This is a guest post by Jihye Park, a Data Scientist at MUSINSA.
MUSINSA is one of the largest online fashion platforms in South Korea, serving 8.4M customers and selling 6,000 fashion brands. Our monthly user traffic reaches 4M, and over 90% of our demographics consist of teens and young adults who are sensitive to fashion trends. MUSINSA is a trend-setting platform leader in the country, leading with massive amounts of data.
The MUSINSA Data Solution Team engages in everything related to data collected from the MUSINSA Store. We do full stack development from log collection to data modeling and model serving. We develop various data-based products, including the Live Product Recommendation Service on our app’s main page and the Keyword Highlighting Service that detects and highlights words such as ‘size’ or ‘satisfaction level’ from text reviews.
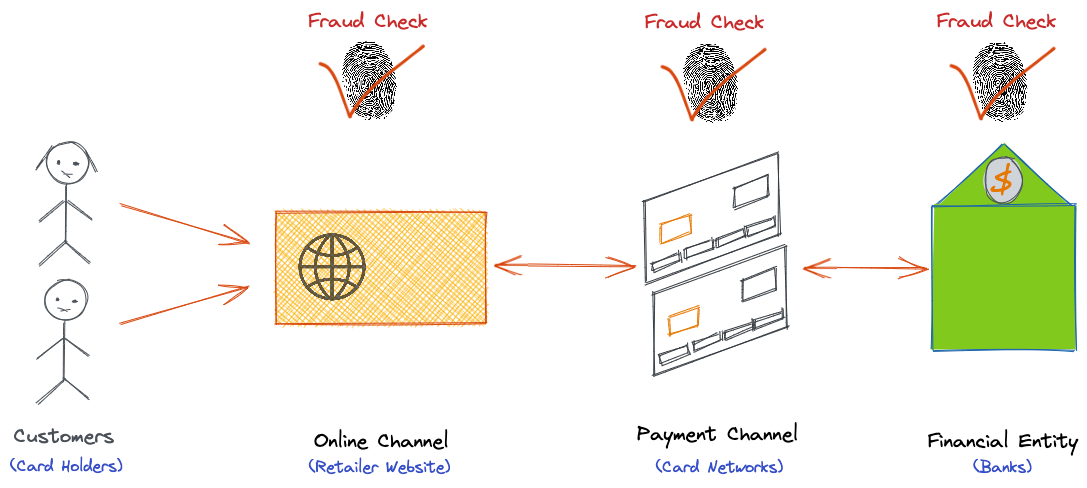
Challenges in the Automate Review Image Inspection Process
The quality and quantity of customer reviews are critical for ecommerce businesses, as customers make purchase decisions without seeing the products in person. We give credits to those who write image reviews on the products they purchased (that is, reviews with photos of the products or photos of them wearing/using the products) to enhance customer experience and increase the purchase conversion rate. To determine if the submitted photos met our criteria for credits, all of the photos are inspected individually by humans. For example, our criteria states that a “Style Review” should contain photos featuring the whole body of a person wearing/using the product while a “Product Review” should provide a full shot of the product. The following images show examples of a Product Review and a Style Review. Uploaders’ consent has been granted for use of the photos.

