New AI system designs proteins that successfully bind to target molecules, with potential for advancing drug design, disease understanding and more.Read More
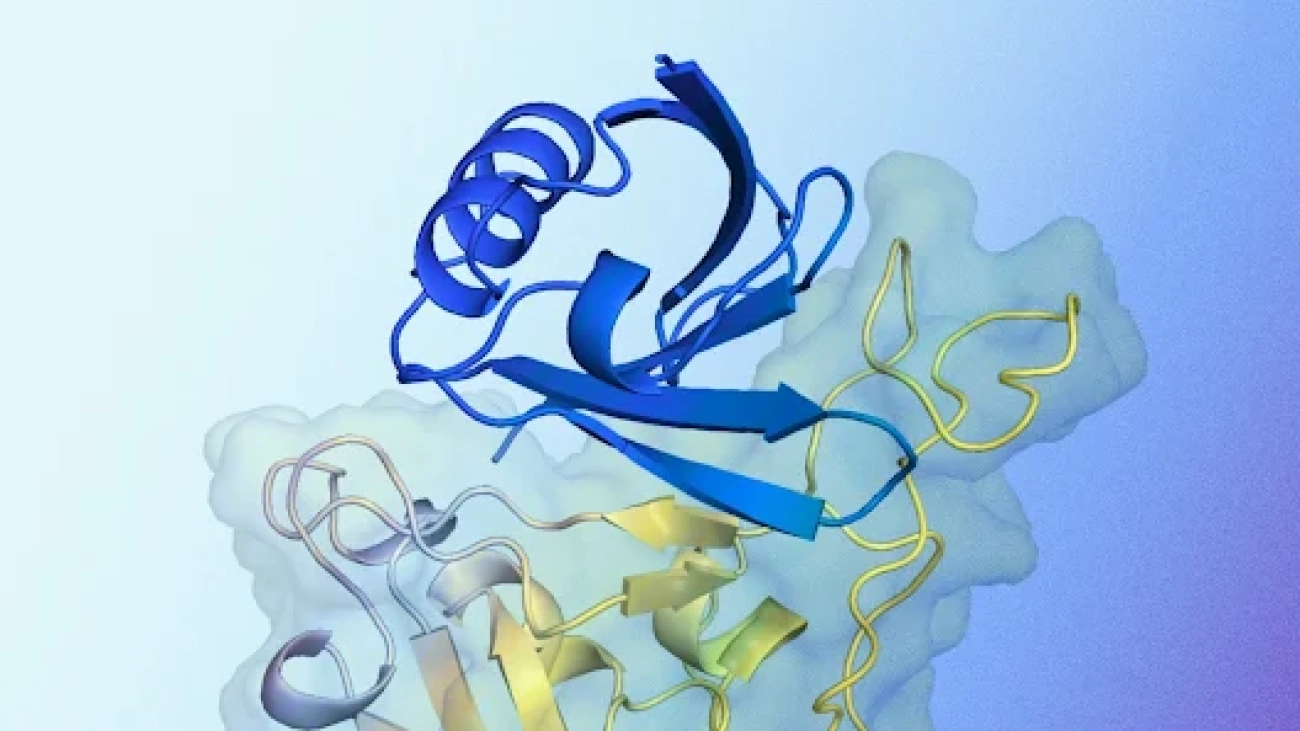
New AI system designs proteins that successfully bind to target molecules, with potential for advancing drug design, disease understanding and more.Read More
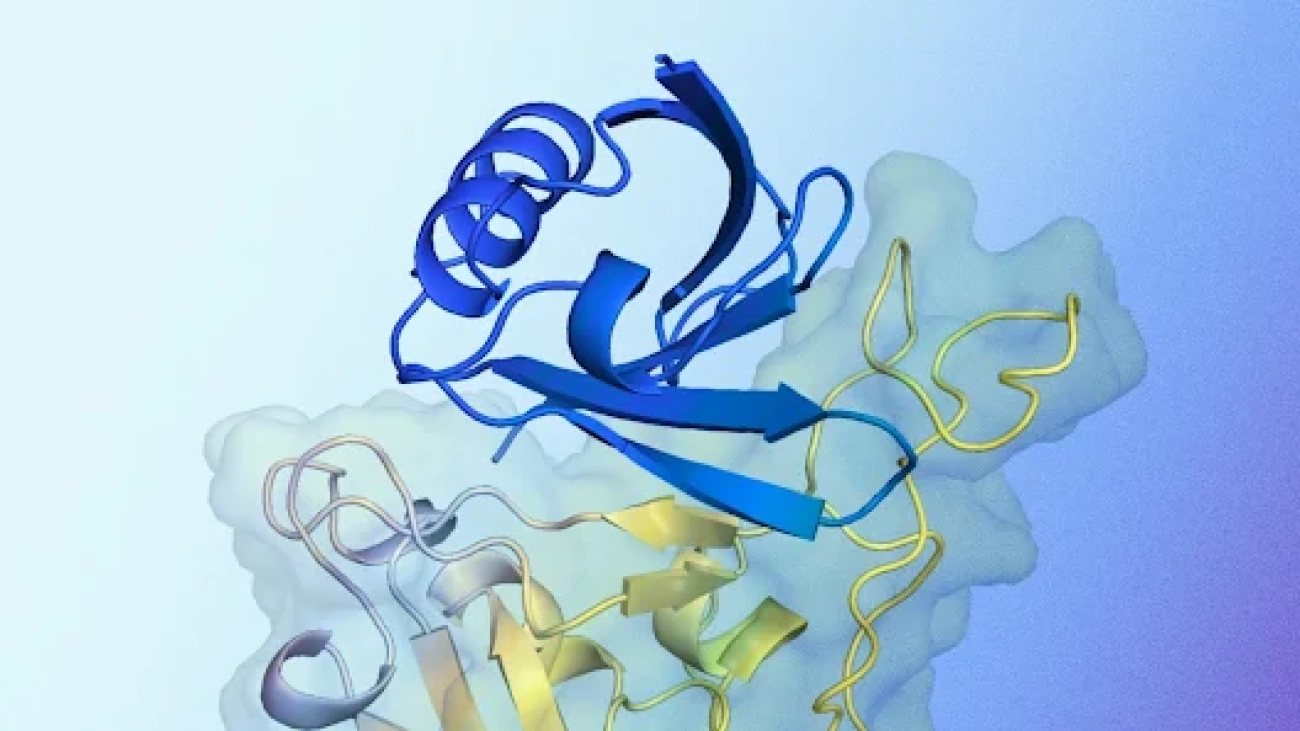
