Enforcing a hierarchical clustering of semantically related labels improves performance on rare “long-tail” classification categories.Read More

Instruction fine-tuning for FLAN T5 XL with Amazon SageMaker Jumpstart
Generative AI is in the midst of a period of stunning growth. Increasingly capable foundation models are being released continuously, with large language models (LLMs) being one of the most visible model classes. LLMs are models composed of billions of parameters trained on extensive corpora of text, up to hundreds of billions or even a trillion tokens. These models have proven extremely effective for a wide range of text-based tasks, from question answering to sentiment analysis.
The power of LLMs comes from their capacity to learn and generalize from extensive and diverse training data. The initial training of these models is performed with a variety of objectives, supervised, unsupervised, or hybrid. Text completion or imputation is one of the most common unsupervised objectives: given a chunk of text, the model learns to accurately predict what comes next (for example, predict the next sentence). Models can also be trained in a supervised fashion using labeled data to accomplish a set of tasks (for example, is this movie review positive, negative, or neutral). Whether the model is trained for text completion or some other task, it is frequently not the task customers want to use the model for.
To improve the performance of a pre-trained LLM on a specific task, we can tune the model using examples of the target task in a process known as instruction fine-tuning. Instruction fine-tuning uses a set of labeled examples in the form of {prompt, response} pairs to further train the pre-trained model in adequately predicting the response given the prompt. This process modifies the weights of the model.
This post describes how to perform instruction fine-tuning of an LLM, namely FLAN T5 XL, using Amazon SageMaker Jumpstart. We demonstrate how to accomplish this using both the Jumpstart UI and a notebook in Amazon SageMaker Studio. You can find the accompanying notebook in the amazon-sagemaker-examples GitHub repository.
Solution overview
The target task in this post is to, given a chunk of text in the prompt, return questions that are related to the text but can’t be answered based on the information it contains. This is a useful task to identify missing information in a description or identify whether a query needs more information to be answered.
FLAN T5 models are instruction fine-tuned on a wide range of tasks to increase the zero-shot performance of these models on many common tasks[1]. Additional instruction fine-tuning for a particular customer task can further increase the accuracy of these models, especially if the target task wasn’t previously used to train a FLAN T5 model, as is the case for our task.
In our example task, we’re interested in generating relevant but unanswered questions. To this end, we use a subset of the version 2 of the Stanford Question Answering Dataset (SQuAD2.0)[2] to fine-tune the model. This dataset contains questions posed by human annotators on a set of Wikipedia articles. In addition to questions with answers, SQuAD2.0 contains about 50,000 unanswerable questions. Such questions are plausible but can’t be directly answered from articles’ content. We only use the unanswerable questions. Our data is structured as a JSON Lines file, with each line containing a context and a question.

Prerequisites
To get started, all you need is an AWS account in which you can use Studio. You will need to create a user profile for Studio if you don’t already have one.
Fine-tune FLAN-T5 with the Jumpstart UI
To fine-tune the model with the Jumpstart UI, complete the following steps:
- On the SageMaker console, open Studio.
- Under SageMaker Jumpstart in the navigation pane, choose Models, notebooks, solutions.
You will see a list of foundation models, including FLAN T5 XL, which is marked as fine-tunable.
- Choose View model.
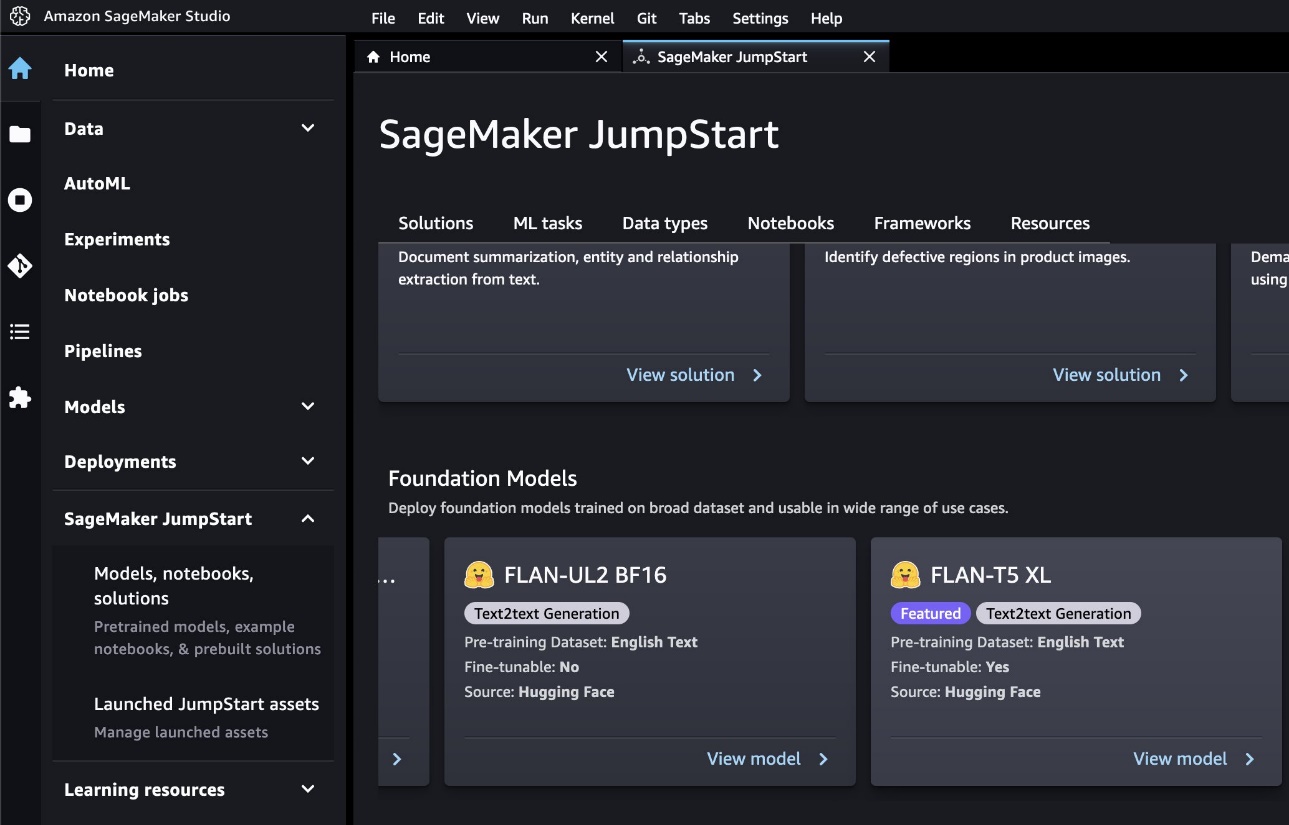
- Under Data source, you can provide the path to your training data. The source for the data used in this post is provided by default.
- You can keep the default value for the deployment configuration (including instance type), security, and the hyperparameters, but you should increase the number of epochs to at least three to get good results.
- Choose Train to train the model.
You can track the status of the training job in the UI.
- When training is complete (after about 53 minutes in our case), choose Deploy to deploy the fine-tuned model.

