Google Cloud empowers organizations to digitally transform themselves into smarter businesses. It offers cloud computing, data analytics, and the latest artificial intelligence (AI) and machine learning tools.Read More

Google Cloud empowers organizations to digitally transform themselves into smarter businesses. It offers cloud computing, data analytics, and the latest artificial intelligence (AI) and machine learning tools.Read More

Google Cloud empowers organizations to digitally transform themselves into smarter businesses. It offers cloud computing, data analytics, and the latest artificial intelligence (AI) and machine learning tools.Read More

Google Cloud empowers organizations to digitally transform themselves into smarter businesses. It offers cloud computing, data analytics, and the latest artificial intelligence (AI) and machine learning tools.Read More

Google Cloud empowers organizations to digitally transform themselves into smarter businesses. It offers cloud computing, data analytics, and the latest artificial intelligence (AI) and machine learning tools.Read More

Google Cloud empowers organizations to digitally transform themselves into smarter businesses. It offers cloud computing, data analytics, and the latest artificial intelligence (AI) and machine learning tools.Read More

Google Cloud empowers organizations to digitally transform themselves into smarter businesses. It offers cloud computing, data analytics, and the latest artificial intelligence (AI) and machine learning tools.Read More

Editor’s note: This post is part of our weekly In the NVIDIA Studio series, which celebrates featured artists, offers creative tips and tricks, and demonstrates how NVIDIA Studio technology improves creative workflows. We’re also deep diving on new GeForce RTX 40 Series GPU features, technologies and resources, and how they dramatically accelerate content creation.
With over 900,000 subscribers on her YouTube channel, editor and filmmaker Sara Dietschy creates docuseries, reviews and vlogs that explore the intersection of technology and creativity. The Los Angeles-based creator shares her AI-powered workflow this week In the NVIDIA Studio, and it’s just peachy — a word that happens to rhyme with her last name.
Dietschy explained in a recent video how five AI tools helped save over 100 hours of work, powered by NVIDIA Studio technology.
“If you do any kind of 3D rendering on the go, a dedicated NVIDIA RTX GPU is nonnegotiable.” — Sara Dietschy
She shows a practical approach to how these tools, running on laptops powered by GeForce RTX 40 Series GPUs, tackle the otherwise manual work that can make nonlinear editing tedious. Using tools like AI Relighting, Video Text Editing and more in Davinci Resolve software, Dietschy saves time on every project — and for creators, time is money, she said.
The NVIDIA Studio team spoke with Dietschy about how she uses AI, how technology can simplify artists’ processes, and how the NVIDIA Studio platform supercharged her creativity and video-editing workflows.

Studio team: What AI features do you use most commonly?
Dietschy: In DaVinci Resolve, there’s neural engine text-based editing, automatic subtitles, Magic Mask and Detect Scene Cuts — all AI-powered features I use daily. And the relighting feature in DaVinci Resolve is crazy good.
In addition, ChatGPT and Notion AI sped up copywriting for my website and social media posts, so I could focus on video editing.
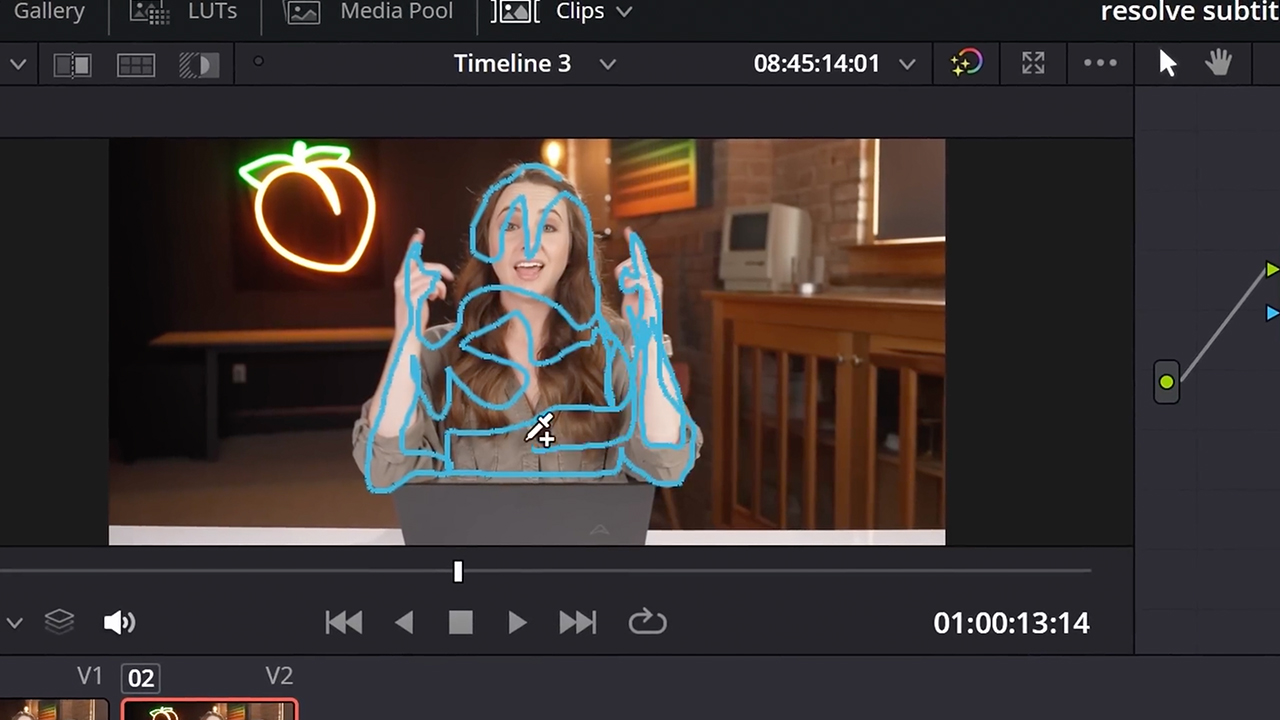
Studio team: How do you use Adobe Premiere Pro?
Dietschy: In the beta version, my entire video can be transcribed quickly, and Premiere Pro can even detect silence. Just click on the three dots in the text, hit delete and boom — AI conveniently edits out that awkward pause. No need for me to hop back and forth.
Plus, Auto Reframe and Unsharp Mask are popular AI features in Premiere Pro that are worth looking into.
Studio team: What prompted the regular use of AI-powered tools and features?
Dietschy: My biggest pet peeve is when a program offers really cool features but requires uploading everything to a web app or starting a completely new workflow. Once these features were made available directly in the apps I already use, things became so much more efficient, which is why I now use them on the daily.
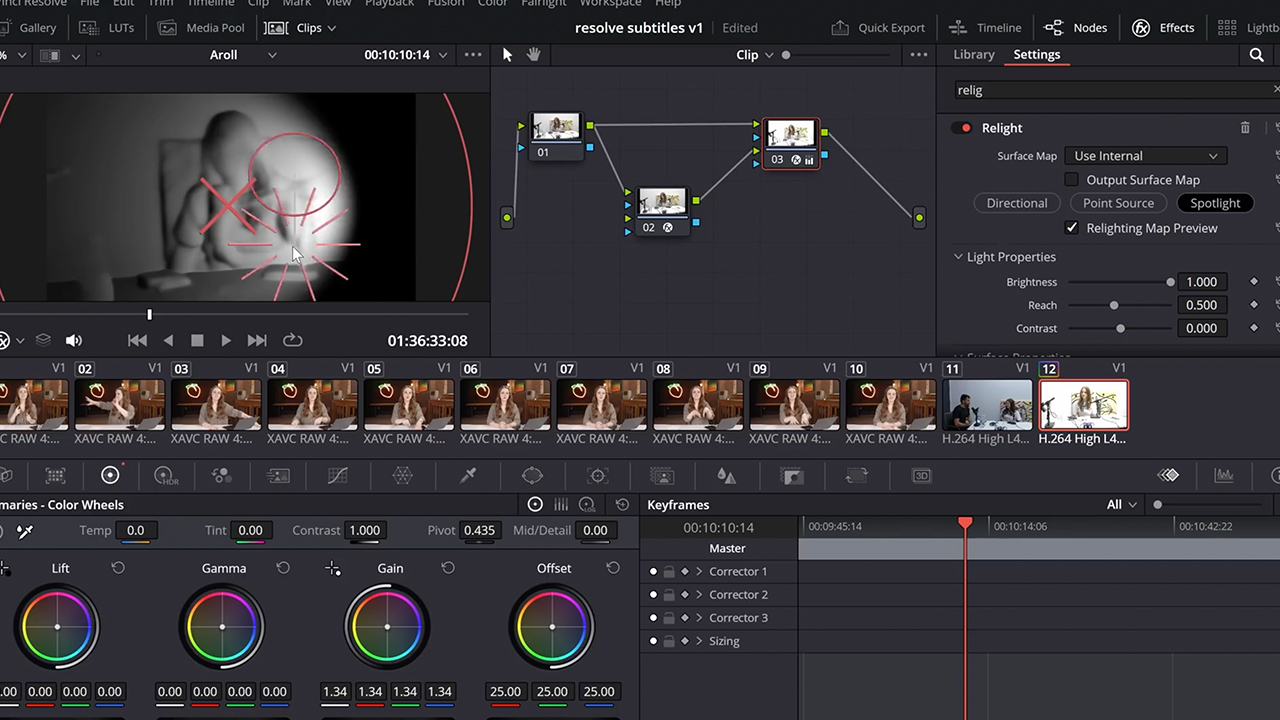
Studio team: For the non-technical people out there, why does GPU acceleration in creative apps matter?
Dietschy: For video editors, GPU acceleration — which is basically a graphics card making the features and effects in creative apps faster — especially in DaVinci Resolve, is everything. It scrubs through footage and playback, and crushes export times. This ASUS Zenbook Pro 14 OLED Studio laptop exported a recent hour-plus-long 4K video in less than 14 minutes. If you release new content every week, like me, time saved is gold.
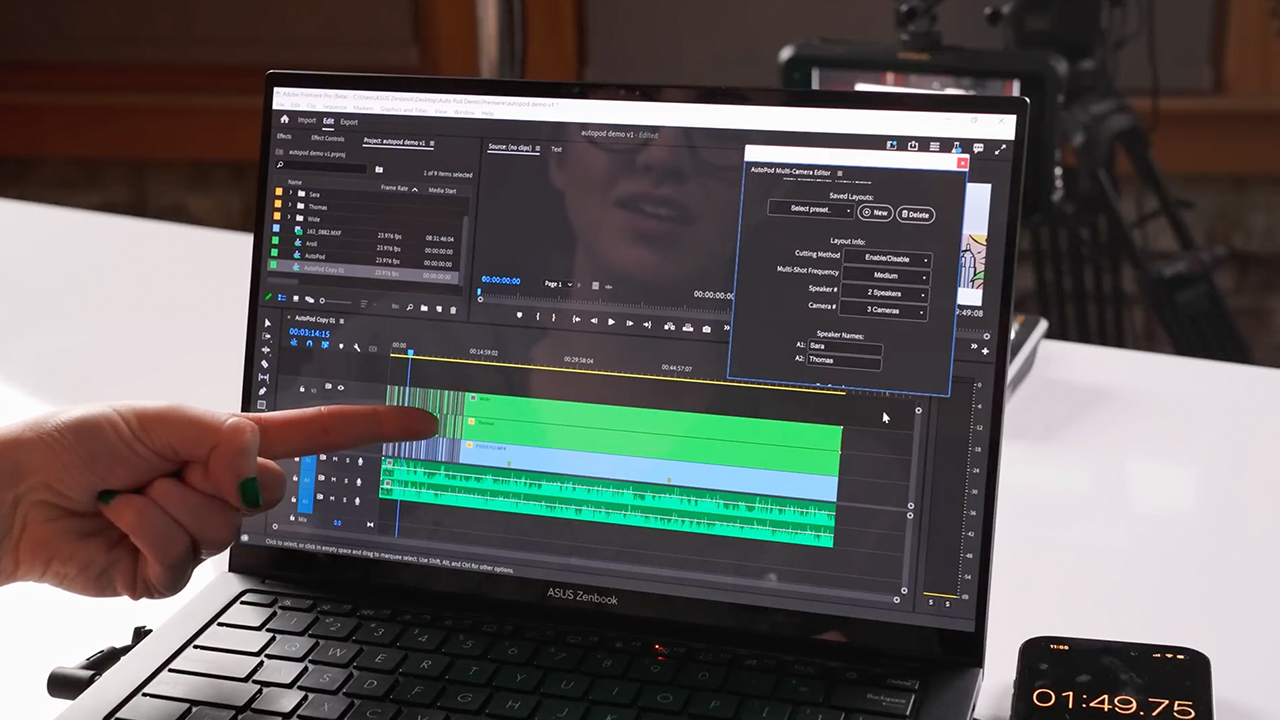
Studio team: Would you recommend GeForce RTX GPUs to other video editors?
Dietschy: Absolutely. A big unlock for me was getting a desktop computer with a nice processor and an NVIDIA GPU. I was just amazed at how much smoother things went.
Studio team: If you could go back to the beginning of your creative journey, what advice would you give yourself?
Dietschy: Don’t focus so much on quantity. Instead, take the time to add structure to your process, because being a “messy creative” only seems cool at first. Organization is already paying crazy dividends in better sleep and mental health.
For more AI insights, watch Dietschy’s video on the dozen-plus AI tools creators should use:
Find more on Sara Dietschy’s YouTube channel.

