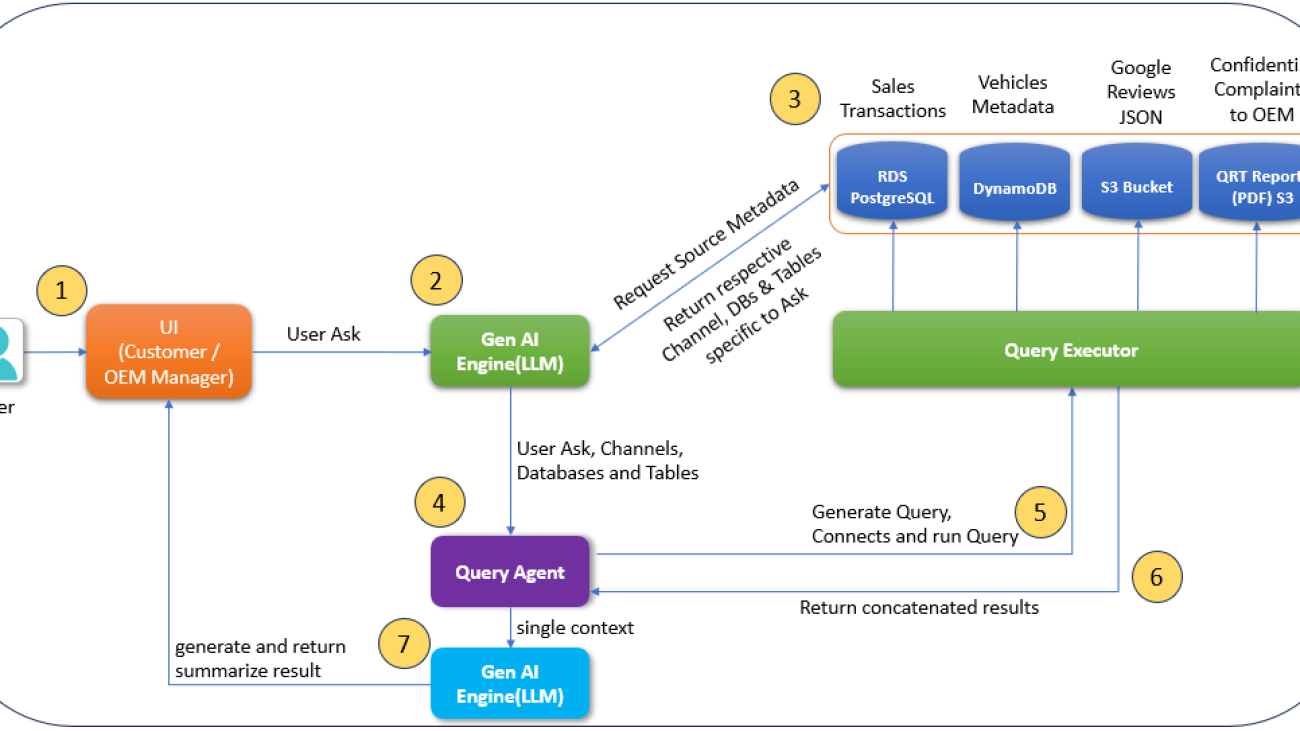
A common use case with generative AI that we usually see customers evaluate for a production use case is a generative AI-powered assistant. However, before it can be deployed, there is the typical production readiness assessment that includes concerns such as understanding the security posture, monitoring and logging, cost tracking, resilience, and more. The highest priority of these production readiness assessments is usually security. If there are security risks that can’t be clearly identified, then they can’t be addressed, and that can halt the production deployment of the generative AI application.
In this post, we show you an example of a generative AI assistant application and demonstrate how to assess its security posture using the OWASP Top 10 for Large Language Model Applications, as well as how to apply mitigations for common threats.
Generative AI scoping framework
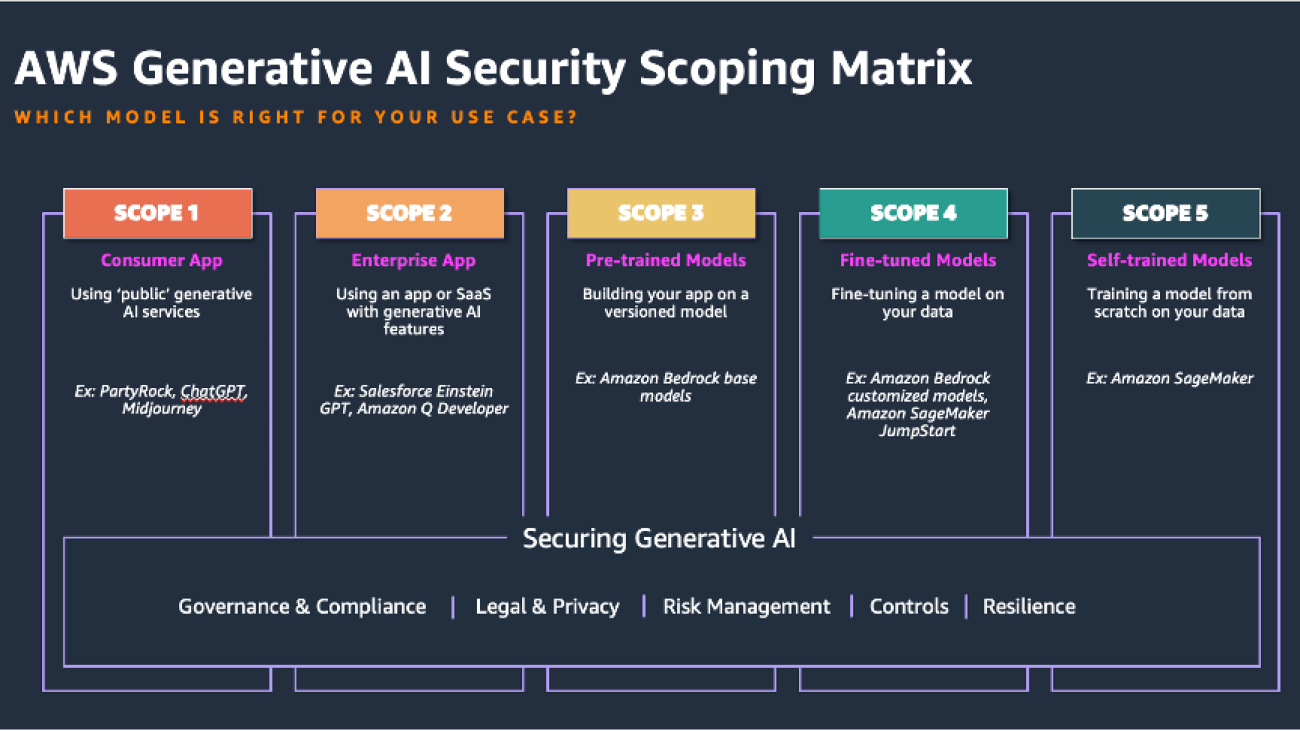
Start by understanding where your generative AI application fits within the spectrum of managed vs. custom. Use the AWS generative AI scoping framework to understand the specific mix of the shared responsibility for the security controls applicable to your application. For example, Scope 1 “Consumer Apps” like PartyRock or ChatGPT are usually publicly facing applications, where most of the application internal security is owned and controlled by the provider, and your responsibility for security is on the consumption side. Contrast that with Scope 4/5 applications, where not only do you build and secure the generative AI application yourself, but you are also responsible for fine-tuning and training the underlying large language model (LLM). The security controls in scope for Scope 4/5 applications will range more broadly from the frontend to LLM model security. This post will focus on the Scope 3 generative AI assistant application, which is one of the more frequent use cases seen in the field.
The following figure of the AWS Generative AI Security Scoping Matrix summarizes the types of models for each scope.

OWASP Top 10 for LLMs
Using the OWASP Top 10 for understanding threats and mitigations to an application is one of the most common ways application security is assessed. The OWASP Top 10 for LLMs takes a tried and tested framework and applies it to generative AI applications to help us discover, understand, and mitigate the novel threats for generative AI.

Solution overview
Let’s start with a logical architecture of a typical generative AI assistant application overlying the OWASP Top 10 for LLM threats, as illustrated in the following diagram.

In this architecture, the end-user request usually goes through the following components:
- Authentication layer – This layer validates that the user connecting to the application is who they say they are. This is typically done through some sort of an identity provider (IdP) capability like Okta, AWS IAM Identity Center, or Amazon Cognito.
- Application controller – This layer contains most of the application business logic and determines how to process the incoming user request by generating the LLM prompts and processing LLM responses before they are sent back to the user.
