Diffusers is the go-to library that provides a unified interface to cutting-edge and open diffusion models for image, video, and audio. Over the past few months, we have deepened its integration with torch.compile. By tailoring the compilation workflow to the diffusion model architecture, torch.compile delivers significant speed-ups with minimal impact on user experience. In this post, we will show how to unlock these gains. The target audience for this post is
- Diffusion-model authors – Learn the small code changes that make your models compiler-friendly so that end-users can benefit from performance boosts.
- Diffusion-model users – Understand compile time vs. run time trade-offs, how to avoid unnecessary recompilations, and other aspects that can help you choose the right setting. We’ll walk through two community-favorite pipelines from Diffusers to illustrate the payoff.
While the examples live in the Diffusers repo, most of the principles apply to other deep learning workloads as well.
Table of contents
- Background
- Use
torch.compile Effectively For Diffusion Models
- Vanilla Compilation
- For Model Authors: Use fullgraph=True
- For Model Users: Use Regional Compilation
- For Model Users: Reduce Recompilations
- Extend
torch.compile to Popular Diffusers Features
- Memory-constrained GPUs
- LoRA adapters
- Operational Hardening
- Conclusion
- Links to important resources
Background
torch.compile delivers its best gains when you know the model well enough to compile the right sub-modules. In this section, we’ll first outline the factors that shape the torch.compileuser experience, then dissect diffusion architectures to pinpoint which components benefit most from compilation.
Core Factors for torch.compile Performance and Usability
torch.compile turns a Python program into an optimized graph and then emits machine code, but the speedup and ease of use depends on the following factors:
Compile latency – As a JIT compiler, torch.compile springs into action on the first run, so users experience the compile cost up front. This startup cost could be high, especially with large graphs.
Mitigation: try regional compilation to target small, repeated regions. While this may limit the maximum possible speedup compared to compiling the full model, it often strikes a better balance between performance and compile time, so evaluate the trade-off before deciding.
Graph breaks — Dynamic Python or unsupported ops slice the Python program into many small graphs, slashing potential speed-ups. Model developers should strive to keep the compute-heavy part of the model free of any graph breaks.
Mitigation: turn on fullgraph=True, identify the breaks, and eliminate them while preparing the model.
Recompilations – torch.compile specializes its code to the exact input shapes, so changing the resolution from 512 × 512 to 1024 × 1024 triggers a recompile and the accompanying latency.
Mitigation: enable dynamic=True to relax shape constraints. Note that dynamic=True works well for diffusion models, but the recommended way is to use mark_dynamic to selectively apply dynamism to your model.
Device-to-host (DtoH) syncs can also get in the way of optimal performance, but these are non-trivial and have to be treated on a case-by-case basis. Most widely used diffusion pipelines in Diffusers are free of those syncs. Interested readers can check out this document to learn more. Since these syncs contribute to little latency increase compared to other mentioned factors, we will not be focusing on them for the rest of this post.
Diffusion Model Architecture
We’ll use Flux‑1‑Dev, an open‑source text‑to‑image model from Black Forest Labs, as our running example. A diffusion pipeline is not a single network; it is a collection of models:
- Text encoders – CLIP‑Text and T5 convert the user prompt into embeddings.
- Denoiser – a Diffusion Transformer (DiT) progressively refines a noisy latent, conditioned on those embeddings.
- Decoder (VAE) – transforms the final latent into RGB pixels.
Among these components, the DiT dominates the compute budget. You could compile every component in the pipeline, but that only adds compile latency, recompilations, and potential graph breaks, overheads that barely matter, since these parts already account for a tiny slice of the total runtime. For these reasons, we restrict torch.compile to the DiT component instead of the entire pipeline.
Use torch.compile Effectively For Diffusion Models
Vanilla Compilation
Let’s establish a baseline that we can incrementally improve, while maintaining a smooth torch.compile user experience. Load the Flux‑1‑Dev checkpoint and generate an image the usual way:
import torch
from diffusers import FluxPipeline
pipe = FluxPipeline.from_pretrained(
"black-forest-labs/FLUX.1-dev", torch_dtype=torch.bfloat16
).to("cuda")
prompt = "A cat holding a sign that says hello world"
out = pipe(
prompt=prompt,
guidance_scale=3.5,
num_inference_steps=28,
max_sequence_length=512,
).images[0]
out.save("image.png")
Now compile the compute‑heavy Diffusion Transformer sub‑module:
pipe.transformer.compile(fullgraph=True)
That single line cuts latency on an H100 from 6.7 seconds to 4.5 seconds, achieving roughly 1.5x speedup, without sacrificing image quality. Under the hood, torch.compile fuses kernels and removes Python overhead, driving both memory and compute efficiency.
For Model Authors: Use fullgraph=True
The DiT’s forward pass is structurally simple, so we expect it to form one contiguous graph. This flag instructs torch.compile to raise an error if any graph break occurs, letting you catch unsupported ops early rather than silently leaving potential performance gains on the table. We recommend that the diffusion model authors set fullgraph=True early in the model preparation phase and fix graph breaks. Please refer to the torch.compile troubleshooting doc and the manual to fix graph breaks.
