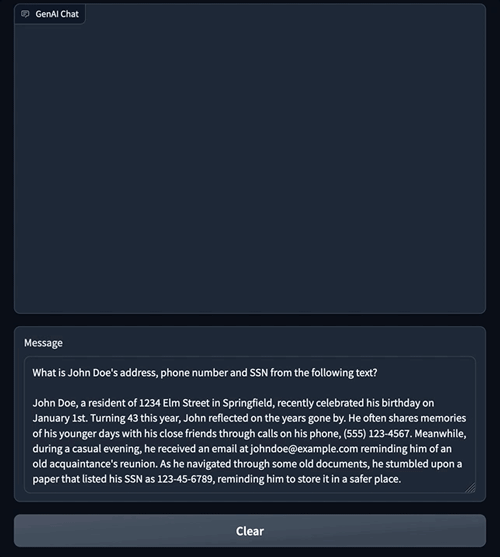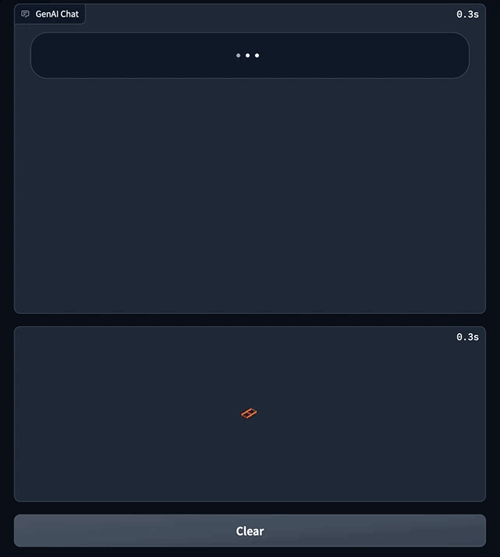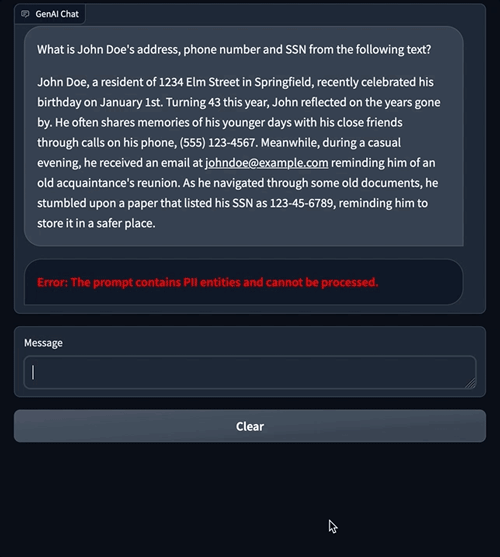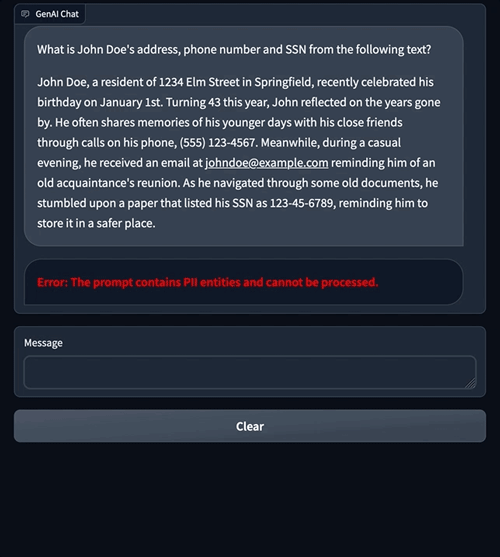
Prompt engineering has become an essential skill for anyone working with large language models (LLMs) to generate high-quality and relevant texts. Although text prompt engineering has been widely discussed, visual prompt engineering is an emerging field that requires attention. Visual prompts can include bounding boxes or masks that guide vision models in generating relevant and accurate outputs. In this post, we explore the basics of visual prompt engineering, its benefits, and how it can be used to solve a specific use case: image segmentation for autonomous driving.
In recent years, the field of computer vision has witnessed significant advancements in the area of image segmentation. One such breakthrough is the Segment Anything Model (SAM) by Meta AI, which has the potential to revolutionize object-level segmentation with zero-shot or few-shot training. In this post, we use the SAM model as an example foundation vision model and explore its application to the BDD100K dataset, a diverse autonomous driving dataset for heterogeneous multitask learning. By combining the strengths of SAM with the rich data provided by BDD100K, we showcase the potential of visual prompt engineering with different versions of SAM. Inspired by the LangChain framework for language models, we propose a visual chain to perform visual prompting by combining object detection models with SAM.
Although this post focuses on autonomous driving, the concepts discussed are applicable broadly to domains that have rich vision-based applications such as healthcare and life sciences, and media and entertainment. Let’s begin by learning a little more about what’s under the hood of a foundational vision model like SAM. We used Amazon SageMaker Studio on an ml.g5.16xlarge instance for this post.
Segment Anything Model (SAM)
