Amazon Q is a fully managed, generative artificial intelligence (AI) powered assistant that you can configure to answer questions, provide summaries, generate content, gain insights, and complete tasks based on data in your enterprise. The enterprise data required for these generative-AI powered assistants can reside in varied repositories across your organization. One common repository to store data is Amazon Simple Storage Service (Amazon S3), which is an object storage service that stores data as objects within storage buckets. Customers of all sizes and industries can securely index data from a variety of data sources such as document repositories, web sites, content management systems, customer relationship management systems, messaging applications, database, and so on.
To build a generative AI-based conversational application that’s integrated with the data sources that contain the relevant content an enterprise needs to invest time, money, and people, you need to build connectors to the data sources. Next you need to index the data to make it available for a Retrieval Augmented Generation (RAG) approach where relevant passages are delivered with high accuracy to a large language model (LLM). To do this you need to select an index that provides the capabilities to index the content for semantic and vector search, build the infrastructure to retrieve the data, rank the answers, and build a feature rich web application. You also need to hire and staff a large team to build, maintain and manage such a system.
Amazon Q Business is a fully managed generative AI-powered assistant that can answer questions, provide summaries, generate content, and securely complete tasks based on data and information in your enterprise systems. Amazon Q business can help you get fast, relevant answers to pressing questions, solve problems, generate content, and take actions using the data and expertise found in your company’s information repositories, code, and enterprise systems such as Atlassian Jira and others. To do this, Amazon Q provides native data source connectors that can index content into a built-in retriever and uses an LLM to provide accurate, well written answers. A data source connector within Amazon Q helps to integrate and synchronize data from multiple repositories into one index.
Amazon Q Business offers multiple prebuilt connectors to a large number of data sources, including Atlassian Jira, Atlassian Confluence, Amazon S3, Microsoft SharePoint, Salesforce, and many more and can help you create your generative AI solution with minimal configuration. For a full list of Amazon Q supported data source connectors, see Amazon Q connectors.
Now you can use the Amazon Q S3 connector to index your data on S3 and build a generative AI assistant that can derive insights from the data stored. Amazon Q generates comprehensive responses to natural language queries from users by analyzing information across content that it has access to. Amazon Q also supports access control for your data so that the right users can access the right content. Its responses to questions are based on the content that your end user has permissions to access.
This post shows how to configure the Amazon Q S3 connector and derive insights by creating a generative-AI powered conversation experience on AWS using Amazon Q while using access control lists (ACLs) to restrict access to documents based on user permissions.
Finding accurate answers from content in S3 using Amazon Q Business
After you integrate Amazon Q Business with Amazon S3, users can ask questions about the content stored in S3. For example, a user might ask about the main points discussed in a blog post on cloud security, the installation steps outlined in a user guide, findings from a case study on hybrid cloud usage, market trends noted in an analyst report, or key takeaways from a whitepaper on data encryption. This integration helps users to quickly find the specific information they need, improving their understanding and ability to make informed business decisions.
Secure querying with ACL crawling and identity crawling
Secure querying is when a user runs a query and is returned answers from documents that the user has access to and not from documents that the user does not have access to. To enable users to do secure querying, Amazon Q Business honors ACLs of the documents. Amazon Q Business does this by first supporting the indexing of ACLs. Indexing documents with ACLs is crucial for maintaining data security, because documents without ACLs are treated as public. Second, at query time the user’s credentials (email address) are passed along with the query so that only answers from documents that are relevant to the query and that the user is authorized to access are displayed.