Follow NVIDIA Studio on Instagram, Twitter and Facebook. Access tutorials on the Studio YouTube channel and get updates directly in your inbox by subscribing to the Studio newsletter.

 Google and YouTube’s new AI-powered solutions help advertisers multiply their creativity and generate demand.Read More
Google and YouTube’s new AI-powered solutions help advertisers multiply their creativity and generate demand.Read More

The use of self-supervision from image-text pairs has been a key enabler in the development of scalable and flexible vision-language AI models in not only general domains but also in biomedical domains such as radiology. The goal in the radiology setting is to produce rich training signals without requiring manual labels so the models can learn to accurately recognize and locate findings in the images and relate them to content in radiology reports.
Radiologists use radiology reports to describe imaging findings and offer a clinical diagnosis or a range of possible diagnoses, all of which can be influenced by considering the findings on previous imaging studies. In fact, comparisons with previous images are crucial for radiologists to make informed decisions. These comparisons can provide valuable context for determining whether a condition is a new concern or improving, deteriorating, or stable if an existing condition and can inform more appropriate treatment recommendations. Despite the importance of comparisons, current AI solutions for radiology often fall short in aligning images with report data because of the lack of access to prior scans. Current AI solutions also typically fail to account for the chronological progression of disease or imaging findings often present in biomedical datasets. This can lead to ambiguity in the model training process and can be risky in downstream applications such as automated report generation, where models may make up temporal content without access to past medical scans. In short, this limits the real-world applicability of such AI models to empower caregivers and augment existing workflows.
In our previous work, we demonstrated that multimodal self-supervised learning of radiology images and reports can yield significant performance improvement in downstream applications of machine learning models, such as detecting the presence of medical conditions and localizing these findings within the images. In our latest study, which is being presented at the 2023 IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR), we propose BioViL-T, a self-supervised training framework that further increases the data efficiency of this learning paradigm by leveraging the temporal structure present in biomedical datasets. This approach enables the incorporation of temporal information and has the potential to perform complementary self-supervision without the need for additional data, resulting in improved predictive performance.
Our proposed approach can handle missing or spatially misaligned images and can potentially scale to process a large number of prior images. By leveraging the existing temporal structure available in datasets, BioViL-T achieves state-of-the-art results on several downstream benchmarks. We’ve made both our models and source code open source, allowing for a comprehensive exploration and validation of the results discussed in our study. We’ve also released a new multimodal temporal benchmark dataset, MS-CXR-T, to support further research into longitudinal modeling of medical images and text data.
SPOTLIGHT: AI focus area