- LLM and LLM agent – The LLM provides the core generative AI capability to the assistant. The LLM agent is an orchestrator of a set of steps that might be necessary to complete the desired request. These steps might involve both the use of an LLM and external data sources and APIs.
- Agent plugin controller – This component is responsible for the API integration to external data sources and APIs. This component also holds the mapping between the logical name of an external component, which the LLM agent might refer to, and the physical name.
- RAG data store – The Retrieval Augmented Generation (RAG) data store delivers up-to-date, precise, and access-controlled knowledge from various data sources such as data warehouses, databases, and other software as a service (SaaS) applications through data connectors.
The OWASP Top 10 for LLM risks map to various layers of the application stack, highlighting vulnerabilities from UIs to backend systems. In the following sections, we discuss risks at each layer and provide an application design pattern for a generative AI assistant application in AWS that mitigates these risks.
The following diagram illustrates the assistant architecture on AWS.

Authentication layer (Amazon Cognito)
Common security threats such as brute force attacks, session hijacking, and denial of service (DoS) attacks can occur. To mitigate these risks, implement best practices like multi-factor authentication (MFA), rate limiting, secure session management, automatic session timeouts, and regular token rotation. Additionally, deploying edge security measures such as AWS WAF and distributed denial of service (DDoS) mitigation helps block common web exploits and maintain service availability during attacks.
In the preceding architecture diagram, AWS WAF is integrated with Amazon API Gateway to filter incoming traffic, blocking unintended requests and protecting applications from threats like SQL injection, cross-site scripting (XSS), and DoS attacks. AWS WAF Bot Control further enhances security by providing visibility and control over bot traffic, allowing administrators to block or rate-limit unwanted bots. This feature can be centrally managed across multiple accounts using AWS Firewall Manager, providing a consistent and robust approach to application protection.
Amazon Cognito complements these defenses by enabling user authentication and data synchronization. It supports both user pools and identity pools, enabling seamless management of user identities across devices and integration with third-party identity providers. Amazon Cognito offers security features, including MFA, OAuth 2.0, OpenID Connect, secure session management, and risk-based adaptive authentication, to help protect against unauthorized access by evaluating sign-in requests for suspicious activity and responding with additional security measures like MFA or blocking sign-ins. Amazon Cognito also enforces password reuse prevention, further protecting against compromised credentials.
