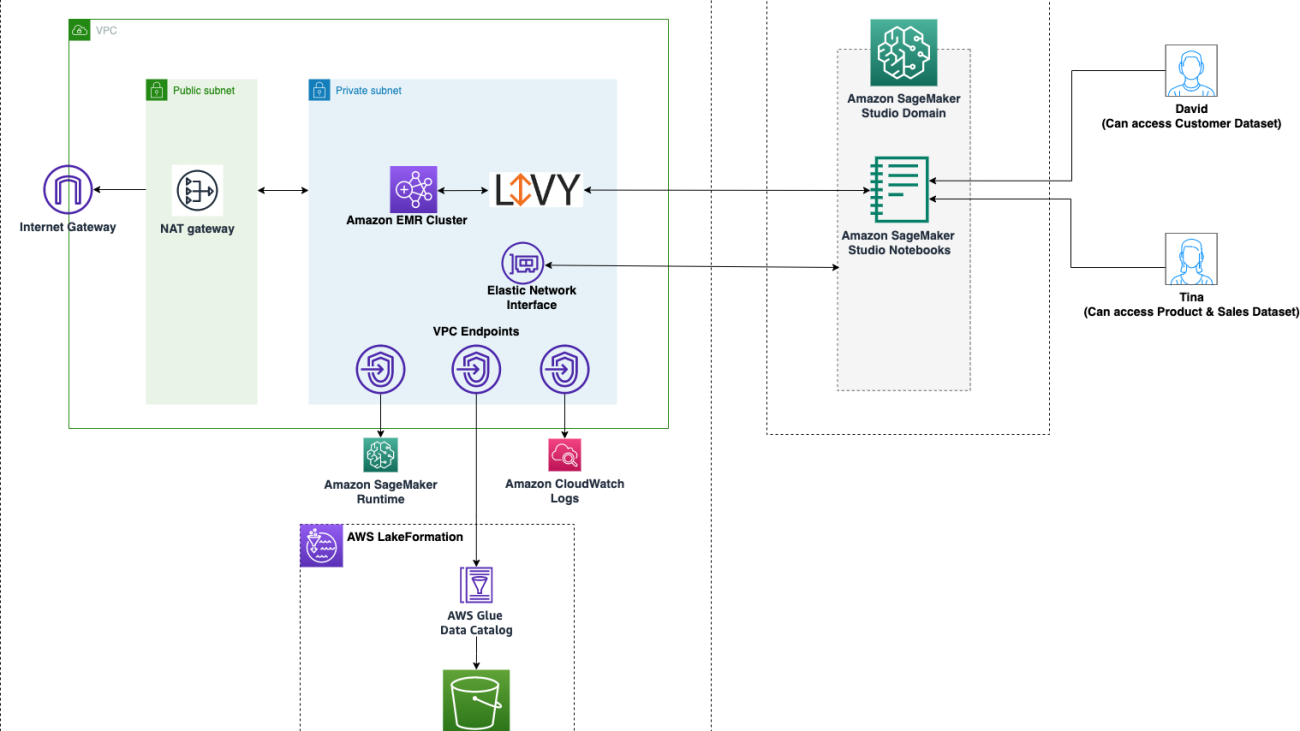
Amazon SageMaker Studio is a fully integrated development environment (IDE) for machine learning (ML) that enables data scientists and developers to perform every step of the ML workflow, from preparing data to building, training, tuning, and deploying models. Studio comes with built-in integration with Amazon EMR so that data scientists can interactively prepare data at petabyte scale using open-source frameworks such as Apache Spark, Hive, and300 Presto right from within Studio notebooks. Data is often stored in data lakes managed by AWS Lake Formation, enabling you to apply fine-grained access control through a simple grant or revoke mechanism. We’re excited to announce that Studio now supports applying this fine-grained data access control with Lake Formation when accessing data through Amazon EMR.
Until now, when you ran multiple data processing jobs on an EMR cluster, all the jobs used the same AWS Identity and Access Management (IAM) role for accessing data—namely, the cluster’s Amazon Elastic Compute Cloud (Amazon EC2) instance profile. Therefore, to run jobs that needed access to different data sources such as different Amazon Simple Storage Service (Amazon S3) buckets, you had to configure the EC2 instance profile with policies that allowed access to the union of all such data sources. Additionally, for enabling groups of users with differential access to data, you had to create multiple separate clusters, one for each group, resulting in operational overheads. Separately, jobs submitted to Amazon EMR from Studio notebooks were unable to apply fine-grained data access control with Lake Formation.
