Amazon Lex provides the power of automatic speech recognition (ASR) for converting speech to text, along with natural language understanding (NLU) for recognizing user intents. This combination allows you to develop sophisticated conversational interfaces using both voice and text for chatbots, IVR bots, and voicebots.
This week, we’re announcing Amazon Lex support for British English and US Spanish. With British English, your conversational bots can be localized to understand the British English accent, while delivering responses in Amazon Polly voices designed to sound like UK English speakers. Brilliant!
With support for US Spanish, you can develop applications for the second-most widely spoken language in the United States. Amazon Lex can now accurately recognize written and spoken Spanish, while providing responses using Amazon Polly’s natural sounding US Spanish voices. Listo!
In this post, we consider a hypothetical appliance manufacturer in the United States. Customers calling into their service center to schedule or change a repair appointment may prefer to speak in English or Spanish. The application for this use case allows callers to select their preferred language by saying “English” or “Español” when prompted. You want to provide them with the best customer service experience, no matter whether it is their washing machine or their lavadora that needs repair.
We show you how to create an Amazon Connect call center experience that supports both US English and US Spanish. Customers can schedule, change, and cancel appointments, using a fully automated solution that converses with them in their preferred language.
Building a multi-language conversational experience
This post uses the following sample conversations:
Agent: Thank you for calling. To continue in English, say “English,” for Spanish, say “Español.”
US English
Agent: I can schedule or change a repair appointment. How can I help?
User: I want to get my dishwasher fixed.
Agent: What city are you in?
User: Philadelphia
Agent: I have technicians available next week. When would you prefer to have them visit?
User: September 24th at noon
Agent: OK, you are all set for your dishwasher repair in Philadelphia on the 24th of September at noon.
US Spanish
Agent: Puede reservar o cambiar una cita de reparación. ¿Cómo puedo ayudar?
User: Me gustaria programar una cita
Agent: Para qué tipo de aparato?
User: Refrigerador
Agent: En que ciudad estas?
User: Brooklyn
Agent: En que fecha te gustaria que vinieran?
User: 24 de Septiembre
Agent: Bien, ya está todo listo para la reparación de su refrigerador en 24 de Septiembre, 2020.
To support these conversation models, you need to create Lex bots with relevant user intents. In this post, we create intents for ScheduleAppointment, ModifyAppointment, and CancelAppointment (and in Spanish, ReservarCita, ModificarCita, CancelarCita).
Deploying the sample Lex bots
To create the sample bots, perform the following steps. For this post, you create two Amazon Lex bots: AppointmentBot_enUS for US English, and AppointmentBot_esUS for US Spanish. To follow along with this post, you can create these Lex bots yourself on the Amazon Lex console, or import them directly.
- To import the bots, download the US English bot and the US Spanish bot
- On the Amazon Lex console, choose
- Select the zip that you downloaded, and choose Import.
- When the import process is complete, choose AppointmentBot_enUS, and choose
- When the build it complete, go back to the Amazon Lex console main window, and choose Import.
- Select the zip that you downloaded, and choose Import.
- When the import process is complete, choose AppointmentBot_esUS, and choose
At this point, you should have two working Lex bots: one for US English, and one for US Spanish.
Creating your Amazon Connect instance
In this section, we integrate the bots with an Amazon Connect cloud-based call center instance. The first step is to create the Amazon Connect instance:
- On the AWS Management Console, choose Amazon Connect.
- If this is your first Amazon Connect instance, choose Get started; otherwise, choose Add an instance.
- For Identity management, choose Store users within Amazon Connect.
- Enter a URL prefix, such as
appointment-bot-############, where ############ is your current AWS account number. - Choose Next step.
- For Create an administrator, enter a name, password, and email address.
- Choose Next step.
- For Telephony Options, leave both call options selected by default.
- Choose Next step.
- For Data storage, choose Next step.
- Review the settings and choose Create instance.
Associating your bots with your Amazon Connect instance
Now that you have an Amazon Connect instance, you can claim a phone number, create a contact flow, and integrate your contact flow with the two Lex bots you created in the prior step. First, associate your bots with your Amazon Connect instance:
- On the Amazon Connect console, open your instance by choosing the Instance Alias
- Choose Contact flows.