After the endpoint is created (a few minutes), you can open a notebook and start using your fine-tuned model.
Fine-tune FLAN-T5 using a Python notebook
Our example notebook shows how to use Jumpstart and SageMaker to programmatically fine-tune and deploy a FLAN T5 XL model. It can be run in Studio or locally.
In this section, we first walk through some general setup. Then you fine-tune the model using the SQuADv2 datasets. Next, you deploy the pre-trained version of the model behind a SageMaker endpoint, and do the same with the fine-tuned model. Finally, you can query the endpoints and compare the quality of the output of the pre-trained and fine-tuned model. You will find that the output of the fine-tuned model is of much higher quality.
Set up prerequisites
Begin by installing and upgrading the necessary packages. Restart the kernel after running the following code:
Next, obtain the execution role associated with the current notebook instance:
You can define a convenient drop-down menu that will list the model sizes available for fine-tuning:
Jumpstart automatically retrieves appropriate training and inference instance types for the model that you chose:
You’re now ready to start fine-tuning.
Retrain the model on the fine-tuning dataset
After your setup is complete, complete the following steps:
Use the following code to retrieve the URI for the artifacts needed:
The training data is located in a public Amazon Simple Storage Service (Amazon S3) bucket.
Use the following code to point to the location of the data and set up the output location in a bucket in your account:
The original data is not in a format that corresponds to the task for which you are fine-tuning the model, so you can reformat it:
Now you can define some hyperparameters for the training:
You are now ready to launch the training job:
Depending on the size of the fine-tuning data and model chosen, the fine-tuning could take up to a couple of hours.
You can monitor performance metrics such as training and validation loss using Amazon CloudWatch during training. Conveniently, you can also fetch the most recent snapshot of metrics by running the following code:
When the training is complete, you have a fine-tuned model at model_uri. Let’s use it!
You can create two inference endpoints: one for the original pre-trained model, and one for the fine-tuned model. This allows you to compare the output of both versions of the model. In the next step, you deploy an inference endpoint for the pre-trained model. Then you deploy an endpoint for your fine-tuned model.
Deploy the pre-trained model
Let’s start by deploying the pre-trained model retrieve the inference Docker image URI. This is the base Hugging Face container image. Use the following code:
You can now create the endpoint and deploy the pre-trained model. Note that you need to pass the Predictor class when deploying model through the Model class to be able to run inference through the SageMaker API. See the following code:
The endpoint creation and model deployment can take a few minutes, then your endpoint is ready to receive inference calls.
Deploy the fine-tuned model
Let’s deploy the fine-tuned model to its own endpoint. The process is almost identical to the one we used earlier for the pre-trained model. The only difference is that we use the fine-tuned model name and URI:
When this process is complete, both pre-trained and fine-tuned models are deployed behind their own endpoints. Let’s compare their outputs.
Generate output and compare the results
Define some utility functions to query the endpoint and parse the response:
In the next code snippet, we define the prompt and the test data. The describes our target task, which is to generate questions that are related to the provided text but can’t be answered based on it.
The test data consists of three different paragraphs, one on the Australian city of Adelaide from the first two paragraphs of it Wikipedia page, one regarding Amazon Elastic Block Store (Amazon EBS) from the Amazon EBS documentation, and one of Amazon Comprehend from the Amazon Comprehend documentation. We expect the model to identify questions related to these paragraphs but that can’t be answered with the information provided therein.
You can now test the endpoints using the example articles
Test data: Adelaide
We use the following context:
The pre-trained model response is as follows:
The fine-tuned model responses are as follows:
Test data: Amazon EBS
We use the following context:
The pre-trained model responses are as follows:
The fine-tuned model responses are as follows:
Test data: Amazon Comprehend
We use the following context:
The pre-trained model responses are as follows:
The fine-tuned model responses are as follows:
The difference in output quality between the pre-trained model and the fine-tuned model is stark. The questions provided by the fine-tuned model touch on a wider range of topics. They are systematically meaningful questions, which isn’t always the case for the pre-trained model, as illustrated with the Amazon EBS example.
Although this doesn’t constitute a formal and systematic evaluation, it’s clear that the fine-tuning process has improved the quality of the model’s responses on this task.
Clean up
Lastly, remember to clean up and delete the endpoints:
Conclusion
In this post, we showed how to use instruction fine-tuning with FLAN T5 models using the Jumpstart UI or a Jupyter notebook running in Studio. We provided code explaining how to retrain the model using data for the target task and deploy the fine-tuned model behind an endpoint. The target task in this post was to identify questions that relate to a chunk of text provided in the input but can’t be answered based on the information provided in that text. We demonstrated that a model fine-tuned for this specific task returns better results than a pre-trained model.
Now that you know how to instruction fine-tune a model with Jumpstart, you can create powerful models customized for your application. Gather some data for your use case, uploaded it to Amazon S3, and use either the Studio UI or the notebook to tune a FLAN T5 model!
References
[1] Chung, Hyung Won, et al. “Scaling instruction-fine tuned language models.” arXiv preprint arXiv:2210.11416 (2022). [2] Rajpurkar, Pranav, Robin Jia, and Percy Liang. “Know What You Don’t Know: Unanswerable Questions for SQuAD.” Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2018.About the authors
 Laurent Callot is a Principal Applied Scientist and manager at AWS AI Labs who has worked on a variety of machine learning problems, from foundational models and generative AI to forecasting, anomaly detection, causality, and AI Ops.
Laurent Callot is a Principal Applied Scientist and manager at AWS AI Labs who has worked on a variety of machine learning problems, from foundational models and generative AI to forecasting, anomaly detection, causality, and AI Ops.
![]() Andrey Kan is a Senior Applied Scientist at AWS AI Labs within interests and experience in different fields of Machine Learning. These include research on foundation models, as well as ML applications for graphs and time series.
Andrey Kan is a Senior Applied Scientist at AWS AI Labs within interests and experience in different fields of Machine Learning. These include research on foundation models, as well as ML applications for graphs and time series.
 Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker built-in algorithms and helps develop machine learning algorithms. He got his PhD from University of Illinois Urbana Champaign. He is an active researcher in machine learning and statistical inference and has published many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.
Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker built-in algorithms and helps develop machine learning algorithms. He got his PhD from University of Illinois Urbana Champaign. He is an active researcher in machine learning and statistical inference and has published many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.
 Baris Kurt is an Applied Scientist at AWS AI Labs. His interests are in time series anomaly detection and foundation models. He loves developing user friendly ML systems.
Baris Kurt is an Applied Scientist at AWS AI Labs. His interests are in time series anomaly detection and foundation models. He loves developing user friendly ML systems.
 Jonas Kübler is an Applied Scientist at AWS AI Labs. He is working on foundation models with the goal to facilitate use-case specific applications.
Jonas Kübler is an Applied Scientist at AWS AI Labs. He is working on foundation models with the goal to facilitate use-case specific applications.
How Amazon’s delivery network bridges cities and rural areas
Amazon scientists use a combination of data, machine learning, and algorithm design to meet last-mile delivery challenges.Read More
Introducing an image-to-speech Generative AI application using Amazon SageMaker and Hugging Face
Vision loss comes in various forms. For some, it’s from birth, for others, it’s a slow descent over time which comes with many expiration dates: The day you can’t see pictures, recognize yourself, or loved ones faces or even read your mail. In our previous blogpost Enable the Visually Impaired to Hear Documents using Amazon Textract and Amazon Polly, we showed you our Text to Speech application called “Read for Me”. Accessibility has come a long way, but what about images?
At the 2022 AWS re:Invent conference in Las Vegas, we demonstrated “Describe for Me” at the AWS Builders’ Fair, a website which helps the visually impaired understand images through image caption, facial recognition, and text-to-speech, a technology we refer to as “Image to Speech.” Through the use of multiple AI/ML services, “Describe For Me” generates a caption of an input image and will read it back in a clear, natural-sounding voice in a variety of languages and dialects.
In this blog post we walk you through the Solution Architecture behind “Describe For Me”, and the design considerations of our solution.
Solution Overview
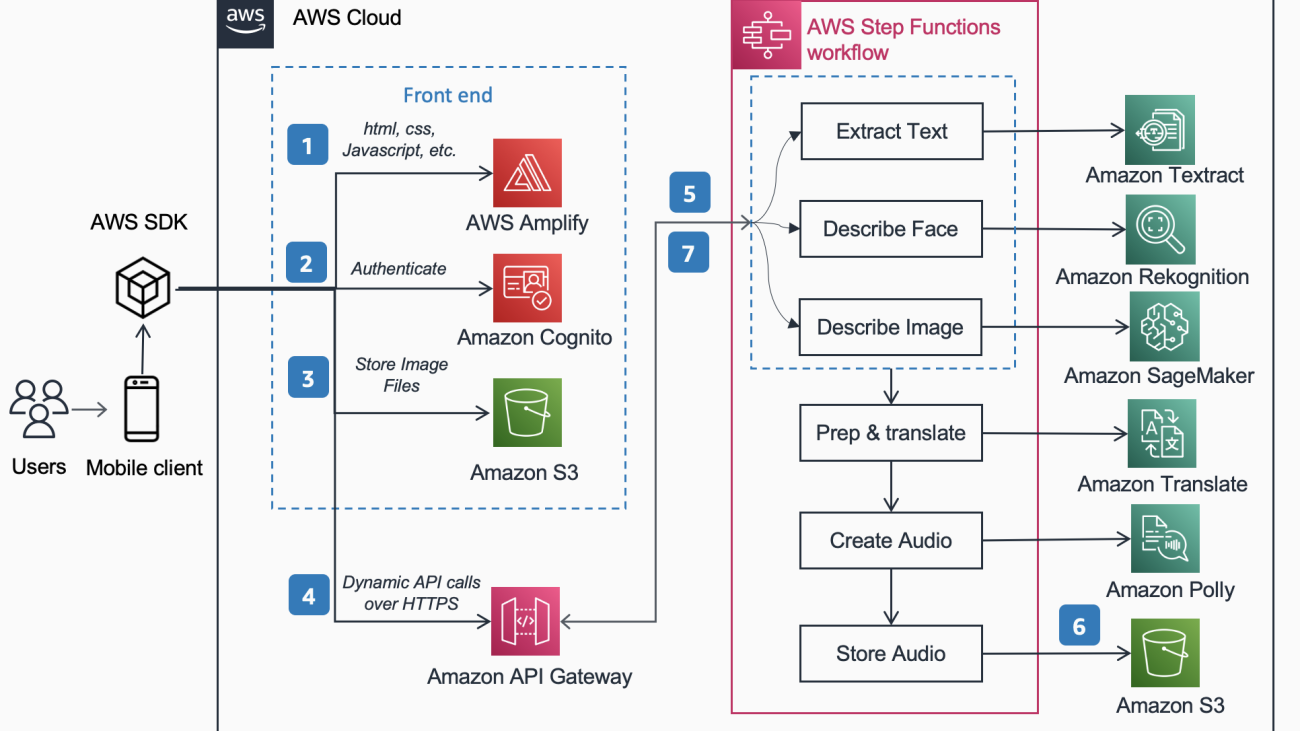
The following Reference Architecture shows the workflow of a user taking a picture with a phone and playing an MP3 of the captioning the image.