Learn more about the breadth of AI research at Microsoft
Solving for the static case in vision-language processing—that is, learning with pairs of single images and captions—is a natural first step in advancing the field. So it’s not surprising that current biomedical vision-language processing work has largely focused on tasks that are dependent on features or abnormalities present at a single point in time—what is a patient’s current condition, and what is a likely diagnosis?—treating image-text pairs such as x-rays and corresponding reports in today’s datasets as independent data points. When prior imaging findings are referenced in reports, that information is often ignored or removed in the training process. Further, a lack of publicly available datasets containing longitudinal series of imaging examinations and reports has further challenged the incorporation of temporal information into medical imaging benchmarks.
Thanks to our early and close collaboration with practicing radiologists and our long-standing work with Nuance, a leading provider of AI solutions in the radiology space that was acquired by Microsoft in 2022, we’ve been able to better understand clinician workflow in the radiological imaging setting. That includes how radiology data is created, what its different components are, and how routinely radiologists refer to prior studies in the context of interpreting medical images. With these insights, we were able to identify temporal alignment of text across multiple images as a clinically significant research problem. To ground, or associate, report information such as “pleural effusion has improved compared to previous study” with the imaging modality requires access to the prior imaging study. We were able to tackle this challenge without gathering additional data or annotations.
As an innovative solution, we leveraged the metadata from de-identified public datasets like MIMIC-CXR. This metadata preserves the original order and intervals of studies, allowing us to connect various images over time and observe disease progression. Developing more data efficient and smart solutions in the healthcare space, where data sources are scarce, is important if we want to develop meaningful AI solutions.
With current and prior images now available for comparison, the question became, how can a model reason about images coming from different time points? Radiological imaging, especially with planar techniques like radiographs, may show noticeable variation. This can be influenced by factors such as the patient’s posture during capture and the positioning of the device. Notably, these variations become more pronounced when images are taken with longer time gaps in between. To manage variations, current approaches to longitudinal analysis, largely used for fully supervised learning of image models only, require extensive preprocessing, such as image registration, a technique that attempts to align multiple images taken at different times from different viewpoints. In addition to better managing image variation, we wanted a framework that could be applied to cases in which prior images weren’t relevant or available and the task involved only one image.
