New research proposes a framework for evaluating general-purpose models against novel threatsRead More

New research proposes a framework for evaluating general-purpose models against novel threatsRead More

New research proposes a framework for evaluating general-purpose models against novel threatsRead More

New research proposes a framework for evaluating general-purpose models against novel threatsRead More
New research proposes a framework for evaluating general-purpose models against novel threatsRead More

AI researchers already use a range of evaluation benchmarks to identify unwanted behaviours in AI systems, such as AI systems making misleading statements, biased decisions, or repeating copyrighted content. Now, as the AI community builds and deploys increasingly powerful AI, we must expand the evaluation portfolio to include the possibility of extreme risks from general-purpose AI models that have strong skills in manipulation, deception, cyber-offense, or other dangerous capabilities.Read More
How ARA recipient Supreeth Shashikumar is using machine learning to help hospitals detect sepsis — before it’s too late.Read More
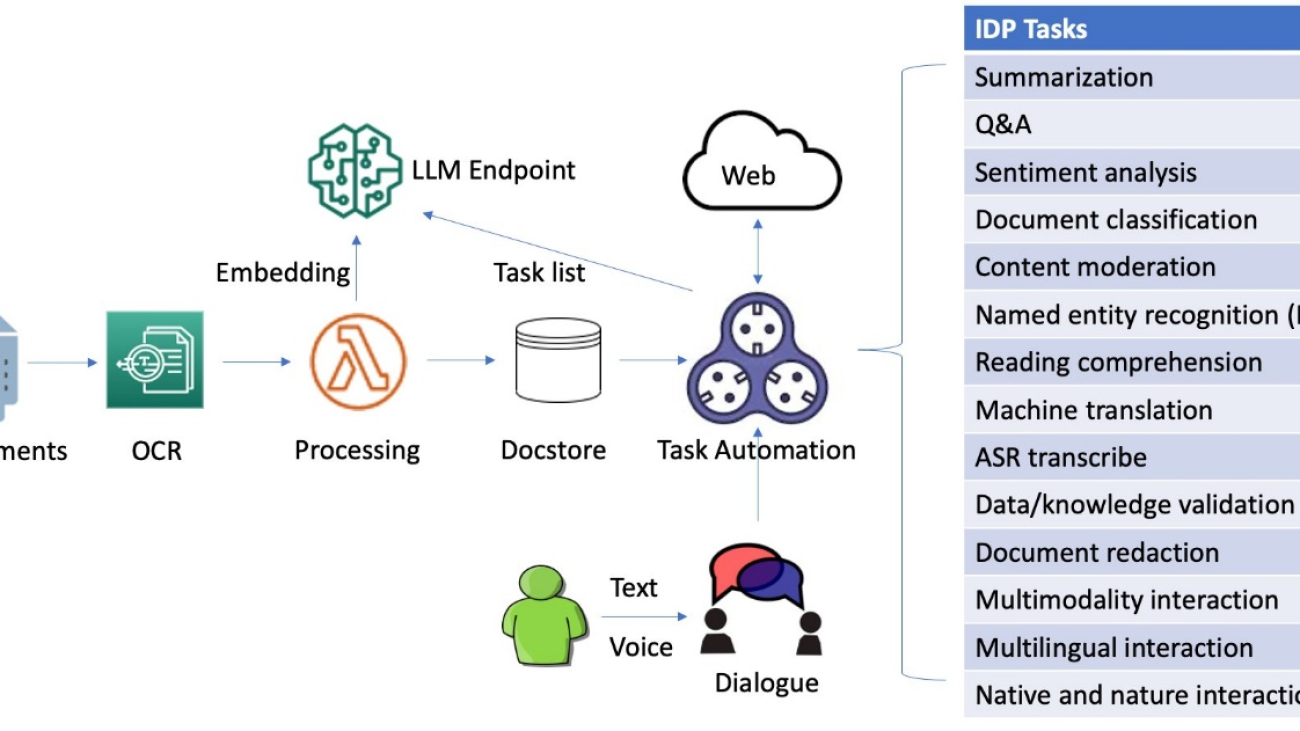
Intelligent document processing (IDP) is a technology that automates the processing of high volumes of unstructured data, including text, images, and videos. IDP offers a significant improvement over manual methods and legacy optical character recognition (OCR) systems by addressing challenges such as cost, errors, low accuracy, and limited scalability, ultimately leading to better outcomes for organizations and stakeholders.
Natural language processing (NLP) is one of the recent developments in IDP that has improved accuracy and user experience. However, despite these advances, there are still challenges to overcome. For instance, many IDP systems are not user-friendly or intuitive enough for easy adoption by users. Additionally, several existing solutions lack the capability to adapt to changes in data sources, regulations, and user requirements through continuous improvement and updates.
Enhancing IDP through dialogue involves incorporating dialogue capabilities into IDP systems. By enabling users to interact with IDP systems in a more natural and intuitive way, through multi-round dialogue by adjusting inaccurate information or adding missing information aided with task automation, these systems can become more efficient, accurate, and user-friendly.
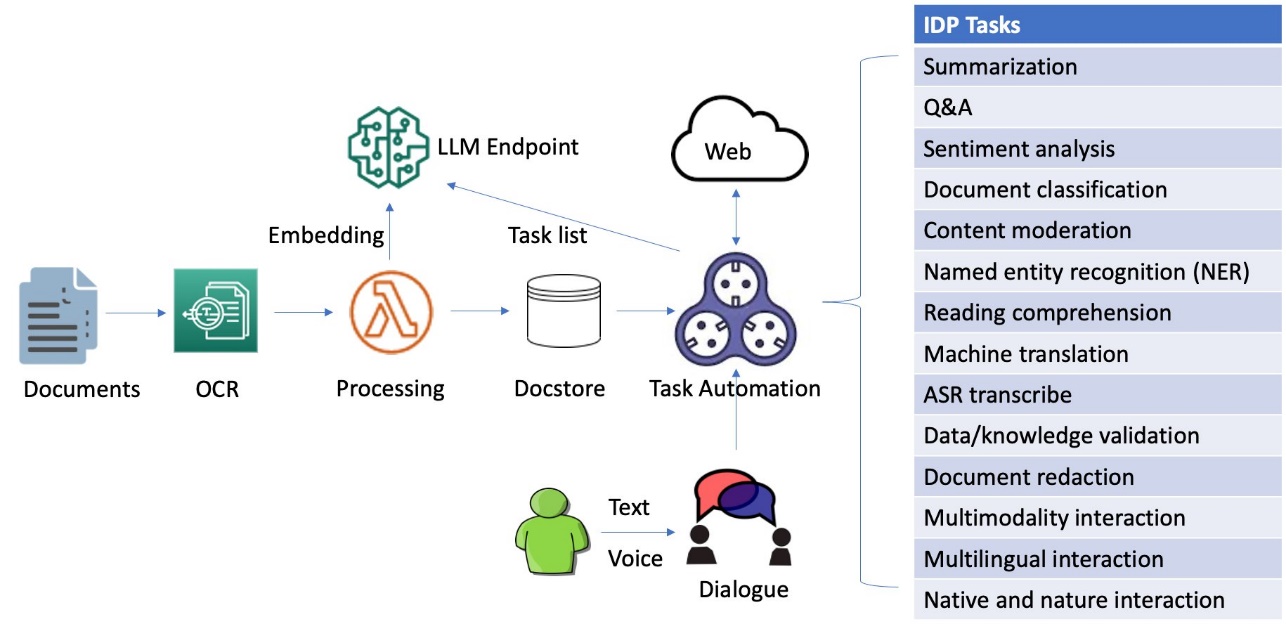
In this post, we explore an innovative approach to IDP that utilizes a dialogue-guided query solution using Amazon Foundation Models and SageMaker JumpStart.
This innovative solution combines OCR for information extraction, a local deployed large language model (LLM) for dialogue and autonomous tasking, VectorDB for embedding subtasks, and LangChain-based task automation for integration with external data sources to transform the way businesses process and analyze document contexts. By harnessing generative AI technologies, organizations can streamline IDP workflows, enhance user experience, and boost overall efficiency.
The following video highlights the dialogue-guided IDP system by processing an article authored by the Federal Reserve Board of Governors, discussing the collapse of Silicon Valley Bank in March 2023.
The system is capable of processing images, large PDF, and documents in other format and answering questions derived from the content via interactive text or voice inputs. If a user needs to inquire beyond the document’s context, the dialogue-guided IDP can create a chain of tasks from the text prompt and then reference external and up-to-date data sources for relevant answers. Additionally, it supports multi-round conversations and accommodates multilingual exchanges, all managed through dialogue.
One of the most promising developments in generative AI is the integration of LLMs into dialogue systems, opening up new avenues for more intuitive and meaningful exchanges. An LLM is a type of AI model designed to understand and generate human-like text. These models are trained on massive amounts of data and consist of billions of parameters, allowing them to perform various language-related tasks with high accuracy. This transformative approach facilitates a more natural and productive interaction, bridging the gap between human intuition and machine intelligence. A key advantage of local LLM deployment lies in its ability to enhance data security without submitting data outside to third-party APIs. Moreover, you can fine-tune your chosen LLM with domain-specific data, resulting in a more accurate, context-aware, and natural language understanding experience.
