Model tuning is the experimental process of finding the optimal parameters and configurations for a machine learning (ML) model that result in the best possible desired outcome with a validation dataset. Single objective optimization with a performance metric is the most common approach for tuning ML models. However, in addition to predictive performance, there may be multiple objectives which need to be considered for certain applications. For example,
- Fairness – The aim here is to encourage models to mitigate bias in model outcomes between certain sub-groups in the data, especially when humans are subject to algorithmic decisions. For example, a credit lending application should not only be accurate but also unbiased to different population sub-groups.
- Inference time – The aim here is to reduce the inference time during model invocation. For example, a speech recognition system must not only understand different dialects of the same language accurately, but also operate within a specified time limit that is acceptable by the business process.
- Energy efficiency – The aim here is to train smaller energy-efficient models. For example, neural network models are compressed for usage on mobile devices and thus naturally reduce their energy consumption by reducing the number of FLOPS required for a pass through the network.
Multi-objective optimization methods represent different trade-offs between the desired metrics. This can involve finding a global minimum of an objective function subject to a set of constraints on different metrics being simultaneously satisfied.
Amazon SageMaker Automatic Model Tuning (AMT) finds the best version of a model by running many SageMaker training jobs on your dataset using the algorithm and ranges of hyperparameters. It then chooses the hyperparameter values that result in a model that performs the best, as measured by a metric (e.g., accuracy, auc, recall) that you define. With Amazon SageMaker automatic model tuning, you can find the best version of your model by running training jobs on your dataset with several search strategies, such as Bayesian, Random search, Grid search, and Hyperband.
Amazon SageMaker Clarify can detect potential bias during data preparation, after model training, and in your deployed model. Currently, it offers 21 different metrics to choose from. These metrics are also openly available with the smclarify python package and github repository here. You can learn more about measuring bias with metrics from Amazon SageMaker Clarify at Learn how Amazon SageMaker Clarify helps detect bias.
In this blog we show you how to automatically tune a ML model with Amazon SageMaker AMT for both accuracy and fairness objectives by creating a single combined metric. We demonstrate a financial services use case of credit risk prediction with an accuracy metric of Area Under the Curve (AUC) to measure performance and a bias metric of Difference in Positive Proportions in Predicted Labels (DPPL) from SageMaker Clarify to measure the imbalance in model predictions for different demographic groups. The code for this example is available on GitHub.
Fairness in Credit Risk prediction
The credit lending industry relies heavily on credit scores for processing loan applications. Generally, credit scores reflect an applicant’s history of borrowing and paying back money, and lenders refer to them when determining an individual’s creditworthiness. Payment firms and banks are interested to build systems that can help identify the risk associated with a particular application and provide competitive credit products. Machine learning (ML) models can be used to build such a system that processes historical applicant data and predicts the credit risk profile. Data can include financial and employment history of the applicant, their demographics, and the new credit/loan context. There is always some statistical uncertainty with any model that predicts whether a particular applicant will default in the future. The systems need to provide a tradeoff between rejecting applications that might default over time and accepting applications that are eventually creditworthy.
Business owners of such a system need to ensure the validity and quality of the models as per existing and upcoming regulatory compliance requirements. They are obligated to treat customers fairly and provide transparency in their decision making. They might want to ensure that positive model predictions are not imbalanced across different groups (for example, gender, race, ethnicity, immigration status and others). Once the required data is collected, the ML model training typically optimizes for prediction performance as a primary objective with a metric like classification accuracy or AUC score. Alternatively, a model with a given performance objective can be constrained with a fairness metric to ensure certain requirements are maintained. One such technique to constrain the model is fairness-aware hyperparameter tuning. By applying these strategies, the best candidate model can have lower bias than the unconstrained model while maintaining a high predictive performance.