AWS Shield Advanced adds an extra layer of defense by providing enhanced protection against sophisticated DDoS attacks. Integrated with AWS WAF, Shield Advanced delivers comprehensive perimeter protection, using tailored detection and health-based assessments to enhance response to attacks. It also offers round-the-clock support from the AWS Shield Response Team and includes DDoS cost protection, making applications remain secure and cost-effective. Together, Shield Advanced and AWS WAF create a security framework that protects applications against a wide range of threats while maintaining availability.
This comprehensive security setup addresses LLM10:2025 Unbound Consumption and LLM02:2025 Sensitive Information Disclosure, making sure that applications remain both resilient and secure.
Application controller layer (LLM orchestrator Lambda function)
The application controller layer is usually vulnerable to risks such as LLM01:2025 Prompt Injection, LLM05:2025 Improper Output Handling, and LLM 02:2025 Sensitive Information Disclosure. Outside parties might frequently attempt to exploit this layer by crafting unintended inputs to manipulate the LLM, potentially causing it to reveal sensitive information or compromise downstream systems.
In the physical architecture diagram, the application controller is the LLM orchestrator AWS Lambda function. It performs strict input validation by extracting the event payload from API Gateway and conducting both syntactic and semantic validation. By sanitizing inputs, applying allowlisting and deny listing of keywords, and validating inputs against predefined formats or patterns, the Lambda function helps prevent LLM01:2025 Prompt Injection attacks. Additionally, by passing the user_id downstream, it enables the downstream application components to mitigate the risk of sensitive information disclosure, addressing concerns related to LLM02:2025 Sensitive Information Disclosure.
Amazon Bedrock Guardrails provides an additional layer of protection by filtering and blocking sensitive content, such as personally identifiable information (PII) and other custom sensitive data defined by regex patterns. Guardrails can also be configured to detect and block offensive language, competitor names, or other undesirable terms, making sure that both inputs and outputs are safe. You can also use guardrails to prevent LLM01:2025 Prompt Injection attacks by detecting and filtering out harmful or manipulative prompts before they reach the LLM, thereby maintaining the integrity of the prompt.
Another critical aspect of security is managing LLM outputs. Because the LLM might generate content that includes executable code, such as JavaScript or Markdown, there is a risk of XSS attacks if this content is not properly handled. To mitigate this risk, apply output encoding techniques, such as HTML entity encoding or JavaScript escaping, to neutralize any potentially harmful content before it is presented to users. This approach addresses the risk of LLM05:2025 Improper Output Handling.
Implementing Amazon Bedrock prompt management and versioning allows for continuous improvement of the user experience while maintaining the overall security of the application. By carefully managing changes to prompts and their handling, you can enhance functionality without introducing new vulnerabilities and mitigating LLM01:2025 Prompt Injection attacks.
Treating the LLM as an untrusted user and applying human-in-the-loop processes over certain actions are strategies to lower the likelihood of unauthorized or unintended operations.
LLM and LLM agent layer (Amazon Bedrock LLMs)
The LLM and LLM agent layer frequently handles interactions with the LLM and faces risks such as LLM10: Unbounded Consumption, LLM05:2025 Improper Output Handling, and LLM02:2025 Sensitive Information Disclosure.
DoS attacks can overwhelm the LLM with multiple resource-intensive requests, degrading overall service quality while increasing costs. When interacting with Amazon Bedrock hosted LLMs, setting request parameters such as the maximum length of the input request will minimize the risk of LLM resource exhaustion. Additionally, there is a hard limit on the maximum number of queued actions and total actions an Amazon Bedrock agent can take to fulfill a customer’s intent, which limits the number of actions in a system reacting to LLM responses, avoiding unnecessary loops or intensive tasks that could exhaust the LLM’s resources.
Improper output handling leads to vulnerabilities such as remote code execution, cross-site scripting, server-side request forgery (SSRF), and privilege escalation. The inadequate validation and management of the LLM-generated outputs before they are sent downstream can grant indirect access to additional functionality, effectively enabling these vulnerabilities. To mitigate this risk, treat the model as any other user and apply validation of the LLM-generated responses. The process is facilitated with Amazon Bedrock Guardrails using filters such as content filters with configurable thresholds to filter harmful content and safeguard against prompt attacks before they are processed further downstream by other backend systems. Guardrails automatically evaluate both user input and model responses to detect and help prevent content that falls into restricted categories.
Amazon Bedrock Agents execute multi-step tasks and securely integrate with AWS native and third-party services to reduce the risk of insecure output handling, excessive agency, and sensitive information disclosure. In the architecture diagram, the action group Lambda function under the agents is used to encode all the output text, making it automatically non-executable by JavaScript or Markdown. Additionally, the action group Lambda function parses each output from the LLM at every step executed by the agents and controls the processing of the outputs accordingly, making sure they are safe before further processing.
Sensitive information disclosure is a risk with LLMs because malicious prompt engineering can cause LLMs to accidentally reveal unintended details in their responses. This can lead to privacy and confidentiality violations. To mitigate the issue, implement data sanitization practices through content filters in Amazon Bedrock Guardrails.