Starting with the release of Amazon EMR 6.9, when you connect to EMR clusters from Studio notebooks, you can visually browse and choose an IAM role on the fly called the runtime IAM role. Subsequently, all your Apache Spark, Apache Hive, or Presto jobs created from Studio notebooks will access only the data and resources permitted by policies attached to the runtime role. Also, when data is accessed from data lakes managed with Lake Formation, you can enforce table-level and column-level access using policies attached to the runtime role.
With this new capability, multiple Studio users can connect to the same EMR cluster, each using a runtime IAM role scoped with permissions matching their individual level of access to data. Their user sessions are also completely isolated from one another on the shared cluster. With this ability to control fine-grained access to data on the same shared cluster, you can simplify provisioning of EMR clusters, thereby reducing operational overhead and saving costs.
In this post, we demonstrate how to use a Studio notebook to connect to an EMR cluster using runtime roles. We provide a sample Studio Lifecycle Configuration that can help configure the EMR runtime roles that a Studio user profile has access to. Additionally, we manage data access in a data lake via Lake Formation by enforcing row-level and column-level permissions to the EMR runtime roles.
Solution overview
We demonstrate this solution with an end-to-end use case using a sample dataset, the TPC data model. This data represents transaction data for products and includes information such as customer demographics, inventory, web sales, and promotions. To demonstrate fine-grained data access permissions, we consider the following two users:
- David, a data scientist on the marketing team. He is tasked with building a model on customer segmentation, and is only permitted to access non-sensitive customer data.
- Tina, a data scientist on the sales team. She is tasked with building the sales forecast model, and needs access to sales data for the particular region. She is also helping the product team with innovation, and therefore needs access to product data as well.
The architecture is implemented as follows:
- Lake Formation manages the data lake, and the raw data is available in S3 buckets
- Amazon EMR is used to query the data from the data lake and perform data preparation using Spark
- IAM roles are used to manage data access using Lake Formation
- Studio is used as the single visual interface to interactively query and prepare the data
The following diagram illustrates this architecture.

The following sections walk through the steps required to enable runtime IAM roles for Amazon EMR integration with an existing Studio domain. You can use the provided AWS CloudFormation stack in the Deploy the solution section below to set up the architectural components for this solution.
Prerequisites
Before you get started, make sure you have the following prerequisites:
Set up Amazon EMR with runtime roles
The EMR cluster should be created with IAM runtime roles enabled. For more details on using runtime roles with Amazon EMR, see Configure runtime roles for Amazon EMR steps. Associating runtime roles with EMR clusters is supported in Amazon EMR 6.9. Make sure the following configuration is in place:
- The EMR runtime role’s trust policy should allow the EMR EC2 instance profile to assume the role
- The EMR EC2 instance profile role should be able to assume the EMR runtime roles
- The EMR cluster should be created with encryption in transit
You can optionally choose to pass the SourceIdentity (the Studio user profile name) for monitoring the user resource access. Follow the steps outlined in Monitoring user resource access from Amazon SageMaker Studio to enable SourceIdentity for your Studio domain.
Finally, refer to Prepare Data using Amazon EMR for detailed setup and networking instructions on integrating Studio with EMR clusters.
Create bootstrap action for the cluster
You need to run a bootstrap action on the cluster to ensure Studio notebook’s connectivity with EMR through runtime roles. Complete the following steps:
- Download the bootstrap script from
s3://emr-data-access-control-<region>/customer-bootstrap-actions/gcsc/replace-rpms.sh, replacing region with your region
- Download this RPM file from
s3://emr-data-access-control-<region>/customer-bootstrap-actions/gcsc/emr-secret-agent-1.18.0-SNAPSHOT20221121212949.noarch.rpm
- Upload both files to an S3 bucket in your account and region
- When creating your EMR cluster, include the following bootstrap action:
--bootstrap-actions "Path=<S3-URI-of-the-bootstrap-script>,Args=[<S3-URI-of-the-RPM-file>]"
Update the Studio execution role
Your Studio user’s execution role needs to be updated to allow the GetClusterSessionCredentials API action. Add the following policy to the Studio execution role, replacing the resource with the cluster ARNs you wish to allow your users to connect to:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowEMRRuntimeRole",
"Effect": "Allow",
"Action": "elasticmapreduce:GetClusterSessionCredentials",
"Resource": [
"arn:aws:elasticmapreduce::<AWS_Account>:cluster/<Cluster-IDs>"
],
"Condition": {
"StringLike": {
"elasticmapreduce:ExecutionRoleArn": [
"arn:aws:iam::<AWS_Account>:role/<EMR-execution-roles>"
]
}
}
}
]
}
You can also use conditions to control which EMR execution roles can be used by the Studio execution role.
