20tree.ai is on a mission to help protect the Earth’s forests by providing data-driven and actionable planet intelligence.Read More
How some of AWS’s most innovative customers are using computer vision technologies
From counting fish to identifying touchdowns, AWS customers are utilizing computer vision and pattern recognition technologies to improve business processes and customer experiences.Read More
Sizing neural networks to the available hardware
A new approach to determining the “channel configuration” of convolutional neural nets improves accuracy while maintaining runtime efficiency.Read More
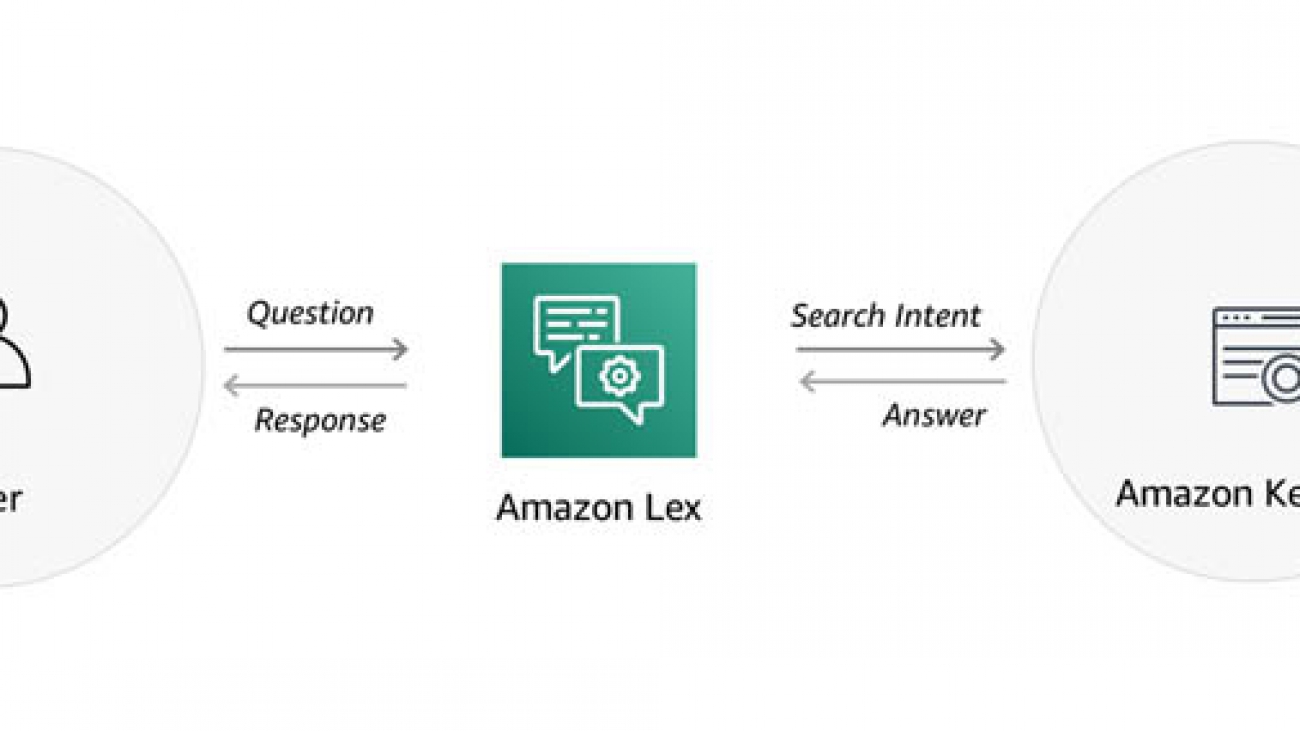
Integrate Amazon Kendra and Amazon Lex using a search intent
Customer service conversations typically revolve around one or more topics and contain related questions. Answering these questions seamlessly is essential for a good conversational experience. For example, as part of a car rental reservation, you have queries such as, “What’s the charge for an additional driver?” or, “Do you have car seats for kids?” Starting today, you can use a search intent in your Amazon Lex bots to integrate with Amazon Kendra, so your bots can surface answers from Kendra.
Amazon Kendra was recently made generally available to all AWS customers, with exciting new features. Amazon Kendra provides you with a highly accurate and easy-to-use enterprise search service powered by machine learning. It offers a more intuitive way to search—using natural language—and returns more accurate answers, so your end-users can discover information stored within your organization’s vast amount of content.
We previously described how you can add an AWS Lambda function in an Amazon Lex bot to integrate with Kendra. For more information, see Smarter FAQ bots with Amazon Kendra. With this approach, you need to write and maintain integration code, and any updates to the configuration require updating this code. Now you can can add a search intent to get the answers you’re looking for from FAQ documents. You simply define the search index parameters in the intent as part of the bot definition. The bot queries the Amazon Kendra search index during the interaction if the user input doesn’t match any of the other configured intents. The search query responses are populated with request attributes that the bot can use in its response. You don’t have to write any Lambda code. The integration is simple, and you can seamlessly deliver natural language answers from Amazon Kendra in your Amazon Lex conversations.
This post shows how you can integrate an Amazon Lex bot with Amazon Kendra using a search intent, so you can quickly build a bot to provide answers in a conversation. The following diagram illustrates this solution.
Building a Lex bot
We will use the same conversation from the previous post to model a bot conversation:
User: Where’s the IT Help Desk?
Agent: 2nd floor; room 201 (two rights after you get out of the elevators).
User: Can I come in at noon?
Agent: Sure. What’s the nature of your problem?
User: I have a cracked laptop screen.
Agent: For verification purposes, can I get the last four digits of your employee ID?
User: 1234.
Agent: Got it, we’ll see you then to take a look at your screen.
User: How long does it take to fix a screen?
