Combining elastic weight consolidation and data mixing yields better trade-offs between performance on old and new tasks.Read More

Another Step Towards Breakeven Fusion
Posted by Ted Baltz, Senior Staff Software Engineer, Google Research
For more than 70 years, plasma physicists have dreamed of controlled “breakeven” fusion, where a system is capable of releasing more energy in a fusion reaction than it takes to initiate and sustain those reactions. The challenge is that the reactor must create a plasma at a temperature of tens of millions of degrees, which requires a highly complex, finely tuned system to confine and sustain. Further, creating the plasma and maintaining it, requires substantial amounts of energy, which, to date, have exceeded that released in the fusion reaction itself. Nevertheless, if a “breakeven” system could be achieved, it could provide ample zero-carbon electricity, the potential impact of which has driven interest by government laboratories, such as ITER and the National Ignition Facility, as well as several privately funded efforts.
Today we highlight two recently published papers arising from our collaboration with TAE Technologies1, which demonstrate exciting advancements in the field. In “Overview of C-2W: High-temperature, steady-state beam-driven field-reversed configuration plasmas,” published in Nuclear Fusion, we describe the experimental program implemented by TAE, which leverages our improved version of the Optometrist Algorithm for machine optimization. Due in part to this contribution, the current state-of-the-art reactor is able to achieve plasma lifetimes up to three times longer than its predecessor. In “Multi-instrument Bayesian reconstruction of plasma shape evolution in the C-2W experiment,” published in Physics of Plasmas, we detail new methods developed for analyzing indirect measurements of plasma to reconstruct its properties in detail. This work enabled us to better understand how instabilities in the plasma arise and to understand how to mitigate these perturbations in practice.
Optimizing the Next Generation Fusion Device
The C-2W “Norman” machine (named for TAE’s late co-founder Prof. Norman Rostoker) is a nearly complete rebuild of the C-2U machine that we described in 2017. For this updated version, the TAE team integrated new pressure vessels, new power supplies, a new vacuum system, along with other substantial upgrades.
Norman is incredibly complex, with over 1000 machine control parameters, and likewise, it captures extensive amounts of data for each run, including over 1000 measurements of conditions in the plasma alone. And while the measurements of each plasma experiment are extremely rich, there is no simple metric for “goodness”. Further complicating matters, it is not possible to rapidly iterate to improve performance, because only one experiment can be executed every eight minutes. For these reasons, tuning the system is quite difficult and relies on the expert intuition developed by the plasma physicists operating the system. To optimize the new reactor’s performance, we needed a control system capable of handling the tremendous complexity of the system while being able to quickly tune the control parameters in response to the extensive data generated in experiments.
To accomplish this, we further adapted the Optometrist Algorithm that we had developed for the C-2U system to leverage the expertise of the operators. In this algorithm, the physicists compare experiment pairs, and determine whether the trial better achieves the current goals of the experiment, according to their judgment, than the current reference experiment — e.g., achieving increased plasma size at a fixed temperature, increased temperature, etc. By updating the reference accordingly, machine performance improves over time. However, accounting for operator intuition during this process is critical, because the measure of improvement may not be immediately obvious. For example, under some situations, an experiment with much denser plasma that is a little bit colder may, in fact, be “better”, because it may lead to other improvements in subsequent experiments. We further modified the algorithm by fitting a logistic regression to the binary decisions of the expert to guide the trial experiments, making a classic exploration-exploitation tradeoff.
Applying the Optometrist Algorithm to the magnetic field coils that form the plasma, we found a novel timing sequence that provides consistent starting conditions for long-lived plasmas, almost tripling the plasma lifetime when first applied. This was a marked improvement over the regime of net plasma heating first seen on the C-2U machine in 2015.
|
| Plasma formation section of the Norman reactor. The outer coils operate for the duration of the experiments while the inner coils accelerate the plasma in less than 10 microseconds. (Photograph by Erik Lucero) |
Bayesian Reconstruction of Plasma Conditions
In addition to optimizing the performance of the machine, we also sought to more thoroughly understand the behavior of the plasmas it is generating. This includes understanding the density profiles, separate electron and ion temperatures, and magnetic fields generated by the plasma. Because the plasma in a fusion generator reaches 30 million Kelvin, which would destroy most solid materials in moments, precise measurements of the plasma conditions are very difficult.
To address this, Norman has a set of indirect diagnostics, generating 5 GB of data per shot, that peer into the plasma without touching it. One of these is a two-story laser interferometer that measures the line-integrated electron density along 14 lines of sight through the plasma, with a sample rate of more than a megahertz. The resulting dataset of line-integrated densities can be used to extract the spatial density profile of the plasma, which is crucial to understanding the plasma behavior. In this case, the Norman reactor generates field-reversed configuration (FRC) plasmas that tend to be best confined when they are hollow (imagine a smoke ring elongated into a barrel shape). The challenge in this situation is that generating the spatial density profiles for such a plasma configuration is an inverse problem, i.e., it is more difficult to infer the shape of the plasma from the measurements (the “inverse” direction) than to predict the measurements from a known shape (the “forward” direction).
 |
| Schematic of C-2W confinement vessel showing measurement systems: interferometer lines of sight measuring electron density (magenta), neutral particle beam lines of sight measuring ion density (purple) and magnetic sensors (blue). These disparate measurements are combined in the Bayesian framework. |
We developed a TensorFlow implementation of the Hamiltonian Monte Carlo (HMC) algorithm to address the problem of inferring the density profile of the plasma from multiple indirect measurements. Because the plasma is described by hundreds to thousands of variables and we want to reconstruct the state for thousands of frames, linked into “bursts” or short movies, for each plasma experiment, processing on CPUs is insufficient. For this reason, we optimized the HMC algorithm to be executed on GPUs. The Bayesian framework for this involves building “forward” models (i.e., predicting effects from causes) for several instruments, which can predict what the instrument would record, given some specified plasma conditions. We can then use HMC to calculate the probabilities of various possible plasma conditions. Understanding both density and temperature are crucial to the problem of breakeven fusion.
High Frequency Plasma Perturbations
Reconstruction of the plasma conditions does more than just recover the plasma density profile, it also recovers the behavior of high frequency density perturbations in the plasma. TAE has done a large number of experiments to determine if Norman’s neutral particle beams and electrode currents can control these oscillations. In the second paper, we demonstrate the strong mitigating effects of the neutral beams, showing that when the neutral beams are turned off, fluctuations immediately begin growing. The reconstruction allows us to see how the radial density profile of the plasma evolves as the perturbations grow, an understanding of which is key to mitigating such perturbations, allowing long-lived stable plasmas. Following a long tradition of listening to plasma perturbations to better intuit their behavior (e.g., ionospheric “whistlers” have been captured by radio operators for over a century), we translate the perturbations to audio (slowed down 500x) in order to listen to them.
| Movie showing spectrogram of magnetic oscillations, played as audio 500 times slower. Different colors indicate different shapes. There is a whistle as the plasma forms, as well as low drum sounds followed immediately by chirps when the plasma destabilizes and recovers. Headphones / earbuds recommended; may annoy pets and humans. |
The Future Looks Hot and Stable
With our assistance using machine optimization and data science, TAE achieved their major goals for Norman, which brings us a step closer to the goal of breakeven fusion. The machine maintains a stable plasma at 30 million Kelvin for 30 milliseconds, which is the extent of available power to its systems. They have completed a design for an even more powerful machine, which they hope will demonstrate the conditions necessary for breakeven fusion before the end of the decade. TAE has succeeded with two complete machine builds during our collaboration, and we are really excited to see the third.
Acknowledgments
We wish to thank Michael Dikovsky, Ian Langmore, Peter Norgaard, Scott Geraedts, Rob von Behren, Bill Heavlin, Anton Kast, Tom Madams, John Platt, Ross Koningstein, and Matt Trevithick for their contributions to this work. We thank the TensorFlow Probability team for considerable implementation assistance. Furthermore, we thank Jeff Dean for visiting TAE’s facility in Southern California and providing thoughtful suggestions. As always we are grateful to our colleagues at TAE Technologies for the opportunity to work on such a fascinating and important problem.
1Google owns stock and warrants in TAE Technologies. ↩

