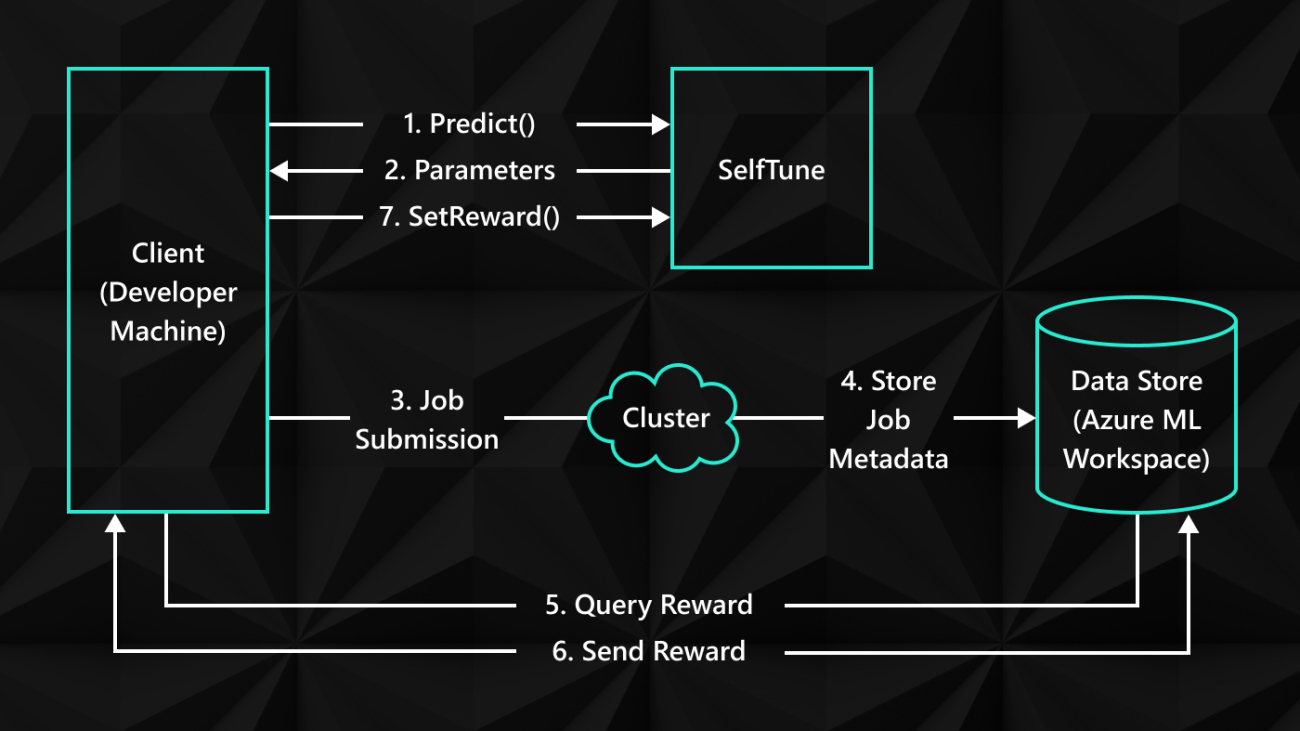
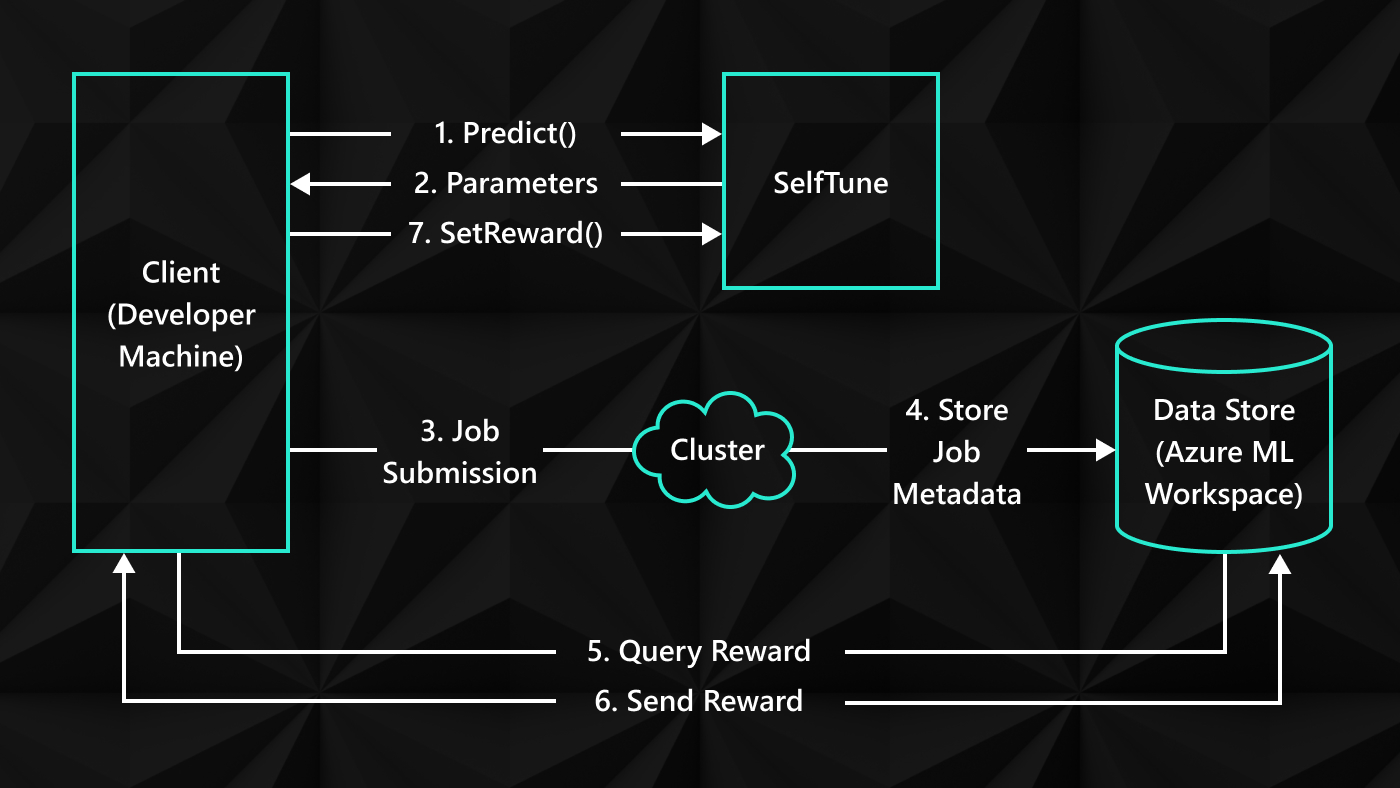
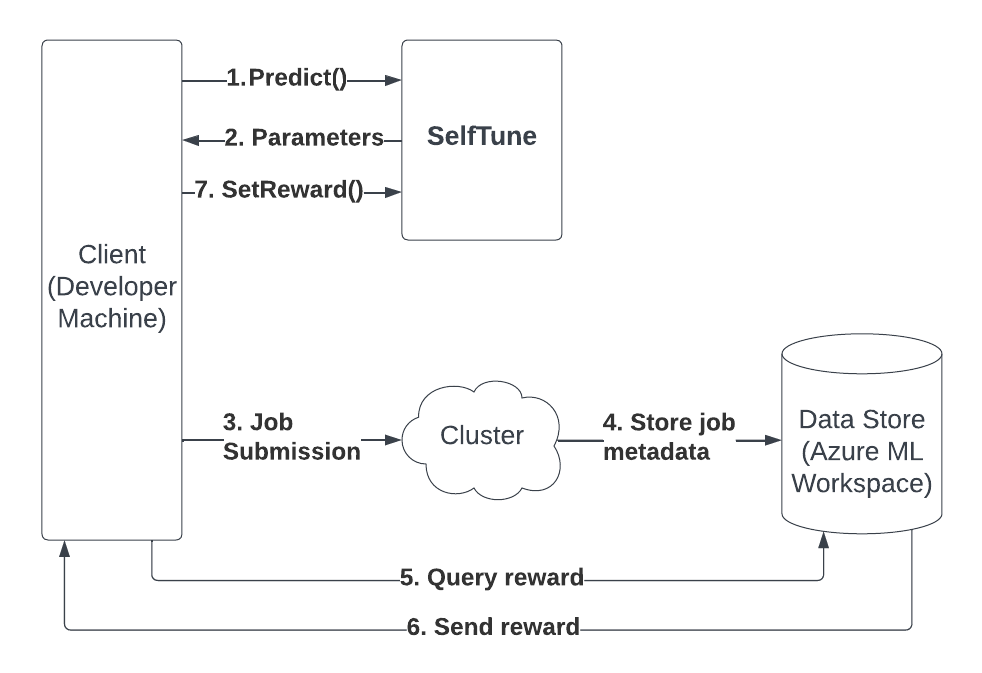
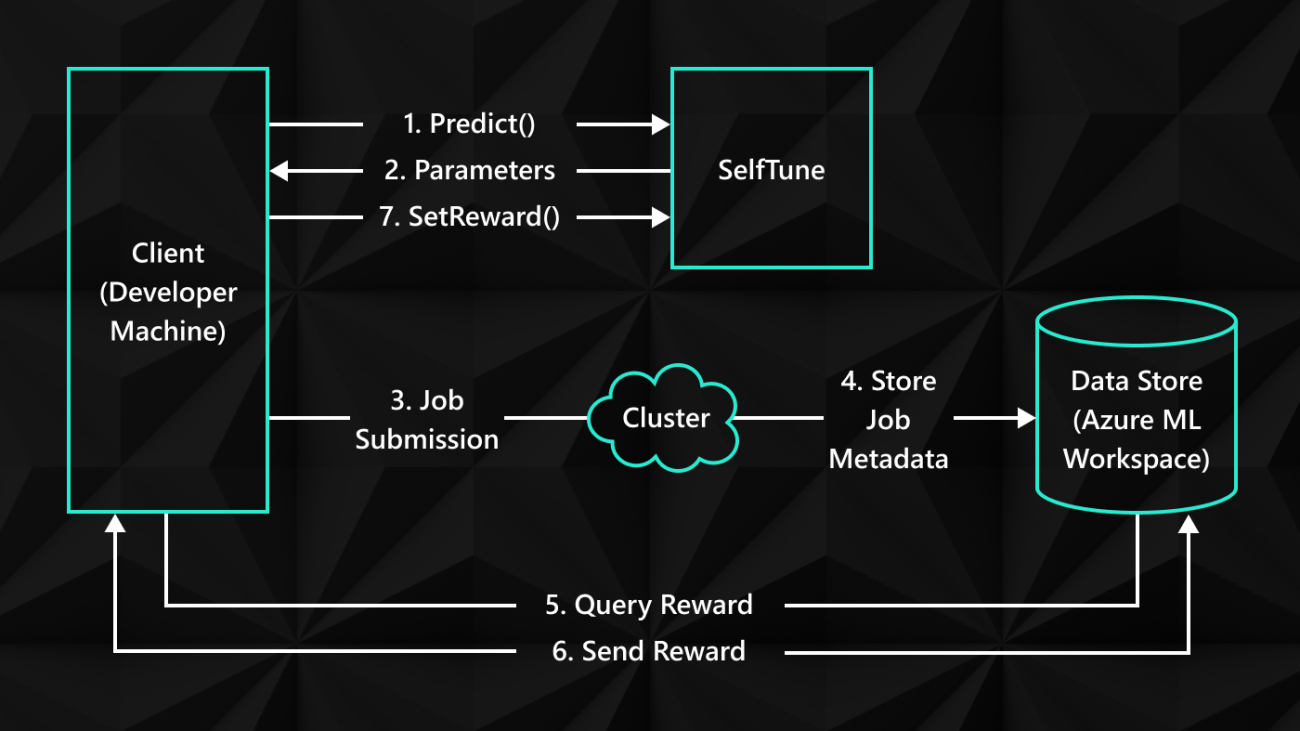
[MUSIC ENDS]
Welcome to Episode 1 of Collaborators. Today, I’m joined by our first two guests, Petar Maymounkov and Kasia Sitkiewicz. Petar and Kasia are working on a project that has collaboration in its DNA: Gov4git, a decentralized, transparent, and secure git-based protocol for governing open-source communities that they say circumvents more costly approaches to things like validation and dispute resolution.
We’re going to unpack all of that in this episode. But before we do, let’s get to know our collaborators. Kasia, let’s start with you. You’re at GitHub, “an open-source platform for collaborative software development and version management.” This platform is well-known in the dev community but give us a brief elevator tour of GitHub and particularly what your role is there.
KASIA SITKIEWICZ: Sure. So I’m happy to give an overview of GitHub. Uh, GitHub is primarily known to be a home for all developers and open-source communities. It’s one of the most popular resources for developers, as you mentioned, to share code and work on projects in collaboration. It makes [it] super easy for developers to share code files and collaborate with each other using GitHub issues, which we will be referencing in the podcast, and pull requests, uh, which we call PRs. So imagine GitHub issues being like a project description or some kind of information that what needs to be built, and PRs, um, are pretty much amendments to the code change that a community wants to merge with the main code branch, uh, and that’s very well known among developer community. So pretty much like that’s how we use version