When ingesting data into Amazon OpenSearch, customers often need to augment data before putting it into their indexes. For instance, you might be ingesting log files with an IP address and want to get a geographic location for the IP address, or you might be ingesting customer comments and want to identify the language they are in. Traditionally, this requires an external process that complicates data ingest pipelines and can cause a pipeline to fail. OpenSearch offers a wide range of third-party machine learning (ML) connectors to support this augmentation.
This post highlights two of these third-party ML connectors. The first connector we demonstrate is the Amazon Comprehend connector. In this post, we show you how to use this connector to invoke the LangDetect API to detect the languages of ingested documents.
The second connector we demonstrate is the Amazon Bedrock connector to invoke the Amazon Titan Text Embeddings v2 model so that you can create embeddings from ingested documents and perform semantic search.
Solution overview
We use Amazon OpenSearch with Amazon Comprehend to demonstrate the language detection feature. To help you replicate this setup, we’ve provided the necessary source code, an Amazon SageMaker notebook, and an AWS CloudFormation template. You can find these resources in the sample-opensearch-ml-rest-api GitHub repo.

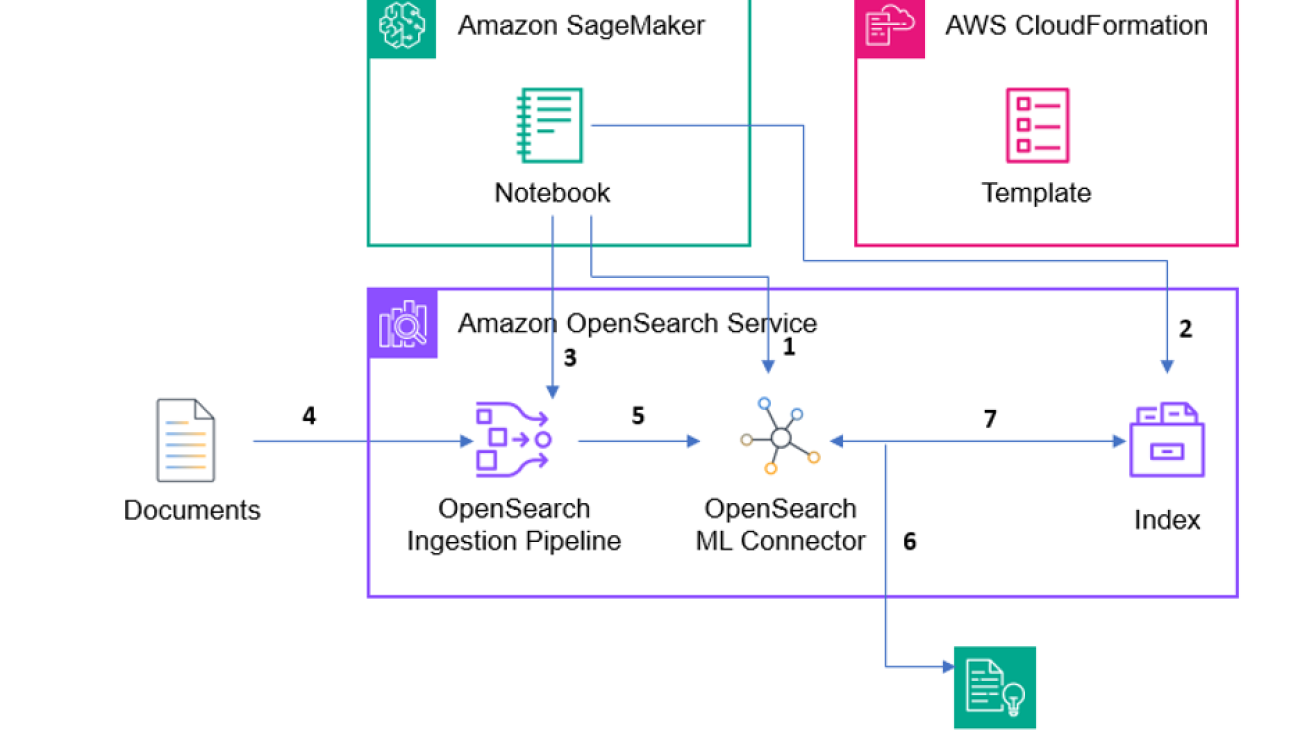
The reference architecture shown in the preceding figure shows the components used in this solution. A SageMaker notebook is used as a convenient way to execute the code that is provided in the Github repository provided above.
Prerequisites
To run the full demo using the sample-opensearch-ml-rest-api, make sure you have an AWS account with access to:
- Run a CloudFormation template
- Create AWS Identity and Access Management (IAM) roles and policies
- Create a SageMaker notebook
- Create an Amazon OpenSearch cluster
- Create an Amazon Simple Storage Service (Amazon S3) bucket
- Invoke Amazon Comprehend APIs
- Invoke Amazon Bedrock models (for part 2)
Part 1: The Amazon Comprehend ML connector
Set up OpenSearch to access Amazon Comprehend
Before you can use Amazon Comprehend, you need to make sure that OpenSearch can call Amazon Comprehend. You do this by supplying OpenSearch with an IAM role that has access to invoke the DetectDominantLanguage API. This requires the OpenSearch Cluster to have fine grained access control enabled. The CloudFormation template creates a role for this called <Your Region>-<Your Account Id>-SageMaker-OpenSearch-demo-role. Use the following steps to attach this role to the OpenSearch cluster.
- Open the OpenSearch Dashboard console—you can find the URL in the output of the CloudFormation template—and sign in using the username and password you provided.

