Text-to-image generation is a task in which a machine learning (ML) model generates an image from a textual description. The goal is to generate an image that closely matches the description, capturing the details and nuances of the text. This task is challenging because it requires the model to understand the semantics and syntax of the text and to generate photorealistic images. There are many practical applications of text-to-image generation in AI photography, concept art, building architecture, fashion, video games, graphic design, and much more.
Stable Diffusion is a text-to-image model that empowers you to create high-quality images within seconds. When real-time interaction with this type of model is the goal, ensuring a smooth user experience depends on the use of accelerated hardware for inference, such as GPUs or AWS Inferentia2, Amazon’s own ML inference accelerator. The steep costs involved in using GPUs typically requires optimizing the utilization of the underlying compute, even more so when you need to deploy different architectures or personalized (fine-tuned) models. Amazon SageMaker multi-model endpoints (MMEs) help you address this problem by helping you scale thousands of models into one endpoint. By using a shared serving container, you can host multiple models in a cost-effective, scalable manner within the same endpoint, and even the same GPU.
In this post, you will learn about Stable Diffusion model architectures, different types of Stable Diffusion models, and techniques to enhance image quality. We also show you how to deploy Stable Diffusion models cost-effectively using SageMaker MMEs and NVIDIA Triton Inference Server.
 |
 |
 |
| Prompt: portrait of a cute bernese dog, art by elke Vogelsang, 8k ultra realistic, trending on artstation, 4 k |
Prompt: architecture design of living room, 8 k ultra-realistic, 4 k, hyperrealistic, focused, extreme details |
Prompt: New York skyline at night, 8k, long shot photography, unreal engine 5, cinematic, masterpiece |
Stable Diffusion architecture
Stable Diffusion is a text-to-image open-source model that you can use to create images of different styles and content simply by providing a text prompt. In the context of text-to-image generation, a diffusion model is a generative model that you can use to generate high-quality images from textual descriptions. Diffusion models are a type of generative model that can capture the complex dependencies between the input and output modalities text and images.
The following diagram shows a high-level architecture of a Stable Diffusion model.
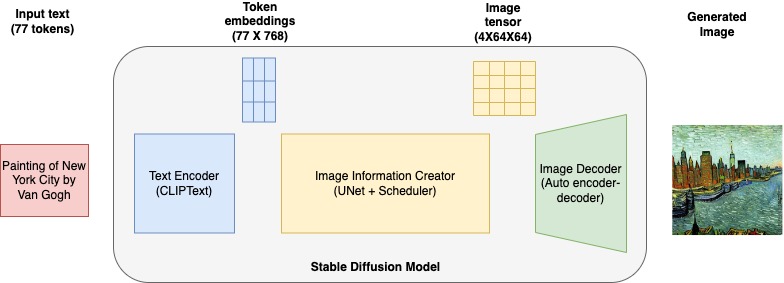
It consists of the following key elements:
- Text encoder – CLIP is a transformers-based text encoder model that takes input prompt text and converts it into token embeddings that represent each word in the text. CLIP is trained on a dataset of images and their captions, a combination of image encoder and text encoder.
- U-Net – A U-Net model takes token embeddings from CLIP along with an array of noisy inputs and produces a denoised output. This happens though a series of iterative steps, where each step processes an input latent tensor and produces a new latent space tensor that better represents the input text.
- Auto encoder-decoder – This model creates the final images. It takes the final denoised latent output from the U-Net model and converts it into images that represents the text input.
Types of Stable Diffusion models
In this post, we explore the following pre-trained Stable Diffusion models by Stability AI from the Hugging Face model hub.
stable-diffusion-2-1-base
Use this model to generate images based on a text prompt. This is a base version of the model that was trained on LAION-5B. The model was trained on a subset of the large-scale dataset LAION-5B, and mainly with English captions. We use StableDiffusionPipeline from the diffusers library to generate images from text prompts. This model can create images of dimension 512 x 512. It uses the following parameters:
- prompt – A prompt can be a text word, phrase, sentences, or paragraphs.
- negative_prompt – You can also pass a negative prompt to exclude specified elements from the image generation process and to enhance the quality of the generated images.
- guidance_scale – A higher guidance scale results in an image more closely related to the prompt, at the expense of image quality. If specified, it must be a float.
stable-diffusion-2-depth
This model is used to generate new images from existing ones while preserving the shape and depth of the objects in the original image. This stable-diffusion-2-depth model is fine-tuned from stable-diffusion-2-base, an extra input channel to process the (relative) depth prediction. We use StableDiffusionDepth2ImgPipeline from the diffusers library to load the pipeline and generate depth images. The following are the additional parameters specific to the depth model:
- image – The initial image to condition the generation of new images.