The Jurassic-2 series from AI21 Labs, which are based on the instruct-tuned 178-billion-parameter Jurassic-1 LLM, are integral parts of the Amazon foundation models available through Amazon Bedrock. The Jurassic-2 instruct was specifically trained to manage prompts that are instructions only, known as zero-shot, without the need for examples, or few-shot. This method provides the most intuitive interaction with LLMs, and it’s the best approach to understand the ideal output for your task without requiring any examples. You can efficiently deploy the pre-trained J2-jumbo-instruct, or other Jurassic-2 models available on AWS Marketplace, into your own own virtual private cloud (VPC) using Amazon SageMaker. See the following code:
import ai21, sagemaker
# Define endpoint name
endpoint_name = "sagemaker-soln-j2-jumbo-instruct"
# Define real-time inference instance type. You can also choose g5.48xlarge or p4de.24xlarge instance types
# Please request P instance quota increase via <a href="https://console.aws.amazon.com/servicequotas/home" target="_blank" rel="noopener">Service Quotas console</a> or your account manager
real_time_inference_instance_type = ("ml.p4d.24xlarge")
# Create a Sgaemkaer endpoint then deploy a pre-trained J2-jumbo-instruct-v1 model from AWS Market Place.
model_package_arn = "arn:aws:sagemaker:us-east-1:865070037744:model-package/j2-jumbo-instruct-v1-0-20-8b2be365d1883a15b7d78da7217cdeab"
model = ModelPackage(
role=sagemaker.get_execution_role(),
model_package_arn=model_package_arn,
sagemaker_session=sagemaker.Session()
)
# Deploy the model
predictor = model.deploy(1, real_time_inference_instance_type,
endpoint_name=endpoint_name,
model_data_download_timeout=3600,
container_startup_health_check_timeout=600,
)After the endpoint has been successfully deployed within your own VPC, you can initiate an inference task to verify that the deployed LLM is functioning as anticipated:
response_jumbo_instruct = ai21.Completion.execute(
sm_endpoint=endpoint_name,
prompt="Explain deep learning algorithms to 8th graders",
numResults=1,
maxTokens=100,
temperature=0.01 #subject to reduce “hallucination” by using common words.
)We delve into the process of building an efficient and effective search index, which forms the foundation for intelligent and responsive dialogues to guide document processing. To begin, we convert documents from various formats into text content using OCR and Amazon Textract. We then read this content and fragment it into smaller pieces, ideally around the size of a sentence each. This granular approach allows for more precise and relevant search results, because it enables better matching of queries against individual segments of a page rather than the entire document. To further enhance the process, we use embeddings such as the sentence transformers library from Hugging Face, which generates vector representations (encoding) of each sentence. These vectors serve as a compact and meaningful representation of the original text, enabling efficient and accurate semantic matching functionality. Finally, we store these vectors in a vector database for similarity search. This combination of techniques lays the groundwork for a novel document processing framework that delivers accurate and intuitive results for users. The following diagram illustrates this workflow.
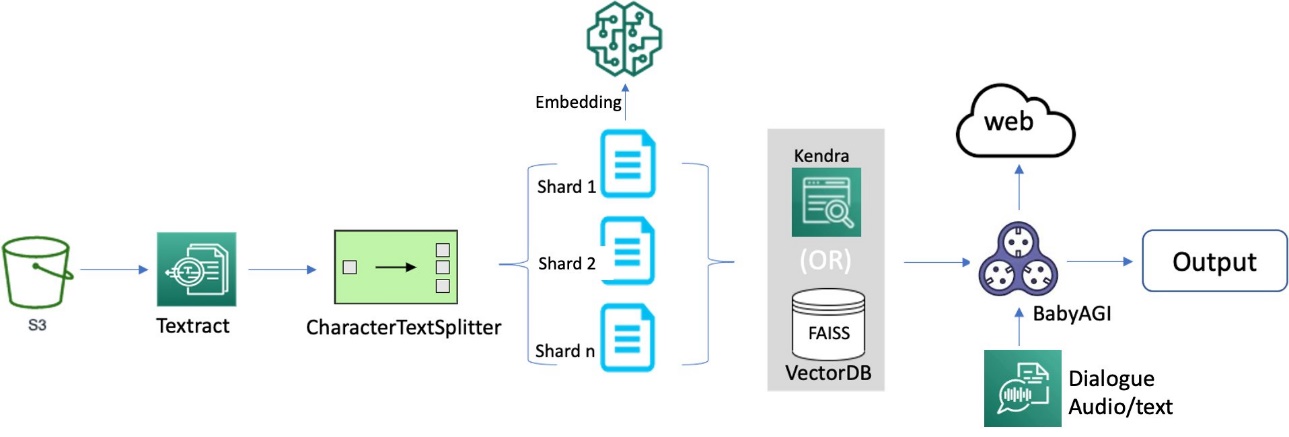
OCR serves as a crucial element in the solution, allowing for the retrieval of text from scanned documents or pictures. We can use Amazon Textract for extracting text from PDF or image files. This managed OCR service is capable of identifying and examining text in multi-page documents, including those in PDF, JPEG or TIFF formats, such as invoices and receipts. The processing of multi-page documents occurs asynchronously, making it advantageous for handling extensive, multi-page documents. See the following code:
def pdf_2_text(input_pdf_file, history):
history = history or []
key = 'input-pdf-files/{}'.format(os.path.basename(input_pdf_file.name))
try:
response = s3_client.upload_file(input_pdf_file.name, default_bucket_name, key)
except ClientError as e:
print("Error uploading file to S3:", e)
s3_object = {'Bucket': default_bucket_name, 'Name': key}
response = textract_client.start_document_analysis(
DocumentLocation={'S3Object': s3_object},
FeatureTypes=['TABLES', 'FORMS']
)
job_id = response['JobId']
while True:
response = textract_client.get_document_analysis(JobId=job_id)
status = response['JobStatus']
if status in ['SUCCEEDED', 'FAILED']:
break
time.sleep(5)
if status == 'SUCCEEDED':
with open(output_file, 'w') as output_file_io:
for block in response['Blocks']:
if block['BlockType'] in ['LINE', 'WORD']:
output_file_io.write(block['Text'] + 'n')
with open(output_file, "r") as file:
first_512_chars = file.read(512).replace("n", "").replace("r", "").replace("[", "").replace("]", "") + " [...]"
history.append(("Document conversion", first_512_chars))
return history, historyWhen dealing with large documents, it’s crucial to break them down into more manageable pieces for easier processing. In the case of LangChain, this means dividing each document into smaller segments, such as 1,000 tokens per chunk with an overlap of 100 tokens. To achieve this smoothly, LangChain utilizes specialized splitters designed specifically for this purpose:
from langchain.text_splitter import CharacterTextSplitter
from langchain.document_loaders import TextLoader
separator = 'n'
overlap_count = 100. # overlap count between the splits
chunk_size = 1000 # Use a fixed split unit size
loader = TextLoader(output_file)
documents = loader.load()
text_splitter = CharacterTextSplitter(separator=separator, chunk_overlap=overlap_count, chunk_size=chunk_size, length_function=len)
texts = text_splitter.split_documents(documents)The duration needed for embedding can fluctuate based on the size of the document; for example, it could take roughly 10 minutes to finish. Although this time frame may not be substantial when dealing with a single document, the ramifications become more notable when indexing hundreds of gigabytes as opposed to just hundreds of megabytes. To expedite the embedding process, you can implement sharding, which enables parallelization and consequently enhances efficiency:
from langchain.document_loaders import ReadTheDocsLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from sentence_transformers import SentenceTransformer
import numpy as np
import ray
from embeddings import LocalHuggingFaceEmbeddings
# Define number of splits
db_shards = 10
loader = TextLoader(output_file)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 1000,
chunk_overlap = 100,
length_function = len,
)
@ray.remote()
def process_shard(shard):
embeddings = LocalHuggingFaceEmbeddings('multi-qa-mpnet-base-dot-v1')
result = Chroma.from_documents(shard, embeddings)
return result
# Read the doc content and split them into chunks.
chunks = text_splitter.create_documents([doc.page_content for doc in documents], metadatas=[doc.metadata for doc in documents])
# Embed the doc chunks into vectors.
shards = np.array_split(chunks, db_shards)
futures = [process_shard.remote(shards[i]) for i in range(db_shards)]
texts = ray.get(futures)Now that we have obtained the smaller segments, we can continue to represent them as vectors through embeddings. Embeddings, a technique in NLP, generate vector representations of text prompts. The Embedding class serves as a unified interface for interacting with various embedding providers, such as SageMaker, Cohere, Hugging Face, and OpenAI, which streamlines the process across different platforms. These embeddings are numeric portrayals of ideas transformed into number sequences, allowing computers to effortlessly comprehend the connections between these ideas. See the following code:
# Choose a SageMaker deployed local LLM endpoint for embedding
llm_embeddings = SagemakerEndpointEmbeddings(
endpoint_name=<endpoint_name>,
region_name=<region>,
content_handler=content_handler
)After creating the embeddings, we need to utilize a vectorstore to store the vectors. Vectorstores like Chroma are specially engineered to construct indexes for quick searches in high-dimensional spaces later on, making them perfectly suited for our objectives. As an alternative, you can use FAISS, an open-source vector clustering solution for storing vectors. See the following code:
from langchain.vectorstores import Chroma
# Store vectors in Chroma vectorDB
docsearch_chroma = Chroma.from_documents(texts, llm_embeddings)
# Alternatively you can choose FAISS vectorstore
from langchain.vectorstores import FAISS
docsearch_faiss = FAISS.from_documents(texts, llm_embeddings)You can also use Amazon Kendra to index enterprise content and produce precise answers. As a fully managed service, Amazon Kendra offers ready-to-use semantic search features for advanced document and passage ranking. With the high-accuracy search in Amazon Kendra, you can obtain the most pertinent content and documents to optimize the quality of your payload. This results in superior LLM responses compared to traditional or keyword-focused search methods. For more information, refer to Quickly build high-accuracy Generative AI applications on enterprise data using Amazon Kendra, LangChain, and large language models.