Examples of Product Review. |

Examples of Style Review. |
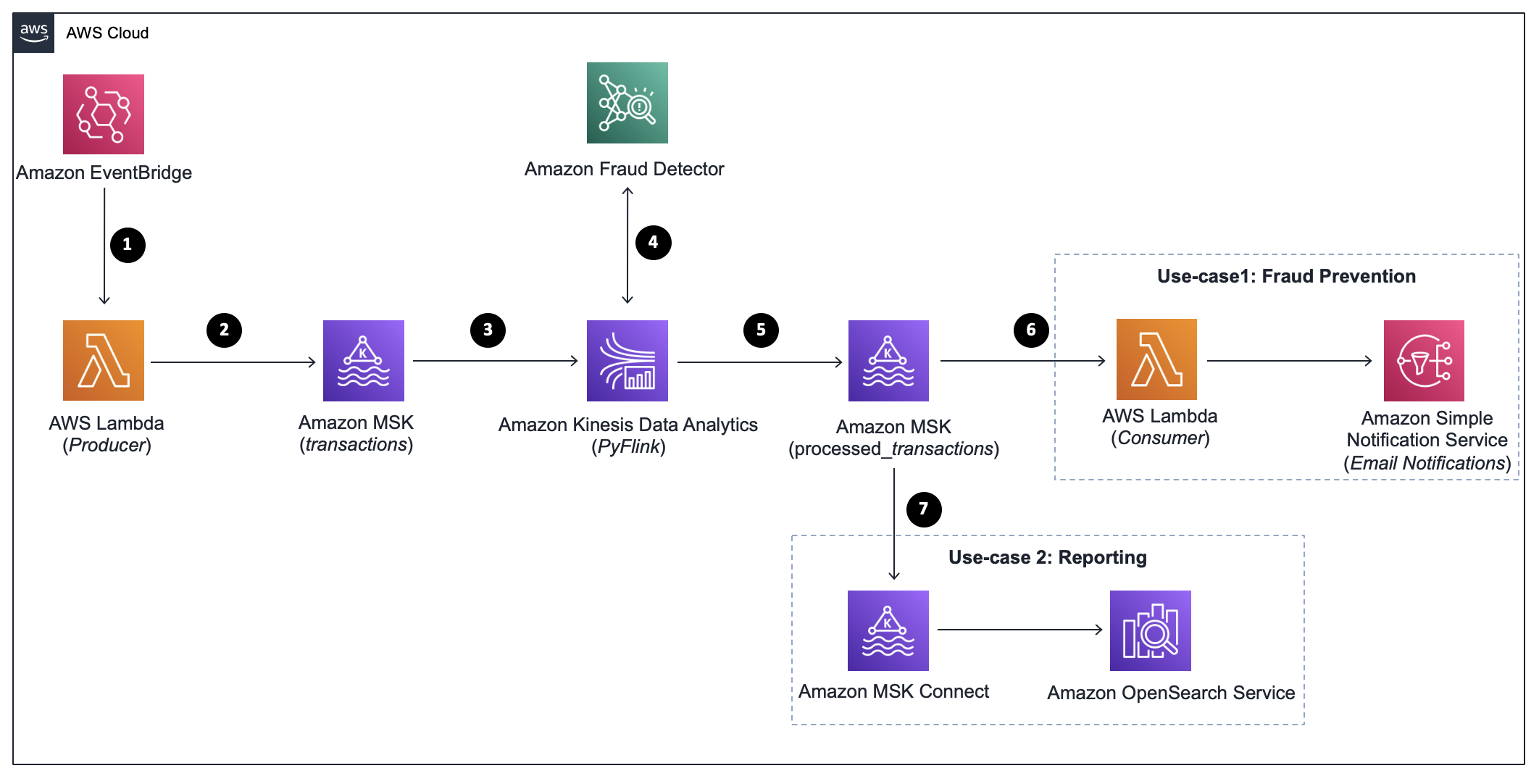
Over 20,000 photos are uploaded daily to the MUSINSA Store platform that require inspection. The inspection process classifies images as ‘package’, ‘product’, ‘full-length’, or ‘half-length’. The image inspection process is completely manual, so it was extremely time consuming and classifications are often done differently by different individuals, even with the guidelines. Faced with this challenge, we used Amazon SageMaker to automate this task.
Amazon SageMaker is a fully managed service for building, training, and deploying machine learning (ML) models for any use case with fully managed infrastructure, tools, and workflows. It let us quickly implement the automated image inspection service with good results.
We will go into detail about how we addressed our problems using ML models and used Amazon SageMaker along the way.
Automation of the Review Image Inspection Process
The first step toward automating the Image Review Inspection process was to manually label images, thereby matching them to the appropriate categories and inspection criteria. For example, we classified images as a “full body shot,” “upper body shot,” “packaging shot,” “product shot,” etc. In the case of a Product Review, credits were given only for a product shot image. Likewise, in the case of a Style Review, credits were given for a full body shot.