- num_inference_steps (optional) – The number of denoising steps. More denoising steps usually leads to a higher-quality image at the expense of slower inference. This parameter is modulated by
strength.
- strength (optional) – Conceptually, this indicates how much to transform the reference image. The value must be between 0–1.
image is used as a starting point, adding more noise to it the larger the strength. The number of denoising steps depends on the amount of noise initially added. When strength is 1, the added noise will be maximum and the denoising process will run for the full number of iterations specified in num_inference_steps. A value of 1, therefore, essentially ignores image. For more details, refer to the following code.
stable-diffusion-2-inpainting
You can use this model for AI image restoration use cases. You can also use it to create novel designs and images from the prompts and additional arguments. This model is also derived from the base model and has a mask generation strategy. It specifies the mask of the original image to represent segments to be changed and segments to leave unchanged. We use StableDiffusionUpscalePipeline from the diffusers library to apply inpaint changes on original image. The following additional parameter is specific to the depth model:
- mask_input – An image where the blacked-out portion remains unchanged during image generation and the white portion is replaced
stable-diffusion-x4-upscaler
This model is also derived from the base model, additionally trained on the 10M subset of LAION containing 2048 x 2048 images. As the name implies, it can be used to upscale lower-resolution images to higher resolutions
Use case overview
For this post, we deploy an AI image service with multiple capabilities, including generating novel images from text, changing the styles of existing images, removing unwanted objects from images, and upscaling low-resolution images to higher resolutions. Using several variations of Stable Diffusion models, you can address all of these use cases within a single SageMaker endpoint. This means that you’ll need to host large number of models in a performant, scalable, and cost-efficient way. In this post, we show how to deploy multiple Stable Diffusion models cost-effectively using SageMaker MMEs and NVIDIA Triton Inference Server. You will learn about the implementation details, optimization techniques, and best practices to work with text-to-image models.
The following table summarizes the Stable Diffusion models that we deploy to a SageMaker MME.
| Model Name |
Model Size in GB |
stabilityai/stable-diffusion-2-1-base |
2.5 |
stabilityai/stable-diffusion-2-depth |
2.7 |
stabilityai/stable-diffusion-2-inpainting |
2.5 |
stabilityai/stable-diffusion-x4-upscaler |
7 |
Solution overview
The following steps are involved in deploying Stable Diffusion models to SageMaker MMEs:
- Use the Hugging Face hub to download the Stable Diffusion models to a local directory. This will download
scheduler, text_encoder, tokenizer, unet, and vae for each Stable Diffusion model into its corresponding local directory. We use the revision="fp16" version of the model.
- Set up the NVIDIA Triton model repository, model configurations, and model serving logic
model.py. Triton uses these artifacts to serve predictions.
- Package the conda environment with additional dependencies and the package model repository to be deployed to the SageMaker MME.
- Package the model artifacts in an NVIDIA Triton-specific format and upload
model.tar.gz to Amazon Simple Storage Service (Amazon S3). The model will be used for generating images.
- Configure a SageMaker model, endpoint configuration, and deploy the SageMaker MME.
- Run inference and send prompts to the SageMaker endpoint to generate images using the Stable Diffusion model. We specify the
TargetModel variable and invoke different Stable Diffusion models to compare the results visually.
We have published the code to implement this solution architecture in the GitHub repo. Follow the README instructions to get started.
Serve models with an NVIDIA Triton Inference Server Python backend
We use a Triton Python backend to deploy the Stable Diffusion pipeline model to a SageMaker MME. The Python backend lets you serve models written in Python by Triton Inference Server. To use the Python backend, you need to create a Python file model.py that has the following structure: Every Python backend can implement four main functions in the TritonPythonModel class:
import triton_python_backend_utils as pb_utils
class TritonPythonModel:
"""Your Python model must use the same class name. Every Python model
that is created must have "TritonPythonModel" as the class name.
"""
def auto_complete_config(auto_complete_model_config):
def initialize(self, args):
def execute(self, requests):
def finalize(self):
Every Python backend can implement four main functions in the TritonPythonModel class: auto_complete_config, initialize, execute, and finalize.
initialize is called when the model is being loaded. Implementing initialize is optional. initialize allows you to do any necessary initializations before running inference. In the initialize function, we create a pipeline and load the pipelines using from_pretrained checkpoints. We configure schedulers from the pipeline scheduler config pipe.scheduler.config. Finally, we specify xformers optimizations to enable the xformer memory efficient parameter enable_xformers_memory_efficient_attention. We provide more details on xformers later in this post. You can refer to model.py of each model to understand the different pipeline details. This file can be found in the model repository.