- From the drop-down list, choose AppointmentBot_enUS. If you don’t see the bot in the list, make sure you have selected the same Region you used when you created your Lex bot.
- Choose + Add Lex Bot.
- From the drop-down list, choose AppointmentBot_esUS and choose + Add Lex Bot.
Configuring Amazon Connect to work with your bot
Now you can use your bots with Amazon Connect. First, claim a phone number for your Amazon Connect instance:
- On the Amazon Connect console, choose Overview.
- Choose the Amazon Connect
- Choose the Login URL link, and enter the user name and password you specified earlier.
- On the Amazon Connect console, for Step 1, Choose Begin.
- For your phone number, choose a country, Direct Dial or Toll Free, and a phone number.
- Choose Next.
- If you want to test your new phone number, try it on the next screen or choose Skip for now.
For this post, you can skip the hours of operation, creating queues, and creating prompts. For more information on these features, see the Amazon Connect Administrator Guide. Now let’s import the contact flow.
- Download and unzip the sample Amazon Connect contact flow for this post: manage_repairs.zip.
- On the Amazon Connect console, go to Step 5, Create contact flows, choose View contact flows.
- Choose Create contact flow.
- From the drop-down at the top right side of the page, choose Import flow (beta).
- Choose Select and select the
manage-repairs.jsonfile you downloaded, and select Import. - Choose Save, and then Publish.
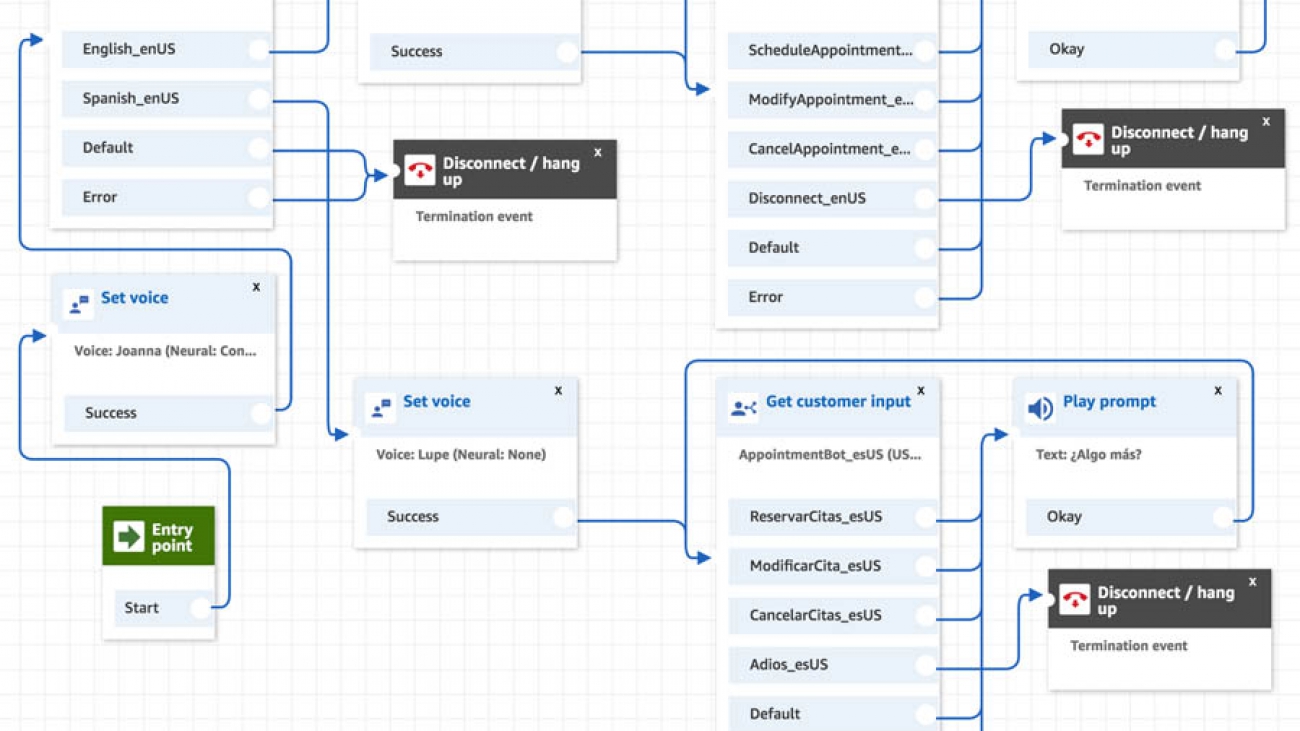
Your contact flow should look like the following screenshot.