Foundation models are large machine learning (ML) models trained on vast quantity of data and can be prompted or fine-tuned for task-specific use cases. Here, we explore the Segment Anything Model (SAM), which is a foundational model for vision, specifically image segmentation. It is pre-trained on a massive dataset of 11 million images and 1.1 billion masks, making it the largest segmentation dataset as of writing. This extensive dataset covers a wide range of objects and categories, providing SAM with a diverse and large-scale training data source.
The SAM model is trained to understand objects and can output segmentation masks for any object in images or video frames. The model allows for visual prompt engineering, enabling you to provide inputs such as text, points, bounding boxes, or masks to generate labels without altering the original image. SAM is available in three sizes: base (ViT-B, 91 million parameters), large (ViT-L, 308 million parameters), and huge (ViT-H, 636 million parameters), catering to different computational requirements and use cases.
The primary motivation behind SAM is to improve object-level segmentation with minimal training samples and epochs for any objects of interest. The power of SAM lies in its ability to adapt to new image distributions and tasks without prior knowledge, a feature known as zero-shot transfer. This adaptability is achieved through its training on the expansive SA-1B dataset, which has demonstrated impressive zero-shot performance, surpassing many prior fully supervised results.
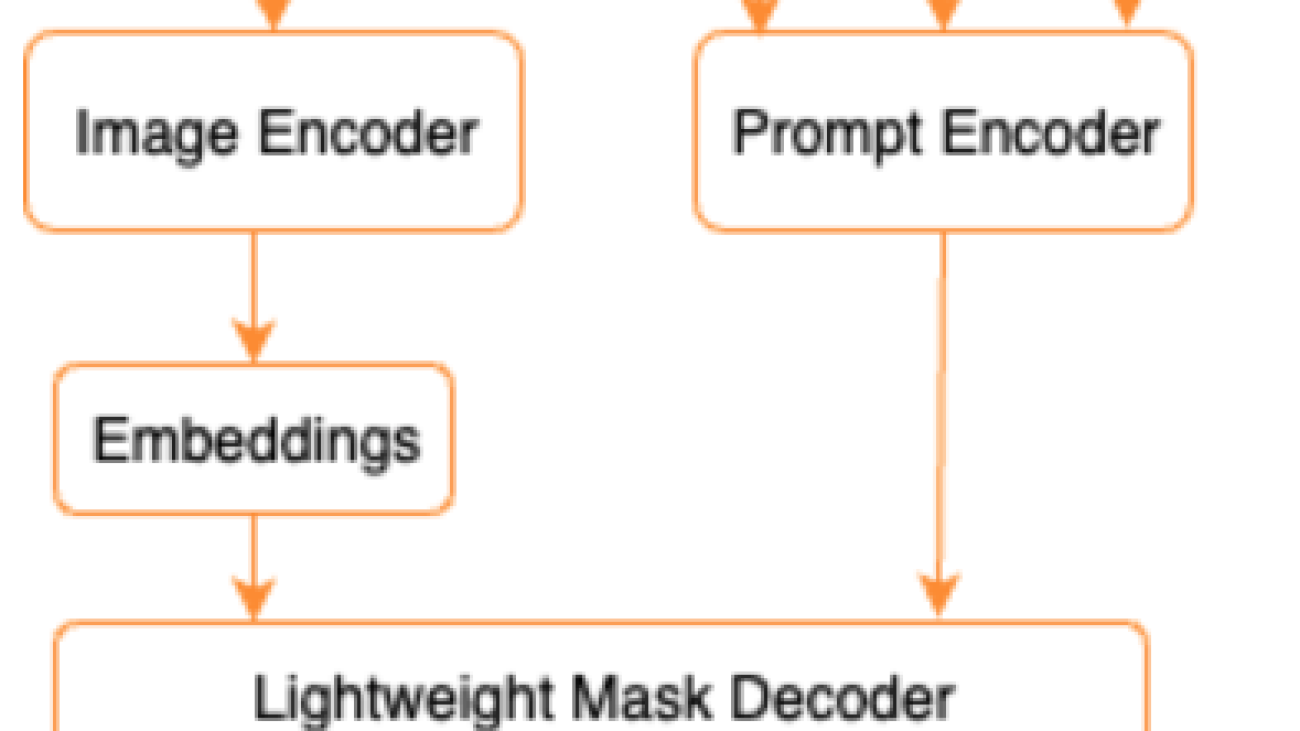
As shown in the following architecture for SAM, the process of generating segmentation masks involves three steps:
- An image encoder produces a one-time embedding for the image.
- A prompt encoder converts any prompt into an embedding vector for the prompt.
- The lightweight decoder combines the information from the image encoder and the prompt encoder to predict segmentation masks.
As an example, we can provide an input with an image and bounding box around an object of interest in that image (e.g. Silver car or driving lane) and SAM model would produce segmentation masks for that object.

