Live video streams are continuously generated across industries including media and entertainment, retail, and many more. Live events like sports, music, news, and other special events are broadcast for viewers on TV and other online streaming platforms.
AWS customers increasingly rely on machine learning (ML) to generate actionable insights in real time and deliver an enhanced viewing experience or timely alert notifications. For example, AWS Sports explains how leagues, broadcasters, and partners can train teams, engage fans, and transform the business of sports with ML.
Amazon Rekognition makes it easy to add image and video analysis to your applications using proven, highly scalable, deep learning technology that requires no ML expertise to use. With Amazon Rekognition, you can identify objects, people, text, scenes, and some pre-defined activities in videos.
However, if you want to use your own video activity dataset and your own model or algorithm, you can use Amazon SageMaker. Amazon SageMaker is a fully managed service that allows you to build, train, and deploy ML models quickly. Amazon SageMaker removes the heavy lifting from each step of the ML process to make it easier to develop high-quality models.
In this post, you use Amazon SageMaker to automatically detect activities from a custom dataset in a live video stream.
The large volume of live video streams generated needs to be stored, processed in real time, and reviewed by a human team at low latency and low cost. Such pipelines include additional processing steps if specific activities are automatically detected in a video segment, such as penalty kicks in football triggering the generation of highlight clips for viewer replay.
ML inference on a live video stream can have the following challenges:
- Input source – The live stream video input must be segmented and made available in a data store for consumption with negligible latency.
- Large payload size – A video segment of 10 seconds can range from 1–15 MB. This is significantly larger than a typical tabular data record.
- Frame sampling – Video frames must be extracted at a sampling rate generally lesser than the original video FPS (frames per second) efficiently and without a loss in output accuracy.
- Frame preprocessing – Video frames must be preprocessed to reduce image size and resolution without a loss in output accuracy. They also need to be normalized across all the images used in training.
- External dependencies – External libraries like opencv and ffmpeg with different license types are generally used for image processing.
- 3D model network – Video models are typically 3D networks with an additional temporal dimension to image networks. They work on 5D input (batch size, time, RGB channel, height, width) and require a large volume of annotated input videos.
- Low latency, low cost – The output ML inference needs to be generated within an acceptable latency and at a low cost to demonstrate value.
This post describes two phases of a ML lifecycle. In the first phase, you build, train, and deploy a 3D video classification model on Amazon SageMaker. You fine-tune a pre-trained model with a ResNet50 backbone by transfer learning on another dataset and test inference on a sample video segment. The pre-trained model from a well-known model zoo reduces the need for large volumes of annotated input videos and can be adapted for tasks in another domain.
In the second phase, you deploy the fine-tuned model on an Amazon SageMaker endpoint in a production context of an end-to-end solution with a live video stream. The live video stream is simulated by a sample video in a continuous playback loop with AWS Elemental MediaLive. Video segments from the live stream are delivered to Amazon Simple Storage Service (Amazon S3), which invokes the Amazon SageMaker endpoint for inference. The inference payload is the Amazon S3 URI of the video segment. The use of the Amazon S3 URI is efficient because it eliminates the need to serialize and deserialize a large video frame payload over a REST API and transfers the responsibility of ingesting the video to the endpoint. The endpoint inference performs frame sampling and pre-processing followed by video segment classification, and outputs the result to Amazon DynamoDB.
Finally, the solution performance is summarized with respect to latency, throughput, and cost.
For the complete code associated with this post, see the GitHub repo.
Building, training, and deploying an activity detection model with Amazon SageMaker
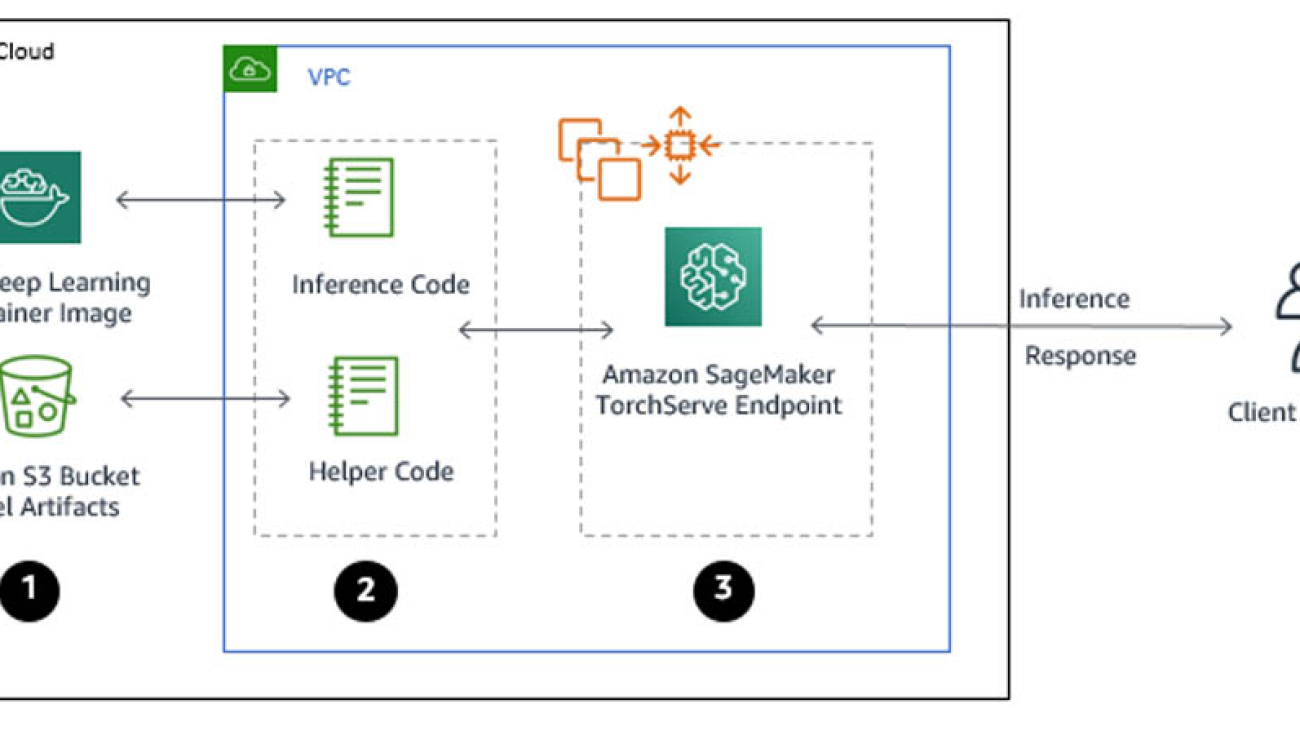
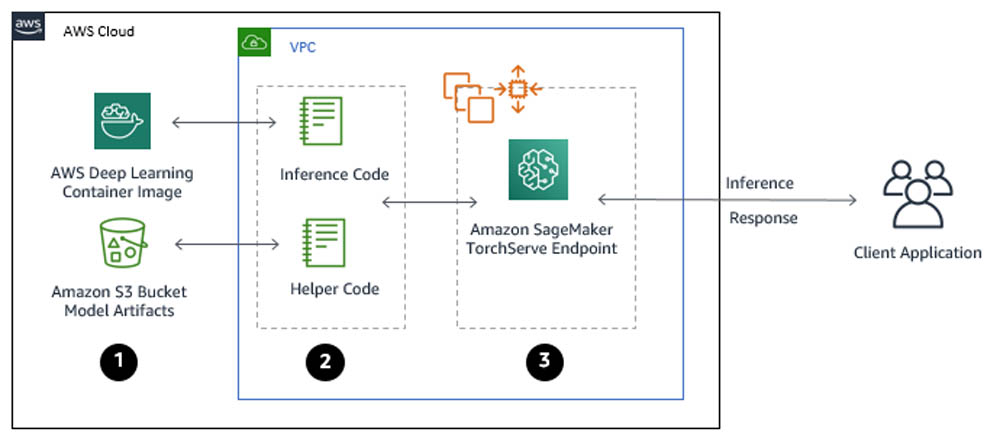
In this section, you use Amazon SageMaker to build, train, and deploy an activity detection model in a development environment. The following diagram depicts the Amazon SageMaker ML pipeline used to perform the end-to-end model development. The training and inference Docker images are available for any deep learning framework of choice, like TensorFlow, Pytorch, and MXNet. You use the “bring your own script” capability of Amazon SageMaker to provide a custom entrypoint script for training and inference. For this use case, you use transfer learning to fine-tune a pretrained model from a model zoo with another dataset loaded in Amazon S3. You use model artifacts from the training job to deploy an endpoint with automatic scaling, which dynamically adjusts the number of instances in response to changes in the invocation workload.