Alternatively, you can attach a role such as below, which restricts access to clusters based on resource tags. This allows for tag-based access control, and you can use the same policy statements across user roles, instead of explicitly adding cluster ARNs.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowEMRRuntimeRole",
"Effect": "Allow",
"Action": "elasticmapreduce:GetClusterSessionCredentials",
"Resource": “*”,
"Condition": {
"StringEquals": {
"elasticmapreduce:ResourceTag/<tag-key>": "<tag-value>"
}
}
}
]
}
Set up role configurations through Studio LCC
By default, the Studio UI uses the Studio execution role to connect to the EMR cluster. If your user can access multiple roles, they can update the EMR cluster connection commands with the role ARN they want to pass as a runtime role. For a better user experience, you can set up a configuration file on the user’s home directory on Amazon Elastic File System (Amazon EFS), which automatically informs the Studio UI of the roles that are available to connect for the user. You can also automate this process through Studio Lifecycle Configurations. We provide the following sample Lifecycle Configuration script to configure the roles:
#!/bin/bash
set -eux
FILE_DIRECTORY="/home/sagemaker-user/.sagemaker-analytics-configuration-DO_NOT_DELETE"
FILE_NAME="emr-configurations-DO_NOT_DELETE.json"
FILE="$FILE_DIRECTORY/$FILE_NAME"
mkdir -p $FILE_DIRECTORY
cat <<'EOF' > "$FILE"
{
"emr-execution-role-arns":
{
"<AccountID-where-cluster-exists>": [
"arn:aws:iam::<AccountID>:role/<emr-execution-role-1>",
"arn:aws:iam::<AccountID>:role/<emr-execution-role-2>"
]
}
}
EOF
Connect to clusters from the Studio UI
After the role and Lifecycle Configuration scripts are set up, you can launch the Studio UI and connect to the clusters when you create a new notebook using any of the following kernels:
- DataScience – Python 3 kernel
- DataScience 2.0 – Python 3 kernel
- DataScience 3.0 – Python 3 kernel
- SparkAnalytics 1.0 – SparkMagic and PySpark kernels
- SparkAnalytics 2.0 – SparkMagic and PySpark kernels
- SparkMagic – PySpark kernel
Note: The Studio UI for connecting to EMR clusters using runtime roles work only on JupyterLab version 3. See Jupyter versioning for details on upgrading to JL3.
Deploy the solution
To test out the solution end to end, we provide a CloudFormation template that sets up the services included in the architecture, to enable repeatable deployments. This template creates the following resources:
- An S3 bucket for the data lake.
- An EMR cluster with EMR runtime roles enabled.
- IAM roles for accessing the data in data lake, with fine-grained permissions:
Marketing-data-access-roleSales-data-access-roleElectronics-data-access-role
- A Studio domain and two user profiles. The Studio execution roles for the users allow the users to assume their corresponding EMR runtime roles.
- A Lifecycle Configuration to enable the selection of the role to use for the EMR connection.
- A Lake Formation database populated with the TPC data.
- Networking resources required for the setup, such as VPC, subnets, and security groups.
To deploy the solution, complete the following steps:
- Choose Launch Stack to launch the CloudFormation stack:

- Enter a stack name, provide the following parameters –
- An idle timeout for the EMR cluster (to avoid paying for the cluster when it’s not being used).
- An S3 URI with the EMR encryption key. You can follow the steps in the EMR documentation here to generate a key and zip file specific to your region. If you are deploying in US East (N. Virginia), remember to use
CN=*.ec2.internal, as specified in the documentation here. Make sure to upload the zip file on a S3 bucket in the same region as your CloudFormation stack deployment.
- Select I acknowledge that AWS CloudFormation might create IAM resources with custom names.
- Choose Create stack.
Once the Stack is created, allow Amazon EMR to query Lake Formation by updating the External Data Filtering settings on Lake Formation. Follow the instructions provided in the Lake Formation guide here, and choose ‘Amazon EMR’ for Session tag values, and enter your AWS account ID under AWS account IDs.
