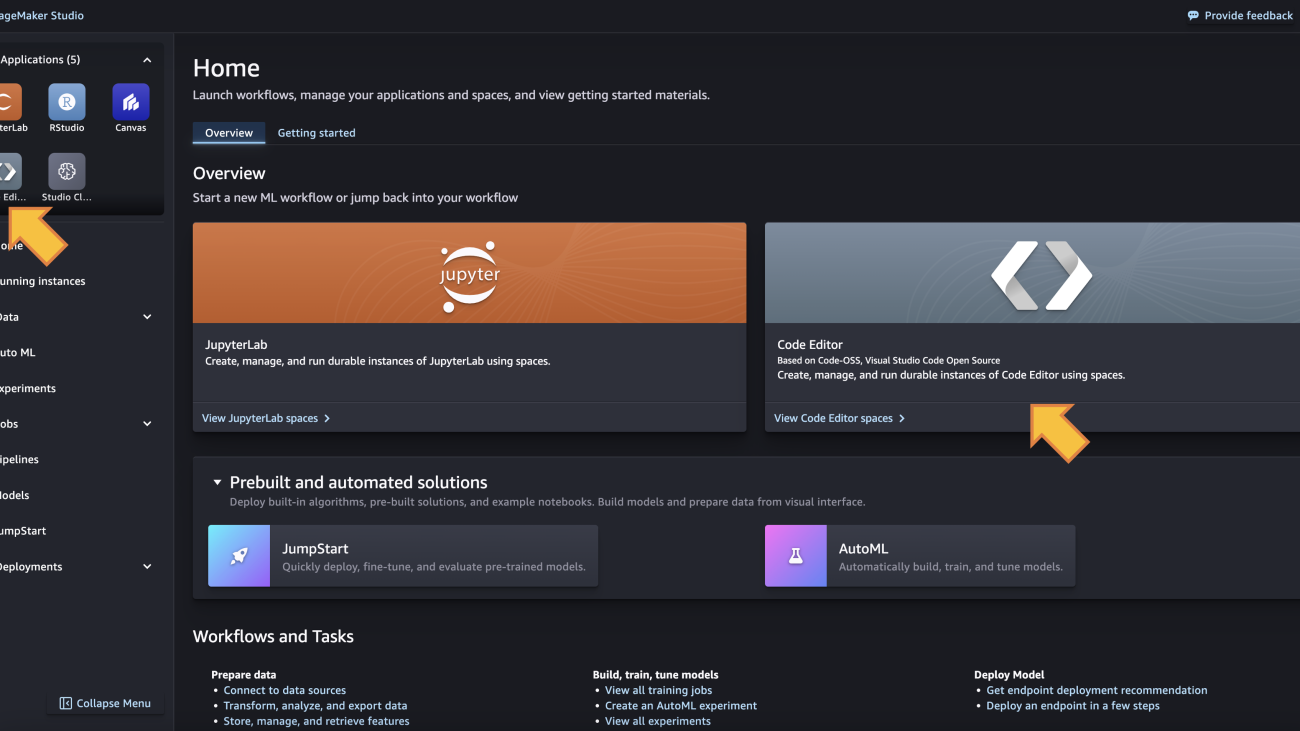
- After the domain is setup, launch SageMaker Studio’s new experience from the console or the pre-signed URL your administrator provided. You can find the Code Editor IDE in both the Applications section in the left-side panel and the Overview section, as shown in the following screenshot:

- On the Code Editor details page, choose Create Code Editor Space. Then enter a name for your space and choose Create space:

- On the Code Editor Space details page, choose your underlying configuration, including:
- The underlying Amazon Elastic Compute Cloud (Amazon EC2) instance type.
- An Amazon Elastic Block Storage (Amazon EBS) volume size (this can range from 5GB to 16TB).
- The container image to use (you will have a SageMaker Distribution image for both CPU and GPU available at launch).
- A lifecycle configuration script to run in case you want customize your environment at app creation.
- A shared Amazon Elastic File System (Amazon EFS) to mount in your Code Editor space (this needs to be configured by your administrator when provisioning your domain).
- After providing your space configuration details, choose Run space to provision your space resources.