control. We know what needs to be changed, what needs to be merged, and community pretty much participates in all of those changes. And what I do at GitHub, uh, I work as a product manager. I oversee growth for GitHub Enterprise Cloud and GitHub Advanced Security, and on the side, I collaborate with Microsoft, Web3, and Microsoft Research team on, uh, working on projects like Gov4git or other Web3 partnerships where I represent GitHub and, um, trying to onboard and make those projects successful.
HUIZINGA: So there’s meta-collaboration, and then there’s micro-collaboration, and collaboration all over the place in GitHub.
SITKIEWICZ: Exactly. Yes, we, we do like to collaborate.
HUIZINGA: [LAUGHS] Well, you’re perfect for this show. So, Petar, you’re at Protocol Labs, “an open-source research, development, and deployment laboratory.” And, and you say you’re “building the next generation of the internet and making human existence orders of magnitude better through technology.” No pressure, right? Briefly tell us about Protocol Labs and your role in taking the internet and humanity to the next level.
PETAR MAYMOUNKOV: Yeah, um, first, thank you for having us. Since you’re asking about the North Star mission of Protocol Labs, so to speak, I think it’s quite simple. I think it’s really trying to sort of create a better world that is both, um, it’s sustainable, fair, and inclusive, and it’s trying to do this through decentralization as a concept and technologies, of course, in particular. Now this is a mighty goal, and in practice, it, um, comprises essentially three workstreams, if you will. Um, the first thing is decentralized infrastructure, because it’s not possible to, to build anything useful without the infrastructure, and in this regard, Protocol Labs