The workflow includes the below steps,
- AWS Amplify distributes the DescribeForMe web app consisting of HTML, JavaScript, and CSS to end users’ mobile devices.
- The Amazon Cognito Identity pool grants temporary access to the Amazon S3 bucket.
- The user uploads an image file to the Amazon S3 bucket using AWS SDK through the web app.
- The DescribeForMe web app invokes the backend AI services by sending the Amazon S3 object Key in the payload to Amazon API Gateway
- Amazon API Gateway instantiates an AWS Step Functions workflow. The state Machine orchestrates the Artificial Intelligence /Machine Learning (AI/ML) services Amazon Rekognition, Amazon SageMaker, Amazon Textract, Amazon Translate, and Amazon Polly using AWS lambda functions.
- The AWS Step Functions workflow creates an audio file as output and stores it in Amazon S3 in MP3 format.
- A pre-signed URL with the location of the audio file stored in Amazon S3 is sent back to the user’s browser through Amazon API Gateway. The user’s mobile device plays the audio file using the pre-signed URL.
Solution Walkthrough
In this section, we focus on the design considerations for why we chose
- parallel processing within an AWS Step Functions workflow
- unified sequence-to-sequence pre-trained machine learning model OFA (One For All) from Hugging Face to Amazon SageMaker for image caption
- Amazon Rekognition for facial recognition
For a more detailed overview of why we chose a serverless architecture, synchronous workflow, express step functions workflow, headless architecture and the benefits gained, please read our previous blog post Enable the Visually Impaired to Hear Documents using Amazon Textract and Amazon Polly.
Parallel Processing
Using parallel processing within the Step Functions workflow reduced compute time up to 48%. Once the user uploads the image to the S3 bucket, Amazon API Gateway instantiates an AWS Step Functions workflow. Then the below three Lambda functions process the image within the Step Functions workflow in parallel.
- The first Lambda function called
describe_imageanalyzes the image using the OFA_IMAGE_CAPTION model hosted on a SageMaker real-time endpoint to provide image caption. - The second Lambda function called
describe_facesfirst checks if there are faces using Amazon Rekognition’s Detect Faces API, and if true, it calls the Compare Faces API. The reason for this is Compare Faces will throw an error if there are no faces found in the image. Also, calling Detect Faces first is faster than simply running Compare Faces and handling errors, so for images without faces in them, processing time will be faster. - The third Lambda function called
extract_texthandles text-to-speech utilizing Amazon Textract, and Amazon Comprehend.
Executing the Lambda functions in succession is suitable, but the faster, more efficient way of doing this is through parallel processing. The following table shows the compute time saved for three sample images.
| Image | People | Sequential Time | Parallel Time | Time Savings (%) | Caption |
 |
0 | 1869ms | 1702ms | 8% | A tabby cat curled up in a fluffy white bed. |
 |
1 | 4277ms | 2197ms | 48% | A woman in a green blouse and black cardigan smiles at the camera. I recognize one person: Kanbo. |
 |
4 | 6603ms | 3904ms | 40% | People standing in front of the Amazon Spheres. I recognize 3 people: Kanbo, Jack, and Ayman. |
Image Caption
Hugging Face is an open-source community and data science platform that allows users to share, build, train, and deploy machine learning models. After exploring models available in the Hugging Face model hub, we chose to use the OFA model because as described by the authors, it is “a task-agnostic and modality-agnostic framework that supports Task Comprehensiveness”.
OFA is a step towards “One For All”, as it is a unified multimodal pre-trained model that can transfer to a number of downstream tasks effectively. While the OFA model supports many tasks including visual grounding, language understanding, and image generation, we used the OFA model for image captioning in the Describe For Me project to perform the image to text portion of the application. Check out the official repository of OFA (ICML 2022), paper to learn about OFA’s Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework.
To integrate OFA in our application we cloned the repo from Hugging Face and containerized the model to deploy it to a SageMaker endpoint. The notebook in this repo is an excellent guide to deploy the OFA large model in a Jupyter notebook in SageMaker. After containerizing your inference script, the model is ready to be deployed behind a SageMaker endpoint as described in the SageMaker documentation. Once the model is deployed, create an HTTPS endpoint which can be integrated with the “describe_image” lambda function that analyzes the image to create the image caption. We deployed the OFA tiny model because it is a smaller model and can be deployed in a shorter period of time while achieving similar performance.
Examples of image to speech content generated by “Describe For Me“ are shown below:

The aurora borealis, or northern lights, fill the night sky above a silhouette of a house..

A dog sleeps on a red blanket on a hardwood floor, next to an open suitcase filled with toys..

A tabby cat curled up in a fluffy white bed.
Facial recognition
Amazon Rekognition Image provides the DetectFaces operation that looks for key facial features such as eyes, nose, and mouth to detect faces in an input image. In our solution we leverage this functionality to detect any people in the input image. If a person is detected, we then use the CompareFaces operation to compare the face in the input image with the faces that “Describe For Me“ has been trained with and describe the person by name. We chose to use Rekognition for facial detection because of the high accuracy and how simple it was to integrate into our application with the out of the box capabilities.