- Choose the Routing icon from the side menu, and choose Phone numbers.
- Choose your phone number to edit it, and change the contact flow or IVR to the
Manage Repairscontact flow you just created. - Choose Save.
Your Amazon Connect instance is now configured to work with your Amazon Lex bots. Try calling the phone number to see how it works!
Conclusion
With the addition of British English and US Spanish language support, along with US English and Australian English, Amazon Lex allows you to create bots that can converse with users in their native language. You can combine Amazon Lex with Amazon Connect to create streamlined, multi-language call center user experiences in minutes. The additional language support in Amazon Lex is available at the same price, and in the same Regions, as US English. You can try these languages via the console, the AWS Command Line Interface (AWS CLI), and the AWS SDKs.
About the Authors
 Claire Mitchell is a Design Consultant with the AWS Professional Services Conversational AI team. Occasionally she spends time exploring speculative design practices, textiles, and playing the drums.
Claire Mitchell is a Design Consultant with the AWS Professional Services Conversational AI team. Occasionally she spends time exploring speculative design practices, textiles, and playing the drums.
 Brian Yost is a Senior Consultant with the AWS Professional Services Conversational AI team. In his spare time, he enjoys mountain biking, home brewing, and tinkering with technology.
Brian Yost is a Senior Consultant with the AWS Professional Services Conversational AI team. In his spare time, he enjoys mountain biking, home brewing, and tinkering with technology.
 As a Product Manager on the Amazon Lex team, Harshal Pimpalkhute spends his time trying to get machines to engage (nicely) with humans.
As a Product Manager on the Amazon Lex team, Harshal Pimpalkhute spends his time trying to get machines to engage (nicely) with humans.



 Ninad Kulkarni is a Data Scientist in the Amazon Machine Learning Solutions Lab. He helps customers adopt ML and AI by building solutions to address their business problems. Most recently, he has built predictive models for sports and automotive customers.
Ninad Kulkarni is a Data Scientist in the Amazon Machine Learning Solutions Lab. He helps customers adopt ML and AI by building solutions to address their business problems. Most recently, he has built predictive models for sports and automotive customers. Daliana Zhen Liu is a Data Scientist in the Amazon Machine Learning Solutions Lab. She has built ML models to help customers accelerate their business in sports, media and education. She is passionate about introducing data science to more people.
Daliana Zhen Liu is a Data Scientist in the Amazon Machine Learning Solutions Lab. She has built ML models to help customers accelerate their business in sports, media and education. She is passionate about introducing data science to more people. Tianyu Zhang is a Data Scientist in the Amazon Machine Learning Solutions Lab. He helps customers solve business problems by applying ML and AI techniques. Most recently, he has built NLP model and predictive model for procurement and sports.
Tianyu Zhang is a Data Scientist in the Amazon Machine Learning Solutions Lab. He helps customers solve business problems by applying ML and AI techniques. Most recently, he has built NLP model and predictive model for procurement and sports.