is, um, essentially working on and stewarding, uh, two products Filecoin and IPFS, which provide decentralized infrastructure in a democratic way to the whole world essentially. Um, now the second workstream is, um—Protocol Labs was one of the companies to realize early on that, uh, whenever decentralized technologies are involved, um, they go hand in hand with, uh, enabling everybody to contribute, so this raises the question of decentralized development, which is how do people collaborate across country boundaries, backgrounds, different levels of experience, and so forth. So along with all the engineering efforts, Protocol Labs is also essentially innovating workflows and culture about being productive in a decentralized development kind of, um setting. And the final workstream, uh, which kind of shows you how long term the vision is in Protocol Labs, so we recognize that, um, we cannot have a sustainable, decentralized world unless we replicate some of the important, um, sort of processes that happen in the real world, in particular the research-to-development innovation pipeline. So in the real world, this goes from academia to industry, and so forth. And part of, um, why this question is new and not the same as in the real world is because, uh, decentralized products being a type of public good, um, do not succumb to the same incentive mechanisms that drive the conventional economy. So we, we have a department called network funding and funding of public goods, which is itself involved in thinking about new mechanisms and incentives for, for making this, this process work in a repeatable fashion, basically. And my, uh, my role currently in the company is, uh, to think about facilitating decentralized development through standardized tools and protocols.