New AI system designs proteins that successfully bind to target molecules, with potential for advancing drug design, disease understanding and more.Read More
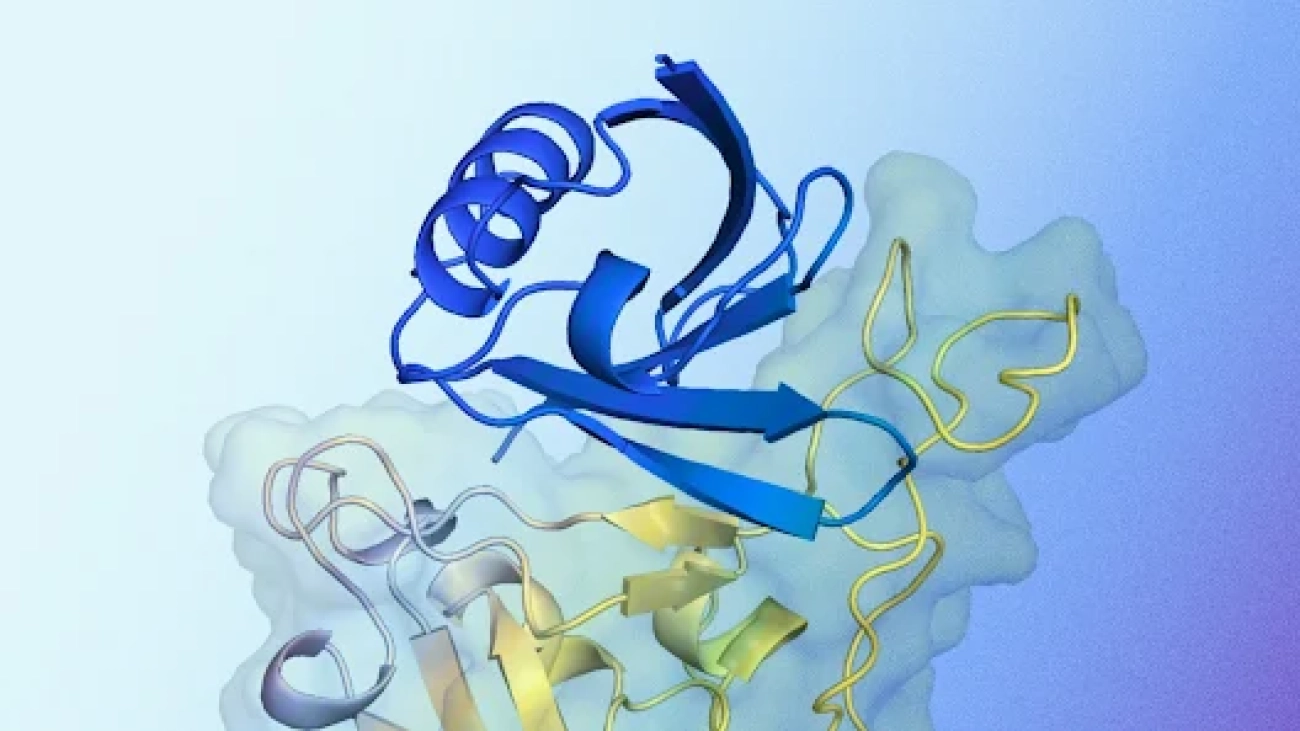
New AI system designs proteins that successfully bind to target molecules, with potential for advancing drug design, disease understanding and more.Read More