Agent: Laptop screen repairs typically take 4 hours.
User: What do I need to bring with me for a screen repair?
Agent: For a laptop screen repair, please bring your employee badge, laptop, and VPN fob.
User: How do I access my documents while my laptop is being repaired?
Agent: You can use Amazon Workdocs to access your documents.
User: Can I use WorkDocs on my tablet?
Agent: Yes. Users can access Amazon WorkDocs using free applications for iPad, Kindle Fire, and Android tablets that you can download from iTunes, Amazon Appstore for Android, and Google Play. Users can also access Amazon WorkDocs using the web browser on any mobile device.
User: When does the help desk close?
Agent: Our hours are from 11 AM to 2 PM.
User: Is there a coffee shop nearby?
Agent: There is one on the third floor and it’s open from 8 AM to 4 PM daily.
The first step is to build an Amazon Lex bot with intents to book an appointment and check appointment status. The MakeAppointment intent elicits the information required to make an appointment, such as the date, time, employee ID, and the nature of the issue. The CheckAppointmentStatus intent provides the status of the appointment. When a user asks a question that the Lex bot can’t answer with these intents, it uses the built-in KendraSearchIntent intent to connect to Amazon Kendra to search for an appropriate answer.
Deploying the sample bot
To create the sample bot, complete the following steps. This creates an Amazon Lex bot called help_desk_bot and a Lambda fulfillment function called help_desk_bot_handler.
- Download the Amazon Lex definition and Lambda code.
- In the AWS Lambda console, choose Create function.
- Enter the function name
help_desk_bot_handler. - Choose the latest Python runtime (for example, Python 3.8).
- For Permissions, choose Create a new role with basic Lambda permissions.
- Choose Create function.
- Once your new Lambda function is available, in the Function code section, choose Actions, choose Upload a .zip file, choose Upload, and select the
help_desk_bot_lambda_handler.zipfile that you downloaded. - Choose Save.
- On the Amazon Lex console, choose Actions, and then Import.
- Choose the file
help_desk_bot.zipthat you downloaded, and choose Import. - On the Amazon Lex console, choose the bot
help_desk_bot. - For each of the intents, choose AWS Lambda function in the Fulfillment section, and select the
help_desk_bot_handlerfunction in the dropdown list. If you are prompted “You are about to give Amazon Lex permission to invoke your Lambda Function”, choose OK. - When all the intents are updated, choose Build.
At this point, you should have a working bot that is not yet connected to Amazon Kendra.
Creating an Amazon Kendra index
You’re now ready to create an Amazon Kendra index for your documents and FAQ. Complete the following steps:
- On the Amazon Kendra console, choose Launch Amazon Kendra.
- If you have existing Amazon Kendra indexes, choose Create index.
- For Index name, enter a name, such as
it-helpdesk. - For Description, enter an optional description, such as
IT Help Desk FAQs. - For IAM role, choose Create a new role to create a role to allow Amazon Kendra to access Amazon CloudWatch Logs.
- For Role name, enter a name, such as
cloudwatch-logs. Kendra will prefix the name withAmazonKendraand the AWS region. - Choose Next.

