Amazon ICML paper proposes information-theoretic measurement of quantitative causal contribution.Read More
Generate synchronized closed captions and audio using the Amazon Polly subtitle generator
Amazon Polly, an AI generated text-to-speech service, enables you to automate and scale your interactive voice solutions, helping to improve productivity and reduce costs.
As our customers continue to use Amazon Polly for its rich set of features and ease of use, we have observed a demand for the ability to simultaneously generate synchronized audio and subtitles or closed captions for a given text input. At AWS, we continuously work backward from our customer asks, so in this post, we outline a method to generate audio and subtitles at the same time for a given text.
Although subtitles and captions are often used interchangeably, including in this post, there are subtle differences among them:
- Subtitles – In subtitles, text language displayed on the screen is different from the audio language and doesn’t display anything for non-dialogue like significant sounds. The primary objective is to reach the audience that doesn’t speak the audio language in the video.
- Captions (closed/open) – Captions display the dialogues being spoken in the audio in the same language. Its primary purpose is to increase accessibility in cases where the audio can’t be heard by the end consumer due to a range of issues. Closed captions are part of a different file than the audio/video source and can be turned off and on at the user’s discretion, whereas open captions are part of the video file and can’t be turned off by the user.
Benefits of using Amazon Polly to generate audio with subtitles or closed captions
Imagine the following use case: you prepare a slide-based presentation for an online learning portal. Each slide includes onscreen content and narration. The onscreen content is a basic outline, and the narration goes into detail. Instead of recording a human voice, which can be cumbersome and inconsistent, you can use Amazon Polly to generate the narration. Amazon Polly produces high-quality, consistent voices. There’s no need for post-production. In the future, if you need to update a portion of the presentation, you only need to update the affected slides. The voice matches the original slides. Additionally, when Amazon Polly generates your audio, captions are included that appear in time with the audio. You save time because there’s no manual recording involved, and save additional time when updates are needed. Your presentation also delivers more value because captions help students consume the content. It’s a win-win-win solution.
There are a multitude of use cases for captions, such as advertisements in social spaces, gymnasiums, coffee shops, and other places where typically there is something on a television with the audio muted and music in the background; online training and classes; virtual meetings; public electronic announcements; watching videos while commuting without headphones and without disturbing co-passengers; and several more.
Irrespective of the field of application, closed captioning can help with the following:
- Accessibility – People with hearing impairments can better consume your content.
- Retention – Online learning is easier for e-learners to grasp and retain when more human senses are involved.
- Reachability – Your content can reach people that have competing priorities, such as gaming and watching news simultaneously, or people who have a different native language than the audio language.
- Searchability – The content is searchable by search engines. Whereas videos can’t be searched optimally by most search engines, search engines can use the caption text files and make your content more discoverable.
- Social courtesy – Sometimes it may be rude to play audio because of your surroundings, or the audio could be difficult to hear because of the noise of your environment.
- Comprehension – The content is easier to comprehend irrespective of the accent of the speaker, native language of the speaker, or speed of speech. You can also take notes without repeatedly watching the same scene.
Solution overview
The library presented in this post uses Amazon Polly to generate sound and closed captions for an input text. You can easily integrate this library in your text-to-speech applications. It supports several audio formats, and captions in both VTT and SRT file formats, which are the most commonly used across the industry.
In this post, we focus on the PollyVTT() syntax and options, and offer a few examples that demonstrate how to use the Python SubtitleGeneratorForPolly to simultaneously generate synchronous audio and subtitle files for a given text input. The output audio file format can be PCM(wav), OGG, or MP3, and the subtitle file format can be VTT or SRT. Furthermore, SubtitleGeneratorForPolly supports all Amazon Polly synthesize_speech parameters and adds to the rich Amazon Polly feature set.
The polly-vtt library and its dependencies are available on GitHub.
Install and use the function
Before we look at some examples of using PollyVTT(), the function that powers SubtitleGeneratorForPolly, let’s look at the installation and syntax of it.
Install the library using the following code:
To run from the command line, you simply run polly-vtt:
The following code shows your options:
Let’s look at a few examples now.
Example 1
This example generates a PCM audio file along with an SRT caption file for two simple sentences:
Example 2
This example demonstrates how to use a paragraph of text as input. This generates audio files in WAV, MP3, and OGG, and subtitles in SRT and VTT. The following example creates six files for the given input text:
pcm_testfile.wavpcm_testfile.wav.vttmp3_testfile.mp3mp3_testfile.mp3.vttogg_testfile.oggogg_testfile.ogg.srt
See the following code:
Example 3
In most cases, however, you want to pass the text as an input file. The following is a Python example of this, with the same output as the previous example:
The following is a testimonial post from the AWS internal training team of using Amazon Polly with closed captions:
The following video offers a short demo of how the internal training team at AWS uses PollyVTT():
Conclusion
In this post, we shared a method to generate audio and subtitles at the same time for a given text. The PollyVTT() function and SubtitleGeneratorForPolly address a common requirement for subtitles in an efficient and effective manner. The Amazon Polly team continues to invent and offer simplified solutions to complex customer requirements.
For more tutorials and information about Amazon Polly, check out the AWS Machine Learning Blog.
About the Authors
 Abhishek Soni is a Partner Solutions Architect at AWS. He works with customers to provide technical guidance for the best outcome of workloads on AWS.
Abhishek Soni is a Partner Solutions Architect at AWS. He works with customers to provide technical guidance for the best outcome of workloads on AWS.
 Dan McKee uses audio, video, and coffee to distill content into targeted, modular, and structured courses. In his role as Curriculum Developer Project Manager for the NetSec Domain at Amazon Web Services, he leverages his experience in Data Center Networking to help subject matter experts bring ideas to life.
Dan McKee uses audio, video, and coffee to distill content into targeted, modular, and structured courses. In his role as Curriculum Developer Project Manager for the NetSec Domain at Amazon Web Services, he leverages his experience in Data Center Networking to help subject matter experts bring ideas to life.
 Orlando Karam is a Technical Curriculum Developer at Amazon Web Services, which means he gets to play with cool new technologies and then talk about it. Occasionally, he also uses those cool technologies to make his job easier.
Orlando Karam is a Technical Curriculum Developer at Amazon Web Services, which means he gets to play with cool new technologies and then talk about it. Occasionally, he also uses those cool technologies to make his job easier.
Accelerate your identity verification projects using AWS Amplify and Amazon Rekognition sample implementations
Amazon Rekognition allows you to mitigate fraudulent attacks and minimize onboarding friction for legitimate customers through a streamlined identity verification process. This can result in an increase in customer trust and safety. Key capabilities of this solution include:
- Register a new user using a selfie
- Register a new user after face match against an ID card and ID card data extraction
- Authenticate returning user
Amazon Rekognition offers pre-trained facial recognition capabilities that you can quickly add to your user onboarding and authentication workflows to verify opted-in users’ identities online. No machine learning (ML) expertise is required to use this service.
In a previous post, we described a typical identity verification workflow and showed you how to build an identity verification solution using various Amazon Rekognition APIs. In this post, we have added a facial identity-based authentication user interface to show a complete end-to-end identity verification solution. We provide a complete sample implementation in our GitHub repository.
Solution overview
The following reference architecture shows how you can use Amazon Rekognition, along with other AWS services, to implement identity verification.
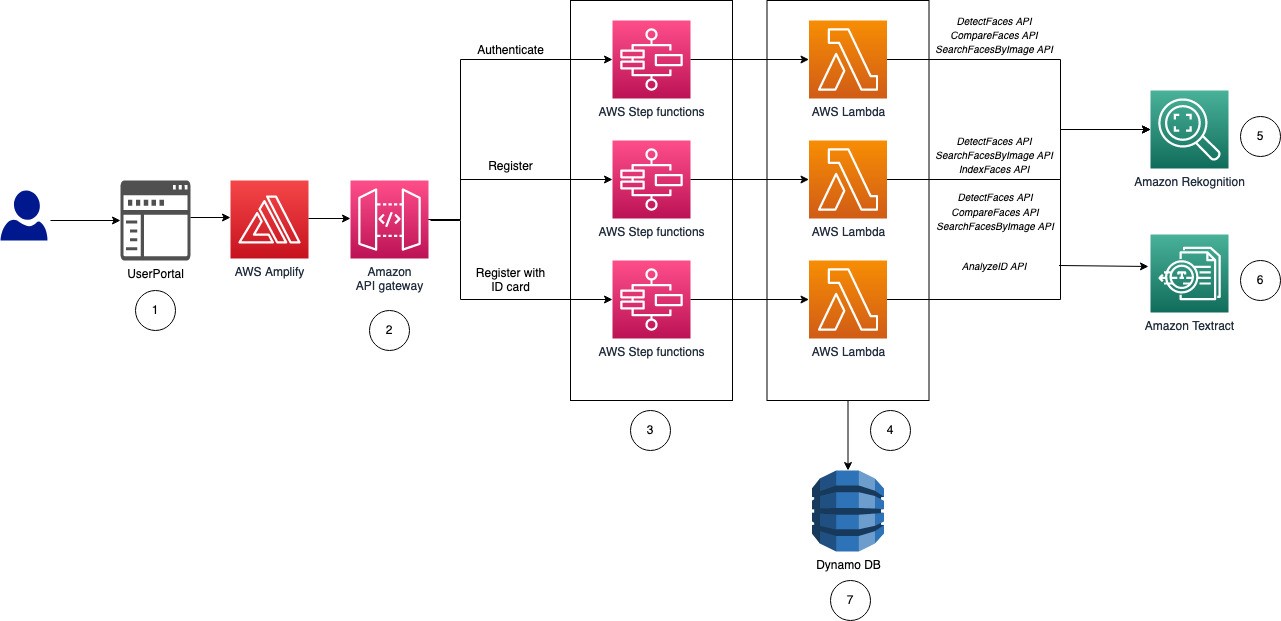
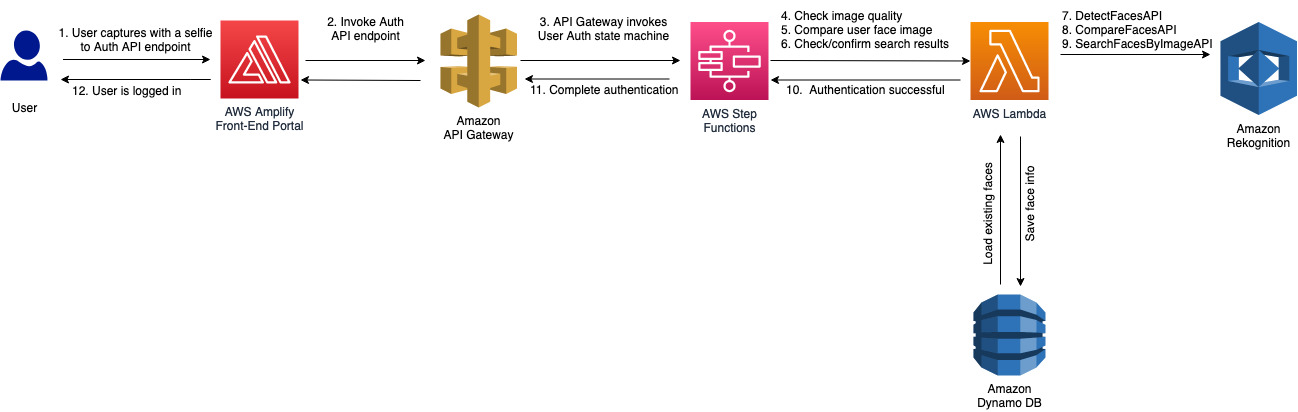
The architecture includes the following components:
- Users access the front-end web portal hosted within the AWS Amplify Amplify is an end-to-end solution that enables front-end web developers to build and deploy secure, scalable full stack applications.