Test role-based data access
With the infrastructure in place, you’re ready to test out the fine-grained data access for the two Studio users. To recap, the user David should only be able to access non-sensitive customer data. Tina can access data in two tables: sales and product information. Let’s test each user profile.
David’s user profile
To test your data access with David’s user profile, complete the following steps:
- Log in to the AWS console.
- From the created Studio domain, launch Studio from the user profile
david-non-sensitive-customer.
- In the Studio UI, start a notebook with any of the supported kernels, e.g., SparkMagic image with the PySpark kernel.
The cluster is pre-created in the account.
- Connect to the cluster by choosing Cluster in your notebook and choosing the cluster
<StackName>-emr-cluster. In the role selector pop-up, choose the <StackName>-marketing-data-access-role.
- Choose Connect.
This will automatically create a notebook cell with magic commands to connect to the cluster. Wait for the cell to execute and the connection to be established before proceeding with the remaining steps.
Now let’s query the marketing table from the notebook.
- In a new cell, enter the following query and run the cell:
sqlContext.sql("show databases").show()
# use the TPC dataset
sqlContext.sql("use tpc")
sqlContext.sql("select * from dl_tpc_customer limit 10").show()
After the cell runs successfully, you can view the first 10 records in the table. Note that you can’t view the customers’ name, as the user only has permissions to read non-sensitive data, through column-level filtering.
Let’s test to make sure David can’t read any sensitive customer data.
- In a new cell, run the following query:
sqlContext.sql("select * from dl_tpc_customer_address limit 10").show()
This cell should throw an Access Denied error.
Tina’s user profile
Tina’s Studio execution role allows her to access the Lake Formation database using two EMR execution roles. This is achieved by listing the role ARNs in a configuration file in Tina’s file directory. These roles can be set using Studio Lifecycle Configurations to persist the roles across app restarts. To test Tina’s access, complete the following steps:
- Launch Studio from the user profile
tina-sales-electronics.
It’s a good practice to close any previous Studio sessions on your browser when switching user profiles. There can only be one active Studio user session at a time.
- In the Studio UI, start a notebook with any of the supported kernels, e.g., SparkMagic image with the PySpark kernel.
- Connect to the cluster by choosing Cluster in your notebook and choosing the cluster
<StackName>-emr-cluster.
- Choose Connect.
Because Tina’s profile is set up with multiple EMR roles, you’re prompted with a UI drop-down that allows you to connect using multiple roles.
- Choose the role
<StackName>-sales-data-access-role and choose Connect.

The Studio execution role is also available in the dropdown, as the clusters connect using the user’s execution role by default to connect to the cluster.
You can directly provide Lake Formation access to the user’s execution role as well.This will automatically create a notebook cell with magic commands to connect to the cluster, using the chosen role.Now let’s query the sales table from the notebook.
- In a new cell, enter the following query and run the cell:
sqlContext.sql("show databases").show()
# use the TPC dataset
sqlContext.sql("use tpc")
sqlContext.sql("select * from dl_tpc_web_sales limit 10").show()
After the cell runs successfully, you can view the first 10 records in the table.
Now let’s try accessing the product table.
- Choose Cluster again, and choose the cluster.
- In the role prompt pop-up, choose the role
<StackName>-electronics-data-access-role and connect to the cluster.
- After you’re connected successfully to the cluster with the electronics data access role, create a new cell and run the following query:
sqlContext.sql("select * from dl_tpc_item limit 10").show()
This cell should complete successfully, and you can view the first 10 records in the products table.
With a single Studio user profile, you have now successfully assumed multiple roles, and queried data in Lake Formation using multiple roles, without the need for restarting the notebooks or creating additional clusters. Now that you’re able to access the data using appropriate roles, you can interactively explore the data, visualize the data, and prepare data for training. You also used different user profiles to provide your users in different teams access to a specific table or columns and rows, without the need for additional clusters.
Clean up
When you’re finished experimenting with this solution, clean up your resources:
- Shut down the Studio apps for the user profiles. See Shut Down and Update SageMaker Studio and Studio Apps for instructions. Ensure that all apps are deleted before deleting the stack.
The EMR cluster will be automatically deleted after the idle timeout value.
- Delete the EFS volume created for the domain. You can view the EFS volume attached with the domain by using a DescribeDomain API call.
- Make sure to empty the S3 buckets created by this stack.
- Delete the stack from the AWS CloudFormation console.