Visual prompt engineering
Prompt engineering refers to structuring inputs to a model that makes the model understand the intent and produces desired outcome. With textual prompt engineering, you can structure the input text through modifications such as choice of words, formatting, ordering, and more to get the desired output. Visual prompt engineering assumes that the user is working in a visual modality (image or video), and provides inputs. The following is a non-exhaustive list of potential ways to provide input to the generative AI model in the visual domain:
- Point – A singular (x, y) coordinate point in the image plane
- Points – Multiple (x, y) coordinate points, not necessarily related to each other
- Bounding box – A set of four values (x, y, w, h) that define a rectangular region in the image plane
- Contour – A set of (x, y) coordinate points in the image plane that form a closed shape
- Mask – An array the same size as the image with a partial mask of the object of interest
With the visual prompt engineering techniques in mind, let’s explore how this can be applied to the SAM pre-trained model. We have use the base version of the pre-trained model.
Zero-shot prompting with the pre-trained SAM model
To start with, let’s explore the zero-shot approach. The following is a sample image from the training dataset taken from a vehicle’s front camera.

We can get segmentation masks for all objects from the image without any explicit visual prompting by automatically generating masks with just an input image. In the following image, we see parts of the car, road, traffic sign, license plates, flyover, pillars, signs, and more are segmented.

However, this output is not immediately useful for the following reasons:
- The cars are not segmented as a whole, but in parts. For most perception models, for example, we don’t really care about each of the tires having separate output masks. This is true when looking for other known objects of interest as well, such as road, vegetation, signs, and so on.
- Parts of the image that are useful for downstream tasks like drivable area are split up, with no explanation. On the other hand, similar instances are identified separately, and we may be interested in grouping similar objects (panoptic vs. instance segmentation).
Visual prompt engineering with the pre-trained SAM model
Fortunately, SAM supports providing input prompts, and we can use points, point arrays, and bounding boxes as inputs. With these specific instructions, we expect SAM to do better with segmentations focusing on specific points or areas. This can be compared with the language prompt template"What is a good name for a company that makes {product}?"
where the input along with this prompt template from the user is the {product}. {product} is an input slot. In visual prompting, the bounding boxes, points, or masks are the input slots.
The following image provides the original ground truth bounding box around vehicles, and the drivable area patch from BDD100K ground truth data. The image also shows an input point (a yellow X) at the center of the green bounding box that we will refer to in the next few sections.

Let’s try to generate a mask for the car on the left with the green bounding box as an input to SAM. As shown in the following example, the base model of SAM doesn’t really find anything. This is also seen in the low segmentation score. When we look at the segmentation masks more closely, we see that there are small regions returned as masks (pointed at using red arrows) that aren’t really usable for any downstream application.

Let’s try a combination of a bounding box and a point as the input visual prompt. The yellow cross in the preceding image is the center of the bounding box. Providing this point’s (x,y) coordinates as the prompt along with the bounding box constraint gives us the following mask and a slightly higher score. This is still not usable by any means.

Finally, with the base pre-trained model, we can provide just the input point as a prompt (without the bounding box). The following images show two of the top three masks we thought were interesting.

Mask 1 segments the full car, whereas Mask 3 segments out an area that holds the car’s number plate close to the yellow cross (input prompt). Mask 1 is still not a tight, clean mask around the car; this points to the quality of the model, which we can assume increases with model size.
We can try larger pre-trained models with the same input prompt. The following images show our results. When using the huge SAM pre-trained model, Mask 3 is the entire car, whereas Mask 1 and 2 can be used to extract the number plate.

