AI agents extend large language models (LLMs) by interacting with external systems, executing complex workflows, and maintaining contextual awareness across operations. Amazon Bedrock Agents enables this functionality by orchestrating foundation models (FMs) with data sources, applications, and user inputs to complete goal-oriented tasks through API integration and knowledge base augmentation. However, in the past, connecting these agents to diverse enterprise systems has created development bottlenecks, with each integration requiring custom code and ongoing maintenance—a standardization challenge that slows the delivery of contextual AI assistance across an organization’s digital ecosystem. This is a problem that you can solve by using Model Context Protocol (MCP), which provides a standardized way for LLMs to connect to data sources and tools.
Today, MCP is providing agents standard access to an expanding list of accessible tools that you can use to accomplish a variety of tasks. In time, MCP can promote better discoverability of agents and tools through marketplaces, enabling agents to share context and have common workspaces for better interaction, and scale agent interoperability across the industry.
In this post, we show you how to build an Amazon Bedrock agent that uses MCP to access data sources to quickly build generative AI applications. Using Amazon Bedrock Agents, your agent can be assembled on the fly with MCP-based tools as in this example:
We showcase an example of building an agent to understand your Amazon Web Service (AWS) spend by connecting to AWS Cost Explorer, Amazon CloudWatch, and Perplexity AI through MCP. You can use the code referenced in this post to connect your agents to other MCP servers to address challenges for your business. We envision a world where agents have access to an ever-growing list of MCP servers that they can use for accomplishing a wide variety of tasks.
Model Context Protocol
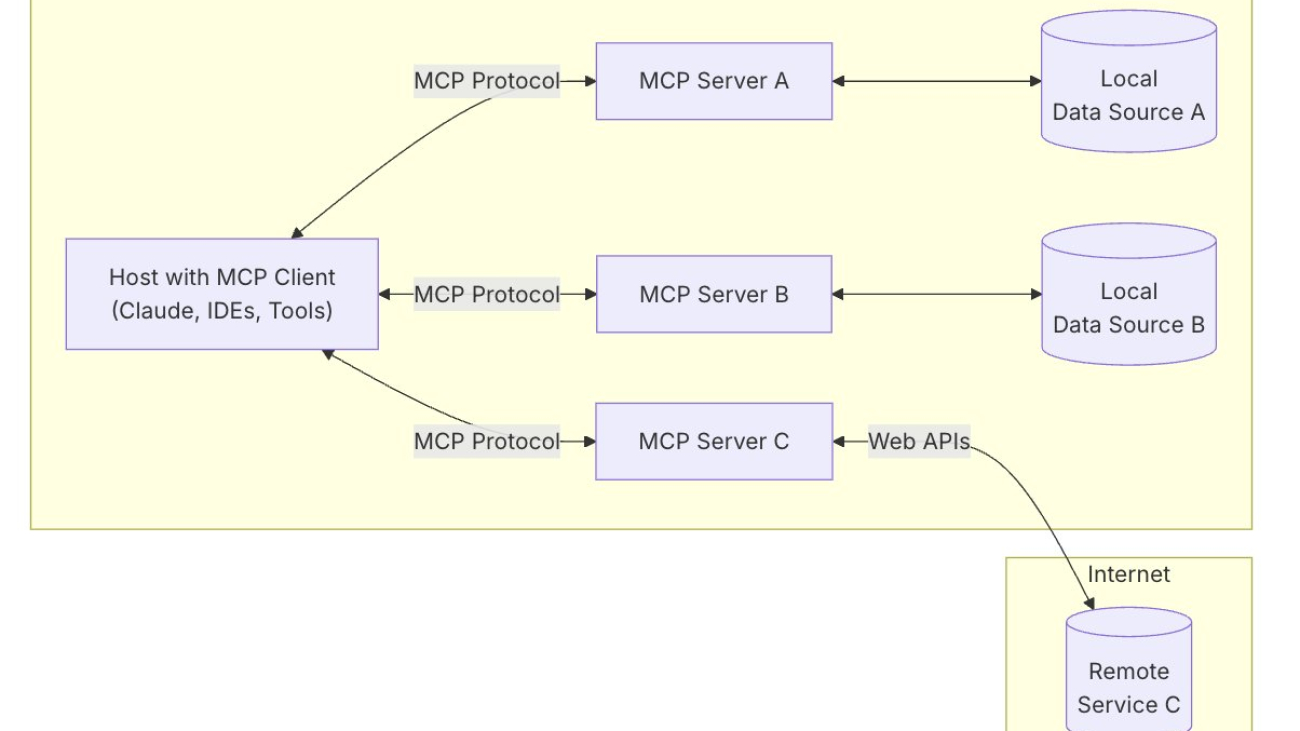
Developed by Anthropic as an open protocol, MCP provides a standardized way to connect AI models to virtually any data source or tool. Using a client-server architecture, MCP enables developers to expose their data through lightweight MCP servers while building AI applications as MCP clients that connect to these servers. Through this architecture, MCP enables users to build more powerful, context-aware AI agents that can seamlessly access the information and tools they need. Whether you’re connecting to external systems or internal data stores or tools, you can now use MCP to interface with all of them in the same way. The client-server architecture of MCP enables your agent to access new capabilities as the MCP server updates without requiring any changes to the application code.