Conclusion
This post showed you how you can use runtime roles to connect Studio with Amazon EMR to apply fine-grained data access control with Lake Formation. We also demonstrated how multiple Studio users canconnect to the same EMR cluster, each using a runtime IAM role scoped with permissions matching their individual level of access to data. We detailed the steps required to manually set up the integration, and provided a CloudFormation template to set up the infrastructure end to end. This feature is available in the following AWS regions: Europe (Paris), US East (N. Virginia and Ohio) and US West (Oregon), and the CloudFormation template will deploy in US East (N. Virginia and Ohio) and US West (Oregon).
To learn more about using EMR with SageMaker Studio, visit Prepare Data using Amazon EMR. We encourage you to try out this new functionality, and connect with the Machine Learning & AI community if you have any questions or feedback!
About the authors
 Durga Sury is a ML Solutions Architect in the Amazon SageMaker Service SA team. She is passionate about making machine learning accessible to everyone. In her 3 years at AWS, she has helped set up AI/ML platforms for enterprise customers. When she isn’t working, she loves motorcycle rides, mystery novels, and hikes with her four-year old husky.
Durga Sury is a ML Solutions Architect in the Amazon SageMaker Service SA team. She is passionate about making machine learning accessible to everyone. In her 3 years at AWS, she has helped set up AI/ML platforms for enterprise customers. When she isn’t working, she loves motorcycle rides, mystery novels, and hikes with her four-year old husky.
 Sriharsh Adari is a Senior Solutions Architect at Amazon Web Services (AWS), where he helps customers work backwards from business outcomes to develop innovative solutions on AWS. Over the years, he has helped multiple customers on data platform transformations across industry verticals. His core area of expertise include Technology Strategy, Data Analytics, and Data Science. In his spare time, he enjoys playing Tennis, binge-watching TV shows, and playing Tabla.
Sriharsh Adari is a Senior Solutions Architect at Amazon Web Services (AWS), where he helps customers work backwards from business outcomes to develop innovative solutions on AWS. Over the years, he has helped multiple customers on data platform transformations across industry verticals. His core area of expertise include Technology Strategy, Data Analytics, and Data Science. In his spare time, he enjoys playing Tennis, binge-watching TV shows, and playing Tabla.
 Maira Ladeira Tanke is an ML Specialist Solutions Architect at AWS. With a background in data science, she has 9 years of experience architecting and building ML applications with customers across industries. As a technical lead, she helps customers accelerate their achievement of business value through emerging technologies and innovative solutions. In her free time, Maira enjoys traveling and spending time with her family someplace warm.
Maira Ladeira Tanke is an ML Specialist Solutions Architect at AWS. With a background in data science, she has 9 years of experience architecting and building ML applications with customers across industries. As a technical lead, she helps customers accelerate their achievement of business value through emerging technologies and innovative solutions. In her free time, Maira enjoys traveling and spending time with her family someplace warm.
 Sumedha Swamy is a Principal Product Manager at Amazon Web Services. He leads SageMaker Studio team to build it into the IDE of choice for interactive data science and data engineering workflows. He has spent the past 15 years building customer-obsessed consumer and enterprise products using Machine Learning. In his free time he likes photographing the amazing geology of the American Southwest.
Sumedha Swamy is a Principal Product Manager at Amazon Web Services. He leads SageMaker Studio team to build it into the IDE of choice for interactive data science and data engineering workflows. He has spent the past 15 years building customer-obsessed consumer and enterprise products using Machine Learning. In his free time he likes photographing the amazing geology of the American Southwest.
 Jun Lyu is a Software Engineer on the SageMaker Notebooks team. He has a Master’s degree in engineering from Duke University. He has been working for Amazon since 2015 and has contributed to AWS services like Amazon Machine Learning, Amazon SageMaker Notebooks, and Amazon SageMaker Studio. In his spare time, he enjoys spending time with his family, reading, cooking, and playing video games.
Jun Lyu is a Software Engineer on the SageMaker Notebooks team. He has a Master’s degree in engineering from Duke University. He has been working for Amazon since 2015 and has contributed to AWS services like Amazon Machine Learning, Amazon SageMaker Notebooks, and Amazon SageMaker Studio. In his spare time, he enjoys spending time with his family, reading, cooking, and playing video games.
Read More









 NVIDIA GeForce NOW (@NVIDIAGFN)
NVIDIA GeForce NOW (@NVIDIAGFN)