Amazon’s 23 papers at EMNLP
Natural-language understanding and question answering are areas of focus, with additional topics ranging from self-learning to text summarization.Read More
Why Generalization in RL is Difficult: Epistemic POMDPs and Implicit Partial Observability
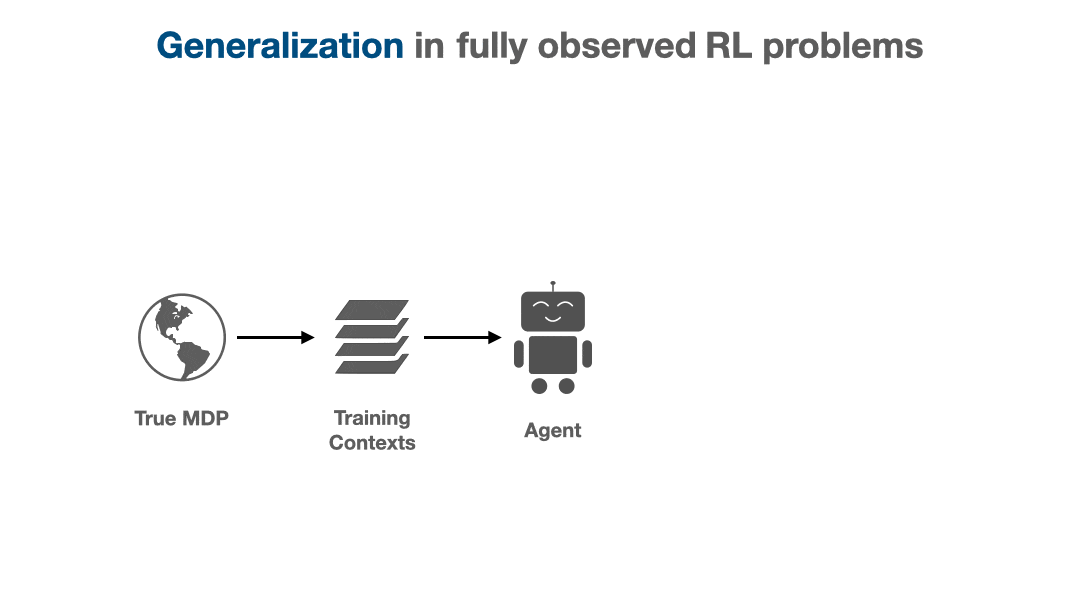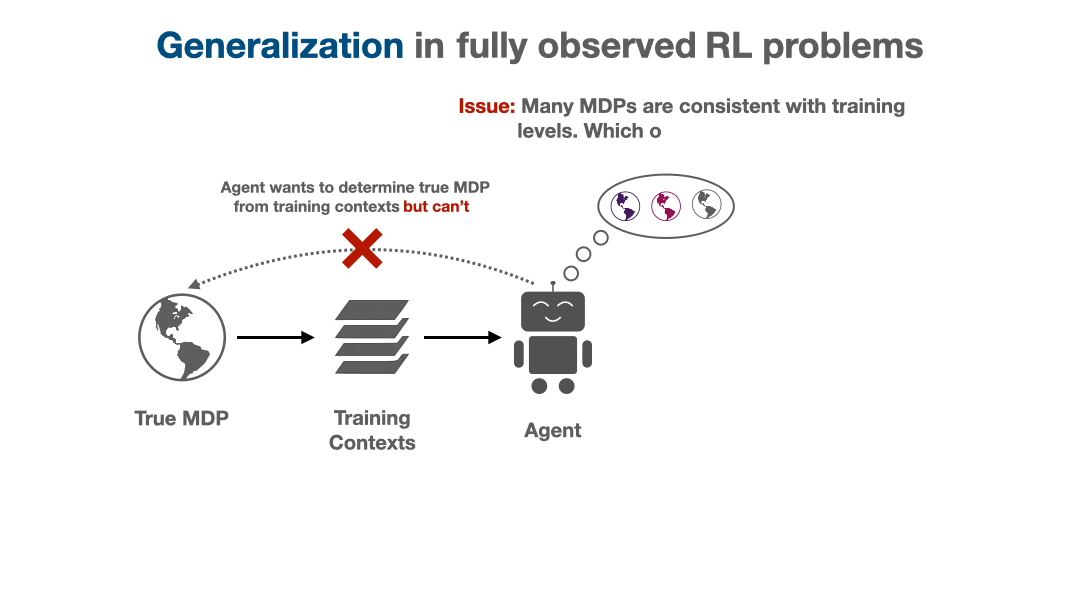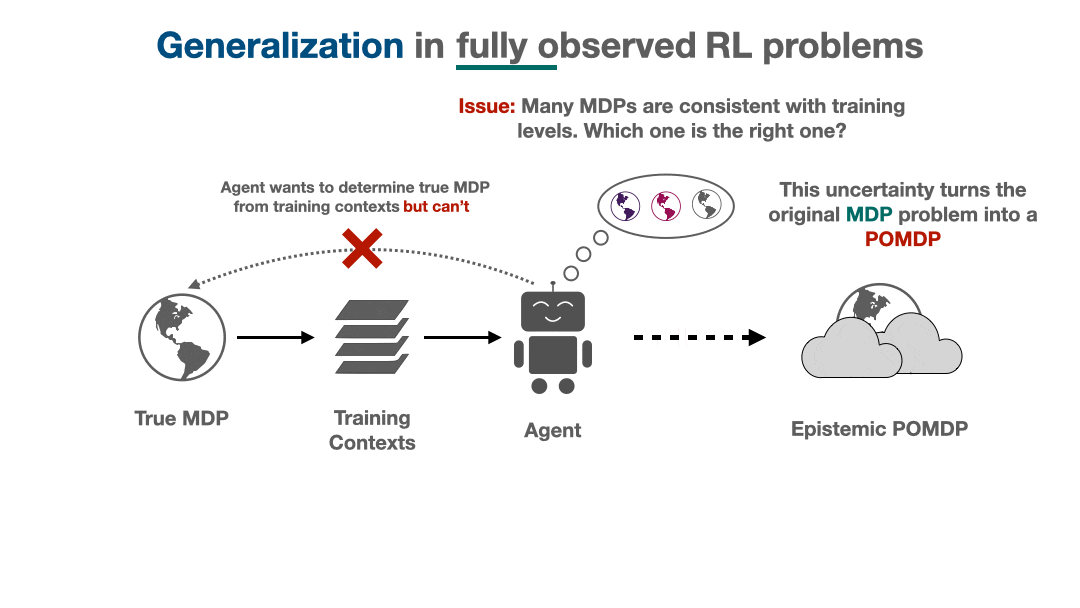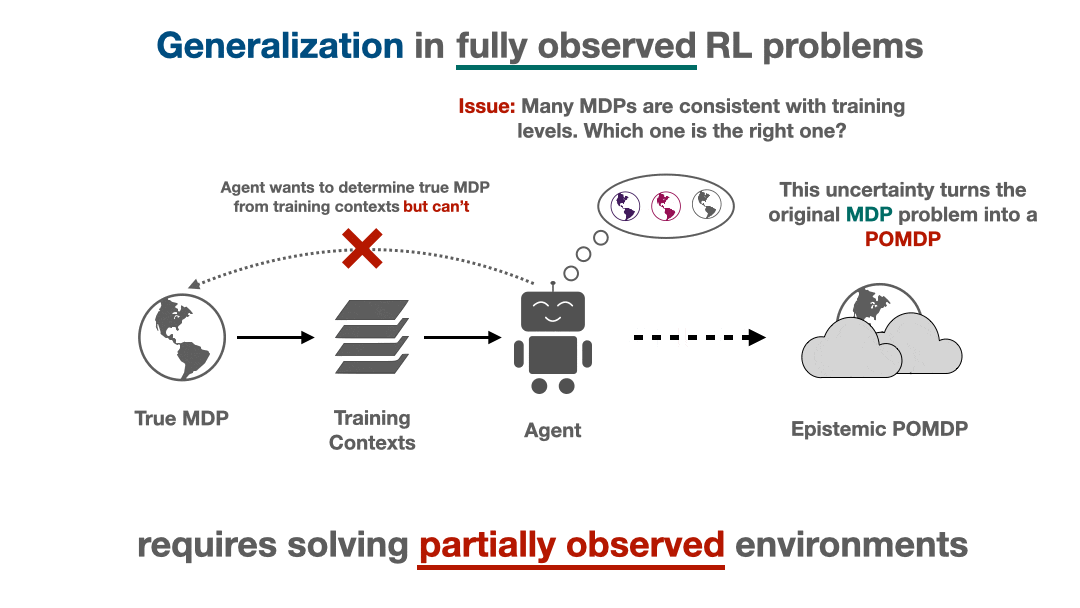
Many experimental works have observed that generalization in deep RL appears to be difficult: although RL agents can learn to perform very complex tasks, they don’t seem to generalize over diverse task distributions as well as the excellent generalization of supervised deep nets might lead us to expect. In this blog post, we will aim to explain why generalization in RL is fundamentally harder, and indeed more difficult even in theory.
We will show that attempting to generalize in RL induces implicit partial observability, even when the RL problem we are trying to solve is a standard fully-observed MDP. This induced partial observability can significantly complicate the types of policies needed to generalize well, potentially requiring counterintuitive strategies like information-gathering actions, recurrent non-Markovian behavior, or randomized strategies. Ordinarily, this is not necessary in fully observed MDPs but surprisingly becomes necessary when we consider generalization from a finite training set in a fully observed MDP. This blog post will walk through why partial observability can implicitly arise, what it means for the generalization performance of RL algorithms, and how methods can account for partial observability to generalize well.
Stanford AI Lab Papers at EMNLP/CoNLL 2021
![]()
The 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP 2021)
will take place next week, colocated with CoNLL 2021. We’re excited to share all the work from SAIL that will be presented, and you’ll find links to papers, videos and blogs below. Feel free to reach out to the contact authors directly to learn more about the work that’s happening at Stanford!
List of Accepted Papers
Calibrate your listeners! Robust communication-based training for pragmatic speakers

Authors: Rose E. Wang, Julia White, Jesse Mu, Noah D. Goodman
Contact: rewang@stanford.edu
Links: Paper | Video
Keywords: language generation, pragmatics, communication-based training, calibration, uncertainty
Cross-Domain Data Integration for Named Entity Disambiguation in Biomedical Text

Authors: Maya Varma, Laurel Orr, Sen Wu, Megan Leszczynski, Xiao Ling, Christopher Ré
Contact: mvarma2@stanford.edu
Links: Paper | Video
Keywords: named entity disambiguation, biomedical text, rare entities, data integration
ContractNLI: A Dataset for Document-level Natural Language Inference for Contracts