Additionally, implement custom data filtering policies based on user_id and strict user access policies. Amazon Bedrock Guardrails helps filter content deemed sensitive, and Amazon Bedrock Agents further reduces the risk of sensitive information disclosure by allowing you to implement custom logic in the preprocessing and postprocessing templates to strip any unexpected information. If you have enabled model invocation logging for the LLM or implemented custom logging logic in your application to record the input and output of the LLM in Amazon CloudWatch, measures such as CloudWatch Log data protection are important in masking sensitive information identified in the CloudWatch logs, further mitigating the risk of sensitive information disclosure.
Agent plugin controller layer (action group Lambda function)
The agent plugin controller frequently integrates with internal and external services and applies custom authorization to internal and external data sources and third-party APIs. At this layer, the risk of LLM08:2025 Vector & Embedding Weaknesses and LLM06:2025 Excessive Agency are in effect. Untrusted or unverified third-party plugins could introduce backdoors or vulnerabilities in the form of unexpected code.
Apply least privilege access to the AWS Identity and Access Management (IAM) roles of the action group Lambda function, which interacts with plugin integrations to external systems to help mitigate the risk of LLM06:2025 Excessive Agency and LLM08:2025 Vector & Embedding Weaknesses. This is demonstrated in the physical architecture diagram; the agent plugin layer Lambda function is associated with a least privilege IAM role for secure access and interface with other internal AWS services.
Additionally, after the user identity is determined, restrict the data plane by applying user-level access control by passing the user_id to downstream layers like the agent plugin layer. Although this user_id parameter can be used in the agent plugin controller Lambda function for custom authorization logic, its primary purpose is to enable fine-grained access control for third-party plugins. The responsibility lies with the application owner to implement custom authorization logic within the action group Lambda function, where the user_id parameter can be used in combination with predefined rules to apply the appropriate level of access to third-party APIs and plugins. This approach wraps deterministic access controls around a non-deterministic LLM and enables granular access control over which users can access and execute specific third-party plugins.
Combining user_id-based authorization on data and IAM roles with least privilege on the action group Lambda function will generally minimize the risk of LLM08:2025 Vector & Embedding Weaknesses and LLM06:2025 Excessive Agency.
RAG data store layer
The RAG data store is responsible for securely retrieving up-to-date, precise, and user access-controlled knowledge from various first-party and third-party data sources. By default, Amazon Bedrock encrypts all knowledge base-related data using an AWS managed key. Alternatively, you can choose to use a customer managed key. When setting up a data ingestion job for your knowledge base, you can also encrypt the job using a custom AWS Key Management Service (AWS KMS) key.
If you decide to use the vector store in Amazon OpenSearch Service for your knowledge base, Amazon Bedrock can pass a KMS key of your choice to it for encryption. Additionally, you can encrypt the sessions in which you generate responses from querying a knowledge base with a KMS key. To facilitate secure communication, Amazon Bedrock Knowledge Bases uses TLS encryption when interacting with third-party vector stores, provided that the service supports and permits TLS encryption in transit.
Regarding user access control, Amazon Bedrock Knowledge Bases uses filters to manage permissions. You can build a segmented access solution on top of a knowledge base using metadata and filtering feature. During runtime, your application must authenticate and authorize the user, and include this user information in the query to maintain accurate access controls. To keep the access controls updated, you should periodically resync the data to reflect any changes in permissions. Additionally, groups can be stored as a filterable attribute, further refining access control.
This approach helps mitigate the risk of LLM02:2025 Sensitive Information Disclosure and LLM08:2025 Vector & Embedding Weaknesses, to assist in that only authorized users can access the relevant data.
Summary
In this post, we discussed how to classify your generative AI application from a security shared responsibility perspective using the AWS Generative AI Security Scoping Matrix. We reviewed a common generative AI assistant application architecture and assessed its security posture using the OWASP Top 10 for LLMs framework, and showed how to apply the OWASP Top 10 for LLMs threat mitigations using AWS service controls and services to strengthen the architecture of your generative AI assistant application. Learn more about building generative AI applications with AWS Workshops for Bedrock.
About the Authors
 Syed Jaffry is a Principal Solutions Architect with AWS. He advises software companies on AI and helps them build modern, robust and secure application architectures on AWS.
Syed Jaffry is a Principal Solutions Architect with AWS. He advises software companies on AI and helps them build modern, robust and secure application architectures on AWS.
 Amit Kumar Agrawal is a Senior Solutions Architect at AWS where he has spent over 5 years working with large ISV customers. He helps organizations build and operate cost-efficient and scalable solutions in the cloud, driving their business and technical outcomes.
Amit Kumar Agrawal is a Senior Solutions Architect at AWS where he has spent over 5 years working with large ISV customers. He helps organizations build and operate cost-efficient and scalable solutions in the cloud, driving their business and technical outcomes.
 Tej Nagabhatla is a Senior Solutions Architect at AWS, where he works with a diverse portfolio of clients ranging from ISVs to large enterprises. He specializes in providing architectural guidance across a wide range of topics around AI/ML, security, storage, containers, and serverless technologies. He helps organizations build and operate cost-efficient, scalable cloud applications. In his free time, Tej enjoys music, playing basketball, and traveling.
Tej Nagabhatla is a Senior Solutions Architect at AWS, where he works with a diverse portfolio of clients ranging from ISVs to large enterprises. He specializes in providing architectural guidance across a wide range of topics around AI/ML, security, storage, containers, and serverless technologies. He helps organizations build and operate cost-efficient, scalable cloud applications. In his free time, Tej enjoys music, playing basketball, and traveling.