For this use case, you use two popular activity detection datasets: Kinetics400 and UCF101. Dataset size is a big factor in the performance of deep learning models. Kinetics400 has 306,245 short trimmed videos from 400 action categories. However, you may not have such a high volume of annotated videos in other domains. Training a deep learning model on small datasets from scratch may lead to severe overfitting, which is why you need transfer learning.
UCF101 has 13,320 videos from 101 action categories. For this post, we use UCF101 as a dataset from another domain for transfer learning. The pre-trained model is fine-tuned by replacing the last classification (dense) layer to the number of classes in the UCF101 dataset. The final test inference is run on new sample videos from Pexels that were unavailable during the training phase. Similarly, you can train good models on activity videos from your own domain without large annotated datasets and with less computing resource utilization.
We chose Apache MXNet as the deep learning framework for this use case because of the availability of the GluonCV toolkit. GluonCV provides implementations of state-of-the-art deep learning algorithms in computer vision. It features training scripts that reproduce state-of-the-art results reported in the latest research papers, a model zoo with a large set of pre-trained models, carefully designed APIs, and easy-to-understand implementations and community support. The action recognition model zoo contains multiple pre-trained models with the Kinetics400 dataset. The following graph shows the inference throughputs vs. validation accuracy and device memory footprint for each of them.

