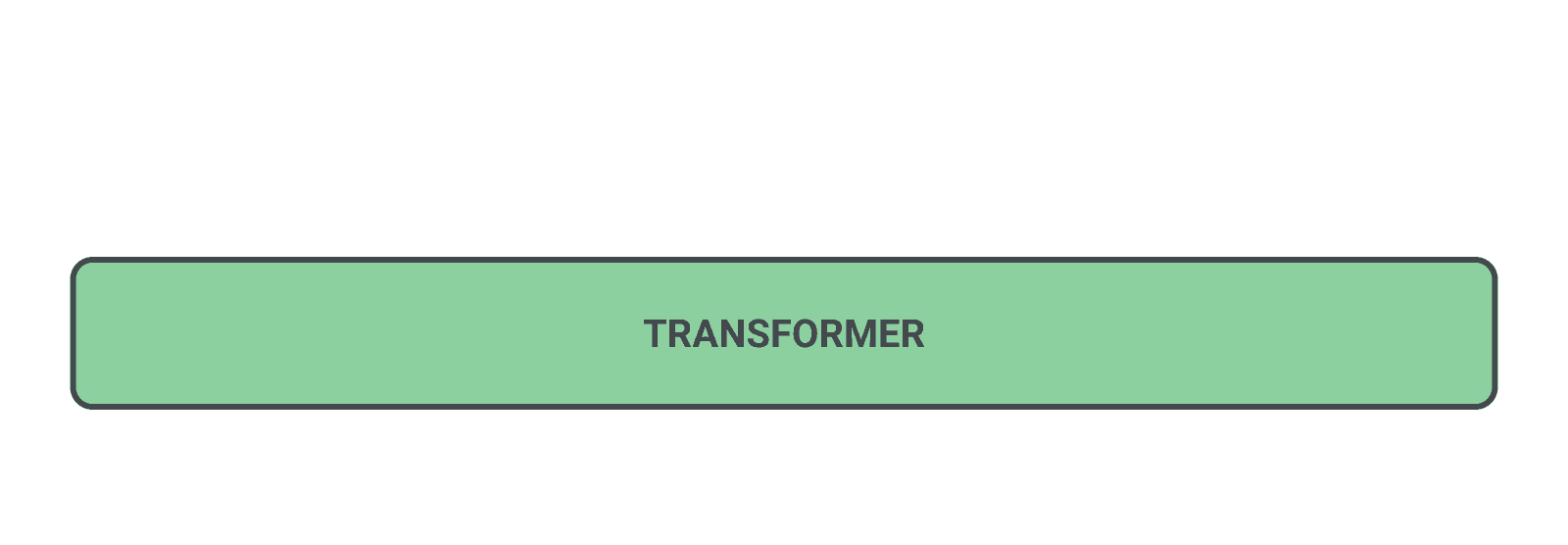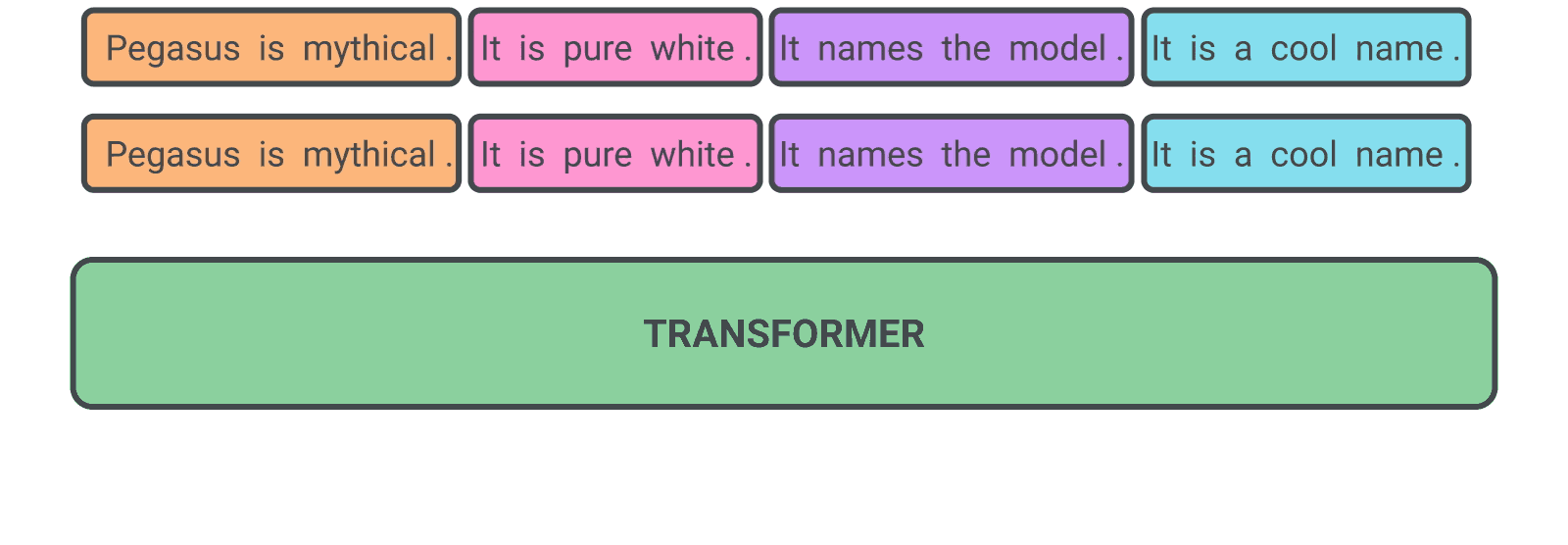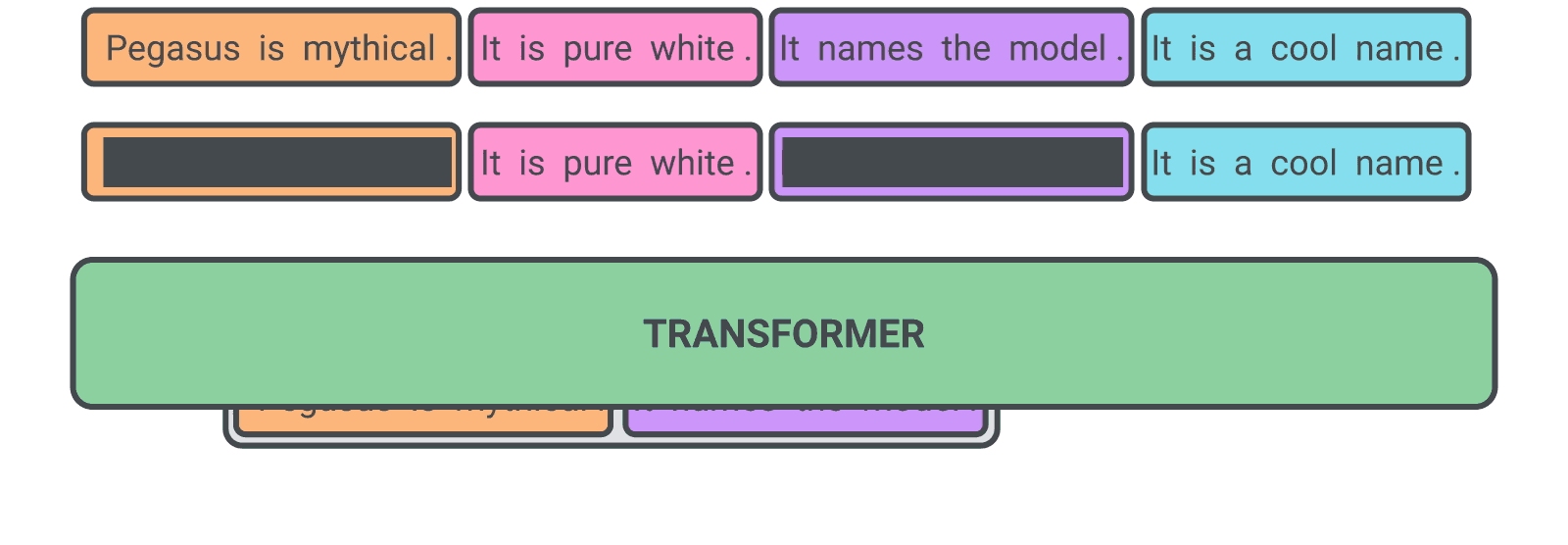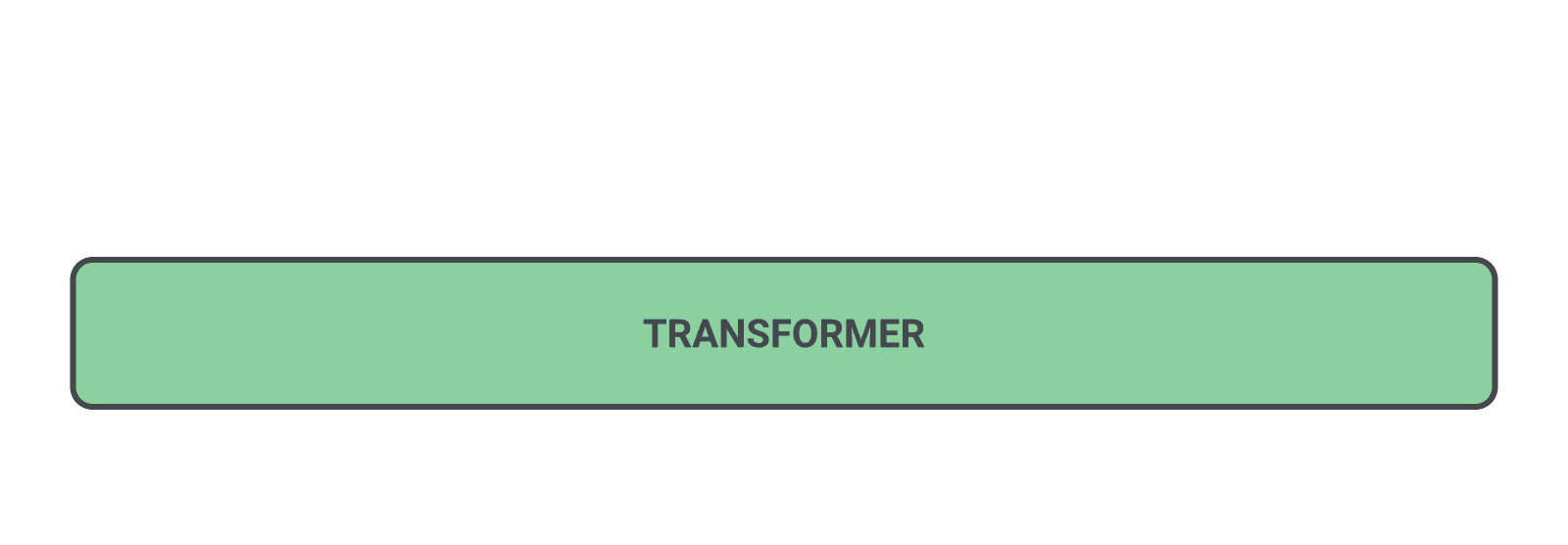

We’re releasing an API for accessing new AI models developed by OpenAI. Unlike most AI systems which are designed for one use-case, the API today provides a general-purpose “text in, text out” interface, allowing users to try it on virtually any English language task. You can now request access in order to integrate the API into your product, develop an entirely new application, or help us explore the strengths and limits of this technology.
Given any text prompt, the API will return a text completion, attempting to match the pattern you gave it. You can “program” it by showing it just a few examples of what you’d like it to do; its success generally varies depending on how complex the task is. The API also allows you to hone