For Model Users: Use Regional Compilation
If you’re following along, you’ll notice the first inference call is very slow, taking 67.4 seconds on an H100 machine. This is the compile overhead. Compilation latency grows with the size of the graph handed to the compiler. One practical way to reduce this cost is to compile smaller, repeated blocks, a strategy we call regional compilation.
A DiT is essentially a stack of identical Transformer layers. If we compile one layer once and reuse its kernels for every subsequent layer, we can slash compile time while keeping nearly all of the runtime gains we saw with full‑graph compilation.
Diffusers exposes this via a single-line helper:
pipe.transformer.compile_repeated_blocks(fullgraph=True)
On an H100, this cuts compile latency from 67.4 seconds to 9.6 seconds, reducing the cold start by 7x while still delivering the 1.5x runtime speedup achieved by the full model compilation. If you’d like to dive deeper or enable your new model with regional compilation, the implementation discussion lives in PR.
Note that the compile time numbers above are cold-start measurements: we wiped off the compilation cache with the torch._inductor.utils.fresh_inductor_cache API, so torch.compile had to start from scratch. Alternatively, in a warm start, cached compiler artifacts (stored either on the local disk or on a remote cache) let the compiler skip parts of the compilation process, reducing compile latency. For our model, regional compilation takes 9.6 seconds on a cold start, but only 2.4 seconds once the cache is warm. See the linked guide for details on using compile caches effectively.
For Model Users: Reduce Recompilations
Because torch.compile is a just‑in‑time compiler, it specializes the compiler artifacts to properties of the inputs it sees – shape, dtype, and device among them (refer to this blog for more details). Changing any of these causes recompilation. Although this happens behind the scenes automatically, this recompilation leads to a higher compile time cost, leading to a bad user experience.
If your application needs to handle multiple image sizes or batch shapes, pass dynamic=True when you compile. For general models, PyTorch recommends mark_dynamic, but dynamic=True works well in diffusion models.
pipe.transformer.compile_repeated_blocks(fullgraph=True, dynamic=True)
We benchmarked the forward pass of the Flux DiT with full compilation on shape changes and obtained convincing results.
Extend torch.compile to Popular Diffusers Features
By now, you should have a clear picture of how to accelerate diffusion models withtorch.compile without compromising user experience. Next, we will discuss two community favorite Diffusers features and keep them fully compatible with torch.compile. We will default to regional compile because it delivers the same speedup as full compile with 8x smaller compile latency.
- Memory‑constrained GPUs – Many Diffusers users work on cards whose VRAM cannot hold the entire model. We’ll look at CPU offloading and quantization to keep generation feasible on those devices.
- Rapid personalization with LoRA adapters – Fine‑tuning via low‑rank adapters is the go‑to method for adapting diffusion models to new styles or tasks. We’ll demonstrate how to swap LoRAs without triggering a recompile.
Memory-constrained GPUs
CPU offloading: A full Flux pipeline in bfloat16 consumes roughly 33 GB, more than most consumer GPUs can spare. Fortunately, not every sub‑module has to occupy GPU memory for the entire forward pass. Once the text encoders finish producing prompt embeddings, they can be moved to system RAM. Likewise, after the DiT refines the latent, it can yield the GPU memory to the VAE decoder.
Diffusers turns this offloading into a one‑liner:
pipe.enable_model_cpu_offload()
Peak GPU usage drops to roughly 22.7 GB, making high‑resolution generation feasible on smaller cards at the cost of extra PCIe traffic. Offloading trades memory for time, the end‑to‑end run now takes about 21.5 seconds instead of 6.7 seconds.
You can claw back some of that time by enabling torch.compile alongside offloading. The compiler’s kernel fusion offsets a little bit of PCIe overhead, trimming latency to roughly 18.7 seconds while preserving the smaller 22.6 GB footprint.
pipe.enable_model_cpu_offload()
pipe.transformer.compile_repeated_blocks(fullgraph=True)
Diffusers ships multiple offloading modes, each with a unique speed‑versus‑memory sweet spot. Check out the offloading guide for the full menu.
Quantization: CPU offloading frees GPU memory, but it still assumes that the largest component, the DiT, can fit into GPU memory. Another way to alleviate the memory pressure is to leverage weight quantization, if there is some tolerance for lossy outputs.
Diffusers supports several quantization backends; here we use 4‑bit NF4 quantization from bitsandbytes. It cuts the DiT’s weight footprint by roughly half, dropping peak GPU memory from roughly 33 GB to 15 GB while retaining the image quality.

In contrast to CPU offloading, weight quantization keeps the weights in GPU memory, leading to a smaller increase in runtime penalty – it increases from the baseline of 6.7 seconds to 7.3 seconds. Adding torch.compile on top fuses the 4‑bit operations, reducing the inference time from 7.279 seconds to 5.048 seconds, achieving roughly 1.5x speedup.