The execute function is called whenever an inference request is made. Every Python model must implement the execute function. In the execute function, you are given a list of InferenceRequest objects. We pass the input text prompt to the pipeline to get an image from the model. Images are decoded and the generated image is returned from this function call.
We get the input tensor from the name defined in the model configuration config.pbtxt file. From the inference request, we get prompt, negative_prompt, and gen_args, and decode them. We pass all the arguments to the model pipeline object. Encode the image to return the generated image predictions. You can refer to the config.pbtxt file of each model to understand the different pipeline details. This file can be found in the model repository. Finally, we wrap the generated image in InferenceResponse and return the response.
Implementing finalize is optional. This function allows you to do any cleanups necessary before the model is unloaded from Triton Inference Server.
When working with the Python backend, it’s the user’s responsibility to ensure that the inputs are processed in a batched manner and that responses are sent back accordingly. To achieve this, we recommend following these steps:
- Loop through all requests in the
requests object to form a batched_input.
- Run inference on the
batched_input.
- Split the results into multiple
InferenceResponse objects and concatenate them as the responses.
Refer to the Triton Python backend documentation or Host ML models on Amazon SageMaker using Triton: Python backend for more details.
NVIDIA Triton model repository and configuration
The model repository contains the model serving script, model artifacts and tokenizer artifacts, a packaged conda environment (with dependencies needed for inference), the Triton config file, and the Python script used for inference. The latter is mandatory when you use the Python backend, and you should use the Python file model.py. Let’s explore the configuration file of the inpaint Stable Diffusion model and understand the different options specified:
name: "sd_inpaint"
backend: "python"
max_batch_size: 8
input [
{
name: "prompt"
data_type: TYPE_STRING
dims: [
-1
]
},
{
name: "negative_prompt"
data_type: TYPE_STRING
dims: [
-1
]
optional: true
},
{
name: "image"
data_type: TYPE_STRING
dims: [
-1
]
},
{
name: "mask_image"
data_type: TYPE_STRING
dims: [
-1
]
},
{
name: "gen_args"
data_type: TYPE_STRING
dims: [
-1
]
optional: true
}
]
output [
{
name: "generated_image"
data_type: TYPE_STRING
dims: [
-1
]
}
]
instance_group [
{
kind: KIND_GPU
}
]
parameters: {
key: "EXECUTION_ENV_PATH",
value: {string_value: "/tmp/conda/sd_env.tar.gz"
}
}
The following table explains the various parameters and values:
| Key |
Details |
name |
It’s not required to include the model configuration name property. In the event that the configuration doesn’t specify the model’s name, it’s presumed to be identical to the name of the model repository directory where the model is stored. However, if a name is provided, it must match the name of the model repository directory where the model is stored. sd_inpaint is the config property name. |
backend |
This specifies the Triton framework to serve model predictions. This is a mandatory parameter. We specify python, because we’ll be using the Triton Python backend to host the Stable Diffusion models. |
max_batch_size |
This indicates the maximum batch size that the model supports for the types of batching that can be exploited by Triton. |
input→ prompt |
Text prompt of type string. Specify -1 to accept dynamic tensor shape. |
input→ negative_prompt |
Negative text prompt of type string. Specify -1 to accept dynamic tensor shape. |
input→ mask_image |
Base64 encoded mask image of type string. Specify -1 to accept dynamic tensor shape. |
input→ image |
Base64 encoded image of type string. Specify -1 to accept dynamic tensor shape. |
input→ gen_args |
JSON encoded additional arguments of type string. Specify -1 to accept dynamic tensor shape. |
output→ generated_image |
Generated image of type string. Specify -1 to accept dynamic tensor shape. |
instance_group |
You can use this this setting to place multiple run instances of a model on every GPU or on only certain GPUs. We specify KIND_GPU to make copies of the model on available GPUs. |
parameters |
We set the conda environment path to EXECUTION_ENV_PATH. |
For details about the model repository and configurations of other Stable Diffusion models, refer to the code in the GitHub repo. Each directory contains artifacts for the specific Stable Diffusion models.