performance on specific tasks by training on a dataset (small or large) of examples you provide, or by learning from human feedback provided by users or labelers.
We’ve designed the API to be both simple for anyone to use but also flexible enough to make machine learning teams more productive. In fact, many of our teams are now using the API so that they can focus on machine learning research rather than distributed systems problems. Today the API runs models with weights from the GPT-3 family with many speed and throughput improvements. Machine learning is moving very fast, and we’re constantly upgrading our technology so that our users stay up to date.
The field’s pace of progress means that there are frequently surprising new applications of AI, both positive and negative. We will terminate API access for obviously harmful use-cases, such as harassment, spam, radicalization, or astroturfing. But we also know we can’t anticipate all of the possible consequences of this technology, so we are launching today in a private beta rather than general availability, building tools to help users better control the content our API returns, and researching safety-relevant aspects of language technology (such as analyzing, mitigating, and intervening on harmful bias). We’ll share what we learn so that our users and the broader community can build more human-positive AI systems.
In addition to being a revenue source to help us cover costs in pursuit of our mission, the API has pushed us to sharpen our focus on general-purpose AI technology—advancing the technology, making it usable, and considering its impacts in the real world. We hope that the API will greatly lower the barrier to producing beneficial AI-powered products, resulting in tools and services that are hard to imagine today.