As for image classification, we largely depended on a pre-trained convolutional neural network (CNN) model due to the sheer volume of input images required to train our model. While defining and categorizing meaningful features from images are both critical to training a model, an image can have a limitless number of features. Therefore, using the CNN model made the most sense, and we pre-trained our model with 10,000+ ImageNet datasets, then we used transfer learning. This meant that our model could be trained more effectively with our image labels later.
Image Collection with Amazon SageMaker Ground Truth
However, transfer learning had its own limitations, because a model must be newly trained on higher layers. This means that it constantly required input images. On the other hand, this method performed well and required fewer input images when trained on entire layers. It easily identified features from images from these layers because it had already been trained with a massive amount of data. At MUSINSA, our entire infrastructure runs on AWS, and we are storing customer-uploaded photos in Amazon Simple Storage Service (S3). We categorized these images into different folders based on the labels we defined, and we used Amazon SageMaker Ground Truth for the following reasons:
- More consistent results – In manual processes, a single inspector’s mistake could be fed into model training without any intervention. With SageMaker Ground Truth, we could have several inspectors review the same image and make sure that the inputs from the most trustworthy inspector were rated higher for image labeling, thus leading to more reliable results.
-
Less manual work – SageMaker Ground Truth automated data labeling can be applied with a confidence score threshold so that any images that cannot be confidently machine-labelled are sent for human labeling. This ensures the best balance of cost and accuracy. More information is available in the Amazon SageMaker Ground Truth Developer Guide.
Using this method, we reduced the number of manually-classified images by 43%. The following table shows the number of images processed per iteration after we adopted Ground Truth (note that the training and validation data are accumulated data, while the other metrics are on a per-iteration basis).
- Directly load results – When building models in SageMaker, we could load the resulting manifest files generated by SageMaker Ground Truth and use them for training.
In summary, categorizing 10,000 images required 22 inspectors five days and cost $980.
Development of Image Classification Model with Amazon SageMaker Studio
We needed to classify review images as full body shots, upper body shots, package shots, product shots, and products into applicable categories. To accomplish our goals, we considered two models: the ResNet-based SageMaker built-in model and the Tensorflow-based MobileNet. We tested both on the same test datasets and found that the SageMaker built-in model was more accurate, with a 0.98 F1 score vs 0.88 from the TensorFlow model. Therefore, we decided on the SageMaker built-in model.
The SageMaker Studio-based model training process was as follows:
- Import labeled images from SageMaker Ground Truth
- Preprocess images – image resizing and augmenting
- Load the Amazon SageMaker built-in model as a Docker image
- Tune hyperparameters through grid search
- Apply transfer learning
- Re-tune parameters based on training metrics
- Save the model
SageMaker made it straightforward to train the model with just one click and without worrying about provisioning and managing a fleet of servers for training.
For hyperparameter turning, we employed grid search to determine the optimal values of hyperparameters, as the number of training layers (num_layers) and training cycles (epochs) during transfer learning had affected our classification model accuracy.