MCP architecture
MCP uses a client-server architecture that contains the following components and is shown in the following figure:
- Host: An MCP host is a program or AI tool that requires access to data through the MCP protocol, such as Claude Desktop, an integrated development environment (IDE), or any other AI application.
- Client: Protocol clients that maintain one-to-one connections with servers.
- Server: Lightweight programs that expose capabilities through standardized MCP.
- Local data sources: Your databases, local data sources, and services that MCP servers can securely access.
- Remote services: External systems available over the internet through APIs that MCP servers can connect to.

Let’s walk through how to set up Amazon Bedrock agents that take advantage of MCP servers.
Using MCP with Amazon Bedrock agents
In this post, we provide a step-by-step guide for how to connect your favorite MCP servers with Amazon Bedrock agents as Action Groups that an agent can use to accomplish tasks provided by the user. The AgentInlineSDK provides a straightforward way to create inline agents, containing a built-in MCP client implementation that provides you with direct access to tools delivered by an MCP server.
As part of creating an agent, the developer creates an MCP client specific to each MCP server that requires agent communication. When invoked, the agent determines which tools are needed for the user’s task; if MCP server tools are required, it uses the corresponding MCP client to request tool execution from that server. The user code doesn’t need to be aware of the MCP protocol because that’s handled by the MCP client provided the InlineAgent code repository.
To orchestrate this workflow, you take advantage of the return control capability of Amazon Bedrock Agents. The following diagram illustrates the end-to-end flow of an agent handling a request that uses two tools. In the first flow, a Lambda-based action is taken, and in the second, the agent uses an MCP server.

Use case: transform how you manage your AWS spend across different AWS services including Amazon Bedrock
To show how an Amazon Bedrock agent can use MCP servers, let’s walk through a sample use case. Imagine asking questions like “Help me understand my Bedrock spend over the last few weeks” or “What were my EC2 costs last month across regions and instance types?” and getting a human-readable analysis of the data instead of raw numbers on a dashboard. The system interprets your intent and delivers precisely what you need—whether that’s detailed breakdowns, trend analyses, visualizations, or cost-saving recommendations. This is useful because what you’re interested in is insights rather than data. You can accomplish this using two MCP servers: a custom-built MCP server for retrieving the AWS spend data and an open source MCP server from Perplexity AI to interpret the data. You add these two MCP servers as action groups in an inline Amazon Bedrock agent. This gives you an AI agent that can transform the way you manage your AWS spend. All the code for this post is available in the GitHub repository.
Let’s walk through how this agent is created using inline agents. You can use inline agents to define and configure Amazon Bedrock agents dynamically at runtime. They provide greater flexibility and control over agent capabilities, enabling users to specify FMs, instructions, action groups, guardrails, and knowledge bases as needed without relying on pre-configured control plane settings. It’s worth noting that you can also orchestrate this behavior without inline agents by using RETURN_CONTROL with the InvokeAgent API.
MCP components in Amazon Bedrock Agents
- Host: This is the Amazon Bedrock inline agent. This agent adds MCP clients as action groups that can be invoked through RETURN_CONTROL when the user asks an AWS spend-related question.
- Client: You create two clients that establish one-to-one connections with their respective servers: a cost explorer client with specific cost server parameters and a Perplexity AI client with Perplexity server parameters.