A group of people posing for a picture in a room. I recognize 4 people: Jack, Kanbo, Alak, and Trac. There was text found in the image as well. It reads: AWS re: Invent
Potential Use Cases
Alternate Text Generation for web images
All images on a web site are required to have an alternative text so that screen readers can speak them to the visually impaired. It’s also good for search engine optimization (SEO). Creating alt captions can be time consuming as a copywriter is tasked with providing them within a design document. The Describe For Me API could automatically generate alt-text for images. It could also be utilized as a browser plugin to automatically add image caption to images missing alt text on any website.
Audio Description for Video
Audio Description provides a narration track for video content to help the visually impaired follow along with movies. As image caption becomes more robust and accurate, a workflow involving the creation of an audio track based upon descriptions for key parts of a scene could be possible. Amazon Rekognition can already detect scene changes, logos, and credit sequences, and celebrity detection. A future version of describe would allow for automating this key feature for films and videos.
Conclusion
In this post, we discussed how to use AWS services, including AI and serverless services, to aid the visually impaired to see images. You can learn more about the Describe For Me project and use it by visiting describeforme.com. Learn more about the unique features of Amazon SageMaker, Amazon Rekognition and the AWS partnership with Hugging Face.
Third Party ML Model Disclaimer for Guidance
This guidance is for informational purposes only. You should still perform your own independent assessment, and take measures to ensure that you comply with your own specific quality control practices and standards, and the local rules, laws, regulations, licenses and terms of use that apply to you, your content, and the third-party Machine Learning model referenced in this guidance. AWS has no control or authority over the third-party Machine Learning model referenced in this guidance, and does not make any representations or warranties that the third-party Machine Learning model is secure, virus-free, operational, or compatible with your production environment and standards. AWS does not make any representations, warranties or guarantees that any information in this guidance will result in a particular outcome or result.
About the Authors
 Jack Marchetti is a Senior Solutions architect at AWS focused on helping customers modernize and implement serverless, event-driven architectures. Jack is legally blind and resides in Chicago with his wife Erin and cat Minou. He also is a screenwriter, and director with a primary focus on Christmas movies and horror. View Jack’s filmography at his IMDb page.
Jack Marchetti is a Senior Solutions architect at AWS focused on helping customers modernize and implement serverless, event-driven architectures. Jack is legally blind and resides in Chicago with his wife Erin and cat Minou. He also is a screenwriter, and director with a primary focus on Christmas movies and horror. View Jack’s filmography at his IMDb page.
 Alak Eswaradass is a Senior Solutions Architect at AWS based in Chicago, Illinois. She is passionate about helping customers design cloud architectures utilizing AWS services to solve business challenges. Alak is enthusiastic about using SageMaker to solve a variety of ML use cases for AWS customers. When she’s not working, Alak enjoys spending time with her daughters and exploring the outdoors with her dogs.
Alak Eswaradass is a Senior Solutions Architect at AWS based in Chicago, Illinois. She is passionate about helping customers design cloud architectures utilizing AWS services to solve business challenges. Alak is enthusiastic about using SageMaker to solve a variety of ML use cases for AWS customers. When she’s not working, Alak enjoys spending time with her daughters and exploring the outdoors with her dogs.
 Kandyce Bohannon is a Senior Solutions Architect based out of Minneapolis, MN. In this role, Kandyce works as a technical advisor to AWS customers as they modernize technology strategies especially related to data and DevOps to implement best practices in AWS. Additionally, Kandyce is passionate about mentoring future generations of technologists and showcasing women in technology through the AWS She Builds Tech Skills program.
Kandyce Bohannon is a Senior Solutions Architect based out of Minneapolis, MN. In this role, Kandyce works as a technical advisor to AWS customers as they modernize technology strategies especially related to data and DevOps to implement best practices in AWS. Additionally, Kandyce is passionate about mentoring future generations of technologists and showcasing women in technology through the AWS She Builds Tech Skills program.
 Trac Do is a Solutions Architect at AWS. In his role, Trac works with enterprise customers to support their cloud migrations and application modernization initiatives. He is passionate about learning customers’ challenges and solving them with robust and scalable solutions using AWS services. Trac currently lives in Chicago with his wife and 3 boys. He is a big aviation enthusiast and in the process of completing his Private Pilot License.
Trac Do is a Solutions Architect at AWS. In his role, Trac works with enterprise customers to support their cloud migrations and application modernization initiatives. He is passionate about learning customers’ challenges and solving them with robust and scalable solutions using AWS services. Trac currently lives in Chicago with his wife and 3 boys. He is a big aviation enthusiast and in the process of completing his Private Pilot License.
Making machine translation more robust, consistent, and stable
Training on pseudo-labeled data limits the consequences of slight input variations and prevents updated models from backsliding on particular tasks.Read More

Announcing the updated Microsoft SharePoint connector (V2.0) for Amazon Kendra
Amazon Kendra is a highly accurate and simple-to-use intelligent search service powered by machine learning (ML). Amazon Kendra offers a suite of data source connectors to simplify the process of ingesting and indexing your content, wherever it resides.
Valuable data in organizations is stored in both structured and unstructured repositories. Amazon Kendra can pull together data across several structured and unstructured knowledge base repositories to index and search on.
One such knowledge base repository is Microsoft SharePoint, and we are excited to announce that we have updated the SharePoint connector for Amazon Kendra to add even more capabilities. In this new version (V2.0), we have added support for SharePoint Subscription Edition and multiple authentication and sync modes to index contents based on new, modified, or deleted contents.
You can now also choose OAuth 2.0 to authenticate with SharePoint Online. Multiple synchronization options are available to update your index when your data source content changes. You can filter the search results based on the user and group information to ensure your search results are only shown based on user access rights.
In this post, we demonstrate how to index content from SharePoint using the Amazon Kendra SharePoint connector V2.0.
Solution overview
You can use Amazon Kendra as a central location to index the content provided by various data sources for intelligent search. In the following sections, we go through the steps to create an index, add the SharePoint connector, and test the solution.
Prerequisites
To get started, you need the following:
- A SharePoint (Server or Online) user with owner rights.
- An AWS account with privileges to create AWS Identity and Access Management (IAM) roles and policies. For more information, see Overview of access management: Permissions and policies.
- Basic knowledge of AWS.
Create an Amazon Kendra Index
To create an Amazon Kendra index, complete the following steps:
- On the Amazon Kendra console, choose Create an index.

- For Index name, enter a name for the index (for example,
my-sharepoint-index). - Enter an optional description.
- Choose Create a new role.
- For Role name, enter an IAM role name.
- Configure optional encryption settings and tags.
- Choose Next.

- For Access control settings, choose Yes.
- For Token configuration, set Token type to JSON and leave the default values for Username and Groups.
- For User-group expansion, leave the defaults.
- Choose Next.

- For Specify provisioning, select Developer edition, which is suited for building a proof of concept and experimentation, and choose Create.

Add a SharePoint data source to your Amazon Kendra index
One of the advantages of implementing Amazon Kendra is that you can use a set of pre-built connectors for data sources such as Amazon Simple Storage Service (Amazon S3), Amazon Relational Database Service (Amazon RDS), SharePoint Online, and Salesforce.
To add a SharePoint data source to your index, complete the following steps:
- On the Amazon Kendra console, navigate to the index that you created.
- Choose Data sources in the navigation pane.
- Under SharePoint Connector V2.0, choose Add connector.

- For Data source name, enter a name (for example,
my-sharepoint-data-source). - Enter an optional description.
- Choose English (en) for Default language.
- Enter optional tags.
- Choose Next.

Depending on the hosting option your SharePoint application is using, pick the appropriate hosting method. The required attributes for the connector configuration appear based on the hosting method you choose.
- If you select SharePoint Online, complete the following steps:
- Enter the URL for your SharePoint Online repository.

- Choose your authentication option (these authentication details will be used by the SharePoint connector to integrate with your SharePoint application).
- Enter the tenant ID of your SharePoint Online application.
- For AWS Secrets Manager secret, pick the secret that has SharePoint Online application credentials or create a new secret and add the connection details (for example,
AmazonKendra-SharePoint-my-sharepoint-online-secret).
- Enter the URL for your SharePoint Online repository.
To learn more about AWS Secrets Manger, refer to Getting started with Secrets Manager.
The SharePoint connector uses the clientId, clientSecret, userName, and password information to authenticate with the SharePoint Online application. These details can be accessed on the App registrations page on the Azure portal, if the SharePoint Online application is already registered.

- If you select SharePoint Server, complete the following steps:
- Choose your SharePoint version (for example, we use SharePoint 2019 for this post).
- Enter the site URL for your SharePoint Server repository.
- For SSL certificate location, enter the path to the S3 bucket file where the SharePoint Server SSL certificate is located.

- Enter the web proxy host name and the port number details if the SharePoint server requires a proxy connection.
For this post, no web proxy is used because the SharePoint application used for this example is a public-facing application.
-
- Select the authorization option for the Access Control List (ACL) configuration.

- Select the authorization option for the Access Control List (ACL) configuration.
These authentication details will be used by the SharePoint connector to integrate with your SharePoint instance.
- For AWS Secrets Manager secret, choose the secret that has SharePoint Server credentials or create a new secret and add the connection details (for example,
AmazonKendra-my-sharepoint-server-secret).
The SharePoint connector uses the user name and password information to authenticate with the SharePoint Server application. If you use an email ID with domain form IDP as the ACL setting, the LDAP server endpoint, search base, LDAP user name, and LDAP password are also required.
To achieve a granular level of control over the searchable and displayable content, identity crawler functionality is introduced in the SharePoint connector V2.0.
- Enable the identity crawler and select Crawl Local Group Mapping and Crawl AD Group Mapping.

- For Virtual Private Cloud (VPC), choose the VPC through which the SharePoint application is reachable from your SharePoint connector.
For this post, we choose No VPC because the SharePoint application used for this example is a public-facing application deployed on Amazon Elastic Compute Cloud (Amazon EC2) instances.
- Chose Create a new role (Recommended) and provide a role name, such as
AmazonKendra-sharepoint-v2. - Choose Next.

- Select entities that you would like to include for indexing. You can choose All or specific entities based on your use case. For this post, we choose All.
You can also include or exclude documents by using regular expressions. You can define patterns that Amazon Kendra either uses to exclude certain documents from indexing or include only documents with that pattern. For more information, refer to SharePoint Configuration.
- Select your sync mode to update the index when your data source content changes.
You can sync and index all contents in all entities, regardless of the previous sync process by selecting Full sync, or only sync new, modified, or deleted content, or only sync new or modified content. For this post, we select Full sync.
- Choose a frequency to run the sync schedule, such as Run on demand.
- Choose Next.