I3D (Inflated 3D Networks) and SlowFast are 3D video classification networks with varying trade-offs between accuracy and efficiency. For this post, we chose the Inflated 3D model (I3D) with ResNet50 backbone trained on the Kinetics400 dataset. It uses 3D convolution to learn spatiotemporal information directly from videos. The input to this model is of the form (N x C x T x H x W), where N is the batch size, C is the number of colour channels, T is the number of frames in the video segment, H is the height of the video frame, and W is the width of the video frame.
Both model training and inference require efficient and convenient slicing methods for video preprocessing. Decord provides such methods based on a thin wrapper on top of hardware accelerated video decoders. We use Decord as a video reader, and use VideoClsCustom as a custom GluonCV video data loader for pre-processing.
We launch the training script mode with the Amazon SageMaker MXNet training toolkit and the AWS Deep Learning container for training on Apache MXNet. The training process includes the following steps for the entire dataset:
- Frame sampling and center cropping
- Frame normalization with mean and standard deviation across all ImageNet images
- Transfer learning on the pre-trained model with a new dataset
After you have a trained model artifact, you can include it in a Docker container that runs your inference script and deploys to an Amazon SageMaker endpoint. Inference is launched with the Amazon SageMaker MXNet inference toolkit and the AWS Deep Learning container for inference on Apache MXNet. The inference process includes the following steps for the video segment payload:
- Pre-processing (similar to training)
- Activity classification
We use the Amazon Elastic Compute Cloud (Amazon EC2) G4 instance for our Amazon SageMaker endpoint hosting. G4 instances provide the latest generation NVIDIA T4 GPUs, AWS custom Intel Cascade Lake CPUs, up to 100 Gbps of networking throughput, and up to 1.8 TB of local NVMe storage. G4 instances are optimized for computer vision application deployments like image classification and object detection. For more information about inference benchmarks, see NVIDIA Data Center Deep Learning Product Performance.
We test the model inference deployed as an Amazon SageMaker endpoint using the following video examples (included in the code repository).
Output activity : TennisSwing
Note that the UCF101 dataset does not have a snowboarding activity class. The most similar activity present in the dataset is skiing and the model predicts skiing when evaluated with a snowboarding video.
You can find the complete Amazon SageMaker Jupyter notebook example with transfer learning and inference on the GitHub repo. After the model is trained, deployed to an Amazon SageMaker endpoint, and tested with the sample videos in the development environment, you can deploy it in a production context of an end-to-end solution.
Deploying the solution with AWS CloudFormation
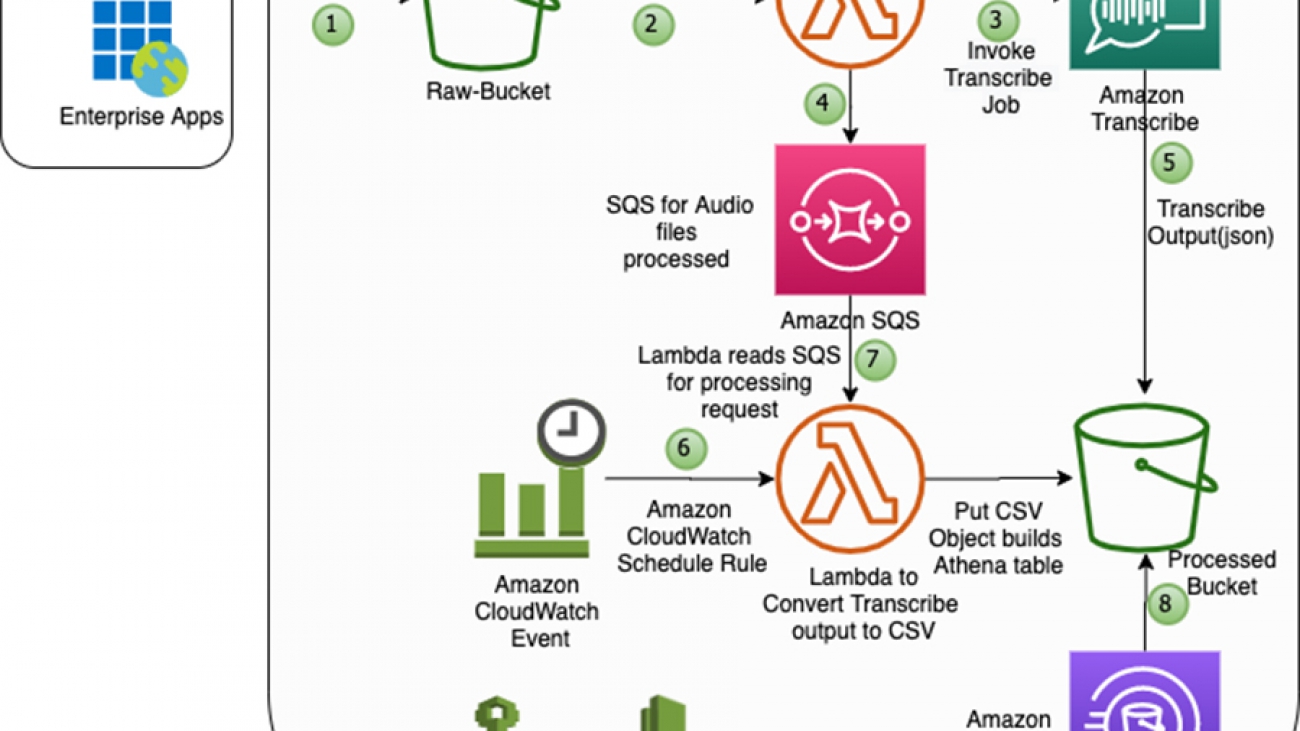
In this step, you deploy the end-to-end activity detection solution using an AWS CloudFormation template. After a successful deployment, you use the model to automatically detect an activity in a video segment from a live video stream. The following diagram depicts the roles of the AWS services in the solution.