Authors: Yuta Koreeda, Christopher D. Manning
Contact: koreeda@stanford.edu
Links: Paper | Website
Keywords: natural language inference, contract, law, legal, dataset
Venue: The Findings of EMNLP 2021
The Emergence of the Shape Bias Results from Communicative Efficiency
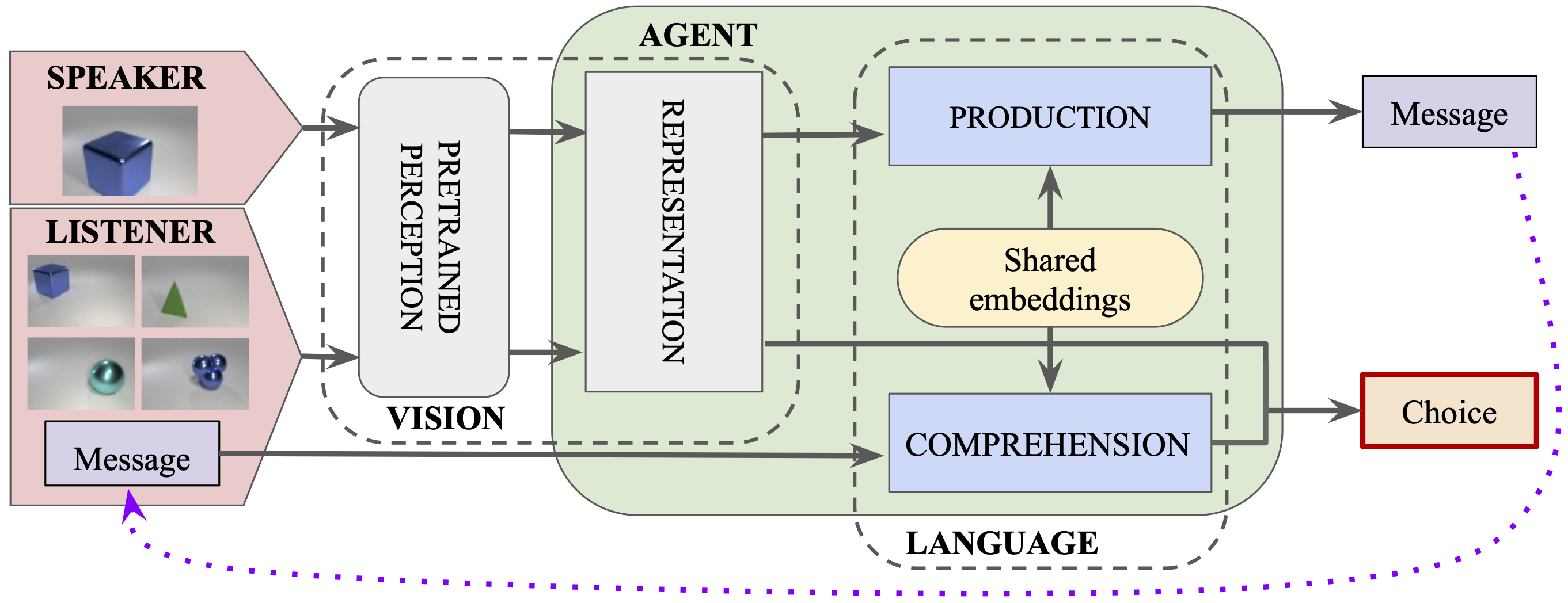
Authors: Eva Portelance, Michael C. Frank, Dan Jurafsky, Alessandro Sordoni, Romain Laroche
Contact: portelan@stanford.edu
Links: Paper | Website
Keywords: emergent communication, shape bias, multi-agent reinforcement learning, language learning, language acquisition
Conference: CoNLL
LM-Critic: Language Models for Unsupervised Grammatical Error Correction

Authors: Michihiro Yasunaga, Jure Leskovec, Percy Liang.
Contact: myasu@cs.stanford.edu
Links: Paper | Blog Post | Website
Keywords: language model, grammatical error correction, unsupervised translation
Sensitivity as a complexity measure for sequence classification tasks

Authors: Michael Hahn, Dan Jurafsky, Richard Futrell
Contact: mhahn2@stanford.edu
Links: Paper
Keywords: decision boundaries, computational complexity
Distributionally Robust Multilingual Machine Translation
Authors: Chunting Zhou*, Daniel Levy*, Marjan Ghazvininejad, Xian Li, Graham Neubig
Contact: daniel.levy0@gmail.com
Keywords: machine translation, robustness, distribution shift, dro, cross-lingual transfer
Learning from Limited Labels for Long Legal Dialogue

Authors: Jenny Hong, Derek Chong, Christopher D. Manning
Contact: jennyhong@cs.stanford.edu
Keywords: legal nlp, information extraction, weak supervision
Capturing Logical Structure of Visually Structured Documents with Multimodal Transition Parser
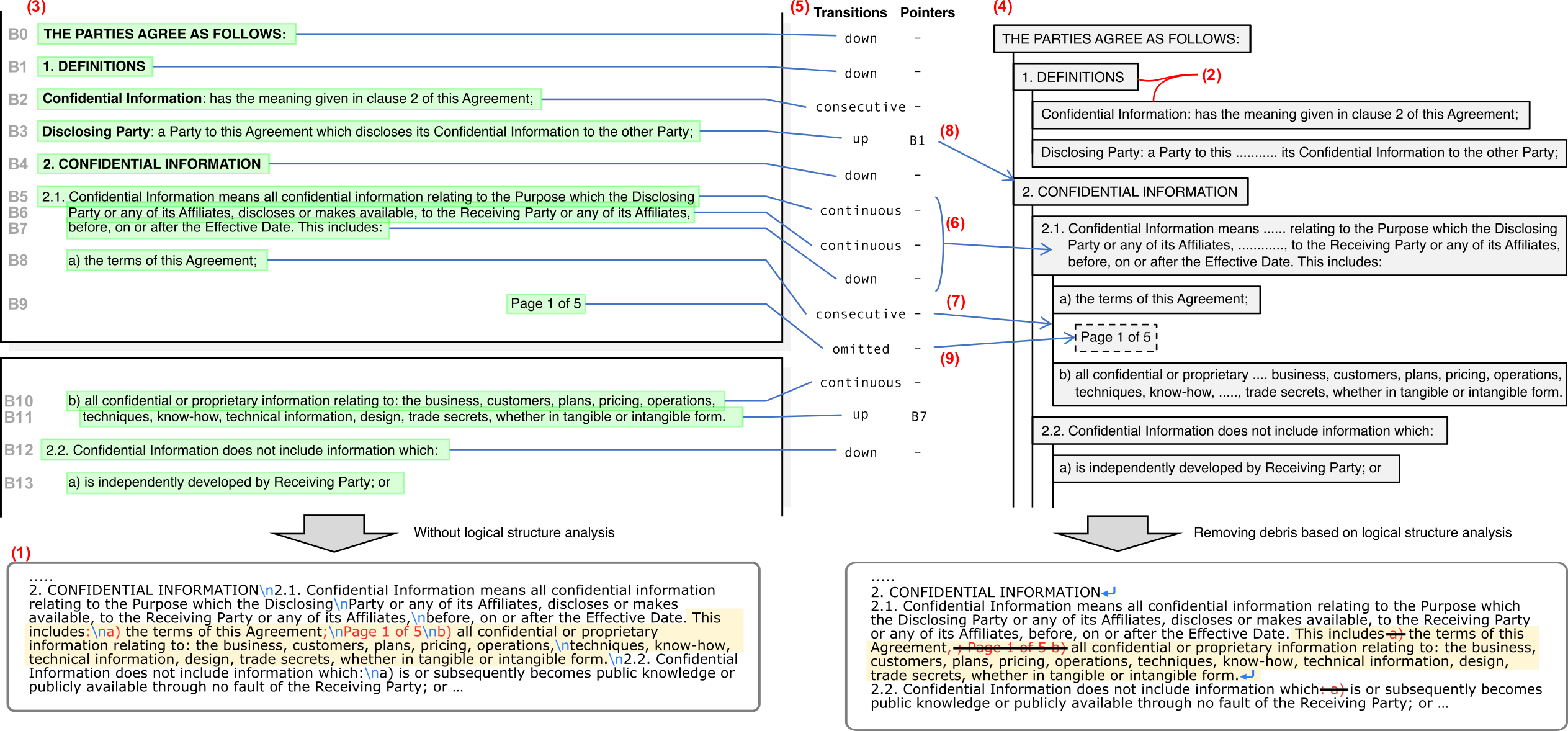
Authors: Yuta Koreeda, Christopher D. Manning
Contact: koreeda@stanford.edu
Links: Paper | Website
Keywords: legal, preprocessing
Workshop: Natural Legal Language Processing Workshop
We look forward to seeing you at EMNLP/CoNLL 2021!
Stanford AI Lab Papers at CoRL 2021
![]()
The Conference on Robot Learning (CoRL 2021)
will take place next week. We’re excited to share all the work from SAIL that will be presented, and you’ll find links to papers, videos and blogs below. Feel free to reach out to the contact authors directly to learn more about the work that’s happening at Stanford!
List of Accepted Papers
LILA: Language-Informed Latent Actions
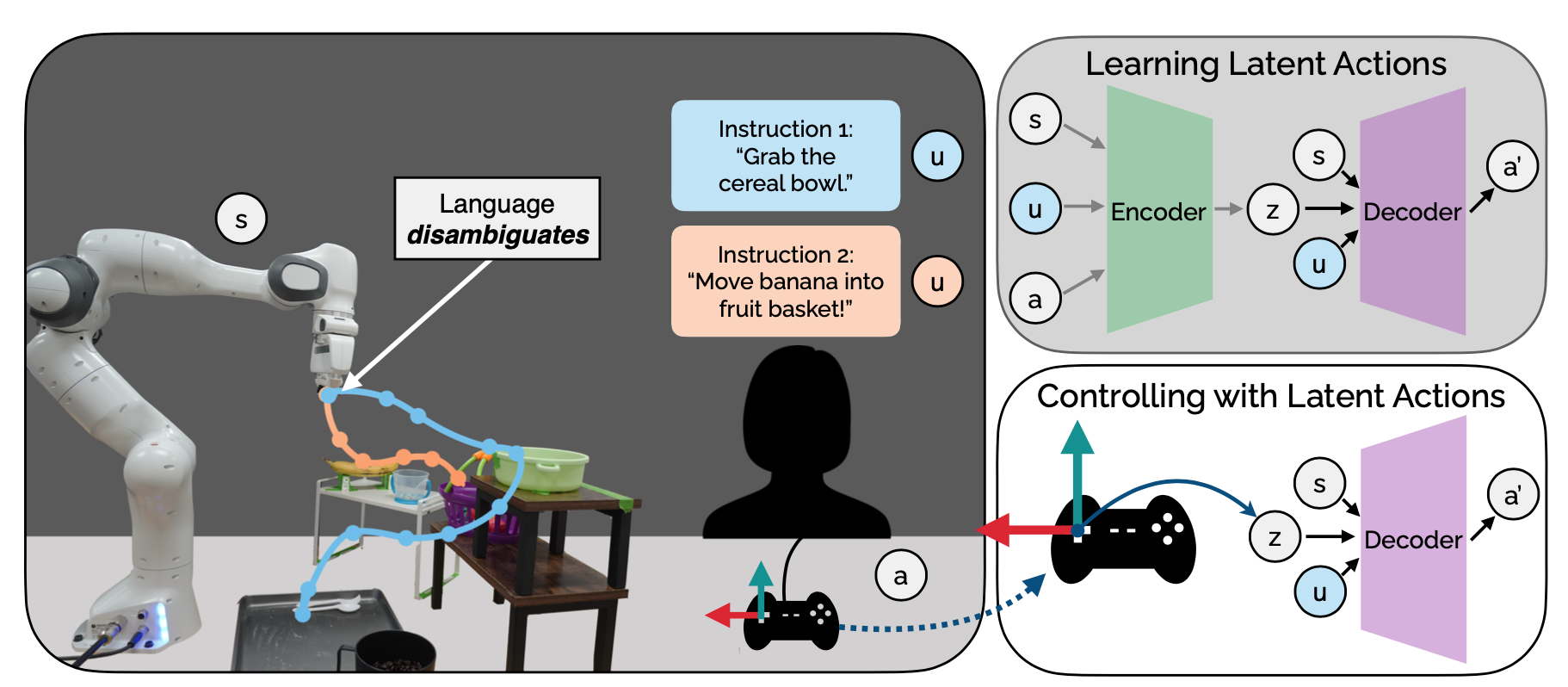
Authors: Siddharth Karamcheti*, Megha Srivastava*, Percy Liang, Dorsa Sadigh
Contact: skaramcheti@cs.stanford.edu, megha@cs.stanford.edu
Keywords: natural language, shared autonomy, human-robot interaction
BEHAVIOR: Benchmark for Everyday Household Activities in Virtual, Interactive, and Ecological Environments
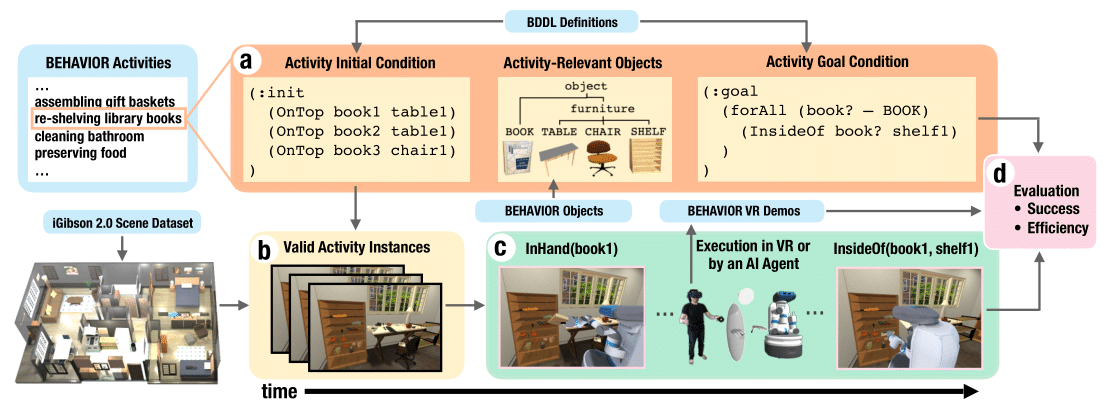
Authors: Sanjana Srivastava*, Chengshu Li*, Michael Lingelbach*, Roberto Martín-Martín*, Fei Xia, Kent Vainio, Zheng Lian, Cem Gokmen, Shyamal Buch, C. Karen Liu, Silvio Savarese, Hyowon Gweon, Jiajun Wu, Li Fei-Fei
Contact: sanjana2@stanford.edu
Links: Paper | Website
Keywords: embodied ai, benchmarking, household activities
Co-GAIL: Learning Diverse Strategies for Human-Robot Collaboration

