Posted by Sella Nevo, Senior Software Engineer, Google Research, Tel Aviv
Flooding is the most common natural disaster on the planet, affecting the lives of hundreds of millions of people around the globe and causing around $10 billion in damages each year. Building on our work in previous years, earlier this week we announced some of our recent efforts to improve flood forecasting in India and Bangladesh, expanding coverage to more than 250 million people, and providing unprecedented lead time, accuracy and clarity.
To enable these breakthroughs, we have devised a new approach for inundation modeling, called a morphological inundation model, which combines physics-based modeling with machine learning (ML) to create more accurate and scalable inundation models in real-world settings. Additionally, our new alert-targeting model allows identifying areas at risk of flooding at unprecedented scale using end-to-end machine learning models and data that is publicly available globally. In this post, we also describe developments for the next generation of flood forecasting systems, called HydroNets (presented at ICLR AI for Earth Sciences and EGU this year), which is a new architecture specially built for hydrologic modeling across multiple basins, while still optimizing for accuracy at each location.
Forecasting Water Levels
The first step in a flood forecasting system is to identify whether a river is expected to flood. Hydrologic models (or gauge-to-gauge models) have long been used by governments and disaster management agencies to improve the accuracy and extend the lead time of their forecasts. These models receive inputs like precipitation or upstream gauge measurements of water level (i.e., the absolute elevation of the water above sea level) and output a forecast for the water level (or discharge) in the river at some time in the future.
The hydrologic model component of the flood forecasting system described in this week’s Keyword post doubled the lead time of flood alerts for areas covering more than 75 million people. These models not only increase lead time, but also provide unprecedented accuracy, achieving an R2 score of more than 99% across all basins we cover, and predicting the water level within a 15 cm error bound more than 90% of the time. Once a river is predicted to reach flood level, the next step in generating actionable warnings is to convert the river level forecast into a prediction for how the floodplain will be affected.
Morphological Inundation Modeling
In prior work, we developed high quality elevation maps based on satellite imagery, and ran physics-based models to simulate water flow across these digital terrains, which allowed warnings with unprecedented resolution and accuracy in data-scarce regions. In collaboration with our satellite partners, Airbus, Maxar and Planet, we have now expanded the elevation maps to cover hundreds of millions of square kilometers. However, in order to scale up the coverage to such a large area while still retaining high accuracy, we had to re-invent how we develop inundation models.
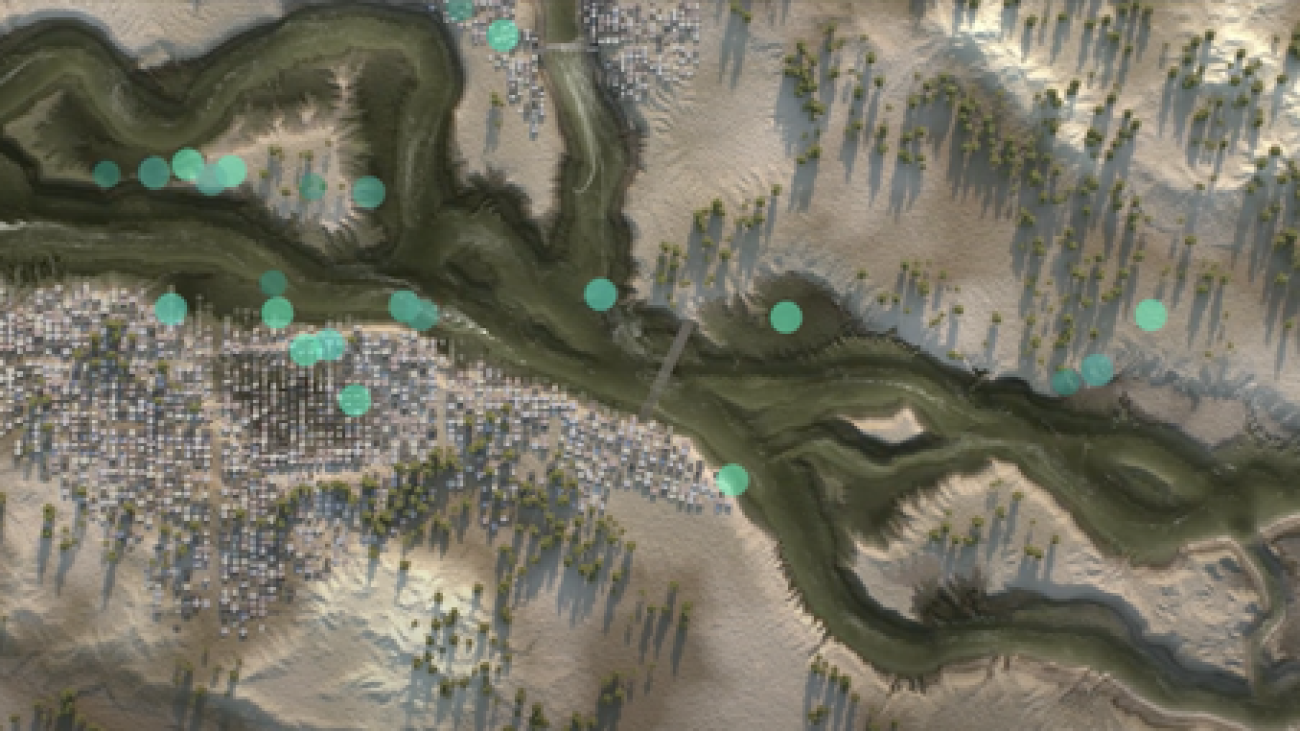
 |
| Inundation modeling estimates what areas will be flooded and how deep the water will be. This visualization conceptually shows how inundation could be simulated, how risk levels could be defined (represented by red and white colors), and how the model could be used to identify areas that should be warned (green dots). |
Inundation modeling at scale suffers from three significant challenges. Due to the large areas involved and the resolution required for such models, they necessarily have high computational complexity. In addition, most global elevation maps don’t include riverbed bathymetry, which is important for accurate modeling. Finally, the errors in existing data, which may include gauge measurement errors, missing features in the elevation maps, and the like, need to be understood and corrected. Correcting such problems may require collecting additional high-quality data or fixing erroneous data manually, neither of which scale well.