You can find different backends and code pointers here.
(We enabled quantization on the DiT and T5 as both of them have considerably higher memory consumption than the CLIP and VAE.)
Quantization + offloading: As you might be expecting, you can combine NF4 quantization with CPU offloading to get the maximum memory benefit. This combined technique reduces the memory footprint to 12.2 GB with 12.2 seconds of inference time. Applying torch.compile works seamlessly, reducing the runtime to 9.8 seconds, achieving a 1.24x speedup.
The benchmarks were conducted using this script on a single H100 machine. Below is a summary of the numbers we have discussed so far. The grey boxes represent the baseline number, and green boxes represent the best configuration.
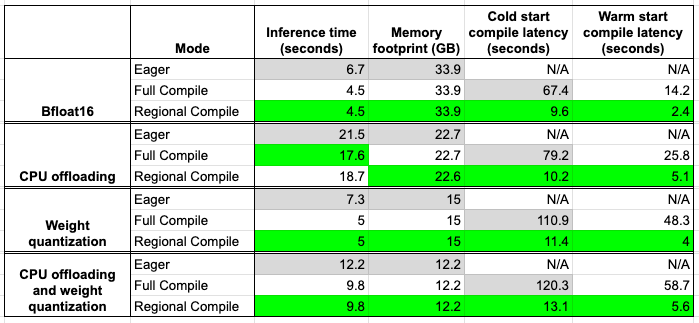
Looking closely at the table above, we can immediately see that regional compilation provides speed-ups almost similar to full compilation, while being significantly faster in terms of compilation time.
LoRA adapters
LoRA adapters let you personalize a base diffusion model without fine‑tuning millions of parameters. The downside is that switching between adapters normally swaps weight tensors inside the DiT, forcing torch.compile to re‑trace and re‑compile.
Diffusers now integrates PEFT’s LoRA hot‑swap to dodge that hit. You declare the maximum LoRA rank you’ll need, compile once, and then swap adapters on the fly. No recompilation required.
pipe = FluxPipeline.from_pretrained(
"black-forest-labs/FLUX.1-dev", torch_dtype=torch.bfloat16
).to("cuda")
pipe.enable_lora_hotswap(target_rank=max_rank)
pipe.load_lora_weights(<lora-adapter-name1>)
pipe.transformer.compile(fullgraph=True)
# from this point on, load new LoRAs with `hotswap=True`
pipe.load_lora_weights(<lora-adapter-name2>, hotswap=True)
Because only the LoRA weight tensors change and their shapes stay fixed, the compiled kernels remain valid and inference latency stays flat.
Caveats
- We need to provide the maximum rank among all LoRA adapters ahead of time. Thus, if we have one adapter with rank 16 and another with 32, we need to pass `max_rank=32`.
- LoRA adapters that are hotswapped can only target the same layers, or a subset of layers, that the first LoRA targets.
- Hot‑swapping the text encoder is not yet supported.
For more details, see the LoRA hot‑swap docs and the test suite.
LoRA inference integrates seamlessly with the offloading and quantization features discussed above. If you’re constrained by GPU VRAM, please consider using them.
Operational Hardening
Diffusers runs a dedicated CI job nightly to keep torch.compile support robust. The suite exercises the most popular pipelines and automatically checks for:
- Graph breaks and silent fallbacks
- Unintended recompilations across common input shapes
- Compatibility between compilation, CPU offloading, and every quantization backend we support
Interested readers are encouraged to check out this link to look at recent PRs that improve torch.compile coverage.
Benchmarks
Correctness is only half the story; we care about performance too. A revamped benchmarking workflow now runs alongside CI, capturing latency and peak memory for each scenario covered in this post. Results are exported to a consolidated CSV so regressions (or wins!) are easy to spot. The design and early numbers live in this PR.

Conclusion
torch.compile can turn a standard Diffusers pipeline into a high‑performance, memory‑efficient workhorse. By focusing compilation on the DiT, leveraging regional compilation and dynamic shapes, and stacking the compiler with offloading, quantization, and LoRA hot‑swap, you can unlock substantial speed‑ups and VRAM savings without sacrificing image quality or flexibility.
We hope these recipes inspire you to weave torch.compile into your own diffusion workflows. We’re excited to see what you build next.
Happy compiling 
The Diffusers team would like to acknowledge the help and support of Animesh and Ryan in improving the torch.compile support.
Links to Important Resources
Read More

















 Thought Leaders Taking the Stage
Thought Leaders Taking the Stage 
 The application deadline for
The application deadline for  Sharpen Your Skills
Sharpen Your Skills Sponsor the Event
Sponsor the Event



 The
The  Keep an eye out for keynote speaker names announced soon!
Keep an eye out for keynote speaker names announced soon!