Authors: Chen Wang, Claudia Pérez-D’Arpino, Danfei Xu, Li Fei-Fei, C. Karen Liu, Silvio Savarese
Contact: chenwj@stanford.edu
Links: Paper | Website
Keywords: learning for human-robot collaboration, imitation learning
DiffImpact: Differentiable Rendering and Identification of Impact Sounds

Authors: Samuel Clarke, Negin Heravi, Mark Rau, Ruohan Gao, Jiajun Wu, Doug James, Jeannette Bohg
Contact: spclarke@stanford.edu
Links: Paper | Website
Keywords: differentiable sound rendering, auditory scene analysis
Example-Driven Model-Based Reinforcement Learning for Solving Long-Horizon Visuomotor Tasks

Authors: Bohan Wu, Suraj Nair, Li Fei-Fei*, Chelsea Finn*
Contact: bohanwu@cs.stanford.edu
Links: Paper
Keywords: model-based reinforcement learning, long-horizon tasks
GRAC: Self-Guided and Self-Regularized Actor-Critic

Authors: Lin Shao, Yifan You, Mengyuan Yan, Shenli Yuan, Qingyun Sun, Jeannette Bohg
Contact: harry473417@ucla.edu
Links: Paper | Website
Keywords: deep reinforcement learning, q-learning
Influencing Towards Stable Multi-Agent Interactions
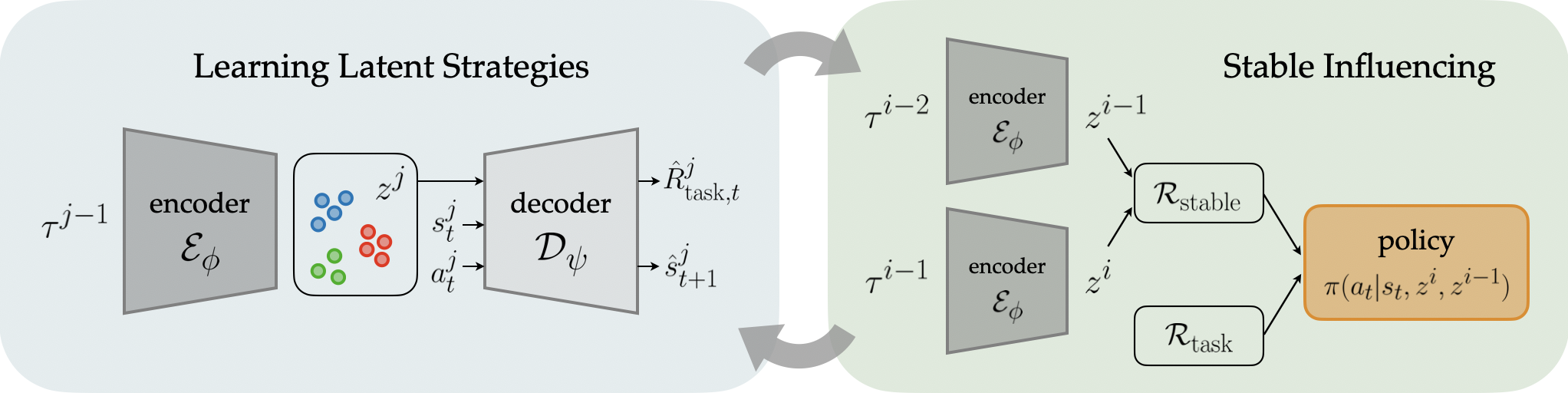
Authors: Woodrow Z. Wang, Andy Shih, Annie Xie, Dorsa Sadigh
Contact: woodywang153@gmail.com
Award nominations: Oral presentation
Links: Paper | Website
Keywords: multi-agent interactions, human-robot interaction, non-stationarity
Learning Language-Conditioned Robot Behavior from Offline Data and Crowd-Sourced Annotation
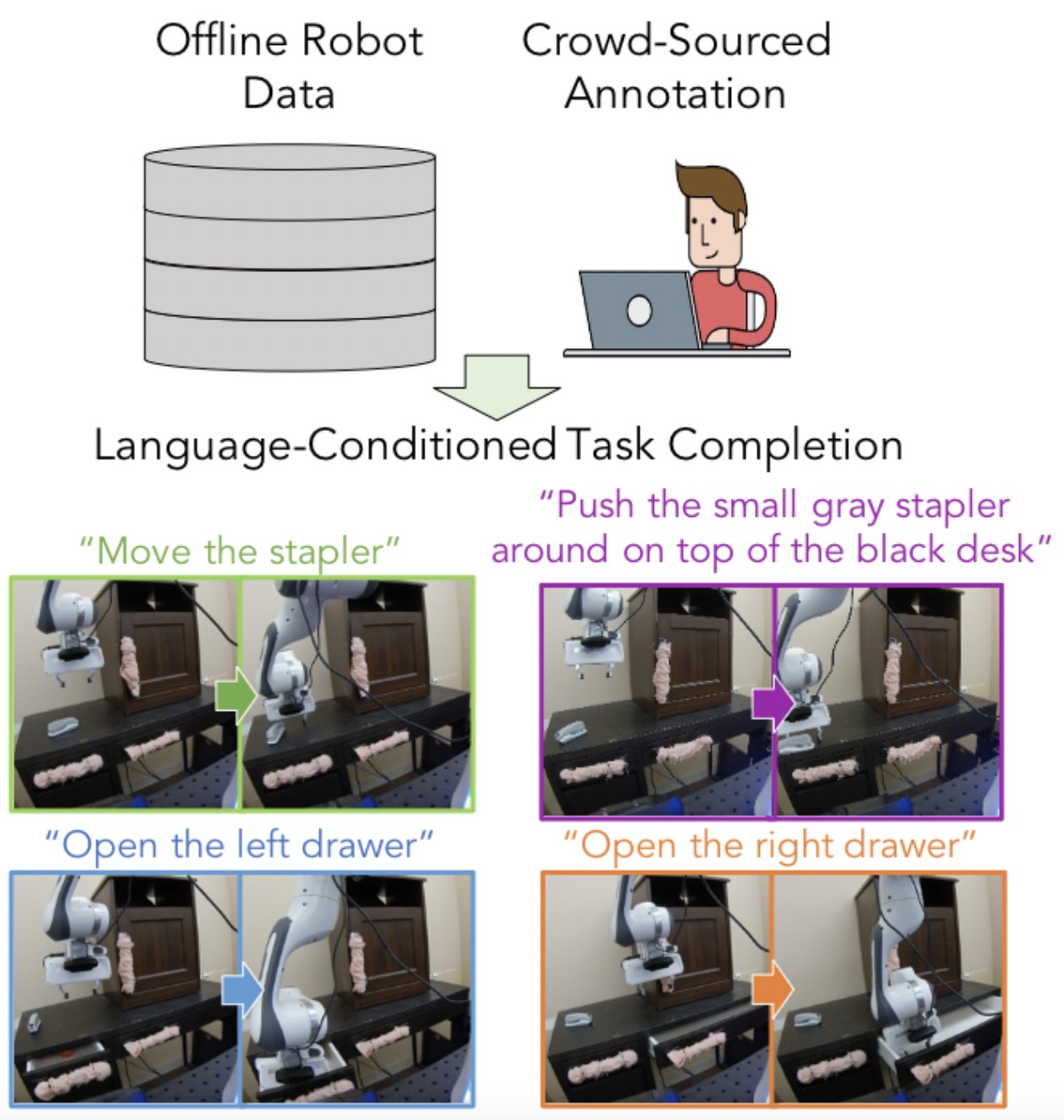
Authors: Suraj Nair, Eric Mitchell, Kevin Chen, Brian Ichter, Silvio Savarese, Chelsea Finn
Contact: surajn@stanford.edu
Links: Paper | Website
Keywords: natural language, offline rl, visuomotor manipulation
Learning Multimodal Rewards from Rankings

