
We’re introducing a neural network called CLIP which efficiently learns visual concepts from natural language supervision. CLIP (Contrastive Language–Image Pre-training) can be applied to any visual classification benchmark by simply providing the names of the visual categories to be recognized, similar to the ”zero-shot” capabilities of GPT-2 and 3.
Although deep learning has revolutionized computer vision, current approaches have several major problems: typical vision datasets are labor intensive and costly to create while teaching only a narrow set of visual concepts; standard vision models are good at one task and one task only, and require significant effort to adapt to a new task; and models that perform well on benchmarks have disappointingly poor performance on stress tests, casting doubt on the entire deep learning approach to computer vision.
We present a neural network that aims to address these problems: it is trained on a wide variety of images with a wide variety of natural language supervision that’s abundantly available on the internet. By design, the network can be instructed in natural language to perform a great variety of classification benchmarks, without directly optimizing for the benchmark’s performance, similar to the “zero-shot” capabilities of GPT-2 and GPT-3. This is a key change: by not directly optimizing for the benchmark, we show that it becomes much more representative: our system closes this “robustness gap” by up to 75% while matching the performance of the original ResNet50 on ImageNet zero-shot without using any of the original 1.28M labeled examples.
Although both models have the same accuracy on the ImageNet test set, CLIP’s performance is much more representative of how it will fare on datasets that measure accuracy in different, non-ImageNet settings. For instance, ObjectNet checks a model’s ability to recognize objects in many different poses and with many different backgrounds inside homes while ImageNet Rendition and ImageNet Sketch check a model’s ability to recognize more abstract depictions of objects.
Background and related work
CLIP builds on a large body of work on zero-shot transfer, natural language supervision, and multimodal learning. The idea of zero-data learning dates back over a decade but until recently was mostly studied in computer vision as a way of generalizing to unseen object categories. A critical insight was to leverage natural language as a flexible prediction space to enable generalization and transfer. In 2013, Richer Socher and co-authors at Stanford developed a proof of concept by training a model on CIFAR-10 to make predictions in a word vector embedding space and showed this model could predict two unseen classes. The same year DeVISE scaled this approach and demonstrated that it was possible to fine-tune an ImageNet model so that it could generalize to correctly predicting objects outside the original 1000 training set.
Most inspirational for CLIP is the work of Ang Li and his co-authors at FAIR who in 2016 demonstrated using natural language supervision to enable zero-shot transfer to several existing computer vision classification datasets, such as the canonical ImageNet dataset. They achieved this by fine-tuning an ImageNet CNN to predict a much wider set of visual concepts (visual n-grams) from the text of titles, descriptions, and tags of 30 million Flickr photos and were able to reach 11.5% accuracy on ImageNet zero-shot.
Finally, CLIP is part of a group of papers revisiting learning visual representations from natural language supervision in the past year. This line of work uses more modern architectures like the Transformer and includes VirTex, which explored autoregressive language modeling, ICMLM, which investigated masked language modeling, and ConVIRT, which studied the same contrastive objective we use for CLIP but in the field of medical imaging.
Approach
We show that scaling a simple pre-training task is sufficient to achieve competitive zero-shot performance on a great variety of image classification datasets. Our method uses an abundantly available source of supervision: the text paired with images found across the internet. This data is used to create the following proxy training task for CLIP: given an image, predict which out of a set of 32,768 randomly sampled text snippets, was actually paired with it in our dataset.
In order to solve this task, our intuition is that CLIP models will need to learn to recognize a wide variety of visual concepts in images and associate them with their names. As a result, CLIP models can then be applied to nearly arbitrary visual classification tasks. For instance, if the task of a dataset is classifying photos of dogs vs cats we check for each image whether a CLIP model predicts the text description “a photo of a dog” or “a photo of a cat” is more likely to be paired with it.


CLIP pre-trains an image encoder and a text encoder to predict which images were paired with which texts in our dataset. We then use this behavior to turn CLIP into a zero-shot classifier. We convert all of a dataset’s classes into captions such as “a photo of a dog” and predict the class of the caption CLIP estimates best pairs with a given image.
CLIP was designed to mitigate a number of major problems in the standard deep learning approach to computer vision:
Costly datasets: Deep learning needs a lot of data, and vision models have traditionally been trained on manually labeled datasets that are expensive to construct and only provide supervision for a limited number of predetermined visual concepts. The ImageNet dataset, one of the largest efforts in this space, required over 25,000 workers to annotate 14 million images for 22,000 object categories. In contrast, CLIP learns from text–image pairs that are already publicly available on the internet. Reducing the need for expensive large labeled datasets has been extensively studied by prior work, notably self-supervised learning, contrastive methods, self-training approaches, and generative modeling.