Package a conda environment and extend the SageMaker Triton container
SageMaker NVIDIA Triton container images don’t contain libraries like transformer, accelerate, and diffusers to deploy and serve Stable Diffusion models. However, Triton allows you to bring additional dependencies using conda-pack. Let’s start by creating the conda environment with the necessary dependencies outlined in the environment.yml file and create a tar model artifact sd_env.tar.gz file containing the conda environment with dependencies installed in it. Run the following YML file to create a conda-pack artifact and copy the artifact to the local directory from where it will be uploaded to Amazon S3. Note that we will be uploading the conda artifacts as one of the models in the MME and invoking this model to set up the conda environment in the SageMaker hosting ML instance.
%%writefile environment.yml
name: mme_env
dependencies:
- python=3.8
- pip
- pip:
- numpy
- torch --extra-index-url https://download.pytorch.org/whl/cu118
- accelerate
- transformers
- diffusers
- xformers
- conda-pack
!conda env create -f environment.yml –force
Upload model artifacts to Amazon S3
SageMaker expects the .tar.gz file containing each Triton model repository to be hosted on the multi-model endpoint. Therefore, we create a tar artifact with content from the Triton model repository. We can use this S3 bucket to host thousands of model artifacts, and the SageMaker MME will use models from this location to dynamically load and serve a large number of models. We store all the Stable Diffusion models in this Amazon S3 location.
Deploy the SageMaker MME
In this section, we walk through the steps to deploy the SageMaker MME by defining container specification, SageMaker model and endpoint configurations.
Define the serving container
In the container definition, define the ModelDataUrl to specify the S3 directory that contains all the models that the SageMaker MME will use to load and serve predictions. Set Mode to MultiModel to indicate that SageMaker will create the endpoint with the MME container specifications. We set the container with an image that supports deploying MMEs with GPU. See Supported algorithms, frameworks, and instances for more details.
We see all three model artifacts in the following Amazon S3 ModelDataUrl location:
container = {"Image": mme_triton_image_uri,
"ModelDataUrl": model_data_url,
"Mode": "MultiModel"}
Create an MME object
We use the SageMaker Boto3 client to create the model using the create_model API. We pass the container definition to the create model API along with ModelName and ExecutionRoleArn:
create_model_response = sm_client.create_model(
ModelName=sm_model_name,
ExecutionRoleArn=role,
PrimaryContainer=container
)
Define configurations for the MME
Create an MME configuration using the create_endpoint_config Boto3 API. Specify an accelerated GPU computing instance in InstanceType (we use the same instance type that we are using to host our SageMaker notebook). We recommend configuring your endpoints with at least two instances with real-life use cases. This allows SageMaker to provide a highly available set of predictions across multiple Availability Zones for the models.
create_endpoint_config_response = sm_client.create_endpoint_config(
EndpointConfigName=endpoint_config_name,
ProductionVariants=[
{
"InstanceType": instance_type,
"InitialVariantWeight": 1,
"InitialInstanceCount": 1,
"ModelName": sm_model_name,
"VariantName": "AllTraffic",
}
],
)
Create an MME
Use the preceding endpoint configuration to create a new SageMaker endpoint and wait for the deployment to finish:
create_endpoint_response = sm_client.create_endpoint(
EndpointName=endpoint_name,
EndpointConfigName=endpoint_config_name
)
The status will change to InService when the deployment is successful.
Generate images using different versions of Stable Diffusion models
Let’s start by invoking the base model with a prompt and getting the generated image. We pass the inputs to the base model with prompt, negative_prompt, and gen_args as a dictionary. We set the data type and shape of each input item in the dictionary and pass it as input to the model.
inputs = dict(prompt = "Infinity pool on top of a high rise overlooking Central Park",
negative_prompt = "blur,low detail, low quality",
gen_args = json.dumps(dict(num_inference_steps=50, guidance_scale=8))
)
payload = {
"inputs":
[{"name": name, "shape": [1,1], "datatype": "BYTES", "data": [data]} for name, data in inputs.items()]
}
response = runtime_sm_client.invoke_endpoint(
EndpointName=endpoint_name,
ContentType="application/octet-stream",
Body=json.dumps(payload),
TargetModel="sd_base.tar.gz",
)
output = json.loads(response["Body"].read().decode("utf8"))["outputs"]
decode_image(output[0]["data"][0])

Prompt: Infinity pool on top of a high rise overlooking Central Park
Working with this image, we can modify it with the versatile Stable Diffusion depth model. For example, we can change the style of the image to an oil painting, or change the setting from Central Park to Yellowstone National Park simply by passing the original image along with a prompt describing the changes we would like to see.