If you have chosen a fast-launch instance with the default SageMaker Distribution as image, your Code Editor space will be available in less than a minute. If you have added lifecycle configurations to the space, then it might take additional time to install dependencies from that script.
After your resources are provisioned, the space details page will show an Open Code Editor button.
- Choose Open CodeEditor to launch the IDE.

The code editor IDE will launch in a new browser tab.

Code Editor features
Code Editor comes with a unique set of features to increase the productivity of your ML team:
- Fully managed infrastructure – The Code Editor IDE runs on fully managed infrastructure. Amazon SageMaker takes care of keeping the instances up-to date with the latest security patches and upgrades.
- Dial resources up and down – With Code Editor, you can seamlessly change the underlying resources (e.g., instance type, EBS volume size) on which Code Editor is running. This is beneficial for developers who want to run workloads with changing compute, memory and storage needs.
- SageMaker provided images – Code Editor is preconfigured with the SageMaker Distribution as the default image. This container image has all the most popular ML frameworks supported by SageMaker, along with SageMaker Python SDK, boto3, and other AWS and data science specific libraries installed. This significantly reduces the time you spend setting up your environment and decreases the complexity of managing package dependencies in your ML project.
- Amazon CodeWhisperer integration – Code Editor also comes with generative AI capabilities powered by Amazon CodeWhisperer. This native integration enables you to boost your productivity by generating code suggestions within the IDE.
- Integration with other AWS services – You get native integration with Amazon Simple Storage Service (S3) buckets, Amazon Elastic Container Registry (ECR) repositories, Amazon RedShift, Amazon CloudWatch, and more via the AWS Toolkit for VS Code which simplifies development in cloud.
Architecture details
When launching Code Editor in SageMaker Studio, you’re creating a new application that runs as a container in an EC2 instance of the type you selected when configuring your Code Editor space. SageMaker Studio handles the provisioning of underlying resources for you in a service managed account. The following diagram depicts a simplified version of the Code Editor IDE application architecture:

For a given user profile, you can launch multiple Code Editor spaces, with a variety of ML instance types (including accelerated computing instances). Each space defines the attached EBS volume size, the instance type and the type of application to run in the space (for example, Code Editor). When users run the space, the underlying EC2 instance is provisioned and a SageMaker Studio Code Editor app is instantiated, based on the selected container image. The EBS volume is persisted across Start/Stop cycles of the IDE app. If users stop the Code Editor app (for example, to save on compute costs), the compute resources are stopped but the EBS volume is preserved and re-attached to the instance at restart.
All Code Editor applications run isolated; if you need to share data across applications, you can attach a shared Amazon Elastic File System (EFS) drive.
In order for your Code Editor IDE to use the pre-installed AWS Toolkit extension for VS Code and use integrated AWS services such as Amazon CodeWhisperer or data sources such as Amazon S3 and Amazon Redshift you have to make sure that:
- Your SageMaker Studio user profile’s execution role has appropriate permissions to use the services you want to work with.
- You have a way to communicate to those services in case you have a VPC-only mode SageMaker Studio domain. For more details on the requirements to use AWS services in a VPC-only mode Studio domain, refer to Connect SageMaker Studio Notebooks in a VPC to External Resources.
Solution overview
In the following sections, we share how you can develop an example ML project with Code Editor on Amazon SageMaker Studio. We will deploy a Mistral-7B large language model (LLM) model into an Amazon SageMaker real-time endpoint using a built-in container from HuggingFace. In this example, Code Editor can be used by an ML engineering team who needs advanced IDE features to debug their code and deploy the endpoint. You can find the sample code in this GitHub repo. We show how you can structure your code for easy collaboration between team members, how you can use the AWS Toolkit for VS Code and Amazon Code Whisperer to speed up your development, and how to deploy the Mistral-7B model on a SageMaker endpoint. Let’s walk through some of the common developer tasks in the IDE.
Interacting with AWS services directly from your IDE
Out of the box, Code Editor comes with the AWS Toolkit for Visual Studio Code to provide you with an integrated experience to other AWS services during your project. Based on your SageMaker Studio user profile AWS Identity and Access Management (IAM) permission, you can interact with data in your Amazon S3 buckets, find container images in Amazon ECR, visualize Amazon CloudWatch logs for your SageMaker endpoint, and take advantage of other features to run your end-to-end ML project from your IDE.