The AWS Elemental MediaLive livestreaming channel that is created from a sample video file in S3 bucket is used to demonstrate the real-time architecture. You can use other live streaming services as well that are capable of delivering live video segments to S3.
- AWS Elemental MediaLive sends live video with HTTP Live Streaming (HLS) and regularly generates fragments of equal length (10 seconds) as .ts files and an index file that contains references of the fragmented files as a .m3u8 file in a S3 bucket.
- An upload of each video .ts fragment into the S3 bucket triggers a lambda function.
- The lambda function simply invokes a SageMaker endpoint for activity detection with the S3 URI of the video fragment as the REST API payload input.
- The SageMaker inference container reads the video from S3, pre-processes it, detects an activity and saves the prediction results to an Amazon DynamoDB table.
For this post, we use the sample Skiing People video to create the MediaLive live stream channel (also included in the code repository). In addition, the deployed model is the I3D model with Resnet50 backbone fine-tuned with the UCF101 dataset, as explained in the previous section. Autoscaling is enabled for the Amazon SageMaker endpoint to adjust the number of instances based on the actual workload.
The end-to-end solution example is provided in the GitHub repo. You can also use your own sample video and fine-tuned model.
There is a cost associated with deploying and running the solution, as mentioned in the Cost Estimation section of this post. Make sure to delete the CloudFormation stack if you no longer need it. The steps to delete the solution are detailed in the section Cleaning up.
You can deploy the solution by launching the CloudFormation stack:

The solution is deployed in the us-east-1 Region. For instructions on changing your Region, see the GitHub repo. After you launch the CloudFormation stack, you can update the parameters for your environments or leave the defaults. All their descriptions are provided when you launch it. Don’t create or select any other options in the configuration. In addition, don’t create or select an AWS Identity and Access Management (IAM) role on the Permissions tab. At the final page of the CloudFormation creation process, you need to select the two check-boxes under Capabilities. To create the AWS resources associated with the solution, you should have permissions to create CloudFormation stacks.
After you launch the stack, make sure that the root stack with its nested sub-stacks are successfully created by viewing the stack on the AWS CloudFormation console.

Wait until all the stacks are successfully created before you proceed to the next session. It takes 15–20 minutes to deploy the architecture.
The root CloudFormation stack ActivityDetectionCFN is mainly used to call the other nested sub-stacks and create the corresponding AWS resources.
The sub-stacks have the root stack name as their prefix. This is mainly to show that they are nested. In addition, the AWS Region name and account ID are added as suffices in the live stream S3 bucket name to avoid naming conflicts.
After the solution is successfully deployed, the following AWS resources are created:
- S3 bucket – The bucket
activity-detection-livestream-bucket-us-east-1-<account-id> stores video segments from the live video stream
- MediaLive channel – The channel
activity-detection-channel creates video segments from the live video stream and saves them to the S3 bucket
- Lambda function – The function
activity-detection-lambda invokes the Amazon SageMaker endpoint to detect activities from each video segment
- SageMaker endpoint – The
endpoint activity-detection-endpoint loads a video segment, detects an activity, and saves the results into a DynamoDB table
- DynamoDB table – The table
activity-detection-table stores the prediction results from the endpoint
Other supporting resources, like IAM roles, are also created to provide permissions to their respective resources.
Using the Solution
After the solution is successfully deployed, it’s time to test the model with a live video stream. You can start the channel on the MediaLive console.

Wait for the channel state to change to Running. When the channel state changes to Running, .ts-formatted video segments are saved into the live stream S3 bucket.

Only the most recent 21 video segments are kept in the S3 bucket to save storage. For more information about increasing the number of segments, see the GitHub repo.
Each .ts-formatted video upload triggers a Lambda function. The function invokes the Amazon SageMaker endpoint with an Amazon S3 URI to the .ts video as the payload. The deployed model predicts the activity and saves the results to the DynamoDB table.