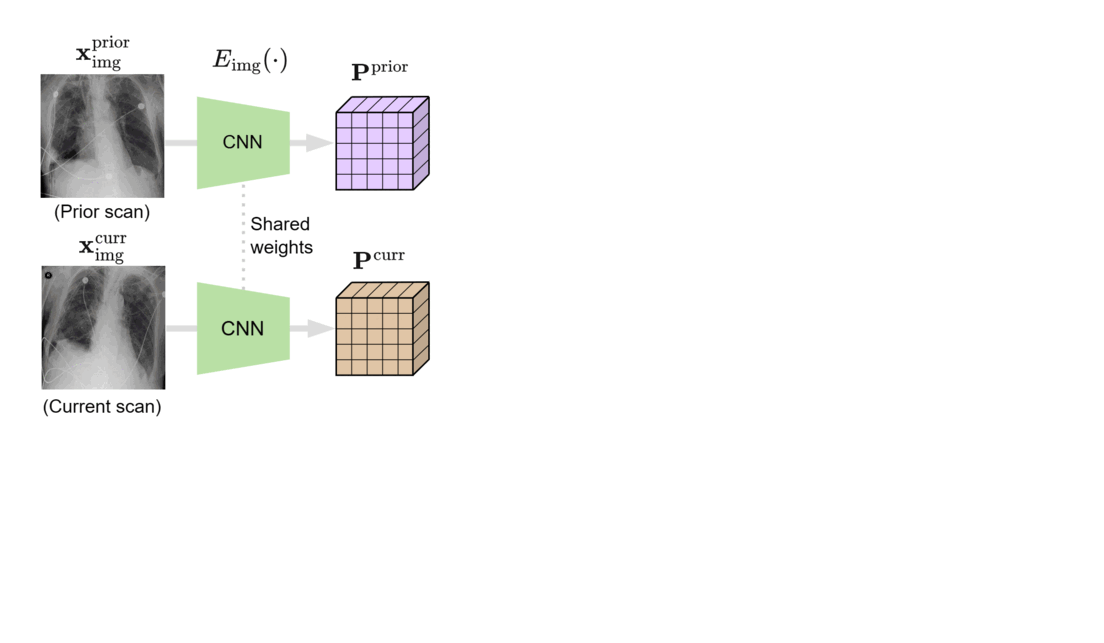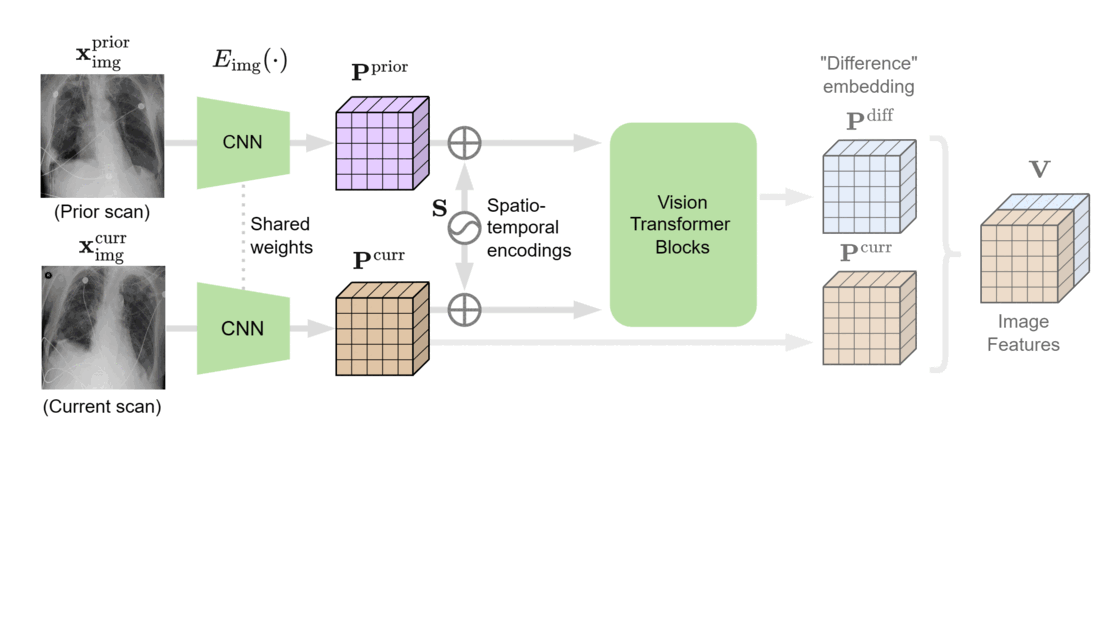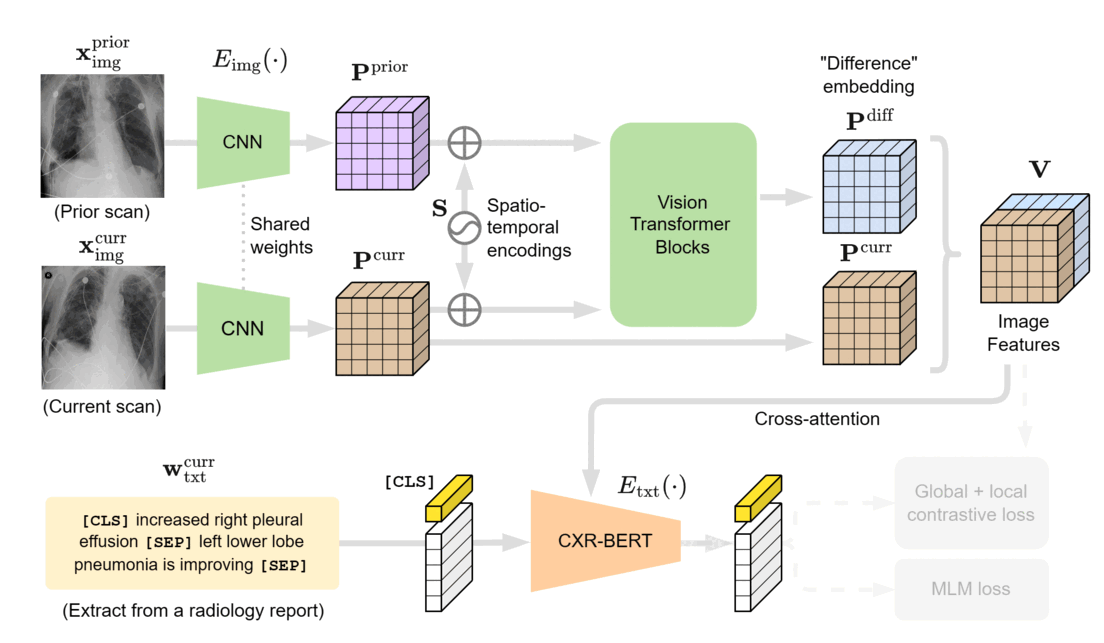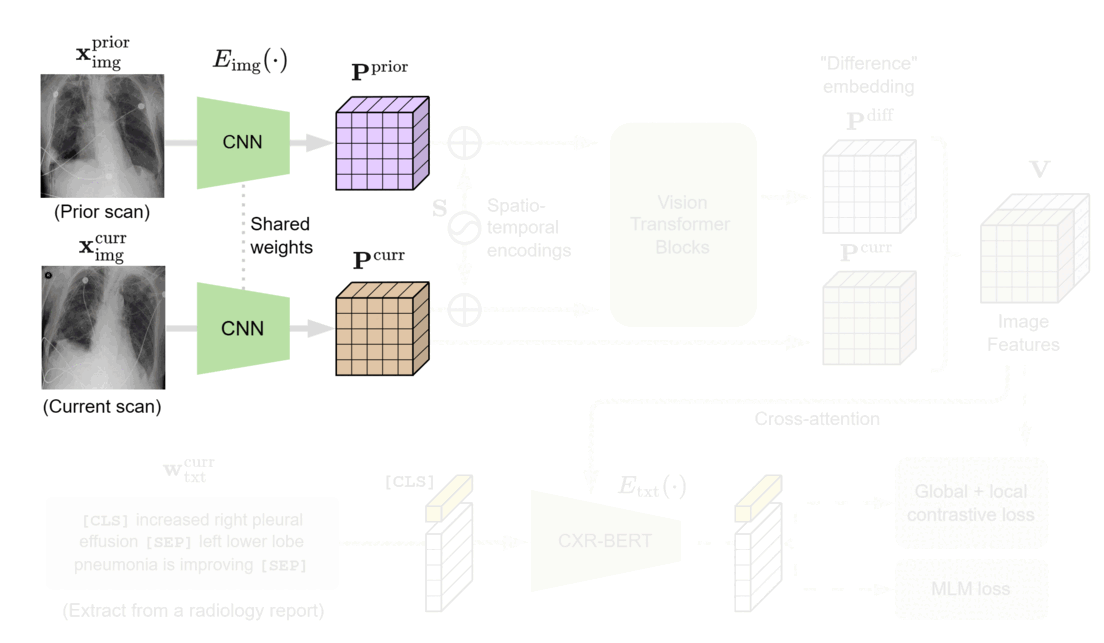
We designed BioViL-T with these challenges in mind. Its main components are a multi-image encoder, consisting of both a vision transformer and a convolutional neural network (CNN), and a text encoder. As illustrated in Figure 1, in the multi-image encoder, each input image is first encoded with the CNN model to independently extract findings, such as opacities, present in each medical scan. Here, the CNN counteracts the large data demands of transformer-based architectures through its efficiency in extracting lower-level semantic features.
At the next stage, the features across time points are matched and compared in the vision transformer block, then aggregated into a single joint representation incorporating both current and historical radiological information. It’s important to note that the transformer architecture can adapt to either single- or multi-image scenarios, thereby better handling situations in which past images are unavailable, such as when there’s no relevant image history. Additionally, a cross-attention mechanism across image regions reduces the need for extensive preprocessing, addressing potential variations across images.
In the final stage, the multi-image encoder is jointly trained with the text encoder to match the image representations with their text counterparts using masked modeling and contrastive supervision techniques. To improve text representations and model supervision, we utilize the domain-specific text encoder CXR-BERT-general, which is pretrained on clinical text corpora and built on a clinical vocabulary.
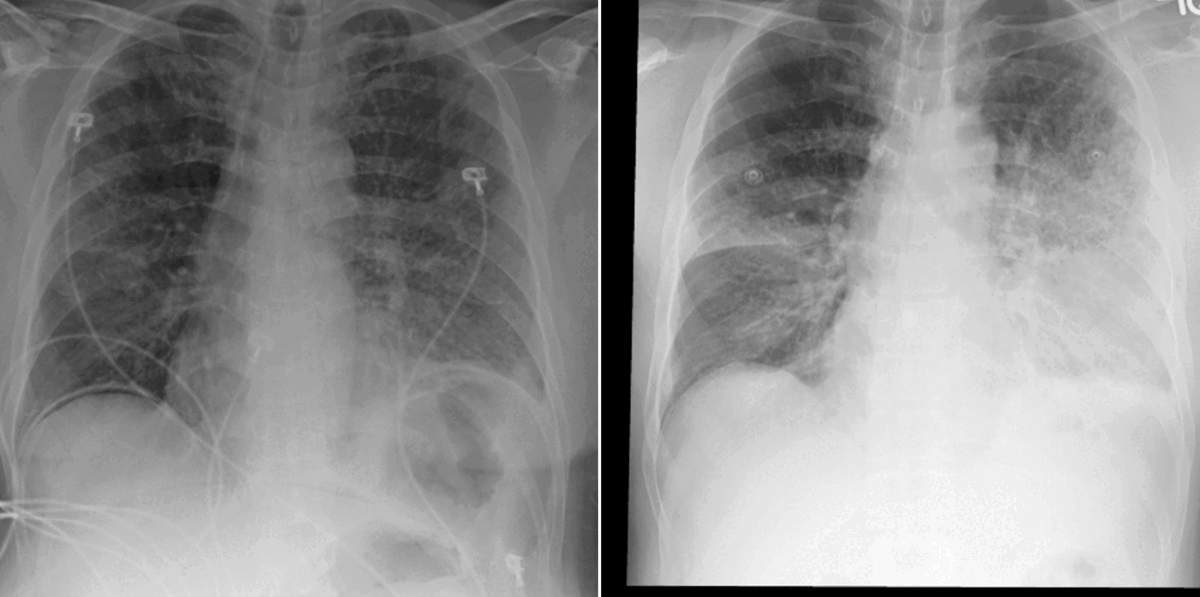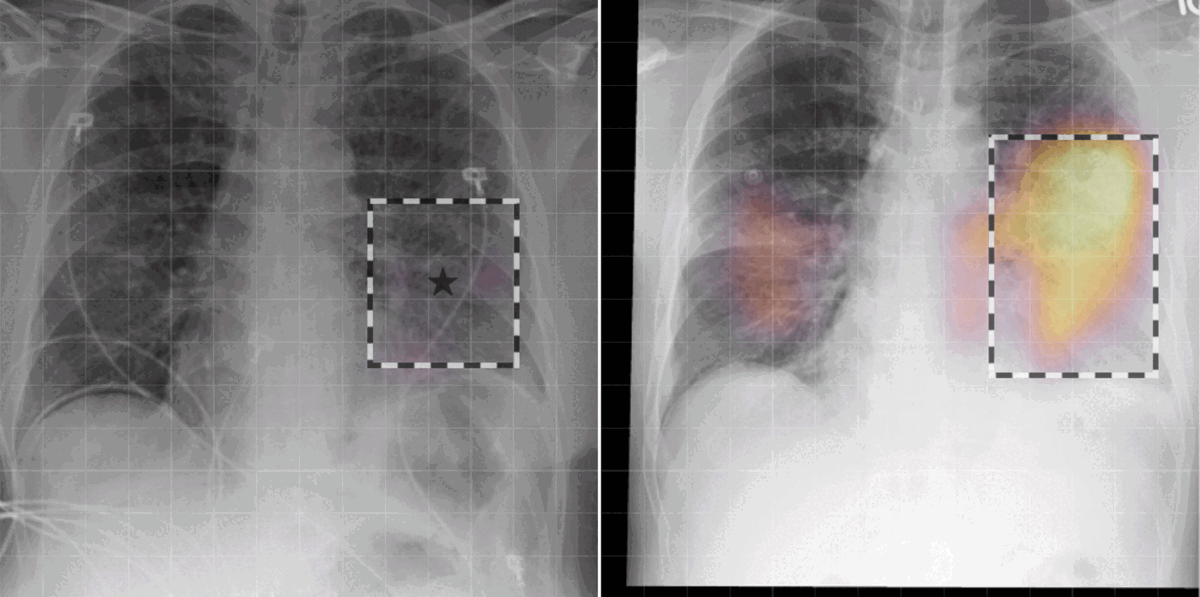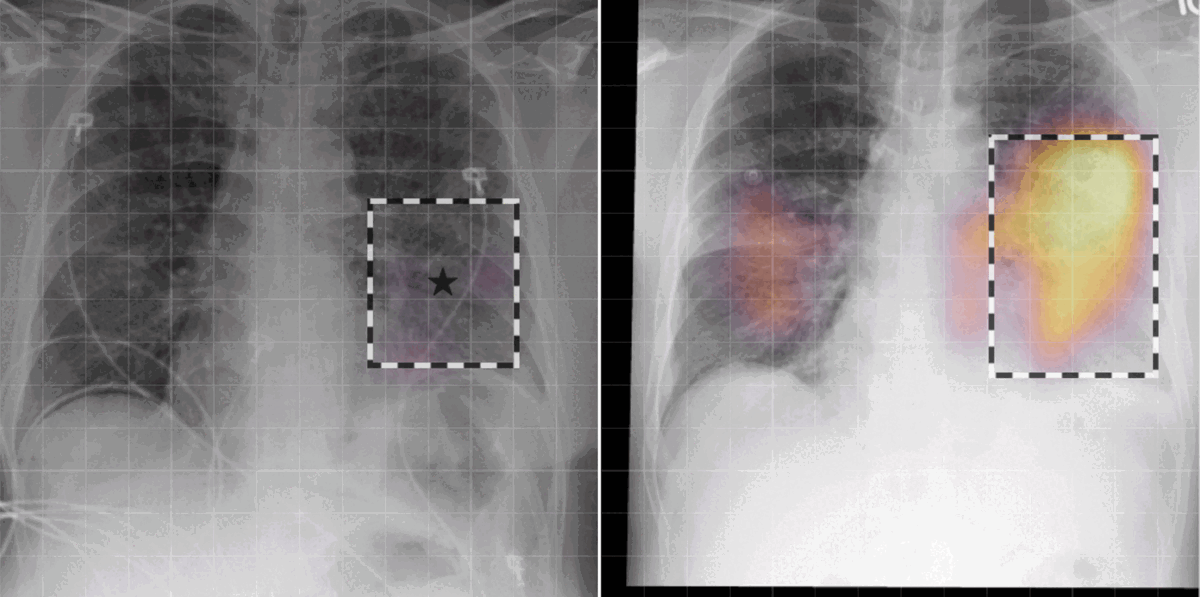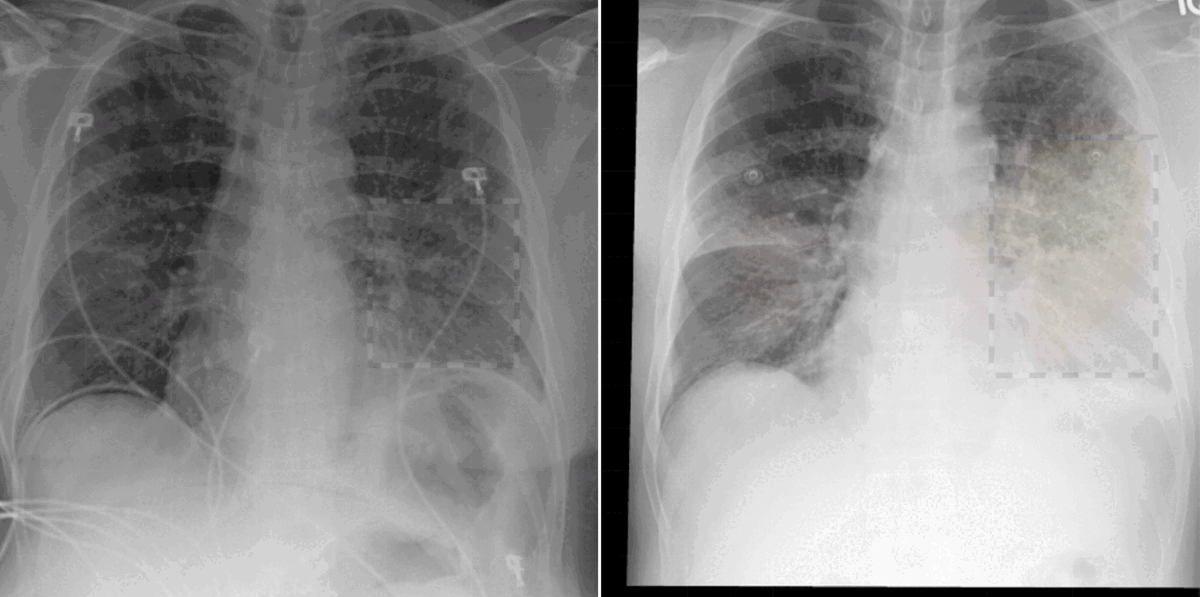
In our work, we found that linking multiple images during pretraining makes for both better language and vision representations, enabling the AI model to better associate information present in both the text and the images. This means that when given a radiology report of a chest x-ray, for example, with the description “increased opacities in the left lower lung compared with prior examination,” a model can more accurately identify, locate, and compare findings, such as opacities. This improved alignment between data modalities is crucial because it allows the model to provide more accurate and relevant insights, such as identifying abnormalities in medical images, generating more accurate diagnostic reports, or tracking the progression of a disease over time.