- Applications invoke Amazon API Gateway to route requests to the correct AWS Lambda function depending on the user flow. There are four major actions in this solution: authenticate, register, register with ID card, and update.
- API Gateway uses a service integration to run the AWS Step Functions express state machine corresponding to the specific endpoint called from API Gateway. Within each step, Lambda functions are responsible for triggering the correct set of calls to and from Amazon DynamoDB and Amazon Simple Storage Service (Amazon S3), along with the relevant Amazon Rekognition APIs.
- DynamoDB holds face IDs (
face-id), S3 path URIs, and unique IDs (for example employee ID number) for eachface-id. Amazon S3 stores all the face images. - The final major component of the solution is Amazon Rekognition. Each flow (authenticate, register, register with ID card, and update) calls different Amazon Rekognition APIs depending on the task.
Before we deploy the solution, it’s important to know the following concepts and API descriptions:
- Collections – Amazon Rekognition stores information about detected faces in server-side containers known as collections. You can use the facial information that’s stored in a collection to search for known faces in images, stored videos, and streaming videos. You can use collections in a variety of scenarios. For example, you might create a face collection to store scanned badge images by using the IndexFaces When an employee enters the building, an image of the employee’s face may be captured and sent to the SearchFacesByImage operation. If the face match produces a sufficiently high similarity score (say 99%), you can authenticate the employee.
- DetectFaces API – This API detects faces within an image provided as input and returns information about faces. In a user registration workflow, this operation may help you screen images before moving to the next step. For example, you can check if a photo contains a face, if the person identified is in the right orientation, and if they’re not wearing a face blocker such as sunglasses or a cap.
- IndexFaces API – This API detects faces in the input image and adds them to the specified collection. This operation is used to add a screened image to a collection for future queries.
- SearchFacesByImage API – For a given input image, the API first detects the largest face in the image, and then searches the specified collection for matching faces. The operation compares the features of the input face with face features in the specified collection.
- CompareFaces API – This API compares a face in the source input image with each of the 100 largest faces detected in the target input image. If the source image contains multiple faces, the service detects the largest face and compares it with each face detected in the target image. For our use case, we expect both the source and target image to contain a single face.
- DeleteFaces API – This API deletes faces from a collection. You specify a collection ID and an array of face IDs to remove.
Workflows
The solution provides a sample of workflows to enable user registration, authentication, and updates to the user profile image. We detail each workflow in this section.
Register a new user using a face selfie
The following figure shows the workflow of a new user registration. Typical steps in this process are:
- A user captures a selfie image.
- A quality check of the selfie image is performed.
Note: A liveness detection check can also be performed after this step. For more details, please read this blog. - The selfie is checked against a database of existing user faces.
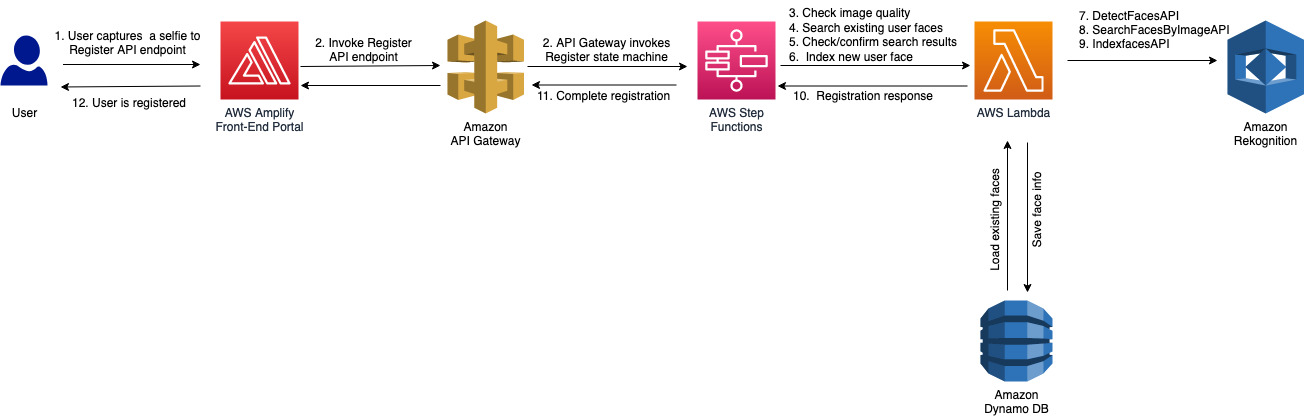
The following image illustrates the Step Functions workflow for new user registration.
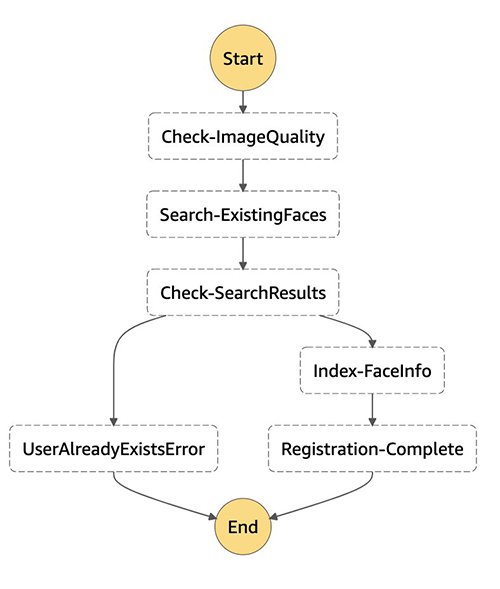
Three functions are called in this workflow: detect-faces, search-faces, and index-faces. The detect-faces function calls the Amazon Rekognition DetectFaces API to determine if a face is detected in an image and is usable. Some of the quality checks include determining that only one face is present in the image, ensuring the face isn’t obscured by sunglasses or a hat, and confirming that the face isn’t rotated by using the pose dimension. If the image passes the quality check, the search-faces function searches for an existing face match in the Amazon Rekognition collections by confirming the FaceMatchThreshold confidence score meets your threshold objective. For more information, refer to Using similarity thresholds to match faces. If the face image doesn’t exist in the collections, the index-faces function is called to index the face in the collections. The face image metadata is stored in the DynamoDB table and the face images are stored in an S3 bucket.
If the new user registration succeeds, the face image attribute information is added in DynamoDB. You can customize the flow according to the business process. It often contains some or all of the steps presented in the preceding diagram. You can choose to run all the steps synchronously (wait for one step to complete before moving on to the next step). Alternately, you can run some of the steps asynchronously (don’t wait for that step to complete) to speed up the user registration process and improve the customer experience. If the steps aren’t successful, you must roll back the user registration.
Register a new user after face match against an ID card with ID card data extraction
In addition to user registration with image, this workflow allows users to register with an identification card like driver’s license. The steps to register a new user with an ID card are similar to the steps for registering a new user.
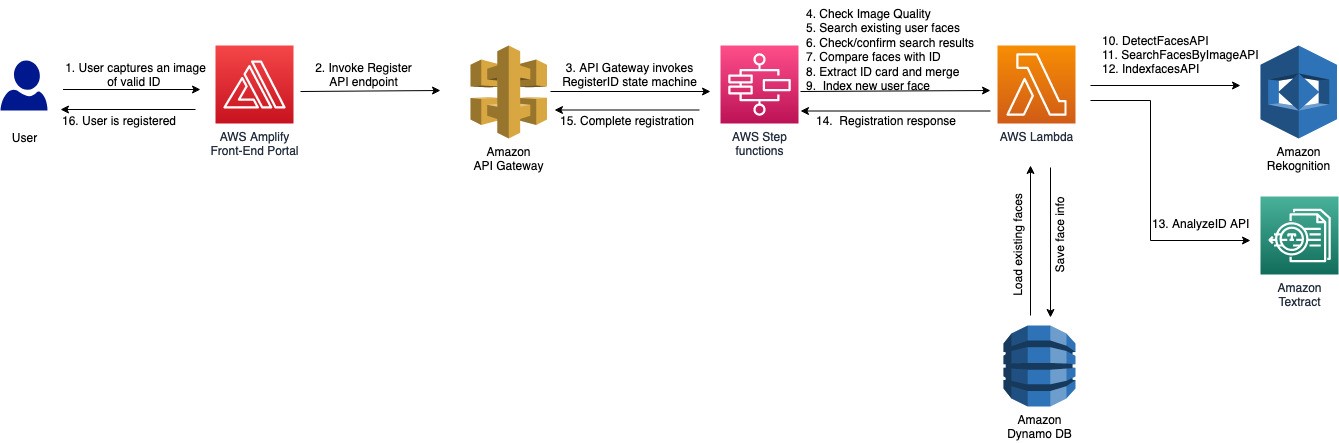
The following image illustrates the Step Functions workflow for new user registration with ID.