The large version of the SAM model also provides similar outputs.
The process we went through here is similar to manual prompt engineering for text prompts that you may already be familiar with. Note that a recent improvement in the SAM model to segment anything in high quality provides much better object- and context-specific outputs. In our case, we find that zero-shot prompting with text and visual prompts (point, box, and point and box inputs) don’t improve results drastically as we saw above.
Prompt templates and visual chains
As we can see from the preceding zero-shot examples, SAM struggles to identify all the objects in the scene. This is a good example of where we can take advantage of prompt templates and visual chains. Visual chain is inspired by the chain concept in the popular LangChain framework for language applications. It helps chain the data sources and an LLM to produce the output. For example, we can use an API chain to call an API and invoke an LLM to answer the question based on the API response.
Inspired by LangChain, we propose a sequential visual chain that looks like the following figure. We use a tool (like a pre-trained object detection model) to get initial bounding boxes, calculate the point at the center of the bounding box, and use this to prompt the SAM model with the input image.

For example, the following image shows the segmentation masks as a result of running this chain.

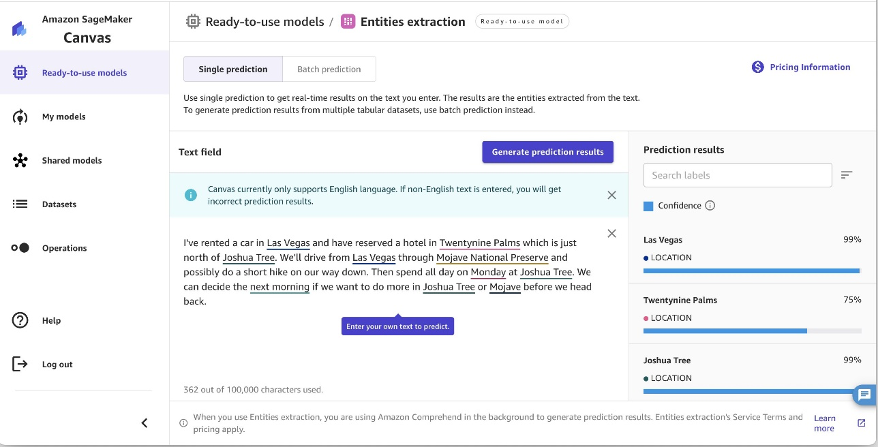
Another example chain can involve a text input of the object the user is interested in identifying. To implement this, we built a pipeline using Grounding DINO, an object detection model to prompt SAM for segmentation.

Grounding DINO is a zero-shot object detection model that can perform object detection with text providing category names (such as “traffic lights” or “truck”) and expressions (such as “yellow truck”). It accepts pairs of text and image to perform the object detection. It’s based on a transformer architecture and enables cross modalities with text and image data. To learn more about Grounding DINO, refer to Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection. This generates bounding boxes and labels and can be processed further to generate center points, filter based on labels, thresholds, and more. This is used (boxes or points) as a prompt to SAM for segmentation, which outputs masks.
The following are some examples showing the input text, DINO output (bounding boxes), and the final SAM output (segmentation masks).
The following images show the output for “yellow truck.”

The following images show the output for “silver car.”

The following image shows the output for “driving lane.”