- For Provisioning editions, choose Developer edition.

- Choose Create.
Adding your FAQ content
While Amazon Kendra creates your new index, upload your content to an Amazon Simple Storage Service (Amazon S3) bucket.
- On the Amazon S3 console, create a new bucket, such as
kendra-it-helpdesk-docs-<your-account#>. - Keep the default settings and choose Create bucket.
- Download the following sample files and upload them to your new S3 bucket:
When the index creation is complete, you can add your FAQ content.
- On the Amazon Kendra console, choose your index, then choose FAQs, and Add FAQ.
- For FAQ name, enter a name, such as
it-helpdesk-faq. - For Description, enter an optional description, such as
FAQ for the IT Help Desk. - For S3, browse Amazon S3 to find your bucket, and choose help-desk-faq.csv.
- For IAM role, choose Create a new role to allow Amazon Kendra to access your S3 bucket.
- For Role name, enter a name, such as
s3-access. Kendra will prefix your role name withAmazonKendra-. - Choose Add.

- Stay on the page while Amazon Kendra creates your FAQ.
- When the FAQ is complete, choose Add FAQ to add another FAQ.
- For FAQ name, enter a name, such as
workdocs-faq. - For Description, enter a description, such as
FAQ for Amazon WorkDocsmobile and web access. - For S3, browse Amazon S3 to find your bucket, and choose workdocs-faq.csv.
- For IAM role, choose the same role you created in step 9.
- Choose Add.

After you create your FAQs, you can try some Kendra searches by choosing Search console. For example:
- When is the help desk open?
- When does the help desk close?
- Where is the help desk?
- Can I access WorkDocs from my phone?
Adding a search intent
Now that you have a working Amazon Kendra index, you need to add a search intent.
- On the Amazon Lex console, choose
help_desk_bot. - Under Intents, choose the + icon next to add an intent.
- Choose Search existing intents.
- Under Built-in intents, choose KendraSearchIntent.
- Enter a name for your intent, such as
help_desk_kendra_search. - Choose Add.
- Under Amazon Kendra query, choose the index you created (
it-helpdesk). - For IAM role, choose Add Amazon Kendra permissions.
- For Fulfillment, leave the default value Return parameters to client selected.

- For Response, choose Message, enter the following message value and choose + to add it:
((x-amz-lex:kendra-search-response-question_answer-answer-1)) - Choose Save intent.
- Choose Build.
The message value you used in step 10 is a request attribute, which is set automatically by the Amazon Kendra search intent. This response is only selected if Kendra surfaces an answer. For more information on request attributes, see the AMAZON.KendraSearchIntent documentation.
Your bot can now execute Amazon Kendra queries. You can test this on the Amazon Lex console. For example, you can try the sample conversation from the beginning of this post.
Deploying on a Slack channel
You can put this solution in a real chat environment, such as Slack, so that users can easily get information. To create a Slack channel association with your bot, complete the following steps:
- On the Amazon Lex console, choose Settings.
- Choose Publish.
- For Create an alias, enter an alias name, such as
test. - Choose Publish.
- When your alias is published, choose the Channels
- Under Channels, choose Slack.
- Enter a Channel Name, such as
slack_help_desk_bot. - For Channel Description, add an optional description.
- From the KMS Key drop-down menu, leave aws/lex selected.
- For Alias, choose
test. - Provide the Client Id, Client Secret, and Verification Token for your Slack application.