Incorporating interactive voice input into document search offers a myriad of advantages that enhance the user experience. By enabling users to verbally articulate search terms, document search becomes more natural and intuitive, making it simpler and quicker for users to find the information they need. Voice input can bolster the precision of search results, because spoken search terms are less susceptible to spelling or grammatical errors. Interactive voice input renders document search more inclusive, catering to a broader spectrum of users with different language speakers and culture background.
The Amazon Transcribe Streaming SDK enables you to perform audio-to-speech recognition by integrating directly with Amazon Transcribe simply with a stream of audio bytes and a basic handler. As an alternative, you can deploy the whisper-large model locally from Hugging Face using SageMaker, which offers improved data security and better performance. For details, refer to the sample notebook published on the GitHub repo.
# Choose ASR using a locally deployed Whisper-large model from Hugging Face
image = sagemaker.image_uris.retrieve(
framework='pytorch',
region=region,
image_scope='inference',
version='1.12',
instance_type='ml.g4dn.xlarge',
)
model_name = f'sagemaker-soln-whisper-model-{int(time.time())}'
whisper_model_sm = sagemaker.model.Model(
model_data=model_uri,
image_uri=image,
role=sagemaker.get_execution_role(),
entry_point="inference.py",
source_dir='src',
name=model_name,
)
# Audio transcribe
transcribe = whisper_endpoint.predict(audio.numpy())The above demonstration video shows how voice commands, in conjunction with text input, can facilitate the task of document summarization through interactive conversation.
Memory in language models maintains a concept of state throughout a user’s interactions. This involves processing a sequence of chat messages to extract and transform knowledge. Memory types vary, but each can be understood using standalone functions and within a chain. Memory can return multiple data points, such as recent messages or message summaries, in the form of strings or lists. This post focuses on the simplest memory form, buffer memory, which stores all prior messages, and demonstrates its usage with modular utility functions and chains.
The LangChain’s ChatMessageHistory class is a crucial utility for memory modules, providing convenient methods to save and retrieve human and AI messages by remembering all previous chat interactions. It’s ideal for managing memory externally from a chain. The following code is an example of applying a simple concept in a chain by introducing ConversationBufferMemory, a wrapper for ChatMessageHistory. This wrapper extracts messages into a variable, allowing them to be represented as a string:
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory(return_messages=True)LangChain works with many popular LLM providers such as AI21 Labs, OpenAI, Cohere, Hugging Face, and more. For this example, we use a locally deployed AI21 Labs’ Jurassic-2 LLM wrapper using SageMaker. AI21 Studio also provides API access to Jurassic-2 LLMs.
from langchain import PromptTemplate, SagemakerEndpoint
from langchain.llms.sagemaker_endpoint import ContentHandlerBase
from langchain.chains.question_answering import load_qa_chain
prompt= PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)
class ContentHandler(ContentHandlerBase):
content_type = "application/json"
accepts = "application/json"
def transform_input(self, prompt: str, model_kwargs: Dict) -- bytes:
input_str = json.dumps({prompt: prompt, **model_kwargs})
return input_str.encode('utf-8')
def transform_output(self, output: bytes) -- str:
response_json = json.loads(output.read().decode("utf-8"))
return response_json[0]["generated_text"]
content_handler = ContentHandler()
llm_ai21=SagemakerEndpoint(
endpoint_name=endpoint_name,
credentials_profile_name=f'aws-credentials-profile-name',
region_name="us-east-1",
model_kwargs={"temperature":0},
content_handler=content_handler)
qa_chain = VectorDBQA.from_chain_type(
llm=llm_ai21,
chain_type='stuff',
vectorstore=docsearch,
verbose=True,
memory=ConversationBufferMemory(return_messages=True)
)
response = qa_chain(
{'query': query_input},
return_only_outputs=True
)In the event that the process is unable to locate an appropriate response from the original documents in response to a user’s inquiry, the integration of a third-party URL or ideally a task-driven autonomous agent with external data sources significantly enhances the system’s ability to access a vast array of information, ultimately improving context and providing more accurate and current results.
With AI21’s preconfigured Summarize run method, a query can access a predetermined URL, condense its content, and then carry out question and answer tasks based on the summarized information:
# Call AI21 API to query the context of a specific URL for Q&A
ai21.api_key = "<YOUR_API_KEY>"
url_external_source = "<your_source_url>"
response_url = ai21.Summarize.execute(
source=url_external_source,
sourceType="URL" )
context = "<concate_document_and_response_url>"
question = "<query>"
response = ai21.Answer.execute(
context=context,
question=question,
sm_endpoint=endpoint_name,
maxTokens=100,
)For additional details and code examples, refer to the LangChain LLM integration document as well as the task-specific API documents provided by AI21.
The task automation mechanism allows the system to process complex queries and generate relevant responses, which greatly improves the validity and authenticity of document processing. LangCain’s BabyAGI is a powerful AI-powered task management system that can autonomously create, prioritize, and run tasks. One of the key features is its ability to interface with external sources of information, such as the web, databases, and APIs. One way to use this feature is to integrate BabyAGI with Serpapi, a search engine API that provides access to search engines. This integration allows BabyAGI to search the web for information related to tasks, allowing BabyAGI to access a wealth of information beyond the input documents.
BabyAGI’s autonomous tasking capacity is fueled by an LLM, a vector search database, an API wrapper to external links, and the LangChain framework, allowing it to run a broad spectrum of tasks across various domains. This enables the system to proactively carry out tasks based on user interactions, streamlining the document processing pipeline that incorporates external sources and creating a more efficient, smooth experience. The following diagram illustrates the task automation process.
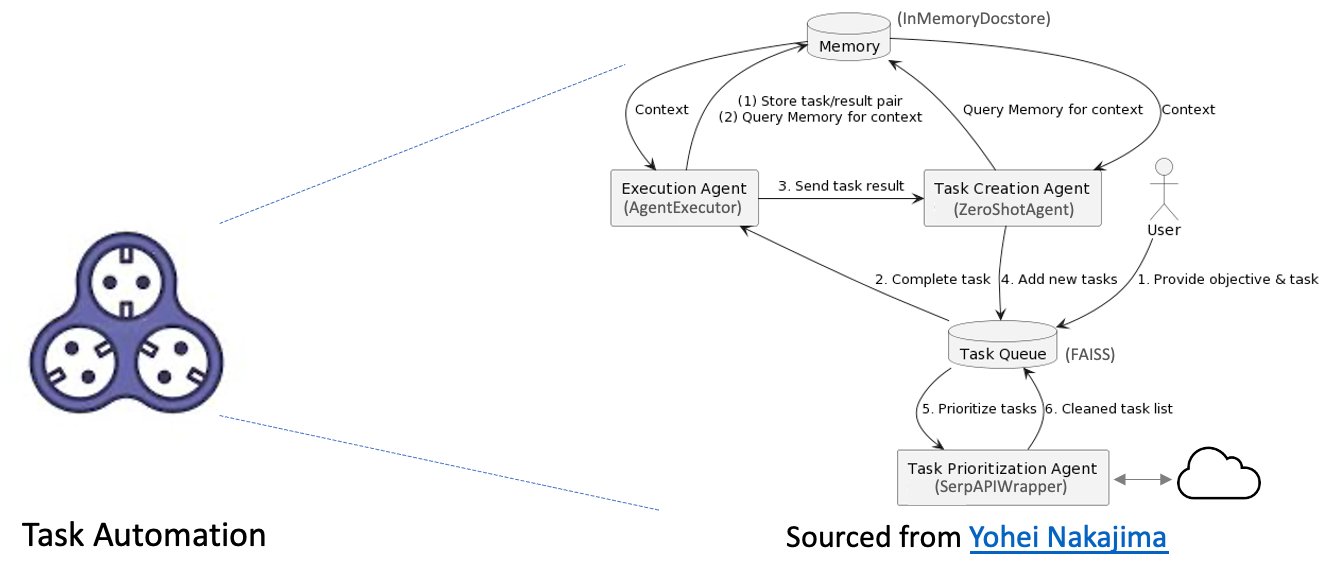
This process includes the following components:
See the following code:
from babyagi import BabyAGI
from langchain.docstore import InMemoryDocstore
import faiss
# Set temperatur=0 to generate the most frequent words, instead of more “poetically free” behavior.
new_query = """
What happened to the First Republic Bank? Will the FED take the same action as it did on SVB's failure?