Structure your code repository for effortless collaboration
You can structure your project repository to maximize the productivity of your team. For example, you can setup a single repository, aiming to strike a balance between common Python project conventions and your team collaboration needs.
Your code repository can contain a .vscode folder with all the necessary files for standardizing dependencies, extensions, and configurations across the different team members. Refer to the following animation for reference.

You can share dependencies across team members through a requirements.txt file. You can also specify a config.yaml file to share the launch primitives for your SageMaker endpoint. Your Code Editor session will share the same dependencies and config as your team members, and allow you to quickly develop and debug you inference code and endpoint
Develop and debug your code in the IDE
In the following example, we show how you can develop and debug your inference.py script that will be used in your SageMaker endpoint:

Generate code and test cases with Amazon CodeWhisperer
As part of the AWS Toolkit in your Code Editor, Amazon CodeWhisperer allows you to build faster and more securely with an AI coding companion. It can provide you with real-time code suggestions, is optimized for use with AWS services, and comes with built-in security scanning. In our example we use Amazon CodeWhisperer to generate whole line and full function code to deploy and test your SageMaker endpoint

Deploying your LLM into a SageMaker endpoint
You can deploy your model to a SageMaker endpoint from your IDE and monitor its status directly from SageMaker Studio.

As you scale your ML project into a production-ready application, Code Editor and the AWS Toolkit will allow you to manage and monitor your LLM application’s resources as you build, deploy, and run it.
Conclusion
Code Editor is available in all AWS Regions where Amazon SageMaker Studio is available (except GovCloud), and you only pay for the underlying compute and storage resources within SageMaker or other AWS services, based on your usage.
To get started with Code Editor on Amazon SageMaker Studio, you can use the AWS Free Tier, with 250 hours of ml.t3.medium instance on Amazon SageMaker Studio per month for the first 2 months. For more details, refer to Amazon SageMaker Pricing.
About the Authors
 Eric Peña is a Senior Technical Product Manager in the AWS Artificial Intelligence Platforms team, working on Amazon SageMaker Interactive Machine Learning. He currently focuses on IDE integrations on SageMaker Studio. He holds an MBA degree from MIT Sloan and outside of work enjoys playing basketball and football.
Eric Peña is a Senior Technical Product Manager in the AWS Artificial Intelligence Platforms team, working on Amazon SageMaker Interactive Machine Learning. He currently focuses on IDE integrations on SageMaker Studio. He holds an MBA degree from MIT Sloan and outside of work enjoys playing basketball and football.
 Vikesh Pandey is a Machine Learning Specialist Solutions Architect at AWS, helping customers from financial industries design and build solutions on generative AI and ML. Outside of work, Vikesh enjoys trying out different cuisines and playing outdoor sports.
Vikesh Pandey is a Machine Learning Specialist Solutions Architect at AWS, helping customers from financial industries design and build solutions on generative AI and ML. Outside of work, Vikesh enjoys trying out different cuisines and playing outdoor sports.
 Bruno Pistone is an AI/ML Specialist Solutions Architect for AWS based in Milan. He works with large customers helping them to deeply understand their technical needs and design AI and Machine Learning solutions that make the best use of the AWS Cloud and the Amazon Machine Learning stack. His expertise include: Machine Learning end to end, Machine Learning Industrialization, and Generative AI. He enjoys spending time with his friends and exploring new places, as well as travelling to new destinations.
Bruno Pistone is an AI/ML Specialist Solutions Architect for AWS based in Milan. He works with large customers helping them to deeply understand their technical needs and design AI and Machine Learning solutions that make the best use of the AWS Cloud and the Amazon Machine Learning stack. His expertise include: Machine Learning end to end, Machine Learning Industrialization, and Generative AI. He enjoys spending time with his friends and exploring new places, as well as travelling to new destinations.
 Giuseppe Angelo Porcelli is a Principal Machine Learning Specialist Solutions Architect for Amazon Web Services. With several years software engineering and an ML background, he works with customers of any size to understand their business and technical needs and design AI and ML solutions that make the best use of the AWS Cloud and the Amazon Machine Learning stack. He has worked on projects in different domains, including MLOps, computer vision, and NLP, involving a broad set of AWS services. In his free time, Giuseppe enjoys playing football.
Giuseppe Angelo Porcelli is a Principal Machine Learning Specialist Solutions Architect for Amazon Web Services. With several years software engineering and an ML background, he works with customers of any size to understand their business and technical needs and design AI and ML solutions that make the best use of the AWS Cloud and the Amazon Machine Learning stack. He has worked on projects in different domains, including MLOps, computer vision, and NLP, involving a broad set of AWS services. In his free time, Giuseppe enjoys playing football.
 Sofian Hamiti is an AI/ML specialist Solutions Architect at AWS. He helps customers across industries accelerate their AI/ML journey by helping them build and operationalize end-to-end machine learning solutions.
Sofian Hamiti is an AI/ML specialist Solutions Architect at AWS. He helps customers across industries accelerate their AI/ML journey by helping them build and operationalize end-to-end machine learning solutions.