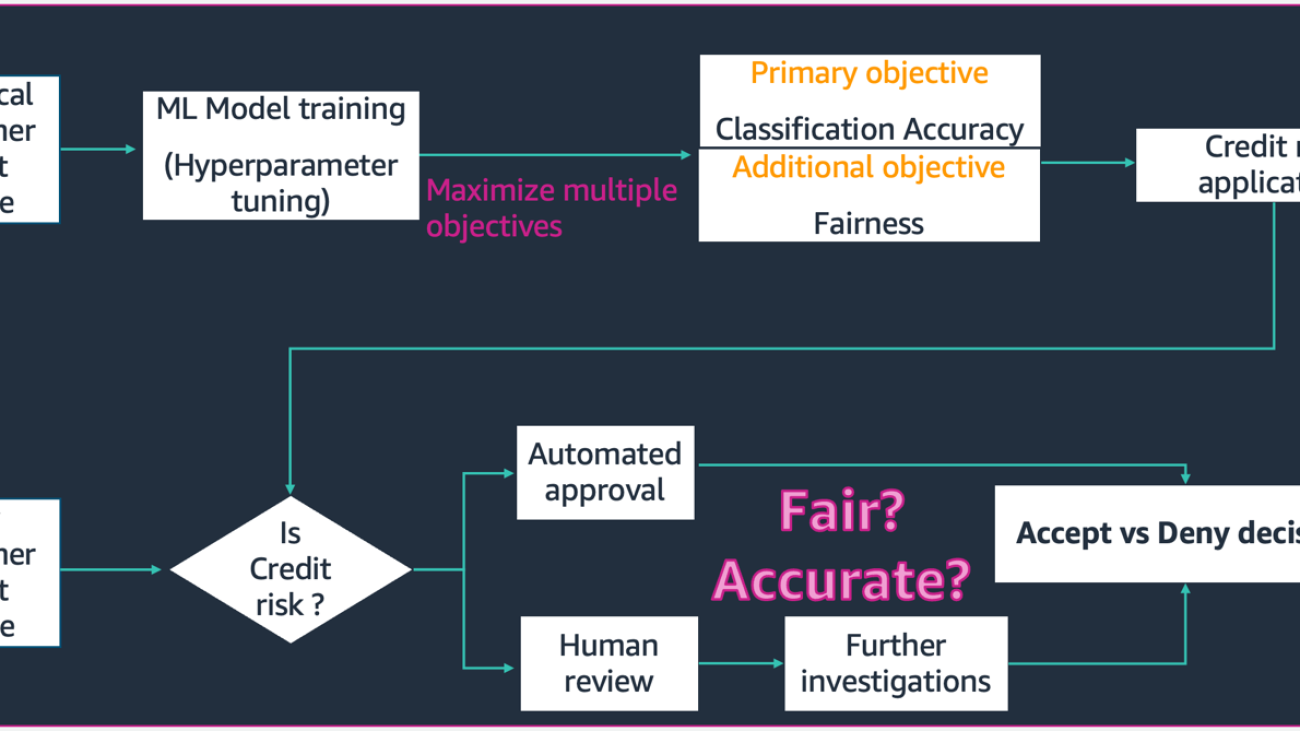
In the scenario depicted in this schematic,
- The ML model is built with historical customer credit profile data. The model training and hyperparameter tuning process maximizes for multiple objectives including classification accuracy and fairness. The model is deployed to an existing business process in a production system.
- A new customer credit profile is evaluated for credit risk. If low risk, it can go through an automated process. High risk applications could include human review before a final acceptance or rejection decision.
The decisions and metrics gathered during design and development, deployment and operations can be documented with SageMaker Model Cards and shared with the stakeholders.
This use case demonstrates how to reduce model bias against a specific group by fine tuning hyperparameters for a combined objective metric of both accuracy and fairness with SageMaker Automatic Model Tuning. We use the South German Credit dataset (South German Credit Data Set) .
The applicant data can be split into following categories:
- Demographic
- Financial Data
- Employment History
- Loan purpose

In this example, we specifically look at the ‘Foreign worker’ demographic and tune a model that predicts credit application decisions with high accuracy and low bias against that particular subgroup.
There are various bias metrics that can be used to evaluate fairness of the system with respect to specific sub-groups in the data. Here, we use the absolute value of Difference in Positive Proportions in Predicted Labels (DPPL) from SageMaker Clarify. In simple terms, DPPL measures the difference in positive class (good credit) assignments between non-foreign workers and foreign workers.
For example, if 4.5% of all foreign workers are assigned the positive label by the model, and 13.7% of all non-foreign workers are assigned the positive label, then DPPL = 0.137 – 0.045 = 0.092.
Solution Architecture
The figure below displays a high level overview of the architecture of an Automatic Model Tuning job with XGBoost on Amazon SageMaker.