A document’s ACL, included in the metadata.json or acl.json files alongside the document in the S3 bucket, contains details such as the user’s email address and local groups.
When a user signs in to a web application to conduct a search, their credentials (such as an email address) need to match what’s in the ACL of the document to return results from that document. The web application that the user uses to retrieve answers would be connected to an identity provider (IdP) or the AWS IAM Identity Center. The user’s credentials from the IdP or IAM Identity Center are referred to here as the federated user credentials. The federated user credentials are passed along with the query so that Amazon Q can return the answers from the documents that this user has access to. However, there are occasions when a user’s federated credentials might be absent from the S3 bucket ACLs. In these instances, only the user’s local alias and local groups are specified in the document’s ACL. Therefore, it’s necessary to map these federated user credentials to the corresponding local user alias and local group in the document’s ACL.
Any document or folder without an explicit ACL Deny clause is treated as public.
Solution overview
As an administrator user of Amazon Q, the high-level steps to set up a generative AI chat application are to create an Amazon Q application, connect to different data sources, and finally deploy your web experience. An Amazon Q web experience is the chat interface that you create using your Amazon Q application. Then, your users can chat with your organization’s Amazon Q web experience, and it can be integrated with IAM Identity Center. You can configure and customize your Amazon Q web experience using either the AWS Management Console for Amazon Q or the Amazon Q API.
Amazon Q understands and respects your existing identities, roles, and permissions and uses this information to personalize its interactions. If a user doesn’t have permission to access data without Amazon Q, they can’t access it using Amazon Q either. The following table outlines which documents each user is authorized to access for our use case. The documents being used in this example are a subset of AWS public documents. In this blog post, we will focus on users Arnav (Guest), Mary, and Pat and their assigned groups.
| First name | Last name | Group | Document type authorized for access | |
| 1 | Arnav | Desai | Blogs | |
| 2 | Pat | Candella | Customer | Blogs, user guides |
| 3 | Jane | Doe | Sales | Blogs, user guides, and case studies |
| 4 | John | Stiles | Marketing | Blogs, user guides, case studies, and analyst reports |
| 5 | Mary | Major | Solutions architect | Blogs, user guides, case studies, analyst reports, and whitepapers |
Architecture diagram
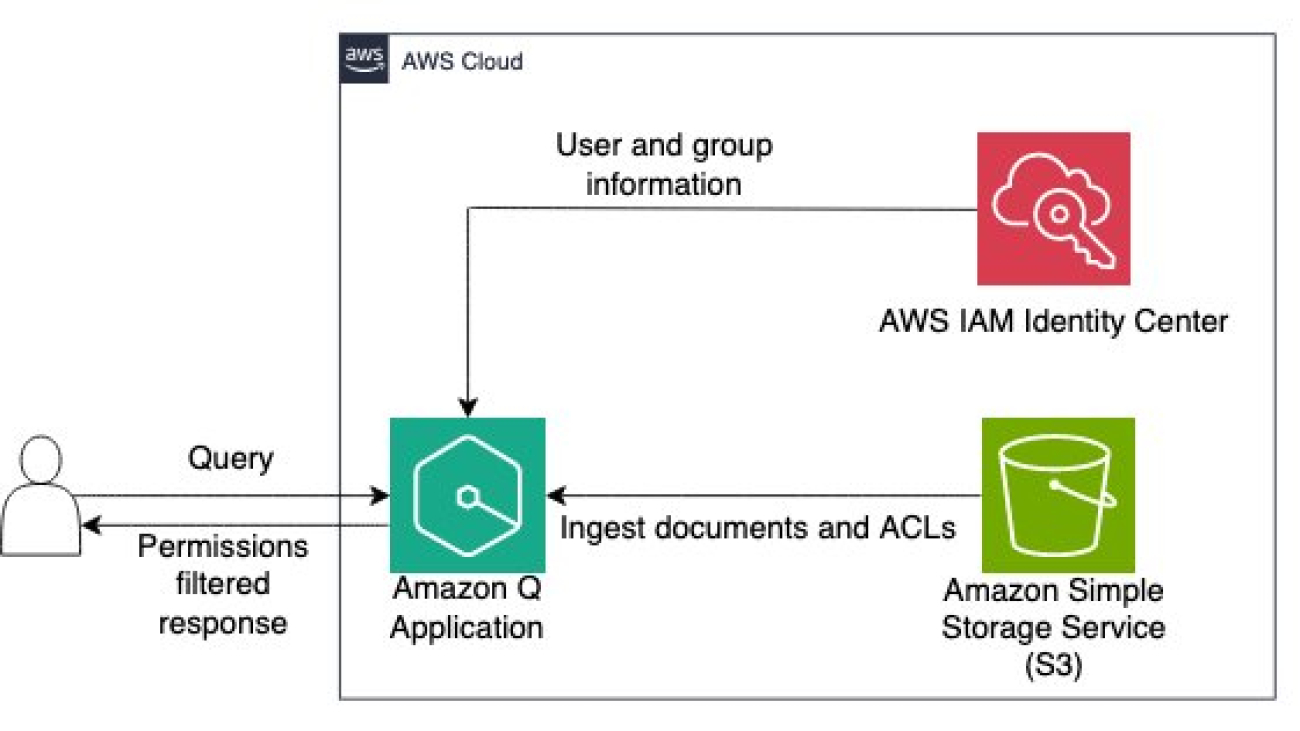
The following diagram illustrates the solution architecture. Amazon S3 is the data source and documents along with the ACL information are passed to Amazon Q from S3. The user submits a query to the Amazon Q application. Amazon Q retrieves the user and group information and provides answers based on the documents that the user has access to.
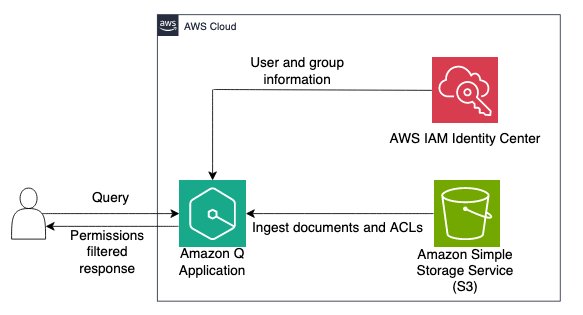
In the upcoming sections, we will show you how to implement this architecture.
Prerequisites
For this walkthrough, you should have the following prerequisites:
- An AWS account.
- Amazon S3 and IAM Identity Center permissions.
- Privileges to create an Amazon Q application, AWS resources, and AWS Identity and Access Management (IAM) roles and policies.
- Basic knowledge of AWS services and working knowledge of S3.
- Follow the steps for Setting up for Amazon Q Business if you’re using Amazon Q Business for the first time.
Prepare your S3 bucket as a data source
In the AWS Region list, choose US East (N. Virginia) as the Region. You can choose any Region that Amazon Q is available in but ensure that you remain in the same Region when creating all other resources. To prepare an S3 bucket as a data source, create an S3 bucket. Note the name of the S3 bucket. Replace <REPLACE-WITH-NAME-OF-S3-BUCKET> with the name of the bucket in the commands below. In a terminal with the AWS Command Line Interface (AWS CLI) or AWS CloudShell, run the following commands to upload the documents to the data source bucket:
The documents being queried are stored in an S3 bucket. Each document type has a separate folder: blogs, case-studies, analyst reports, user guides, and white papers. This folder structure is contained in a folder named Data as shown below:

Each object in S3 is considered a single document. Any <object-name>.metadata.json file and access control list (ACL) file is considered metadata for the object it’s associated with and not treated as a separate document. In this example, metadata files including the ACLs are in a folder named Meta. We use the Amazon Q S3 connector to configure this S3 bucket as the data source. When the data source is synced with the Amazon Q index, it crawls and indexes all documents and collects the ACLs and document attributes from the metadata files. To learn more about ACLs using metadata files, see Amazon S3 document metadata. Here’s the sample metadata JSON file:
Create users and groups in IAM Identity Center
In this section, you create the following mapping for demonstration:
| User | Group name | |
| 1 | Arnav | |
| 2 | Pat | customer |
| 3 | Mary | AWS-SA |
To create users:
- Open the AWS IAM Identity Center
- If you haven’t enabled IAM Identity Center, choose Enable. If there’s a pop-up, choose how you want to enable IAM Identity Center. For this example, select Enable only in this AWS account. Choose Continue.

- In the IAM Identity Center dashboard, choose Users in the navigation pane.
- Choose Add User.
- Enter the user details for Mary:
- Username: mary_major
- Email address: mary_major@example.com
Note: Use or create a real email address for each user to use in a later step. - First name: Mary
- Last name: Major
- Display name: Mary Major

- Skip the optional fields and choose Next to create the user.
- In the Add user to groups page, choose Next and then choose Add user. Follow the same steps to create users for Pat and Arnav (Guest user).
(You will assign users to groups at a later step.)
To create groups:
- Now, you will create two groups: AWS-SA and customer. Choose Groups on the navigation pane and choose Create group.