Model Serving with SageMaker Batch Transform and Apache Airflow
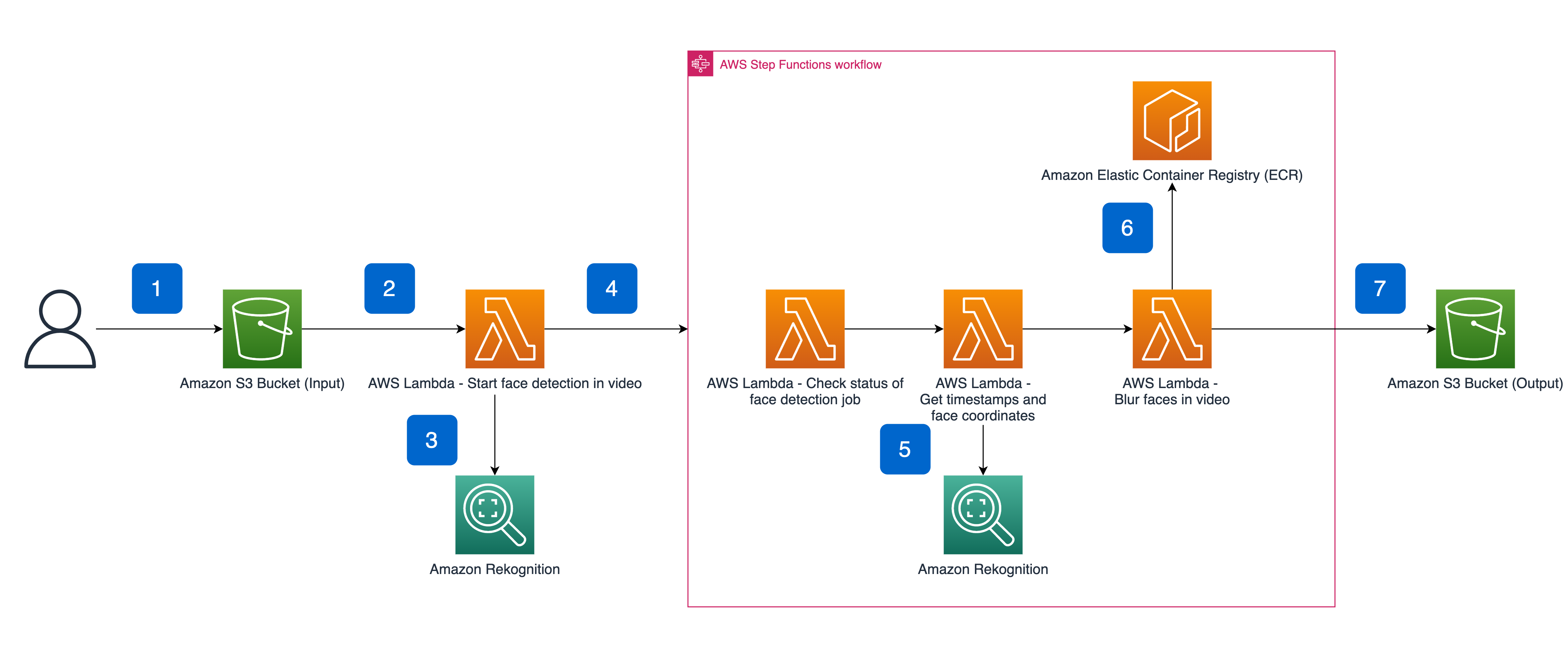
The image classification model we built required ML workflows to determine if a review image was qualified for credits. We established workflows with the following four steps.
- Import review images and metadata that must be automatically reviewed
- Infer the labels of the images (inference)
- Determine if credits should be given based on the inferred labels
- Store the results table in the production database
We are using Apache Airflow to manage data product workflows. It is a workflow scheduling and monitoring platform developed by Airbnb known for simple and intuitive web UI graphs. It supports Amazon SageMaker, so it easily migrates the code developed with SageMaker Studio to Apache Airflow. There are two ways to run SageMaker jobs on Apache Airflow:
- Using Amazon SageMaker Operators
- Using Python Operators : Write a Python function with Amazon SageMaker Python SDK on Apache Airflow and import it as a callable parameter
The second option let us maintain our existing Python codes that we already had on SageMaker Studio, and it didn’t require us to learn new grammars for Amazon SageMaker Operators.
However, we went through some trial and error, as it was our first time integrating Apache Airflow with Amazon SageMaker. The lessons we learned were:
- Boto3 update: Amazon SageMaker Python SDK version 2 required Boto3 1.14.12 or newer. Therefore, we needed to update the Boto3 version of our existing Apache Airflow environment, which was at 1.13.4.
- IAM Role and permission inheritance: AWS IAM roles used by Apache Airflow needed to inherit roles that could run Amazon SageMaker.
-
Network configuration: To run SageMaker codes with Apache Airflow, its endpoints needed to be configured for network connections. The following endpoints were based on the AWS Regions and services that we were using. For more information, see the AWS website.
api.sagemaker.ap-northeast-2.amazonaws.comruntime.sagemaker.ap-northeast-2.amazonaws.comaws.sagemaker.ap-northeast-2.studio
Outcomes
By automating review image inspection processes, we gained the following business outcomes:
- Increased work efficiency – Currently, 76% of images of the categories where the service were applied are inspected automatically with a 98% inspection accuracy.