Two findings were particularly insightful for us during our experimentation with BioViL-T:
Through our relationships with practicing radiologists and Nuance, we were able to identify and concentrate on a clinically important research problem, finding that accounting for patient history matters if we want to develop AI solutions with value. To help the research community advance longitudinal analysis, we’ve released a new benchmark dataset. MS-CXR-T, which was curated by a board-certified radiologist, consists of current-prior image pairs of chest x-rays labeled with a state of progression for the temporal image classification task and pairs of sentences about disease progression that are either contradictory or capture the same assessment but are phrased differently for the sentence similarity task.
We focused on chest x-rays and lung diseases, but we see our work as having the potential to be extended into other medical imaging settings where analyzing images over time plays an important part in clinician decision-making, such as scenarios involving MRI or CT scans. However far the reach, it’s vital to ensure that models such as BioViL-T generalize well across different population groups and under the various conditions in which medical images are captured. This important part of the journey requires extensive benchmarking of models on unseen datasets. These datasets should widely vary in terms of acquisition settings, patient demographics, and disease prevalence. Another aspect of this work we look forward to exploring and monitoring is the potential role of general foundation models like GPT-4 in domain-specific foundation model training and the benefits of pairing larger foundation models with smaller specialized models such as BioViL-T.
To learn more and to access our text and image models and source code, visit the BioViL-T Hugging Face page and GitHub.
We’d like to thank our co-authors: Shruthi Bannur, Stephanie Hyland, Qianchu Liu, Fernando Pérez-García, Maximilian Ilse, Daniel C. Castro, Benedikt Boecking, Harshita Sharma, Kenza Bouzid, Anja Thieme, Anton Schwaighofer, Maria Wetscherek, and Aditya Nori. We’d also like to thank Hoifung Poon, Melanie Bernhardt, Melissa Bristow, and Naoto Usuyama for their valuable technical feedback and Hannah Richardson for assisting with compliance reviews.
BioViL-T was developed for research purposes and is not designed, intended, or made available as a medical device and should not be used to replace or as a substitute for professional medical advice, diagnosis, treatment, or judgment.
The post Accounting for past imaging studies: Enhancing radiology AI and reporting appeared first on Microsoft Research.