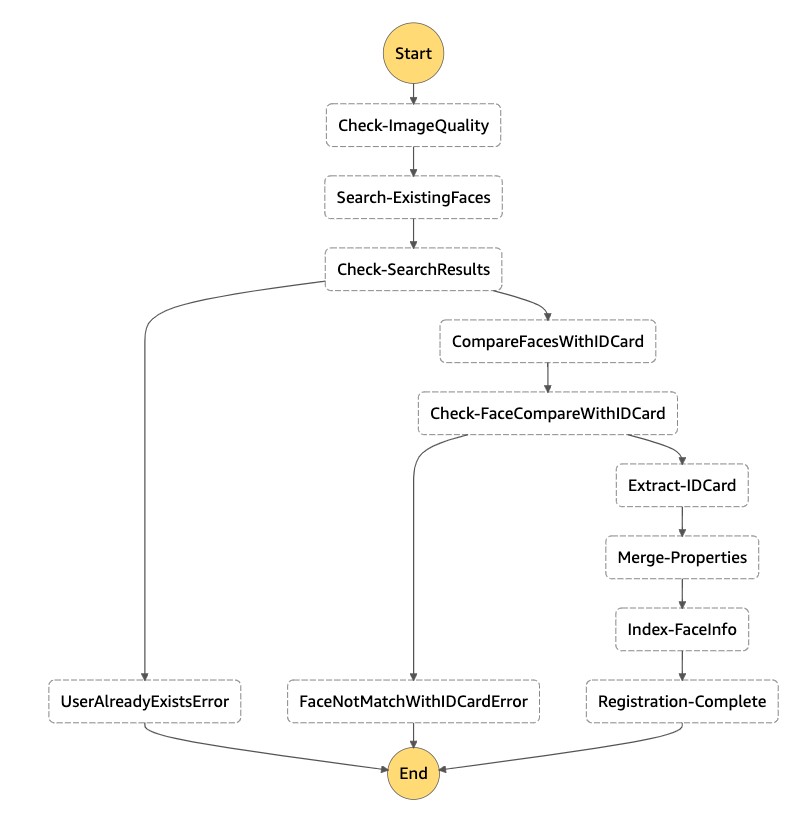
Four functions are called in this workflow: detect-faces, search-faces, index-faces and compare-faces. The sequence of operations in this workflow is similar to the user registration workflow with the addition of compare-faces. After verifying the quality of the selfie image and ensuring the face image is not present in the collection, the compare-faces function is invoked to verify the selfie image matches the face image in the ID card. If the images match, the relevant properties are extracted from the ID card. You can extract key-value pairs from identity documents using the newly launched Amazon Textract AnalyzeID API (for US regions) or Amazon Rekognition DetectText API (non-US regions and non-English languages). The extracted properties from the ID card are merged and the user’s face is indexed in the collection via the index-faces function.
The face image metadata is stored in the DynamoDB table and the face images are stored in an S3 bucket.
If the images don’t match or a duplicate registration is detected, the user receives a login failure. Login failures can be logged using an Amazon CloudWatch event, and actions can be triggered using Amazon Simple Notification Service (Amazon SNS) to notify security operations for monitoring and tracking failed logins. For more information, refer to Monitoring Amazon SNS topics using CloudWatch.
Authenticate returning user
Another common flow is an existing or returning user login. In this flow, a check of the user face (selfie) is performed against a previously registered face. Typical steps in this process include user face capture (selfie), check of the selfie image quality, and search and compare of the selfie against the faces database. The following diagram shows a possible flow.
The following image illustrates the workflow for authenticating an existing user.
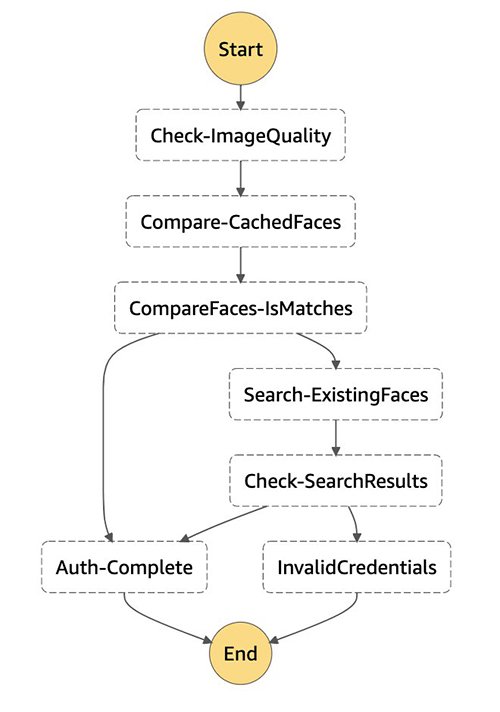
This Step Function workflow calls three functions: detect-faces, compare-faces and search-faces. After the detect-faces function verifies that the captured face image is valid, the compare-faces function checks the link in the DynamoDB table for a face image in S3 bucket that matches an existing user. If a match is found, the user authenticates successfully. If a match isn’t found, the search-faces function is called to search for the face image in the collections. The user is verified and the authentication process completes if their face image exists in the collections. Otherwise, the user’s access is denied.
Prerequisites
Before you get started, complete the following prerequisites:
- Create an AWS account.
- Install the AWS Command Line Interface (AWS CLI) version 2 on your local machine. For instructions, refer to Installing or updating the latest version of the AWS CLI.
- Set up the AWS CLI.
- Install Node.js on your local machine.
- Clone the sample repo on your local machine:
Deploy the solution
Choose the appropriate CloudFormation stack to provision the solution in your AWS account in your preferred Region. This solution deploys API Gateway integrated with Step Functions and Amazon Rekognition APIs to run the identity verification workflows.
Clicking on one of the following launch buttons will provision the solution into your AWS Account in the particular region.
![]() N. Virginia (
N. Virginia (us-east-1)
![]() Oregon (
Oregon (us-west-2)
Run the following steps on your local machine to deploy the Front-end application:
Invoke the web UI
The web portal is deployed with Amplify. On the Amplify console, locate the hosted web application environment and the URL. Copy the URL and access it from your browser.

Register a new user using a face selfie
Register yourself as a user with the following steps:
- Open the web URL provided from Amplify.
- Choose Register
- Enable your camera and capture a face image.
- Enter your user name and details.
- Choose Signup to register your account.
Authenticate returning user
After you’re registered, you log in using the face ID as an authentication mechanism.
- Open the web URL provided by Amplify
- Capture your face ID.
- Enter your user ID.
- Choose Login.

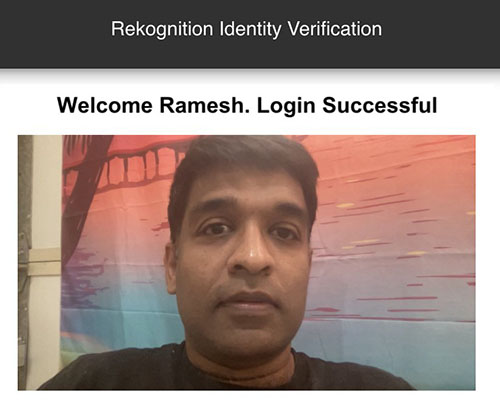
You get a “Login successful” message after your face ID is verified with the registration image.
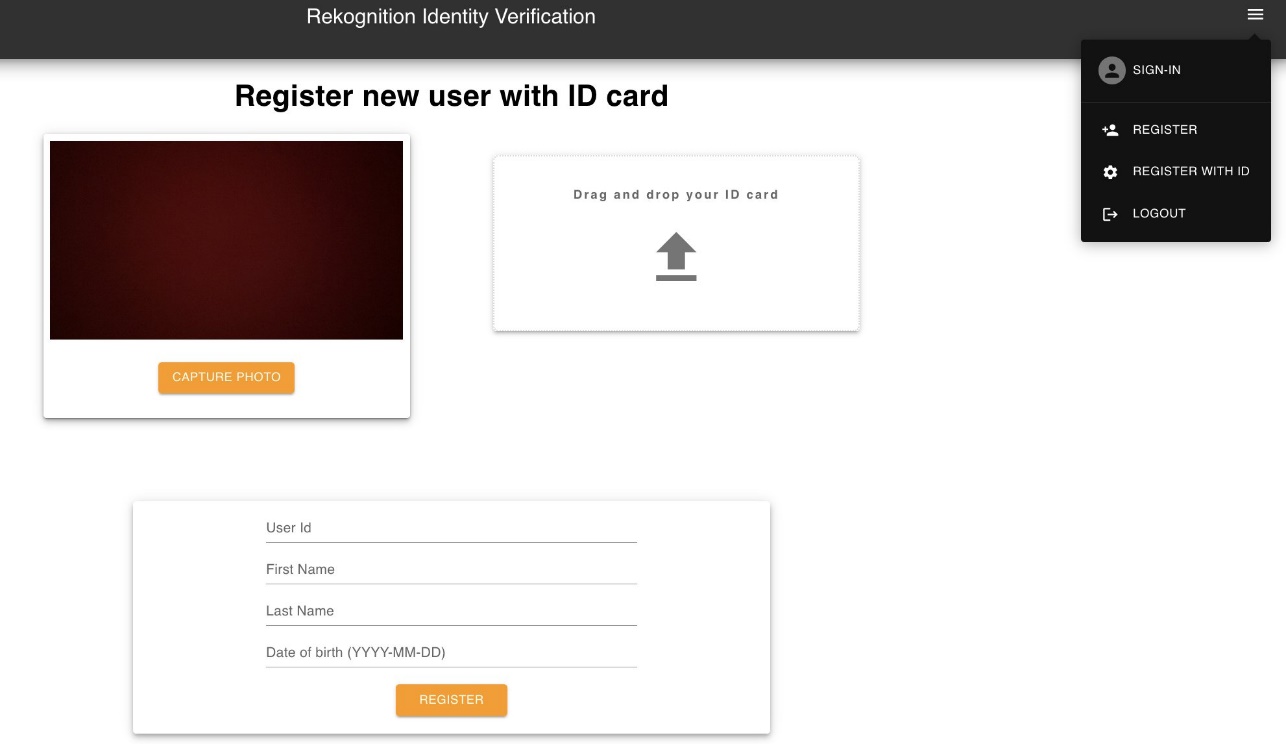
Register a new user after face match against an ID card with ID card data extraction
To test user registration with an ID, complete the following steps:
- Open the web URL provided by Amplify.
- Choose Register with ID
- Enable your camera and capture a face image.
- Drag and drop your ID card
- Choose Register.