Evaluating performance results
The Amazon SageMaker endpoint instance in this post is a ml.g4dn.2xlarge with 8 vCPU and 1 Nvidia T4 Tensor Core GPU. The solution generates one video segment every 10 seconds at 30 FPS. Therefore, there are six endpoint requests per minute (RPM). The overhead latency in video segment creation from the live stream up to delivery in Amazon S3 is approximately 1 second.
Amazon SageMaker supports automatic scaling for your hosted models. Autoscaling dynamically adjusts the number of instances provisioned for a model in response to changes in your workload. You can simulate a load test to determine the throughput of the system and the scaling policy for autoscaling in Amazon SageMaker. For the activity detection model in this post, a single ml.g4dn.2xlarge instance hosting the endpoint can handle 600 RPM with a latency of 300 milliseconds and with less than 5% number of HTTP errors. With a SAFETY_FACTOR = 0.5, the autoscaling target metric can be set as SageMakerVariantInvocationsPerInstance = 600 * 0.5 = 300 RPM.

For more information on load testing, see Load testing your autoscaling configuration.
Observe the differences between two scenarios under the same increasing load up to 1,700 invocations per minute in a period of 15 minutes. The BEFORE scenario is for a single instance without autoscaling, and the AFTER scenario is after two additional instances are launched by autoscaling.
The following graphs report the number of invocations and invocations per instance per minute. In the BEFORE scenario, with a single instance, both lines merge. In the AFTER scenario, the load pattern and Invocations (the blue line) are similar, but InvocationsPerInstance (the red line) is lower because the endpoint has scaled out.

The following graphs report average ModelLatency per minute. In the BEFORE scenario, the average latency remains under 300 milliseconds for the first 3 minutes of the test. The average ModelLatency exceeds 1 second after the endpoint gets more than 600 RPS and goes up to 8 seconds during peak load. In the AFTER scenario, the endpoint has already scaled to three instances and the average ModelLatency per minute remains close to 300 milliseconds.

The following graphs report the errors from the endpoint. In the BEFORE scenario, as the load exceeds 300 RPS, the endpoint starts to error out for some requests and increases as the number of invocations increase. In the AFTER scenario, the endpoint has scaled out already and reports no errors.

In the AFTER scenario, at peak load, average CPU utilization across instances is near maximum (100 % * 8 vcpu = 800 %) and average GPU utilization across instances is about 35%. To improve GPU utilization, additional effort can be made to optimize the CPU intensive pre-processing.

Cost Estimation
The following table summarizes the cost estimation for this solution. The cost includes the per hour pricing for one Amazon SageMaker endpoint instance of type ml.g4dn.2xlarge in the us-east-1 Region. If autoscaling is applied, the cost per hour includes the cost of the number of active instances. Also, MediaLive channel pricing is governed by the input and output configuration for the channel.
| Component |
Details |
Pricing (N.Virginia) |
Cost per hour |
| Elemental Media Live |
Single pipeline, On-Demand, SD |
$0.036 / hr input + $0.8496 / hr output |
$ 0.8856
|
| S3 |
30 mb per minute |
$0.023 per gb |
$ 0.0414 |
| Lambda |
Only invoke sm, minimum config (128 mb) |
$0.0000002083 per 100 ms |
$ 0.00007
|
| SageMaker endpoint |
(ml.g4dn.2xlarge) single instance |
$1.053 per hour |
$1.053 |
| DynamoDB |
|
$1.25 per million write request units |
$ 0.0015 |
Cleaning up
If you no longer need the solution, complete the following steps to properly delete all the associated AWS resources:
- On the MediaLive console, stop the live stream channel.
- On the Amazon S3 console, delete the S3 bucket you created earlier.
- On the AWS CloudFormation console, delete the root
ActivityDetectionCFN This also removes all nested sub-stacks.
Conclusion
In this post, you used Amazon SageMaker to automatically detect activity in a simulated live video stream. You used a pre-trained model from the gluon-cv model zoo and Apache MXNet framework for transfer learning on another dataset. You also used Amazon SageMaker inference to preprocess and classify a video segment delivered to Amazon S3. Finally, you evaluated the solution respect to model latency, system throughput, and cost.
About the Authors
 Hasan Poonawala is a Machine Learning Specialist Solution Architect at AWS, based in London, UK. Hasan helps customers design and deploy machine learning applications in production on AWS. He is passionate about the use of machine learning to solve business problems across various industries. In his spare time, Hasan loves to explore nature outdoors and spend time with friends and family.
Hasan Poonawala is a Machine Learning Specialist Solution Architect at AWS, based in London, UK. Hasan helps customers design and deploy machine learning applications in production on AWS. He is passionate about the use of machine learning to solve business problems across various industries. In his spare time, Hasan loves to explore nature outdoors and spend time with friends and family.
 Tesfagabir Meharizghi is a Data Scientist at the Amazon ML Solutions Lab where he works with customers across different verticals accelerate their use of machine learning and AWS cloud services to solve their business challenges. Outside of work, he enjoys spending time with his family and reading books.
Tesfagabir Meharizghi is a Data Scientist at the Amazon ML Solutions Lab where he works with customers across different verticals accelerate their use of machine learning and AWS cloud services to solve their business challenges. Outside of work, he enjoys spending time with his family and reading books.
Read More