- Servers: You create two MCP servers that each run locally on your machine and communicate to your application over standard input/output (alternatively, you could also configure the client to talk to remote MCP servers).
- Cost Explorer and Amazon CloudWatch Logs (for Amazon Bedrock model invocation log data) and an MCP server to retrieve the AWS spend data.
- Perplexity AI MCP server to interpret the AWS spend data.
- Data sources: The MCP servers talk to remote data sources such as Cost Explorer API, CloudWatch Logs and the Perplexity AI search API.
Prerequisites
You need the following prerequisites to get started implementing the solution in this post:
- An AWS account
- Familiarity with FMs and Amazon Bedrock
- Install AWS Command Line Interface (AWS CLI) and set up credentials
- Python 3.11 or later
- AWS Cloud Development Kit (AWS CDK) CLI
- Enable model access for Anthropic’s Claude 3.5 Sonnet v2
- You need to have your
AWS_ACCESS_KEY_IDandAWS_SECRET_ACCESS_KEYso that you can set them using environment variables for the server - The two MCP servers are run as Docker daemons, so you need to have Docker installed and running on your computer
The MCP servers run locally on your computer and need to access AWS services and the Perplexity API. You can read more about AWS credentials in Manage access keys for IAM users. Make sure that your credentials include AWS Identity and Access Manager (IAM) read access to Cost Explorer and CloudWatch. You can do this by using AWSBillingReadOnlyAccess and CloudWatchReadOnlyAccess managed IAM permissions. You can get the Perplexity API key from the Perplexity Sonar API page.
Steps to run
With the prerequisites in place, you’re ready to implement the solution.
- Navigate to the InlineAgent GitHub repository.
- Follow the setup steps.
- Navigate to the cost_explorer_agent This folder contains the code for this post.
- Create a
.envfile incost_explorer_agentdirectory using example. - Build
aws-cost-explorer-mcpserver - You’re now ready to create an agent that can invoke these MCP servers to provide insights into your AWS spend. You can do this by running the python
main.pycommand. The output will look like the following example. The agent connects with the two MCP servers and accesses their respective tools. Next, the agent lays out a plan to use specific tools sequentially, uses code interpreter to generate a chart showing cost distribution, and uses Cost Explorer and Perplexity API to provide information about Amazon Bedrock and the AWS account’s cost expenditure.
Implementation details
Now that you understand the output produced by an agent, let’s lift the curtain and review some of the important pieces of code that produce the output.
- Creating MCP clients: config.py, defines the two MCP clients that talk to your two MCP servers.
- Server parameters are defined for the cost explorer and Perplexity clients. The solution uses
StdioServerParameters, which configures how the client should communicate over standard input/output (stdio) streams. This contains the parameters required by the server to access the required data through APIs. - In
main.py, the MCP server parameters are imported and used to create your two MCP clients.
- Server parameters are defined for the cost explorer and Perplexity clients. The solution uses
- Configure agent action group:
main.pycreates the action group that combines the MCP clients into a single interface that the agent can access. This enables the agent to ask your application to invoke either of these MCP servers as needed through return of control. - Inline agent creation: The inline agent can be created with the following specifications:
- Foundation model: Configure your choice of FM to power your agent. This can be any model provided on Amazon Bedrock. This example uses Anthropic’s Claude 3.5 Sonnet model.
- Agent instruction: Provide instructions to your agent that contain the guidance and steps for orchestrating responses to user queries. These instructions anchor the agent’s approach to handling various types of queries
- Agent name: Name of your agent.
- Action groups: Define the action groups that your agent can access. These can include single or multiple action groups, with each group having access to multiple MCP clients or AWS Lambda As an option, you can configure your agent to use Code Interpreter to generate, run, and test code for your application.
You can use this example to build an inline agent on Amazon Bedrock that establishes connections with different MCP servers and groups their clients into a single action group for the agent to access.
Conclusion
The Anthropic MCP protocol offers a standardized way of connecting FMs to data sources, and now you can use this capability with Amazon Bedrock Agents. In this post, you saw an example of combining the power of Amazon Bedrock and MCP to build an application that offers a new perspective on understanding and managing your AWS spend.