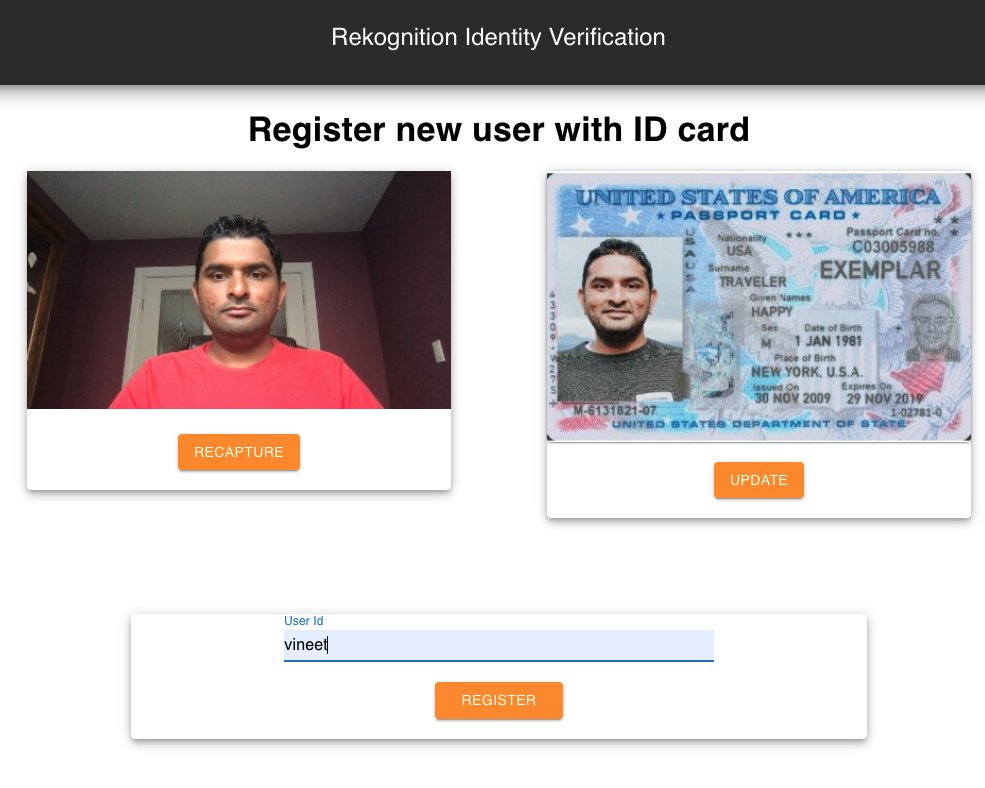
The following screenshot shows an example. The application supports ID card images of up to 256 KB.
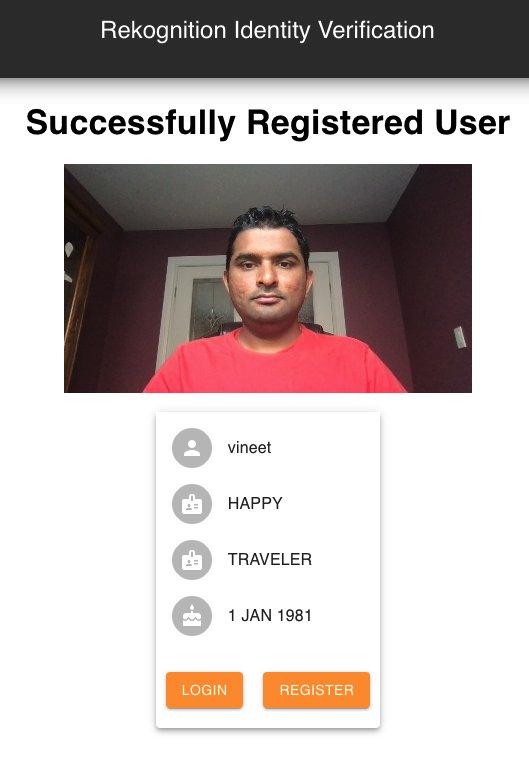
You receive a “Successfully Registered User” message.
Clean up
To prevent accruing additional charges in your AWS account, delete the resources you provisioned by navigating to the AWS CloudFormation console and deleting the Riv-Prod stack.
Deleting the stack doesn’t delete the S3 bucket you created. This bucket stores all the face images. If you want to delete the S3 bucket, navigate to the Amazon S3 console, empty the bucket, and then confirm you want to permanently delete it.
Conclusion
Amazon Rekognition makes it easy to add image analysis to your identity verification applications using proven, highly scalable, deep learning technology that requires no ML expertise to use. Amazon Rekognition provides face detection and comparison capabilities. With a combination of the DetectFaces, CompareFaces, IndexFaces, SearchFacesByImage, DetectText and AnalyzeID, you can implement the common flows around new user registration and existing user logins.
Amazon Rekognition collections provide a method to store information about detected faces in server-side containers. You can then use the facial information stored in a collection to search for known faces in images. When using collections, you don’t need to store original photos after you index faces in the collection. Amazon Rekognition collections don’t persist actual images. Instead, the underlying detection algorithm detects the faces in the input image, extracts facial features into a feature vector for each face, and stores it in the collection.
To start your journey towards identity verification, visit Identity Verification using Amazon Rekognition.
About the authors
 Vineet Kacchawaha is a Solutions Architect at AWS with expertise in Machine Learning. He is responsible for helping customers architect scalable, secure, and cost-effective workloads on AWS.
Vineet Kacchawaha is a Solutions Architect at AWS with expertise in Machine Learning. He is responsible for helping customers architect scalable, secure, and cost-effective workloads on AWS.
 Ramesh Thiagarajan is a Senior Solutions Architect based out of San Francisco. He holds a Bachelor of Science in Applied Sciences and a master’s in Cyber Security. He specializes in cloud migration, cloud security, compliance, and risk management. Outside of work, he is a passionate gardener, and has an avid interest in real estate and home improvement projects.
Ramesh Thiagarajan is a Senior Solutions Architect based out of San Francisco. He holds a Bachelor of Science in Applied Sciences and a master’s in Cyber Security. He specializes in cloud migration, cloud security, compliance, and risk management. Outside of work, he is a passionate gardener, and has an avid interest in real estate and home improvement projects.
 Amit Gupta is an AI Services Solutions Architect at AWS. He is passionate about enabling customers with well-architected machine learning solutions at scale.
Amit Gupta is an AI Services Solutions Architect at AWS. He is passionate about enabling customers with well-architected machine learning solutions at scale.
 Tim Murphy is a Senior Solutions Architect for AWS, working with enterprise financial service customers building business cloud centric solutions. He has spent the last decade working with startups, non-profits, commercial enterprise, and government agencies, deploying infrastructure at scale. In his spare time when he isn’t tinkering with technology, you’ll most likely find him in far flung areas of the earth hiking mountains, surfing waves, or biking through a new city.
Tim Murphy is a Senior Solutions Architect for AWS, working with enterprise financial service customers building business cloud centric solutions. He has spent the last decade working with startups, non-profits, commercial enterprise, and government agencies, deploying infrastructure at scale. In his spare time when he isn’t tinkering with technology, you’ll most likely find him in far flung areas of the earth hiking mountains, surfing waves, or biking through a new city.
 Nate Bachmeier is an AWS Senior Solutions Architect that nomadically explores New York, one cloud integration at a time. He specializes in migrating and modernizing applications. Besides this, Nate is a full-time student and has two kids.
Nate Bachmeier is an AWS Senior Solutions Architect that nomadically explores New York, one cloud integration at a time. He specializes in migrating and modernizing applications. Besides this, Nate is a full-time student and has two kids.
 Jessie-Lee Fry is a Snr AIML Specialist with a focus on Computer Vision at AWS. She helps organizations leverage Machine Learning and AI to combat fraud and drive innovation on behalf of their customers. Outside of work, she enjoys spending time with her family, traveling and read all about Responsible AI.
Jessie-Lee Fry is a Snr AIML Specialist with a focus on Computer Vision at AWS. She helps organizations leverage Machine Learning and AI to combat fraud and drive innovation on behalf of their customers. Outside of work, she enjoys spending time with her family, traveling and read all about Responsible AI.
74 Amazon Research Awards recipients announced
The awardees represent 51 universities in 17 countries. Recipients have access to more than 300 Amazon public datasets, and can utilize AWS AI/ML services and tools.Read More
Build a news-based real-time alert system with Twitter, Amazon SageMaker, and Hugging Face
Today, social media is a huge source of news. Users rely on platforms like Facebook and Twitter to consume news. For certain industries such as insurance companies, first respondents, law enforcement, and government agencies, being able to quickly process news about relevant events occurring can help them take action while these events are still unfolding.
It’s not uncommon for organizations trying to extract value from text data to look for a solution that doesn’t involve the training of a complex NLP (natural language processing) model. For those organizations, using a pre-trained NLP model is more practical. Furthermore, if the chosen model doesn’t satisfy their success metrics, organizations want to be able to easily pick another model and reassess.
At present, it’s easier than ever to extract information from text data thanks to the following:
- The rise of state-of-the art, general-purpose NLP architectures such as transformers
- The ability that developers and data scientists have to quickly build, train, and deploy machine learning (ML) models at scale on the cloud with services like Amazon SageMaker
- The availability of thousands of pre-trained NLP models in hundreds of languages and with support for multiple frameworks provided by the community in platforms like Hugging Face Hub
In this post, we show you how to build a real-time alert system that consumes news from Twitter and classifies the tweets using a pre-trained model from the Hugging Face Hub. You can use this solution for zero-shot classification, meaning you can classify tweets at virtually any set of categories, and deploy the model with SageMaker for real-time inference.
Alternatively, if you’re looking for insights into your customer’s conversations and deepen brand awareness by analyzing social media interactions, we encourage you to check out the AI-Driven Social Media Dashboard. The solution uses Amazon Comprehend, a fully managed NLP service that uncovers valuable insights and connections in text without requiring machine learning experience.
Zero-shot learning
The fields of NLP and natural language understanding (NLU) have rapidly evolved to address use cases involving text classification, question answering, summarization, text generation, and more. This evolution has been possible, in part, thanks to the rise of state-of-the art, general-purpose architectures such as transformers, but also the availability of more and better-quality text corpora available for the training of such models.
The transformer architecture is a complex neural network that requires domain expertise and a huge amount of data in order to be trained from scratch. A common practice is to take a pre-trained state-of-the-art transformer like BERT, RoBERTa, T5, GPT-2, or DistilBERT and fine-tune (transfer learning) the model to a specific use case.
Nevertheless, even performing transfer learning on a pre-trained NLP model can often be a challenging task, requiring large amounts of labeled text data and a team of experts to curate the data. This complexity prevents most organizations from using these models effectively, but zero-shot learning helps ML practitioners and organizations overcome this shortcoming.
Zero-shot learning is a specific ML task in which a classifier learns on one set of labels during training, and then during inference is evaluated on a different set of labels that the classifier has never seen before. In NLP, you can use a zero-shot sequence classifier trained on a natural language inference (NLI) task to classify text without any fine-tuning. In this post, we use the popular NLI BART model bart-large-mnli to classify tweets. This is a large pre-trained model (1.6 GB), available on the Hugging Face model hub.
Hugging Face is an AI company that manages an open-source platform (Hugging Face Hub) with thousands of pre-trained NLP models (transformers) in more than 100 different languages and with support for different frameworks such as TensorFlow and PyTorch. The transformers library helps developers and data scientists get started in complex NLP and NLU tasks such as classification, information extraction, question answering, summarization, translation, and text generation.
AWS and Hugging Face have been collaborating to simplify and accelerate the adoption of NLP models. A set of Deep Learning Containers (DLCs) for training and inference in PyTorch or TensorFlow, and Hugging Face estimators and predictors for the SageMaker Python SDK are now available. These capabilities help developers with all levels of expertise get started with NLP easily.