"""
# Enable verbose logging and use a fixed embedding size.
verbose = True
embedding_size = 1536
# Using FAISS vector cluster for vectore store
index = faiss.IndexFlatL2(embedding_size)
vectorstore = FAISS(llm_embeddings.embed_query, index, InMemoryDocstore({}), {})
# Choose 1 iteration for demo and 1>N>10 for real. If None, it will loop indefinitely
max_iterations: Optional[int] = 2
# Call bayagi class for task automation
baby_agi = BabyAGI.from_llm(
llm=llm_embedding, vectorstore=vectorstore, verbose=verbose, max_iterations=max_iterations<br />)
response = baby_agi({"objective": new_query})Let’s examine the tasks gathered and their outcomes from a single iteration, used for demonstration purposes, to accomplish the objective in response to the user’s inquiry. BabyAGI operates through a continuous cycle of the following steps:
This iterative process enables BabyAGI to learn and develop over time. As it successfully completes an increasing number of tasks, BabyAGI’s knowledge and comprehension of the world expand. Consequently, it can generate and efficiently run more intricate and advanced tasks. By augmenting the iteration count, you can enhance the outcome through the reorganization of the task list, which focuses on the goal and the outcome of preceding tasks, ultimately yielding more pertinent and precise responses.
See the following example output:
*****TASK LIST*****
1: Make a todo list
*****NEXT TASK*****
1: Make a todo list
> Entering new AgentExecutor chain...
Thought: I need to research the First Republic Bank and the FED's action
Action: Search
Action Input: What happened to the First Republic Bank? Will the FED take the same
action as it did on SVB's failure?
Observation: First Republic's failure was due to a run on deposits following the
collapse of Silicon Valley Bank and Signature Bank. JPMorgan Chase acquired
First Republic Bank on May 1, 2023. If you had insured or uninsured money in First Republic accounts, your funds are safe and now managed by JPMorgan Chase.
Thought: I need to research the FED's action on SVB's failure
Action: Search
Action Input: What action did the FED take on SVB's failure?
Observation: The Hutchins Center explains how the Federal Reserve has responded to the
March 2023 failures of Silicon Valley Bank and Signature Bank.
Thought: I now know the final answer
Final Answer: The FED responded to the March 2023 failures of Silicon Valley Bank and <br />Signature Bank by providing liquidity to the banking system. JPMorgan
Chase acquired First Republic Bank on May 1, 2023, and if you had insured
or uninsured money in First Republic accounts, your funds are safe and
now managed by JPMorgan Chase.
> Finished chain.
*****TASK RESULT*****
The Federal Reserve responded to the March 2023 failures of Silicon Valley Bank and Signature Bank by providing liquidity to the banking system. It is unclear what action the FED will take in response to the failure of First Republic Bank.
***TASK LIST***
2: Research the timeline of First Republic Bank's failure.
3: Analyze the Federal Reserve's response to the failure of Silicon Valley Bank and Signature Bank.
4: Compare the Federal Reserve's response to the failure of Silicon Valley Bank and Signature Bank to the Federal Reserve's response to the failure of First Republic Bank.
5: Investigate the potential implications of the Federal Reserve's response to the failure of First Republic Bank.
6: Identify any potential risks associated with the Federal Reserve's response to the failure of First Republic Bank.<br />*****NEXT TASK*****
2: Research the timeline of First Republic Bank's failure.
> Entering new AgentExecutor chain...
Will the FED take the same action as it did on SVB's failure?
Thought: I should search for information about the timeline of First Republic Bank's failure and the FED's action on SVB's failure.
Action: Search
Action Input: Timeline of First Republic Bank's failure and FED's action on SVB's failure
Observation: March 20: The FDIC decides to break up SVB and hold two separate auctions for its traditional deposits unit and its private bank after failing ...
Thought: I should look for more information about the FED's action on SVB's failure.
Action: Search
Action Input: FED's action on SVB's failure
Observation: The Fed blamed failures on mismanagement and supervisory missteps, compounded by a dose of social media frenzy.
Thought: I now know the final answer.
Final Answer: The FED is likely to take similar action on First Republic Bank's failure as it did on SVB's failure, which was to break up the bank and hold two separate auctions for its traditional deposits unit and its private bank.</p><p>> Finished chain.
*****TASK RESULT*****
The FED responded to the March 2023 failures of ilicon Valley Bank and Signature Bank
by providing liquidity to the banking system. JPMorgan Chase acquired First Republic
Bank on May 1, 2023, and if you had insured or uninsured money in First Republic
accounts, your funds are safe and now managed by JPMorgan Chase.*****TASK ENDING*****With BabyAGI for task automation, the dialogue-guided IDP system showcased its effectiveness by going beyond the original document’s context to address the user’s query about the Federal Reserve’s potential actions concerning the First Republic Bank’s failure, which occurred in late April 2023, 1 month after the sample publication, in comparison to SVB’s failure. To achieve this, the system generated a to-do list and completed tasks sequentially. It investigated the circumstances surrounding the First Republic Bank’s failure, pinpointed potential risks tied to the Federal Reserve’s response, and compared it to the response to SVB’s failure.
Although BabyAGI remains a work in progress, it carries the promise of revolutionizing machine interactions, inventive thinking, and problem resolution. As BabyAGI’s learning and enhancement persist, it will be capable of producing more precise, insightful, and inventive responses. By empowering machines to learn and evolve autonomously, BabyAGI could facilitate their assistance in a broad spectrum of tasks, ranging from mundane chores to intricate problem-solving.
Dialogue-guided IDP offers a promising approach to enhancing the efficiency and effectiveness of document analysis and extraction. However, we must acknowledge its current constraints and limitations, such as the need for data bias avoidance, hallucination mitigation, the challenge of handling complex and ambiguous language, and difficulties in understanding context or maintaining coherence in longer conversations.
Additionally, it’s important to consider confabulations and hallucinations in AI-generated responses, which may lead to the creation of inaccurate or fabricated information. To address these challenges, ongoing developments are focusing on refining LLMs with better natural language understanding capabilities, incorporating domain-specific knowledge and developing more robust context-aware models. Building an LLM from scratch can be costly and time-consuming; however, you can employ several strategies to improve existing models:
By adopting these approaches, AI-generated responses can be made more reliable and valuable.
The task-driven autonomous agent offers significant potential across various applications, but it is vital to consider key risks before adopting the technology. These risks include:
Addressing these risks is crucial for responsible and successful application, allowing us to maximize the benefits of AI-powered language models while minimizing potential risks.
The dialogue-guided solution for IDP presents a groundbreaking approach to document processing by integrating OCR, automatic speech recognition, LLMs, task automation, and external data sources. This comprehensive solution enables businesses to streamline their document processing workflows, making them more efficient and intuitive. By incorporating these cutting-edge technologies, organizations can not only revolutionize their document management processes, but also bolster decision-making capabilities and considerably boost overall productivity. The solution offers a transformative and innovative means for businesses to unlock the full potential of their document workflows, ultimately driving growth and success in the era of generative AI. Refer to SageMaker Jumpstart for other solutions and Amazon Bedrock for additional generative AI models.
The authors would like to sincerely express their appreciation to Ryan Kilpatrick, Ashish Lal, and Kristine Pearce for their valuable inputs and contributions to this work. They also acknowledge Clay Elmore for the code sample provided on Github.
 Alfred Shen is a Senior AI/ML Specialist at AWS. He has been working in Silicon Valley, holding technical and managerial positions in diverse sectors including healthcare, finance, and high-tech. He is a dedicated applied AI/ML researcher, concentrating on CV, NLP, and multimodality. His work has been showcased in publications such as EMNLP, ICLR, and Public Health.
Alfred Shen is a Senior AI/ML Specialist at AWS. He has been working in Silicon Valley, holding technical and managerial positions in diverse sectors including healthcare, finance, and high-tech. He is a dedicated applied AI/ML researcher, concentrating on CV, NLP, and multimodality. His work has been showcased in publications such as EMNLP, ICLR, and Public Health.
 Dr. Vivek Madan is an Applied Scientist with the Amazon SageMaker JumpStart team. He got his PhD from University of Illinois at Urbana-Champaign and was a Post Doctoral Researcher at Georgia Tech. He is an active researcher in machine learning and algorithm design and has published papers in EMNLP, ICLR, COLT, FOCS, and SODA conferences.
Dr. Vivek Madan is an Applied Scientist with the Amazon SageMaker JumpStart team. He got his PhD from University of Illinois at Urbana-Champaign and was a Post Doctoral Researcher at Georgia Tech. He is an active researcher in machine learning and algorithm design and has published papers in EMNLP, ICLR, COLT, FOCS, and SODA conferences.
 Dr. Li Zhang is a Principal Product Manager-Technical for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms, a service that helps data scientists and machine learning practitioners get started with training and deploying their models, and uses reinforcement learning with Amazon SageMaker. His past work as a principal research staff member and master inventor at IBM Research has won the test of time paper award at IEEE INFOCOM.
Dr. Li Zhang is a Principal Product Manager-Technical for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms, a service that helps data scientists and machine learning practitioners get started with training and deploying their models, and uses reinforcement learning with Amazon SageMaker. His past work as a principal research staff member and master inventor at IBM Research has won the test of time paper award at IEEE INFOCOM.
 Dr. Changsha Ma is an AI/ML Specialist at AWS. She is a technologist with a PhD in Computer Science, a master’s degree in Education Psychology, and years of experience in data science and independent consulting in AI/ML. She is passionate about researching methodological approaches for machine and human intelligence. Outside of work, she loves hiking, cooking, hunting food, mentoring college students for entrepreneurship, and spending time with friends and families.
Dr. Changsha Ma is an AI/ML Specialist at AWS. She is a technologist with a PhD in Computer Science, a master’s degree in Education Psychology, and years of experience in data science and independent consulting in AI/ML. She is passionate about researching methodological approaches for machine and human intelligence. Outside of work, she loves hiking, cooking, hunting food, mentoring college students for entrepreneurship, and spending time with friends and families.