- Consistency in giving credits – Credits are given based on clear criteria. However, there were occasions where credits were given differently for similar cases due to differences in inspectors’ judgments. The ML model applies rules more consistently with and higher consistency in applying our credit policies.
- Reduced human errors – Every human engagement carries a risk of human errors. For example, we had cases where Style Review criteria were used for Product Reviews. Our automatic inspection model dramatically reduced the risks of these human errors.
We gained the following benefits specifically by using Amazon SageMaker to automate the image inspection process:
- Established an environment where we can build and test models through modular processes – What we liked most about Amazon SageMaker is that it consists of modules. This lets us build and test services easily and quickly. We obviously needed some time to learn about Amazon SageMaker at first, but once learned, we could easily apply it in our operations. We believe that Amazon SageMaker is ideal for businesses requiring rapid service developments, as in the case of the MUSINSA Store.
- Collect reliable input data with Amazon SageMaker Ground Truth – Collecting input data is becoming increasingly more important than modeling itself in the area of ML. With the rapid advancement of ML, pre-trained models can perform much better than before, and without additional tuning. AutoML has also removed the need to write codes for ML modeling. Therefore, the ability to collect quality input data is more important than ever, and using labeling services such as Amazon SageMaker Ground Truth is critical.
Conclusion
Going forward, we plan to automate not only model serving but also model training through automatic batches. We want our model to identify the optimal hyperparameters automatically when new labels or images are added. In addition, we will continue improving the performance of our model, namely recalls and precision, based on the previously mentioned automated training method. We will increase our model coverage so that it can inspect more review images, reduce more costs, and achieve higher accuracies, which will all lead to higher customer satisfaction.
For more information about how to use Amazon SageMaker to solve your business problems using ML, visit the product webpage. And, as always, stay up to date with the latest AWS Machine Learning News here.
The content and opinions in this post are those of the third-party author and AWS is not responsible for the content or accuracy of this post.
About the Authors
 Jihye Park is a Data Scientist at MUSINSA who is responsible for data analysis and modeling. She loves working with ubiquitous data such as ecommerce. Her main role is data modeling but she has interests in data engineering too.
Jihye Park is a Data Scientist at MUSINSA who is responsible for data analysis and modeling. She loves working with ubiquitous data such as ecommerce. Her main role is data modeling but she has interests in data engineering too.
 Sungmin Kim is a Sr. Solutions Architect at Amazon Web Services. He works with startups to architect, design, automated, and build solutions on AWS for their business needs. He specializes in AI/ML and Analytics.
Sungmin Kim is a Sr. Solutions Architect at Amazon Web Services. He works with startups to architect, design, automated, and build solutions on AWS for their business needs. He specializes in AI/ML and Analytics.



















 Claire Mitchell is a Design Strategy Lead with the AWS Professional Services AWS Professional Services Emerging Technologies Intelligence Practice—Solutions team. Occasionally she spends time exploring speculative design practices, textiles, and playing the drums.
Claire Mitchell is a Design Strategy Lead with the AWS Professional Services AWS Professional Services Emerging Technologies Intelligence Practice—Solutions team. Occasionally she spends time exploring speculative design practices, textiles, and playing the drums.


 Ram Vegiraju is a ML Architect with the SageMaker Service team. He focuses on helping customers build and optimize their AI/ML solutions on Amazon SageMaker. In his spare time, he loves traveling and writing.
Ram Vegiraju is a ML Architect with the SageMaker Service team. He focuses on helping customers build and optimize their AI/ML solutions on Amazon SageMaker. In his spare time, he loves traveling and writing.
 Michael Pham is a Software Development Engineer in the Amazon SageMaker team. His current work focuses on helping developers efficiently host machine learning models. In his spare time he enjoys Olympic weightlifting, reading, and playing chess.
Michael Pham is a Software Development Engineer in the Amazon SageMaker team. His current work focuses on helping developers efficiently host machine learning models. In his spare time he enjoys Olympic weightlifting, reading, and playing chess.