Authors: Vivek Myers, Erdem Bıyık, Nima Anari, Dorsa Sadigh
Contact: ebiyik@stanford.edu
Links: Paper | Video | Website
Keywords: reward learning, active learning, learning from rankings, multimodality
Learning Reward Functions from Scale Feedback

Authors: Nils Wilde*, Erdem Bıyık*, Dorsa Sadigh, Stephen L. Smith
Contact: ebiyik@stanford.edu
Links: Paper | Video | Website
Keywords: preference-based learning, reward learning, active learning, scale feedback
Learning to Regrasp by Learning to Place
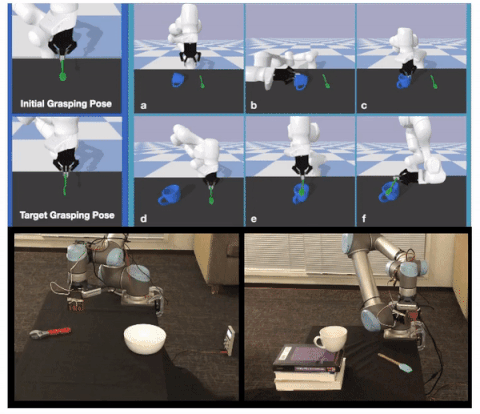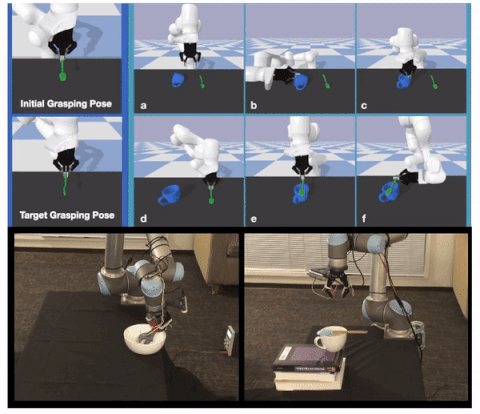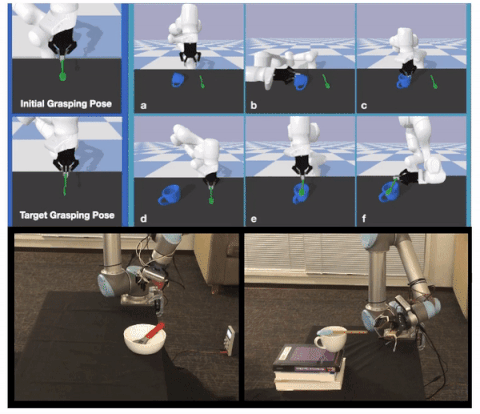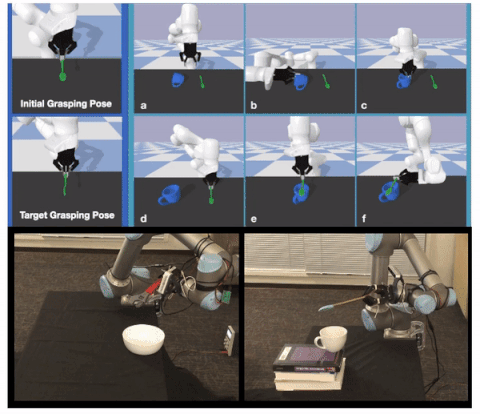
Authors: Shuo Cheng, Kaichun Mo, Lin Shao
Contact: lins2@stanford.edu
Links: Paper | Website
Keywords: regrasping, object placement, robotic manipulation
Learning to be Multimodal : Co-evolving Sensory Modalities and Sensor Properties
Authors: Rika Antonova, Jeannette Bohg
Contact: rika.antonova@stanford.edu
Links: Paper
Keywords: co-design, multimodal sensing, corl blue sky track
O2O-Afford: Annotation-Free Large-Scale Object-Object Affordance Learning

Authors: Kaichun Mo, Yuzhe Qin, Fanbo Xiang, Hao Su, Leonidas J. Guibas
Contact: kaichun@cs.stanford.edu
Links: Paper | Video | Website
Keywords: robotic vision, object-object interaction, visual affordance
ObjectFolder: A Dataset of Objects with Implicit Visual, Auditory, and Tactile Representations
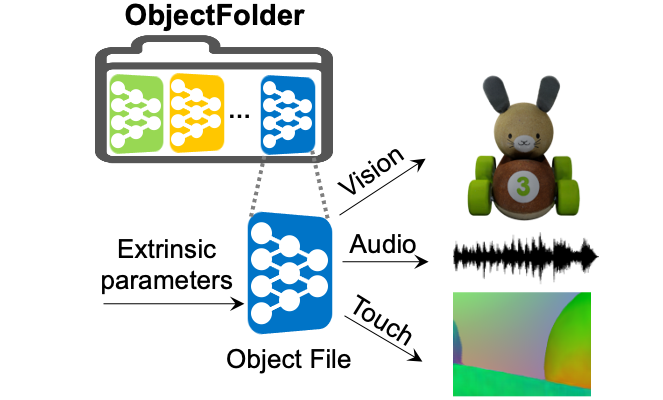
Authors: Ruohan Gao, Yen-Yu Chang, Shivani Mall, Li Fei-Fei, Jiajun Wu
Contact: rhgao@cs.stanford.edu
Links: Paper | Video | Website
Keywords: object dataset, multisensory learning, implicit representations
Taskography: Evaluating robot task planning over large 3D scene graphs
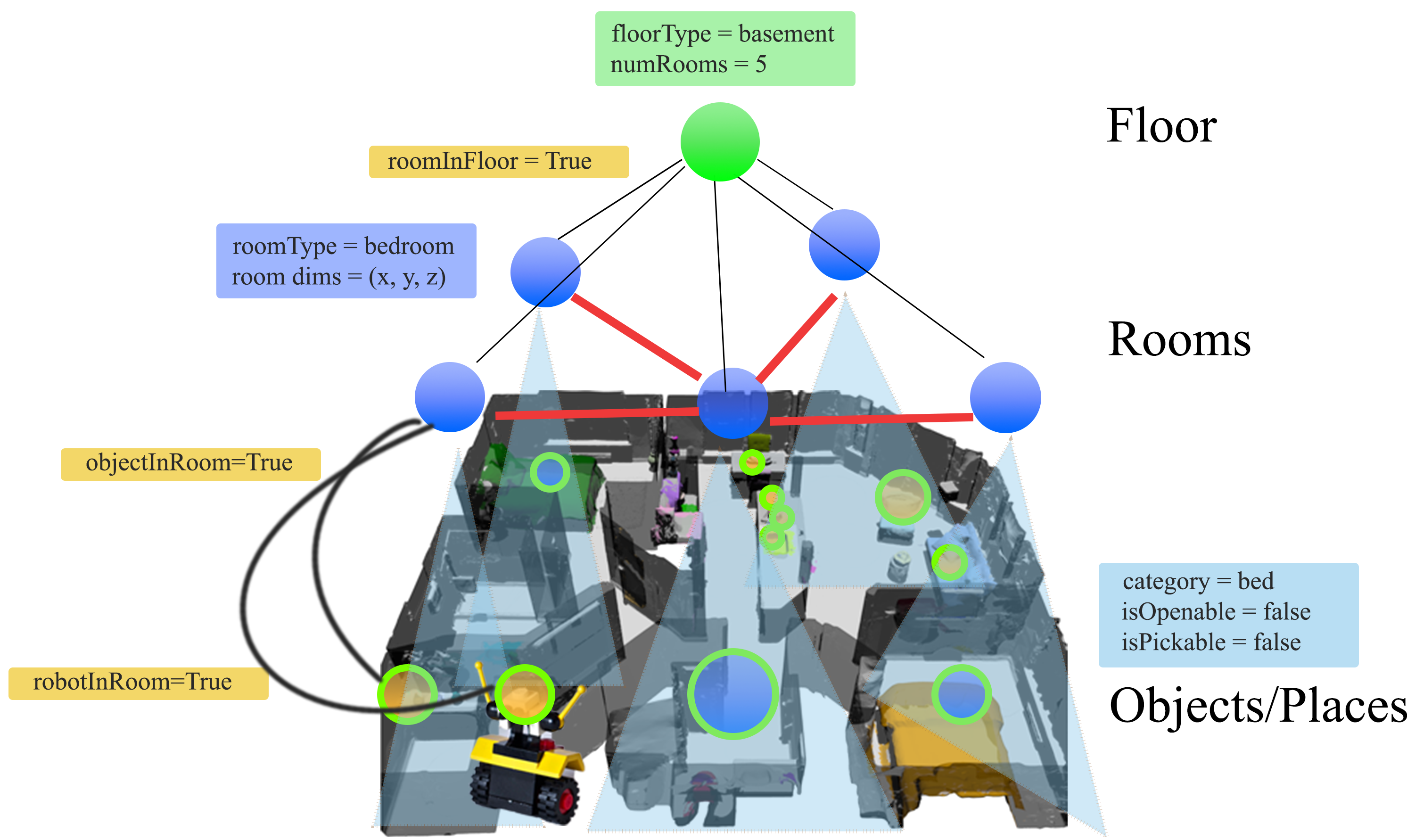
Authors: Christopher Agia, Krishna Murthy Jatavallabhula, Mohamed Khodeir, Ondrej Miksik, Vibhav Vineet, Mustafa Mukadam, Liam Paull, Florian Shkurti
Contact: cagia@stanford.edu
Links: Paper | Website
Keywords: robot task planning, 3d scene graphs, learning to plan, benchmarks
What Matters in Learning from Offline Human Demonstrations for Robot Manipulation

Authors: Ajay Mandlekar, Danfei Xu, Josiah Wong, Soroush Nasiriany, Chen Wang, Rohun Kulkarni, Li Fei-Fei, Silvio Savarese, Yuke Zhu, Roberto Martín-Martín
Contact: amandlek@cs.stanford.edu
Award nominations: Oral
Links: Paper | Blog Post | Video | Website
Keywords: imitation learning, offline reinforcement learning, robot manipulation
XIRL: Cross-embodiment Inverse Reinforcement Learning