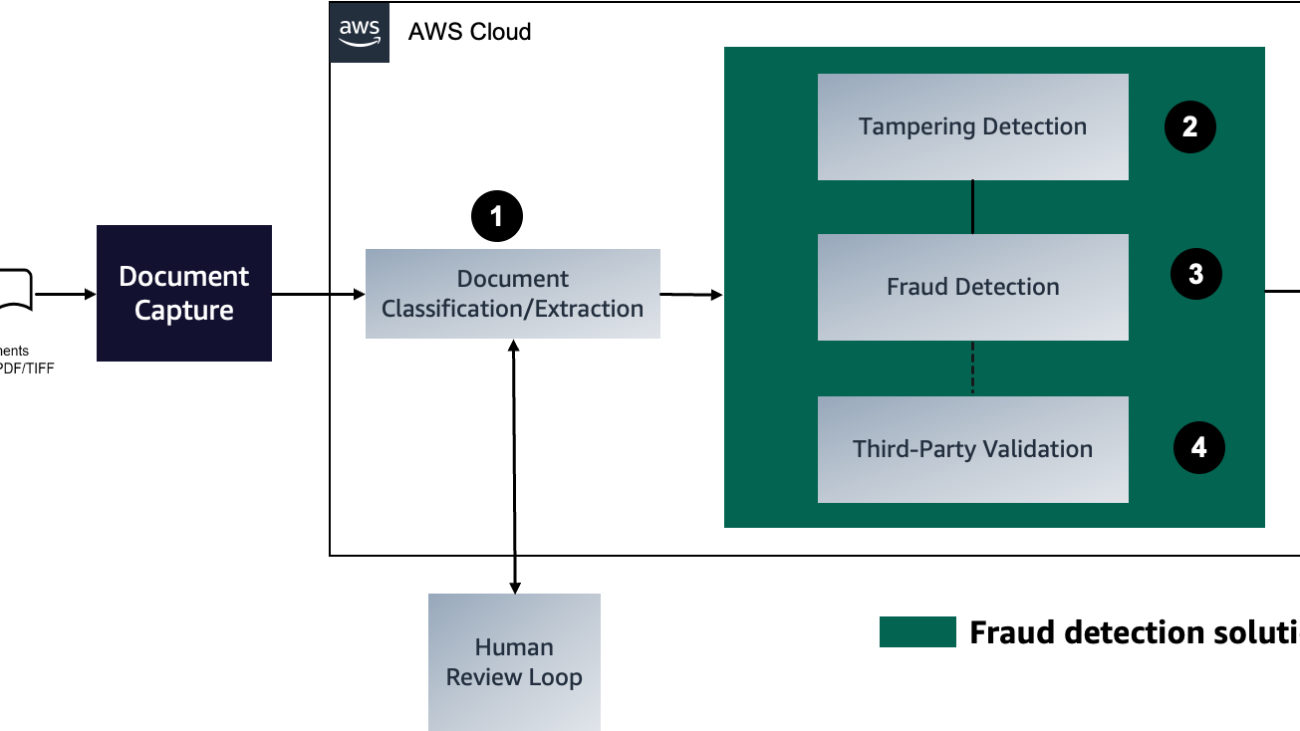
In this three-part series, we present a solution that demonstrates how you can automate detecting document tampering and fraud at scale using AWS AI and machine learning (ML) services for a mortgage underwriting use case.
This solution rides on a more significant global wave of increasing mortgage fraud, which is worsening as more people present fraudulent proofs to qualify for loans. Data suggests high-risk and suspected fraudulent mortgage activity is on the rise, noting a 52% increase in suspected fraudulent mortgage applications since 2013. (Source: Equifax)
Part 1 of this series discusses the most common challenges associated with the manual lending process. We provide concrete guidance on addressing this issue with AWS AI and ML services to detect document tampering, identify and categorize patterns for fraudulent scenarios, and integrate with business-defined rules while minimizing human expertise for fraud detection.
In Part 2, we demonstrate how to train and host a computer vision model for tampering detection and localization on Amazon SageMaker. In Part 3, we show how to automate detecting fraud in mortgage documents with an ML model and business-defined rules using Amazon Fraud Detector.
Organizations in the lending and mortgage industry receive thousands of applications, ranging from new mortgage applications to refinancing an existing mortgage. These documents are increasingly susceptible to document fraud as fraudsters attempt to exploit the system and qualify for mortgages in several illegal ways. To be eligible for a mortgage, the applicant must provide the lender with documents verifying their employment, assets, and debts. Changing borrowing rules and interest rates can drastically alter an applicant’s credit affordability. Fraudsters range from blundering novices to near-perfect masters when creating fraudulent loan application documents. Fraudulent paperwork includes but is not limited to altering or falsifying paystubs, inflating information about income, misrepresenting job status, and forging letters of employment and other key mortgage underwriting documents. These fraud attempts can be challenging for mortgage lenders to capture.
The significant challenges associated with the manual lending process include but not limited to:
Finally, the underwriting process, or the analysis of creditworthiness and the loan decision, takes additional time if done manually. Again, the manual consumer lending process has some advantages, such as approving a loan that requires human judgment. The solution will provide automation and risk mitigation in mortgage underwriting which will help reduce time and cost as compared to the manual process.
Document validation is a critical type of input for mortgage fraud decisions. Understanding the risk profile of the supporting mortgage documents and driving insights from this data can significantly improve risk decisions and is central to any underwriter’s fraud management strategy.
The following diagram represents each stage in a mortgage document fraud detection pipeline. We walk through each of these stages and how they aid towards underwriting accuracy (initiated with capturing documents to classify and extract required content), detecting tampered documents, and finally using an ML model to detect potential fraud classified according to business-driven rules.
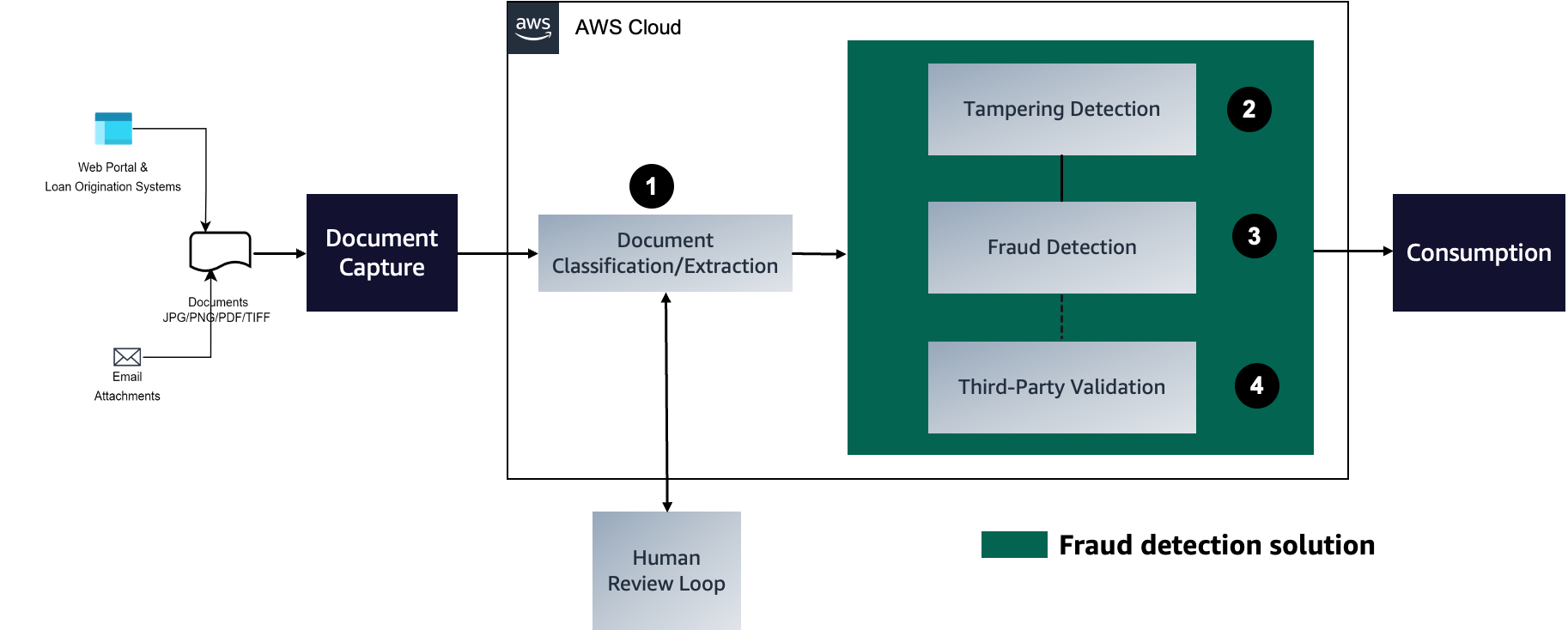
In the following sections, we discuss the stages of the process in detail.
With intelligent document processing (IDP), we can automatically process financial documents using AWS AI services such as Amazon Textract and Amazon Comprehend.
Additionally, we can use the Amazon Textract Analyze Lending API in processing mortgage documents. Analyze Lending uses pre-trained ML models to automatically extract, classify, and validate information in mortgage-related documents with high speed and accuracy while reducing human error. As depicted in the following figure, Analyze Lending receives a loan document and then splits it into pages, classifying them according to the type of document. The document pages are then automatically routed to Amazon Textract text processing operations for accurate data extraction and analysis.