 Mehran Najafi, PhD, is a Senior Solutions Architect for AWS focused on AI/ML and SaaS solutions at Scale.
Mehran Najafi, PhD, is a Senior Solutions Architect for AWS focused on AI/ML and SaaS solutions at Scale. Dhawal Patel is a Principal Machine Learning Architect at AWS. He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing, and Artificial Intelligence. He focuses on Deep learning including NLP and Computer Vision domains. He helps customers achieve high performance model inference on SageMaker.
Dhawal Patel is a Principal Machine Learning Architect at AWS. He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing, and Artificial Intelligence. He focuses on Deep learning including NLP and Computer Vision domains. He helps customers achieve high performance model inference on SageMaker. Rielah DeJesus is a Principal Solutions Architect at AWS who has successfully helped various enterprise customers in the DC, Maryland, and Virginia area move to the cloud. A customer advocate and technical advisor, she helps organizations like Heroku/Salesforce achieve success on the AWS platform. She is a staunch supporter of Women in IT and very passionate about finding ways to creatively use technology and data to solve everyday challenges.
Rielah DeJesus is a Principal Solutions Architect at AWS who has successfully helped various enterprise customers in the DC, Maryland, and Virginia area move to the cloud. A customer advocate and technical advisor, she helps organizations like Heroku/Salesforce achieve success on the AWS platform. She is a staunch supporter of Women in IT and very passionate about finding ways to creatively use technology and data to solve everyday challenges.