 As a Principal Solutions Architect, Todd spends his time working with strategic and global customers to define business requirements, provide architectural guidance around specific use cases, and design applications and services that are scalable, reliable, and performant. He has helped launch and scale the reinforcement learning powered AWS DeepRacer service, is a host for the AWS video series “This is My Architecture”, and speaks regularly at AWS re:Invent, AWS Summits, and technology conferences around the world.
As a Principal Solutions Architect, Todd spends his time working with strategic and global customers to define business requirements, provide architectural guidance around specific use cases, and design applications and services that are scalable, reliable, and performant. He has helped launch and scale the reinforcement learning powered AWS DeepRacer service, is a host for the AWS video series “This is My Architecture”, and speaks regularly at AWS re:Invent, AWS Summits, and technology conferences around the world.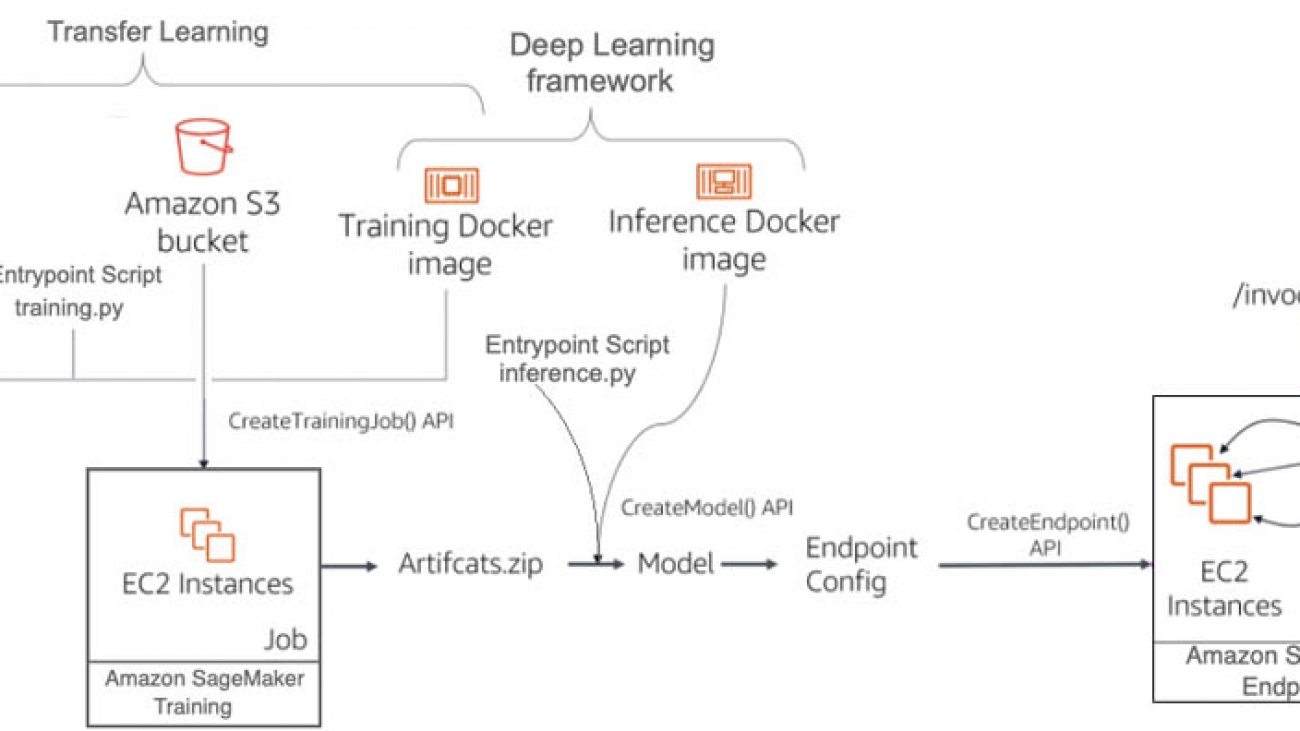