 Muni Annachi, a Senior DevOps Consultant at AWS, boasts over a decade of expertise in architecting and implementing software systems and cloud platforms. He specializes in guiding non-profit organizations to adopt DevOps CI/CD architectures, adhering to AWS best practices and the AWS Well-Architected Framework. Beyond his professional endeavors, Muni is an avid sports enthusiast and tries his luck in the kitchen.
Muni Annachi, a Senior DevOps Consultant at AWS, boasts over a decade of expertise in architecting and implementing software systems and cloud platforms. He specializes in guiding non-profit organizations to adopt DevOps CI/CD architectures, adhering to AWS best practices and the AWS Well-Architected Framework. Beyond his professional endeavors, Muni is an avid sports enthusiast and tries his luck in the kitchen. Ajay Raghunathan is a Machine Learning Engineer at AWS. His current work focuses on architecting and implementing ML solutions at scale. He is a technology enthusiast and a builder with a core area of interest in AI/ML, data analytics, serverless, and DevOps. Outside of work, he enjoys spending time with family, traveling, and playing football.
Ajay Raghunathan is a Machine Learning Engineer at AWS. His current work focuses on architecting and implementing ML solutions at scale. He is a technology enthusiast and a builder with a core area of interest in AI/ML, data analytics, serverless, and DevOps. Outside of work, he enjoys spending time with family, traveling, and playing football. Arun Dyasani is a Senior Cloud Application Architect at AWS. His current work focuses on designing and implementing innovative software solutions. His role centers on crafting robust architectures for complex applications, leveraging his deep knowledge and experience in developing large-scale systems.
Arun Dyasani is a Senior Cloud Application Architect at AWS. His current work focuses on designing and implementing innovative software solutions. His role centers on crafting robust architectures for complex applications, leveraging his deep knowledge and experience in developing large-scale systems. Shweta Singh is a Senior Product Manager in the Amazon SageMaker Machine Learning platform team at AWS, leading the SageMaker Python SDK. She has worked in several product roles in Amazon for over 5 years. She has a Bachelor of Science degree in Computer Engineering and a Masters of Science in Financial Engineering, both from New York University.
Shweta Singh is a Senior Product Manager in the Amazon SageMaker Machine Learning platform team at AWS, leading the SageMaker Python SDK. She has worked in several product roles in Amazon for over 5 years. She has a Bachelor of Science degree in Computer Engineering and a Masters of Science in Financial Engineering, both from New York University. Jenna Eun is a Principal Practice Manager for the Health and Advanced Compute team at AWS Professional Services. Her team focuses on designing and delivering data, ML, and advanced computing solutions for the public sector, including federal, state and local governments, academic medical centers, nonprofit healthcare organizations, and research institutions.
Jenna Eun is a Principal Practice Manager for the Health and Advanced Compute team at AWS Professional Services. Her team focuses on designing and delivering data, ML, and advanced computing solutions for the public sector, including federal, state and local governments, academic medical centers, nonprofit healthcare organizations, and research institutions. Meenakshi Ponn Shankaran is a Principal Domain Architect at AWS in the Data & ML Professional Services Org. He has extensive expertise in designing and building large-scale data lakes, handling petabytes of data. Currently, he focuses on delivering technical leadership to AWS US Public Sector clients, guiding them in using innovative AWS services to meet their strategic objectives and unlock the full potential of their data.
Meenakshi Ponn Shankaran is a Principal Domain Architect at AWS in the Data & ML Professional Services Org. He has extensive expertise in designing and building large-scale data lakes, handling petabytes of data. Currently, he focuses on delivering technical leadership to AWS US Public Sector clients, guiding them in using innovative AWS services to meet their strategic objectives and unlock the full potential of their data.

















 Christian Kamwangala is an AI/ML and Generative AI Specialist Solutions Architect at AWS, based in Paris, France. He helps enterprise customers architect and implement cutting-edge AI solutions using the comprehensive suite of AWS tools, with a focus on production-ready systems that follow industry best practices. In his spare time, Christian enjoys exploring nature and spending time with family and friends.
Christian Kamwangala is an AI/ML and Generative AI Specialist Solutions Architect at AWS, based in Paris, France. He helps enterprise customers architect and implement cutting-edge AI solutions using the comprehensive suite of AWS tools, with a focus on production-ready systems that follow industry best practices. In his spare time, Christian enjoys exploring nature and spending time with family and friends. Irene Arroyo Delgado is an AI/ML and GenAI Specialist Solutions Architect at AWS. She focuses on bringing out the potential of generative AI for each use case and productionizing ML workloads to achieve customers’ desired business outcomes by automating end-to-end ML lifecycles. In her free time, Irene enjoys traveling and hiking.
Irene Arroyo Delgado is an AI/ML and GenAI Specialist Solutions Architect at AWS. She focuses on bringing out the potential of generative AI for each use case and productionizing ML workloads to achieve customers’ desired business outcomes by automating end-to-end ML lifecycles. In her free time, Irene enjoys traveling and hiking.




 Ken Haynes is a Senior Solutions Architect in AWS Global Financial Services and has been with AWS since September 2022. Prior to AWS, Ken worked for Santander UK Technology and Deutsche Bank helping them build their cloud foundations on AWS, Azure, and GCP.