- Choose Activate to generate the OAuth URL and Postback URL.
Use the OAuth URL and Postback URL on the Slack application portal to complete the integration. For more information about setting up a Slack application and integrating with Amazon Lex, see Integrating an Amazon Lex Bot with Slack.
Conclusion
This post demonstrates how to integrate Amazon Lex and Amazon Kendra using a search intent. Amazon Kendra can extract specific answers from unstructured data. No pre-training is required; you simply point Amazon Kendra at your content, and it provides specific answers to natural language queries. For more information about incorporating these techniques into your bots, please see the AMAZON.KendraSearchIntent documentation.
About the authors
 Brian Yost is a Senior Consultant with the AWS Professional Services Conversational AI team. In his spare time, he enjoys mountain biking, home brewing, and tinkering with technology.
Brian Yost is a Senior Consultant with the AWS Professional Services Conversational AI team. In his spare time, he enjoys mountain biking, home brewing, and tinkering with technology.
 As a Product Manager on the Amazon Lex team, Harshal Pimpalkhute spends his time trying to get machines to engage (nicely) with humans.
As a Product Manager on the Amazon Lex team, Harshal Pimpalkhute spends his time trying to get machines to engage (nicely) with humans.
2019 Amazon Research Awards recipients announcement
Earlier this year, Amazon notified grant applicants who were recipients of the 2019 Amazon Research Awards.Read More
Michael J. Black awarded CVPR “test of time” honor
Black, a distinguished Amazon scholar, has been awarded the Longuet-Higgins Prize. Award recognizes paper that has made a significant impact in computer vision research field.Read More
Detecting and visualizing telecom network outages from tweets with Amazon Comprehend
In today’s world, social media has become a place where customers share their experiences with services that they consume. Every telecom provider wants to have the ability to understand their customer pain points as soon as possible and to do this carriers frequently establish a social media team within their NOC (network operation center). This team manually reviews social media messages, such as tweets, trying to identify patterns of customer complaints or issues that might suggest that there is a specific problem in the carrier’s network .
Unhappy customers are more likely to change provider, so operators look to improve their customers’ experience and proactively approach dissatisfied customers who are reporting issues with their services .
Of course, social media operates at a vast scale and our telecom customers are telling us that trying to uncover customer issues from social media data manually is extremely challenging.
This post shows how to classify tweets in real time so telecom companies can identify outages and proactively engage with customers by using Amazon Comprehend custom multi-class classification.
Solution overview
Telecom customers not only post about outages on social media, but also comment on the service they get or compare the company to a competitor.
Your company can benefit from targeting those types of tweets separately. One option is customer feedback, in which care agents respond to the customer. For outages, you need to collect information and open a ticket in an external system so an engineer can specify the problem.
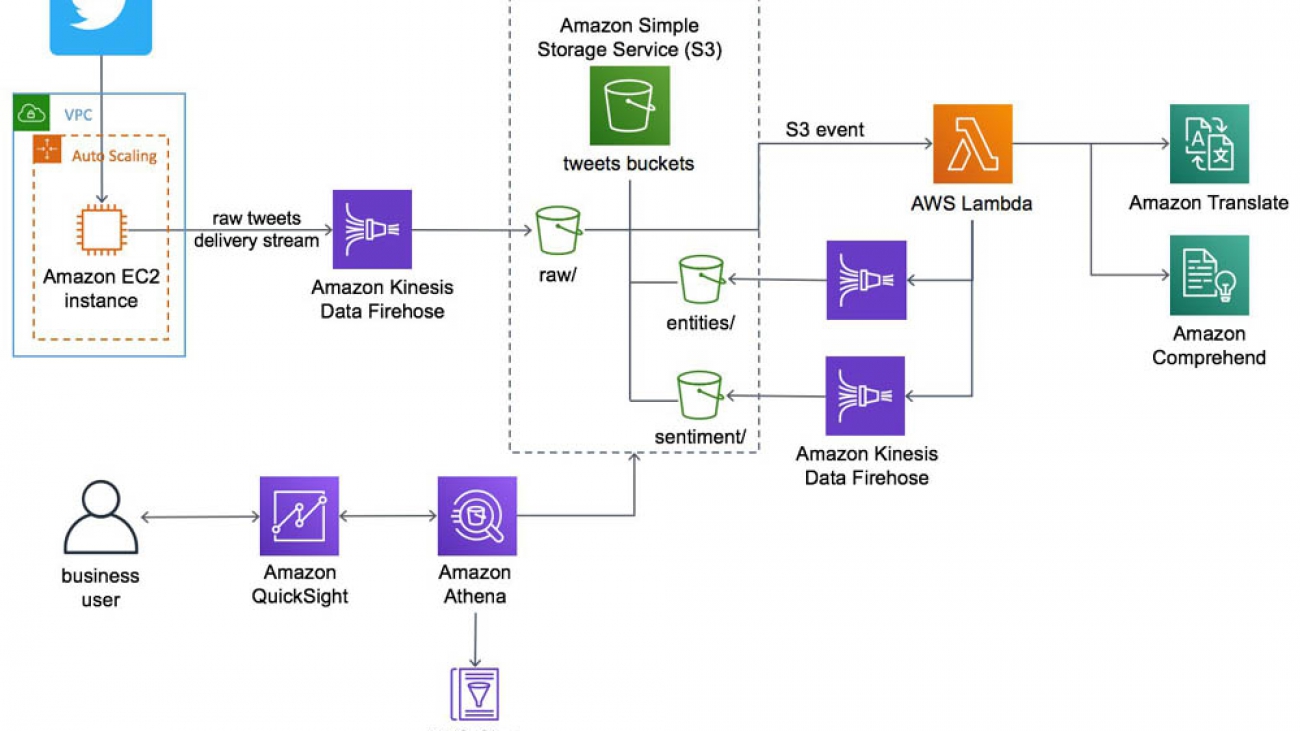
The solution for this post extends the AI-Driven Social Media Dashboard solution. The following diagram illustrates the solution architecture.