- For the group name, enter AWS-SA, add user Mary to the group,and choose Create group.

- Similarly, create a group name customer, add user Pat, and choose Create group.
- Now, add multi-factor authentication to the users following the instructions sent to the user email. For more details, see Multi-factor authentication for Identity Center users. When done, you will have the users and groups set up on IAM Identity Center.
Create and configure your Amazon Q application
In this step, you create an Amazon Q application that powers the conversation web experience:
- On the AWS Management Console for Amazon Q, in the Region list, choose US East (N. Virginia).
- On the Getting started page, select Enable identity-aware sessions. Once enabled, Amazon Q connected to IAM Identity Center should be displayed. Choose Subscribe in Q Business.

- On the Amazon Q Business console, choose Get started.

- On the Applications page, choose Create application.

- On the Create application page, enter Application name and leave everything else with default values.

- Choose Create.
- On the Select retriever page, for Retrievers, select Use native retriever.

- Choose Next. This will take you to the Connect data sources
Configure Amazon S3 as the data source
In this section, you walk through an example of adding an S3 connector. The S3 connector consists of blogs, user guides, case studies, analyst reports, and whitepapers.
To add the S3 connector:
- On the Connect data sources page, select Amazon S3 connector.

- For Data source name, enter a name for your data source.
- In the IAM role section, select Create new service role (Recommended).

- In Sync scope section, browse to your S3 bucket containing the data files.
- Under Advanced settings, for Metadata files prefix folder location, enter Meta/
- Choose Filter patterns. Under Include patterns, enter Data/ as the prefix and choose Add.

- For Frequency under Sync run schedule, choose Run on demand.
- Leave the rest as default and choose Add data source. Wait until the data source is added.
- On the Connect data sources page, choose Next. This will take you to the Add users and groups
Add users and groups in Amazon Q
In this section, you set up users and groups to showcase how access can be managed based on the permissions.
- On the Add users and groups page, choose Assign existing users and groups and choose Next.

- Enter the users and groups you want to add and choose Assign. You will have to enter the user names and groups in the search box and select the user or group. Verify that users and groups are correctly displayed under the Users and Groups tabs respectively.

- Select the Current subscription. In this example, we selected choose Q Business Lite for groups. Choose the same subscription for users under the Users tab. You can also update subscriptions after creating the application.

- Leave the Service role name as default and choose Create application.
Sync S3 data source
With your application created, you will crawl and index the documents in the S3 bucket created at the beginning of the process.
- Select the name of the application

- Go to the Data sources Select the radio button next to the S3 data source and choose Sync now.

- The sync can take from a few minutes to a few hours. Wait for the sync to complete. Verify the sync is complete and documents have been added.

Run queries with Amazon Q
Now that you have configured the Amazon Q application and integrated it with IAM Identity Center, you can test queries from different users based on their group permissions. This will demonstrate how Amazon Q respects the access control rules set up in the Amazon S3 data source.
You have three users for testing—Pat from the Customer group, Mary from the AWS-SA group, and Arnav who isn’t part of any group. According to the access control list (ACL) configuration, Pat should have access to blogs and user guides, Mary should have access to blogs, user guides, case studies, analyst reports, and whitepapers, and Arnav should have access only to blogs.
In the following steps, you will sign in as each user and ask various questions to see what responses Amazon Q provides based on the permitted document types for their respective groups. You will also test edge cases where users try to access information from restricted sources to validate the access control functionality.
- In the Amazon Q Business console, choose Applications on the navigation pane and copy the Web experience URL.

Sign in as Pat to the Amazon Q chat interface.
Pat is part of the Customer group and has access to blogs and user guides
When asked a question like “What is AWS?” Amazon Q will provide a summary pulling information from blogs and user guides, highlighting the sources at the end of each excerpt.

