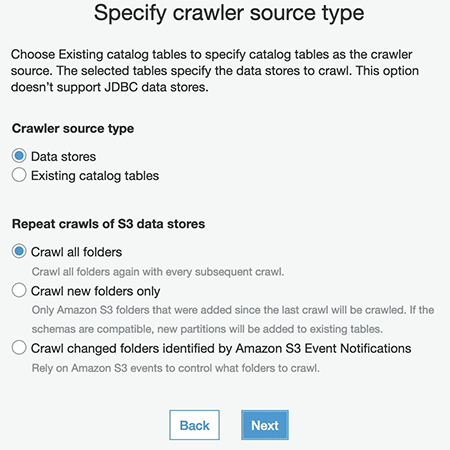
So much data, so little time. Machine learning (ML) experts, data scientists, engineers and enthusiasts have encountered this problem the world over. From natural language processing to computer vision, tabular to time series, and everything in-between, the age-old problem of optimizing for speed when running data against as many GPUs as you can get has inspired countless solutions. Today, we’re happy to announce features for PyTorch developers using native open-source frameworks, like PyTorch Lightning and PyTorch DDP, that will streamline their path to the cloud.
Amazon SageMaker is a fully-managed service for ML, and SageMaker model training is an optimized compute environment for high-performance training at scale. SageMaker model training offers a remote training experience with a seamless control plane to easily train and reproduce ML models at high performance and low cost. We’re thrilled to announce new features in the SageMaker training portfolio that make running PyTorch at scale even easier and more accessible:
- PyTorch Lightning can now be integrated to SageMaker’s distributed data parallel library with only one-line of code change.
- SageMaker model training now has support for native PyTorch Distributed Data Parallel with NCCL backend, allowing developers to migrate onto SageMaker easier than ever before.
In this post, we discuss these new features, and also learn how Amazon Search has run PyTorch Lightning with the optimized distributed training backend in SageMaker to speed up model training time.
Before diving into the Amazon Search case study, for those who aren’t familiar we would like to give some background on SageMaker’s distributed data parallel library. In 2020, we developed and launched a custom cluster configuration for distributed gradient descent at scale that increases overall cluster efficiency, introduced on Amazon Science as Herring. Using the best of both parameter servers and ring-based topologies, SageMaker Distributed Data Parallel (SMDDP) is optimized for the Amazon Elastic Compute Cloud (Amazon EC2) network topology, including EFA. For larger cluster sizes, SMDDP is able to deliver 20–40% throughput improvements relative to Horovod (TensorFlow) and PyTorch Distributed Data Parallel. For smaller cluster sizes and supported models, we recommend the SageMaker Training Compiler, which is able to decrease overall job time by up to 50%.
Customer spotlight: PyTorch Lightning on SageMaker’s optimized backend with Amazon Search
Amazon Search is responsible for the search and discovery experience on Amazon.com. It powers the search experience for customers looking for products to buy on Amazon. At a high level, Amazon Search builds an index for all products sold on Amazon.com. When a customer enters a query, Amazon Search then uses a variety of ML techniques, including deep learning models, to match relevant and interesting products to the customer query. Then it ranks the products before showing the results to the customer.
Amazon Search scientists have used PyTorch Lightning as one of the main frameworks to train the deep learning models that power Search ranking due to its added usability features on top of PyTorch. SMDDP was not supported for deep learning models written in PyTorch Lightning before this new SageMaker launch. This prevented Amazon Search scientists who prefer using PyTorch Lightning from scaling their model training using data parallel techniques, significantly slowing down their training time and preventing them from testing new experiments that require more scalable training.
The team’s early benchmarking results show 7.3 times faster training time for a sample model when trained on eight nodes as compared to a single-node training baseline. The baseline model used in these benchmarking is a multi-layer perceptron neural network with seven dense fully connected layers and over 200 parameters. The following table summarizes the benchmarking result on ml.p3.16xlarge SageMaker training instances.
| Number of Instances | Training Time (minutes) | Improvement |
| 1 | 99 | Baseline |
| 2 | 55 | 1.8x |
| 4 | 27 | 3.7x |
| 8 | 13.5 | 7.3x |
Next, we dive into the details on the new launches. If you like, you can step through our corresponding example notebook .
Run PyTorch Lightning with the SageMaker distributed training library
We are happy to announce that SageMaker Data Parallel now seamlessly integrates with PyTorch Lightning within SageMaker training.