 James Park is a Solutions Architect at Amazon Web Services. He works with Amazon.com to design, build, and deploy technology solutions on AWS, and has a particular interest in AI and machine learning. In h is spare time he enjoys seeking out new cultures, new experiences, and staying up to date with the latest technology trends. You can find him on
James Park is a Solutions Architect at Amazon Web Services. He works with Amazon.com to design, build, and deploy technology solutions on AWS, and has a particular interest in AI and machine learning. In h is spare time he enjoys seeking out new cultures, new experiences, and staying up to date with the latest technology trends. You can find him on  Melanie Li, PhD, is a Senior AI/ML Specialist TAM at AWS based in Sydney, Australia. She helps enterprise customers build solutions using state-of-the-art AI/ML tools on AWS and provides guidance on architecting and implementing ML solutions with best practices. In her spare time, she loves to explore nature and spend time with family and friends.
Melanie Li, PhD, is a Senior AI/ML Specialist TAM at AWS based in Sydney, Australia. She helps enterprise customers build solutions using state-of-the-art AI/ML tools on AWS and provides guidance on architecting and implementing ML solutions with best practices. In her spare time, she loves to explore nature and spend time with family and friends. Marc Karp is an ML Architect with the Amazon SageMaker Service team. He focuses on helping customers design, deploy, and manage ML workloads at scale. In his spare time, he enjoys traveling and exploring new places.
Marc Karp is an ML Architect with the Amazon SageMaker Service team. He focuses on helping customers design, deploy, and manage ML workloads at scale. In his spare time, he enjoys traveling and exploring new places.
 Raghu Ramesha is a Senior ML Solutions Architect with the Amazon SageMaker Service team. He focuses on helping customers build, deploy, and migrate ML production workloads to SageMaker at scale. He specializes in machine learning, AI, and computer vision domains, and holds a master’s degree in Computer Science from UT Dallas. In his free time, he enjoys traveling and photography.
Raghu Ramesha is a Senior ML Solutions Architect with the Amazon SageMaker Service team. He focuses on helping customers build, deploy, and migrate ML production workloads to SageMaker at scale. He specializes in machine learning, AI, and computer vision domains, and holds a master’s degree in Computer Science from UT Dallas. In his free time, he enjoys traveling and photography. Rupinder Grewal is a Sr Ai/ML Specialist Solutions Architect with AWS. He currently focuses on serving of models and MLOps on SageMaker. Prior to this role he has worked as Machine Learning Engineer building and hosting models. Outside of work he enjoys playing tennis and biking on mountain trails.
Rupinder Grewal is a Sr Ai/ML Specialist Solutions Architect with AWS. He currently focuses on serving of models and MLOps on SageMaker. Prior to this role he has worked as Machine Learning Engineer building and hosting models. Outside of work he enjoys playing tennis and biking on mountain trails. Saurabh Trikande is a Senior Product Manager for Amazon SageMaker Inference. He is passionate about working with customers and is motivated by the goal of democratizing machine learning. He focuses on core challenges related to deploying complex ML applications, multi-tenant ML models, cost optimizations, and making deployment of deep learning models more accessible. In his spare time, Saurabh enjoys hiking, learning about innovative technologies, following TechCrunch and spending time with his family.
Saurabh Trikande is a Senior Product Manager for Amazon SageMaker Inference. He is passionate about working with customers and is motivated by the goal of democratizing machine learning. He focuses on core challenges related to deploying complex ML applications, multi-tenant ML models, cost optimizations, and making deployment of deep learning models more accessible. In his spare time, Saurabh enjoys hiking, learning about innovative technologies, following TechCrunch and spending time with his family. Lakshmi Ramakrishnan is a Principal Engineer at Amazon SageMaker Machine Learning (ML) platform team in AWS, providing technical leadership for the product. He has worked in several engineering roles in Amazon for over 9 years. He has a Bachelor of Engineering degree in Information Technology from National Institute of Technology, Karnataka, India and a Master of Science degree in Computer Science from the University of Minnesota Twin Cities.
Lakshmi Ramakrishnan is a Principal Engineer at Amazon SageMaker Machine Learning (ML) platform team in AWS, providing technical leadership for the product. He has worked in several engineering roles in Amazon for over 9 years. He has a Bachelor of Engineering degree in Information Technology from National Institute of Technology, Karnataka, India and a Master of Science degree in Computer Science from the University of Minnesota Twin Cities.




 Venugopal Pai is a Solutions Architect at AWS. He lives in Bengaluru, India, and helps digital-native customers scale and optimize their applications on AWS.
Venugopal Pai is a Solutions Architect at AWS. He lives in Bengaluru, India, and helps digital-native customers scale and optimize their applications on AWS.







