Overview of solution
We provide a working solution that fetches tweets in real time from selected Twitter accounts. For the demonstration of our solution, we use three accounts, Amazon Web Services (@awscloud), AWS Security (@AWSSecurityInfo), and Amazon Science (@AmazonScience), and classify their content into one of the following categories: security, database, compute, storage, and machine learning. If the model returns a category with a confidence score greater than 40%, a notification is sent.
In the following example, the model classified a tweet from Amazon Web Services in the machine learning category, with a confidence score of 97%, generating an alert.
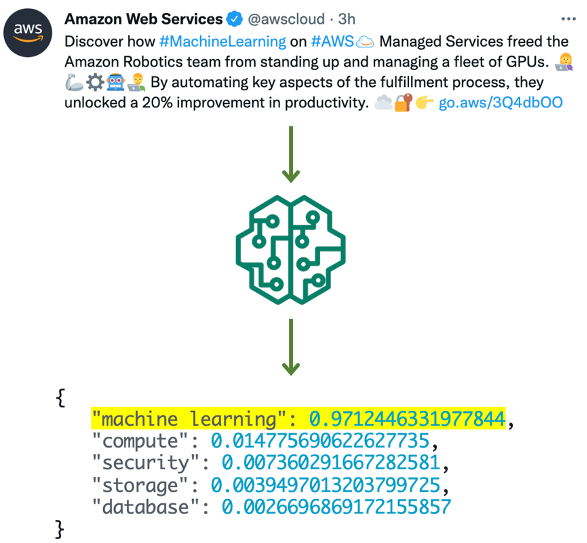
The solution relies on a Hugging Face pre-trained transformer model (from the Hugging Face Hub) to classify tweets based on a set of labels that are provided at inference time—the model doesn’t need to be trained. The following screenshots show more examples and how they were classified.
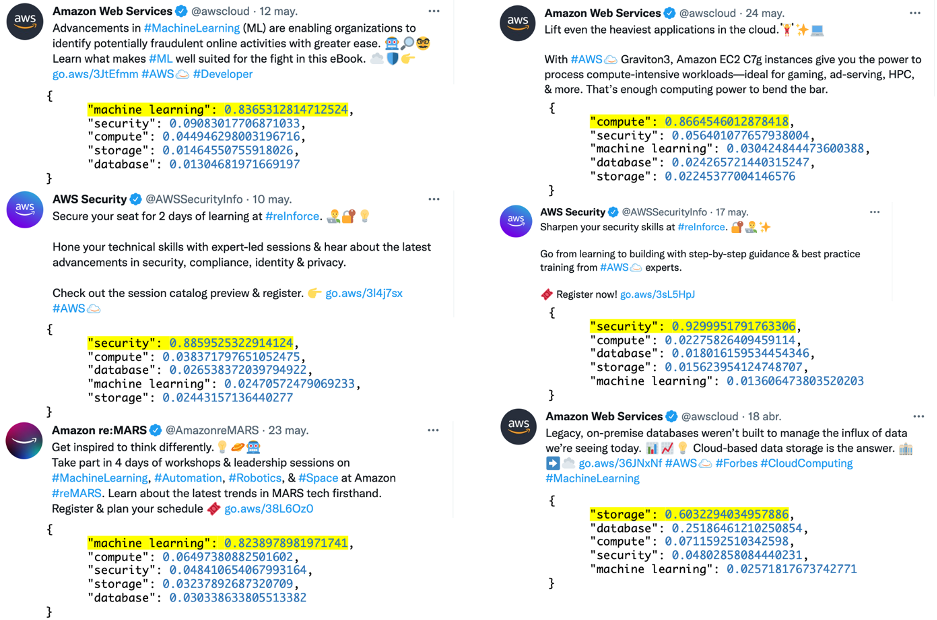
We encourage you to try the solution for yourself. Simply download the source code from the GitHub repository and follow the deployment instructions in the README file.
Solution architecture
The solution keeps an open connection to Twitter’s endpoint and, when a new tweet arrives, sends a message to a queue. A consumer reads messages from the queue, calls the classification endpoint, and, depending on the results, notifies the end user.
The following is the architecture diagram of the solution.
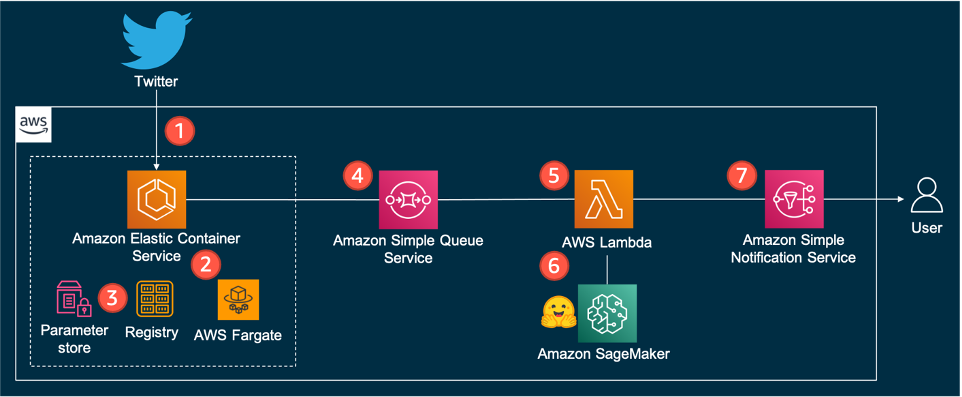
The solution workflow consists of the following components:
- The solution relies on Twitter’s Stream API to get tweets that match the configured rules (tweets from the accounts of interest) in real time. To do so, an application running inside a container keeps an open connection to Twitter’s endpoint. Refer to Twitter API for more details.
- The container runs on Amazon Elastic Container Service (Amazon ECS), a fully managed container orchestration service that makes it easy for you to deploy, manage, and scale containerized applications. A single task runs on a serverless infrastructure managed by AWS Fargate.
- The Twitter Bearer token is securely stored in AWS Systems Manager Parameter Store, a capability of AWS Systems Manager that provides secure, hierarchical storage for configuration data and secrets. The container image is hosted on Amazon Elastic Container Registry (Amazon ECR), a fully managed container registry offering high-performance hosting.
- Whenever a new tweet arrives, the container application puts the tweet into an Amazon Simple Queue Service (Amazon SQS) queue. Amazon SQS is a fully managed message queuing service that enables you to decouple and scale microservices, distributed systems, and serverless applications.
- The logic of the solution resides in an AWS Lambda function. Lambda is a serverless, event-driven compute service. The function consumes new tweets from the queue and classifies them by calling an endpoint.
- The endpoint relies on a Hugging Face model and is hosted on SageMaker. The endpoint runs the inference and outputs the class of the tweet.
- Depending on the classification, the function generates a notification through Amazon Simple Notification Service (Amazon SNS), a fully managed messaging service. You can subscribe to the SNS topic, and multiple destinations can receive that notification (see Amazon SNS event destinations). For instance, you can deliver the notification to inboxes as email messages (see Email notifications).
Deploy Hugging Face models with SageMaker
You can select any of the over 10,000 publicly available models from the Hugging Face Model Hub and deploy them with SageMaker by using Hugging Face Inference DLCs.
When using AWS CloudFormation, you select one of the publicly available Hugging Face Inference Containers and configure the model and the task. This solution uses the facebook/bart-large-mnli model and the zero-shot-classification task, but you can choose any of the models under Zero-Shot Classification on the Hugging Face Model Hub. You configure those by setting the HF_MODEL_ID and HF_TASK environment variables in your CloudFormation template, as in the following code:
Alternatively, if you’re not using AWS CloudFormation, you can achieve the same results with few lines of code. Refer to Deploy models to Amazon SageMaker for more details.
To classify the content, you just call the SageMaker endpoint. The following is a Python code snippet:
Note the False value for the multi_class parameter to indicate that the sum of all the probabilities for each class will add up to 1.
Solution improvements
You can enhance the solution proposed here by storing the tweets and the model results. Amazon Simple Storage Service (Amazon S3), an object storage service, is one option. You can write tweets, results, and other metadata as JSON objects into an S3 bucket. You can then perform ad hoc queries against that content using Amazon Athena, an interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL.
You can use the history not only to extract insights but also to train a custom model. You can use Hugging Face support to train a model with your own data with SageMaker. Learn more on Run training on Amazon SageMaker.
Real-world use cases
Customers are already experimenting with Hugging Face models on SageMaker. Seguros Bolívar, a Colombian financial and insurance company founded in 1939, is an example.
“We developed a threat notification solution for customers and insurance brokers. We use Hugging Face pre-trained NLP models to classify tweets from relevant accounts to generate notifications for our customers in near-real time as a prevention strategy to help mitigate claims. A claim occurs because customers are not aware of the level of risk they are exposed to. The solution allows us to generate awareness in our customers, turning risk into something measurable in concrete situations.”
– Julian Rico, Chief of Research and Knowledge at Seguros Bolívar.
Seguros Bolívar worked with AWS to re-architecture their solution; it now relies on SageMaker and resembles the one described in this post.
Conclusion
Zero-shot classification is ideal when you have little data to train a custom text classifier or when you can’t afford to train a custom NLP model. For specialized use cases, when text is based on specific words or terms, it’s better to go with a supervised classification model based on a custom training set.
In this post, we showed you how to build a news classifier using a Hugging Face zero-shot model on AWS. We used Twitter as our news source, but you can choose a news source that is more suitable to your specific needs. Furthermore, you can easily change the model, just specify your chosen model in the CloudFormation template.
For the source code, refer to the GitHub repository It includes the full setup instructions. You can clone, change, deploy, and run it yourself. You can also use it as a starting point and customize the categories and the alert logic or build another solution for a similar use case.
Please give it a try, and let us know what you think. As always, we’re looking forward to your feedback. You can send it to your usual AWS Support contacts, or in the AWS Forum for SageMaker.
About the authors
 David Laredo is a Prototyping Architect at AWS Envision Engineering in LATAM, where he has helped develop multiple machine learning prototypes. Previously he has worked as a Machine Learning Engineer and has been doing machine learning for over 5 years. His areas of interest are NLP, time series, and end-to-end ML.
David Laredo is a Prototyping Architect at AWS Envision Engineering in LATAM, where he has helped develop multiple machine learning prototypes. Previously he has worked as a Machine Learning Engineer and has been doing machine learning for over 5 years. His areas of interest are NLP, time series, and end-to-end ML.
 Rafael Werneck is a Senior Prototyping Architect at AWS Envision Engineering, based in Brazil. Previously, he worked as a Software Development Engineer on Amazon.com.br and Amazon RDS Performance Insights.