 Rajarao Vijjapu is a data architect with AWS. He works with AWS customers and partners to provide guidance and technical assistance about Big Data, Analytics, AI/ML and Security projects, helping them improve the value of their solutions when using AWS.
Rajarao Vijjapu is a data architect with AWS. He works with AWS customers and partners to provide guidance and technical assistance about Big Data, Analytics, AI/ML and Security projects, helping them improve the value of their solutions when using AWS.



 Paloma Pineda is a Product Marketing Manager for AWS Artificial Intelligence Devices. She is passionate about the intersection of technology, art, and human centered design. Out of the office, Paloma enjoys photography, watching foreign films, and cooking French cuisine.
Paloma Pineda is a Product Marketing Manager for AWS Artificial Intelligence Devices. She is passionate about the intersection of technology, art, and human centered design. Out of the office, Paloma enjoys photography, watching foreign films, and cooking French cuisine.
 Vaibhav Sethi is the Product Manager for Amazon Personalize. He focuses on delivering products that make it easier to build machine learning solutions. In his spare time, he enjoys hiking and reading.
Vaibhav Sethi is the Product Manager for Amazon Personalize. He focuses on delivering products that make it easier to build machine learning solutions. In his spare time, he enjoys hiking and reading.

 Vadim Dabravolski is AI/ML Solutions Architect with FinServe team. He is focused on Computer Vision and NLP technologies and how to apply them to business use cases. After hours Vadim enjoys jogging in NYC boroughs, reading non-fiction (business, history, culture, politics, you name it), and rarely just doing nothing.
Vadim Dabravolski is AI/ML Solutions Architect with FinServe team. He is focused on Computer Vision and NLP technologies and how to apply them to business use cases. After hours Vadim enjoys jogging in NYC boroughs, reading non-fiction (business, history, culture, politics, you name it), and rarely just doing nothing. Corey Barrett is a Data Scientist in the Amazon ML Solutions Lab. As a member of the ML Solutions Lab, he leverages Machine Learning and Deep Learning to solve critical business problems for AWS customers. Outside of work, you can find him enjoying the outdoors, sipping on scotch, and spending time with his family.
Corey Barrett is a Data Scientist in the Amazon ML Solutions Lab. As a member of the ML Solutions Lab, he leverages Machine Learning and Deep Learning to solve critical business problems for AWS customers. Outside of work, you can find him enjoying the outdoors, sipping on scotch, and spending time with his family. Chaitanya Bapat is a Software Engineer with the AWS Deep Learning team. He works on Apache MXNet and integrating the framework with Amazon Sagemaker, DLC and DLAMI. In his spare time, he loves watching sports and enjoys reading books and learning Spanish.
Chaitanya Bapat is a Software Engineer with the AWS Deep Learning team. He works on Apache MXNet and integrating the framework with Amazon Sagemaker, DLC and DLAMI. In his spare time, he loves watching sports and enjoys reading books and learning Spanish. Karan Jariwala is a Software Development Engineer on the AWS Deep Learning team. His work focuses on training deep neural networks. Outside of work, he enjoys hiking, swimming, and playing tennis.
Karan Jariwala is a Software Development Engineer on the AWS Deep Learning team. His work focuses on training deep neural networks. Outside of work, he enjoys hiking, swimming, and playing tennis.