Interested in exploring the API? Join companies like Algolia, Quizlet, and Reddit, and researchers at institutions like the Middlebury Institute in our private beta.
FAQ
Why did OpenAI decide to release a commercial product?
Ultimately, what we care about most is ensuring artificial general intelligence benefits everyone. We see developing commercial products as one of the ways to make sure we have enough funding to succeed.
We also believe that safely deploying powerful AI systems in the world will be hard to get right. In releasing the API, we are working closely with our partners to see what challenges arise when AI systems are used in the real world. This will help guide our efforts to understand how deploying future AI systems will go, and what we need to do to make sure they are safe and beneficial for everyone.
Why did OpenAI choose to release an API instead of open-sourcing the models?
There are three main reasons we did this. First, commercializing the technology helps us pay for our ongoing AI research, safety, and policy efforts.
Second, many of the models underlying the API are very large, taking a lot of expertise to develop and deploy and making them very expensive to run. This makes it hard for anyone except larger companies to benefit from the underlying technology. We’re hopeful that the API will make powerful AI systems more accessible to smaller businesses and organizations.
Third, the API model allows us to more easily respond to misuse of the technology. Since it is hard to predict the downstream use cases of our models, it feels inherently safer to release them via an API and broaden access over time, rather than release an open source model where access cannot be adjusted if it turns out to have harmful applications.
What specifically will OpenAI do about misuse of the API, given what you’ve previously said about GPT-2?
With GPT-2, one of our key concerns was malicious use of the model (e.g., for disinformation), which is difficult to prevent once a model is open sourced. For the API, we’re able to better prevent misuse by limiting access to approved customers and use cases. We have a mandatory production review process before proposed applications can go live. In production reviews, we evaluate applications across a few axes, asking questions like: Is this a currently supported use case?, How open-ended is the application?, How risky is the application?, How do you plan to address potential misuse?, and Who are the end users of your application?.
We terminate API access for use cases that are found to cause (or are intended to cause) physical, emotional, or psychological harm to people, including but not limited to harassment, intentional deception, radicalization, astroturfing, or spam, as well as applications that have insufficient guardrails to limit misuse by end users. As we gain more experience operating the API in practice, we will continually refine the categories of use we are able to support, both to broaden the range of applications we can support, and to create finer-grained categories for those we have misuse concerns about.
One key factor we consider in approving uses of the API is the extent to which an application exhibits open-ended versus constrained behavior with regard to the underlying generative capabilities of the system. Open-ended applications of the API (i.e., ones that enable frictionless generation of large amounts of customizable text via arbitrary prompts) are especially susceptible to misuse. Constraints that can make generative use cases safer include systems design that keeps a human in the loop, end user access restrictions, post-processing of outputs, content filtration, input/output length limitations, active monitoring, and topicality limitations.
We are also continuing to conduct research into the potential misuses of models served by the API, including with third-party researchers via our academic access program. We’re starting with a very limited number of researchers at this time and already have some results from our academic partners at Middlebury Institute, University of Washington, and Allen Institute for AI. We have tens of thousands of applicants for this program already and are currently prioritizing applications focused on fairness and representation research.
How will OpenAI mitigate harmful bias and other negative effects of models served by the API?
Mitigating negative effects such as harmful bias is a hard, industry-wide issue that is extremely important. As we discuss in the GPT-3 paper and model card, our API models do exhibit biases that will be reflected in generated text. Here are the steps we’re taking to address these issues:
- We’ve developed usage guidelines that help developers understand and address potential safety issues.
- We’re working closely with users to understand their use cases and develop tools to surface and intervene to mitigate harmful bias.
- We’re conducting our own research into manifestations of harmful bias and broader issues in fairness and representation, which will help inform our work via improved documentation of existing models as well as various improvements to future models.
- We recognize that bias is a problem that manifests at the intersection of a system and a deployed context; applications built with our technology are sociotechnical systems, so we work with our developers to ensure they’re putting in appropriate processes and human-in-the-loop systems to monitor for adverse behavior.
Our goal is to continue to develop our understanding of the API’s potential harms in each context of use, and continually improve our tools and processes to help minimize them.
Updated September 18, 2020
OpenAI