Authors: Kevin Zakka, Andy Zeng, Pete Florence, Jonathan Tompson, Jeannette Bohg, Debidatta Dwibedi
Contact: zakka@berkeley.edu
Links: Paper | Website
Keywords: inverse reinforcement learning, imitation learning, self-supervised learning
iGibson 2.0: Object-Centric Simulation for Robot Learning of Everyday Household Tasks

Authors: Chengshu Li*, Fei Xia*, Roberto Martín-Martín*, Michael Lingelbach, Sanjana Srivastava, Bokui Shen, Kent Vainio, Cem Gokmen, Gokul Dharan, Tanish Jain, Andrey Kurenkov, C. Karen Liu, Hyowon Gweon, Jiajun Wu, Li Fei-Fei, Silvio Savarese
Contact: chengshu@stanford.edu
Links: Paper | Website
Keywords: simulation environment, embodied ai, virtual reality interface
Learning Feasibility to Imitate Demonstrators with Different Dynamics
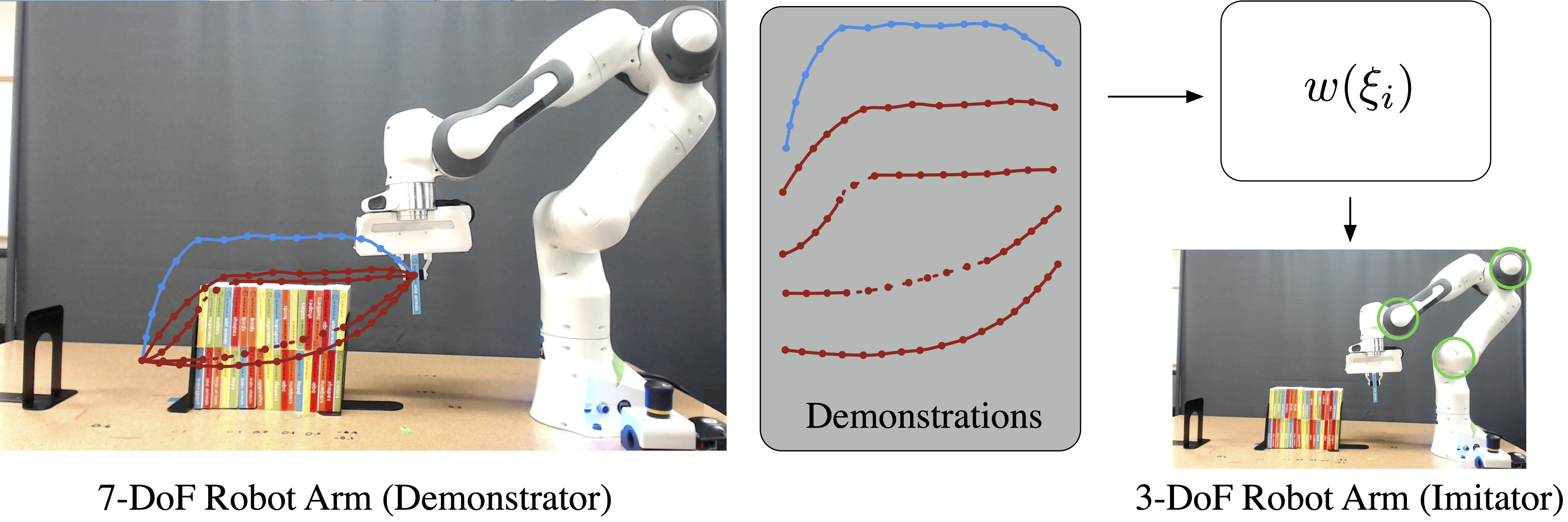
Authors: Zhangjie Cao, Yilun Hao, Mengxi Li, Dorsa Sadigh
Contact: caozj@cs.stanford.edu
Keywords: imitation learning, learning from agents with different dynamics
We look forward to seeing you at CoRL 2021!
Differences in public views on climate change around the world, by gender
Emergencies tend to exacerbate preexisting vulnerabilities, leaving women more likely to experience the negative effects of environmental, economic, and social crises. The COVID-19 pandemic was no exception, during which women were forced to spend more time doing unpaid domestic work. In the last year, women-led businesses also closed at higher rates than those led by men.
Climate change is already having a disproportionate impact on women, which will only increase as the climate crisis progresses. Women, for example, have higher rates of heat-related morbidity and mortality than men. In many countries, however, the unequal impacts from climate change are driven by long-standing social norms whereby women carry the primary responsibility for managing the household, including the provision of food, water, and shelter — activities all affected by climate change. For example, as rivers have become saltier, women have to travel farther to fetch clean water. When severe weather such as floods and droughts caused by climate change affects communities, young women and girls may have to drop out of school to support their families, and they may be at an increased risk of organized human trafficking because protective patterns in families and society are disrupted. Even at home, they may be at a higher risk of physical, sexual, and domestic violence in the aftermath of disasters.
Information is critical for climate resiliency
Given their disproportionate vulnerability, it is critical to support women around the world as they work to increase their climate resiliency. To better understand viewpoints and challenges associated with climate change, Data for Good at Meta partnered with the Yale Program on Climate Change Communication to conduct a survey of Facebook users in early 2021. The survey asked over 75,000 people across 31 countries and territories about their climate change knowledge, attitudes, policy preferences, and behaviors. All respondents were asked to self-identify their gender*, allowing for a unique analysis of the viewpoints of women and how climate change affects them.
Gender differences in awareness of climate change and concern about its effects
In this study, we found that a majority of people in about half of the countries and territories surveyed said they knew at least a moderate amount about climate change, led by Australia and Germany. However, in some countries, there were significant numbers of people who had little to no knowledge of climate change. This includes more than a quarter of people in Nigeria who reported that they had “never heard of it,” as well as substantial portions of people in Malaysia, Egypt, Saudi Arabia, and Vietnam. Since this survey was conducted on Facebook, it may also have underrepresented offline populations that research has shown are less likely to know about climate change, suggesting that even higher proportions of some populations may not know about the existence of this crisis.
While there is lower reported knowledge of climate change in less industrialized countries, there are larger gaps between genders in industrial countries such as the U.K., Canada, and the United States. We see significantly more men saying they know at least a moderate amount about climate change in these countries, highlighting the need to raise public awareness on the issue in both developed and developing countries.

While on average women who took the survey said they knew less about climate change, we found that they were consistently more worried about the issue than men. In the United States, this difference was much larger than in previous studies, with about three-quarters of women reporting being “somewhat worried” or “very worried” about this issue, compared with just over half of men, with similar discrepancies in most of Europe, Canada, and Australia.

Analyzing the potential harm of the changing climate, more women than men said it would harm them personally “a great deal” or a “moderate amount.” In the United States, the U.K., and Canada, there was a nearly 15 percentage point difference between men’s and women’s predictions of harm. This difference is not unfounded — previous research has shown that heatwaves in France, China, and India, as well as tropical cyclones in Bangladesh and the Philippines, were more deadly for women than they were for men. Prior comparisons in the United States also show that women perceive more harm than men on a range of climate-related risk perceptions.

Education and communication
Knowledge about the impacts of climate change along with mitigation and adaptation strategies are all necessary for households and communities addressing this crisis. In particular, women need access to information that helps them address climate impacts that affect their well-being, such as their access to food, water, fuel, and possible displacement due to extreme weather.
While a majority of people in all countries and territories said they want more information about climate change, significantly greater proportions of women reported wanting to know more about the topic. The difference between men and women was notable in the United States, the Czech Republic, Australia, and Saudi Arabia, where the proportion of women who wanted more information about climate change was 10 to 15 percentage points higher than the proportion of men saying so.

There is still an enormous need for basic education, awareness building, and understanding of climate change around the world. As a global social media platform, Meta is well positioned to help share accurate information about climate change, a core motivation for the creation of its Climate Science Center. Through this survey, we learned that while most people surveyed correctly identified human activity as the primary cause of climate change, sizable portions of the population still believe it is caused mostly by natural changes or equally by natural changes and human activity. People in Spain were the most aware that climate change is caused mostly by human activity (64 percent), but even in that setting, more than one in three thought that climate change was caused mostly by natural changes in the environment or caused equally by human activities and natural changes. At the other end of the spectrum, fewer than two in 10 people in Indonesia correctly understood the main driver of climate change.
We observe differences by gender even on these beliefs about climate change. Even though a larger proportion of women are worried about climate change, fewer women are aware of its root causes. This discrepancy is particularly large in Vietnam and Nigeria, where women are less aware than men of the causes of climate change. However, in a few European countries, such as the Netherlands and Czech Republic, more women than men understand the causes of climate change.