Organizations can now offer their teams natural, conversational access to complex financial data while enhancing responses with contextual intelligence from sources like Perplexity. As AI continues to evolve, the ability to securely connect models to your organization’s critical systems will become increasingly valuable. Whether you’re looking to transform customer service, streamline operations, or gain deeper business insights, the Amazon Bedrock and MCP integration provides a flexible foundation for your next AI innovation. You can dive deeper on this MCP integration by exploring our code samples.
Here are some examples of what you can build by connecting your Amazon Bedrock Agents to MCP servers:
- A multi-data source agent that retrieves data from different data sources such as Amazon Bedrock Knowledge Bases, Sqlite, or even your local filesystem.
- A developer productivity assistant agent that integrates with Slack and GitHub MCP servers.
- A machine learning experiment tracking agent that integrates with the Opik MCP server from Comet ML for managing, visualizing, and tracking machine learning experiments directly within development environments.
What business challenges will you tackle with these powerful new capabilities?
About the authors
 Mark Roy is a Principal Machine Learning Architect for AWS, helping customers design and build generative AI solutions. His focus since early 2023 has been leading solution architecture efforts for the launch of Amazon Bedrock, the flagship generative AI offering from AWS for builders. Mark’s work covers a wide range of use cases, with a primary interest in generative AI, agents, and scaling ML across the enterprise. He has helped companies in insurance, financial services, media and entertainment, healthcare, utilities, and manufacturing. Prior to joining AWS, Mark was an architect, developer, and technology leader for over 25 years, including 19 years in financial services. Mark holds six AWS certifications, including the ML Specialty Certification.
Mark Roy is a Principal Machine Learning Architect for AWS, helping customers design and build generative AI solutions. His focus since early 2023 has been leading solution architecture efforts for the launch of Amazon Bedrock, the flagship generative AI offering from AWS for builders. Mark’s work covers a wide range of use cases, with a primary interest in generative AI, agents, and scaling ML across the enterprise. He has helped companies in insurance, financial services, media and entertainment, healthcare, utilities, and manufacturing. Prior to joining AWS, Mark was an architect, developer, and technology leader for over 25 years, including 19 years in financial services. Mark holds six AWS certifications, including the ML Specialty Certification.
 Eashan Kaushik is a Specialist Solutions Architect AI/ML at Amazon Web Services. He is driven by creating cutting-edge generative AI solutions while prioritizing a customer-centric approach to his work. Before this role, he obtained an MS in Computer Science from NYU Tandon School of Engineering. Outside of work, he enjoys sports, lifting, and running marathons.
Eashan Kaushik is a Specialist Solutions Architect AI/ML at Amazon Web Services. He is driven by creating cutting-edge generative AI solutions while prioritizing a customer-centric approach to his work. Before this role, he obtained an MS in Computer Science from NYU Tandon School of Engineering. Outside of work, he enjoys sports, lifting, and running marathons.
 Madhur Prashant is an AI and ML Solutions Architect at Amazon Web Services. He is passionate about the intersection of human thinking and generative AI. His interests lie in generative AI, specifically building solutions that are helpful and harmless, and most of all optimal for customers. Outside of work, he loves doing yoga, hiking, spending time with his twin, and playing the guitar.
Madhur Prashant is an AI and ML Solutions Architect at Amazon Web Services. He is passionate about the intersection of human thinking and generative AI. His interests lie in generative AI, specifically building solutions that are helpful and harmless, and most of all optimal for customers. Outside of work, he loves doing yoga, hiking, spending time with his twin, and playing the guitar.
 Amit Arora is an AI and ML Specialist Architect at Amazon Web Services, helping enterprise customers use cloud-based machine learning services to rapidly scale their innovations. He is also an adjunct lecturer in the MS data science and analytics program at Georgetown University in Washington, D.C.
Amit Arora is an AI and ML Specialist Architect at Amazon Web Services, helping enterprise customers use cloud-based machine learning services to rapidly scale their innovations. He is also an adjunct lecturer in the MS data science and analytics program at Georgetown University in Washington, D.C.
 Andy Palmer is a Director of Technology for AWS Strategic Accounts. His teams provide Specialist Solutions Architecture skills across a number of speciality domain areas, including AIML, generative AI, data and analytics, security, network, and open source software. Andy and his team have been at the forefront of guiding our most advanced customers through their generative AI journeys and helping to find ways to apply these new tools to both existing problem spaces and net new innovations and product experiences.