Narrow: An ImageNet model is good at predicting the 1000 ImageNet categories, but that’s all it can do “out of the box.” If we wish to perform any other task, an ML practitioner needs to build a new dataset, add an output head, and fine-tune the model. In contrast, CLIP can be adapted to perform a wide variety of visual classification tasks without needing additional training examples. To apply CLIP to a new task, all we need to do is “tell” CLIP’s text-encoder the names of the task’s visual concepts, and it will output a linear classifier of CLIP’s visual representations. The accuracy of this classifier is often competitive with fully supervised models.
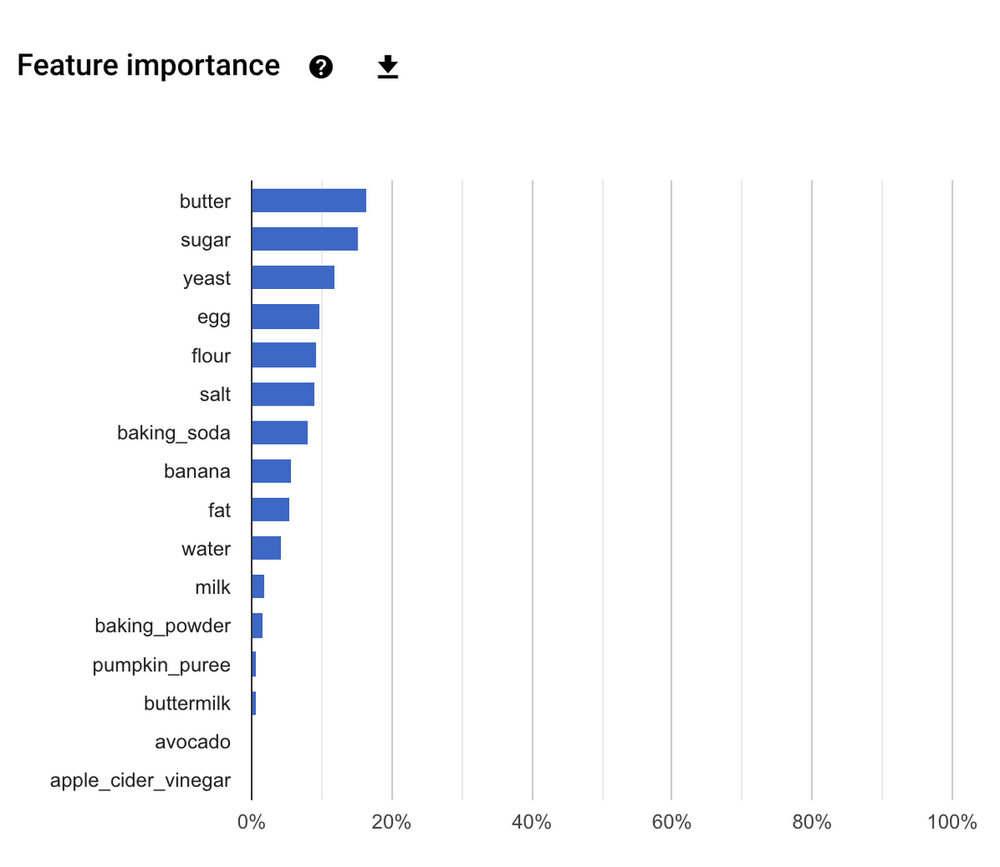
We show random, non-cherry picked, predictions of zero-shot CLIP classifiers on examples from various datasets below.
Poor real-world performance: Deep learning systems are often reported to achieve human or even superhuman performance[1] on vision benchmarks, yet when deployed in the wild, their performance can be far below the expectation set by the benchmark. In other words, there is a gap between “benchmark performance” and “real performance.” We conjecture that this gap occurs because the models “cheat” by only optimizing for performance on the benchmark, much like a student who passed an exam by studying only the questions on past years’ exams. In contrast, the CLIP model can be evaluated on benchmarks without having to train on their data, so it can’t “cheat” in this manner. This results in its benchmark performance being much more representative of its performance in the wild. To verify the “cheating hypothesis”, we also measure how CLIP’s performance changes when it is able to “study” for ImageNet. When a linear classifier is fitted on top of CLIP’s features, it improves CLIP’s accuracy on the ImageNet test set by almost 10%. However, this classifier does no better on average across an evaluation suite of 7 other datasets measuring “robust” performance.
Key takeaways
1. CLIP is highly efficient
CLIP learns from unfiltered, highly varied, and highly noisy data, and is intended to be used in a zero-shot manner. We know from GPT-2 and 3 that models trained on such data can achieve compelling zero shot performance; however, such models require significant training compute. To reduce the needed compute, we focused on algorithmic ways to improve the training efficiency of our approach.