We can use this pipeline to build a visual chain. The following code snippet explains this concept:
pipeline = [object_predictor, segment_predictor]
image_chain = ImageChain.from_visual_pipeline(pipeline, image_store, verbose=True)
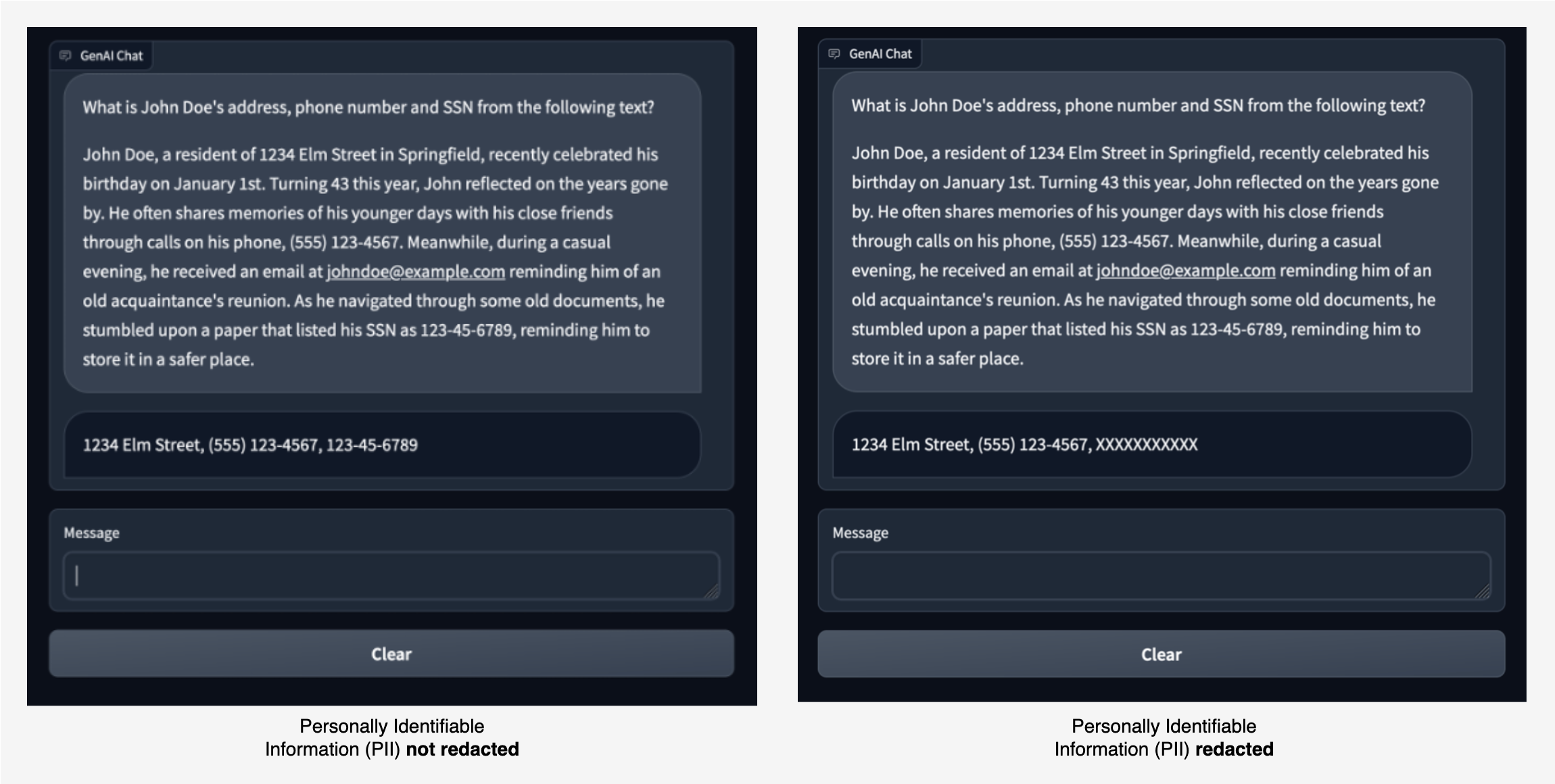
image_chain.run('All silver cars', image_id='5X3349')Although this is a simple example, this concept can be extended to process feeds from cameras on vehicles to perform object tracking, personally identifiable information (PII) data redaction, and more. We can also get the bounding boxes from smaller models, or in some cases, using standard computer vision tools. It’s fairly straightforward to use a pre-trained model or a service like Amazon Rekognition to get initial (visual) labels for your prompt. At the time of writing this, there are over 70 models available on Amazon SageMaker Jumpstart for object detection, and Amazon Rekognition already identifies several useful categories of objects in images, including cars, pedestrians, and other vehicles.
Next, we look at some quantitative results related to performance of SAM models with a subset of BDD100K data.
Quantitative results
Our objective is to compare the performance of three pre-trained models when given the same visual prompting. In this case, we use the center point of the object location as the visual input. We compare the performance with respect to the object sizes (in proportion to image size)— small (area <0.11%), medium (0.11% < area < 1%), and large (area > 1%). The bounding box area thresholds are defined by the Common Objects in Context (COCO) evaluation metrics [Lin et al., 2014].
The evaluation is at the pixel level and we use the following evaluation metrics:
- Precision = (number relevant and retrieved instances) / (total number of retrieved instances)
- Recall = (number of relevant and retrieve instances) / (total number of relevant instances)
- Instances here are each pixel within the bounding box of the object of interest
The following table reports the performance of three different versions of the SAM model (base, large, and huge). These versions have three different encoders: ViT-B (base), ViT-L (large), ViT-H (huge). The encoders have different parameter counts, where the base model has less parameters than large, and large is less than huge. Although increasing the number of parameters shows improved performance with larger objects, this is not so for smaller objects.