Andy Palmer is a Director of Technology for AWS Strategic Accounts. His teams provide Specialist Solutions Architecture skills across a number of speciality domain areas, including AIML, generative AI, data and analytics, security, network, and open source software. Andy and his team have been at the forefront of guiding our most advanced customers through their generative AI journeys and helping to find ways to apply these new tools to both existing problem spaces and net new innovations and product experiences.





 Sriharsh Adari is a Senior Solutions Architect at Amazon Web Services (AWS), where he helps customers work backwards from business outcomes to develop innovative solutions on AWS. Over the years, he has helped multiple customers on data platform transformations across industry verticals. His core area of expertise include Technology Strategy, Data Analytics, and Data Science. In his spare time, he enjoys playing sports, binge-watching TV shows, and playing Tabla.
Sriharsh Adari is a Senior Solutions Architect at Amazon Web Services (AWS), where he helps customers work backwards from business outcomes to develop innovative solutions on AWS. Over the years, he has helped multiple customers on data platform transformations across industry verticals. His core area of expertise include Technology Strategy, Data Analytics, and Data Science. In his spare time, he enjoys playing sports, binge-watching TV shows, and playing Tabla. David Min is a Senior Partner Sales Solutions Architect at Amazon Web Services (AWS) specializing in Generative AI, where he helps customers transform their businesses through innovative AI solutions. Throughout his career, David has helped numerous organizations across industries bridge the gap between cutting-edge AI technology and practical business applications, focusing on executive engagement and successful solution adoption.
David Min is a Senior Partner Sales Solutions Architect at Amazon Web Services (AWS) specializing in Generative AI, where he helps customers transform their businesses through innovative AI solutions. Throughout his career, David has helped numerous organizations across industries bridge the gap between cutting-edge AI technology and practical business applications, focusing on executive engagement and successful solution adoption. Stephen Garth is a Data Scientist at Insagic, where he develops advanced machine learning solutions, including LLM-powered automation tools and deep clustering models for actionable, consumer insights. With a strong background spanning software engineering, healthcare data science, and computational research, he is passionate to bring his expertise in AI-driven analytics and large-scale data processing to drive solutions.
Stephen Garth is a Data Scientist at Insagic, where he develops advanced machine learning solutions, including LLM-powered automation tools and deep clustering models for actionable, consumer insights. With a strong background spanning software engineering, healthcare data science, and computational research, he is passionate to bring his expertise in AI-driven analytics and large-scale data processing to drive solutions. Chris Cocking specializes in scalable enterprise application design using multiple programming languages. With a nearly 20 years of experience, he excels in LAMP and IIS environments, SEO strategies, and most recently designing agentic systems. Outside of work, Chris is an avid bassist and music lover, which helps fuel his creativity and problem-solving skills.
Chris Cocking specializes in scalable enterprise application design using multiple programming languages. With a nearly 20 years of experience, he excels in LAMP and IIS environments, SEO strategies, and most recently designing agentic systems. Outside of work, Chris is an avid bassist and music lover, which helps fuel his creativity and problem-solving skills.





















 Umesh Kalaspurkar is a Principal Solutions Architect at AWS based in New York, bringing over two decades of expertise in digital transformation and innovation across both enterprise and startup environments. He specializes in designing solutions that help organizations overcome their most pressing challenges. When not architecting cloud solutions, Umesh cherishes time spent with his children, carving down ski slopes, and exploring new destinations around the world.
Umesh Kalaspurkar is a Principal Solutions Architect at AWS based in New York, bringing over two decades of expertise in digital transformation and innovation across both enterprise and startup environments. He specializes in designing solutions that help organizations overcome their most pressing challenges. When not architecting cloud solutions, Umesh cherishes time spent with his children, carving down ski slopes, and exploring new destinations around the world. Samit Kumbhani is an AWS Senior Solutions Architect in the New York City area with over 18 years of experience. He currently partners with independent software vendors (ISVs) to build highly scalable, innovative, and secure cloud solutions. Outside of work, Samit enjoys playing cricket, traveling, and biking.