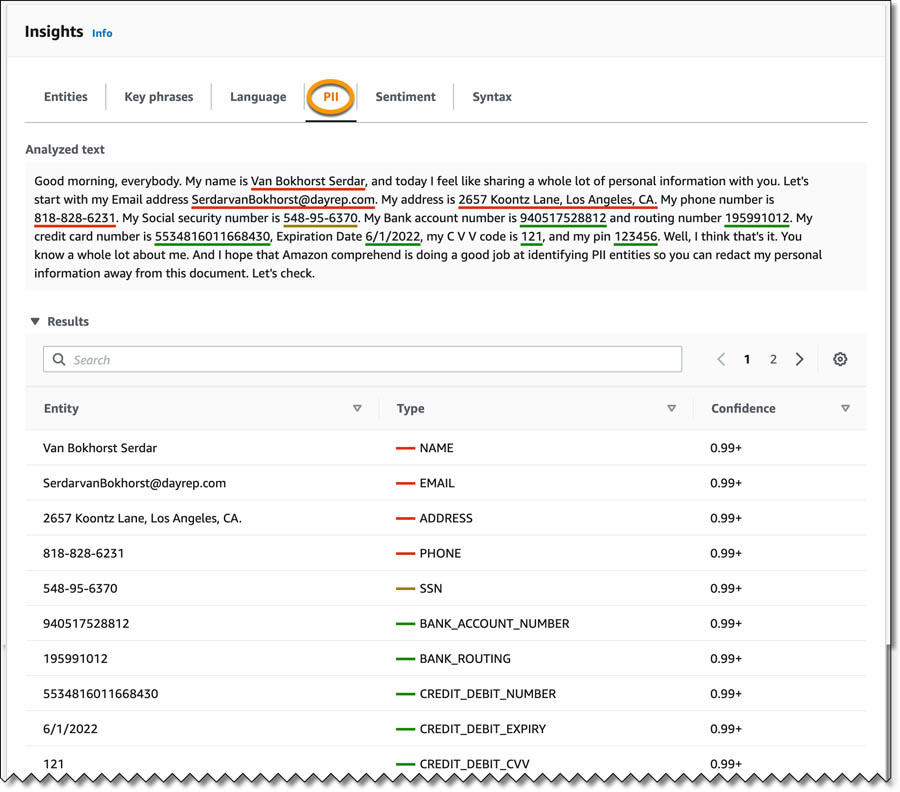
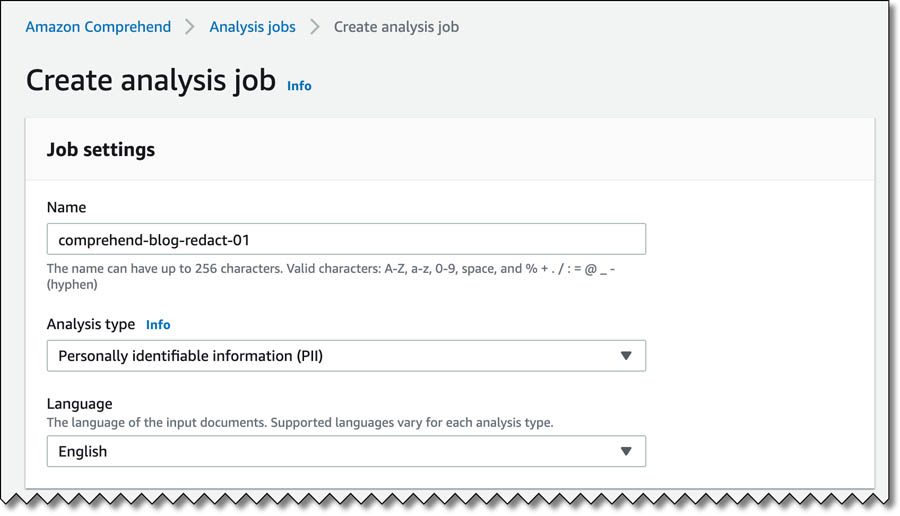
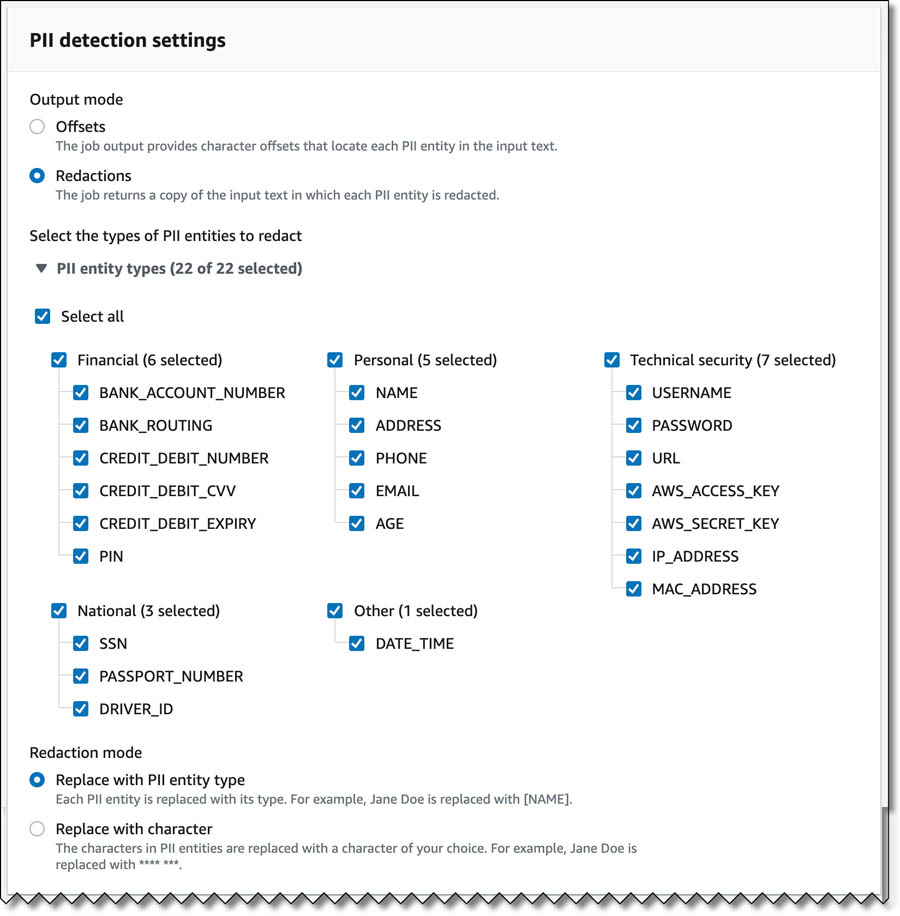
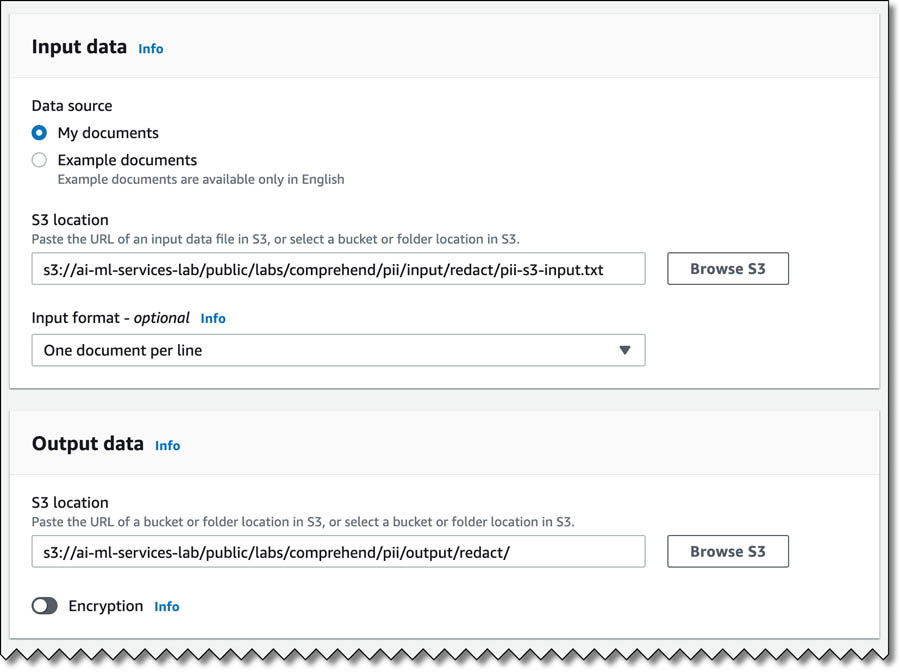
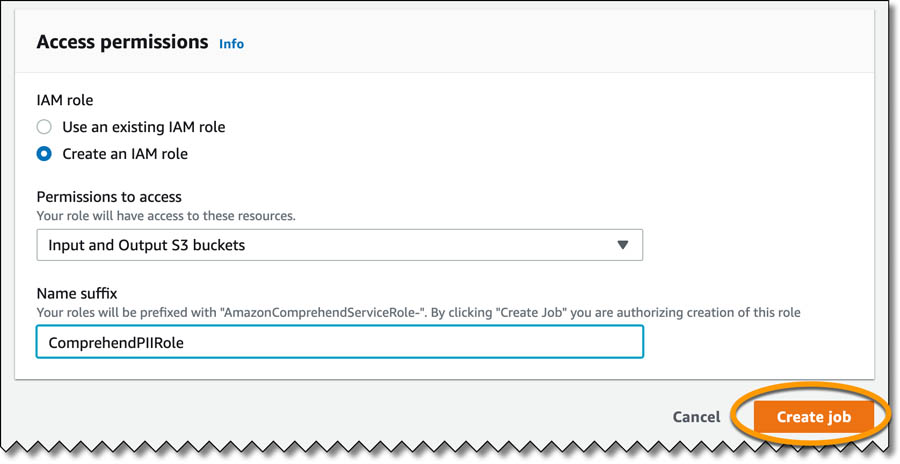
 ) capabilities, TeraDact’s tools provide the user with a safe information sharing environment. “Using Amazon Comprehend for PII redaction with our tokenization system not only helps us reach a larger set of our customers but also helps us overcome the shortcomings of rules-based PII detection which can result in false alarms or missed details. PII detection is critical for businesses and with the power of context-aware NLP models from Comprehend we can uphold the trust customers place in us with their information. Amazon is innovating in ways to help push our business forward by adding new features which are critical to our business thereby providing enhanced service to 100% of customers able to access Comprehend in AWS.” said Chris Schrichte, CEO, TeraDact Solutions, Inc.