Try asking a question that requires information from user guides, such as “How do I set up an AWS account?” Amazon Q will summarize relevant details from the permitted user guide sources for Pat’s group.

However, if you, as Pat, ask a question that requires information from whitepapers, analyst reports, or case studies, Amazon Q will indicate that it could not find any relevant information from the sources she has access to.
Ask a question such as “What are the strategic planning assumptions for the year 2025?” to see this.

Sign in as Mary to the Amazon Q chat interface.
Sign out as user Pat. Start a new incognito browser session or use a different browser. Copy the web experience URL and sign in as user Mary. Repeat these steps each time you need to sign in as a different user.
Mary is part of the AWS-SA group, so she has access to blogs, case studies, analyst reports, and whitepapers.
When Mary asks the same question about strategic planning, Amazon Q will provide a comprehensive summary pulling information from all the permitted sources.

With Mary’s sign-in, you can ask various other questions related to AWS services, architectures, or solutions, and Amazon Q will effectively summarize information from across all the content types Mary’s group has access to.

Sign in as Arnav to the Amazon Q chat interface
Arnav is not part of any group and is able to access only blogs. If Arnav asks a question about Amazon Polly, Amazon Q will return blog posts.

When Arnav tries to get information from the user guides, access is restricted. If they ask about something like how to set up an AWS account, Amazon Q responds that it could not find relevant information.

This shows how Amazon Q respects the data access rules configured in the Amazon S3 data source, allowing users to gain insights only from the content their group has permissions to view, while still providing comprehensive answers when possible within those boundaries.
Troubleshooting
Troubleshooting your Amazon S3 connector provides information about error codes you might see for the Amazon S3 connector and suggested troubleshooting actions. If you encounter an HTTP status code 403 (Forbidden) error when you open your Amazon Q Business application, it means that the user is unable to access the application. See Troubleshooting Amazon Q Business and identity provider integration for common causes and how to address them.
Frequently asked questions
Q. Why isn’t Amazon Q Business answering any of my questions?
A. Verify that you have synced your data source on the Amazon Q console. Also, check the ACLs to ensure you have the required permissions to retrieve answers from Amazon Q.
Q. How can I sync documents without ACLs?
A. When configuring the Amazon S3 connector, under Sync scope, you can optionally choose not to include the metadata or ACL configuration file location in Advanced settings. This will allow you to sync documents without ACLs.
Q. I updated the contents of my S3 data source but Amazon Q business answers using old data.
A. After content has been updated in your S3 data source location, you must re-sync the contents for the updated data to be picked up by Amazon Q. Go to the Data sources Select the radio button next to the S3 data source and choose Sync now. After the sync is complete, verify that the updated data is reflected by running queries on Amazon Q.
Q. I am unable to sign in as a new user through the web experience URL.
A. Clear your browser cookies and sign in as a new user.
Q. I keep trying to sign in but am getting this error:

A. Try signing in from a different browser or clear browser cookies and try again.
Q. What are the supported document formats and what is considered a document in Amazon S3?
A. See Supported document types and What is a document? to learn more.
Call to action
Explore other features in Amazon Q Business such as:
- The Amazon Q Business document enrichment feature helps you control both what documents and document attributes are ingested into your index and also how they’re ingested. Using document enrichment, you can create, modify, or delete document attributes and document content when you ingest them into your Amazon Q Business index. For example, you can scrub personally identifiable information (PII) by choosing to delete any document attributes related to PII.
- Amazon Q Business features
- Filtering using metadata – Use document attributes to customize and control users’ chat experience. Currently supported only if you use the Amazon Q Business API.
- Source attribution with citations – Verify responses using Amazon Q Business source attributions.
- Upload files and chat – Let users upload files directly into chat and use uploaded file data to perform web experience tasks.
- Quick prompts – Feature sample prompts to inform users of the capabilities of their Amazon Q Business web experience.
- To improve retrieved results and customize the user chat experience, you can map document attributes from your data sources to fields in your Amazon Q index. Learn more by exploring Amazon Q Business Amazon S3 data source connector field mappings.
Clean up
To avoid incurring future charges and to clean out unused roles and policies, delete the resources you created: the Amazon Q application, data sources, and corresponding IAM roles.
- To delete the Amazon Q application, go to the Amazon Q console and, on the Applications page, select your application.
- On the Actions drop-down menu, choose Delete.
- To confirm deletion, enter delete in the field and choose Delete. Wait until you get the confirmation message; the process can take up to 15 minutes.
- To delete the S3 bucket created in Prepare your S3 bucket as a data source, empty the bucket and then follow the steps to delete the bucket.
- Delete your IAM Identity Center instance.
Conclusion
This blog post has walked you through the steps to build a secure, permissions-based generative AI solution using Amazon Q and Amazon S3 as the data source. By configuring user groups and mapping their access privileges to different document folders in S3, it demonstrated that Amazon Q respects these access control rules. When users query the AI assistant, it provides comprehensive responses by analyzing only the content their group has permission to view, preventing unauthorized access to restricted information. This solution allows organizations to safely unlock insights from their data repositories using generative AI while ensuring data access governance.
Don’t let your data’s potential go untapped. Continue exploring how Amazon Q can transform your enterprise data to gain actionable insights. Join the conversation and share your thoughts or questions in the comments section below.
About the Author
 Kruthi Jayasimha Rao is a Partner Solutions Architect with a focus in AI and ML. She provides technical guidance to AWS Partners in following best practices to build secure, resilient, and highly available solutions in the AWS Cloud.
Kruthi Jayasimha Rao is a Partner Solutions Architect with a focus in AI and ML. She provides technical guidance to AWS Partners in following best practices to build secure, resilient, and highly available solutions in the AWS Cloud.

Keagan Mirazee is a Partner Solutions Architect specializing in Generative AI to assist AWS Partners in engineering reliable and scalable cloud solutions.

Dipti Kulkarni is a Sr. Software Development Engineer for Amazon Q. Dipti is a passionate engineer building connectors for Amazon Q.


 Pawan Agarwal is the Senior Director of Software Engineering at Salesforce. He leads efforts in Generative and Predictive AI, focusing on inferencing, training, fine-tuning, and notebooking technologies that power the Salesforce Einstein suite of applications.
Pawan Agarwal is the Senior Director of Software Engineering at Salesforce. He leads efforts in Generative and Predictive AI, focusing on inferencing, training, fine-tuning, and notebooking technologies that power the Salesforce Einstein suite of applications. Rielah De Jesus is a Principal Solutions Architect at AWS who has successfully helped various enterprise customers in the DC, Maryland, and Virginia area move to the cloud. In her current role she acts as a customer advocate and technical advisor focused on helping organizations like Salesforce achieve success on the AWS platform. She is also a staunch supporter of Women in IT and is very passionate about finding ways to creatively use technology and data to solve everyday challenges.
Rielah De Jesus is a Principal Solutions Architect at AWS who has successfully helped various enterprise customers in the DC, Maryland, and Virginia area move to the cloud. In her current role she acts as a customer advocate and technical advisor focused on helping organizations like Salesforce achieve success on the AWS platform. She is also a staunch supporter of Women in IT and is very passionate about finding ways to creatively use technology and data to solve everyday challenges.