AI-Driven Social Media Dashboard Solutions Implementation architecture
This solution deploys an Amazon Elastic Compute Cloud (Amazon EC2) instance running in an Amazon Virtual Private Cloud (Amazon VPC) that ingests tweets from Twitter. An Amazon Kinesis Data Firehose delivery stream loads the streaming tweets into the raw prefix in the solution’s Amazon Simple Storage Service (Amazon S3) bucket. Amazon S3 invokes an AWS Lambda function to analyze the raw tweets using Amazon Translate to translate non-English tweets into English, and Amazon Comprehend to use natural-language-processing (NLP) to perform entity extraction and sentiment analysis.
A second Kinesis Data Firehose delivery stream loads the translated tweets and sentiment values into the sentiment prefix in the Amazon S3 bucket. A third delivery stream loads entities in the entities prefix using in the Amazon S3 bucket.
The solution also deploys a data lake that includes AWS Glue for data transformation, Amazon Athena for data analysis, and Amazon QuickSight for data visualization. AWS Glue Data Catalog contains a logical database which is used to organize the tables for the data on Amazon S3. Athena uses these table definitions to query the data stored on Amazon S3 and return the information to an Amazon QuickSight dashboard.
You can extend this solution by building Amazon Comprehend custom classification to detect outages, customer feedback, and comparisons to competitors.
Creating the dataset
The solution uses raw data from tweets. In the original solution, you deploy an AWS CloudFormation template that defines a comma-delimited list of terms for the solution to monitor. As an example, this post focuses on tweets that contain the word “BT” (BT Group in the UK), but equally this could be any network provider.
To get started, launch the AI-driven Social Media Dashboard solution. On the Specify Stack Details page, replace the default TwitterTermList with your terms. For this example, 'BT','bt'. After you click on Create Stack, wait 15 minutes for the deployment to complete. You will now begin capturing tweets.
For more information about available attributes and data types, see Appendix B: Auto-generated Data Model.
The tweet data is stored in Amazon Simple Storage Service (Amazon S3), which you can query with Amazon Athena. The following screenshot shows an example query.
SELECT id,text FROM "ai_driven_social_media_dashboard"."tweets" limit 10;
Because you captured every tweet that contains the keyword BT or bt, you have a lot of tweets that aren’t referring to British Telecom; for example, tweets that misspell the word “but.”
Additionally, the tweets in your dataset are global, but for this post, you want to focus on the United Kingdom, so the tweets are even more likely to refer to British Telecom (and therefore your dataset is more accurate). You can modify this solution for use cases in other countries, for example, defining the keyword as KPN and narrowing the dataset to focus only on the Netherlands.
In the existing solution, the coordinates and geo types look relevant, but those usually aren’t populated—tweets don’t include the poster’s location by default due to privacy requirements, unless the user allows it.
The user type contains relevant user data that comes from the user profile. You can use the location data from the user profile to narrow down tweets to your target country or region.
To look at the user type, you can use the Athena CREATE TABLE AS SELECT (CTAS) query. For more information, see Creating a Table from Query Results (CTAS). The following screenshot shows the Create table from query option in the Create drop-down menu.
SELECT text,user.location from tweets
You can create a table that consists of the tweet text and the user location, which gives you the ability to look only at tweets that originated in the UK. The following screenshot shows the query results.
SELECT * FROM "ai_driven_social_media_dashboard"."location_text_02"
WHERE location like '%UK%' or location like '%England%' or location like '%Scotland%' or location like '%Wales%'
Now that you have a dataset with your target location and tweet keywords, you can train your custom classifier.
Amazon Comprehend custom classification
You train your model in multi-class mode. For this post, you label three different classes:
- Outage – People who are experiencing or reporting an outage in their provider network
- Customer feedback – Feedback regarding the service they have received from the provider
- Competition – Tweets about the competition and the provider itself
You can export the dataset from Athena and train it to use the custom classifier.
You first look at the dataset and start labeling the different tweets. Because you have a large number of tweets, it can take manual effort and perhaps several hours to review the data and label it. We recommend that you train the model with at least 50 documents per label.
In the dataset, customers reported an outage, which resulted in 71 documents with the outage label. Competition and customer feedback had under 50 labels.
After you gather sufficient data, you can always improve your accuracy by training a new model.
The following screenshot shows some of the entries in the final training CSV file.