Fine-tuning SAM for your use case
In many cases, directly using a pre-trained SAM model may not be very useful. For example, let’s look at a typical scene in traffic—the following picture is the output from the SAM model with randomly sampled prompt points as input on the left, and the actual labels from the semantic segmentation task from BDD100K on the right. These are obviously very different.

Perception stacks in AVs can easily use the second image, but not the first. On the other hand, there some useful outputs from the first image that can be used, and that the model was not explicitly trained on, for example, lane markings, sidewalk segmentation, license plate masks, and so on. We can fine-tune the SAM model to improve the segmentation results. To perform this fine-tuning, we created a training dataset using an instance segmentation subset (500 images) from the BDD10K dataset. This is a very small subset of images, but our purpose is to prove that foundational vision models (much like LLMs) can perform well for your use case with a surprisingly small number of images. The following image shows the input image, output mask (in blue, with a red border for the car on the left), and possible prompts (bounding box in green and center point X in yellow).

We performed fine-tuning using the Hugging Face library on Amazon SageMaker Studio. We used the ml.g4dn.xlarge instance for the SAM base model tests, and the ml.g4dn.2xlarge for the SAM huge model tests. In our initial experiments, we observed that fine-tuning the base model with just bounding boxes was not successful. The fine-tuned and pre-trained models weren’t able to learn car-specific ground truth masks from the original datasets. Adding query points to the fine-tuning also didn’t improve the training.
Next, we can try fine-tuning the SAM huge model for 30 epochs, with a very small dataset (500 images). The original ground truth mask looks like the following image for the label type car.

As shown in the following images, the original pre-trained version of the huge model with a specific bounding box prompt (in green) gives no output, whereas the fine-tuned version gives an output (still not accurate but fine-tuning was cut off after 40 epochs, and with a very small training dataset of 500 images). The original, pre-trained huge model wasn’t able to predict masks for any of the images we tested. As an example downstream application, the fine-tuned model can be used in pre-labeling workflows such as the one described in Auto-labeling module for deep learning-based Advanced Driver Assistance Systems on AWS.

Conclusion
In this post, we discussed the foundational vision model known as the Segment Anything Model (SAM) and its architecture. We used the SAM model to discuss visual prompting and the various inputs to visual prompting engineering. We explored how different visual prompts perform and their limitations. We also described how visual chains increase performance over using just one prompt, similar to the LangChain API. Next, we provided a quantitative evaluation of three pre-trained models. Lastly, we discussed the fine-tuned SAM model and its results compared to the original base model. Fine-tuning of foundation models helps improve model performance for specific tasks like segmentation. It should be noted that SAM model due to its resource requirements, limits usage for real-time use-cases and inferencing at the edge in its current state. We hope with future iterations and improved techniques, would reduce compute requirements and improve latency.
It is our hope that this post encourages you to explore visual prompting for your use cases. Because this is still an emerging form of prompt engineering, there is much to discover in terms of visual prompts, visual chains, and performance of these tools. Amazon SageMaker is a fully managed ML platform that enables builders to explore large language and visual models and build generative AI applications. Start building the future with AWS today.
About the authors
 Gopi Krishnamurthy is a Senior AI/ML Solutions Architect at Amazon Web Services based in New York City. He works with large Automotive customers as their trusted advisor to transform their Machine Learning workloads and migrate to the cloud. His core interests include deep learning and serverless technologies. Outside of work, he likes to spend time with his family and explore a wide range of music.
Gopi Krishnamurthy is a Senior AI/ML Solutions Architect at Amazon Web Services based in New York City. He works with large Automotive customers as their trusted advisor to transform their Machine Learning workloads and migrate to the cloud. His core interests include deep learning and serverless technologies. Outside of work, he likes to spend time with his family and explore a wide range of music.
 Shreyas Subramanian is a Principal AI/ML specialist Solutions Architect, and helps customers by using Machine Learning to solve their business challenges using the AWS platform. Shreyas has a background in large scale optimization and Machine Learning, and in use of Machine Learning and Reinforcement Learning for accelerating optimization tasks.
Shreyas Subramanian is a Principal AI/ML specialist Solutions Architect, and helps customers by using Machine Learning to solve their business challenges using the AWS platform. Shreyas has a background in large scale optimization and Machine Learning, and in use of Machine Learning and Reinforcement Learning for accelerating optimization tasks.
 Sujitha Martin is an Applied Scientist in the Generative AI Innovation Center (GAIIC). Her expertise is in building machine learning solutions involving computer vision and natural language processing for various industry verticals. In particular, she has extensive experience working on human-centered situational awareness and knowledge infused learning for highly autonomous systems.
Sujitha Martin is an Applied Scientist in the Generative AI Innovation Center (GAIIC). Her expertise is in building machine learning solutions involving computer vision and natural language processing for various industry verticals. In particular, she has extensive experience working on human-centered situational awareness and knowledge infused learning for highly autonomous systems.
 Francisco Calderon is a Data Scientist in the Generative AI Innovation Center (GAIIC). As a member of the GAIIC, he helps discover the art of the possible with AWS customers using Generative AI technologies. In his spare time, Francisco likes to play music and guitar, playing soccer with his daughters, and enjoying time with his family.
Francisco Calderon is a Data Scientist in the Generative AI Innovation Center (GAIIC). As a member of the GAIIC, he helps discover the art of the possible with AWS customers using Generative AI technologies. In his spare time, Francisco likes to play music and guitar, playing soccer with his daughters, and enjoying time with his family.