HUIZINGA: Gotcha. Well, as we’re talking about collaboration and collaborators and you two are at two different companies, I’m going to call this question “how I met your mother”! How did Gov4git come about, and what was the initial felt need that defined the purpose? And as you answer that, tell us who’s all involved and how you each got involved on the team. Kasia, I’ll let you take the lead on this one.
SITKIEWICZ: Sure. So I guess on my end, it all started through the passion I have for open source and the idea of decentralized communities. As I mentioned, I’m part of a lot of, uh, projects here at Microsoft and GitHub, and one of them is Web3 and Plural Technology Collaboratory that is led by Glen Weyl, and a few months ago, Glen and I, we had a conversation about how amazing git is and how amazing our GitHub communities are and overall like the efforts that they are working on towards like better world, public goods, and so on, and I share my vision for GitHub to be a tool or platform that can be accessible by anyone around the world where people can collaborate, they can own, uh, share and like earn money pretty much because of those contributions that they have. So we talk about this vision and we share the same kind of like a passion for all of those different projects and, you know, aspects of like open source, and he mentioned like, “Hey, we’re actually working on this like open-source book, uh, that will be hosted on GitHub, and we would love to do some kind of collaboration here.” And then he introduced me to Petar and Protocol Labs, and we had our first intro call. Uh, we learned like what is the objective, what problems we are trying to solve, and we put a small team of GitHub, Microsoft, and folks from Protocol Labs and a few folks also from open source, like purely I put a tweet about like, “Hey, I’m looking for contributors to this amazing project that will help with governance for open source,” and few folks reach out, and that’s how we kind of put it together.
HUIZINGA: Right. Petar, how do you see the, the thing coming around?
MAYMOUNKOV: So I had been working for Protocol Labs for about three and a half years. The first couple of years, I spent most of my time engineering and sort of being in the real-world decentralized development kind of environment, so I saw lots of things that work well; I saw lots of things that need improving; and over time, I developed an interest to kind of address, uh, this question sort of systematically and head on, which is when I, um, started working specifically just on this problem. And about six months ago or so, when I was starting, I was initially researching the space and what’s known. This is how I ran into Glen Weyl’s work, so eventually, we, we connected, and, um, I read sort of most of the stuff that he’s been working on and tried to sort of find a connection between this and what I knew from, from the trenches, if you will, from the engineering department, and then—and then, you know, he connected us with, um, with, uh, with Kasia. But the thing that sparked it, though, so at some point, Glen did sort of point out the specific project that he was trying to initiate, the plurality book, and this was kind of the thing that put a shape to our efforts because it was a very concrete task that we needed to figure out how to like address and accomplish in like a reasonable time.
HUIZINGA: Yeah, so, so let’s get sort of granular about Gov4git and what it is, because I don’t think we’ve defined that, uh, from the get-go here, so, Kasia, can you kind of explain what it is and why it’s different?
SITKIEWICZ: Sure. So Gov4git is pretty much a tool that helps, uh, open-source community to govern their community members in a more efficient, transparent, and easy way. There is a lot of problems in traditional governance model for any communities, and the larger communities are, there, there are more problems. And Gov4git is trying to solve a very particular problem of giving autonomy and ownership to the community to make decision what needs to happen and what changes the community needs to prioritize in order to make the project more successful. So, it’s just a solution that helps you to govern your communities in an efficient way.
HUIZINGA: Yeah, so even as we’re talking, I’m thinking, OK, you’ve got Microsoft Research, you’ve got GitHub, you’ve got Protocol Labs. But do you use this to govern the things that you guys are working through as a community collaboration?
MAYMOUNKOV: The tool itself is essentially implementing processes that kind of have organically emerged both in, in the context of Protocol Labs, as well as even other organizations like Ethereum. Um, I mean, this is the process of people kind of collaborating on specifications for decentralized protocols and so forth. For the particular—for Gov4git specifically, since the tool is still, uh, in some sense under development, but it, but it is kind of approaching MVP, we have used it internally as, as dog food, um, but not at large scale yet.
HUIZINGA: Right. Gotcha.
SITKIEWICZ: Yeah. And I think the beauty of Gov4git is actually very useful when you have a bigger community. Right now, our team is very small. It’s just like, uh, six people working together, so—and this is something I want to elaborate a little bit more in our, later in the podcast—but the smaller community, there is less problems, and you kind of make a decision on the fly, on the go, like, “Hey, what are we going to build next? And should we, should we focus on this or that?” So you can actually make those decisions without really spending too much time. And that’s a beauty for all startups moving fast, but the moment the community grows, you have those constraints and problems. So Gov4git is precisely designed for those growing communities and making sure the communities grow in like a very healthy way versus like there is a stop at some point where, like, you cannot make a consensus because of, you know, this person is out, or I don’t have enough information, or I don’t have rights or permissions to make those changes. So, uh, we—like Petar said—we dogfood the code, but at the same time, the use cases are like for a little bit bigger groups and communities.