This post is co-written with Jad Chamoun, Director of Engineering at Forethought Technologies, Inc. and Salina Wu, Senior ML Engineer at Forethought Technologies, Inc.
Forethought is a leading generative AI suite for customer service. At the core of its suite is the innovative SupportGPT technology which uses machine learning to transform the customer support lifecycle—increasing deflection, improving CSAT, and boosting agent productivity. SupportGPT leverages state-of-the-art Information Retrieval (IR) systems and large language models (LLMs) to power over 30 million customer interactions annually.
technology which uses machine learning to transform the customer support lifecycle—increasing deflection, improving CSAT, and boosting agent productivity. SupportGPT leverages state-of-the-art Information Retrieval (IR) systems and large language models (LLMs) to power over 30 million customer interactions annually.

SupportGPT’s primary use case is enhancing the quality and efficiency of customer support interactions and operations. By using state-of-the-art IR systems powered by embeddings and ranking models, SupportGPT can quickly search for relevant information, delivering accurate and concise answers to customer queries. Forethought uses per-customer fine-tuned models to detect customer intents in order to solve customer interactions. The integration of large language models helps humanize the interaction with automated agents, creating a more engaging and satisfying support experience.
SupportGPT also assists customer support agents by offering autocomplete suggestions and crafting appropriate responses to customer tickets that align with the company’s based on previous replies. By using advanced language models, agents can address customers’ concerns faster and more accurately, resulting in higher customer satisfaction.
Additionally, SupportGPT’s architecture enables detecting gaps in support knowledge bases, which helps agents provide more accurate information to customers. Once these gaps are identified, SupportGPT can automatically generate articles and other content to fill these knowledge voids, ensuring the support knowledge base remains customer-centric and up to date.
In this post, we share how Forethought uses Amazon SageMaker multi-model endpoints in generative AI use cases to save over 66% in cost.
To help bring these capabilities to market, Forethought efficiently scales its ML workloads and provides hyper-personalized solutions tailored to each customer’s specific use case. This hyper-personalization is achieved through fine-tuning embedding models and classifiers on customer data, ensuring accurate information retrieval results and domain knowledge that caters to each client’s unique needs. The customized autocomplete models are also fine-tuned on customer data to further enhance the accuracy and relevance of the responses generated.
One of the significant challenges in AI processing is the efficient utilization of hardware resources such as GPUs. To tackle this challenge, Forethought uses SageMaker multi-model endpoints (MMEs) to run multiple AI models on a single inference endpoint and scale. Because the hyper-personalization of models requires unique models to be trained and deployed, the number of models scales linearly with the number of clients, which can become costly.
To achieve the right balance of performance for real-time inference and cost, Forethought chose to use SageMaker MMEs, which support GPU acceleration. SageMaker MMEs enable Forethought to deliver high-performance, scalable, and cost-effective solutions with subsecond latency, addressing multiple customer support scenarios at scale.
SageMaker is a fully managed service that provides developers and data scientists the ability to build, train, and deploy ML models quickly. SageMaker MMEs provide a scalable and cost-effective solution for deploying a large number of models for real-time inference. MMEs use a shared serving container and a fleet of resources that can use accelerated instances such as GPUs to host all of your models. This reduces hosting costs by maximizing endpoint utilization compared to using single-model endpoints. It also reduces deployment overhead because SageMaker manages loading and unloading models in memory and scaling them based on the endpoint’s traffic patterns. In addition, all SageMaker real-time endpoints benefit from built-in capabilities to manage and monitor models, such as including shadow variants, auto scaling, and native integration with Amazon CloudWatch (for more information, refer to CloudWatch Metrics for Multi-Model Endpoint Deployments).
As Forethought grew to host hundreds of models that also required GPU resources, we saw an opportunity to create a more cost-effective, reliable, and manageable architecture through SageMaker MMEs. Prior to migrating to SageMaker MMEs, our models were deployed on Kubernetes on Amazon Elastic Kubernetes Service (Amazon EKS). Although Amazon EKS provided management capabilities, it was immediately apparent that we were managing infrastructure that wasn’t specifically tailored for inference. Forethought had to manage model inference on Amazon EKS ourselves, which was a burden on engineering efficiency. For example, in order to share expensive GPU resources between multiple models, we were responsible for allocating rigid memory fractions to models that were specified during deployment. We wanted to address the following key problems with our existing infrastructure:
Ultimately, we needed an inference platform to take on the heavy lifting of managing our models at runtime to improve the cost, reliability, and the management of serving our models. SageMaker MMEs allowed us to address these needs.
Through its smart and dynamic model loading and unloading, and its scaling capabilities, SageMaker MMEs provided a significantly less expensive and more reliable solution for hosting our models. We are now able to fit many more models per instance and don’t have to worry about OOM errors because SageMaker MMEs handle loading and unloading models dynamically. In addition, deployments are now as simple as calling Boto3 SageMaker APIs and attaching the proper auto scaling policies.
The following diagram illustrates our legacy architecture.
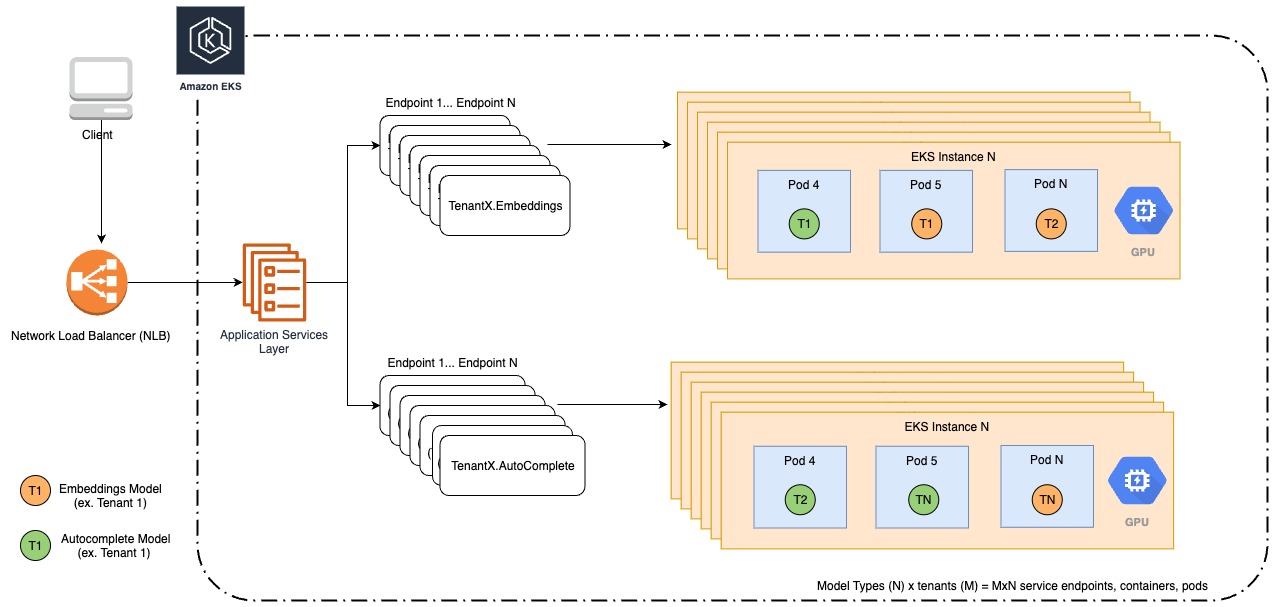
To begin our migration to SageMaker MMEs, we identified the best use cases for MMEs and which of our models would benefit the most from this change. MMEs are best used for the following:
We identified our embeddings models and autocomplete language models as the best candidates for our migration. To organize these models under MMEs, we would create one MME per model type, or task, one for our embeddings models, and another for autocomplete language models.
We already had an API layer on top of our models for model management and inference. Our task at hand was to rework how this API was deploying and handling inference on models under the hood with SageMaker, with minimal changes to how clients and product teams interacted with the API. We also needed to package our models and custom inference logic to be compatible with NVIDIA Triton Inference Server using SageMaker MMEs.
The following diagram illustrates our new architecture.
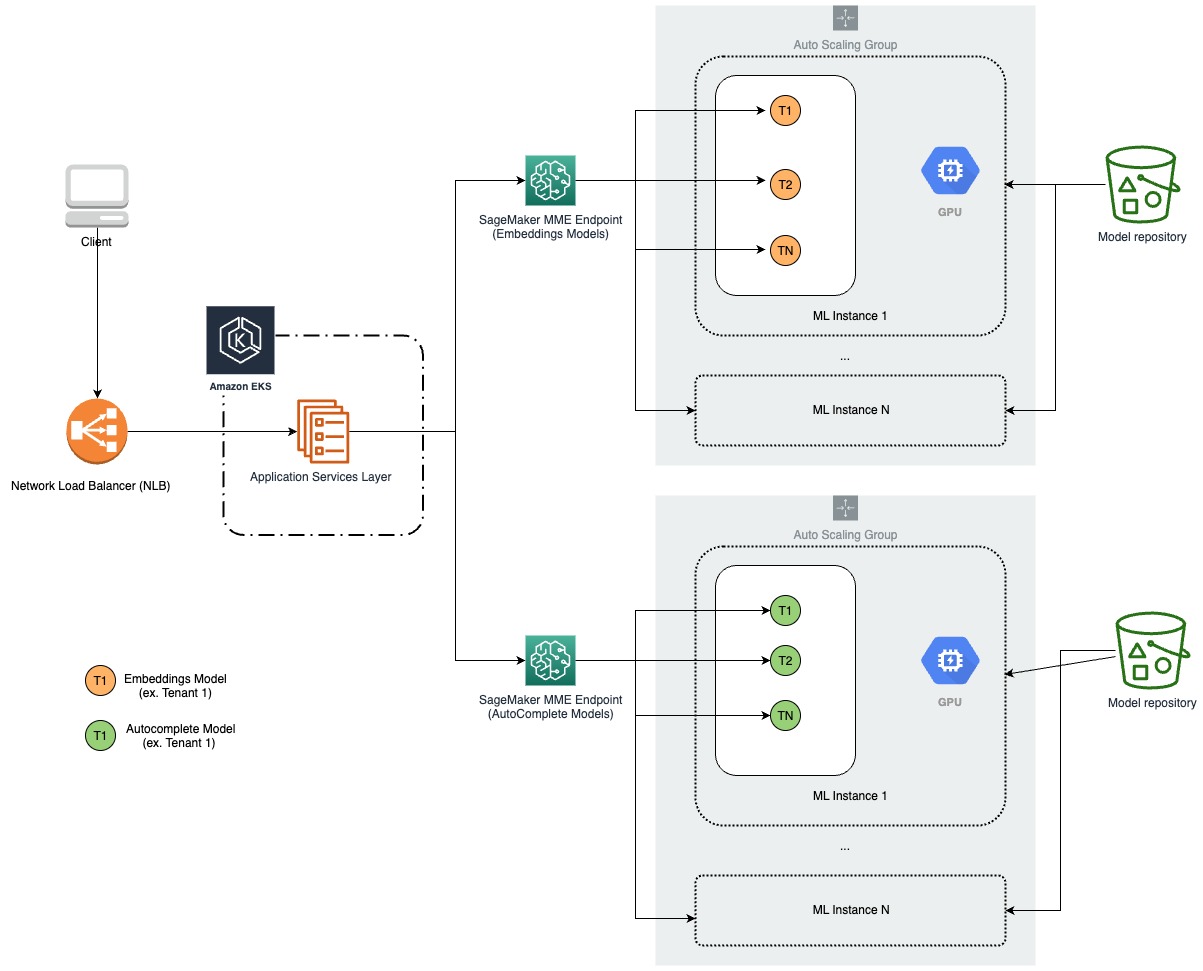
Before migrating to SageMaker, Forethought’s custom inference code (preprocessing and postprocessing) ran in the API layer when a model was invoked. The objective was to transfer this functionality to the model itself to clarify the separation of responsibilities, modularize and simplify their code, and reduce the load on the API.