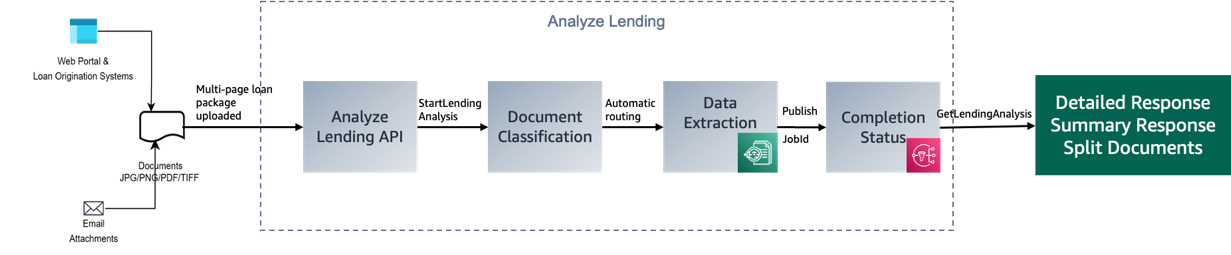
The Analyze Lending API offers the following benefits:
We use a computer vision model deployed on SageMaker for our end-to-end image forgery detection and localization solution, which means it takes a testing image as input and predicts pixel-level forgery likelihood as output.
Most research studies focus on four image forgery techniques: splicing, copy-move, removal, and enhancement. Both splicing and copy-move involve adding image content to the target (forged) image. However, the added content is obtained from a different image in splicing. In copy-move, it’s from the target image. Removal, or inpainting, removes a selected image region (for example, hiding an object) and fills the space with new pixel values estimated from the background. Finally, image enhancement is a vast collection of local manipulations, such as sharpening, brightness, and adjustment.
Depending on the characteristics of the forgery, different clues can be used as the foundation for detection and localization. These clues include JPEG compression artifacts, edge inconsistencies, noise patterns, color consistency, visual similarity, EXIF consistency, and camera model. However, real-life forgeries are more complex and often use a sequence of manipulations to hide the forgery. Most existing methods focus on image-level detection, whether or not an image is forged, and not on localizing or highlighting a forged area of the document image to aid the underwriter in making informed decisions.
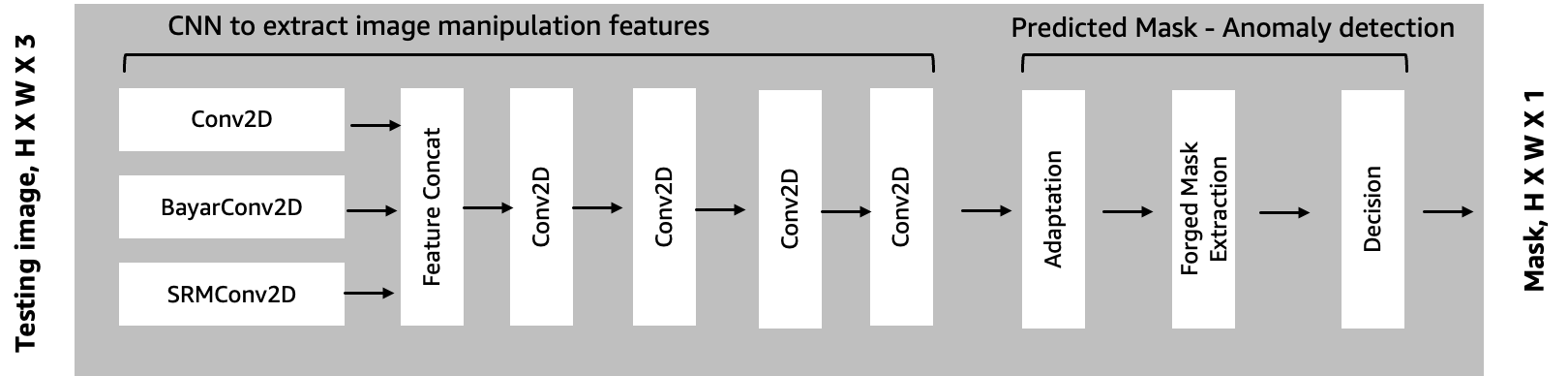
We walk through the implementation details of training and hosting a computer vision model for tampering detection and localization on SageMaker in Part 2 of this series. The conceptual CNN-based architecture of the model is depicted in the following diagram. The model extracts image manipulation trace features for a testing image and identifies anomalous regions by assessing how different a local feature is from its reference features. It detects forged pixels by identifying local anomalous features as a predicted mask of the testing image.
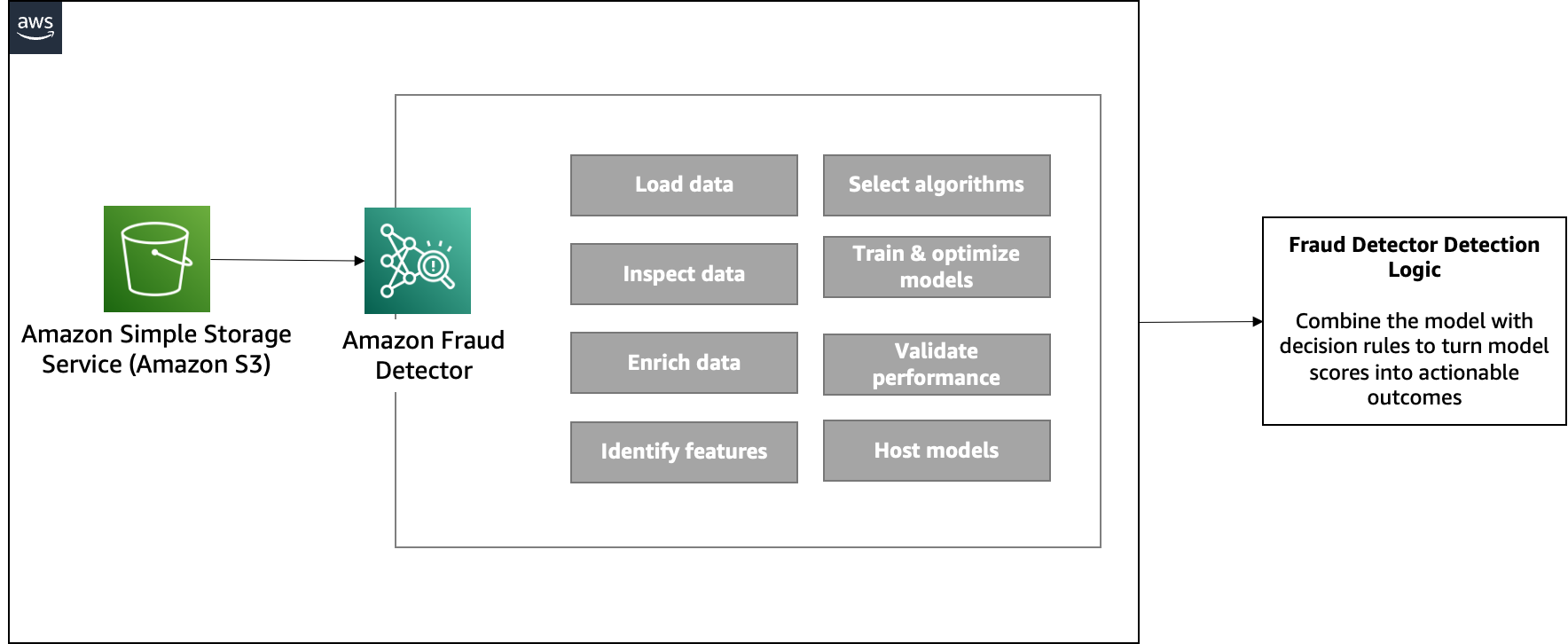
We use Amazon Fraud Detector, a fully managed AI service, to automate the generation, evaluation, and detection of fraudulent activities. This is achieved by generating fraud predictions based on data extracted from the mortgage documents against ML fraud models trained with the customer’s historical (fraud) data. You can use the prediction to trigger business rules in relation to underwriting decisions.