- Choose Security in the left-hand menu (if you don’t see the menu, choose the three horizontal lines icon at the top left of the dashboard).

- From the security menu, select Roles to manage the OpenSearch roles.

- In the search box. enter
ml_full_accessrole.
- Select the Mapped users link to map the IAM role to this OpenSearch role.

- On the Mapped users screen, choose Manage mapping to edit the current mappings.

- Add the IAM role mentioned previously to map it to the
ml_full_accessrole, this will allow OpenSearch to access the needed AWS resources from the ml-commons plugin. Enter your IAM role Amazon Resource Name (ARN) (arn:aws:iam::<your account id>:role/<your region>-<your account id>-SageMaker-OpenSearch-demo-role) in the backend roles field and choose Map.
Set up the OpenSearch ML connector to Amazon Comprehend
In this step, you set up the ML connector to connect Amazon Comprehend to OpenSearch.
- Get an authorization token to use when making the call to OpenSearch from the SageMaker notebook. The token uses an IAM role attached to the notebook by the CloudFormation template that has permissions to call OpenSearch. That same role is mapped to the OpenSearch admin role in the same way you just mapped the role to access Amazon Comprehend. Use the following code to set this up:
- Create the connector. It needs a few pieces of information:
- It needs a protocol. For this example, use
aws_sigv4, which allows OpenSearch to use an IAM role to call Amazon Comprehend. - Provide the ARN for this role, which is the same role you used to set up permissions for the
ml_full_accessrole. - Provide
comprehendas theservice_name, andDetectDominateLanguageas theapi_name. - Provide the URL to Amazon Comprehend and set up how to call the API and what data to pass to it.
- It needs a protocol. For this example, use
The final call looks like:
Register the Amazon Comprehend API connector
The next step is to register the Amazon Comprehend API connector with OpenSearch using the Register Model API from OpenSearch.
- Use the
comprehend_connectorthat you saved from the last step.
As of OpenSearch 2.13, when the model is first invoked, it’s automatically deployed. Prior to 2.13 you would have to manually deploy the model within OpenSearch.
Test the Amazon Comprehend API in OpenSearch
With the connector in place, you need to test the API to make sure it was set up and configured correctly.
- Make the following call to OpenSearch.
- You should get the following result from the call, showing the language code as
zhwith a score of1.0:
Create an ingest pipeline that uses the Amazon Comprehend API to annotate the language
The next step is to create a pipeline in OpenSearch that calls the Amazon Comprehend API and adds the results of the call to the document being indexed. To do this, you provide both an input_map and an output_map. You use these to tell OpenSearch what to send to the API and how to handle what comes back from the call.
You can see from the preceding code that you are pulling back both the top language result and its score from Amazon Comprehend and adding those fields to the document.
Part 2: The Amazon Bedrock ML connector
In this section, you use Amazon OpenSearch with Amazon Bedrock through the ml-commons plugin to perform a multilingual semantic search. Make sure that you have the solution prerequisites in place before attempting this section.
In the SageMaker instance that was deployed for you, you can see the following files: english.json, french.json, german.json.
These documents have sentences in their respective languages that talk about the term spring in different contexts. These contexts include spring as a verb meaning to move suddenly, as a noun meaning the season of spring, and finally spring as a noun meaning a mechanical part. In this section, you deploy Amazon Titan Text Embeddings model v2 using the ml connector for Amazon Bedrock. You then use this embeddings model to create vectors of text in three languages by ingesting the different language JSON files. Finally, these vectors are stored in Amazon OpenSearch to enable semantic searches to be used across the language sets.
Amazon Bedrock provides streamlined access to various powerful AI foundation models through a single API interface. This managed service includes models from Amazon and other leading AI companies. You can test different models to find the ideal match for your specific needs, while maintaining security, privacy, and responsible AI practices. The service enables you to customize these models with your own data through methods such as fine-tuning and Retrieval Augmented Generation (RAG). Additionally, you can use Amazon Bedrock to create AI agents that can interact with enterprise systems and data, making it a comprehensive solution for developing generative AI applications.