We invoke the depth model by specifying sd_depth.tar.gz in the TargetModel of the invoke_endpoint function call. In the outputs, notice how the orientation of the original image is preserved, but for one example, the NYC buildings have been transformed into rock formations of the same shape.
inputs = dict(prompt = "highly detailed oil painting of an inifinity pool overlooking central park",
image=image,
gen_args = json.dumps(dict(num_inference_steps=50, strength=0.9))
)
payload = {
"inputs":
[{"name": name, "shape": [1,1], "datatype": "BYTES", "data": [data]} for name, data in inputs.items()]
}
response = runtime_sm_client.invoke_endpoint(
EndpointName=endpoint_name,
ContentType="application/octet-stream",
Body=json.dumps(payload),
TargetModel="sd_depth.tar.gz",
)
output = json.loads(response["Body"].read().decode("utf8"))["outputs"]
print("original image")
display(original_image)
print("generated image")
display(decode_image(output[0]["data"][0]))
 |
 |
 |
| Original image |
Oil painting |
Yellowstone Park |
Another useful model is Stable Diffusion inpainting, which we can use to remove certain parts of the image. Let’s say you want to remove the tree in the following example image. We can do so by invoking the inpaint model sd_inpaint.tar.gz. To remove the tree, we need to pass a mask_image, which indicates which regions of the image should be retained and which should be filled in. The black pixel portion of the mask image indicates the regions that should remain unchanged, and the white pixels indicate what should be replaced.
image = encode_image(original_image).decode("utf8")
mask_image = encode_image(Image.open("sample_images/bertrand-gabioud-mask.png")).decode("utf8")
inputs = dict(prompt = "building, facade, paint, windows",
image=image,
mask_image=mask_image,
negative_prompt = "tree, obstruction, sky, clouds",
gen_args = json.dumps(dict(num_inference_steps=50, guidance_scale=10))
)
payload = {
"inputs":
[{"name": name, "shape": [1,1], "datatype": "BYTES", "data": [data]} for name, data in inputs.items()]
}
response = runtime_sm_client.invoke_endpoint(
EndpointName=endpoint_name,
ContentType="application/octet-stream",
Body=json.dumps(payload),
TargetModel="sd_inpaint.tar.gz",
)
output = json.loads(response["Body"].read().decode("utf8"))["outputs"]
decode_image(output[0]["data"][0])
 |
 |
 |
| Original image |
Mask image |
Inpaint image |
In our final example, we downsize the original image that was generated earlier from its 512 x 512 resolution to 128 x 128. We then invoke the Stable Diffusion upscaler model to upscale the image back to 512 x 512. We use the same prompt to upscale the image as what we used to generate the initial image. While not necessary, providing a prompt that describes the image helps guide the upscaling process and should lead to better results.
low_res_image = output_image.resize((128, 128))
inputs = dict(prompt = "Infinity pool on top of a high rise overlooking Central Park",
image=encode_image(low_res_image).decode("utf8")
)
payload = {
"inputs":
[{"name": name, "shape": [1,1], "datatype": "BYTES", "data": [data]} for name, data in inputs.items()]
}
response = runtime_sm_client.invoke_endpoint(
EndpointName=endpoint_name,
ContentType="application/octet-stream",
Body=json.dumps(payload),
TargetModel="sd_upscale.tar.gz",
)
output = json.loads(response["Body"].read().decode("utf8"))["outputs"]
upscaled_image = decode_image(output[0]["data"][0])
 |
 |
| Low-resolution image |
Upscaled image |
Although the upscaled image is not as detailed as the original, it’s a marked improvement over the low-resolution one.
Optimize for memory and speed
The xformers library is a way to speed up image generation. This optimization is only available for NVIDIA GPUs. It speeds up image generation and lowers VRAM usage. We have used the xformers library for memory-efficient attention and speed. When the enable_xformers_memory_efficient_attention option is enabled, you should observe lower GPU memory usage and a potential speedup at inference time.
Clean Up
Follow the instruction in the clean up section of the notebook to delete the resource provisioned part of this blog to avoid unnecessary charges. Refer Amazon SageMaker Pricing for details the cost of the inference instances.
Conclusion
In this post, we discussed Stable Diffusion models and how you can deploy different versions of Stable Diffusion models cost-effectively using SageMaker multi-model endpoints. You can use this approach to build a creator image generation and editing tool. Check out the code samples in the GitHub repo to get started and let us know about the cool generative AI tool that you build.