Forethought’s embedding models consist of two PyTorch model artifacts, and the inference request determines which model to call. Each model requires preprocessed text as input. The main challenges were integrating a preprocessing step and accommodating two model artifacts per model definition. To address the need for multiple steps in the inference logic, Forethought developed a Triton ensemble model with two steps: a Python backend preprocessing process and a PyTorch backend model call. Ensemble models allow for defining and ordering steps in the inference logic, with each step represented by a Triton model of any backend type. To ensure compatibility with the Triton PyTorch backend, the existing model artifacts were converted to TorchScript format. Separate Triton models were created for each model definition, and Forethought’s API layer was responsible for determining the appropriate TargetModel to invoke based on the incoming request.
The autocomplete models (sequence to sequence) presented a distinct set of requirements. Specifically, we needed to enable the capability to loop through multiple model calls and cache substantial inputs for each call, all while maintaining low latency. Additionally, these models necessitated both preprocessing and postprocessing steps. To address these requirements and achieve the desired flexibility, Forethought developed autocomplete MME models utilizing the Triton Python backend, which offers the advantage of writing the model as Python code.
After the Triton model shapes were determined, we deployed models to staging endpoints and conducted resource and performance benchmarking. Our main goal was to determine the latency for cold start vs in-memory models, and how latency was affected by request size and concurrency. We also wanted to know how many models could fit on each instance, how many models would cause the instances to scale up with our auto scaling policy, and how quickly the scale-up would happen. In keeping with the instance types we were already using, we did our benchmarking with ml.g4dn.xlarge and ml.g4dn.2xlarge instances.
The following table summarizes our results.
| Request Size | Cold Start Latency | Cached Inference Latency | Concurrent Latency (5 requests) |
| Small (30 tokens) | 12.7 seconds | 0.03 seconds | 0.12 seconds |
| Medium (250 tokens) | 12.7 seconds | 0.05 seconds | 0.12 seconds |
| Large (550 tokens) | 12.7 seconds | 0.13 seconds | 0.12 seconds |
Noticeably, the latency for cold start requests is significantly higher than the latency for cached inference requests. This is because the model needs to be loaded from disk or Amazon Simple Storage Service (Amazon S3) when a cold start request is made. The latency for concurrent requests is also higher than the latency for single requests. This is because the model needs to be shared between concurrent requests, which can lead to contention.
The following table compares the latency of the legacy models and the SageMaker models.
| Request Size | Legacy Models | SageMaker Models |
| Small (30 tokens) | 0.74 seconds | 0.24 seconds |
| Medium (250 tokens) | 0.74 seconds | 0.24 seconds |
| Large (550 tokens) | 0.80 seconds | 0.32 seconds |
Overall, the SageMaker models are a better choice for hosting autocomplete models than the legacy models. They offer lower latency, scalability, reliability, and security.
In our quest to determine the optimal number of models that could fit on each instance, we conducted a series of tests. Our experiment involved loading models into our endpoints using an ml.g4dn.xlarge instance type, without any auto scaling policy.
These particular instances offer 15.5 GB of memory, and we aimed to achieve approximately 80% GPU memory usage per instance. Considering the size of each encoder model artifact, we managed to find the optimal number of Triton encoders to load on an instance to reach our targeted GPU memory usage. Furthermore, given that each of our embeddings models corresponds to two Triton encoder models, we were able to house a set number of embeddings models per instance. As a result, we calculated the total number of instances required to serve all our embeddings models. This experimentation has been crucial in optimizing our resource usage and enhancing the efficiency of our models.
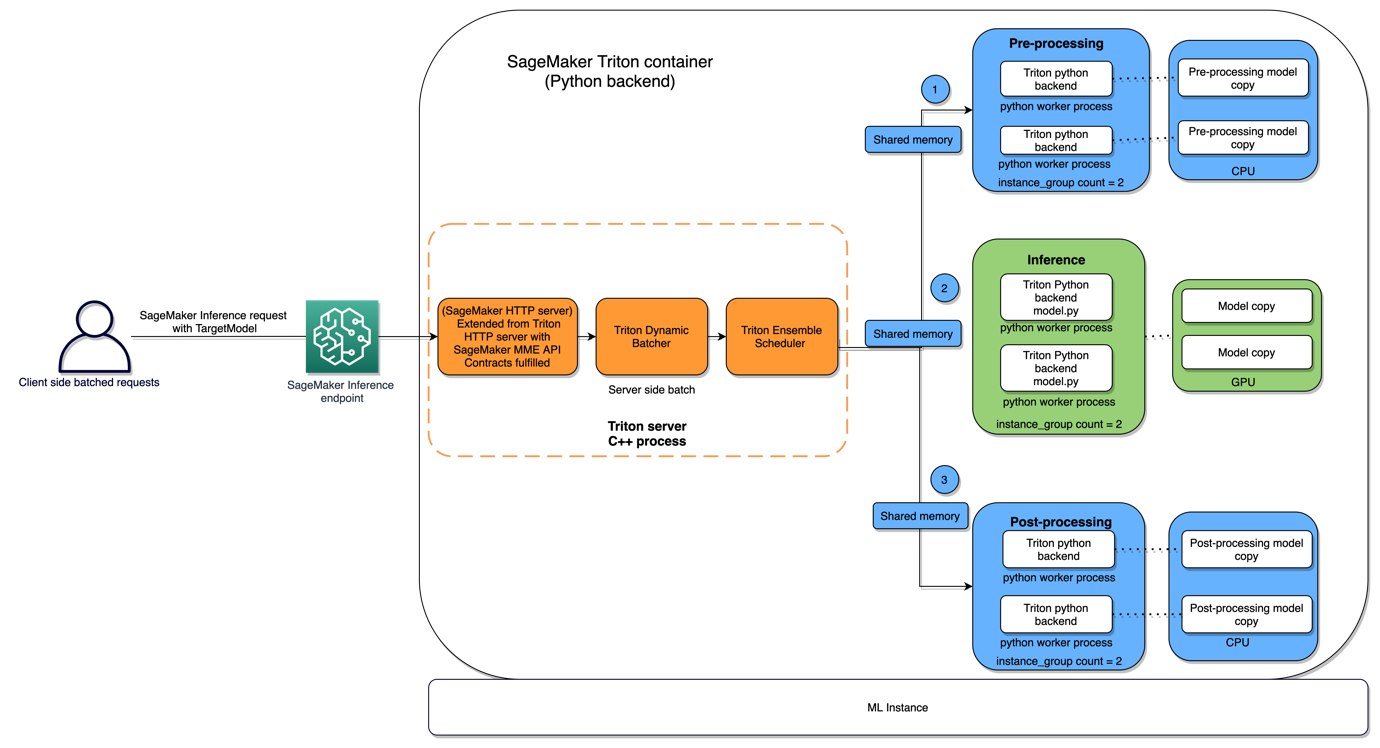
We conducted similar benchmarking for our autocomplete models. These models were around 292.0 MB each. As we tested how many models would fit on a single ml.g4dn.xlarge instance, we noticed that we were only able to fit four models before our instance started unloading models, despite the models having a small size. Our main concerns were:
We were able to pinpoint the root cause of the memory utilization spike coming from initializing our CUDA runtime environment in our Python model, which was necessary to move our models and data on and off the GPU device. CUDA loads many external dependencies into CPU memory when the runtime is initialized. Because the Triton PyTorch backend handles and abstracts away moving data on and off the GPU device, we didn’t run into this issue for our embedding models. To address this, we tried using ml.g4dn.2xlarge instances, which had the same amount of GPU memory but twice as much CPU memory. In addition, we added several minor optimizations in our Python backend code, including deleting tensors after use, emptying the cache, disabling gradients, and garbage collecting. With the larger instance type, we were able to fit 10 models per instance, and the CPU and GPU memory utilization became much more aligned.
The following diagram illustrates this architecture.
We attached auto scaling policies to both our embeddings and autocomplete MMEs. Our policy for our embeddings endpoint targeted 80% average GPU memory utilization using custom metrics. Our autocomplete models saw a pattern of high traffic during business hours and minimal traffic overnight. Because of this, we created an auto scaling policy based on InvocationsPerInstance so that we could scale according to the traffic patterns, saving on cost without sacrificing reliability. Based on our resource usage benchmarking, we configured our scaling policies with a target of 225 InvocationsPerInstance.
Creating an MME on SageMaker is straightforward and similar to creating any other endpoint on SageMaker. After the endpoint is created, adding additional models to the endpoint is as simple as moving the model artifact to the S3 path that the endpoint targets; at this point, we can make inference requests to our new model.
We defined logic that would take in model metadata, format the endpoint deterministically based on the metadata, and check whether the endpoint existed. If it didn’t, we create the endpoint and add the Triton model artifact to the S3 patch for the endpoint (also deterministically formatted). For example, if the model metadata indicated that it is an autocomplete model, it would create an endpoint for auto-complete models and an associated S3 path for auto-complete model artifacts. If the endpoint existed, we would copy the model artifact to the S3 path.
Now that we had our model shapes for our MME models and the functionality for deploying our models to MME, we needed a way to automate the deployment. Our users must specify which model they want to deploy; we handle packaging and deployment of the model. The custom inference code packaged with the model is versioned and pushed to Amazon S3; in the packaging step, we pull the inference code according to the version specified (or the latest version) and use YAML files that indicate the file structures of the Triton models.
One requirement for us was that all of our MME models would be loaded into memory to avoid any cold start latency during production inference requests to load in models. To achieve this, we provision enough resources to fit all our models (according to the preceding benchmarking) and call every model in our MME at an hourly cadence.
The following diagram illustrates the model deployment pipeline.
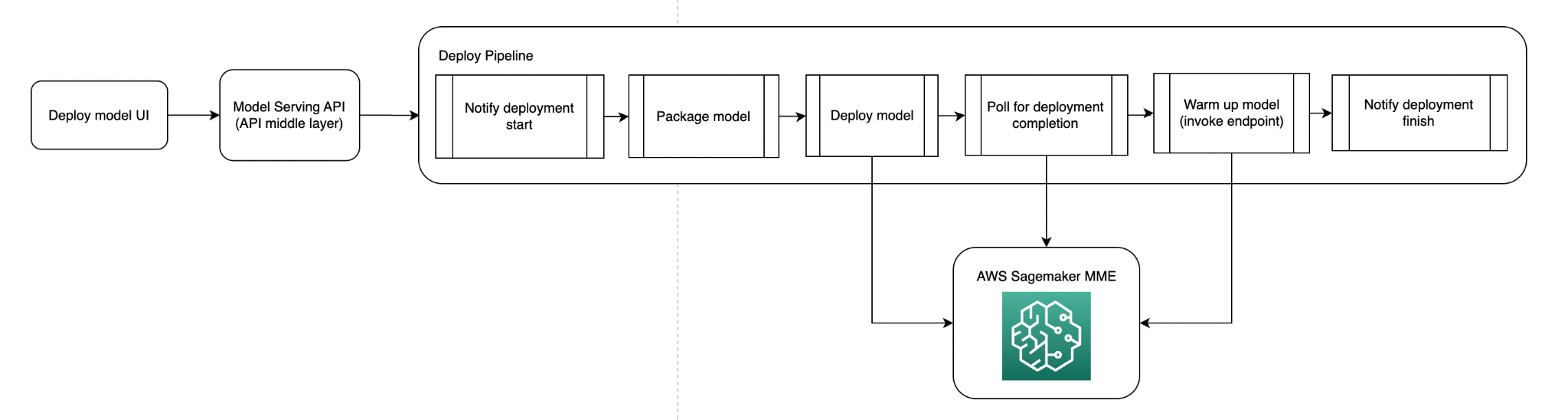
The following diagram illustrates the model warm-up pipeline.