The reference architecture in the preceding figure shows the components used in this solution.
(1) First we must create the OpenSearch ML connector via running code within the Amazon SageMaker notebook. The connector essentially creates a Rest API call to any model, we specifically want to create a connector to call the Titan Embeddings model within Amazon Bedrock.
(2) Next, we must create an index to later index our language documents into. When creating an index, you can specify its mappings, settings, and aliases.
(3) After creating an index within Amazon OpenSearch, we want to create an OpenSearch Ingestion pipeline that will allow us to streamline data processing and preparation for indexing, making it easier to manage and utilize the data. (4) Now that we have created an index and set up a pipeline, we can start indexing our documents into the pipeline.
(5 – 6) We use the pipeline in OpenSearch that calls the Titan Embeddings model API. We send our language documents to the titan embeddings model, and the model returns vector embeddings of the sentences.
(7) We store the vector embeddings within our index and perform vector semantic search.
While this post highlights only specific areas of the overall solution, the SageMaker notebook has the code and instructions to run the full demo yourself.
Before you can use Amazon Bedrock, you need to make sure that OpenSearch can call Amazon Bedrock. .
Load sentences from the JSON documents into dataframes
Start by loading the JSON document sentences into dataframes for more structured organization. Each row can contain the text, embeddings, and additional contextual information:
Create the OpenSearch ML connector to Amazon Bedrock
After loading the JSON documents into dataframes, you’re ready to set up the OpenSearch ML connector to connect Amazon Bedrock to OpenSearch.
- The connector needs the following information.
- It needs a protocol. For this solution, use
aws_sigv4, which allows OpenSearch to use an IAM role to call Amazon Bedrock. - Provide the same role used earlier to set up permissions for the
ml_full_accessrole. - Provide the
service_name, model, dimensions of the model, and embedding type.
- It needs a protocol. For this solution, use
The final call looks like the following:
Test the Amazon Titan Embeddings model in OpenSearch
After registering and deploying the Amazon Titan Embeddings model using the Amazon Bedrock connector, you can test the API to verify that it was set up and configured correctly. To do this, make the following call to OpenSearch:
You should get a formatted result, similar to the following, from the call that shows the generated embedding from the Amazon Titan Embeddings model:
The preceding result is significantly shortened compared to the actual embedding result you might receive. The purpose of this snippet is to show you the format.
Create the index pipeline that uses the Amazon Titan Embeddings model
Create a pipeline in OpenSearch. You use this pipeline to tell OpenSearch to send the fields you want embeddings for to the embeddings model.
pipeline_name = "titan_embedding_pipeline_v2"
url = f"{host}/_ingest/pipeline/{pipeline_name}"
pipeline_body = {
"description": "Titan embedding pipeline",
"processors": [
{
"text_embedding": {
"model_id": bedrock_model_id,
"field_map": {
"sentence": "sentence_vector"
}
}
}
]
}
response = requests.put(url, auth=awsauth, json=pipeline_body, headers={"Content-Type": "application/json"})
print(response.text)
Create an index
With the pipeline in place, the next step is to create an index that will use the pipeline. There are three fields in the index:
sentence_vector– This is where the vector embedding will be stored when returned from Amazon Bedrock.sentence– This is the non-English language sentence.sentence_english– this is the English translation of the sentence. Include this to see how well the model is translating the original sentence.
Load dataframes into the index
Earlier in this section, you loaded the sentences from the JSON documents into dataframes. Now, you can index the documents and generate embeddings for them using the Amazon Titan Text Embeddings Model v2. The embeddings will be stored in the sentence_vector field.
Perform semantic k-NN across the documents
The final step is to perform a k-nearest neighbor (k-NN) search across the documents.
The example query is in French and can be translated to the sun is shining. Keeping in mind that the JSON documents have sentences that use spring in different contexts, you’re looking for query results and vector matches of sentences that use spring in the context of the season of spring.
Here are some of the results from this query:
This shows that the model can provide results across all three languages. It is important to note that the confidence scores for these results might be low because you’ve only ingested a couple documents with a handful of sentences in each for this demo. To increase confidence scores and accuracy, ingest a robust dataset with multiple languages and plenty of sentences for reference.
Clean Up
To avoid incurring future charges, go to the AWS Management Console for CloudFormation console and delete the stack you deployed. This will terminate the resources used in this solution.
Benefits of using the ML connector for machine learning model integration with OpenSearch
There are many ways you can perform k-nn semantic vector searches; a popular methods is to deploy external Hugging Face sentence transformer models to a SageMaker endpoint. The following are the benefits of using the ML connector approach we showed in this post, and why should you use it instead of deploying models to a SageMaker endpoint:
- Simplified architecture
- Single system to manage
- Native OpenSearch integration
- Simpler deployment
- Unified monitoring
- Operational benefits
- Less infrastructure to maintain
- Built-in scaling with OpenSearch
- Simplified security model
- Straightforward updates and maintenance
- Cost efficiency
- Single system costs
- Pay-per-use Amazon Bedrock pricing
- No endpoint management costs
- Simplified billing
Conclusion
Now that you’ve seen how you can use the OpenSearch ML connector to augment your data with external REST calls, we recommend that you visit the GitHub repo if you haven’t already and walk through the full demo yourselves. The full demo shows how you can use Amazon Comprehend for language detection and how to use Amazon Bedrock for multilingual semantic vector search, using the ml-connector plugin for both use cases. It also has sample text and JSON documents to ingest so you can see how the pipeline works.
About the Authors