HUIZINGA: Well let’s get specific about the problems and solutions from a technical perspective. And, um, Petar, I’m going to ask you to take the lead on this. As I understand Gov4git from my non-technical perch, it’s a sort of sandbox for community governments mechanisms. How would you define the problems you’re trying to solve with Gov4git, and how are you going about solving them technically?
MAYMOUNKOV: Yeah, this is a good way of putting it. It’s, it’s a sandbox for governance, um, solutions, so, um, indeed I have the, um, technical kind of part of this, um, project. And from, um, from a computer science point of view, governance is synonymous with trusted computation. So trusted computation is, is an abstraction or a notion whereby there is a public, uh, program or rules of governance and the community has a method of kind of—there is a, there is a device that, that executes and follows the rules of governance and the community members have, um, assurance that the rules are followed as advertised and that nobody can sidestep the system regardless of their role in the community. So governance is trusted computation to scientists, basically. Now, uh, trusted computation being a general abstraction is, is something that has various embodiments in the real world, and the most, uh, famously known currently embodiment of trusted computation are public blockchains such as Ethereum, Filecoin, and others. So we could have sort of chosen to use these existing solutions to how you build governance applications, um, but we ran into a number of practical issues with them that prevent us from delivering sort of practical results in a reasonable amount of time. And also, there are some shortcomings that prevent these solutions from reaching people in unprivileged parts of the world, so developing world, war zones, authoritarian countries. Uh, so effectively, Gov4git from a technical standpoint is a different embodiment, a different implementation, of trusted computation, which is not in competition with public blockchains. It captures a, a different tradeoff, so to speak.
HUIZINGA: OK, talk a little bit more about the tradeoff. I mean, some of these things would represent to me a barrier to entry—I wouldn’t be able to, um, afford it. What are some of the, the upsides to Gov4git that, um, we don’t find in the other spaces?
MAYMOUNKOV: Yeah, so to make a fair comparison, I should first give some context on the existing blockchains. Um, so the existing blockchain technologies are quite exciting, um, and they, they’re very promising. But currently, they’re in a state of having overshot in their level of ambition and slightly underdelivered, at least for the present time, and I’m sure they will eventually deliver, uh, sort of completely. So what do I mean by this? So they have overshot in the sense that they are—they provide so many features and, and they capture an extremely large set of applications, but at the same time, this of course involves a lot of complexity that they need to deal with, and this complexity hasn’t been fully sorted out yet to make them usable for sort of common cases. So what, what we’ve noticed here is that there is a large group of applications, in particular community governance, which does not need most of the features that are provided by public blockchains. And so once you realize that this is the case, you unlock much simpler solutions that have the same sort of outcome for the users. So public blockchains—let me be a little bit specific here for the technical listeners—so public blockchains, they’re global systems, so across the world. They’re capable of hosting multiple independent applications. Uh, you can think of this as independent communities which need to interact with each other at very high speeds and with a very high throughput. So the typical applications that you can think of is essentially high-volume, cross-community business or trade interactions. And, of course, this is a real use case, especially with financial systems and so forth. But, um, in contrast, community governance applications, which are sort of designed to serve humancentric deliberative processes within a community, they’re not global; they’re local to a community. They are not multiple applications; they are a single application that governs one community. And because they are human-deliberative applications, they don’t need high speeds and high throughput, so recognizing that these, um, this is the case, alternative designs for trusted computation, um, sort of emerge and this is what we’ve, what we went after.
HUIZINGA: That’s, that’s awesome. Well, and so, Kasia, let’s go back to a little bit because we’re going to cross over here. There’s a couple of themes that are emerging that I think are really interesting. Um, you talk about, earlier, the issues in pull requests that you deal with and that Gov4git has some mechanisms to help address the tension between what I might call anarchy and dictatorship. Is there some kind of a, a mechanism that’s different that can help mitigate that?
SITKIEWICZ: Yeah, absolutely. So, as I mentioned, there are different types of communities, and the bigger the community gets, the more issues you have. Within smaller community, you pretty much know who you’re interacting with; you know the contributors; you know who is the maintainer. And it’s actually quite fast to make those changes and like approving those pull requests and reviewing comments and issues and other activities that are happening around every project. With the bigger communities, there’s more, uh, logistics problem and governance problem, and many times, you truly don’t know who is contributing to your code source. You just know their handle. That can be anyone; that can be even some kind of like ChatGPT, especially with like right now like the generative foundation models. Like we’re going to see more problems of like interacting with non-humans, right? So I feel like communities will have more and more problems facing like, “OK, how do I manage my contributors, and, uh, how fast we want to move the project?” So Gov4git is using, uh, a lot of like beautiful features from Web3, which is quadratic voting. It’s, uh, pretty much collective decision-making procedures that involve individuals who are part of your community with allocating votes to express the degree of their preferences. So as you mention, in a traditional organization, there is one person or one dictator that tells you like, “Hey, you’re going to build that.” And once we have it, we’re going to like approve it, right? And we’re going to like ship it. With quadratic voting, the decision is made collectively. So we’re going to implement quadratic voting part of our governance model. Second feature that is also very nice is like the governance tokens. Right now, um, communities, there are few ways of like how they make decisions, either majority of the votes or through consensus. With this type of governance tokens, you will be able to see like how many people voted on a specific pull request or a feature, and the majority of the votes will be pretty much the decision-making. So community can use those governance tokens for making the decision. And lastly, uh, there is a concept of badges. So in the Web3 space, there are like NFTs, and one of the NFTs is a soulbound token, which is a token that you are given that you cannot transfer, and we believe that by implementing those soulbound tokens, you can authenticate the user, you can say, “Hey, I know you; you’re part of this community; you got this badge.” And that badge gives you, let’s say, right to receive those tokens and so on. So again, those are just like a few features that are actually like very nice in that decentralized communities that we want to bring into Gov4git so that the communities can benefit from having specific features like, uh, quadratic voting, governance tokens, or like those badges. And what I want to say is like, you know, GitHub or like other git platforms, they don’t support this type of governance features, and that’s the need from the users and customers being like, “Hey, I need something that will be very easy, efficient, and transparent,” and Gov4git provides all of it.