) capabilities, TeraDact’s tools provide the user with a safe information sharing environment. “Using Amazon Comprehend for PII redaction with our tokenization system not only helps us reach a larger set of our customers but also helps us overcome the shortcomings of rules-based PII detection which can result in false alarms or missed details. PII detection is critical for businesses and with the power of context-aware NLP models from Comprehend we can uphold the trust customers place in us with their information. Amazon is innovating in ways to help push our business forward by adding new features which are critical to our business thereby providing enhanced service to 100% of customers able to access Comprehend in AWS.” said Chris Schrichte, CEO, TeraDact Solutions, Inc.
 Sriharsha M S is an AI/ML specialist solution architect in the Strategic Specialist team at Amazon Web Services. He works with strategic AWS customers who are taking advantage of AI/ML to solve complex business problems. He provides technical guidance and design advice to implement AI/ML applications at scale. His expertise spans application architecture, bigdata, analytics and machine learning.
Sriharsha M S is an AI/ML specialist solution architect in the Strategic Specialist team at Amazon Web Services. He works with strategic AWS customers who are taking advantage of AI/ML to solve complex business problems. He provides technical guidance and design advice to implement AI/ML applications at scale. His expertise spans application architecture, bigdata, analytics and machine learning.











 Suresh Patnam is a Solutions Architect at AWS. He helps customers innovate on the AWS platform by building highly available, scalable, and secure architectures on Big Data and AI/ML. In his spare time, Suresh enjoys playing tennis and spending time with his family.
Suresh Patnam is a Solutions Architect at AWS. He helps customers innovate on the AWS platform by building highly available, scalable, and secure architectures on Big Data and AI/ML. In his spare time, Suresh enjoys playing tennis and spending time with his family.