John Trollinger is a Principal Solutions Architect supporting the World Wide Public Sector with a focus on OpenSearch and Data Analytics. John has been working with public sector customers over the past 25 years helping them deliver mission capabilities. Outside of work, John likes to collect AWS certifications and compete in triathlons.

Shwetha Radhakrishnan is a Solutions Architect for Amazon Web Services (AWS) with a focus in Data Analytics & Machine Learning. She has been building solutions that drive cloud adoption and help empower organizations to make data-driven decisions within the public sector. Outside of work, she loves dancing, spending time with friends and family, and traveling.



 Neeraj Lamba is a Cloud Infrastructure Architect with Amazon Web Services (AWS) Worldwide Public Sector Professional Services. He helps customers transform their business by helping design their cloud solutions and offering technical guidance. Outside of work, he likes to travel, play Tennis and experimenting with new technologies.
Neeraj Lamba is a Cloud Infrastructure Architect with Amazon Web Services (AWS) Worldwide Public Sector Professional Services. He helps customers transform their business by helping design their cloud solutions and offering technical guidance. Outside of work, he likes to travel, play Tennis and experimenting with new technologies.












 Ying Hou, PhD, is a Sr. Specialist Solution Architect for Gen AI at AWS, where she collaborates with model providers to onboard the latest and most intelligent AI models onto AWS platforms. With deep expertise in Gen AI, ASR, computer vision, NLP, and time-series forecasting models, she works closely with customers to design and build cutting-edge ML and GenAI applications. Outside of architecting innovative AI solutions, she enjoys spending quality time with her family, getting lost in novels, and exploring the UK’s national parks.
Ying Hou, PhD, is a Sr. Specialist Solution Architect for Gen AI at AWS, where she collaborates with model providers to onboard the latest and most intelligent AI models onto AWS platforms. With deep expertise in Gen AI, ASR, computer vision, NLP, and time-series forecasting models, she works closely with customers to design and build cutting-edge ML and GenAI applications. Outside of architecting innovative AI solutions, she enjoys spending quality time with her family, getting lost in novels, and exploring the UK’s national parks. Preston Tuggle is a Sr. Specialist Solutions Architect with the Third-Party Model Provider team at AWS. He focuses on working with model providers across Amazon Bedrock and Amazon SageMaker, helping them accelerate their go-to-market strategies through technical scaling initiatives and customer engagement.
Preston Tuggle is a Sr. Specialist Solutions Architect with the Third-Party Model Provider team at AWS. He focuses on working with model providers across Amazon Bedrock and Amazon SageMaker, helping them accelerate their go-to-market strategies through technical scaling initiatives and customer engagement.


