In this next step, you can create field mappings to add an extra layer of metadata to your documents. This enables you to improve accuracy through manual tuning, filtering, and faceting.
- Review the default field mappings information and choose Next.

- As a last step, review the configuration details and choose Add data source to create the SharePoint connector data source for the Amazon Kendra index.
Test the solution
Now you’re ready to prepare and test the Amazon Kendra search features using the SharePoint connector.
For this post, AWS getting started documents are added to the SharePoint data source. The sample dataset used for this post can be downloaded from AWS_Whitepapers.zip. This dataset has PDF documents categorized into multiple directories based on the type of documents (for example, documents related to AWS database options, security, and ML).
Also, sample dataset directories in SharePoint are configured with user email IDs and group details so that only the users and groups with permissions can access specific directories or individual files.
To achieve granular-level control over the search results, the SharePoint connector crawls the local or Active Directory (AD) group mapping in the SharePoint data source in addition to the content when the identity crawler is enabled with the local and AD group mapping options selected. With this capability, Amazon Kendra indexed content is searchable and displayable based on the access control permissions of the users and groups.
To sync our index with SharePoint content, complete the following steps:
- On the Amazon Kendra console, navigate to the index you created.
- Choose Data sources in the navigation pane and select the SharePoint data source.
- Choose Sync now to start the process to index the content from the SharePoint application and wait for the process to complete.
If you encounter any sync issues, refer to Troubleshooting data sources for more information.
When the sync process is successful, the value for Last sync status will be set to Successful – service is operating normally. The content from the SharePoint application is now indexed and ready for queries.
- Choose Search indexed content (under Data management) in the navigation pane.

- Enter a test query in the search field and press Enter.
A test query such as “What is the durability of S3?” provides the following Amazon Kendra suggested answers. Note that the results for this query are from all the indexed content. This is because there is no context of user name or group information for this query.
- To test the access-controlled search, expand Test query with username or groups and choose Apply user name or groups to add a user name (email ID) or group information.

When an Experience Builder app is used, it includes the user context, and therefore you don’t need to add user or group IDs explicitly.
- For this post, access to the Databases directory in the SharePoint site is provided to the database-specialists group only.

- Enter a new test query and press Enter.
In this example, only the content in the Databases directory is searched and the results are displayed. This is because the database-specialists group only has access to the Databases directory.
Congratulations! You have successfully used Amazon Kendra to surface answers and insights based on the content indexed from your SharePoint application.
Amazon Kendra Experience Builder
You can build and deploy an Amazon Kendra search application without the need for any front-end code. Amazon Kendra Experience Builder helps you build and deploy a fully functional search application in a few clicks so that you can start searching right away.
Refer to Building a search experience with no code for more information.
Clean up
To avoid incurring future costs, clean up the resources you created as part of this solution. If you created a new Amazon Kendra index while testing this solution, delete it if you no longer need it. If you only added a new data source using the Amazon Kendra connector for SharePoint, delete that data source after your solution review is completed.
Refer to Deleting an index and data source for more information.
Conclusion
In this post, we showed how to ingest documents from your SharePoint application into your Amazon Kendra index. We also reviewed some of the new features that are introduced in the new version of the SharePoint connector.
To learn more about the Amazon Kendra connector for SharePoint, refer to Microsoft SharePoint connector V2.0.
Finally, don’t forget to check out the other blog posts about Amazon Kendra!
About the Author
 Udaya Jaladi is a Solutions Architect at Amazon Web Services (AWS), specializing in assisting Independent Software Vendor (ISV) customers. With expertise in cloud strategies, AI/ML technologies, and operations, Udaya serves as a trusted advisor to executives and engineers, offering personalized guidance on maximizing the cloud’s potential and driving innovative product development. Leveraging his background as an Enterprise Architect (EA) across diverse business domains, Udaya excels in architecting scalable cloud solutions tailored to meet the specific needs of ISV customers.
Udaya Jaladi is a Solutions Architect at Amazon Web Services (AWS), specializing in assisting Independent Software Vendor (ISV) customers. With expertise in cloud strategies, AI/ML technologies, and operations, Udaya serves as a trusted advisor to executives and engineers, offering personalized guidance on maximizing the cloud’s potential and driving innovative product development. Leveraging his background as an Enterprise Architect (EA) across diverse business domains, Udaya excels in architecting scalable cloud solutions tailored to meet the specific needs of ISV customers.
Lihong Li wins 2023 Seoul Test of Time Award
The Amazon senior principal scientist coauthored a 2010 paper that introduced a new way to develop algorithms that make personalized recommendations for website users.Read More

Build a serverless meeting summarization backend with large language models on Amazon SageMaker JumpStart
AWS delivers services that meet customers’ artificial intelligence (AI) and machine learning (ML) needs with services ranging from custom hardware like AWS Trainium and AWS Inferentia to generative AI foundation models (FMs) on Amazon Bedrock. In February 2022, AWS and Hugging Face announced a collaboration to make generative AI more accessible and cost efficient.
Generative AI has grown at an accelerating rate from the largest pre-trained model in 2019 having 330 million parameters to more than 500 billion parameters today. The performance and quality of the models also improved drastically with the number of parameters. These models span tasks like text-to-text, text-to-image, text-to-embedding, and more. You can use large language models (LLMs), more specifically, for tasks including summarization, metadata extraction, and question answering.
Amazon SageMaker JumpStart is an ML hub that can helps you accelerate your ML journey. With JumpStart, you can access pre-trained models and foundation models from the Foundations Model Hub to perform tasks like article summarization and image generation. Pre-trained models are fully customizable for your use cases and can be easily deployed into production with the user interface or SDK. Most importantly, none of your data is used to train the underlying models. Because all data is encrypted and doesn’t leave the virtual private cloud (VPC), you can trust that your data will remain private and confidential.
This post focuses on building a serverless meeting summarization using Amazon Transcribe to transcribe meeting audio and the Flan-T5-XL model from Hugging Face (available on JumpStart) for summarization.
Solution overview
The Meeting Notes Generator Solution creates an automated serverless pipeline using AWS Lambda for transcribing and summarizing audio and video recordings of meetings. The solution can be deployed with other FMs available on JumpStart.
The solution includes the following components:
- A shell script for creating a custom Lambda layer
- A configurable AWS CloudFormation template for deploying the solution
- Lambda function code for starting Amazon Transcribe transcription jobs
- Lambda function code for invoking a SageMaker real-time endpoint hosting the Flan T5 XL model
The following diagram illustrates this architecture.

As shown in the architecture diagram, the meeting recordings, transcripts, and notes are stored in respective Amazon Simple Storage Service (Amazon S3) buckets. The solution takes an event-driven approach to transcribe and summarize upon S3 upload events. The events trigger Lambda functions to make API calls to Amazon Transcribe and invoke the real-time endpoint hosting the Flan T5 XL model.
The CloudFormation template and instructions for deploying the solution can be found in the GitHub repository.
Real-time inference with SageMaker
Real-time inference on SageMaker is designed for workloads with low latency requirements. SageMaker endpoints are fully managed and support multiple hosting options and auto scaling. Once created, the endpoint can be invoked with the InvokeEndpoint API. The provided CloudFormation template creates a real-time endpoint with the default instance count of 1, but it can be adjusted based on expected load on the endpoint and as the service quota for the instance type permits. You can request service quota increases on the Service Quotas page of the AWS Management Console.
The following snippet of the CloudFormation template defines the SageMaker model, endpoint configuration, and endpoint using the ModelData and ImageURI of the Flan T5 XL from JumpStart. You can explore more FMs on Getting started with Amazon SageMaker JumpStart. To deploy the solution with a different model, replace the ModelData and ImageURI parameters in the CloudFormation template with the desired model S3 artifact and container image URI, respectively. Check out the sample notebook on GitHub for sample code on how to retrieve the latest JumpStart model artifact on Amazon S3 and the corresponding public container image provided by SageMaker.
Deploy the solution
For detailed steps on deploying the solution, follow the Deployment with CloudFormation section of the GitHub repository.
If you want to use a different instance type or more instances for the endpoint, submit a quota increase request for the desired instance type on the AWS Service Quotas Dashboard.
To use a different FM for the endpoint, replace the ImageURI and ModelData parameters in the CloudFormation template for the corresponding FM.
Test the solution
After you deploy the solution using the Lambda layer creation script and the CloudFormation template, you can test the architecture by uploading an audio or video meeting recording in any of the media formats supported by Amazon Transcribe. Complete the following steps:
- On the Amazon S3 console, choose Buckets in the navigation pane.
- From the list of S3 buckets, choose the S3 bucket created by the CloudFormation template named
meeting-note-generator-demo-bucket-<aws-account-id>. - Choose Create folder.
- For Folder name, enter the S3 prefix specified in the
S3RecordingsPrefixparameter of the CloudFormation template (recordingsby default). - Choose Create folder.