Ken Haynes is a Senior Solutions Architect in AWS Global Financial Services and has been with AWS since September 2022. Prior to AWS, Ken worked for Santander UK Technology and Deutsche Bank helping them build their cloud foundations on AWS, Azure, and GCP. Rim Zaafouri is a technologist at heart and a cloud enthusiast. As an AWS Solutions Architect, she guides financial services businesses in their cloud adoption journey and helps them to drive innovation, with a particular focus on serverless technologies and generative AI. Beyond the tech world, Rim is an avid fitness enthusiast and loves exploring new destinations around the world.
Rim Zaafouri is a technologist at heart and a cloud enthusiast. As an AWS Solutions Architect, she guides financial services businesses in their cloud adoption journey and helps them to drive innovation, with a particular focus on serverless technologies and generative AI. Beyond the tech world, Rim is an avid fitness enthusiast and loves exploring new destinations around the world. Patrick Sard works as a Solutions Architect accompanying financial institutions in EMEA through their cloud transformation journeys. He has helped multiple enterprises harness the power of AI and machine learning on AWS. He’s currently guiding organizations to unlock the transformative potential of Generative AI technologies. When not architecting cloud solutions, you’ll likely find Patrick on a tennis court, applying the same determination to perfect his game as he does to solving complex technical challenges.
Patrick Sard works as a Solutions Architect accompanying financial institutions in EMEA through their cloud transformation journeys. He has helped multiple enterprises harness the power of AI and machine learning on AWS. He’s currently guiding organizations to unlock the transformative potential of Generative AI technologies. When not architecting cloud solutions, you’ll likely find Patrick on a tennis court, applying the same determination to perfect his game as he does to solving complex technical challenges.






 Asaf Fried leads the Data Science team in Cato Research Labs at Cato Networks. Member of Cato Ctrl. Asaf has more than six years of both academic and industry experience in applying state-of-the-art and novel machine learning methods to the domain of networking and cybersecurity. His main research interests include asset discovery, risk assessment, and network-based attacks in enterprise environments.
Asaf Fried leads the Data Science team in Cato Research Labs at Cato Networks. Member of Cato Ctrl. Asaf has more than six years of both academic and industry experience in applying state-of-the-art and novel machine learning methods to the domain of networking and cybersecurity. His main research interests include asset discovery, risk assessment, and network-based attacks in enterprise environments. Daniel Pienica is a Data Scientist at Cato Networks with a strong passion for large language models (LLMs) and machine learning (ML). With six years of experience in ML and cybersecurity, he brings a wealth of knowledge to his work. Holding an MSc in Applied Statistics, Daniel applies his analytical skills to solve complex data problems. His enthusiasm for LLMs drives him to find innovative solutions in cybersecurity. Daniel’s dedication to his field is evident in his continuous exploration of new technologies and techniques.
Daniel Pienica is a Data Scientist at Cato Networks with a strong passion for large language models (LLMs) and machine learning (ML). With six years of experience in ML and cybersecurity, he brings a wealth of knowledge to his work. Holding an MSc in Applied Statistics, Daniel applies his analytical skills to solve complex data problems. His enthusiasm for LLMs drives him to find innovative solutions in cybersecurity. Daniel’s dedication to his field is evident in his continuous exploration of new technologies and techniques. Sergey Volkovich is an experienced Data Scientist at Cato Networks, where he develops AI-based solutions in cybersecurity & computer networks. He completed an M.Sc. in physics at Bar-Ilan University, where he published a paper on theoretical quantum optics. Before joining Cato, he held multiple positions across diverse deep learning projects, ranging from publishing a paper on discovering new particles at the Weizmann Institute to advancing computer networks and algorithmic trading. Presently, his main area of focus is state-of-the-art natural language processing.
Sergey Volkovich is an experienced Data Scientist at Cato Networks, where he develops AI-based solutions in cybersecurity & computer networks. He completed an M.Sc. in physics at Bar-Ilan University, where he published a paper on theoretical quantum optics. Before joining Cato, he held multiple positions across diverse deep learning projects, ranging from publishing a paper on discovering new particles at the Weizmann Institute to advancing computer networks and algorithmic trading. Presently, his main area of focus is state-of-the-art natural language processing. Omer Haim is a Senior Solutions Architect at Amazon Web Services, with over 6 years of experience dedicated to solving complex customer challenges through innovative machine learning and AI solutions. He brings deep expertise in generative AI and container technologies, and is passionate about working backwards from customer needs to deliver scalable, efficient solutions that drive business value and technological transformation.
Omer Haim is a Senior Solutions Architect at Amazon Web Services, with over 6 years of experience dedicated to solving complex customer challenges through innovative machine learning and AI solutions. He brings deep expertise in generative AI and container technologies, and is passionate about working backwards from customer needs to deliver scalable, efficient solutions that drive business value and technological transformation.




























 Aditya Pendyala is a Principal Solutions Architect at AWS based out of NYC. He has extensive experience in architecting cloud-based applications. He is currently working with large enterprises to help them craft highly scalable, flexible, and resilient cloud architectures, and guides them on all things cloud. He has a Master of Science degree in Computer Science from Shippensburg University and believes in the quote “When you cease to learn, you cease to grow.