About the Authors
 Simon Zamarin is an AI/ML Solutions Architect whose main focus is helping customers extract value from their data assets. In his spare time, Simon enjoys spending time with family, reading sci-fi, and working on various DIY house projects.
Simon Zamarin is an AI/ML Solutions Architect whose main focus is helping customers extract value from their data assets. In his spare time, Simon enjoys spending time with family, reading sci-fi, and working on various DIY house projects.
 Vikram Elango is a Sr. AI/ML Specialist Solutions Architect at AWS, based in Virginia, US. He is currently focused on generative AI, LLMs, prompt engineering, large model inference optimization, and scaling ML across enterprises. Vikram helps financial and insurance industry customers with design and architecture to build and deploy ML applications at scale. In his spare time, he enjoys traveling, hiking, cooking, and camping with his family.
Vikram Elango is a Sr. AI/ML Specialist Solutions Architect at AWS, based in Virginia, US. He is currently focused on generative AI, LLMs, prompt engineering, large model inference optimization, and scaling ML across enterprises. Vikram helps financial and insurance industry customers with design and architecture to build and deploy ML applications at scale. In his spare time, he enjoys traveling, hiking, cooking, and camping with his family.
 João Moura is an AI/ML Specialist Solutions Architect at AWS, based in Spain. He helps customers with deep learning model training and inference optimization, and more broadly building large-scale ML platforms on AWS. He is also an active proponent of ML-specialized hardware and low-code ML solutions.
João Moura is an AI/ML Specialist Solutions Architect at AWS, based in Spain. He helps customers with deep learning model training and inference optimization, and more broadly building large-scale ML platforms on AWS. He is also an active proponent of ML-specialized hardware and low-code ML solutions.
 Saurabh Trikande is a Senior Product Manager for Amazon SageMaker Inference. He is passionate about working with customers and is motivated by the goal of democratizing machine learning. He focuses on core challenges related to deploying complex ML applications, multi-tenant ML models, cost optimizations, and making deployment of deep learning models more accessible. In his spare time, Saurabh enjoys hiking, learning about innovative technologies, following TechCrunch, and spending time with his family.
Saurabh Trikande is a Senior Product Manager for Amazon SageMaker Inference. He is passionate about working with customers and is motivated by the goal of democratizing machine learning. He focuses on core challenges related to deploying complex ML applications, multi-tenant ML models, cost optimizations, and making deployment of deep learning models more accessible. In his spare time, Saurabh enjoys hiking, learning about innovative technologies, following TechCrunch, and spending time with his family.
Read More



















 Posted by Wei Wei, Developer Advocate
Posted by Wei Wei, Developer Advocate

















 Amit Arora is an AI and ML Specialist Architect at Amazon Web Services, helping enterprise customers use cloud-based machine learning services to rapidly scale their innovations. He is also an adjunct lecturer in the MS data science and analytics program at Georgetown University in Washington D.C.
Amit Arora is an AI and ML Specialist Architect at Amazon Web Services, helping enterprise customers use cloud-based machine learning services to rapidly scale their innovations. He is also an adjunct lecturer in the MS data science and analytics program at Georgetown University in Washington D.C. Dr. Xin Huang is a Senior Applied Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on developing scalable machine learning algorithms. His research interests are in the area of natural language processing, explainable deep learning on tabular data, and robust analysis of non-parametric space-time clustering. He has published many papers in ACL, ICDM, KDD conferences, and Royal Statistical Society: Series A.
Dr. Xin Huang is a Senior Applied Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on developing scalable machine learning algorithms. His research interests are in the area of natural language processing, explainable deep learning on tabular data, and robust analysis of non-parametric space-time clustering. He has published many papers in ACL, ICDM, KDD conferences, and Royal Statistical Society: Series A. Navneet Tuteja is a Data Specialist at Amazon Web Services. Before joining AWS, Navneet worked as a facilitator for organizations seeking to modernize their data architectures and implement comprehensive AI/ML solutions. She holds an engineering degree from Thapar University, as well as a master’s degree in statistics from Texas A&M University.
Navneet Tuteja is a Data Specialist at Amazon Web Services. Before joining AWS, Navneet worked as a facilitator for organizations seeking to modernize their data architectures and implement comprehensive AI/ML solutions. She holds an engineering degree from Thapar University, as well as a master’s degree in statistics from Texas A&M University.{kind=link}