 John Gray is a Sr. Solutions Architect in Annapurna Labs, AWS, based out of Seattle. In this role, John works with customers on their AI and machine learning use cases, architects solutions to cost-effectively solve their business problems, and helps them build a scalable prototype using AWS AI chips.
John Gray is a Sr. Solutions Architect in Annapurna Labs, AWS, based out of Seattle. In this role, John works with customers on their AI and machine learning use cases, architects solutions to cost-effectively solve their business problems, and helps them build a scalable prototype using AWS AI chips. Pinak Panigrahi works with customers to build ML-driven solutions to solve strategic business problems on AWS. In his current role, he works on optimizing training and inference of generative AI models on AWS AI chips.
Pinak Panigrahi works with customers to build ML-driven solutions to solve strategic business problems on AWS. In his current role, he works on optimizing training and inference of generative AI models on AWS AI chips. Kamran Khan, Head of Business Development for AWS Inferentina/Trianium at AWS. He has over a decade of experience helping customers deploy and optimize deep learning training and inference workloads using AWS Inferentia and AWS Trainium.
Kamran Khan, Head of Business Development for AWS Inferentina/Trianium at AWS. He has over a decade of experience helping customers deploy and optimize deep learning training and inference workloads using AWS Inferentia and AWS Trainium. Shruti Koparkar is a Senior Product Marketing Manager at AWS. She helps customers explore, evaluate, and adopt Amazon EC2 accelerated computing infrastructure for their machine learning needs.
Shruti Koparkar is a Senior Product Marketing Manager at AWS. She helps customers explore, evaluate, and adopt Amazon EC2 accelerated computing infrastructure for their machine learning needs.
 Sebastian Bustillo
Sebastian Bustillo Dr. Farooq Sabir
Dr. Farooq Sabir Dr. Natarajan Chennimalai Kumar
Dr. Natarajan Chennimalai Kumar Madhur Prashant is an AI and ML Solutions Architect at Amazon Web Services. He is passionate about the intersection of human thinking and generative AI. His interests lie in generative AI, specifically building solutions that are helpful and harmless, and most of all optimal for customers. Outside of work, he loves doing yoga, writing blogs, hiking, spending time with his twin, and playing the guitar.
Madhur Prashant is an AI and ML Solutions Architect at Amazon Web Services. He is passionate about the intersection of human thinking and generative AI. His interests lie in generative AI, specifically building solutions that are helpful and harmless, and most of all optimal for customers. Outside of work, he loves doing yoga, writing blogs, hiking, spending time with his twin, and playing the guitar. Dr. Nikita Ivkin is a Senior Applied Scientist for Amazon SageMaker. He focuses on inference acceleration for foundation models and scalable ML algorithms in general. His research interests are in the area of inference acceleration, streaming algorithms, and federated learning, with publishing in a variety of machine learning and computer science venues such as NeurIPS, ICML, ICLR, STOC, PODS, and others.
Dr. Nikita Ivkin is a Senior Applied Scientist for Amazon SageMaker. He focuses on inference acceleration for foundation models and scalable ML algorithms in general. His research interests are in the area of inference acceleration, streaming algorithms, and federated learning, with publishing in a variety of machine learning and computer science venues such as NeurIPS, ICML, ICLR, STOC, PODS, and others. Supriya Puragundla is a Senior Solutions Architect at AWS. She has over 15 years of IT experience in software development, design, and architecture. She helps key customer accounts on their data, generative AI, and AI/ML journeys. She is passionate about data-driven AI and the area of depth in ML and generative AI.
Supriya Puragundla is a Senior Solutions Architect at AWS. She has over 15 years of IT experience in software development, design, and architecture. She helps key customer accounts on their data, generative AI, and AI/ML journeys. She is passionate about data-driven AI and the area of depth in ML and generative AI. Dr. Xin Huang is a Senior Applied Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on developing scalable machine learning algorithms. His research interests are in the area of natural language processing, explainable deep learning on tabular data, and robust analysis of non-parametric space-time clustering. He has published many papers in ACL, ICDM, and KDD conferences, and Royal Statistical Society: Series A.
Dr. Xin Huang is a Senior Applied Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on developing scalable machine learning algorithms. His research interests are in the area of natural language processing, explainable deep learning on tabular data, and robust analysis of non-parametric space-time clustering. He has published many papers in ACL, ICDM, and KDD conferences, and Royal Statistical Society: Series A. Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker JumpStart and helps develop machine learning algorithms. He got his PhD from University of Illinois Urbana-Champaign. He is an active researcher in machine learning and statistical inference, and has published many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.
Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker JumpStart and helps develop machine learning algorithms. He got his PhD from University of Illinois Urbana-Champaign. He is an active researcher in machine learning and statistical inference, and has published many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences. Karl Albertsen leads the product management and partnership teams for Amazon SageMaker. He is focused on making AI accessible, cost-effective, and high-performing for business applications.
Karl Albertsen leads the product management and partnership teams for Amazon SageMaker. He is focused on making AI accessible, cost-effective, and high-performing for business applications. Christopher Whitten is an SDE with the SageMaker JumpStart team leading model onboarding and deeper integration with SageMaker services. Chris is passionate about accelerating the ubiquity of AI in practical business applications. His technical interests include agentic workflows and MLOps.
Christopher Whitten is an SDE with the SageMaker JumpStart team leading model onboarding and deeper integration with SageMaker services. Chris is passionate about accelerating the ubiquity of AI in practical business applications. His technical interests include agentic workflows and MLOps. Hemant Singh is an Applied Scientist with experience in Amazon SageMaker JumpStart. He got his master’s from Courant Institute of Mathematical Sciences and B.Tech from IIT Delhi. He has experience in working on a diverse range of machine learning problems within the domain of natural language processing, computer vision, and time series analysis.
Hemant Singh is an Applied Scientist with experience in Amazon SageMaker JumpStart. He got his master’s from Courant Institute of Mathematical Sciences and B.Tech from IIT Delhi. He has experience in working on a diverse range of machine learning problems within the domain of natural language processing, computer vision, and time series analysis. Evan Kravitz is a software engineer at Amazon Web Services, working on SageMaker JumpStart. He is interested in the confluence of machine learning with cloud computing. Evan received his undergraduate degree from Cornell University and master’s degree from the University of California, Berkeley. In 2021, he presented a paper on adversarial neural networks at the ICLR conference. In his free time, Evan enjoys cooking, traveling, and going on runs in New York City.
Evan Kravitz is a software engineer at Amazon Web Services, working on SageMaker JumpStart. He is interested in the confluence of machine learning with cloud computing. Evan received his undergraduate degree from Cornell University and master’s degree from the University of California, Berkeley. In 2021, he presented a paper on adversarial neural networks at the ICLR conference. In his free time, Evan enjoys cooking, traveling, and going on runs in New York City.