This study demonstrates that gender plays an important role in shaping public understanding and responses to climate change. As a result, climate communication campaigns need to recognize these diverse responses and tailor their strategies. We are encouraged by promising research that our partners at the Yale Program on Climate Change Communication are doing to better understand different audiences on the topic of climate change and meet their unique needs. Strategies such as storytelling may be particularly effective by including emotional content as well as accurate information.
As a global platform, Meta has a unique ability to inform and engage people around the world in climate change solutions. This study is the first of many to help our partners ensure that people have access to information, resources, and tools to reduce the threat of climate change and prepare for the impacts.
For researchers interested in using this survey data or other datasets provided by Data for Good at Meta, please contact dataforgood@fb.com. Our publicly available datasets can also be found on the Humanitarian Data Exchange.
*The survey was fielded between February 17, 2021, and March 3, 2021, to Facebook users over the age of 18. Survey results have been weighted to better reflect the population of each country or territory. More on the methodology is available here. This blog focuses on differences between men and women and unfortunately does not include perspectives of people beyond the gender binary due to a few constraints, including limitations in sample size.
The post Differences in public views on climate change around the world, by gender appeared first on Facebook Research.
EMNLP: Mitigating bias and “getting closer to the user”
Amazon’s Georgiana Dinu on current challenges in machine translation.Read More
Toward speech recognition for uncommon spoken languages
Automated speech-recognition technology has become more common with the popularity of virtual assistants like Siri, but many of these systems only perform well with the most widely spoken of the world’s roughly 7,000 languages.
Because these systems largely don’t exist for less common languages, the millions of people who speak them are cut off from many technologies that rely on speech, from smart home devices to assistive technologies and translation services.
Recent advances have enabled machine learning models that can learn the world’s uncommon languages, which lack the large amount of transcribed speech needed to train algorithms. However, these solutions are often too complex and expensive to be applied widely.
Researchers at MIT and elsewhere have now tackled this problem by developing a simple technique that reduces the complexity of an advanced speech-learning model, enabling it to run more efficiently and achieve higher performance.
Their technique involves removing unnecessary parts of a common, but complex, speech recognition model and then making minor adjustments so it can recognize a specific language. Because only small tweaks are needed once the larger model is cut down to size, it is much less expensive and time-consuming to teach this model an uncommon language.
This work could help level the playing field and bring automatic speech-recognition systems to many areas of the world where they have yet to be deployed. The systems are important in some academic environments, where they can assist students who are blind or have low vision, and are also being used to improve efficiency in health care settings through medical transcription and in the legal field through court reporting. Automatic speech-recognition can also help users learn new languages and improve their pronunciation skills. This technology could even be used to transcribe and document rare languages that are in danger of vanishing.
“This is an important problem to solve because we have amazing technology in natural language processing and speech recognition, but taking the research in this direction will help us scale the technology to many more underexplored languages in the world,” says Cheng-I Jeff Lai, a PhD student in MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL) and first author of the paper.
Lai wrote the paper with fellow MIT PhD students Alexander H. Liu, Yi-Lun Liao, Sameer Khurana, and Yung-Sung Chuang; his advisor and senior author James Glass, senior research scientist and head of the Spoken Language Systems Group in CSAIL; MIT-IBM Watson AI Lab research scientists Yang Zhang, Shiyu Chang, and Kaizhi Qian; and David Cox, the IBM director of the MIT-IBM Watson AI Lab. The research will be presented at the Conference on Neural Information Processing Systems in December.
Learning speech from audio
The researchers studied a powerful neural network that has been pretrained to learn basic speech from raw audio, called Wave2vec 2.0.
A neural network is a series of algorithms that can learn to recognize patterns in data; modeled loosely off the human brain, neural networks are arranged into layers of interconnected nodes that process data inputs.
Wave2vec 2.0 is a self-supervised learning model, so it learns to recognize a spoken language after it is fed a large amount of unlabeled speech. The training process only requires a few minutes of transcribed speech. This opens the door for speech recognition of uncommon languages that lack large amounts of transcribed speech, like Wolof, which is spoken by 5 million people in West Africa.
However, the neural network has about 300 million individual connections, so it requires a massive amount of computing power to train on a specific language.
The researchers set out to improve the efficiency of this network by pruning it. Just like a gardener cuts off superfluous branches, neural network pruning involves removing connections that aren’t necessary for a specific task, in this case, learning a language. Lai and his collaborators wanted to see how the pruning process would affect this model’s speech recognition performance.
After pruning the full neural network to create a smaller subnetwork, they trained the subnetwork with a small amount of labeled Spanish speech and then again with French speech, a process called finetuning.
“We would expect these two models to be very different because they are finetuned for different languages. But the surprising part is that if we prune these models, they will end up with highly similar pruning patterns. For French and Spanish, they have 97 percent overlap,” Lai says.
They ran experiments using 10 languages, from Romance languages like Italian and Spanish to languages that have completely different alphabets, like Russian and Mandarin. The results were the same — the finetuned models all had a very large overlap.
A simple solution
Drawing on that unique finding, they developed a simple technique to improve the efficiency and boost the performance of the neural network, called PARP (Prune, Adjust, and Re-Prune).
In the first step, a pretrained speech recognition neural network like Wave2vec 2.0 is pruned by removing unnecessary connections. Then in the second step, the resulting subnetwork is adjusted for a specific language, and then pruned again. During this second step, connections that had been removed are allowed to grow back if they are important for that particular language.
Because connections are allowed to grow back during the second step, the model only needs to be finetuned once, rather than over multiple iterations, which vastly reduces the amount of computing power required.
Testing the technique
The researchers put PARP to the test against other common pruning techniques and found that it outperformed them all for speech recognition. It was especially effective when there was only a very small amount of transcribed speech to train on.
They also showed that PARP can create one smaller subnetwork that can be finetuned for 10 languages at once, eliminating the need to prune separate subnetworks for each language, which could also reduce the expense and time required to train these models.
Moving forward, the researchers would like to apply PARP to text-to-speech models and also see how their technique could improve the efficiency of other deep learning networks.
“There are increasing needs to put large deep-learning models on edge devices. Having more efficient models allows these models to be squeezed onto more primitive systems, like cell phones. Speech technology is very important for cell phones, for instance, but having a smaller model does not necessarily mean it is computing faster. We need additional technology to bring about faster computation, so there is still a long way to go,” Zhang says.
Self-supervised learning (SSL) is changing the field of speech processing, so making SSL models smaller without degrading performance is a crucial research direction, says Hung-yi Lee, associate professor in the Department of Electrical Engineering and the Department of Computer Science and Information Engineering at National Taiwan University, who was not involved in this research.
“PARP trims the SSL models, and at the same time, surprisingly improves the recognition accuracy. Moreover, the paper shows there is a subnet in the SSL model, which is suitable for ASR tasks of many languages. This discovery will stimulate research on language/task agnostic network pruning. In other words, SSL models can be compressed while maintaining their performance on various tasks and languages,” he says.
This work is partially funded by the MIT-IBM Watson AI Lab and the 5k Language Learning Project.
Self-Supervised Reversibility-Aware Reinforcement Learning
Posted by Johan Ferret, Student Researcher, Google Research, Brain Team
An approach commonly used to train agents for a range of applications from robotics to chip design is reinforcement learning (RL). While RL excels at discovering how to solve tasks from scratch, it can struggle in training an agent to understand the reversibility of its actions, which can be crucial to ensure that agents behave in a safe manner within their environment. For instance, robots are generally costly and require maintenance, so one wants to avoid taking actions that might lead to broken components. Estimating if an action is reversible or not (or better, how easily it can be reversed) requires a working knowledge of the physics of the environment in which the agent is operating. However, in the standard RL setting, agents do not possess a model of the environment sufficient to do this.