 Xin Huang is a Senior Applied Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on developing scalable machine learning algorithms. His research interests are in the area of natural language processing, explainable deep learning on tabular data, and robust analysis of non-parametric space-time clustering. He has published many papers in ACL, ICDM, KDD conferences, and Royal Statistical Society: Series A.
Xin Huang is a Senior Applied Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on developing scalable machine learning algorithms. His research interests are in the area of natural language processing, explainable deep learning on tabular data, and robust analysis of non-parametric space-time clustering. He has published many papers in ACL, ICDM, KDD conferences, and Royal Statistical Society: Series A. Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker built-in algorithms and helps develop machine learning algorithms. He got his PhD from University of Illinois Urbana-Champaign. He is an active researcher in machine learning and statistical inference, and has published many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.
Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker built-in algorithms and helps develop machine learning algorithms. He got his PhD from University of Illinois Urbana-Champaign. He is an active researcher in machine learning and statistical inference, and has published many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.







 James Wu is a Senior AI/ML Specialist Solution Architect at AWS. helping customers design and build AI/ML solutions. James’s work covers a wide range of ML use cases, with a primary interest in computer vision, deep learning, and scaling ML across the enterprise. Prior to joining AWS, James was an architect, developer, and technology leader for over 10 years, including 6 years in engineering and 4 years in marketing & advertising industries.
James Wu is a Senior AI/ML Specialist Solution Architect at AWS. helping customers design and build AI/ML solutions. James’s work covers a wide range of ML use cases, with a primary interest in computer vision, deep learning, and scaling ML across the enterprise. Prior to joining AWS, James was an architect, developer, and technology leader for over 10 years, including 6 years in engineering and 4 years in marketing & advertising industries. Pranav Murthy is an AI/ML Specialist Solutions Architect at AWS. He focuses on helping customers build, train, deploy and migrate machine learning (ML) workloads to SageMaker. He previously worked in the semiconductor industry developing large computer vision (CV) and natural language processing (NLP) models to improve semiconductor processes. In his free time, he enjoys playing chess and traveling.
Pranav Murthy is an AI/ML Specialist Solutions Architect at AWS. He focuses on helping customers build, train, deploy and migrate machine learning (ML) workloads to SageMaker. He previously worked in the semiconductor industry developing large computer vision (CV) and natural language processing (NLP) models to improve semiconductor processes. In his free time, he enjoys playing chess and traveling. Mecit Gungor is an AI/ML Specialist Solution Architect at AWS helping customers design and build AI/ML solutions at scale. He covers a wide range of AI/ML use cases for Telecommunication customers and currently focuses on Generative AI, LLMs, and training and inference optimization. He can often be found hiking in the wilderness or playing board games with his friends in his free time.
Mecit Gungor is an AI/ML Specialist Solution Architect at AWS helping customers design and build AI/ML solutions at scale. He covers a wide range of AI/ML use cases for Telecommunication customers and currently focuses on Generative AI, LLMs, and training and inference optimization. He can often be found hiking in the wilderness or playing board games with his friends in his free time. Shelbee Eigenbrode is a Principal AI and Machine Learning Specialist Solutions Architect at Amazon Web Services (AWS). She has been in technology for 24 years spanning multiple industries, technologies, and roles. She is currently focusing on combining her DevOps and ML background into the domain of MLOps to help customers deliver and manage ML workloads at scale. With over 35 patents granted across various technology domains, she has a passion for continuous innovation and using data to drive business outcomes. Shelbee is a co-creator and instructor of the Practical Data Science specialization on Coursera. She is also the Co-Director of Women In Big Data (WiBD), Denver chapter. In her spare time, she likes to spend time with her family, friends, and overactive dogs.
Shelbee Eigenbrode is a Principal AI and Machine Learning Specialist Solutions Architect at Amazon Web Services (AWS). She has been in technology for 24 years spanning multiple industries, technologies, and roles. She is currently focusing on combining her DevOps and ML background into the domain of MLOps to help customers deliver and manage ML workloads at scale. With over 35 patents granted across various technology domains, she has a passion for continuous innovation and using data to drive business outcomes. Shelbee is a co-creator and instructor of the Practical Data Science specialization on Coursera. She is also the Co-Director of Women In Big Data (WiBD), Denver chapter. In her spare time, she likes to spend time with her family, friends, and overactive dogs.