PyTorch Lightning is an open-source framework that provides a simplification for writing custom models in PyTorch. In some ways similar to what Keras did for TensorFlow, or even arguably Hugging Face, PyTorch Lightning provides a high-level API with abstractions for much of the lower-level functionality of PyTorch itself. This includes defining the model, profiling, evaluation, pruning, model parallelism, hyperparameter configurations, transfer learning, and more.
Previously, PyTorch Lightning developers were uncertain about how to seamlessly migrate their training code on to high-performance SageMaker GPU clusters. In addition, there was no way for them to take advantage of efficiency gains introduced by SageMaker Data Parallel.
For PyTorch Lightning, generally speaking, there should be little-to-no code changes to simply run these APIs on SageMaker Training. In the example notebooks we use the DDPStrategy and DDPPlugin methods.
There are three steps to use PyTorch Lightning with SageMaker Data Parallel as an optimized backend:
- Use a supported AWS Deep Learning Container (DLC) as your base image, or optionally create your own container and install the SageMaker Data Parallel backend yourself. Ensure that you have PyTorch Lightning included in your necessary packages, such as with a
requirements.txtfile. - Make a few minor code changes to your training script that enable the optimized backend. These include:
- Import the SM DDP library:
- Set up the PyTorch Lightning environment for SageMaker:
- If you’re using a version of PyTorch Lightning older than 1.5.10, you’ll need to add a few more steps.
- First, add the environment variable:
- Second, ensure you use
DDPPlugin, rather thanDDPStrategy. If you’re using a more recent version, which you can easily set by placing therequirements.txtin thesource_dirfor your job, then this isn’t necessary. See the following code:
- Optionally, define your process group backend as
"smddp"in theDDPSTrategyobject. However, if you’re using PyTorch Lightning with the PyTorch DDP backend, which is also supported, simply remove this `process_group_backend` parameter. See the following code:
- Ensure that you have a distribution method noted in the estimator, such as
distribution={"smdistributed":{"dataparallel":{"enabled":True}if you’re using the Herring backend, ordistribution={"pytorchddp":{"enabled":True}.
- For a full listing of suitable parameters in the
distributionparameter, see our documentation here.
Now you can launch your SageMaker training job! You can launch your training job via the Python SDK, Boto3, the SageMaker console, the AWS Command Line Interface (AWS CLI), and countless other methods. From an AWS perspective, this is a single API command: create-training-job. Whether you launch this command from your local terminal, an AWS Lambda function, an Amazon SageMaker Studio notebook, a KubeFlow pipeline, or any other compute environment is completely up to you.
Please note that the integration between PyTorch Lightning and SageMaker Data Parallel is currently supported for only newer versions of PyTorch, starting at 1.11. In addition, this release is only available in the AWS DLCs for SageMaker starting at PyTorch 1.12. Make sure you point to this image as your base. In us-east-1, this address is as follows:
Then you can extend your Docker container using this as your base image, or you can pass this as a variable into the image_uri argument of the SageMaker training estimator.
As a result, you’ll be able to run your PyTorch Lightning code on SageMaker Training’s optimized GPUs, with the best performance available on AWS.
Run PyTorch Distributed Data Parallel on SageMaker
The biggest problem PyTorch Distributed Data Parallel (DDP) solves is deceptively simple: speed. A good distributed training framework should provide stability, reliability, and most importantly, excellent performance at scale. PyTorch DDP delivers on this through providing torch developers with APIs to replicate their models over multiple GPU devices, in both single-node and multi-node settings. The framework then manages sharding different objects from the training dataset to each model copy, averaging the gradients for each of the model copies to synchronize them at each step. This produces one model at the total completion of the full training run. The following diagram illustrates this process.

PyTorch DDP is common in projects that use large datasets. The precise size of each dataset will vary widely, but a general guideline is to scale datasets, compute sizes, and model sizes in similar ratios. Also called scaling laws, the optimal combination of these three is very much up for debate and will vary based on applications. At AWS, based on working with multiple customers, we can clearly see benefits from data parallel strategies when an overall dataset size is at least a few tens of GBs. When the datasets get even larger, implementing some type of data parallel strategy is a critical technique to speed up the overall experiment and improve your time to value.
Previously, customers who were using PyTorch DDP for distributed training on premises or in other compute environments lacked a framework to easily migrate their projects onto SageMaker Training to take advantage of high-performance GPUs with a seamless control plane. Specifically, they needed to either migrate their data parallel framework to SMDDP, or develop and test the capabilities of PyTorch DDP on SageMaker Training manually. Today, SageMaker Training is happy to provide a seamless experience for customers onboarding their PyTorch DDP code.