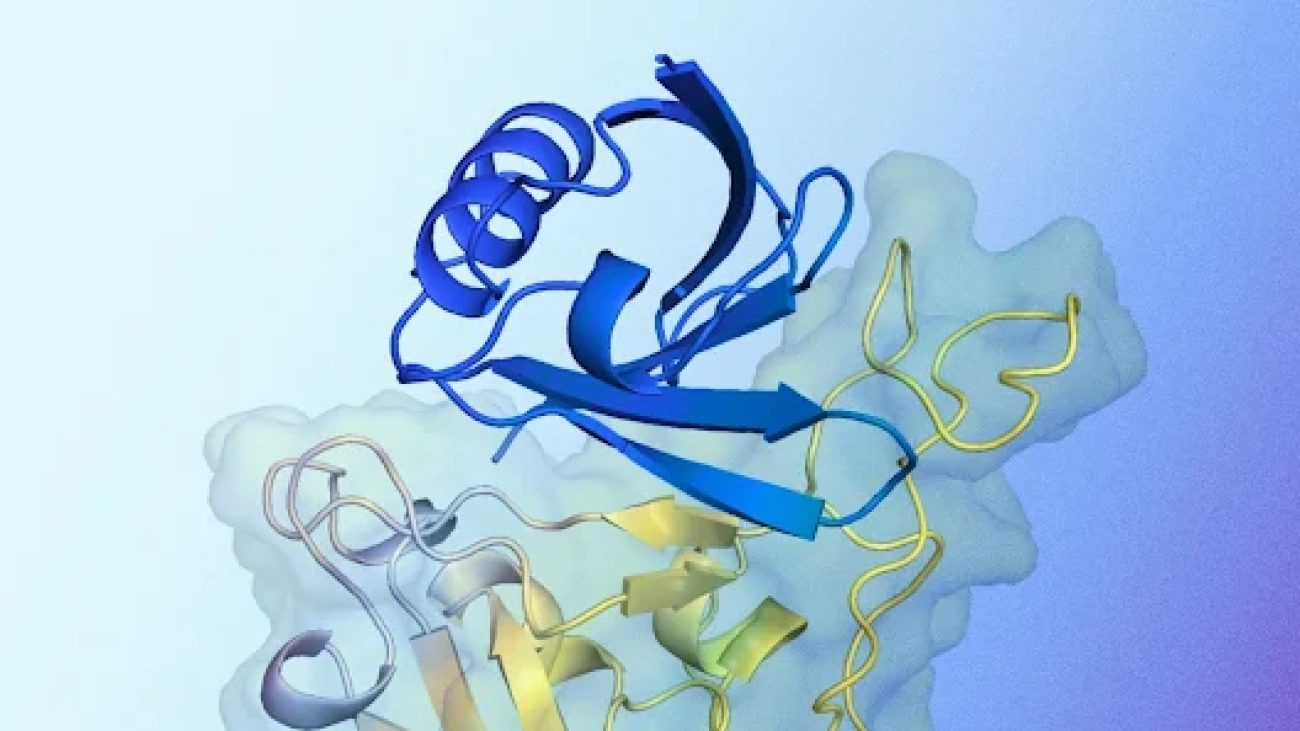
New AI system designs proteins that successfully bind to target molecules, with potential for advancing drug design, disease understanding and more.Read More
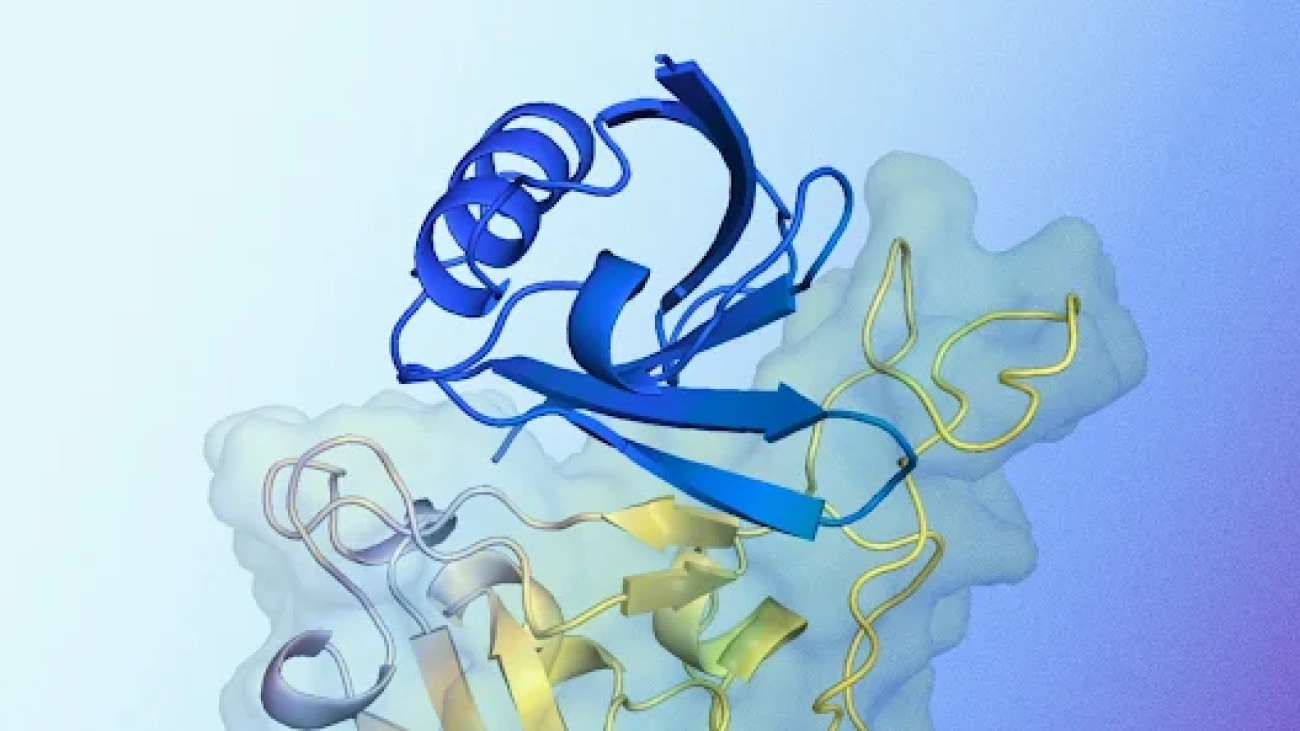
New AI system designs proteins that successfully bind to target molecules, with potential for advancing drug design, disease understanding and more.Read More