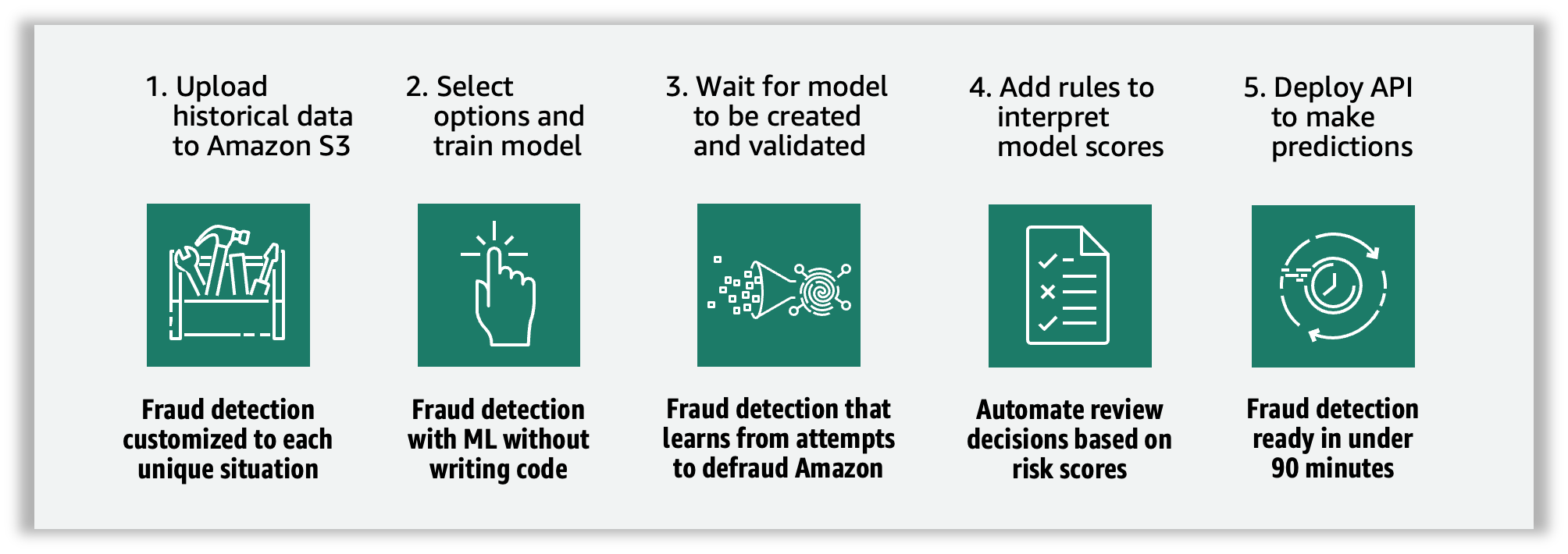
Defining the fraud prediction logic involves the following components:
The following diagram illustrates the architecture of this component.
After you deploy your model, you may evaluate its performance scores and metrics based on the prediction explanations. This helps identify top risk indicators and analyze fraud patterns across the data.
We integrate the solution with third-party providers (via API) to validate the extracted information from the documents, such as personal and employment information. This is particularly useful to cross-validate details in addition to document tampering detection and fraud detection based on the historical pattern of applications.
The following architecture diagram illustrates a batch-oriented fraud detection pipeline in mortgage application processing using various AWS services.
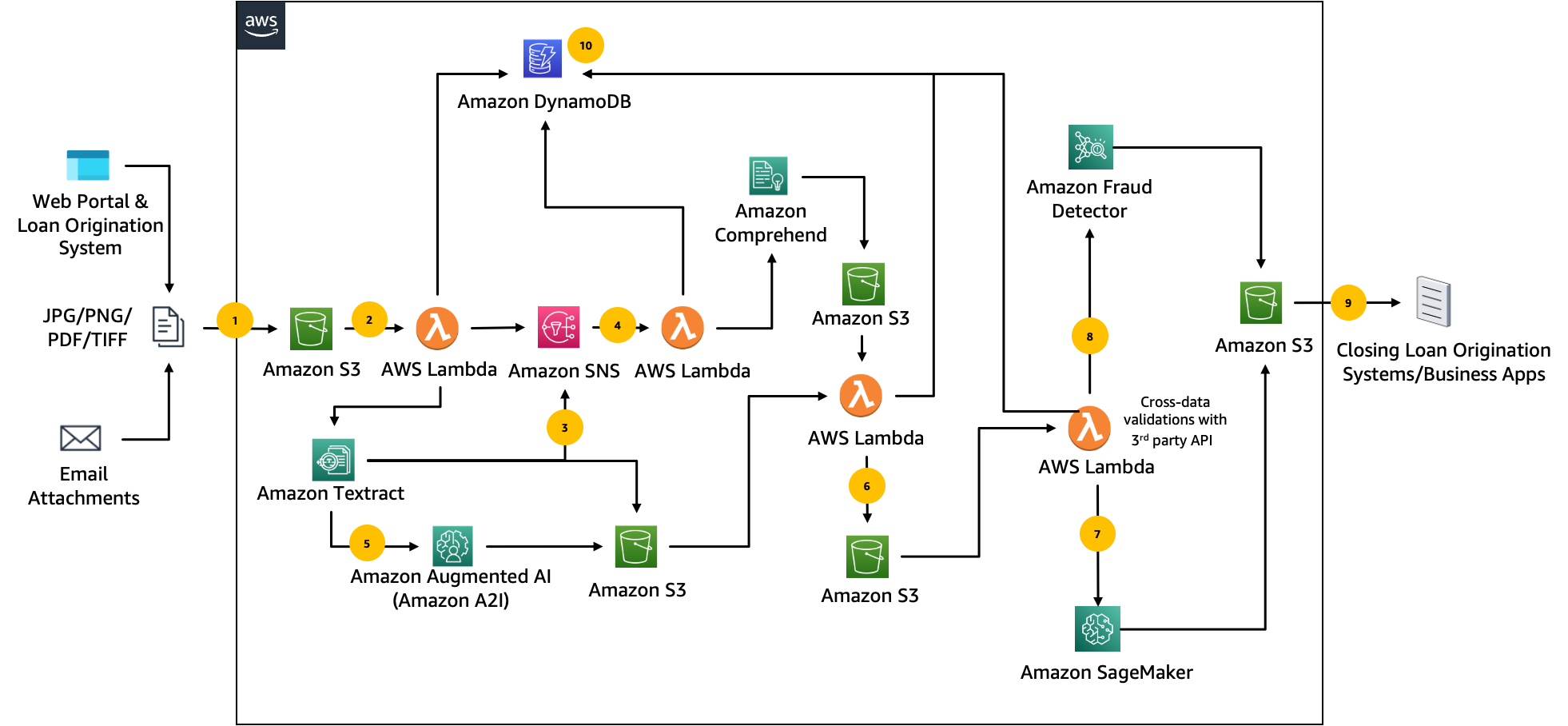
The workflow includes the following steps:
This post walked through an automated solution to detect document tampering and fraud in the mortgage underwriting process using Amazon Fraud Detector and other Amazon AI and ML services. This solution allows you to detect fraudulent attempts closer to the time of fraud occurrence and helps underwriters with an effective decision-making process. The flexibility of the implementation allows you to define business-driven rules to classify and capture the fraudulent attempts customized to specific business needs.
In Part 2 of this series, we provide the implementation details for detecting document tampering using SageMaker. In Part 3, we demonstrate how to implement the solution on Amazon Fraud Detector.
 Anup Ravindranath is a Senior Solutions Architect at Amazon Web Services (AWS) based in Toronto, Canada working with Financial Services organizations. He helps customers to transform their businesses and innovate on cloud.
Anup Ravindranath is a Senior Solutions Architect at Amazon Web Services (AWS) based in Toronto, Canada working with Financial Services organizations. He helps customers to transform their businesses and innovate on cloud.
 Vinnie Saini is a Senior Solutions Architect at Amazon Web Services (AWS) based in Toronto, Canada. She has been helping Financial Services customers transform on cloud, with AI and ML driven solutions laid on strong foundational pillars of Architectural Excellence.
Vinnie Saini is a Senior Solutions Architect at Amazon Web Services (AWS) based in Toronto, Canada. She has been helping Financial Services customers transform on cloud, with AI and ML driven solutions laid on strong foundational pillars of Architectural Excellence.

Today we are excited to announce that you can now perform batch transforms with Amazon SageMaker JumpStart large language models (LLMs) for Text2Text Generation. Batch transforms are useful in situations where the responses don’t need to be real time and therefore you can do inference in batch for large datasets in bulk. For batch transform, a batch job is run that takes batch input as a dataset and a pre-trained model, and outputs predictions for each data point in the dataset. Batch transform is cost-effective because unlike real-time hosted endpoints that have persistent hardware, batch transform clusters are torn down when the job is complete and therefore the hardware is only used for the duration of the batch job.
In some use cases, real-time inference requests can be grouped in small batches for batch processing to create real-time or near-real-time responses. For example, if you need to process a continuous stream of data with low latency and high throughput, invoking a real-time endpoint for each request separately would require more resources and can take longer to process all the requests because the processing is being done serially. A better approach would be to group some of the requests and call the real-time endpoint in batch inference mode, which processes your requests in one forward pass of the model and returns the bulk response for the request in real time or near-real time. The latency of the response will depend upon how many requests you group together and instance memory size, therefore you can tune the batch size per your business requirements for latency and throughput. We call this real-time batch inference because it combines the concept of batching while still providing real-time responses. With real-time batch inference, you can achieve a balance between low latency and high throughput, enabling you to process large volumes of data in a timely and efficient manner.
Jumpstart batch transform for Text2Text Generation models allows you to pass the batch hyperparameters through environment variables that further increase throughput and minimize latency.
JumpStart provides pretrained, open-source models for a wide range of problem types to help you get started with machine learning (ML). You can incrementally train and tune these models before deployment. JumpStart also provides solution templates that set up infrastructure for common use cases, and executable example notebooks for ML with Amazon SageMaker. You can access the pre-trained models, solution templates, and examples through the JumpStart landing page in Amazon SageMaker Studio. You can also access JumpStart models using the SageMaker Python SDK.
In this post, we demonstrate how to use the state-of-the-art pre-trained text2text FLAN T5 models from Hugging Face for batch transform and real-time batch inference.
The notebook showing batch transform of pre-trained Text2Text FLAN T5 models from Hugging Face in available in the following GitHub repository. This notebook uses data from the Hugging Face cnn_dailymail dataset for a text summarization task using the SageMaker SDK.