To use this effectively, you don’t need to make any changes to your training scripts.
You can see this new parameter in the following code. In the distribution parameter, simply add pytorchddp and set enabled as true.
This new configuration starts at SageMaker Python SDK versions 2.102.0 and PyTorch DLC’s 1.11.
For PyTorch DDP developers who are familiar with the popular torchrun framework, it’s helpful to know that this isn’t necessary on the SageMaker training environment, which already provides robust fault tolerance. However, to minimize code rewrites, you can bring another launcher script that runs this command as your entry point.
Now PyTorch developers can easily move their scripts onto SageMaker, ensuring their scripts and containers can run seamlessly across multiple compute environments.
This prepares them to, in the future, take advantage of SageMaker’s distributed training libraries that provide AWS-optimized training topologies to deliver up to 40% speedup enhancements. For PyTorch developers, this is a single line of code! For PyTorch DDP code, you can simply set the backend to smddp in the initialization (see Modify a PyTorch Training Script), as shown in the following code:
As we saw above, you can also set the backend of DDPStrategy to smddp when using Lightning. This can lead to up to 40% overall speedups for large clusters! To learn more about distributed training on SageMaker see our on-demand webinar, supporting notebooks, relevant documentation, and papers.
Conclusion
In this post, we introduced two new features within the SageMaker Training family. These make it much easier for PyTorch developers to use their existing code on SageMaker, both PyTorch DDP and PyTorch Lightning.
We also showed how Amazon Search uses SageMaker Training for training their deep learning models, and in particular PyTorch Lightning with the SageMaker Data Parallel optimized collective library as a backend. Moving to distributed training overall helped Amazon Search achieve 7.3x faster train times.
About the authors
 Emily Webber joined AWS just after SageMaker launched, and has been trying to tell the world about it ever since! Outside of building new ML experiences for customers, Emily enjoys meditating and studying Tibetan Buddhism.
Emily Webber joined AWS just after SageMaker launched, and has been trying to tell the world about it ever since! Outside of building new ML experiences for customers, Emily enjoys meditating and studying Tibetan Buddhism.
 Karan Dhiman is a Software Development Engineer at AWS, based in Toronto, Canada. He is very passionate about Machine Learning space and building solutions for accelerating distributed computing workloads.
Karan Dhiman is a Software Development Engineer at AWS, based in Toronto, Canada. He is very passionate about Machine Learning space and building solutions for accelerating distributed computing workloads.
 Vishwa Karia is a Software Development Engineer at AWS Deep Engine. Her interests lie at the intersection of Machine Learning and Distributed Systems and she is also passionate about empowering women in tech and AI.
Vishwa Karia is a Software Development Engineer at AWS Deep Engine. Her interests lie at the intersection of Machine Learning and Distributed Systems and she is also passionate about empowering women in tech and AI.
 Eiman Elnahrawy is a Principal Software Engineer at Amazon Search leading the efforts on Machine Learning acceleration, scaling, and automation. Her expertise spans multiple areas, including Machine Learning, Distributed Systems, and Personalization.
Eiman Elnahrawy is a Principal Software Engineer at Amazon Search leading the efforts on Machine Learning acceleration, scaling, and automation. Her expertise spans multiple areas, including Machine Learning, Distributed Systems, and Personalization.









 James Jory is a Principal Solutions Architect in Applied AI with AWS. He has a special interest in personalization and recommender systems and a background in ecommerce, marketing technology, and customer data analytics. In his spare time, he enjoys camping and auto racing simulations.
James Jory is a Principal Solutions Architect in Applied AI with AWS. He has a special interest in personalization and recommender systems and a background in ecommerce, marketing technology, and customer data analytics. In his spare time, he enjoys camping and auto racing simulations. Daniel Foley is a Senior Product Manager for Amazon Personalize. He is focused on building applications that leverage artificial intelligence to solve our customers’ largest challenges. Outside of work, Dan is an avid skier and hiker.
Daniel Foley is a Senior Product Manager for Amazon Personalize. He is focused on building applications that leverage artificial intelligence to solve our customers’ largest challenges. Outside of work, Dan is an avid skier and hiker. Alex Berlingeri is a Software Development Engineer with Amazon Personalize working on a machine learning powered recommendations service. In his free time he enjoys reading, working out and watching soccer.
Alex Berlingeri is a Software Development Engineer with Amazon Personalize working on a machine learning powered recommendations service. In his free time he enjoys reading, working out and watching soccer.