 Sovik Kumar Nath is an AI/ML and Generative AI senior solution architect with AWS. He has extensive experience designing end-to-end machine learning and business analytics solutions in finance, operations, marketing, healthcare, supply chain management, and IoT. He has double masters degrees from the University of South Florida, University of Fribourg, Switzerland, and a bachelors degree from the Indian Institute of Technology, Kharagpur. Outside of work, Sovik enjoys traveling, taking ferry rides, and watching movies.
Sovik Kumar Nath is an AI/ML and Generative AI senior solution architect with AWS. He has extensive experience designing end-to-end machine learning and business analytics solutions in finance, operations, marketing, healthcare, supply chain management, and IoT. He has double masters degrees from the University of South Florida, University of Fribourg, Switzerland, and a bachelors degree from the Indian Institute of Technology, Kharagpur. Outside of work, Sovik enjoys traveling, taking ferry rides, and watching movies. Lucas Banerji is an AI/ML and GenAI specialist Solutions Architect at AWS. He is passionate about building agentic AI systems and exploring the frontier of what’s possible with intelligent automation. Lucas holds a degree in Computer Science from the University of Virginia. Outside of work, he enjoys running, practicing Muay Thai, and traveling the world.
Lucas Banerji is an AI/ML and GenAI specialist Solutions Architect at AWS. He is passionate about building agentic AI systems and exploring the frontier of what’s possible with intelligent automation. Lucas holds a degree in Computer Science from the University of Virginia. Outside of work, he enjoys running, practicing Muay Thai, and traveling the world. Mohan Musti is a Principal Technical Account Manger based out of Dallas. Mohan helps customers architect and optimize applications on AWS. Mohan has Computer Science and Engineering from JNT University, India. In his spare time, he enjoys spending time with his family and camping.
Mohan Musti is a Principal Technical Account Manger based out of Dallas. Mohan helps customers architect and optimize applications on AWS. Mohan has Computer Science and Engineering from JNT University, India. In his spare time, he enjoys spending time with his family and camping.