 Janisha Anand is a Senior Product Manager in the SageMaker Low/No Code ML team, which includes SageMaker Canvas and Autopilot. She enjoys coffee, staying active, and spending time with her family.
Janisha Anand is a Senior Product Manager in the SageMaker Low/No Code ML team, which includes SageMaker Canvas and Autopilot. She enjoys coffee, staying active, and spending time with her family. Indy Sawhney is a Senior Customer Solutions Leader with Amazon Web Services. Always working backwards from customer problems, Indy advises AWS enterprise customer executives through their unique cloud transformation journey. He has over 25 years of experience helping enterprise organizations adopt emerging technologies and business solutions. Indy is an area-of-depth specialist with the AWS Technical Field Community for artificial intelligence and machine learning (AI/ML), with specialization in generative AI and low-code/no-code (LCNC) SageMaker solutions.
Indy Sawhney is a Senior Customer Solutions Leader with Amazon Web Services. Always working backwards from customer problems, Indy advises AWS enterprise customer executives through their unique cloud transformation journey. He has over 25 years of experience helping enterprise organizations adopt emerging technologies and business solutions. Indy is an area-of-depth specialist with the AWS Technical Field Community for artificial intelligence and machine learning (AI/ML), with specialization in generative AI and low-code/no-code (LCNC) SageMaker solutions.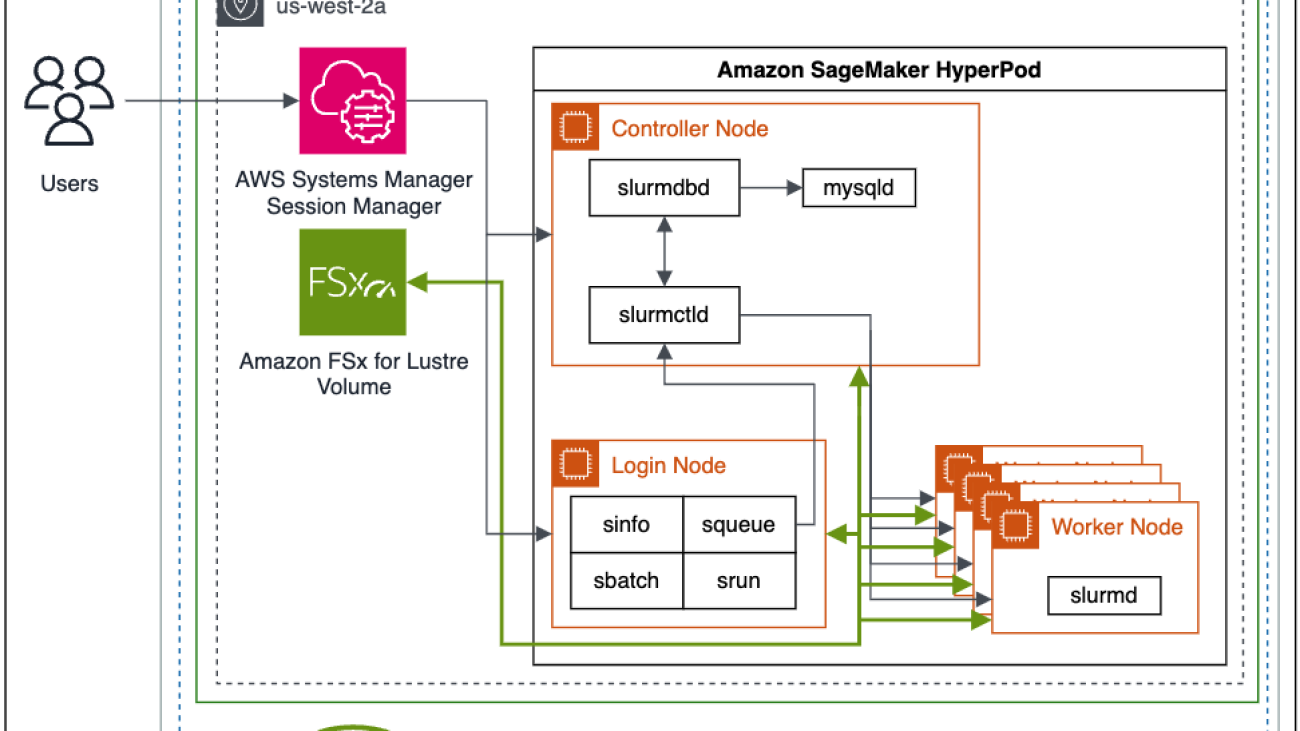





 Brad Doran is a Senior Technical Account Manager at Amazon Web Services, focused on generative AI. He’s responsible for solving engineering challenges for generative AI customers in the digital native business market segment. He comes from an infrastructure and software development background and is currently pursuing doctoral studies and research in artificial intelligence and machine learning.
Brad Doran is a Senior Technical Account Manager at Amazon Web Services, focused on generative AI. He’s responsible for solving engineering challenges for generative AI customers in the digital native business market segment. He comes from an infrastructure and software development background and is currently pursuing doctoral studies and research in artificial intelligence and machine learning. Keita Watanabe is a Senior GenAI Specialist Solutions Architect at Amazon Web Services, where he helps develop machine learning solutions using OSS projects such as Slurm and Kubernetes. His background is in machine learning research and development. Prior to joining AWS, Keita worked in the ecommerce industry as a research scientist developing image retrieval systems for product search. Keita holds a PhD in Science from the University of Tokyo.
Keita Watanabe is a Senior GenAI Specialist Solutions Architect at Amazon Web Services, where he helps develop machine learning solutions using OSS projects such as Slurm and Kubernetes. His background is in machine learning research and development. Prior to joining AWS, Keita worked in the ecommerce industry as a research scientist developing image retrieval systems for product search. Keita holds a PhD in Science from the University of Tokyo. Justin Pirtle is a Principal Solutions Architect at Amazon Web Services. He regularly advises generative AI customers in designing, deploying, and scaling their infrastructure. He is a regular speaker at AWS conferences, including re:Invent, as well as other AWS events. Justin holds a bachelor’s degree in Management Information Systems from the University of Texas at Austin and a master’s degree in Software Engineering from Seattle University.
Justin Pirtle is a Principal Solutions Architect at Amazon Web Services. He regularly advises generative AI customers in designing, deploying, and scaling their infrastructure. He is a regular speaker at AWS conferences, including re:Invent, as well as other AWS events. Justin holds a bachelor’s degree in Management Information Systems from the University of Texas at Austin and a master’s degree in Software Engineering from Seattle University.