The following are the key steps for implementing batch transform and real-time batch inference:
Before you run the notebook, you must complete some initial setup steps. Let’s set up the SageMaker execution role so it has permissions to run AWS services on your behalf:
We use the huggingface-text2text-flan-t5-large model as a default model. Optionally, you can retrieve the list of available Text2Text models on JumpStart and choose your preferred model. This method provides a straightforward way to select different model IDs using same notebook. For demonstration purposes, we use the huggingface-text2text-flan-t5-large model:
With SageMaker, we can perform inference on the pre-trained model, even without fine-tuning it first on a new dataset. We start by retrieving the deploy_image_uri, deploy_source_uri, and model_uri for the pre-trained model:
You may pass any subset of hyperparameters as environment variables to the batch transform job. You can also pass these hyperparameters in a JSON payload. However, if you’re setting environment variables for hyperparameters like the following code shows, then the advanced hyperparameters from the individual examples in the JSON lines payload will not be used. If you want to use hyperparameters from the payload, you may want to set the hyper_params_dict parameter as null instead.
Now we’re ready to load the cnn_dailymail dataset from Hugging Face:
We go over each data entry and create the input data in the required format. We create an articles.jsonl file as a test data file containing articles that need to be summarized as input payload. As we create this file, we append the prompt "Briefly summarize this text:" to each test input row. If you want to have different hyperparameters for each test input, you can append those hyperparameters as part of creating the dataset.
We create highlights.jsonl as the ground truth file containing highlights of each article stored in the test file articles.jsonl. We store both test files in an Amazon Simple Storage Service (Amazon S3) bucket. See the following code:
When you start a batch transform job, SageMaker launches the necessary compute resources to process the data, including CPU or GPU instances depending on the selected instance type. During the batch transform job, SageMaker automatically provisions and manages the compute resources required to process the data, including instances, storage, and networking resources. When the batch transform job is complete, the compute resources are automatically cleaned up by SageMaker. This means that the instances and storage used during the job are stopped and removed, freeing up resources and minimizing cost. See the following code:
The following is one example record from the articles.jsonl test file. Note that record in this file has an ID that matched with predict.jsonl file records that shows a summarized record as output from the Hugging Face Text2Text model. Similarly, the ground truth file also has a matching ID for the data record. The matching ID across the test file, ground truth file, and output file allows linking input records with output records for easy interpretation of the results.
The following is the example input record provided for summarization:
The following is the predicted output with summarization:
The following is the ground truth summarization for model evaluation purposes:
Next, we use the ground truth and predicted outputs for model evaluation.
ROUGE, or Recall-Oriented Understudy for Gisting Evaluation, is a set of metrics and a software package used for evaluating automatic summarization and machine translation in natural language processing. The metrics compare an automatically produced summary or translation against a reference (human-produced) summary or translation or a set of references.
In the following code, we combine the predicted and original summaries by joining them on the common key id and use this to compute the ROUGE score:
Next, we show you how to run real-time batch inference on the endpoint by providing the inputs as a list. We use the same model ID and dataset as earlier, except we take a few records from the test dataset and use them to invoke a real-time endpoint.
The following code shows how to create and deploy a real-time endpoint for real-time batch inference:
Next, we prepare our input payload. For this, we use the data that we prepared earlier and extract the first 10 test inputs and append the text inputs with hyperparameters that we want to use. We provide this payload to the real-time invoke_endpoint. The response payload is then returned as a list of responses. See the following code:
After you have tested the endpoint, make sure you delete the SageMaker inference endpoint and delete the model to avoid incurring charges.
In this notebook, we performed a batch transform to showcase the Hugging Face Text2Text Generator model for summarization tasks. Batch transform is advantageous in obtaining inferences from large datasets without requiring a persistent endpoint. We linked input records with inferences to aid in result interpretation. We used the ROUGE score to compare the test data summarization with the model-generated summarization.
Additionally, we demonstrated real-time batch inference, where you can send a small batch of data to a real-time endpoint to achieve a balance between latency and throughput for scenarios like streaming input data. Real-time batch inference helps increase throughput for real-time requests.
Try out the batch transform with Text2Text Generation models in SageMaker today and let us know your feedback!
 Hemant Singh is a Machine Learning Engineer with experience in Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He got his masters from Courant Institute of Mathematical Sciences and B.Tech from IIT Delhi. He has experience in working on a diverse range of machine learning problems within the domain of natural language processing, computer vision, and time series analysis.
Hemant Singh is a Machine Learning Engineer with experience in Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He got his masters from Courant Institute of Mathematical Sciences and B.Tech from IIT Delhi. He has experience in working on a diverse range of machine learning problems within the domain of natural language processing, computer vision, and time series analysis.
 Rachna Chadha is a Principal Solutions Architect AI/ML in Strategic Accounts at AWS. Rachna is an optimist who believes that the ethical and responsible use of AI can improve society in future and bring economic and social prosperity. In her spare time, Rachna likes spending time with her family, hiking, and listening to music.
Rachna Chadha is a Principal Solutions Architect AI/ML in Strategic Accounts at AWS. Rachna is an optimist who believes that the ethical and responsible use of AI can improve society in future and bring economic and social prosperity. In her spare time, Rachna likes spending time with her family, hiking, and listening to music.
 Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker built-in algorithms and helps develop machine learning algorithms. He got his PhD from University of Illinois Urbana-Champaign. He is an active researcher in machine learning and statistical inference, and has published many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.
Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker built-in algorithms and helps develop machine learning algorithms. He got his PhD from University of Illinois Urbana-Champaign. He is an active researcher in machine learning and statistical inference, and has published many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.


Welcome to Research Focus, a series of blog posts that highlights notable publications, events, code/datasets, new hires and other milestones from across the research community at Microsoft.
Emre Kıcıman, Robert Ness, Amit Sharma, Chenhao Tan
Recent advances in scaling large language models (LLMs) have led to breakthroughs in AI capabilities, including writing code in programming languages, generating stories, poems, essays, and other texts, and strong performance in certain reasoning tasks. LLMs can even create plausible explanations for their outputs, and update their conclusions given new evidence.
At the same time, LLMs can make absurd claims and basic errors of logic, mathematics, and complex reasoning, which raises questions about their applicability in societally impactful domains such as medicine, science, law, and policy.
In a new paper: Causal Reasoning and Large Language Models: Opening a New Frontier for Causality, researchers from Microsoft examine the causal capabilities of LLMs. They find that LLMs, on average, can outperform state-of-the-art causal algorithms in graph discovery and counterfactual inference, and can systematize nebulous concepts like necessity and sufficiency of cause by operating solely on natural language input. They show that by capturing commonsense and domain knowledge about causal mechanisms, LLMs open new frontiers for advancing the research, practice, and adoption of causality. The researchers envision pairing LLMs alongside existing causal methods to reduce the required manual effort that has been a major impediment to widespread adoption of causal analysis.
Spotlight: Microsoft Research Podcast

What is intelligence? How does it emerge and how do we measure it? Ashley Llorens and machine learning theorist Sébastian Bubeck discuss accelerating progress in large-scale AI and early experiments with GPT-4.
As the world generates more and more data, data storage capacity has not kept pace. Traditional long-term storage media such as hard disks or magnetic tape have limited durability and storage density. But DNA has an intrinsic capacity for information storage, durability, and high information density.
In DNA data storage, a large amount of data is stored together, and it is important to perform random access – selective retrieval of individual data files. This is achieved using polymerase chain reaction (PCR), a molecular process that can exponentially amplify a target file. However, this process can damage the data and cause errors. PCR amplification of multiple files simultaneously creates serious undesired DNA crosstalk. Currently one can only read one file at a time, but not a subset of files in a larger set.
In a recent paper: DNA storage in thermoresponsive microcapsules for repeated random multiplexed data access, researchers from Microsoft and external colleagues report on their work to develop a microcapsule-based PCR random access. By encapsulating individual files in each capsule, DNA files were physically separated, reducing undesired crosstalk. This enabled the simultaneous reading of all 25 files in the pool, without significant errors. The use of microcapsules also allowed DNA files to be recovered after random access, addressing the destructive reads problem and potentially making DNA data storage more economical.
A new synthesis is emerging that integrates AI technologies with human-computer interaction (HCI) to produce human-centered AI (HCAI). Advocates of HCAI seek to amplify, augment, and enhance human abilities, so as to empower people, build their self-efficacy, support creativity, recognize responsibility, and promote social connections. Researchers, developers, business leaders, policy makers, and others are expanding the technology-centered scope of AI to include HCAI ways of thinking.
In this recent Microsoft Research Talk: Human-Centered AI: Ensuring Human Control While Increasing Automation Ben Shneiderman discusses his HCAI framework, design metaphors, and governance structures and other ideas drawn from his award-winning new book Human-Centered AI. The talk by Shneiderman, a Distinguished University Professor in the University of Maryland Department of Computer Science, is hosted by Mary Czerwinski, Partner Researcher and Research Manager with Microsoft Research.
The Microsoft New Future of Work Initiative is now accepting proposals to fund academic projects that help maximize the impact of LLMs and related AI systems on how work gets done. This call for proposals targets work that specifically supports the use of LLMs in productivity scenarios. The program plans to distribute five $50,000 USD unrestricted awards to support creative research that redefines what work might mean in various contexts.
For example: how can we ensure these new technologies truly accelerate productivity rather than having effects on the margins; how can LLMs achieve these gains by augmenting human labor; what is the future of a ‘document’ in a world where natural language can be so easily remixed and repurposed.
Proposals will be accepted through June 5, 2023.
The post Research Focus: Week of May 22, 2023 appeared first on Microsoft Research.