In the solution, SageMaker Processing preprocesses the training dataset from Amazon S3. Amazon SageMaker Automatic Tuning instantiates multiple SageMaker training jobs with their associated EC2 instances and EBS volumes. The container for the algorithm (XGBoost) is loaded from Amazon ECR in each job. SageMaker AMT finds the best version of a model by running many training jobs on the preprocessed dataset using the specified algorithm script and range of hyperparameters. The output metrics are logged in Amazon CloudWatch for monitoring.
The hyperparameters we are tuning in this use case are as follows:
- eta – Step size shrinkage used in updates to prevent overfitting.
- min_child_weight – Minimum sum of instance weight (hessian) needed in a child.
- gamma – Minimum loss reduction required to make a further partition on a leaf node of the tree.
- max_depth – Maximum depth of a tree.
The definition of these hyperparameters and others available with SageMaker AMT can be found here.
First, we demonstrate a baseline scenario of a single performance objective metric for tuning hyperparameters with Automatic Model Tuning. Then, we demonstrate the optimized scenario of a multi-objective metric specified as a combination of performance metric and fairness metric.
Single Metric Hyperparameter Tuning (Baseline)
There is a choice of multiple metrics for a tuning job to evaluate the individual training jobs. As per the code snippet below, we specify the single objective metric as objective_metric_name. The hyperparameter tuning job returns the training job that gave the best value for the chosen objective metric.
In this baseline scenario, we are tuning for Area Under Curve (AUC) as seen below. It is important to note that we are only optimizing AUC, and not optimizing for other metrics such as fairness.
from sagemaker.tuner import IntegerParameter, CategoricalParameter, ContinuousParameter, HyperparameterTuner
hyperparameter_ranges = {'eta': ContinuousParameter(0, 1),
'min_child_weight': IntegerParameter(1, 10),
'gamma': IntegerParameter(1, 5),
'max_depth': IntegerParameter(1, 10)}
objective_metric_name = 'validation:auc'
tuner = HyperparameterTuner(estimator,
objective_metric_name,
hyperparameter_ranges,
max_jobs=100,
max_parallel_jobs=10,
)
tuning_job_name = "xgb-tuner-{}".format(strftime("%d-%H-%M-%S", gmtime()))
inputs = {'train': train_data_path, 'validation': val_data_path}
tuner.fit(inputs, job_name=tuning_job_name)
tuner.wait()
tuner_metrics = sagemaker.HyperparameterTuningJobAnalytics(tuning_job_name)In this context max jobs allows us to specify how many times a single training job will be tuned, and finding the best training job from there.
Multi Objective Hyperparameter Tuning (Fairness Optimized)
We want to optimize multiple objective metrics with hyperparameter tuning as described in this paper. However, SageMaker AMT still accepts only a single metric as input.
To address this challenge, we express multiple metrics as a single metric function and optimize this metric:
- maxM(y1,y2,θ)
- y1,y2 are different metrics. For example AUC score and DPPL.
- M(⋅,⋅,θ)is a scalarization function and is parameterized by a fixed parameter
Higher weight favors that particular objective in model tuning. Weights may wary from case to case and you might need to try different weights for your use case. In this example, weights for AUC and DPPL have been set heuristically. Let’s walk through how this would look like in code. You can see the training job returning a single metric based on a combination function of AUC Score for performance and DPPL for fairness. The hyperparameter optimization ranges for multiple objectives are the same as the single objective. We are passing the validation metric as “auc” but behind the scenes we are returning the results of the combined metric function as described last in the list of functions below:
Here is the function Multi Objective optimization:
objective_metric_name = 'validation:auc'
tuner = HyperparameterTuner(estimator,
objective_metric_name,
hyperparameter_ranges,
max_jobs=100,
max_parallel_jobs=10
)Here is the function for computing AUC score:
def eval_auc_score(predt, dtrain):
fY = [1 if p > 0.5 else 0 for p in predt]
y = dtrain.get_label()
auc_score = roc_auc_score(y, fY)
return auc_scoreHere is the function for computing DPPL score:
def eval_dppl(predt, dtrain):
dtrain_np = dmatrix_to_numpy(dtrain)
# groups: an np array containing 1 or 2
groups = dtrain_np[:, -1]
# sensitive_facet_index: boolean column indicating sensitive group
sensitive_facet_index = pd.Series(groups - 1, dtype=bool)
# positive_predicted_label_index: boolean column indicating positive predicted labels
positive_label_index = pd.Series(predt > 0.5)
return abs(DPPL(predt, sensitive_facet_index, positive_label_index))Here is the function for the Combined Metric:
def eval_combined_metric(predt, dtrain):
auc_score = eval_auc_score(predt, dtrain)
DPPL = eval_dppl(predt, dtrain)
# Assign weight of 3 to AUC and 1 to DPPL
# Maximize (1-DPPL) for the purpose of minimizing DPPL
combined_metric = ((3*auc_score)+(1-DPPL))/4
print("DPPL, AUC Score, Combined Metric: ", DPPL, auc_score, combined_metric)
return "auc", combined_metricExperiments & Results
Synthetic data generation for bias dataset
The original South German Credit dataset contained 1000 records, and we generated 100 more records synthetically to create a dataset where the bias in model predictions disfavors Foreign Workers. This is done to simulate bias that could manifest itself in the real world. New records of foreign workers labeled as “bad credit” applicants were extrapolated from existing foreign workers with the same label.