HUIZINGA: Yeah. Well, and on that same topic, Petar, I always like to ask what could possibly go wrong, and even as Kasia’s talking, all kinds of things are coming into my head like, um, could a bot get an SBT or, I mean, do you have to be, provide validation to who you are and what you represent yourself as?
MAYMOUNKOV: Yeah, so, um, let me answer the general question and the specific question. So I think the specific question about bots is that, has the following answer. So I think people in Microsoft Research in particular, but people in general, are realizing that identity is going to be much harder to, uh, prove and understand in the presence of AI. And so here we kind of—especially Glen, sort of leading with his paper on soulbound tokens, is essentially looking into something that we do in the real world, uh, which is that we have deep ways of verifying people’s identity by essentially, um, looking into their history with communities and within society. Uh, so the presence of these badges that Kasia is mentioning is essentially creating a system whereby people can collect certificates from different endeavors that they have participated in to build out a résumé that is verifiable by the communities where they participated that they are who they are. In some, in some sense, the person is the sum total of everything they’ve done for other people. And currently, a bot cannot accomplish as much as a person and get sort of, you know, certificates from other humans that this has been the case. So roughly, this addresses the question of, OK, can something go wrong with, with bots. In a sense, bot or not, to be acknowledged in a system, you have to have contributed verifiably to, to multiple communities eventually. Um, but there is a bigger sort of picture about what can possibly go wrong. And so in this regard, Gov4git kind of sits in a very standard situation with most, uh, very promising software tools, which is that it, it is, it is a powerful tool that can fall in the hands both of good and bad people, acknowledging the fact that good and bad are relative terms. And, and this is, this actually also plays on a, on a general theme in software and science, which is that software engineers and engineers, scientists and so forth, they design software which is symmetric, so the software from the start treats everybody in the same way. It doesn’t have a way of distinguishing, you know, who’s using it. And even though this sounds like the right place to be—it’s a neutral place to be—there are plenty of cases already in the real world where, um, it is unclear, you know, whether society wants symmetric treatment of everybody. The, the classical example here that I would give is, is Twitter. When it comes to the question of censorship on Twitter, there’s a few different alternative, um, kind of directions that that people can think of, of taking. One direction is to say that, uh, no censorship should happen, uh, which is the symmetric treatment. So everybody gets the same agency within a system. But as you know, there’s plenty of people who don’t like this approach. There’s other approaches, such as “somebody should censor us.” But who’s, who’s the somebody? So, so these kinds of issues all apply in this case, as well, because if governance for git is to be successful, what I hope, or, you know, cautiously hope, that it will result in, it’ll enable communities to forum at a much larger speed and a much larger volume around the world. And usually, when things speed up for humans, just like Twitter sped up discourse between people, um, we tend to find ourselves in a situation where we are slightly unprepared to, to, to reason about where does this go.
HUIZINGA: Right. Kasia, what do you have to add to Petar’s conversation there on the “what could go wrong” from your end?
SITKIEWICZ: I think from the product side—and I can speak as a product manager—there might be a case where like the community will come back to us like, “Hey, this is not what we want. We want something different,” right. Which, it’s a hypothesis, and can, this can, this feedback can happen, right. But at the same time, I believe that the community will ask for more. So like we are building just a very simple MVP to pretty much let the community to make those decisions, but perhaps the direction might be like, “Hey, the value’s somewhere else.” Uh, because once we launch, we can learn like, OK, this is great, but it’s not enough. So I would speak from the product side and like the user testing that perhaps we might discover like, oh, the actually true value will be somewhere else, and perhaps it can be a quadratic voting; it can be those tokens or those badges, right. So from my end, I feel like that’s the biggest like unknown, and speaking about bots and, uh, all the AI work, I feel like there is a lot of value in that, as well. So it’s not just a negative aspect of like, “Hey, I don’t want automation to be part of my project.” I think we will see it more, and there will be a lot of benefits. It’s just there are a lot of things we do not know as of now, and we just have to make sure like we are very flexible in terms of like how we pivot and how we adapt to feedback.
HUIZINGA: Right. But, but in other ways, GitHub itself and Gov4git is a platform for people to form their own communities and govern their own communities, right? So you’re not going to be sort of the 10,000-foot hall monitor and try to meta-govern the people that are governing their own communities, correct?
MAYMOUNKOV: Yes. SITKIEWICZ: That’s correct, yes.