Aditya Pendyala is a Principal Solutions Architect at AWS based out of NYC. He has extensive experience in architecting cloud-based applications. He is currently working with large enterprises to help them craft highly scalable, flexible, and resilient cloud architectures, and guides them on all things cloud. He has a Master of Science degree in Computer Science from Shippensburg University and believes in the quote “When you cease to learn, you cease to grow. Julio Hanna, an AWS Solutions Architect based in New York City, specializes in enterprise technology solutions and operational efficiency. With a career focused on driving innovation, he currently leverages Artificial Intelligence, Machine Learning, and Generative AI to help organizations navigate their digital transformation journeys. Julio’s expertise lies in harnessing cutting-edge technologies to deliver strategic value and foster innovation in enterprise environments.
Julio Hanna, an AWS Solutions Architect based in New York City, specializes in enterprise technology solutions and operational efficiency. With a career focused on driving innovation, he currently leverages Artificial Intelligence, Machine Learning, and Generative AI to help organizations navigate their digital transformation journeys. Julio’s expertise lies in harnessing cutting-edge technologies to deliver strategic value and foster innovation in enterprise environments.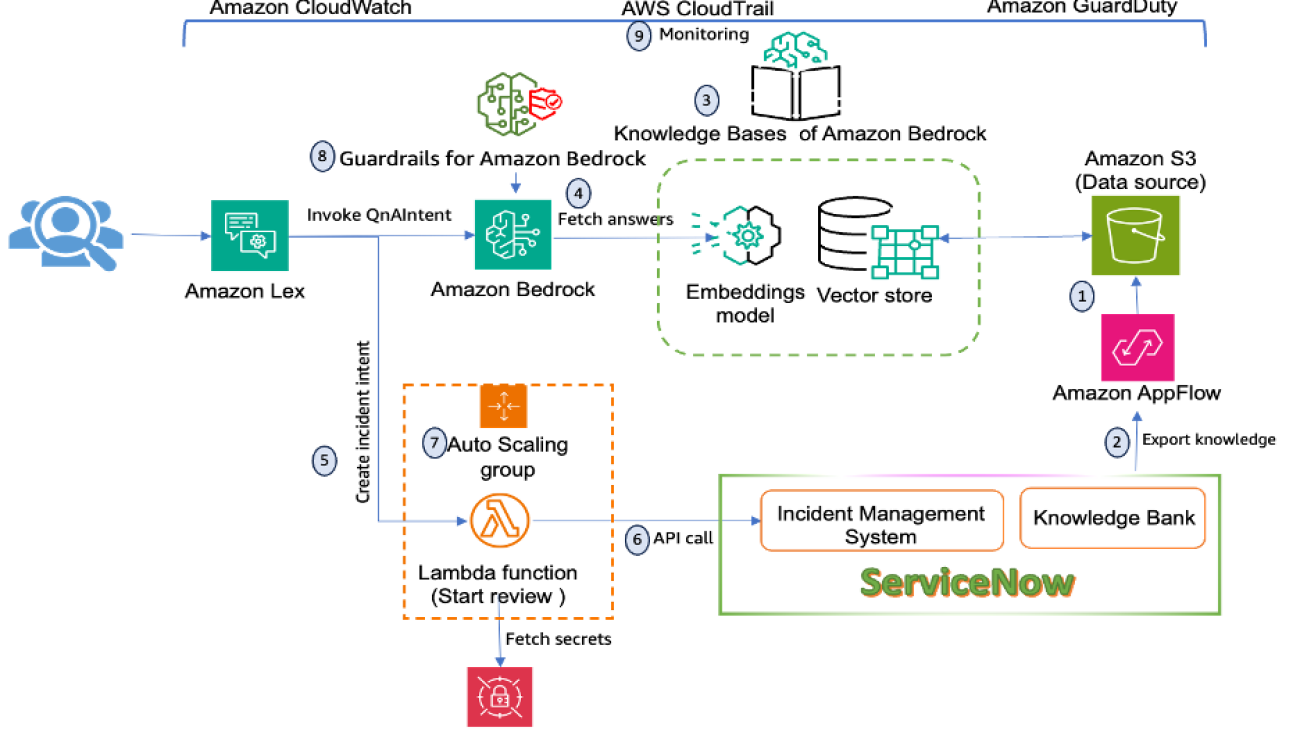





















 Marcelo Silva is an experienced tech professional who excels in designing, developing, and implementing cutting-edge products. Starting off his career at Cisco, Marcelo worked on various high-profile projects including deployments of the first ever carrier routing system and the successful rollout of ASR9000. His expertise extends to cloud technology, analytics, and product management, having served as senior manager for several companies such as Cisco, Cape Networks, and AWS before joining GenAI. Currently working as a Conversational AI/GenAI Product Manager, Marcelo continues to excel in delivering innovative solutions across industries.
Marcelo Silva is an experienced tech professional who excels in designing, developing, and implementing cutting-edge products. Starting off his career at Cisco, Marcelo worked on various high-profile projects including deployments of the first ever carrier routing system and the successful rollout of ASR9000. His expertise extends to cloud technology, analytics, and product management, having served as senior manager for several companies such as Cisco, Cape Networks, and AWS before joining GenAI. Currently working as a Conversational AI/GenAI Product Manager, Marcelo continues to excel in delivering innovative solutions across industries. Sujatha Dantuluri is a seasoned Senior Solutions Architect on the US federal civilian team at AWS, with over two decades of experience supporting commercial and federal government clients. Her expertise lies in architecting mission-critical solutions and working closely with customers to ensure their success. Sujatha is an accomplished public speaker, frequently sharing her insights and knowledge at industry events and conferences. She has contributed to IEEE standards and is passionate about empowering others through her engaging presentations and thought-provoking ideas.