Rafael Werneck is a Senior Prototyping Architect at AWS Envision Engineering, based in Brazil. Previously, he worked as a Software Development Engineer on Amazon.com.br and Amazon RDS Performance Insights.
 Vikram Elango is an AI/ML Specialist Solutions Architect at Amazon Web Services, based in Virginia, USA. Vikram helps financial and insurance industry customers with design and thought leadership to build and deploy machine learning applications at scale. He is currently focused on natural language processing, responsible AI, inference optimization, and scaling ML across the enterprise. In his spare time, he enjoys traveling, hiking, cooking, and camping with his family.
Vikram Elango is an AI/ML Specialist Solutions Architect at Amazon Web Services, based in Virginia, USA. Vikram helps financial and insurance industry customers with design and thought leadership to build and deploy machine learning applications at scale. He is currently focused on natural language processing, responsible AI, inference optimization, and scaling ML across the enterprise. In his spare time, he enjoys traveling, hiking, cooking, and camping with his family.
Filtering out “forbidden” documents during information retrieval
New method optimizes the twin demands of retrieving relevant content and filtering out bad content.Read More
Amazon scientists Mike Hicks and René Vidal honored
Hicks wins 2022 ACM SIGPLAN Distinguished Service Award for career contributions; Vidal wins IEEE Signal Processing Magazine Best Paper Award.Read More
Achieve enterprise-grade monitoring for your Amazon SageMaker models using Fiddler
This is a guest blog post by Danny Brock, Rajeev Govindan and Krishnaram Kenthapadi at Fiddler AI.
Your Amazon SageMaker models are live. They’re handling millions of inferences each day and driving better business outcomes for your company. They’re performing exactly as well as the day they were launched.
Er, wait. Are they? Maybe. Maybe not.
Without enterprise-class model monitoring, your models may be decaying in silence. Your machine learning (ML) teams may never know that these models have actually morphed from miracles of revenue generation to liabilities making incorrect decisions that cost your company time and money.
Don’t fret. The solution is closer than you think.
Fiddler, an enterprise-class Model Performance Management solution available on the AWS Marketplace, offers model monitoring and explainable AI to help ML teams inspect and address a comprehensive range of model issues. Through model monitoring, model explainability, analytics, and bias detection, Fiddler provides your company with an easy-to-use single pane of glass to ensure your models are behaving as they should. And if they’re not, Fiddler also provides features that allow you to inspect your models to find the underlying root causes of performance decay.
This post shows how your MLOps team can improve data scientist productivity and reduce time to detect issues for your models deployed in SageMaker by integrating with the Fiddler Model Performance Management Platform in a few simple steps.
Solution overview
The following reference architecture highlights the primary points of integration. Fiddler exists as a “sidecar” to your existing SageMaker ML workflow.
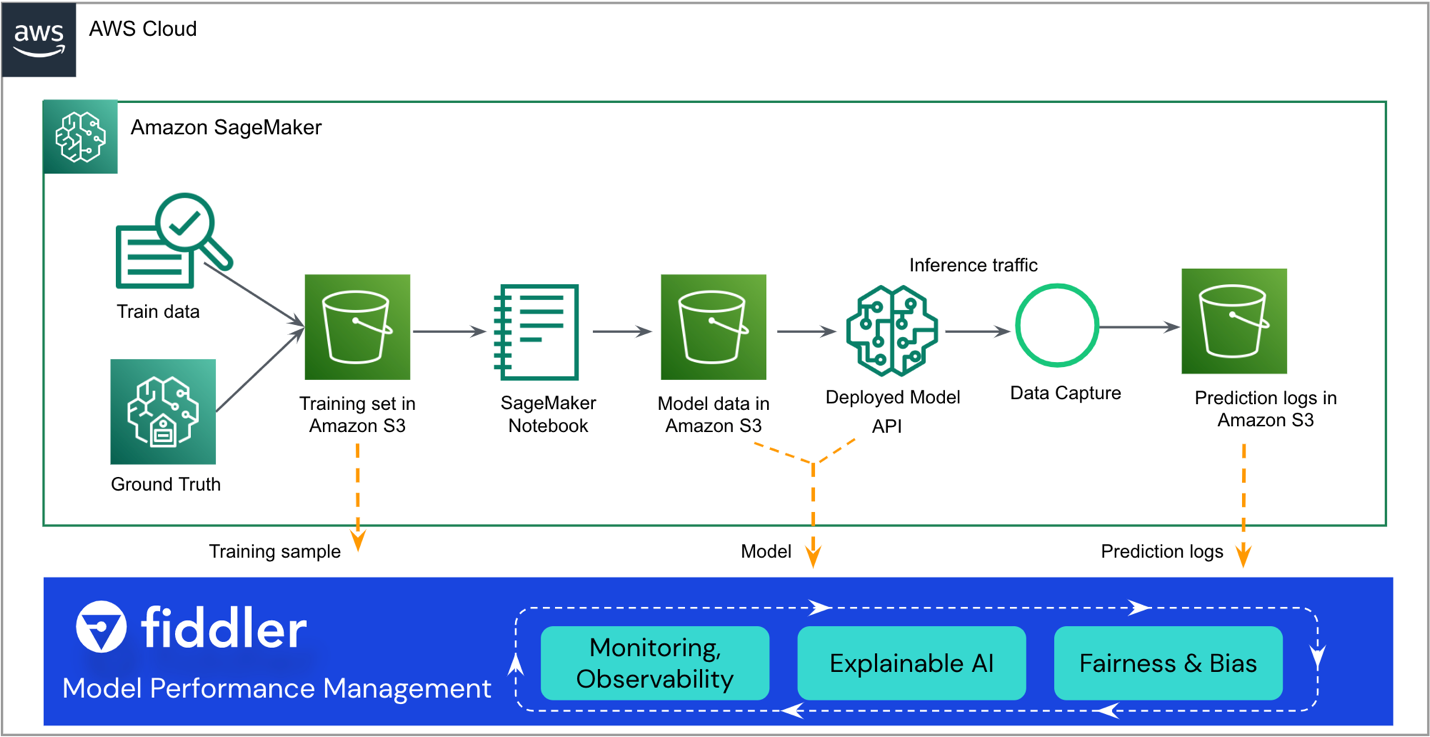
The remainder of this post walks you through the steps to integrate your SageMaker model with Fiddler’s Model Performance Management Platform:
- Ensure your model has data capture enabled.
- Create a Fiddler trial environment.
- Register information about your model in your Fiddler environment.
- Create an AWS Lambda function to publish SageMaker inferences to Fiddler.
- Explore Fiddler’s monitoring capabilities in your Fiddler trial environment.
Prerequisites
This post assumes that you have set up SageMaker and deployed a model endpoint. To learn how to configure SageMaker for model serving, refer to Deploy Models for Inference. Some examples are also available on the GitHub repo.
Ensure your model has data capture enabled
On the SageMaker console, navigate to your model’s serving endpoint and ensure you have enabled data capture into an Amazon Simple Storage Service (Amazon S3) bucket. This stores the inferences (requests and responses) your model makes each day as JSON lines files (.jsonl) in Amazon S3.

Create a Fiddler trial environment
From the fiddler.ai website, you can request a free trial. After filling out a quick form, Fiddler will contact you to understand the specifics of your model performance management needs and will have a trial environment ready for you in a few hours. You can expect a dedicated environment like https://yourcompany.try.fiddler.ai.

Register information about your model in your Fiddler environment
Before you can begin publishing events from your SageMaker hosted model into Fiddler, you need to create a project within your Fiddler trial environment and provide Fiddler details about your model through a step called model registration. If you want to use a preconfigured notebook from within Amazon SageMaker Studio rather than copy and paste the following code snippets, you can reference the Fiddler quickstart notebook on GitHub. Studio provides a single web-based visual interface where you can perform all ML development steps.
First, you must install the Fiddler Python client in your SageMaker notebook and instantiate the Fiddler client. You can get the AUTH_TOKEN from the Settings page in your Fiddler trial environment.
Next, create a project within your Fiddler trial environment:
Now upload your training dataset. The notebook also provides a sample dataset to run Fiddler’s explainability algorithms and as a baseline for monitoring metrics. The dataset is also used to generate the schema for this model in Fiddler.
Lastly, before you can start publishing inferences to Fiddler for monitoring, root cause analysis, and explanations, you need to register your model. Let’s first create a model_info object that contains the metadata about your model:
Then you can register the model using your new model_info object:
Great! Now you can publish some events to Fiddler in order to observe the model’s performance.
Create a Lambda function to publish SageMaker inferences to Fiddler
With the simple-to-deploy serverless architecture of Lambda, you can quickly build the mechanism required to move your inferences from the S3 bucket you set up earlier into your newly provisioned Fiddler trial environment. This Lambda function is responsible for opening any new JSONL event log files in your model’s S3 bucket, parsing and formatting the JSONL content into a dataframe, and then publishing that dataframe of events to your Fiddler trial environment. The following screenshot shows the code details of our function.