Samit Kumbhani is an AWS Senior Solutions Architect in the New York City area with over 18 years of experience. He currently partners with independent software vendors (ISVs) to build highly scalable, innovative, and secure cloud solutions. Outside of work, Samit enjoys playing cricket, traveling, and biking. Haoran (Hao) Su is a Senior Technical Account Manager in New York City with over 8 years of experience with the cloud. He collaborates with Software, Internet and Model providers (SWIM) and Digitally Native Businesses (DNB) to improve their financial and operational efficiency, and architectural resiliency. Outside of work, Hao enjoys international traveling, exercising, and streaming.
Haoran (Hao) Su is a Senior Technical Account Manager in New York City with over 8 years of experience with the cloud. He collaborates with Software, Internet and Model providers (SWIM) and Digitally Native Businesses (DNB) to improve their financial and operational efficiency, and architectural resiliency. Outside of work, Hao enjoys international traveling, exercising, and streaming. Anshika Tandon is a Senior Product Manager – Technical at AWS with a decade of experience building AI and B2B SaaS products from concept to launch. She excels in cross-functional product leadership, focusing on delivering measurable business value through strategic initiatives. A global citizen having lived in 10 cities and visited 26 countries, Anshika balances her professional life with interests in skiing, travel, and performing in improv comedy shows.
Anshika Tandon is a Senior Product Manager – Technical at AWS with a decade of experience building AI and B2B SaaS products from concept to launch. She excels in cross-functional product leadership, focusing on delivering measurable business value through strategic initiatives. A global citizen having lived in 10 cities and visited 26 countries, Anshika balances her professional life with interests in skiing, travel, and performing in improv comedy shows. Alex (Tao) Jia is a Senior Product Marketing Manager at AWS, focusing on generative AI. With 15+ years in tech marketing, she drives products from concept to scale, shaping positioning, fostering adoption, and leading global go-to-market strategies. She has worked with enterprises and ISVs, reaching millions of developers. Outside work, Alex enjoys exploring technology’s impact on humanity through books, research, and conversations.
Alex (Tao) Jia is a Senior Product Marketing Manager at AWS, focusing on generative AI. With 15+ years in tech marketing, she drives products from concept to scale, shaping positioning, fostering adoption, and leading global go-to-market strategies. She has worked with enterprises and ISVs, reaching millions of developers. Outside work, Alex enjoys exploring technology’s impact on humanity through books, research, and conversations.







 Jasmine Rasheed Syed is a Senior Customer Solutions manager at AWS, focused on accelerating time to value for the customers on their cloud journey by adopting best practices and mechanisms to transform their business at scale. Jasmine is a seasoned, result oriented leader with 20+ years of progressive experience in Insurance, Retail & CPG with exemplary track record spanning across Business Development, Cloud/Digital Transformation, Delivery, Operational & Process Excellence and Executive Management.
Jasmine Rasheed Syed is a Senior Customer Solutions manager at AWS, focused on accelerating time to value for the customers on their cloud journey by adopting best practices and mechanisms to transform their business at scale. Jasmine is a seasoned, result oriented leader with 20+ years of progressive experience in Insurance, Retail & CPG with exemplary track record spanning across Business Development, Cloud/Digital Transformation, Delivery, Operational & Process Excellence and Executive Management. Suprakash Dutta is a Sr. Solutions Architect at Amazon Web Services. He focuses on digital transformation strategy, application modernization and migration, data analytics, and machine learning. He is part of the AI/ML community at AWS and designs Generative AI and Intelligent Document Processing(IDP) solutions.
Suprakash Dutta is a Sr. Solutions Architect at Amazon Web Services. He focuses on digital transformation strategy, application modernization and migration, data analytics, and machine learning. He is part of the AI/ML community at AWS and designs Generative AI and Intelligent Document Processing(IDP) solutions. Joshua Amah is a Partner Solutions Architect at Amazon Web Services, specializing in supporting SI partners with a focus on AI/ML and generative AI technologies. He is passionate about guiding AWS Partners in using cutting-edge technologies and best practices to build innovative solutions that meet customer needs. Joshua provides architectural guidance and strategic recommendations for both new and existing workloads.