 James Park is a Solutions Architect at Amazon Web Services. He works with Amazon.com to design, build, and deploy technology solutions on AWS, and has a particular interest in AI and machine learning. In his spare time he enjoys seeking out new cultures, new experiences, and staying up to date with the latest technology trends.You can find him on
James Park is a Solutions Architect at Amazon Web Services. He works with Amazon.com to design, build, and deploy technology solutions on AWS, and has a particular interest in AI and machine learning. In his spare time he enjoys seeking out new cultures, new experiences, and staying up to date with the latest technology trends.You can find him on  Dr. Kyle Ulrich is an Applied Scientist with the
Dr. Kyle Ulrich is an Applied Scientist with the  Jonathan Guinegagne is a Senior Software Engineer with Amazon SageMaker JumpStart at AWS. He got his master’s degree from Columbia University. His interests span machine learning, distributed systems, and cloud computing, as well as democratizing the use of AI. Jonathan is originally from France and now lives in Brooklyn, NY.
Jonathan Guinegagne is a Senior Software Engineer with Amazon SageMaker JumpStart at AWS. He got his master’s degree from Columbia University. His interests span machine learning, distributed systems, and cloud computing, as well as democratizing the use of AI. Jonathan is originally from France and now lives in Brooklyn, NY.









 Govind Palanisamy is a Solutions Architect at AWS, where he helps government agencies migrate and modernize their workloads to increase citizen experience. He is passionate about technology and transformation, and he helps customers transform their businesses using AI/ML and generative AI-based solutions.
Govind Palanisamy is a Solutions Architect at AWS, where he helps government agencies migrate and modernize their workloads to increase citizen experience. He is passionate about technology and transformation, and he helps customers transform their businesses using AI/ML and generative AI-based solutions. Bharath Gunapati is a Sr. Solutions architect at AWS, where he helps clinicians, researchers, and staff at academic medical centers to adopt and use cloud technologies. He is passionate about technology and the impact it can make on healthcare and research.
Bharath Gunapati is a Sr. Solutions architect at AWS, where he helps clinicians, researchers, and staff at academic medical centers to adopt and use cloud technologies. He is passionate about technology and the impact it can make on healthcare and research.