 Cristian Marquez is a Senior Cloud Application Architect. He has vast experience designing, building, and delivering enterprise-level software, high load and distributed systems and cloud native applications. He has experience in backend and frontend programming languages, as well as system design and implementation of DevOps practices. He actively assists customers build and secure innovative cloud solutions, solving their business problems and achieving their business goals.
Cristian Marquez is a Senior Cloud Application Architect. He has vast experience designing, building, and delivering enterprise-level software, high load and distributed systems and cloud native applications. He has experience in backend and frontend programming languages, as well as system design and implementation of DevOps practices. He actively assists customers build and secure innovative cloud solutions, solving their business problems and achieving their business goals. Anand Komandooru is a Senior Cloud Architect at AWS. He joined AWS Professional Services organization in 2021 and helps customers build cloud-native applications on AWS cloud. He has over 20 years of experience building software and his favorite Amazon leadership principle is “
Anand Komandooru is a Senior Cloud Architect at AWS. He joined AWS Professional Services organization in 2021 and helps customers build cloud-native applications on AWS cloud. He has over 20 years of experience building software and his favorite Amazon leadership principle is “




 Antonia Wiebeler is a Data Scientist at the AWS Generative AI Innovation Center, where she enjoys building proofs of concept for customers. Her passion is exploring how generative AI can solve real-world problems and create value for customers. While she is not coding, she enjoys running and competing in triathlons.
Antonia Wiebeler is a Data Scientist at the AWS Generative AI Innovation Center, where she enjoys building proofs of concept for customers. Her passion is exploring how generative AI can solve real-world problems and create value for customers. While she is not coding, she enjoys running and competing in triathlons. Nikita Kozodoi is an Applied Scientist at the AWS Generative AI Innovation Center, where he develops ML solutions to solve customer problems across industries. In his role, he focuses on advancing generative AI to tackle real-world challenges. In his spare time, he loves playing beach volleyball and reading.
Nikita Kozodoi is an Applied Scientist at the AWS Generative AI Innovation Center, where he develops ML solutions to solve customer problems across industries. In his role, he focuses on advancing generative AI to tackle real-world challenges. In his spare time, he loves playing beach volleyball and reading.





 Julia Ang is a Solutions Architect based in Singapore. She has worked with customers in a range of fields, from health and public sector to digital native businesses, to adopt solutions according to their business needs. She has also been supporting customers in Southeast Asia and beyond to use AI & ML in their businesses. Outside of work, she enjoys learning about the world through traveling and engaging in creative pursuits.
Julia Ang is a Solutions Architect based in Singapore. She has worked with customers in a range of fields, from health and public sector to digital native businesses, to adopt solutions according to their business needs. She has also been supporting customers in Southeast Asia and beyond to use AI & ML in their businesses. Outside of work, she enjoys learning about the world through traveling and engaging in creative pursuits. Loke Jun Kai is a Specialist Solutions Architect for AI/ML based in Singapore. He works with customer across ASEAN to architect machine learning solutions at scale in AWS. Jun Kai is an advocate for Low-Code No-Code machine learning tools. In his spare time, he enjoys being with the nature.
Loke Jun Kai is a Specialist Solutions Architect for AI/ML based in Singapore. He works with customer across ASEAN to architect machine learning solutions at scale in AWS. Jun Kai is an advocate for Low-Code No-Code machine learning tools. In his spare time, he enjoys being with the nature.