HUIZINGA: They’re nodding their heads. It’s a podcast—you can’t see it! [LAUGHS] Well, and this, this discussion on the “what could possibly go wrong” is important for me because I think people who are going to use the technology want to know that people promoting it are aware of the potential for unforeseen and unintended consequences and have a plan for mitigating. But it’s such an interesting ramp up to this new kind of use case for collaborative, open-source governance that it’s really cool. Kasia, let’s talk specifically about some of those use cases from the product side that you’ve alluded to. Um, GitHub is well known in the developer community, but how’s the idea of decentralized open-source work moving into non-technical communities and applications?
SITKIEWICZ: Yeah, absolutely. So in any open-source project, you will find very technical contributors and maintainers and also you will find people who just like want to like observe the project or perhaps help with like project management or translation and so on. So we already have a lot of non-technical contributors who perhaps are struggling when they first log in to GitHub and they learn about git. They were like, “What the heck is that?” It’s a black box. So we truly get that feedback from customers. It’s like a very overwhelming experience, and it takes some time to wrap up and kind of learn how to use it. So the idea for Gov4git is pretty much a very simple presentation, or UI, via extension, Chrome extension, where you will see something very familiar like you see on Twitter, where you have like a post that you need to vote on, and if you are eligible to vote, you will, you’ll be able to use your tokens, uh, and vote on the decision, and you will be able to comment and interact with the community, and so on. So the ultimate goal is to create something very simple, just like a Twitter, you know, is simple, so that community is like, “Hey, I can participate, and I can put my vote, and I can contribute to this project.” So ultimately that’s the case. And the way—how we will be testing it, we talked about this book. So the book is called Plurality: Technology for Collaborative Diversity and Democracy, and it’s led by Audrey Tang and Glen Weyl and with, along with the plurality community. So the Plurality, it’s an open git-based collective book project that aims to offer a vision for the future of technology focusing on empowering and bridging social differences. So that book is on GitHub, and collaborators and maintainers who are participating are writing this book in an open-source way. And as you can imagine, writing a book is not an easy or trivial thing. You have a lot of reviews; you have everyone looking and providing feedback. So we believe that they can benefit from, uh, using Gov4git, with like management of like PRs and issues and decision-making. And, um, the initiative is already like there, right; it’s started. So we are just like trying to see like how that can—book can be completely managed by a community versus like Audrey or Glen has to like spend a lot of hours to review all of those PRs. And it sometimes is very challenging, and it’s almost impossible to go every single comment, so we believe that this can help and expedite the process and make it very transparent and efficient way to write in open source.
HUIZINGA: Petar, talk a little bit about the other applications, including this one, from a technical perspective. Um, what makes it easier to resolve arguments and make edits with Gov4git versus other mechanisms to do that?
MAYMOUNKOV: Gov4git, being a sandbox, at least technologically, is not trying to be prescriptive about how people do this. We’re trying to enable people to, to, to pick the mechanisms that they want for themselves, for arbitrating conflicts, so, you know, starting with, with Glen’s project, of course, we are starting with quadratic voting, and we plan, um, the quadratic voting is a, is a large, at this point, field. There’s lots of different variants of it. So we, we build the product so that over time Glen and Audrey can experiment with, you know, different types of conflict resolution and, and so forth. What Gov4git provides is the ease of adding a new mechanism that the community wants. And of course, we plan to have a library of like mechanisms that people can choose from. One nice side benefit from this entire project is that Gov4git, uh, enables people to like reflect on what they’ve done and, and what is happening. So with Gov4git, you always have a complete history, both of the governance motions of, of the community, alongside with the actual open-source collaborative work, which in particular enables academics and researchers from organizations such as the Metagovernance Project being a good example to go in there and study what types of mechanisms make for better results, basically, and kind of improve iteratively over this.
HUIZINGA: Yeah. So it sounds like there’s a spectrum of assessment or meta-governance testing with computer scientists, product managers, academics. Even there, you see this great collaboration happening. Go back to the, the academics and other, uh, collaborators that are coming in on this. Do you find a broad spectrum of disciplines involved, not just computer scientists in academia but perhaps social scientists, legal scholars, any of these kinds of things coming into this?
MAYMOUNKOV: Um, it’s too early to tell, but, uh, but there has been indeed interest, so, so from a few places, right. So the, the academics are indeed interested to, to consume this data when it’s available from real-world communities, because the key thing for them is to have real-world data like sufficiently scaled communities, like the Plurality book would be a great example because it’s probably expecting to have thousands of contributors. And otherwise, um, in addition to, uh, the Plurality book as like a first customer, so to speak, uh, we already have lots of interest from AI companies. So these are AI companies that are currently building open-source AI models, and they want to experiment with attaching governance to their open-source work, which is already happening on gits and GitHub. And they want—uh, because once you have governance plus open source, then you, you have a holistically democratic development of something like an AI tool.
HUIZINGA: Right. That just struck me that you say thousands of contributors to a book and you never [LAUGHS] think of that being the case. Um …
MAYMOUNKOV: Well, that’s a special, that’s a special book because it’s, it’s going to have translations in multiple languages, and being, being it, uh, also needs to be fact-checked, so there’s a lot of work on fact-checking that, that goes along with the writing process.
HUIZINGA: Yeah. Sounds a bit like wiki in terms of contributors and checking and making decisions and so on. Um, is, is Gov4git even in beta yet, or is it still just, um, sandboxing itself?