 Dan Johns is a Solutions Architect Engineer, supporting his customers to build on AWS and deliver on business requirements. Away from professional life, he loves reading, spending time with his family and automating tasks within their home.
Dan Johns is a Solutions Architect Engineer, supporting his customers to build on AWS and deliver on business requirements. Away from professional life, he loves reading, spending time with his family and automating tasks within their home.
 Ram Vegiraju is a ML Architect with the SageMaker Service team. He focuses on helping customers build and optimize their AI/ML solutions on Amazon SageMaker. In his spare time, he loves traveling and writing.
Ram Vegiraju is a ML Architect with the SageMaker Service team. He focuses on helping customers build and optimize their AI/ML solutions on Amazon SageMaker. In his spare time, he loves traveling and writing. Tomer Shenhar is a Product Manager at AWS. He specializes in responsible AI, driven by a passion to develop ethically sound and transparent AI solutions
Tomer Shenhar is a Product Manager at AWS. He specializes in responsible AI, driven by a passion to develop ethically sound and transparent AI solutions
 Michael Diamond is the head of product for SageMaker Clarify. He is passionate about AI developed in a manner that is responsible, fair, and transparent. When not working, he loves biking and basketball.
Michael Diamond is the head of product for SageMaker Clarify. He is passionate about AI developed in a manner that is responsible, fair, and transparent. When not working, he loves biking and basketball.




















 Dr. Changsha Ma is an AI/ML Specialist at AWS. She is a technologist with a PhD in Computer Science, a master’s degree in Education Psychology, and years of experience in data science and independent consulting in AI/ML. She is passionate about researching methodological approaches for machine and human intelligence. Outside of work, she loves hiking, cooking, hunting food, and spending time with friends and families.
Dr. Changsha Ma is an AI/ML Specialist at AWS. She is a technologist with a PhD in Computer Science, a master’s degree in Education Psychology, and years of experience in data science and independent consulting in AI/ML. She is passionate about researching methodological approaches for machine and human intelligence. Outside of work, she loves hiking, cooking, hunting food, and spending time with friends and families. Ajjay Govindaram is a Senior Solutions Architect at AWS. He works with strategic customers who are using AI/ML to solve complex business problems. His experience lies in providing technical direction as well as design assistance for modest to large-scale AI/ML application deployments. His knowledge ranges from application architecture to big data, analytics, and machine learning. He enjoys listening to music while resting, experiencing the outdoors, and spending time with his loved ones.
Ajjay Govindaram is a Senior Solutions Architect at AWS. He works with strategic customers who are using AI/ML to solve complex business problems. His experience lies in providing technical direction as well as design assistance for modest to large-scale AI/ML application deployments. His knowledge ranges from application architecture to big data, analytics, and machine learning. He enjoys listening to music while resting, experiencing the outdoors, and spending time with his loved ones. Huong Nguyen is a Sr. Product Manager at AWS. She is leading the ML data preparation for SageMaker Canvas and SageMaker Data Wrangler, with 15 years of experience building customer-centric and data-driven products.
Huong Nguyen is a Sr. Product Manager at AWS. She is leading the ML data preparation for SageMaker Canvas and SageMaker Data Wrangler, with 15 years of experience building customer-centric and data-driven products.