- In the newly created folder, choose Upload.

- Choose Add files and choose the meeting recording file to upload.
- Choose Upload.
Now we can check for a successful transcription.
- On the Amazon Transcribe console, choose Transcription jobs in the navigation pane.
- Check that a transcription job with a corresponding name to the uploaded meeting recording has the status In progress or Complete.

- When the status is Complete, return to the Amazon S3 console and open the demo bucket.
- In the S3 bucket, open the
transcripts/folder. - Download the generated text file to view the transcription.
We can also check the generated summary.
- In the S3 bucket, open the
notes/folder. - Download the generated text file to view the generated summary.
Prompt engineering
Even though LLMs have improved in the last few years, the models can only take in finite inputs; therefore, inserting an entire transcript of a meeting may exceed the limit of the model and cause an error with the invocation. To design around this challenge, we can break down the context into manageable chunks by limiting the number of tokens in each invocation context. In this sample solution, the transcript is broken down into smaller chunks with a maximum limit on the number of tokens per chunk. Then each transcript chunk is summarized using the Flan T5 XL model. Finally, the chunk summaries are combined to form the context for the final combined summary, as shown in the following diagram.

The following code from the GenerateMeetingNotes Lambda function uses the Natural Language Toolkit (NLTK) library to tokenize the transcript, then it chunks the transcript into sections, each containing up to a certain number of tokens:
Finally, the following code snippet combines the chunk summaries as the context to generate a final summary:
The full GenerateMeetingNotes Lambda function can be found in the GitHub repository.
Clean up
To clean up the solution, complete the following steps:
- Delete all objects in the demo S3 bucket and the logs S3 bucket.
- Delete the CloudFormation stack.
- Delete the Lambda layer.
Conclusion
This post demonstrated how to use FMs on JumpStart to quickly build a serverless meeting notes generator architecture with AWS CloudFormation. Combined with AWS AI services like Amazon Transcribe and serverless technologies like Lambda, you can use FMs on JumpStart and Amazon Bedrock to build applications for various generative AI use cases.
For additional posts on ML at AWS, visit the AWS ML Blog.
About the author
 Eric Kim is a Solutions Architect (SA) at Amazon Web Services. He works with game developers and publishers to build scalable games and supporting services on AWS. He primarily focuses on applications of artificial intelligence and machine learning.
Eric Kim is a Solutions Architect (SA) at Amazon Web Services. He works with game developers and publishers to build scalable games and supporting services on AWS. He primarily focuses on applications of artificial intelligence and machine learning.

Prepare training and validation dataset for facies classification using Snowflake integration and train using Amazon SageMaker Canvas
This post is co-written with Thatcher Thornberry from bpx energy.
Facies classification is the process of segmenting lithologic formations from geologic data at the wellbore location. During drilling, wireline logs are obtained, which have depth-dependent geologic information. Geologists are deployed to analyze this log data and determine depth ranges for potential facies of interest from the different types of log data. Accurately classifying these regions is critical for the drilling processes that follow.
Facies classification using AI and machine learning (ML) has become an increasingly popular area of investigation for many oil majors. Many data scientists and business analysts at large oil companies don’t have the necessary skillset to run advanced ML experiments on important tasks such as facies classification. To address this, we show you how to easily prepare and train a best-in-class ML classification model on this problem.
In this post, aimed primarily at those who are already using Snowflake, we explain how you can import both training and validation data for a facies classification task from Snowflake into Amazon SageMaker Canvas and subsequently train the model using a 3+ category prediction model.
Solution overview
Our solution consists of the following steps:
- Upload facies CSV data from your local machine to Snowflake. For this post, we use data from the following open-source GitHub repo.
- Configure AWS Identity and Access Management (IAM) roles for Snowflake and create a Snowflake integration.
- Create a secret for Snowflake credentials (optional, but advised).
- Import Snowflake directly into Canvas.
- Build a facies classification model.
- Analyze the model.
- Run batch and single predictions using the multi-class model.
- Share the trained model to Amazon SageMaker Studio.
Prerequisites
Prerequisites for this post include the following:
- An AWS account.
- Canvas set up, with an Amazon SageMaker user profile associated with it.
- A Snowflake account. For steps to create a Snowflake account, refer to How to: Create a Snowflake Free Trial Account
- The Snowflake CLI. For steps to connect to Snowflake by CLI, refer to SnowSQL, the command line interface for connecting to Snowflake. For steps to connect to to Snowflake by CLI, refer to Snowflake SnowSQL: Command Line Tool to access Snowflake.
- An existing database within Snowflake.
Upload facies CSV data to Snowflake
In this section, we take two open-source datasets and upload them directly from our local machine to a Snowflake database. From there, we set up an integration layer between Snowflake and Canvas.
- Download the training_data.csv and validation_data_nofacies.csv files to your local machine. Make note of where you saved them.
- Ensuring that you have the correct Snowflake credentials and have installed the Snowflake CLI desktop app, you can federate in. For more information, refer to Log into SnowSQL.

- Select the appropriate Snowflake warehouse to work within, which in our case is
COMPUTE_WH:

- Choose a database to use for the remainder of the walkthrough:
- Create a named file format that will describe a set of staged data to access or load into Snowflake tables.
This can be run either in the Snowflake CLI or in a Snowflake worksheet on the web application. For this post, we run a SnowSQL query in the web application. See Getting Started With Worksheets for instructions to create a worksheet on the Snowflake web application.

- Create a table in Snowflake using the CREATE statement.
The following statement creates a new table in the current or specified schema (or replaces an existing table).
It’s important that the data types and the order in which they appear are correct, and align with what is found in the CSV files that we previously downloaded. If they’re inconsistent, we’ll run into issues later when we try to copy the data across.

- Do the same for the validation database.
Note that the schema is a little different to the training data. Again, ensure that the data types and column or feature orders are correct.

- Load the CSV data file from your local system into the Snowflake staging environment:
- The following is the syntax of the statement for Windows OS:
- The following is the syntax of the statement for Mac OS:
The following screenshot shows an example command and output from within the SnowSQL CLI.

- Copy the data into the target Snowflake table.
Here, we load the training CSV data to the target table, which we created earlier. Note that you have to do this for both the training and validation CSV files, copying them into the training and validation tables, respectively.

- Verify that the data has been loaded into the target table by running a SELECT query (you can do this for both the training and validation data):

Configure Snowflake IAM roles and create the Snowflake integration
As a prerequisite for this section, please follow the official Snowflake documentation on how to configure a Snowflake Storage Integration to Access Amazon S3.
Retrieve the IAM user for your Snowflake account
Once you have successfully configured your Snowflake storage integration, run the following DESCRIBE INTEGRATION command to retrieve the ARN for the IAM user that was created automatically for your Snowflake account:

Record the following values from the output:
- STORAGE_AWS_IAM_USER_ARN – The IAM user created for your Snowflake account
- STORAGE_AWS_EXTERNAL_ID – The external ID needed to establish a trust relationship
Update the IAM role trust policy
Now we update the trust policy:
- On the IAM console, choose Roles in the navigation pane.
- Choose the role you created.
- On the Trust relationship tab, choose Edit trust relationship.
- Modify the policy document as shown in the following code with the DESC STORAGE INTEGRATION output values you recorded in the previous step.
- Choose Update trust policy.
Create an external stage in Snowflake
We use an external stage within Snowflake for loading data from an S3 bucket in your own account into Snowflake. In this step, we create an external (Amazon S3) stage that references the storage integration you created. For more information, see Creating an S3 Stage.
This requires a role that has the CREATE_STAGE privilege for the schema as well as the USAGE privilege on the storage integration. You can grant these privileges to the role as shown in the code in the next step.
Create the stage using the CREATE_STAGE command with placeholders for the external stage and S3 bucket and prefix. The stage also references a named file format object called my_csv_format:
Create a secret for Snowflake credentials
Canvas allows you to use the ARN of an AWS Secrets Manager secret or a Snowflake account name, user name, and password to access Snowflake. If you intend to use the Snowflake account name, user name, and password option, skip to the next section, which covers adding the data source.
To create a Secrets Manager secret manually, complete the following steps:
- On the Secrets Manager console, choose Store a new secret.
- For Select secret type¸ select Other types of secrets.
- Specify the details of your secret as key-value pairs.