Our new approach to inundation modeling, which we call a morphological model, addresses these issues by using several innovative tricks. Instead of modeling the complex behaviors of water flow in real time, we compute modifications to the morphology of the elevation map that allow one to simulate the inundation using simple physical principles, such as those describing hydrostatic systems.
First, we train a pure-ML model (devoid of physics-based information) to estimate the one-dimensional river profile from gauge measurements. The model takes as input the water level at a specific point on the river (the stream gauge) and outputs the river profile, which is the water level at all points in the river. We assume that if the gauge increases, the water level increases monotonically, i.e., the water level at other points in the river increases as well. We also assume that the absolute elevation of the river profile decreases downstream (i.e., the river flows downhill).
We then use this learned model and some heuristics to edit the elevation map to approximately “cancel out” the pressure gradient that would exist if that region were flooded. This new synthetic elevation map provides the foundation on which we model the flood behavior using a simple flood-fill algorithm. Finally, we match the resulting flooded map to the satellite-based flood extent with the original stream gauge measurement.
This approach abandons some of the realistic constraints of classical physics-based models, but in data scarce regions where existing methods currently struggle, its flexibility allows the model to automatically learn the correct bathymetry and fix various errors to which physics-based models are sensitive. This morphological model improves accuracy by 3%, which can significantly improve forecasts for large areas, while also allowing for much more rapid model development by reducing the need for manual modeling and correction.
Alert targeting
Many people reside in areas that are not covered by the morphological inundation models, yet access to accurate predictions are still urgently needed. To reach this population and to increase the impact of our flood forecasting models, we designed an end-to-end ML-based approach, using almost exclusively data that is globally publicly available, such as stream gauge measurements, public satellite imagery, and low resolution elevation maps. We train the model to use the data it is receiving to directly infer the inundation map in real time.
 |
| A direct ML approach from real-time measurements to inundation. |
This approach works well “out of the box” when the model only needs to forecast an event that is within the range of events previously observed. Extrapolating to more extreme conditions is much more challenging. Nevertheless, proper use of existing elevation maps and real-time measurements can enable alerts that are more accurate than presently available for those in areas not covered by the more detailed morphological inundation models. Because this model is highly scalable, we were able to launch it across India after only a few months of work, and we hope to roll it out to many more countries soon.
Improving Water Levels Forecasting
In an effort to continue improving flood forecasting, we have developed HydroNets — a specialized deep neural network architecture built specifically for water levels forecasting — which allows us utilize some exciting recent advances in ML-based hydrology in a real-world operational setting. Two prominent features distinguish it from standard hydrologic models. First, it is able to differentiate between model components that generalize well between sites, such as the modeling of rainfall-runoff processes, and those that are specific to a given site, like the rating curve, which converts a predicted discharge volume into an expected water level. This enables the model to generalize well to different sites, while still fine-tuning its performance to each location. Second, HydroNets takes into account the structure of the river network being modeled, by training a large architecture that is actually a web of smaller neural networks, each representing a different location along the river. This allows neural networks that are modeling upstream sites to pass information encoded in embeddings to models of downstream sites, so that every model can know everything it needs without a drastic increase in parameters.
The animation below illustrates the structure and flow of information in HydroNets. The output from the modeling of upstream sub-basins is combined into a single representation of a given basin state. It is then processed by the shared model component, which is informed by all basins in the network, and passed on to the label prediction model, which calculates the water level (and the loss function). The output from this iteration of the network is then passed on to inform downstream models, and so on.
 |
| An illustration of the HydroNets architecture. |
We’re incredibly excited about this progress, and are working hard on improving our systems further.
Acknowledgements
This work is a collaboration between many research teams at Google, and is part of our AI for Social Good efforts. We’d also like to thank our Geo and Policy teams, as well as Google.org.
 Read More
Read More