As a future enhancement to remove the manual effort of labeling tweets, you can automate the process with Amazon SageMaker Ground Truth. Ground Truth offers easy access to labelers through Amazon Mechanical Turk and provides built-in workflows and interfaces for common labeling tasks.
When the labeling work is complete, upload the CSV file to your S3 bucket.

Now that the training data is in Amazon S3, you can train your custom classifier. Complete the following steps:
- On the Amazon Comprehend console, choose Custom classification.
- Choose Train classifier.

- For Name, enter a name for your classifier; for example,
TweetsBT. - For Classifier mode, select Using multi-class mode.
- For S3 location, enter the location of your CSV file.

- Choose Train classifier.
The status of the classifier changes from Submitted to Training. When the job is finished, the status changes to Trained.
After you train the custom classifier, you can analyze documents in either asynchronous or synchronous operations. You can analyze a large number of documents at the same time by using the asynchronous operation. The resulting analysis returns in a separate file. When you use the synchronous operation, you can only analyze a single document, but you can get results in real time.
For this use case, you want to analyze tweets in real time. When a tweet lands in Amazon S3 via Amazon Kinesis Data Firehose, it triggers an AWS Lambda function. The function triggers the custom classifier endpoint to run an analysis on the tweet and determine if it’s in regards to an outage, customer feedback, or referring to a competitor.
Testing the training data
After you train the model, Amazon Comprehend uses approximately 10% of the training documents to test the custom classifier model. Testing the model provides you with metrics that you can use to determine if the model is trained well enough for your purposes. These metrics are displayed in the Classifier performance section of the Classifier details page on the Amazon Comprehend console. See the following screenshot.

They’re also returned in the Metrics fields returned by the DescribeDocumentClassifier operation.
Creating an endpoint
To create an endpoint, complete the following steps:
- On the Amazon Comprehend console, choose Custom classification.
- From the Actions drop-down menu, choose Create endpoint.

- For Endpoint name, enter a name; for example,
BTtweetsEndpoint. - For Inference units¸ enter the number to assign to an endpoint.
Each unit represents a throughput of 100 characters per second for up to two documents per second. You can assign up to 10 inference units per endpoint. This post assigns 1.
- Choose Create endpoint.

When the endpoint is ready, the status changes to Ready.

Triggering the endpoint and customizing the existing Lambda function
You can use the existing Lambda function from the original solution and extend it to do the following:
- Trigger the Amazon Comprehend custom classifier endpoint per tweet
- Determine which class has the highest confidence score
- Create an additional Firehose delivery stream so the results land back in Amazon S3
For more information about the original Lambda function, see the GitHub repo.
To make the necessary changes to the function, complete the following steps:
- On the Lambda console, select the function that contains the string Tweet-SocialMediaAnalyticsLambda.