Joshua Amah is a Partner Solutions Architect at Amazon Web Services, specializing in supporting SI partners with a focus on AI/ML and generative AI technologies. He is passionate about guiding AWS Partners in using cutting-edge technologies and best practices to build innovative solutions that meet customer needs. Joshua provides architectural guidance and strategic recommendations for both new and existing workloads. Brad King is an Enterprise Account Executive at Amazon Web Services specializing in translating complex technical concepts into business value and making sure that clients achieve their digital transformation goals efficiently and effectively through long term partnerships.
Brad King is an Enterprise Account Executive at Amazon Web Services specializing in translating complex technical concepts into business value and making sure that clients achieve their digital transformation goals efficiently and effectively through long term partnerships. Joseph Mart is an AI/ML Specialist Solutions Architect at Amazon Web Services (AWS). His core competence and interests lie in machine learning applications and generative AI. Joseph is a technology addict who enjoys guiding AWS customers on architecting their workload in the AWS Cloud. In his spare time, he loves playing soccer and visiting nature.
Joseph Mart is an AI/ML Specialist Solutions Architect at Amazon Web Services (AWS). His core competence and interests lie in machine learning applications and generative AI. Joseph is a technology addict who enjoys guiding AWS customers on architecting their workload in the AWS Cloud. In his spare time, he loves playing soccer and visiting nature.









 Erik Cordsen is a Solutions Architect at AWS serving customers in Georgia. He is passionate about applying cloud technologies and ML to solve real life problems. When he is not designing cloud solutions, Erik enjoys travel, cooking, and cycling.
Erik Cordsen is a Solutions Architect at AWS serving customers in Georgia. He is passionate about applying cloud technologies and ML to solve real life problems. When he is not designing cloud solutions, Erik enjoys travel, cooking, and cycling. Renu Yadav is a Solutions Architect at Amazon Web Services (AWS), where she works with enterprise-level AWS customers providing them with technical guidance and help them achieve their business objectives. Renu has a strong passion for learning with her area of specialization in DevOps. She leverages her expertise in this domain to assist AWS customers in optimizing their cloud infrastructure and streamlining their software development and deployment processes.
Renu Yadav is a Solutions Architect at Amazon Web Services (AWS), where she works with enterprise-level AWS customers providing them with technical guidance and help them achieve their business objectives. Renu has a strong passion for learning with her area of specialization in DevOps. She leverages her expertise in this domain to assist AWS customers in optimizing their cloud infrastructure and streamlining their software development and deployment processes. Venkata Moparthi is a Senior Solutions Architect at AWS who empowers financial services organizations and other industries to navigate cloud transformation with specialized expertise in Cloud Migrations, Generative AI, and secure architecture design. His customer-focused approach combines technical innovation with practical implementation, helping businesses accelerate digital initiatives and achieve strategic outcomes through tailored AWS solutions that maximize cloud potential.
Venkata Moparthi is a Senior Solutions Architect at AWS who empowers financial services organizations and other industries to navigate cloud transformation with specialized expertise in Cloud Migrations, Generative AI, and secure architecture design. His customer-focused approach combines technical innovation with practical implementation, helping businesses accelerate digital initiatives and achieve strategic outcomes through tailored AWS solutions that maximize cloud potential.

 Upendra V is a Sr. Solutions Architect at Amazon Web Services, specializing in Generative AI and cloud solutions. He helps enterprise customers design and deploy production-ready Generative AI workloads, implement Large Language Models (LLMs) and Agentic AI systems, and optimize cloud deployments. With expertise in cloud adoption and machine learning, he enables organizations to build and scale AI-driven applications efficiently.
Upendra V is a Sr. Solutions Architect at Amazon Web Services, specializing in Generative AI and cloud solutions. He helps enterprise customers design and deploy production-ready Generative AI workloads, implement Large Language Models (LLMs) and Agentic AI systems, and optimize cloud deployments. With expertise in cloud adoption and machine learning, he enables organizations to build and scale AI-driven applications efficiently. Deepak Dixit is a Solutions Architect at Amazon Web Services, specializing in Generative AI and cloud solutions. He helps enterprises architect scalable AI/ML workloads, implement Large Language Models (LLMs), and optimize cloud-native applications.