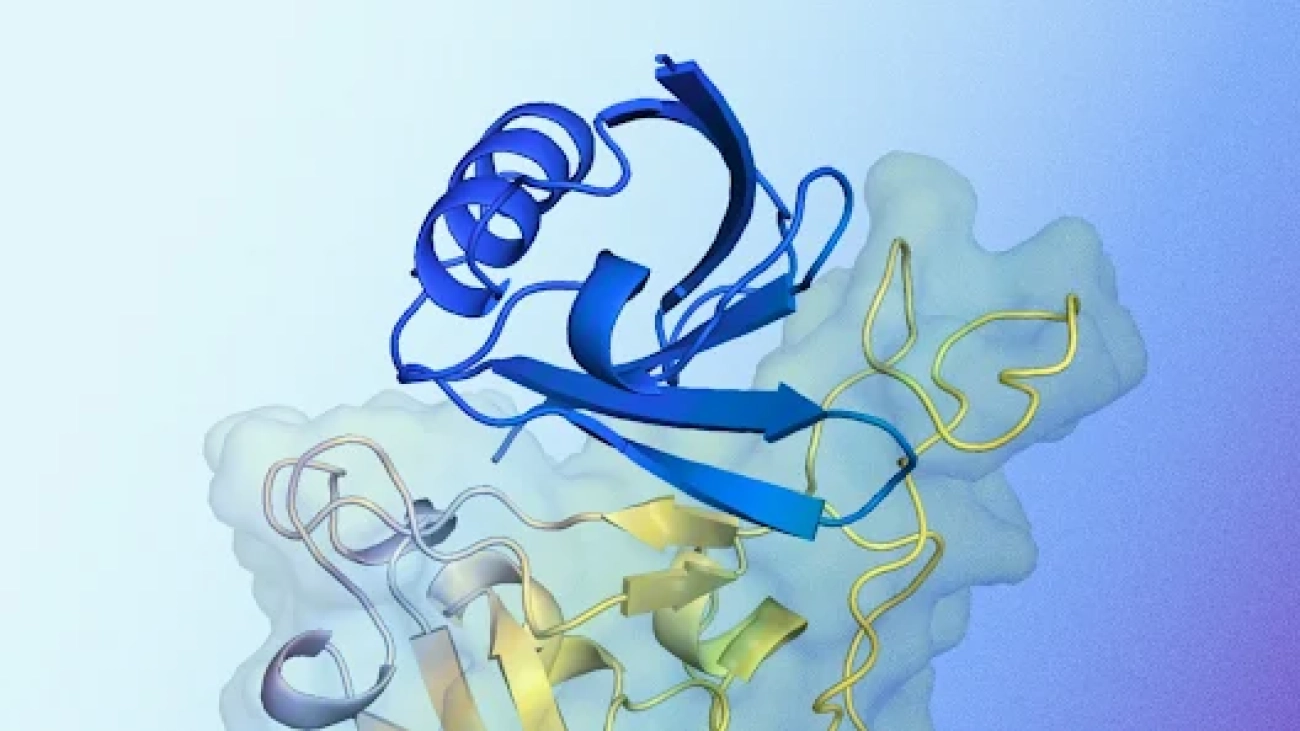
New AI system designs proteins that successfully bind to target molecules, with potential for advancing drug design, disease understanding and more.Read More

Using deep learning to solve fundamental problems in computational quantum chemistry and explore how matter interacts with lightRead More

Using deep learning to solve fundamental problems in computational quantum chemistry and explore how matter interacts with lightRead More

Using deep learning to solve fundamental problems in computational quantum chemistry and explore how matter interacts with lightRead More

Using deep learning to solve fundamental problems in computational quantum chemistry and explore how matter interacts with lightRead More