There are many libraries/techniques to create synthetic data and we use Synthetic Data Vault (DPPLV).
From the following code snippet we can see how synthetic data is generated with DPPLV with the South German Credit Data Set:
# Parameters for generated data
# How many rows of synthetic data
num_rows = 100
# Select all foreign workers who were accepted (foreign_worker value 1 credit_risk 1)
ForeignWorkerData = training_data.loc[(training_data['foreign_worker'] == 1) & (training_data['credit_risk'] == 1)]
# Fit Foreign Worker data to SDV model
model = GaussianCopula()
model.fit(ForeignWorkerData)
# Generate Synthetic foreign worker data based on rows stated
SynthForeignWorkers = model.sample(Rows)We generated 100 new synthetic records of Foreign Workers based on Foreign Workers who were accepted in the original dataset. We will now take those records and convert the “credit_risk” label to 0 (bad credit). This will mark these Foreign Workers unfairly as bad credit, hence inserting bias into our dataset
SynthForeignWorkers.loc[SynthForeignWorkers['credit_risk'] == 1, 'credit_risk'] = 0We explore the bias in the dataset through the graphs below.
The pie graph on top shows the percentage of Non-Foreign Workers labelled as good credit or bad credit, and the bottom pie graph shows the same for Foreign Workers. The percentage of Foreign workers labeled as “bad credit” is 75.90% and far outweigh the 30.70% of Non-Foreign workers labeled the same. The stack bar displays the almost similar percentage breakdown of total workers across the category of Foreign & Non-Foreign workers.
We want to avoid the ML model from learning a strong bias against Foreign Workers either through explicit features or implicit proxy features in the data. With an additional fairness objective, we guide the ML model to mitigate the bias of lower creditworthiness towards Foreign Workers.
Model performance after tuning for both performance and fairness
This chart depicts the density plot of up to 100 tuning jobs run by SageMaker AMT and their corresponding combined objective metric values. Although we have set max jobs to 100, it is changeable under the discretion of the user. The combined metric was a combination of AUC and DPPL with a function of: (3*AUC + (1-DPPL)) / 4. The reason that we use (1-DPPL) instead of (DPPL) is because we would like to maximize the combined objective for the lowest DPPL possible (lower DPPL means lower bias against foreign workers). The plot shows how AMT helps identify the best hyperparameters for the XGBoost model that returns the highest combined evaluation metric value of 0.68.
Model performance with combined metric
Below we take a look at the pareto front chart for the individual metrics of AUC and DPPL. A Pareto Front chart is used here to visually represent the trade-offs between multiple objectives, in this case the two metric values (AUC & DPPL). Points on the curve front are considered as equally good and one metric cannot be improved without degrading the other. The Pareto chart allows us to see how different jobs performed against the baseline (red circle) in terms of both metrics. It also shows us the most optimal job (green triangle). The position of the red circle and green triangle are important because it allows us to understand if our combined metric is actually performing as expected and truly optimizing for both metrics. The code to generate the pareto front chart is included in the notebook in GitHub.

In this scenario, a lower DPPL value is more desirable (less bias), while higher AUC is better (increased performance).