The names of the key are case-sensitive and must be lowercase.
If you prefer, you can use the plaintext option and enter the secret values as JSON:
- Choose Next.
- For Secret name, add the prefix
AmazonSageMaker(for example, our secret isAmazonSageMaker-CanvasSnowflakeCreds). - In the Tags section, add a tag with the key SageMaker and value true.

- Choose Next.
- The rest of the fields are optional; choose Next until you have the option to choose Store to store the secret.
- After you store the secret, you’re returned to the Secrets Manager console.
- Choose the secret you just created, then retrieve the secret ARN.
- Store this in your preferred text editor for use later when you create the Canvas data source.
Import Snowflake directly into Canvas
To import your facies dataset directly into Canvas, complete the following steps:
- On the SageMaker console, choose Amazon SageMaker Canvas in the navigation pane.
- Choose your user profile and choose Open Canvas.
- On the Canvas landing page, choose Datasets in the navigation pane.
- Choose Import.

- Click on Snowflake in the below image and then immediately “Add Connection”.

- Enter the ARN of the Snowflake secret that we previously created, the storage integration name (
SAGEMAKER_CANVAS_INTEGRATION), and a unique connection name of your choosing. - Choose Add connection.

If all the entries are valid, you should see all the databases associated with the connection in the navigation pane (see the following example for NICK_FACIES).

- Choose the
TRAINING_DATAtable, then choose Preview dataset.
If you’re happy with the data, you can edit the custom SQL in the data visualizer.
- Choose Edit in SQL.
- Run the following SQL command before importing into Canvas. (This assumes that the database is called
NICK_FACIES. Replace this value with your database name.)
Something similar to the following screenshot should appear in the Import preview section.
- If you’re happy with the preview, choose Import data.

- Choose an appropriate data name, ensuring that it’s unique and fewer than 32 characters long.
- Use the following command to import the validation dataset, using the same method as earlier:
Build a facies classification model
To build your facies classification model, complete the following steps:
- Choose Models in the navigation pane, then choose New Model.
- Give your model a suitable name.
- On the Select tab, choose the recently imported training dataset, then choose Select dataset.
- On the Build tab, drop the
WELL_NAMEcolumn.
We do this because the well names themselves aren’t useful information for the ML model. They are merely arbitrary names that we find useful to distinguish between the wells themselves. The name we give a particular well is irrelevant to the ML model.
- Choose FACIES as the target column.
- Leave Model type as 3+ category prediction.
- Validate the data.
- Choose Standard build.
Your page should look similar to the following screenshot just before building your model.

After you choose Standard build, the model enters the analyze stage. You’re provided an expected build time. You can now close this window, log out of Canvas (in order to avoid charges), and return to Canvas at a later time.
Analyze the facies classification model
To analyze the model, complete the following steps:
- Federate back into Canvas.
- Locate your previously created model, choose View, then choose Analyze.
- On the Overview tab, you can see the impact that individual features are having on the model output.
- In the right pane, you can visualize the impact that a given feature (X axis) is having on the prediction of each facies class (Y axis).
These visualizations will change accordingly depending on the feature you select. We encourage you to explore this page by cycling through all 9 classes and 10 features.
- On the Scoring tab, we can see the predicted vs. actual facies classification.
- Choose Advanced metrics to view F1 scores, average accuracy, precision, recall, and AUC.
- Again, we encourage viewing all the different classes.
- Choose Download to download an image to your local machine.
In the following image, we can see a number of different advanced metrics, such as the F1 score. In statistical analysis, the F1 score conveys the balance between the precision and the recall of a classification model, and is computed using the following equation: 2*((Precision * Recall)/ (Precision + Recall)).

Run batch and single prediction using the multi-class facies classification model
To run a prediction, complete the following steps:
- Choose Single prediction to modify the feature values as needed, and get a facies classification returned on the right of the page.
You can then copy the prediction chart image to your clipboard, and also download the predictions into a CSV file.

- Choose Batch prediction and then choose Select dataset to choose the validation dataset you previously imported.
- Choose Generate predictions.
You’re redirected to the Predict page, where the Status will read Generating predictions for a few seconds.
After the predictions are returned, you can preview, download, or delete the predictions by choosing the options menu (three vertical dots) next to the predictions.

The following is an example of a predictions preview.

Share a trained model in Studio
You can now share the latest version of the model with another Studio user. This allows data scientists to review the model in detail, test it, make any changes that may improve accuracy, and share the updated model back with you.
The ability to share your work with a more technical user within Studio is a key feature of Canvas, given the key distinction between ML personas’ workflows. Note the strong focus here on collaboration between cross-functional teams with differing technical abilities.
- Choose Share to share the model.

- Choose which model version to share.
- Enter the Studio user to share the model with.
- Add an optional note.
- Choose Share.

Conclusion
In this post, we showed how with just a few clicks in Amazon SageMaker Canvas you can prepare and import your data from Snowflake, join your datasets, analyze estimated accuracy, verify which columns are impactful, train the best performing model, and generate new individual or batch predictions. We’re excited to hear your feedback and help you solve even more business problems with ML. To build your own models, see Getting started with using Amazon SageMaker Canvas.
About the Authors
 Nick McCarthy is a Machine Learning Engineer in the AWS Professional Services team. He has worked with AWS clients across various industries including healthcare, finance, sports, telecoms and energy to accelerate their business outcomes through the use of AI/ML. Working with the bpx data science team, Nick recently finished building bpx’s Machine Learning platform on Amazon SageMaker.
Nick McCarthy is a Machine Learning Engineer in the AWS Professional Services team. He has worked with AWS clients across various industries including healthcare, finance, sports, telecoms and energy to accelerate their business outcomes through the use of AI/ML. Working with the bpx data science team, Nick recently finished building bpx’s Machine Learning platform on Amazon SageMaker.
 Thatcher Thornberry is a Machine Learning Engineer at bpx Energy. He supports bpx’s data scientists by developing and maintaining the company’s core Data Science platform in Amazon SageMaker. In his free time he loves to hack on personal coding projects and spend time outdoors with his wife.
Thatcher Thornberry is a Machine Learning Engineer at bpx Energy. He supports bpx’s data scientists by developing and maintaining the company’s core Data Science platform in Amazon SageMaker. In his free time he loves to hack on personal coding projects and spend time outdoors with his wife.