Before you start adding code, make sure you understand how the function reads the tweets coming in, calls the Amazon Comprehend API, and stores the responses on a Firehose delivery stream so it writes the data to Amazon S3.
- Call the custom classifier endpoint (see the following code example).
The first two calls use the API on the tweet text to detect sentiment and entities; those both come out-of-the-box with the officinal solution.
The following code uses the ClassifyDocument API:
sentiment_response = comprehend.detect_sentiment(
Text=comprehend_text,
LanguageCode='en'
)
#print(sentiment_response)
entities_response = comprehend.detect_entities(
Text=comprehend_text,
LanguageCode='en'
)
#we will create a 'custom_response' using the ClassifyDocument API call
custom_response = comprehend.classify_document(
#point to the relevant Custom classifier endpoint ARN
EndpointArn= "arn:aws:comprehend:us-east-1:12xxxxxxx91:document-classifier-endpoint/BTtweets-endpoint",
#this is where we use comprehend_text which is the original tweet text
Text=comprehend_text
)
The following code is the returned result:
{"File": "all_tweets.csv", "Line": "23", "Classes": [{"Name": "outage", "Score": 0.9985}, {"Name": "Competition", "Score": 0.0005}, {"Name": "Customer feedback", "Score": 0.0005}]}You now need to iterate over to the array, which contains the classes and confidence scores. For more information, see DocumentClass.
Because you’re using the multi-class approach, you can pick the class with the highest score and add some simple code that iterates over the array and takes the biggest score and class.
You also take tweet[‘id’] because you can join it with the other tables that the solution generates to relate the results to the original tweet.
- Enter the following code:
score=0 for classs in custom_response['Classes']: if score<classs['Score']: score=classs['Score'] custom_record = { 'tweetid': tweet['id'], 'classname':classs['Name'], 'classscore':classs['Score'] }
After you create the custom_record, you can decide if you want to define a certain threshold for your class score (the level of confidence for the results you want to store in Amazon S3). For this use case, you choose to only define classes with a confidence score of at least 70%.
To put the result on a Firehose delivery stream (which you need to create in advance), use the PutRecord API. See the following code:
if custom_record['classscore']>0.7:
print('we are in')
response = firehose.put_record(
DeliveryStreamName=os.environ['CUSTOM_STREAM'],
Record={
'Data': json.dumps(custom_record) + 'n'
}
)You now have a dataset in Amazon S3 based on your Amazon Comprehend custom classifier output.
Exploring the output
You can now explore the output from your custom classifier in Athena. Complete the following steps:
- On the Athena console, run a
SELECTquery to see the following:- tweetid – You can use this to join the original tweet table to get the tweet text and additional attributes.
- classname – This is the class that the custom classifier identified the tweet as with the highest level of confidence.
- classscore – This is the level of confidence.
- Stream partitions – These help you know the time when the data was written to Amazon S3:
Partition_0(month)Partition_1(day)Partition_2(hour)
The following screenshot shows your query results.
SELECT * FROM "ai_driven_social_media_dashboard"."custom2020" where classscore>0.7 limit 10;

- Join your table using the
tweetidwith the following:- The original tweet table to get the actual tweet text.
- A sentiment table that Amazon Comprehend generated in the original solution.
The following screenshot shows your results. One of the tweets contains negative feedback, and other tweets identify potential outages.
SELECT classname,classscore,tweets.text,sentiment FROM "ai_driven_social_media_dashboard"."custom2020"
left outer join tweets on custom2020.tweetid=tweets.id
left outer join tweet_sentiments on custom2020.tweetid=tweet_sentiments.tweetid
where classscore>0.7
limit 10;
Preparing the data for visualization
To prepare the data for visualization, first create a timestamp field by concatenating the partition fields.
You can use timestamp field for various visualizations, such as outages in a certain period or customer feedback on a specific day. To do so, use AWS Glue notebooks and write a piece of code in PySpark.
You can use the PySpark code to not only prepare your data but also transform the data from CSV to Apache Parquet format. For more information, see the GitHub repo.
You should now have a new dataset that contains a timestamp field in Parquet format, which is more efficient and cost-effective to query.
For this use case, you can determine the outages reported on a map using geospacial charts in Amazon QuickSight. To get the location of the tweet, you can use the following:
- Longitude and latitude coordinates in the original
tweetsdataset. Unfortunately, coordinates aren’t usually present due to privacy defaults. - Amazon Comprehend
entitydataset, which can identify locations as entities within the tweet text.
For this use case, you can create a new dataset combining the tweets, custom2020 (your new dataset based on the custom classifier output, and tweetsEntities datasets.
The following screenshot shows the query results, which returned tweets with locations that also identify outages.
SELECT distinct classname,final,text,entity FROM "ai_driven_social_media_dashb
oard"."custom2020"."quicksight_with_lat_lang"
where type='LOCATION' and classname='outage'
order by final asc 
You have successfully identified outages in a specific window and determined their location.
To get the geolocation of a specific location, you could choose from a variety of publicly available datasets to upload to Amazon S3 and join with your data. This post uses the World Cities Database, which has a free option. You can join it with your existing data to get the location coordinates.
Visualizing outage locations in Amazon QuickSight
To visualize your outage locations in Amazon QuickSight, complete the following steps:
- To add the dataset you created in Athena, on the Amazon QuickSight console, choose Manage data.
- Choose New dataset.
- Choose Athena.
- Select your database or table.