Here, the baseline (red circle) represents the scenario where the objective metric is AUC alone. In other words, the baseline does not consider DPPL at all and optimizes only for AUC (no fine tuning for fairness). We see the baseline has a good AUC score of 0.74, but does not perform well on fairness with a DPPL score of 0.75.
The Optimized model (green triangle) represents the best candidate model when fine-tuned for a combined metric with weight ratio of 3:1 for AUC:DPPL. We see the optimized model has a good AUC score of 0.72, and also a low DPPL score of 0.43 (low bias). This tuning job found a model configuration where DPPL can be significantly lower than the baseline, without a significant drop in AUC. Models with even lower DPPL scores can be identified by moving the green triangle further left along the Pareto Front. We thus achieved the combined objective of a well performing model with fairness for Foreign Worker sub-groups.
In the chart below, we can see the results of the predictions from the baseline model and the optimized model. The optimized model with a combined objective of performance and fairness predicts a positive outcome for 30.6% Foreign Workers as opposed to the 13.9% from the baseline model. The optimized model thus reduces the model bias against this sub-group.

Conclusion
The blog shows you to implement multi-objective optimization with SageMaker Automatic Model Tuning for real-world applications. In many instances, collected data in the real world may be biased against certain subgroups. Multi-objective optimization using automatic model tuning enables customers to build ML models easily that optimize fairness in addition to accuracy. We demonstrate an example of credit risk prediction and specifically look at fairness for foreign workers. We show that it is possible to maximize for another metric like fairness while continuing to train models with high performance. If what you have read has piqued your interest you may try out the code example hosted in Github here.
About the authors
 Munish Dabra is a Senior Solutions Architect at Amazon Web Services (AWS). His current areas of focus are AI/ML, Data Analytics and Observability. He has a strong background in designing and building scalable distributed systems. He enjoys helping customers innovate and transform their business in AWS. LinkedIn: /mdabra
Munish Dabra is a Senior Solutions Architect at Amazon Web Services (AWS). His current areas of focus are AI/ML, Data Analytics and Observability. He has a strong background in designing and building scalable distributed systems. He enjoys helping customers innovate and transform their business in AWS. LinkedIn: /mdabra
 Hasan Poonawala is a Senior AI/ML Specialist Solutions Architect at AWS, Hasan helps customers design and deploy machine learning applications in production on AWS. He has over 12 years of work experience as a data scientist, machine learning practitioner, and software developer. In his spare time, Hasan loves to explore nature and spend time with friends and family.
Hasan Poonawala is a Senior AI/ML Specialist Solutions Architect at AWS, Hasan helps customers design and deploy machine learning applications in production on AWS. He has over 12 years of work experience as a data scientist, machine learning practitioner, and software developer. In his spare time, Hasan loves to explore nature and spend time with friends and family.
 Mohammad (Moh) Tahsin is an associate AI/ML Specialist Solutions Architect for AWS. Moh has experience teaching students about responsible AI concepts, and is passionate about conveying these concepts through cloud based architectures. In his spare time he loves to lift weights, play games, and explore nature.
Mohammad (Moh) Tahsin is an associate AI/ML Specialist Solutions Architect for AWS. Moh has experience teaching students about responsible AI concepts, and is passionate about conveying these concepts through cloud based architectures. In his spare time he loves to lift weights, play games, and explore nature.
 Xingchen Ma is an Applied Scientist at AWS. He works in service team for SageMaker Automatic Model Tuning.
Xingchen Ma is an Applied Scientist at AWS. He works in service team for SageMaker Automatic Model Tuning.
 Rahul Sureka is an Enterprise Solution Architect at AWS based out of India. Rahul has more than 22 years of experience in architecting and leading large business transformation programs across multiple industry segments. His areas of interests are data and analytics, streaming, and AI/ML applications.
Rahul Sureka is an Enterprise Solution Architect at AWS based out of India. Rahul has more than 22 years of experience in architecting and leading large business transformation programs across multiple industry segments. His areas of interests are data and analytics, streaming, and AI/ML applications.





 Meet Google for Startups Black Founders Fund recipients from Africa, Brazil, Europe and the United States using Google AI technology to help people and society.
Meet Google for Startups Black Founders Fund recipients from Africa, Brazil, Europe and the United States using Google AI technology to help people and society.

 software development kit
software development kit