GPT-NeoXT-Chat-Base-20B foundation model for chatbot applications is now available on Amazon SageMaker
Today we are excited to announce that Together Computer’s GPT-NeoXT-Chat-Base-20B language foundation model is available for customers using Amazon SageMaker JumpStart. GPT-NeoXT-Chat-Base-20B is an open-source model to build conversational bots. You can easily try out this model and use it with JumpStart. JumpStart is the machine learning (ML) hub of Amazon SageMaker that provides access to foundation models in addition to built-in algorithms and end-to-end solution templates to help you quickly get started with ML.
In this post, we walk through how to deploy the GPT-NeoXT-Chat-Base-20B model and invoke the model within an OpenChatKit interactive shell. This demonstration provides an open-source foundation model chatbot for use within your application.
JumpStart models use Deep Java Serving that uses the Deep Java Library (DJL) with deep speed libraries to optimize models and minimize latency for inference. The underlying implementation in JumpStart follows an implementation that is similar to the following notebook. As a JumpStart model hub customer, you get improved performance without having to maintain the model script outside of the SageMaker SDK. JumpStart models also achieve improved security posture with endpoints that enable network isolation.
Foundation models in SageMaker
JumpStart provides access to a range of models from popular model hubs, including Hugging Face, PyTorch Hub, and TensorFlow Hub, which you can use within your ML development workflow in SageMaker. Recent advances in ML have given rise to a new class of models known as foundation models, which are typically trained on billions of parameters and are adaptable to a wide category of use cases, such as text summarization, generating digital art, and language translation. Because these models are expensive to train, customers want to use existing pre-trained foundation models and fine-tune them as needed, rather than train these models themselves. SageMaker provides a curated list of models that you can choose from on the SageMaker console.
You can now find foundation models from different model providers within JumpStart, enabling you to get started with foundation models quickly. You can find foundation models based on different tasks or model providers, and easily review model characteristics and usage terms. You can also try out these models using a test UI widget. When you want to use a foundation model at scale, you can do so easily without leaving SageMaker by using pre-built notebooks from model providers. Because the models are hosted and deployed on AWS, you can rest assured that your data, whether used for evaluating or using the model at scale, is never shared with third parties.
GPT-NeoXT-Chat-Base-20B foundation model
Together Computer developed GPT-NeoXT-Chat-Base-20B, a 20-billion-parameter language model, fine-tuned from ElutherAI’s GPT-NeoX model with over 40 million instructions, focusing on dialog-style interactions. Additionally, the model is tuned on several tasks, such as question answering, classification, extraction, and summarization. The model is based on the OIG-43M dataset that was created in collaboration with LAION and Ontocord.
In addition to the aforementioned fine-tuning, GPT-NeoXT-Chat-Base-20B-v0.16 has also undergone further fine-tuning via a small amount of feedback data. This allows the model to better adapt to human preferences in the conversations. GPT-NeoXT-Chat-Base-20B is designed for use in chatbot applications and may not perform well for other use cases outside of its intended scope. Together, Ontocord and LAION collaborated to release OpenChatKit, an open-source alternative to ChatGPT with a comparable set of capabilities. OpenChatKit was launched under an Apache-2.0 license, granting complete access to the source code, model weights, and training datasets. There are several tasks that OpenChatKit excels at out of the box. This includes summarization tasks, extraction tasks that allow extracting structured information from unstructured documents, and classification tasks to classify a sentence or paragraph into different categories.
Let’s explore how we can use the GPT-NeoXT-Chat-Base-20B model in JumpStart.
Solution overview
You can find the code showing the deployment of GPT-NeoXT-Chat-Base-20B on SageMaker and an example of how to use the deployed model in a conversational manner using the command shell in the following GitHub notebook.
In the following sections, we expand each step in detail to deploy the model and then use it to solve different tasks:
- Set up prerequisites.
- Select a pre-trained model.
- Retrieve artifacts and deploy an endpoint.
- Query the endpoint and parse a response.
- Use an OpenChatKit shell to interact with your deployed endpoint.
Set up prerequisites
This notebook was tested on an ml.t3.medium instance in Amazon SageMaker Studio with the Python 3 (Data Science) kernel and in a SageMaker notebook instance with the conda_python3 kernel.
Before you run the notebook, use the following command to complete some initial steps required for setup:
Select a pre-trained model
We set up a SageMaker session like usual using Boto3 and then select the model ID that we want to deploy:
Retrieve artifacts and deploy an endpoint
With SageMaker, we can perform inference on the pre-trained model, even without fine-tuning it first on a new dataset. We start by retrieving the instance_type, image_uri, and model_uri for the pre-trained model. To host the pre-trained model, we create an instance of sagemaker.model.Model and deploy it. The following code uses ml.g5.24xlarge for the inference endpoint. The deploy method may take a few minutes.
Query the endpoint and parse the response
Next, we show you an example of how to invoke an endpoint with a subset of the hyperparameters:
The following is the response that we get:
Here, we have provided the payload argument "stopping_criteria": ["<human>"], which has resulted in the model response ending with the generation of the word sequence <human>. The JumpStart model script will accept any list of strings as desired stop words, convert this list to a valid stopping_criteria keyword argument to the transformers generate API, and stop text generation when the output sequence contains any specified stop words. This is useful for two reasons: first, inference time is reduced because the endpoint doesn’t continue to generate undesired text beyond the stop words, and second, this prevents the OpenChatKit model from hallucinating additional human and bot responses until other stop criteria are met.
Use an OpenChatKit shell to interact with your deployed endpoint
OpenChatKit provides a command line shell to interact with the chatbot. In this step, you create a version of this shell that can interact with your deployed endpoint. We provide a bare-bones simplification of the inference scripts in this OpenChatKit repository that can interact with our deployed SageMaker endpoint.
There are two main components to this:
- A shell interpreter (
JumpStartOpenChatKitShell) that allows for iterative inference invocations of the model endpoint - A conversation object (
Conversation) that stores previous human/chatbot interactions locally within the interactive shell and appropriately formats past conversations for future inference context
The Conversation object is imported as is from the OpenChatKit repository. The following code creates a custom shell interpreter that can interact with your endpoint. This is a simplified version of the OpenChatKit implementation. We encourage you to explore the OpenChatKit repository to see how you can use more in-depth features, such as token streaming, moderation models, and retrieval augmented generation, within this context. The context of this notebook focuses on demonstrating a minimal viable chatbot with a JumpStart endpoint; you can add complexity as needed from here.
A short demo to showcase the JumpStartOpenChatKitShell is shown in the following video.
The following snippet shows how the code works:
You can now launch this shell as a command loop. This will repeatedly issue a prompt, accept input, parse the input command, and dispatch actions. Because the resulting shell may be utilized in an infinite loop, this notebook provides a default command queue (cmdqueue) as a queued list of input lines. Because the last input is the command /quit, the shell will exit upon exhaustion of the queue. To dynamically interact with this chatbot, remove the cmdqueue.
Example 1: Conversation context is retained
The following prompt shows that the chatbot is able to retain the context of the conversation to answer follow-up questions:
Example 2: Classification of sentiments
In the following example, the chatbot performed a classification task by identifying the sentiments of the sentence. As you can see, the chatbot was able to classify positive and negative sentiments successfully.
Example 3: Summarization tasks
Next, we tried summarization tasks with the chatbot shell. The following example shows how the long text about Amazon Comprehend was summarized to one sentence and the chatbot was able to answer follow-up questions on the text:
Example 4: Extract structured information from unstructured text
In the following example, we used the chatbot to create a markdown table with headers, rows, and columns to create a project plan using the information that is provided in free-form language:
Example 5: Commands as input to chatbot
We can also provide input as commands like /hyperparameters to see hyperparameters values and /quit to quit the command shell:
These examples showcased just some of the tasks that OpenChatKit excels at. We encourage you to try various prompts and see what works best for your use case.
Clean up
After you have tested the endpoint, make sure you delete the SageMaker inference endpoint and the model to avoid incurring charges.
Conclusion
In this post, we showed you how to test and use the GPT-NeoXT-Chat-Base-20B model using SageMaker and build interesting chatbot applications. Try out the foundation model in SageMaker today and let us know your feedback!
This guidance is for informational purposes only. You should still perform your own independent assessment, and take measures to ensure that you comply with your own specific quality control practices and standards, and the local rules, laws, regulations, licenses and terms of use that apply to you, your content, and the third-party model referenced in this guidance. AWS has no control or authority over the third-party model referenced in this guidance, and does not make any representations or warranties that the third-party model is secure, virus-free, operational, or compatible with your production environment and standards. AWS does not make any representations, warranties or guarantees that any information in this guidance will result in a particular outcome or result.
About the authors
 Rachna Chadha is a Principal Solutions Architect AI/ML in Strategic Accounts at AWS. Rachna is an optimist who believes that the ethical and responsible use of AI can improve society in the future and bring economic and social prosperity. In her spare time, Rachna likes spending time with her family, hiking, and listening to music.
Rachna Chadha is a Principal Solutions Architect AI/ML in Strategic Accounts at AWS. Rachna is an optimist who believes that the ethical and responsible use of AI can improve society in the future and bring economic and social prosperity. In her spare time, Rachna likes spending time with her family, hiking, and listening to music.
 Dr. Kyle Ulrich is an Applied Scientist with the Amazon SageMaker built-in algorithms team. His research interests include scalable machine learning algorithms, computer vision, time series, Bayesian non-parametrics, and Gaussian processes. His PhD is from Duke University and he has published papers in NeurIPS, Cell, and Neuron.
Dr. Kyle Ulrich is an Applied Scientist with the Amazon SageMaker built-in algorithms team. His research interests include scalable machine learning algorithms, computer vision, time series, Bayesian non-parametrics, and Gaussian processes. His PhD is from Duke University and he has published papers in NeurIPS, Cell, and Neuron.
 Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker built-in algorithms and helps develop machine learning algorithms. He got his PhD from University of Illinois Urbana-Champaign. He is an active researcher in machine learning and statistical inference, and has published many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.
Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker built-in algorithms and helps develop machine learning algorithms. He got his PhD from University of Illinois Urbana-Champaign. He is an active researcher in machine learning and statistical inference, and has published many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.