- Choose Save & Visualize.
- Under Visual types, choose the Points on map
- Drag the lng and lat fields to the field wells.
The following screenshot shows the outages on a UK map.

To see the text of a specific tweet, hover over one of the dots on the map.

You have many different options when analyzing your data and can further enhance this solution. For example, you can enrich your dataset with potential contributors and drill down on a specific outage location for more details.
Conclusion
We have now the ability to detect outages which customers are reporting upon, we can also leverage the solution to look on customer feedback and competition. We are now able to identify key trends on the social media at scale. In the blog post we have showed an example which is relevant for telecom companies, but this solution can be customized and leveraged by every company that has customers using the social media.
In the near feature, we would like to extend this solution, and create an end to end flow , where the customer reporting an outage ,will automatically receive a reply in tweeter from an Amazon Lex chat bot, which can ask for more information from the customer who complained via a secured channel and send this info to a call center agent via an integration with Amazon Connect or create a ticket in an external ticket system for an engineer to work on the problem .
Give the solution a try, see if you can extend it further, and share your feedback and questions in the comments.
About the Author
 Guy Ben-Baruch is a Senior solution architect in the news & communications team in AWS UKIR. Since Guy joined AWS in March 2016, he has worked closely with enterprise customers, focusing on the telecom vertical, supporting their digital transformation and their cloud adoption. Outside of work, Guy likes doing BBQ and playing football with his kids in the park when the British weather allows it.
Guy Ben-Baruch is a Senior solution architect in the news & communications team in AWS UKIR. Since Guy joined AWS in March 2016, he has worked closely with enterprise customers, focusing on the telecom vertical, supporting their digital transformation and their cloud adoption. Outside of work, Guy likes doing BBQ and playing football with his kids in the park when the British weather allows it.
Amazon Polly launches a child US English NTTS voice
Amazon Polly turns text into lifelike speech, allowing you to create voice-enabled applications. We’re excited to announce the general availability of a new US English child voice—Kevin. Kevin’s voice was developed using the latest Neural Text-to-Speech (NTTS) technology, making it sound natural and human-like. This voice imitates the voice of a male child. Have a listen to the Kevin voice:
Kevin sample 1
| Listen now Voiced by Amazon Polly |
Kevin sample 2
| Listen now Voiced by Amazon Polly |
Amazon Polly has 14 neural voices to choose from:
- US English (en-US): Ivy, Joey, Justin, Kendra, Kevin, Kimberly, Joanna, Matthew, Salli
- British English (en-GB): Amy, Brian, Emma
- Brazilian Portuguese (pt-BR): Camila
- US Spanish (es-US): Lupe
Neural voices are supported in the following Regions:
- US East (N. Virginia)
- US West (Oregon)
- Asia Pacific (Sydney)
- EU (Ireland)
For the full list of text-to-speech voices, see Voices in Amazon Polly.
Our customers are using Amazon Polly voices to build new categories of speech-enabled products, including (but not limited to) voicing news content, games, eLearning platforms, telephony applications, accessibility applications, and Internet of Things (IoT). Amazon Polly voices are high quality, cost-effective, and ensure fast responses, which makes it a viable option for low-latency use cases. Amazon Polly also supports SSML tags, which give you additional control over speech output.
For more information, see What Is Amazon Polly? and log in to the Amazon Polly console to try it out!
About the Author
 Ankit Dhawan is a Senior Product Manager for Amazon Polly, technology enthusiast, and huge Liverpool FC fan. When not working on delighting our customers, you will find him exploring the Pacific Northwest with his wife and dog. He is an eternal optimist, and loves reading biographies and playing poker. You can indulge him in a conversation on technology, entrepreneurship, or soccer any time of the day.
Ankit Dhawan is a Senior Product Manager for Amazon Polly, technology enthusiast, and huge Liverpool FC fan. When not working on delighting our customers, you will find him exploring the Pacific Northwest with his wife and dog. He is an eternal optimist, and loves reading biographies and playing poker. You can indulge him in a conversation on technology, entrepreneurship, or soccer any time of the day.
CVPR: Deep learning has more gas in the tank
Amazon’s Larry Davis on the past and future of computer vision research.Read More
Computer vision: a look at the past, present, and future
Watch the webcast discussion with Gerard Medioni, Amazon distinguished scientist, Pietro Perona, Amazon Fellow, and Larry Davis, Amazon senior principal scientist.Read More