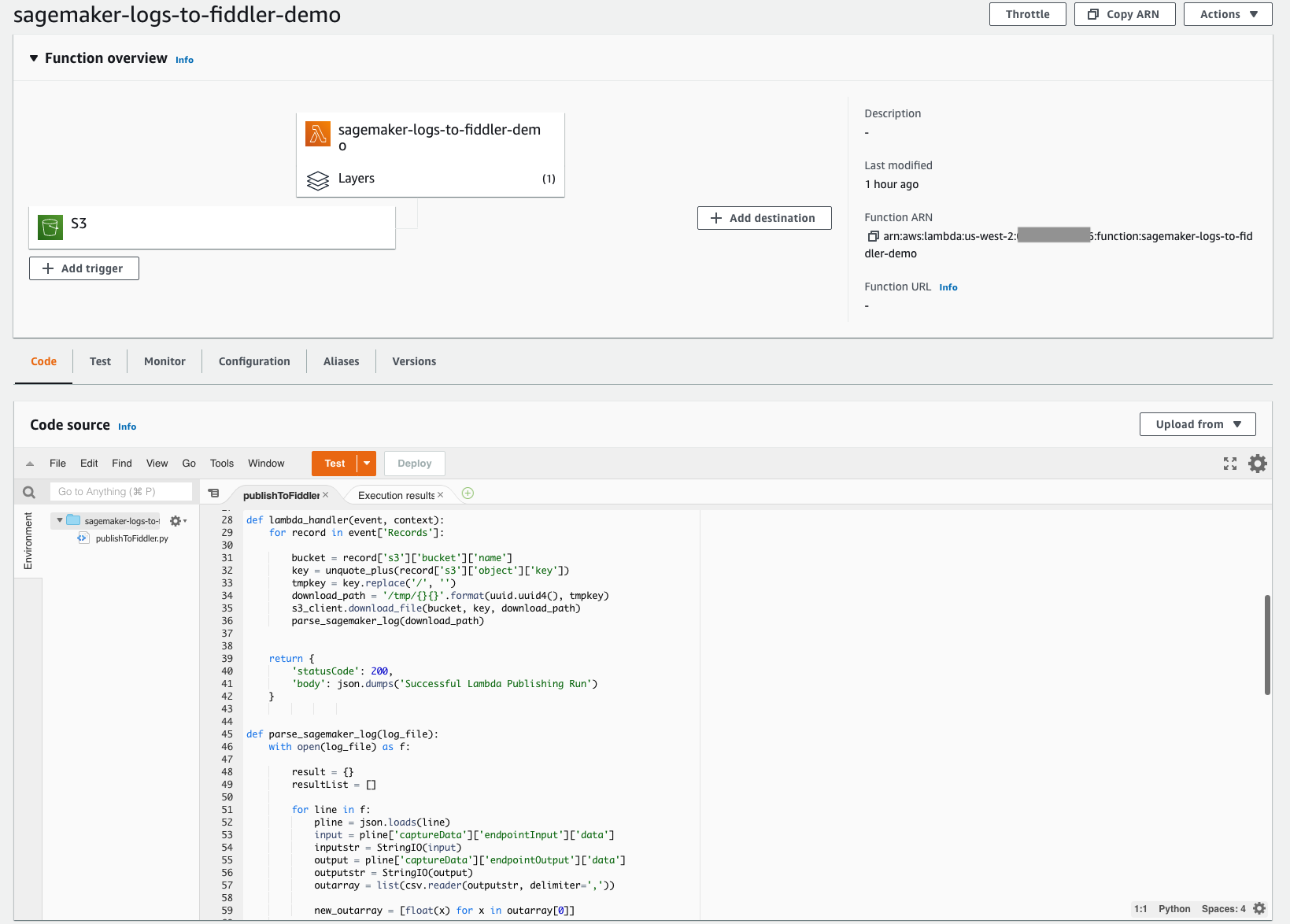
The Lambda function needs to be configured to trigger off of newly created files in your S3 bucket. The following tutorial guides you through creating an Amazon EventBridge trigger that invokes the Lambda function whenever a file is uploaded to Amazon S3. The following screenshot shows our function’s trigger configuration. This makes it simple to ensure that any time your model makes new inferences, those events stored in Amazon S3 are loaded into Fiddler to drive the model observability your company needs.
To simplify this further, the code for this Lambda function is publicly available from Fiddler’s documentation site. This code example currently works for binary classification models with structured inputs. If you have model types with different features or tasks, please contact Fiddler for assistance with minor changes to the code.
The Lambda function needs to make reference to the Fiddler Python client. Fiddler has created a publicly available Lambda layer that you can reference to ensure that the import fiddler as fdl step works seamlessly. You can reference this layer via an ARN in the us-west-2 Region: arn:aws:lambda:us-west-2:079310353266:layer:fiddler-client-0814:1, as shown in the following screenshot.

You also need to specify Lambda environment variables so the Lambda function knows how to connect to your Fiddler trial environment, and what the inputs and outputs are within the .jsonl files being captured by your model. The following screenshot shows a list of the required environment variables, which are also on Fiddler’s documentation site. Update the values for the environment variables to match your model and dataset.

Explore Fiddler’s monitoring capabilities in your Fiddler trial environment
You’ve done it! With your baseline data, model, and traffic connected, you can now explain data drift, outliers, model bias, data issues, and performance blips, and share dashboards with others. Complete your journey by watching a demo about the model performance management capabilities you have introduced to your company.
The example screenshots below provide a glimpse of model insights like drift, outlier detection, local point explanations, and model analytics that will be found in your Fiddler trial environment.

Conclusion
This post highlighted the need for enterprise-class model monitoring and showed how you can integrate your models deployed in SageMaker with the Fiddler Model Performance Management Platform in just a few steps. Fiddler offers functionality for model monitoring, explainable AI, bias detection, and root cause analysis, and is available on the AWS Marketplace. By providing your MLOps team with an easy-to-use single pane of glass to ensure your models are behaving as expected and to identify the underlying root causes of performance degradation, Fiddler can help improve data scientist productivity and reduce time to detect and resolve issues.
If you would like to learn more about Fiddler please visit fiddler.ai or if you would prefer to set up a personalized demo and technical discussion email sales@fiddler.ai.
About the Authors
 Danny Brock is a Sr Solutions Engineer at Fiddler AI. Danny is long tenured in the analytics and ML space, running presales and post-sales teams for startups like Endeca and Incorta. He founded his own big data analytics consulting company, Branchbird, in 2012.
Danny Brock is a Sr Solutions Engineer at Fiddler AI. Danny is long tenured in the analytics and ML space, running presales and post-sales teams for startups like Endeca and Incorta. He founded his own big data analytics consulting company, Branchbird, in 2012.
 Rajeev Govindan is a Sr Solutions Engineer at Fiddler AI. Rajeev has extensive experience in sales engineering and software development at several enterprise companies, including AppDynamics.
Rajeev Govindan is a Sr Solutions Engineer at Fiddler AI. Rajeev has extensive experience in sales engineering and software development at several enterprise companies, including AppDynamics.
 Krishnaram Kenthapadi is the Chief Scientist of Fiddler AI. Previously, he was a Principal Scientist at Amazon AWS AI, where he led the fairness, explainability, privacy, and model understanding initiatives in the Amazon AI platform, and prior to that, he held roles at LinkedIn AI and Microsoft Research. Krishnaram received his PhD in Computer Science from Stanford University in 2006.
Krishnaram Kenthapadi is the Chief Scientist of Fiddler AI. Previously, he was a Principal Scientist at Amazon AWS AI, where he led the fairness, explainability, privacy, and model understanding initiatives in the Amazon AI platform, and prior to that, he held roles at LinkedIn AI and Microsoft Research. Krishnaram received his PhD in Computer Science from Stanford University in 2006.
Why ambient computing needs self-learning
To become the interface for the Internet of things, conversational agents will need to learn on their own. Alexa has already started down that path.Read More
Track your ML experiments end to end with Data Version Control and Amazon SageMaker Experiments
Data scientists often work towards understanding the effects of various data preprocessing and feature engineering strategies in combination with different model architectures and hyperparameters. Doing so requires you to cover large parameter spaces iteratively, and it can be overwhelming to keep track of previously run configurations and results while keeping experiments reproducible.
This post walks you through an example of how to track your experiments across code, data, artifacts, and metrics by using Amazon SageMaker Experiments in conjunction with Data Version Control (DVC). We show how you can use DVC side by side with Amazon SageMaker processing and training jobs. We train different CatBoost models on the California housing dataset from the StatLib repository, and change holdout strategies while keeping track of the data version with DVC. In each individual experiment, we track input and output artifacts, code, and metrics using SageMaker Experiments.
SageMaker Experiments
SageMaker Experiments is an AWS service for tracking machine learning (ML) experiments. The SageMaker Experiments Python SDK is a high-level interface to this service that helps you track experiment information using Python.
The goal of SageMaker Experiments is to make it as simple as possible to create experiments, populate them with trials, add tracking and lineage information, and run analytics across trials and experiments.
When discussing SageMaker Experiments, we refer to the following concepts:
- Experiment – A collection of related trials. You add trials to an experiment that you want to compare together.
- Trial – A description of a multi-step ML workflow. Each step in the workflow is described by a trial component.
- Trial component – A description of a single step in an ML workflow, such as data cleaning, feature extraction, model training, or model evaluation.
- Tracker – A Python context manager for logging information about a single trial component (for example, parameters, metrics, or artifacts).
Data Version Control
Data Version Control (DVC) is a new type of data versioning, workflow, and experiment management software that builds upon Git (although it can work standalone). DVC reduces the gap between established engineering toolsets and data science needs, allowing you to take advantage of new features while reusing existing skills and intuition.
Data science experiment sharing and collaboration can be done through a regular Git flow (commits, branching, tagging, pull requests) the same way it works for software engineers. With Git and DVC, data science and ML teams can version experiments, manage large datasets, and make projects reproducible.
DVC has the following features:
- DVC is a free, open-source command line tool.
- DVC works on top of Git repositories and has a similar command line interface and flow as Git. DVC can also work standalone, but without versioning capabilities.
- Data versioning is enabled by replacing large files, dataset directories, ML models, and so on with small metafiles (easy to handle with Git). These placeholders point to the original data, which is decoupled from source code management.
- You can use on-premises or cloud storage to store the project’s data separate from its code base. This is how data scientists can transfer large datasets or share a GPU-trained model with others.
- DVC makes data science projects reproducible by creating lightweight pipelines using implicit dependency graphs, and by codifying the data and artifacts involved.
- DVC is platform agnostic. It runs on all major operating systems (Linux, macOS, and Windows), and works independently of the programming languages (Python, R, Julia, shell scripts, and so on) or ML libraries (Keras, TensorFlow, PyTorch, Scipy, and more) used in the project.
- DVC is quick to install and doesn’t require special infrastructure, nor does it depend on APIs or external services. It’s a standalone CLI tool.
SageMaker Experiments and DVC sample
The following GitHub sample shows how to use DVC within the SageMaker environment. In particular, we look at how to build a custom image with DVC libraries installed by default to provide a consistent development environment to your data scientists in Amazon SageMaker Studio, and how to run DVC alongside SageMaker managed infrastructure for processing and training. Furthermore, we show how to enrich SageMaker tracking information with data versioning information from DVC, and visualize them within the Studio console.
The following diagram illustrates the solution architecture and workflow.
Build a custom Studio image with DVC already installed
In this GitHub repository, we explain how to create a custom image for Studio that has DVC already installed. The advantage of creating an image and making it available to all Studio users is that it creates a consistent environment for the Studio users, which they could also run locally. Although the sample is based on AWS Cloud9, you can also build the container on your local machine as long as you have Docker installed and running. This sample is based on the following Dockerfile and environment.yml. The resulting Docker image is stored in Amazon Elastic Container Registry (Amazon EMR) in your AWS account. See the following code:
You can now create a new Studio domain or update an existing Studio domain that has access to the newly created Docker image.
We use AWS Cloud Development Kit (AWS CDK) to create the following resources via AWS CloudFormation:
- A SageMaker execution role with the right permissions to your new or existing Studio domain
- A SageMaker image and SageMaker image version from the Docker image
conda-env-dvc-kernelthat we created earlier - An
AppImageConfigthat specifies how the kernel gateway should be configured - A Studio user (
data-scientist-dvc) with the correct SageMaker execution role and the custom Studio image available to it
For detailed instructions, refer to Associate a custom image to SageMaker Studio.
Run the lab
To run the lab, complete the following steps:
- In the Studio domain, launch Studio for the
data-scientist-dvcuser. - Choose the Git icon, then choose Clone a Repository.