Sujatha Dantuluri is a seasoned Senior Solutions Architect on the US federal civilian team at AWS, with over two decades of experience supporting commercial and federal government clients. Her expertise lies in architecting mission-critical solutions and working closely with customers to ensure their success. Sujatha is an accomplished public speaker, frequently sharing her insights and knowledge at industry events and conferences. She has contributed to IEEE standards and is passionate about empowering others through her engaging presentations and thought-provoking ideas. NagaBharathi Challa is a solutions architect on the US federal civilian team at Amazon Web Services (AWS). She works closely with customers to effectively use AWS services for their mission use cases, providing architectural best practices and guidance on a wide range of services. Outside of work, she enjoys spending time with family and spreading the power of meditation.
NagaBharathi Challa is a solutions architect on the US federal civilian team at Amazon Web Services (AWS). She works closely with customers to effectively use AWS services for their mission use cases, providing architectural best practices and guidance on a wide range of services. Outside of work, she enjoys spending time with family and spreading the power of meditation. Pranit Raje is a Cloud Architect on the AWS Professional Services India team. He specializes in DevOps, operational excellence, and automation using DevSecOps practices and infrastructure as code. Outside of work, he enjoys going on long drives with his beloved family, spending time with them, and watching movies.
Pranit Raje is a Cloud Architect on the AWS Professional Services India team. He specializes in DevOps, operational excellence, and automation using DevSecOps practices and infrastructure as code. Outside of work, he enjoys going on long drives with his beloved family, spending time with them, and watching movies.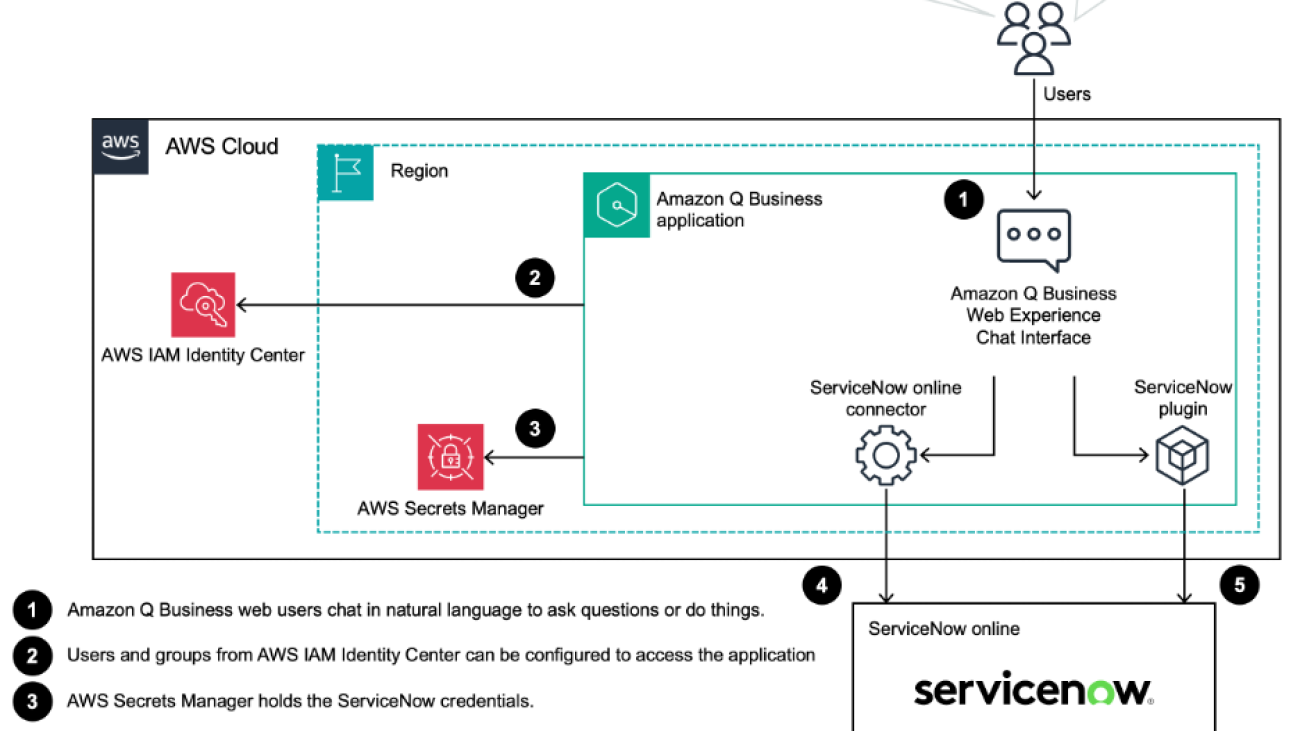































 Asif Fouzi is a Principal Solutions Architect leading a team of seasoned technologists supporting Global Service Integrators (GSI) such as Kyndryl in their cloud journey. When he is not innovating on behalf of users, he likes to play guitar, travel, and spend time with his family.
Asif Fouzi is a Principal Solutions Architect leading a team of seasoned technologists supporting Global Service Integrators (GSI) such as Kyndryl in their cloud journey. When he is not innovating on behalf of users, he likes to play guitar, travel, and spend time with his family.