In “There Is No Turning Back: A Self-Supervised Approach to Reversibility-Aware Reinforcement Learning”, accepted at NeurIPS 2021, we present a novel and practical way of approximating the reversibility of agent actions in the context of RL. This approach, which we call Reversibility-Aware RL, adds a separate reversibility estimation component to the RL procedure that is self-supervised (i.e., it learns from unlabeled data collected by the agents). It can be trained either online (jointly with the RL agent) or offline (from a dataset of interactions). Its role is to guide the RL policy towards reversible behavior. This approach increases the performance of RL agents on several tasks, including the challenging Sokoban puzzle game.
Reversibility-Aware RL
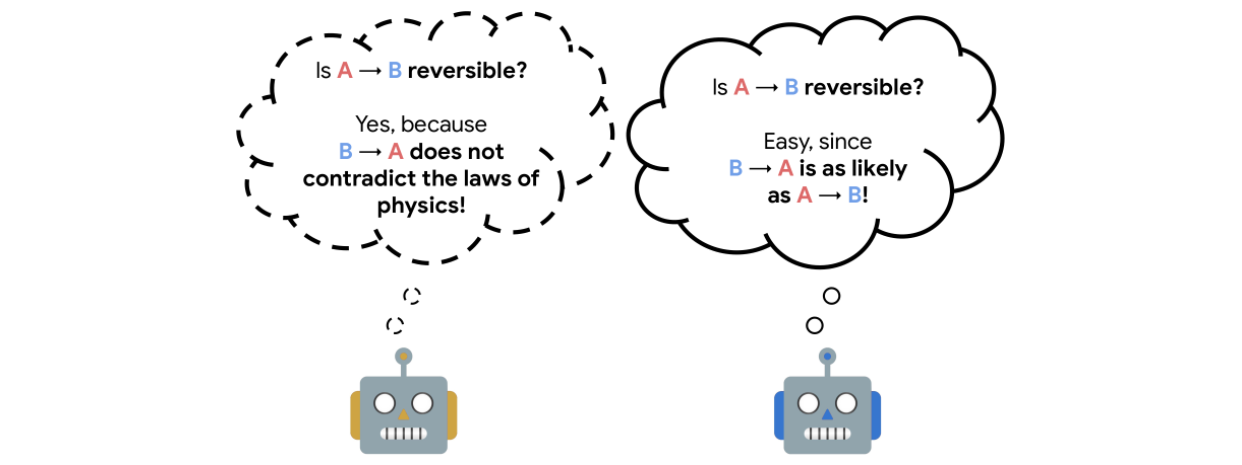
The reversibility component added to the RL procedure is learned from interactions, and crucially, is a model that can be trained separate from the agent itself. The model training is self-supervised and does not require that the data be labeled with the reversibility of the actions. Instead, the model learns about which types of actions tend to be reversible from the context provided by the training data alone.We call the theoretical explanation for this empirical reversibility, a measure of the probability that an event A precedes another event B, knowing that A and B both happen. Precedence is a useful proxy for true reversibility because it can be learned from a dataset of interactions, even without rewards.
Imagine, for example, an experiment where a glass is dropped from table height and when it hits the floor it shatters. In this case, the glass goes from position A (table height) to position B (floor) and regardless of the number of trials, A always precedes B, so when randomly sampling pairs of events, the probability of finding a pair in which A precedes B is 1. This would indicate an irreversible sequence. Assume, instead, a rubber ball was dropped instead of the glass. In this case, the ball would start at A, drop to B, and then (approximately) return to A. So, when sampling pairs of events, the probability of finding a pair in which A precedes B would only be 0.5 (the same as the probability that a random pair showed B preceding A), and would indicate a reversible sequence.
|
| Reversibility estimation relies on the knowledge of the dynamics of the world. A proxy to reversibility is precedence, which establishes which of two events comes first on average,given that both are observed. |
In practice, we sample pairs of events from a collection of interactions, shuffle them, and train the neural network to reconstruct the actual chronological order of the events. The network’s performance is measured and refined by comparing its predictions against the ground truth derived from the timestamps of the actual data. Since events that are temporally distant tend to be either trivial or impossible to order, we sample events in a temporal window of fixed size. We then use the prediction probabilities of this estimator as a proxy for reversibility: if the neural network’s confidence that event A happens before event B is higher than a chosen threshold, then we deem that the transition from event A to B is irreversible.
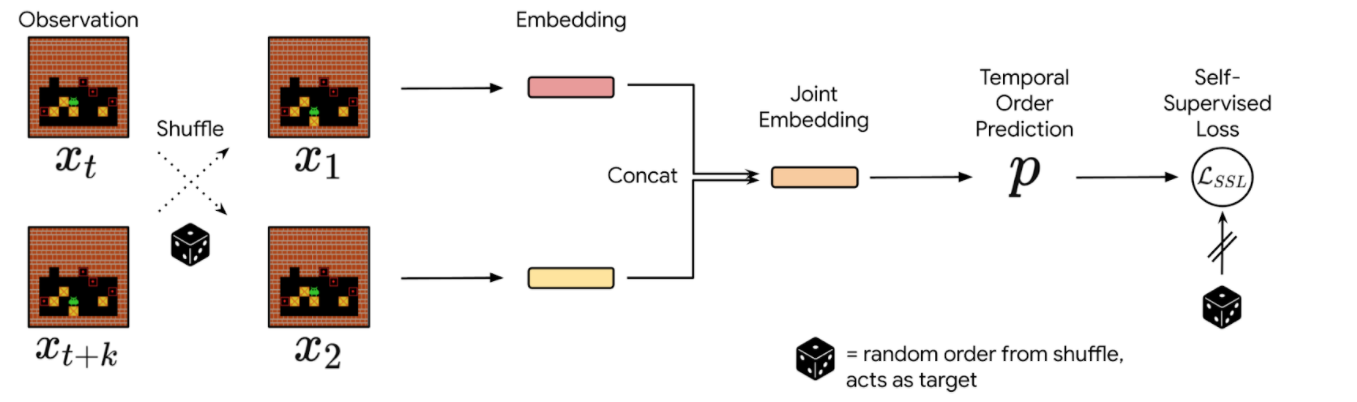 |
| Precedence estimation consists of predicting the temporal order of randomly shuffled events. |
Integrating Reversibility into RL
We propose two concurrent ways of integrating reversibility in RL:
- Reversibility-Aware Exploration (RAE): This approach penalizes irreversible transitions, via a modified reward function. When the agent picks an action that is considered irreversible, it receives a reward corresponding to the environment’s reward minus a positive, fixed penalty, which makes such actions less likely, but does not exclude them.
- Reversibility-Aware Control (RAC): Here, all irreversible actions are filtered out, a process that serves as an intermediate layer between the policy and the environment. When the agent picks an action that is considered irreversible, the action selection process is repeated, until a reversible action is chosen.
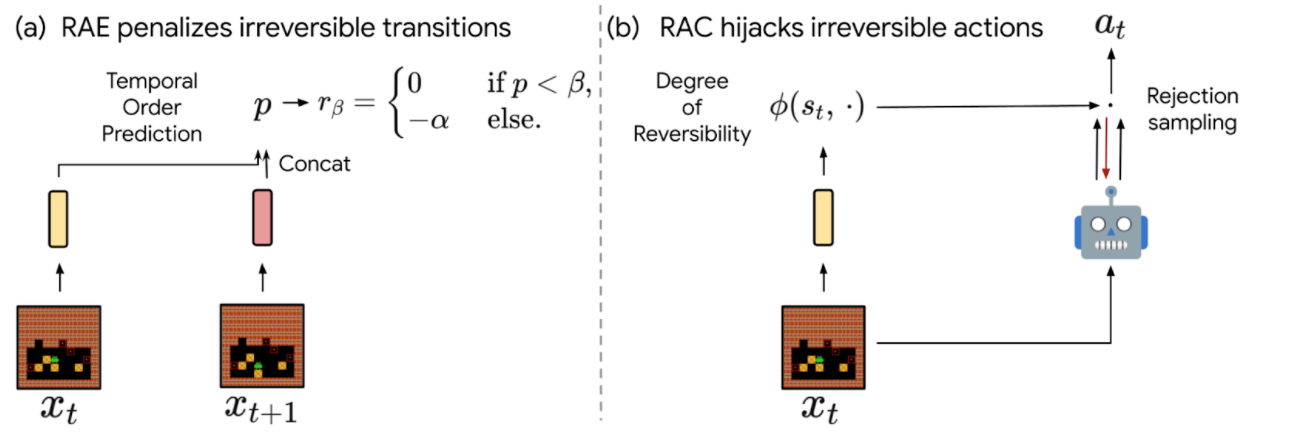 |
| The proposed RAE (left) and RAC (right) methods for reversibility-aware RL. |
An important distinction between RAE and RAC is that RAE only encourages reversible actions, it does not prohibit them, which means that irreversible actions can still be performed when the benefits outweigh costs (as in the Sokoban example below). As a result, RAC is better suited for safe RL where irreversible side-effects induce risks that should be avoided entirely, and RAE is better suited for tasks where it is suspected that irreversible actions are to be avoided most of the time.
To illustrate the distinction between RAE and RAC, we evaluate the capabilities of both proposed methods. A few example scenarios follow:
- Avoiding (but not prohibiting) irreversible side-effects
A general rule for safe RL is to minimize irreversible interactions when possible, as a principle of caution. To test such capabilities, we introduce a synthetic environment where an agent in an open field is tasked with reaching a goal. If the agent follows the established pathway, the environment remains unchanged, but if it departs from the pathway and onto the grass, the path it takes turns to brown. While this changes the environment, no penalty is issued for such behavior.
In this scenario, a typical model-free agent, such as a Proximal Policy Optimization (PPO) agent, tends to follow the shortest path on average and spoils some of the grass, whereas a PPO+RAE agent avoids all irreversible side-effects.
Top-left: The synthetic environment in which the agent (blue) is tasked with reaching a goal (pink). A pathway is shown in grey leading from the agent to the goal, but it does not follow the most direct route between the two. Top-right: An action sequence with irreversible side-effects of an agent’s actions. When the agent departs from the path, it leaves a brown path through the field. Bottom-left: The visitation heatmap for a PPO agent. Agents tend to follow a more direct path than that shown in grey. Bottom-right: The visitation heatmap for a PPO+RAE agent. The irreversibility of going off-path encourages the agent to stay on the established grey path. - Safe interactions by prohibiting irreversibility
We also tested against the classic Cartpole task, in which the agent controls a cart in order to balance a pole standing precariously upright on top of it. We set the maximum number of interactions to 50k steps, instead of the usual 200. On this task, irreversible actions tend to cause the pole to fall, so it is better to avoid such actions at all.
We show that combining RAC with any RL agent (even a random agent) never fails, given that we select an appropriate threshold for the probability that an action is irreversible. Thus, RAC can guarantee safe, reversible interactions from the very first step in the environment.
We show how the Cartpole performance of a random policy equipped with RAC evolves with different threshold values (ꞵ). Standard model-free agents (DQN, M-DQN) typically score less than 3000, compared to 50000 (the maximum score) for an agent governed by a random+RAC policy at a threshold value of β=0.4. - Avoiding deadlocks in Sokoban
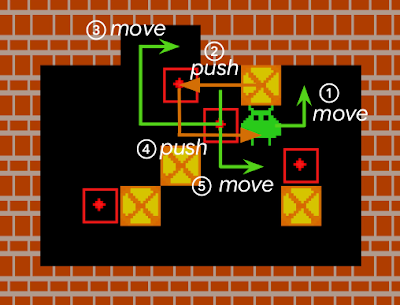
Sokoban is a puzzle game in which the player controls a warehouse keeper and has to push boxes onto target spaces, while avoiding unrecoverable situations (e.g., when a box is in a corner or, in some cases, along a wall).
An action sequence that completes a Sokoban level. Boxes (yellow squares with a red “x”) must be pushed by an agent onto targets (red outlines with a dot in the middle). Because the agent cannot pull the boxes, any box pushed against a wall can be difficult, if not impossible to get away from the wall, i.e., it becomes “deadlocked”. For a standard RL model, early iterations of the agent typically act in a near-random fashion to explore the environment, and consequently, get stuck very often. Such RL agents either fail to solve Sokoban puzzles, or are quite inefficient at it.
Agents that explore randomly quickly engage themselves in deadlocks that prevent them from completing levels (as an example here, pushing the rightmost box on the wall cannot be reversed). We compared the performance in the Sokoban environment of IMPALA, a state-of-the-art model-free RL agent, to that of an IMPALA+RAE agent. We find that the agent with the combined IMPALA+RAE policy is deadlocked less frequently, resulting in superior scores.
The scores of IMPALA and IMPALA+RAE on a set of 1000 Sokoban levels. A new level is sampled at the beginning of each episode.The best score is level dependent and close to 10. In this task, detecting irreversible actions is difficult because it is a highly imbalanced learning problem — only ~1% of actions are indeed irreversible, and many other actions are difficult to flag as reversible, because they can only be reversed through a number of additional steps by the agent.
Reversing an action is sometimes non-trivial. In the example shown here, a box has been pushed against the wall, but is still reversible. However, reversing the situation takes at least five separate movements comprising 17 distinct actions by the agent (each numbered move being the result of several actions from the agent). We estimate that approximately half of all Sokoban levels require at least one irreversible action to be completed (e.g., because at least one target destination is adjacent to a wall). Since IMPALA+RAE solves virtually all levels, it implies that RAE does not prevent the agent from taking irreversible actions when it is crucial to do so.





Conclusion
We present a method that enables RL agents to predict the reversibility of an action by learning to model the temporal order of randomly sampled trajectory events, which results in better exploration and control. Our proposed method is self-supervised, meaning that it does not necessitate any prior knowledge about the reversibility of actions, making it well suited to a variety of environments. In the future, we are interested in studying further how these ideas could be applied in larger scale and safety-critical applications.
Acknowledgements
We would like to thank our paper co-authors Nathan Grinsztajn, Philippe Preux, Olivier Pietquin and Matthieu Geist. We would also like to thank Bobak Shahriari, Théophane Weber, Damien Vincent, Alexis Jacq, Robert Dadashi, Léonard Hussenot, Nino Vieillard, Lukasz Stafiniak, Nikola Momchev, Sabela Ramos and all those who provided helpful discussion and feedback on this work.