- Enter the URL of the repository (
https://github.com/aws-samples/amazon-sagemaker-experiments-dvc-demo) and choose Clone.
- In the file browser, choose the
amazon-sagemaker-experiments-dvc-demorepository. - Open the
dvc_sagemaker_script_mode.ipynbnotebook. - For Custom Image, choose the image conda-env-dvc-kernel.
- Choose Select.

Configure DVC for data versioning
We create a subdirectory where we prepare the data: sagemaker-dvc-sample. Within this subdirectory, we initialize a new Git repository and set the remote to a repository we create in AWS CodeCommit. The goal is to have DVC configurations and files for data tracking versioned in this repository. However, Git offers native capabilities to manage subprojects via, for example, git submodules and git subtrees, and you can extend this sample to use any of the aforementioned tools that best fit your workflow.
The main advantage of using CodeCommit with SageMaker in our case is its integration with AWS Identity and Access Management (IAM) for authentication and authorization, meaning we can use IAM roles to push and pull data without the need to fetch credentials (or SSH keys). Setting the appropriate permissions on the SageMaker execution role also allows the Studio notebook and the SageMaker training and processing job to interact securely with CodeCommit.
Although you can replace CodeCommit with any other source control service, such as GitHub, Gitlab, or Bitbucket, you need consider how to handle the credentials for your system. One possibility is to store these credentials on AWS Secrets Manager and fetch them at run time from the Studio notebook as well as from the SageMaker processing and training jobs.

Process and train with DVC and SageMaker
In this section, we explore two different approaches to tackle our problem and how we can keep track of the two tests using SageMaker Experiments according to the high-level conceptual architecture we showed you earlier.
Set up a SageMaker experiment
To track this test in SageMaker, we need to create an experiment. We need to also define the trial within the experiment. For the sake of simplicity, we just consider one trial for the experiment, but you can have any number of trials within an experiment, for example, if you want to test different algorithms.
We create an experiment named DEMO-sagemaker-experiments-dvc with two trials, dvc-trial-single-file and dvc-trial-multi-files, each representing a different version of the dataset.
Let’s create the DEMO-sagemaker-experiments-dvc experiment:
Test 1: Generate single files for training and validation
In this section, we create a processing script that fetches the raw data directly from Amazon Simple Storage Service (Amazon S3) as input; processes it to create the train, validation, and test datasets; and stores the results back to Amazon S3 using DVC. Furthermore, we show how you can track output artifacts generated by DVC with SageMaker when running processing and training jobs and via SageMaker Experiments.
First, we create the dvc-trial-single-file trial and add it to the DEMO-sagemaker-experiments-dvc experiment. By doing so, we keep all trial components related to this test organized in a meaningful way.
Use DVC in a SageMaker processing job to create the single file version
In this section, we create a processing script that gets the raw data directly from Amazon S3 as input using the managed data loading capability of SageMaker; processes it to create the train, validation, and test datasets; and stores the results back to Amazon S3 using DVC. It’s very important to understand that when using DVC to store data to Amazon S3 (or pull data from Amazon S3), we’re losing SageMaker managed data loading capabilities, which can potentially have an impact on performance and costs of our processing and training jobs, especially when working with very large datasets. For more information on the different SageMaker native input mode capabilities, refer to Access Training Data.
Finally, we unify DVC tracking capabilities with SageMaker tracking capabilities when running processing jobs via SageMaker Experiments.
The processing script expects the address of the Git repository and the branch we want to create to store the DVC metadata passed via environmental variables. The datasets themselves are stored in Amazon S3 by DVC. Although environmental variables are automatically tracked in SageMaker Experiments and visible in the trial component parameters, we might want to enrich the trial components with further information, which then become available for visualization in the Studio UI using a tracker object. In our case, the trial components parameters include the following:
DVC_REPO_URLDVC_BRANCHUSERdata_commit_hashtrain_test_split_ratio
The preprocessing script clones the Git repository; generates the train, validation, and test datasets; and syncs it using DVC. As mentioned earlier, when using DVC, we can’t take advantage of native SageMaker data loading capabilities. Aside from the performance penalties we might suffer on large datasets, we also lose the automatic tracking capabilities for the output artifacts. However, thanks to the tracker and the DVC Python API, we can compensate for these shortcomings, retrieve such information at run time, and store it in the trial component with little effort. The added value by doing so is to have in single view of the input and output artifacts that belong to this specific processing job.
The full preprocessing Python script is available in the GitHub repo.
SageMaker gives us the possibility to run our processing script on container images managed by AWS that are optimized to run on the AWS infrastructure. If our script requires additional dependencies, we can supply a requirements.txt file. When we start the processing job, SageMaker uses pip-install to install all the libraries we need (for example, DVC-related libraries). If you need to have a tighter control of all libraries installed on the containers, you can bring your own container in SageMaker, for example for processing and training.
We have now all the ingredients to run our SageMaker processing job:
- A processing script that can process several arguments (
--train-test-split-ratio) and two environmental variables (DVC_REPO_URLandDVC_BRANCH) - A
requiremets.txtfile - A Git repository (in CodeCommit)
- A SageMaker experiment and trial
We then run the processing job with the preprocessing-experiment.py script, experiment_config, dvc_repo_url, and dvc_branch we defined earlier.
The processing job takes approximately 5 minutes to complete. Now you can view the trial details for the single file dataset.
The following screenshot shows where you can find the stored information within Studio. Note the values for dvc-trial-single-file in DVC_BRANCH, DVC_REPO_URL, and data_commit_hash on the Parameters tab.

Also note the input and output details on the Artifacts tab.

Create an estimator and fit the model with single file data version
To use DVC integration inside a SageMaker training job, we pass a dvc_repo_url and dvc_branch as environmental variables when you create the Estimator object.
We train on the dvc-trial-single-file branch first.
When pulling data with DVC, we use the following dataset structure:
Now we create a Scikit-learn Estimator using the SageMaker Python SDK. This allows us to specify the following:
- The path to the Python source file, which should be run as the entry point to training.
- The IAM role that controls permissions for accessing Amazon S3 and CodeCommit data and running SageMaker functions.
- A list of dictionaries that define the metrics used to evaluate the training jobs.
- The number and type of training instances. We use one ml.m5.large instance.
- Hyperparameters that are used for training.
- Environment variables to use during the training job. We use
DVC_REPO_URL,DVC_BRANCH, andUSER.
We call the fit method of the Estimator with the experiment_config we defined earlier to start the training.
The training job takes approximately 5 minutes to complete. The logs show those lines, indicating the files pulled by DVC:
Test 2: Generate multiple files for training and validation
We create a new dvc-trial-multi-files trial and add it to the current DEMO-sagemaker-experiments-dvc experiment.
Differently from the first processing script, we now create out of the original dataset multiple files for training and validation and store the DVC metadata in a different branch.
You can explore the second preprocessing Python script on GitHub.
The processing job takes approximately 5 minutes to complete. Now you can view the trial details for the multi-file dataset.
The following screenshots show where you can find the stored information within SageMaker Experiments in the Trial components section within the Studio UI. Note the values for dvc-trial-multi-files in DVC_BRANCH, DVC_REPO_URL, and data_commit_hash on the Parameters tab.

You can also review the input and output details on the Artifacts tab.

We now train on the dvc-trial-multi-files branch. When pulling data with DVC, we use the following dataset structure:
Similar as we did before, we create a new Scikit-learn Estimator with the trial name dvc-trial-multi-files and start the training job.
The training job takes approximately 5 minutes to complete. On the training job logs output to the notebook, you can see those lines, indicating the files pulled by DVC:
Host your model in SageMaker
After you train your ML model, you can deploy it using SageMaker. To deploy a persistent, real-time endpoint that makes one prediction at a time, we use SageMaker real-time hosting services.
First, we get the latest test dataset locally on the development notebook in Studio. For this purpose, we can use dvc.api.read() to load the raw data that was stored in Amazon S3 by the SageMaker processing job.
Then we prepare the data using Pandas, load a test CSV file, and call predictor.predict to invoke the SageMaker endpoint created earlier, with data, and get predictions.
Delete the endpoint
You should delete endpoints when they’re no longer in use, because they’re billed by the time deployed (for more information, see Amazon SageMaker Pricing). Make sure to delete the endpoint to avoid unexpected costs.
Clean up
Before you remove all the resources you created, make sure that all apps are deleted from the data-scientist-dvc user, including all KernelGateway apps, as well as the default JupiterServer app.
Then you can destroy the AWS CDK stack by running the following command:
If you used an existing domain, also run the following commands:
Conclusion
In this post, you walked through an example of how to track your experiments across code, data, artifacts, and metrics by using SageMaker Experiments and SageMaker processing and training jobs in conjunction with DVC. We created a Docker image containing DVC, which was required for Studio as the development notebook, and showed how you can use processing and training jobs with DVC. We prepared two versions of the data and used DVC to manage it with Git. Then you used SageMaker Experiments to track the processing and training with the two versions of the data in order to have a unified view of parameters, artifacts, and metrics in a single pane of glass. Finally, you deployed the model to a SageMaker endpoint and used a testing dataset from the second dataset version to invoke the SageMaker endpoint and get predictions.
As next step, you can extend the existing notebook and introduce your own feature engineering strategy and use DVC and SageMaker to run your experiments. Let’s go build!
For further reading, refer to the following resources:
- Amazon SageMaker Experiments – Organize, Track And Compare Your Machine Learning Training
- Manage Machine Learning with Amazon SageMaker Experiments
- SageMaker Experiments Python SDK
- DVC – Get Started
- DVC – Get Started: Data and Model Access
About the Authors
 Paolo Di Francesco is a solutions architect at AWS. He has experience in the telecommunications and software engineering. He is passionate about machine learning and is currently focusing on using his experience to help customers reach their goals on AWS, in particular in discussions around MLOps. Outside of work, he enjoys playing football and reading.
Paolo Di Francesco is a solutions architect at AWS. He has experience in the telecommunications and software engineering. He is passionate about machine learning and is currently focusing on using his experience to help customers reach their goals on AWS, in particular in discussions around MLOps. Outside of work, he enjoys playing football and reading.
 Eitan Sela is a Machine Learning Specialist Solutions Architect with Amazon Web Services. He works with AWS customers to provide guidance and technical assistance, helping them build and operate machine learning solutions on AWS. In his spare time, Eitan enjoys jogging and reading the latest machine learning articles.
Eitan Sela is a Machine Learning Specialist Solutions Architect with Amazon Web Services. He works with AWS customers to provide guidance and technical assistance, helping them build and operate machine learning solutions on AWS. In his spare time, Eitan enjoys jogging and reading the latest machine learning articles.