Deepak Dixit is a Solutions Architect at Amazon Web Services, specializing in Generative AI and cloud solutions. He helps enterprises architect scalable AI/ML workloads, implement Large Language Models (LLMs), and optimize cloud-native applications.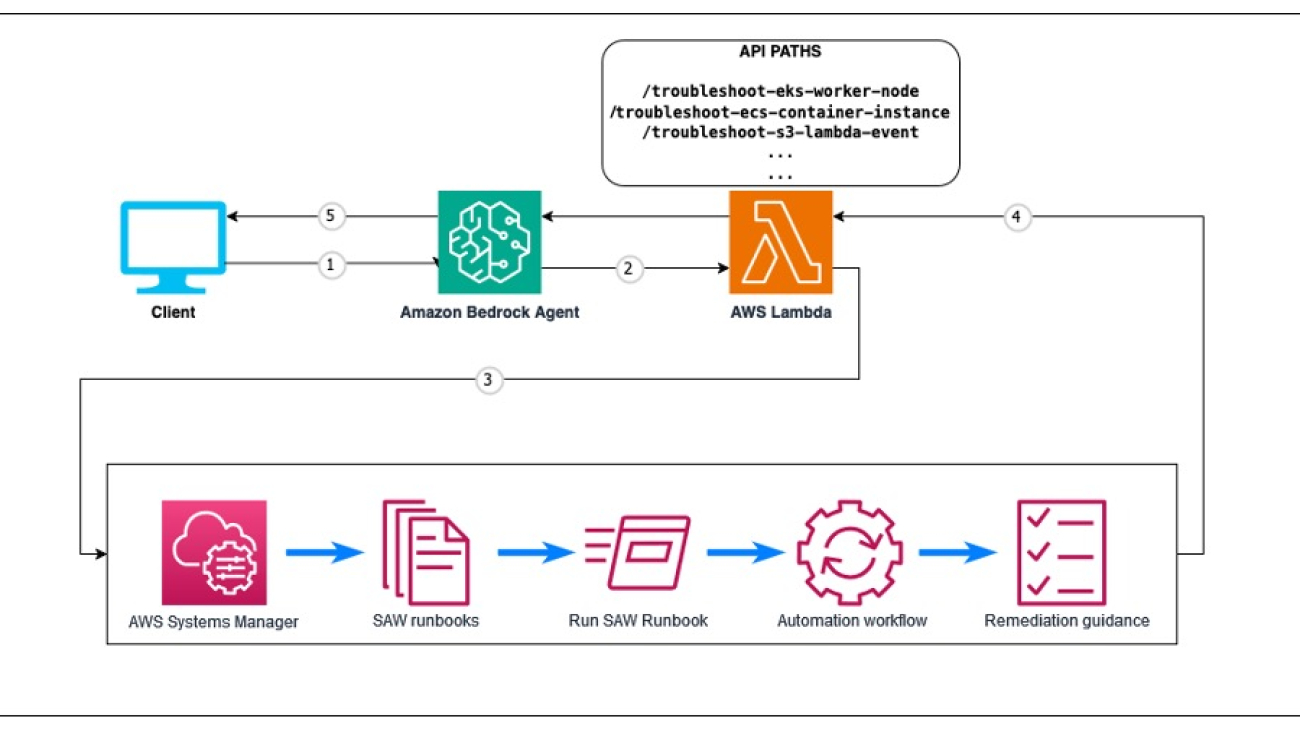




 Wael Dimassi is a Technical Account Manager at AWS, building on his 7-year background as a Machine Learning specialist. He enjoys learning about AWS AI/ML services and helping customers meet their business outcomes by building solutions for them.
Wael Dimassi is a Technical Account Manager at AWS, building on his 7-year background as a Machine Learning specialist. He enjoys learning about AWS AI/ML services and helping customers meet their business outcomes by building solutions for them. Marwen Benzarti is a Senior Cloud Support Engineer at AWS Support where he specializes in Infrastructure as Code. With over 4 years at AWS and 2 years of previous experience as a DevOps engineer, Marwen works closely with customers to implement AWS best practices and troubleshoot complex technical challenges. Outside of work, he enjoys playing both competitive multiplayer and immersive story-driven video games.
Marwen Benzarti is a Senior Cloud Support Engineer at AWS Support where he specializes in Infrastructure as Code. With over 4 years at AWS and 2 years of previous experience as a DevOps engineer, Marwen works closely with customers to implement AWS best practices and troubleshoot complex technical challenges. Outside of work, he enjoys playing both competitive multiplayer and immersive story-driven video games.