 Ganesh Raam Ramadurai is a Senior Technical Program Manager at Amazon Web Services (AWS), where he leads the PACE (Prototyping and Cloud Engineering) team. He specializes in delivering innovative, AI/ML and Generative AI-driven prototypes that help AWS customers explore emerging technologies and unlock real-world business value. With a strong focus on experimentation, scalability, and impact, Ganesh works at the intersection of strategy and engineering—accelerating customer innovation and enabling transformative outcomes across industries.
Ganesh Raam Ramadurai is a Senior Technical Program Manager at Amazon Web Services (AWS), where he leads the PACE (Prototyping and Cloud Engineering) team. He specializes in delivering innovative, AI/ML and Generative AI-driven prototypes that help AWS customers explore emerging technologies and unlock real-world business value. With a strong focus on experimentation, scalability, and impact, Ganesh works at the intersection of strategy and engineering—accelerating customer innovation and enabling transformative outcomes across industries. Jeff Harman is a Senior Prototyping Architect on the Amazon Web Services (AWS) Prototyping and Cloud Engineering team, he specializes in developing innovative solutions that leverage AWS’s cloud infrastructure to meet complex business needs. Jeff Harman is a seasoned technology professional with over three decades of experience in software engineering, enterprise architecture, and cloud computing. Prior to his tenure at AWS, Jeff held various leadership roles at Webster Bank, including Vice President of Platform Architecture for Core Banking, Vice President of Enterprise Architecture, and Vice President of Application Architecture. During his time at Webster Bank, he was instrumental in driving digital transformation initiatives and enhancing the bank’s technological capabilities. He holds a Master of Science degree from the Rochester Institute of Technology, where he conducted research on creating a Java-based, location-independent desktop environment—a forward-thinking project that anticipated the growing need for remote computing solutions. Based in Unionville, Connecticut, Jeff continues to be a driving force in the field of cloud computing, applying his extensive experience to help organizations harness the full potential of AWS technologies.
Jeff Harman is a Senior Prototyping Architect on the Amazon Web Services (AWS) Prototyping and Cloud Engineering team, he specializes in developing innovative solutions that leverage AWS’s cloud infrastructure to meet complex business needs. Jeff Harman is a seasoned technology professional with over three decades of experience in software engineering, enterprise architecture, and cloud computing. Prior to his tenure at AWS, Jeff held various leadership roles at Webster Bank, including Vice President of Platform Architecture for Core Banking, Vice President of Enterprise Architecture, and Vice President of Application Architecture. During his time at Webster Bank, he was instrumental in driving digital transformation initiatives and enhancing the bank’s technological capabilities. He holds a Master of Science degree from the Rochester Institute of Technology, where he conducted research on creating a Java-based, location-independent desktop environment—a forward-thinking project that anticipated the growing need for remote computing solutions. Based in Unionville, Connecticut, Jeff continues to be a driving force in the field of cloud computing, applying his extensive experience to help organizations harness the full potential of AWS technologies. Kosal Sen is a Design Technologist on the Amazon Web Services (AWS) Prototyping and Cloud Engineering team. Kosal specializes in creating solutions that bridge the gap between technology and actual human needs. As an AWS Design Technologist, that means building prototypes on AWS cloud technologies, and ensuring they bring empathy and value into the real world. Kosal has extensive experience spanning design, consulting, software development, and user experience. Prior to AWS, Kosal held various roles where he combined technical skillsets with human-centered design principles across enterprise-scale projects.
Kosal Sen is a Design Technologist on the Amazon Web Services (AWS) Prototyping and Cloud Engineering team. Kosal specializes in creating solutions that bridge the gap between technology and actual human needs. As an AWS Design Technologist, that means building prototypes on AWS cloud technologies, and ensuring they bring empathy and value into the real world. Kosal has extensive experience spanning design, consulting, software development, and user experience. Prior to AWS, Kosal held various roles where he combined technical skillsets with human-centered design principles across enterprise-scale projects.











 Santosh Vallurupalli is a Sr. Solutions Architect at AWS. Santosh specializes in networking, containers, and migrations, and enjoys helping customers in their journey of cloud adoption and building cloud-based solutions for challenging issues. In his spare time, he likes traveling, watching Formula1, and watching The Office on repeat.
Santosh Vallurupalli is a Sr. Solutions Architect at AWS. Santosh specializes in networking, containers, and migrations, and enjoys helping customers in their journey of cloud adoption and building cloud-based solutions for challenging issues. In his spare time, he likes traveling, watching Formula1, and watching The Office on repeat. Aravind Singirikonda is an AI/ML Solutions Architect at AWS. He works with AWS customers in the healthcare and life sciences domain to provide guidance and technical assistance, helping them improve the value of their AI/ML solutions when using AWS.
Aravind Singirikonda is an AI/ML Solutions Architect at AWS. He works with AWS customers in the healthcare and life sciences domain to provide guidance and technical assistance, helping them improve the value of their AI/ML solutions when using AWS. Pawan Matta is a Sr. Solutions Architect at AWS. He works with AWS customers in the gaming industry and guides them to deploy highly scalable, performant architectures. His area of focus is management and governance. In his free time, he likes to play FIFA and watch cricket.
Pawan Matta is a Sr. Solutions Architect at AWS. He works with AWS customers in the gaming industry and guides them to deploy highly scalable, performant architectures. His area of focus is management and governance. In his free time, he likes to play FIFA and watch cricket. Ajit Mahareddy is an experienced Product and Go-To-Market (GTM) leader with over 20 years of experience in product management, engineering, and GTM. Prior to his current role, Ajit led product management building AI/ML products at leading technology companies, including Uber, Turing, and eHealth. He is passionate about advancing generative AI technologies and driving real-world impact with generative AI.
Ajit Mahareddy is an experienced Product and Go-To-Market (GTM) leader with over 20 years of experience in product management, engineering, and GTM. Prior to his current role, Ajit led product management building AI/ML products at leading technology companies, including Uber, Turing, and eHealth. He is passionate about advancing generative AI technologies and driving real-world impact with generative AI.