We report two algorithmic choices that led to significant compute savings. The first choice is the adoption of a contrastive objective for connecting text with images. We originally explored an image-to-text approach, similar to VirTex, but encountered difficulties scaling this to achieve state-of-the-art performance. In small to medium scale experiments, we found that the contrastive objective used by CLIP is 4x to 10x more efficient at zero-shot ImageNet classification. The second choice was the adoption of the Vision Transformer, which gave us a further 3x gain in compute efficiency over a standard ResNet. In the end, our best performing CLIP model trains on 256 GPUs for 2 weeks which is similar to existing large scale image models.
2. CLIP is flexible and general
Because they learn a wide range of visual concepts directly from natural language, CLIP models are significantly more flexible and general than existing ImageNet models. We find they are able to zero-shot perform many different tasks. To validate this we have measured CLIP’s zero-shot performance on over 30 different datasets including tasks such as fine-grained object classification, geo-localization, action recognition in videos, and OCR.[2] In particular, learning OCR is an example of an exciting behavior that does not occur in standard ImageNet models. Above, we visualize a random non-cherry picked prediction from each zero-shot classifier.
This finding is also reflected on a standard representation learning evaluation using linear probes. The best CLIP model outperforms the best publicly available ImageNet model, the Noisy Student EfficientNet-L2, on 20 out of 26 different transfer datasets we tested.
Limitations
While CLIP usually performs well on recognizing common objects, it struggles on more abstract or systematic tasks such as counting the number of objects in an image and on more complex tasks such as predicting how close the nearest car is in a photo. On these two datasets, zero-shot CLIP is only slightly better than random guessing. Zero-shot CLIP also struggles compared to task specific models on very fine-grained classification, such as telling the difference between car models, variants of aircraft, or flower species.
CLIP also still has poor generalization to images not covered in its pre-training dataset. For instance, although CLIP learns a capable OCR system, when evaluated on handwritten digits from the MNIST dataset, zero-shot CLIP only achieves 88% accuracy, well below the 99.75% of humans on the dataset. Finally, we’ve observed that CLIP’s zero-shot classifiers can be sensitive to wording or phrasing and sometimes require trial and error “prompt engineering” to perform well.
Broader impacts
CLIP allows people to design their own classifiers and removes the need for task-specific training data. The manner in which these classes are designed can heavily influence both model performance and model biases. For example, we find that when given a set of labels including Fairface race labels[3] and a handful of egregious terms such as “criminal”, “animal” etc. the model tends to classify images of people aged 0–20 in the egregious category at a rate of ~32.3%. However, when we add the class “child” to the list of possible classes, this behaviour drops to ~8.7%.
Additionally, given that CLIP does not need task-specific training data it can unlock certain niche tasks with greater ease. Some of these tasks may raise privacy or surveillance related risks and we explore this concern by studying the performance of CLIP on celebrity identification. CLIP has a top-1 accuracy of 59.2% for “in the wild” celebrity image classification when choosing from 100 candidates and a top-1 accuracy of 43.3% when choosing from 1000 possible choices. Although it’s noteworthy to achieve these results with task agnostic pre-training, this performance is not competitive when compared to widely available production level models. We further explore challenges that CLIP poses in our paper and we hope that this work motivates future research on the characterization of the capabilities, shortcomings, and biases of such models. We are excited to engage with the research community on such questions.
Conclusion
With CLIP, we’ve tested whether task agnostic pre-training on internet scale natural language, which has powered a recent breakthrough in NLP, can also be leveraged to improve the performance of deep learning for other fields. We are excited by the results we’ve seen so far applying this approach to computer vision. Like the GPT family, CLIP learns a wide variety of tasks during pre-training which we demonstrate via zero-shot transfer. We are also encouraged by our findings on ImageNet that suggest zero-shot evaluation is a more representative measure of a model’s capability.
OpenAI
























































 Geremy Cohen is a Solutions Architect with AWS where he helps customers build cutting-edge, cloud-based solutions. In his spare time, he enjoys short walks on the beach, exploring the bay area with his family, fixing things around the house, breaking things around the house, and BBQing.
Geremy Cohen is a Solutions Architect with AWS where he helps customers build cutting-edge, cloud-based solutions. In his spare time, he enjoys short walks on the beach, exploring the bay area with his family, fixing things around the house, breaking things around the house, and BBQing.











 Abhinav Jawadekar is a Senior Partner Solutions Architect at Amazon Web Services. Abhinav works with AWS partners to help them in their cloud journey.
Abhinav Jawadekar is a Senior Partner Solutions Architect at Amazon Web Services. Abhinav works with AWS partners to help them in their cloud journey.