MAYMOUNKOV: Um, so the, the MVP—the first version, if you will—is, is ready and has been tested for a few months internally at Protocol Labs. What we’re missing and we’re still working on is like the user interface that brings in the non-technical users. So I guess you could say that it’s in beta. I think like our launch with the Plurality book would be the first kind of official introduction event.
HUIZINGA: Right. Yeah, and that’s an interesting, you know, when the outsiders looking in going open source, you think software, you think developers, you think code, but there’s a lot of other applications, including writing a book, which is basically just text-based writing. So, Kasia, are there any other sort of cream-floating-to-the-top applications or products that you could see coming out of this?
SITKIEWICZ: Technically, anyone who wants to start something new and is looking for collaborators, and it can be pretty much whatever you want to build. It doesn’t have to be like a big idea. It can be just, “Hey, I want to collaborate with someone, and I want to like figure out how to do things and how to practice.” It can be used by academics, as you mentioned. Like pretty much any, any, any person who wants to start with like building something in public, they can do it and use it. So there is no limits. It’s up to you if you want to build community around the project you’re working on. So we don’t have any restrictions, and I feel like, um, we are in the stage right now or like this AI revolution where we’re just entering this like open-source community’s growth because there is like a lot of hype right now and everybody’s interested in it. Oh, maybe I can build that. It’s just so much easier to do things right now. And, you know, if you want to grow, you have to have a community around you. Um, so I think this is just like a best practices for anyone who wants to start writing in public. Whatever is that is—it might be like just a book or a code or like learning or like sharing some information. It doesn’t really matter. And, you know, being at GitHub, we see a lot of like amazing projects regardless of the discipline and like the area, and communities are just fascinating. And I think that’s the future. Like pretty much a lot of companies will start doing open-source code, just [like] Twitter has done it, right, just to bring the transparencies, because in a decentralized world, that’s like the value proposition, like, hey, it’s a very transparent way of building, and you have a history being displayed of the decision-making. And there are a lot of companies started noticing the beauty of it, and they—I think the movement is just starting, so I see a huge growth.
HUIZINGA: Yeah, and that leads into the last question I wanted to ask both of you, um, and you both alluded to some of this already in your answers, but just if you could encapsulate in your ideal preferred future, what is your work look like in five to 10 years? How have you changed the landscape of collaborative work, community governance, and even that concept of communities?
MAYMOUNKOV: So I hope that well within 10 years, this tool becomes perceived as a somewhat go-to tool for building, you know, communities from scratch, and, in particular, I actually hope that the tool reaches a critical point which you can label the beginning of intersectionality, to borrow a term from Glen’s, um, Glen’s vocabulary. Um, and what this means, this is a point where there is enough deployments of Gov4git that you have a non-trivial amount of people that are members of more than one community. So in other words, communities are starting to overlap, and when, when we reach this critical point, there’s a whole new set of applications that open up because now communities can, uh, interact with each other, uh, and ask each other for various kinds of help. The classical example here is that, um, one community can ask another community whether a given member has had a long and productive career in the other community. And this kind of idea—also mostly coming from Glen—is actually a mirror image of what I mentioned earlier, what happens in the real world. So when you apply for a job with, uh, an employer, the employer being a community, this employer calls up your university to verify that you actually went there and you did a good job. So you have these two communities basically sharing information. Um, so there’s lots of applications of intersectionality, but the reason I call this a critical point is because once you get there, you actually expect the network effect that we know from social networks to start taking place. In particular, if the network of communities using Gov4git is, is, is large and there’s lots of intersection, then any new communities being formed would benefit a lot from reusing the same technologies because now they can benefit from all of these other communities that already exist and that they can interoperate with. This is sort of a critical point, because, uh, if we reach it, then the tool really has a chance of becoming like an international standard for like conceiving communities, basically.
HUIZINGA: Yeah. Kasia, what would you add to that?
SITKIEWICZ: So I will speak a little bit more high level on the data we are seeing at GitHub, and what we believe that will happen is last year we hit 100 million developers being on our platform …
HUIZINGA: Wow.
SITKIEWICZ: … and they’re like thousands of thousand different open-source communities. And we, we see a huge growth, and especially with like the AI innovation that is happening in that space, I think this will like triple in the upcoming few years. So the more people start understanding the beauty of technology and collaboration and like writing in public, the more adoption we will have. So I think it’s just a matter of time how fast, uh, tools like Gov4git will grow and will be needed. We’re still early because there is, like we don’t know what we don’t know. We know the problem. But we don’t know how the problem will, um, intensify in the upcoming like months or years, right. So I truly believe that there is a need for it. There will be a huge growth in terms of like creating new communities, and people from around the world, they can unite through using platforms like GitHub or other services where they can actually engage with other people who are passionate about the same thing. So as you mentioned, open-source concept is not new, but it’s actually getting more in the strength, and the value’s there. So in my eyes, it’s just a matter of time on like the scale and the growth, and features like, like prioritization or like quadratic funding will be just like more adopted by the community. So that’s my, uh, take and, uh, opinion about the space.
[MUSIC]
HUIZINGA: Petar and Kasia, thank you so much for coming on the show today and being our first guests on the Collaborators podcast.
MAYMOUNKOV: It’s a pleasure.
SITKIEWICZ: Thank you for having us.
[MUSIC ENDS]