Our existing API layer provides an abstraction for callers to make inference on all of our ML models. This meant we only had to add functionality to the API layer to call the SageMaker MME with the correct target model depending on the inference request, without any changes to the calling code. The SageMaker inference code takes the inference request, formats the Triton inputs defined in our Triton models, and invokes the MMEs using Boto3.
Forethought made significant strides in reducing model hosting costs and mitigating model OOM errors, thanks to the migration to SageMaker MMEs. Before this change, ml.g4dn.xlarge instances running in Amazon EKS. With the transition to MMEs, we discovered it could house 12 embeddings models per instance while achieving 80% GPU memory utilization. This led to a significant decline in our monthly expenses. To put it in perspective, we realized a cost saving of up to 80%. Moreover, to manage higher traffic, we considered scaling up the replicas. Assuming a scenario where we employ three replicas, we found that our cost savings would still be substantial even under these conditions, hovering around 43%.
The journey with SageMaker MMEs has proven financially beneficial, reducing our expenses while ensuring optimal model performance. Previously, our autocomplete language models were deployed in Amazon EKS, necessitating a varying number of ml.g4dn.xlarge instances based on the memory allocation per model. This resulted in a considerable monthly cost. However, with our recent migration to SageMaker MMEs, we’ve been able to reduce these costs substantially. We now host all our models on ml.g4dn.2xlarge instances, giving us the ability to pack models more efficiently. This has significantly trimmed our monthly expenses, and we’ve now realized cost savings in the 66–74% range. This move has demonstrated how efficient resource utilization can lead to significant financial savings using SageMaker MMEs.
In this post, we reviewed how Forethought uses SageMaker multi-model endpoints to decrease cost for real-time inference. SageMaker takes on the undifferentiated heavy lifting, so Forethought can increase engineering efficiency. It also allows Forethought to dramatically lower the cost for real-time inference while maintaining the performance needed for the business-critical operations. By doing so, Forethought is able to provide a differentiated offering for their customers using hyper-personalized models. Use SageMaker MME to host your models at scale and reduce hosting costs by improving endpoint utilization. It also reduces deployment overhead because Amazon SageMaker manages loading models in memory and scaling them based on the traffic patterns to your endpoint. You can find code samples on hosting multiple models using SageMaker MME on GitHub.
 Jad Chamoun is a Director of Core Engineering at Forethought. His team focuses on platform engineering covering Data Engineering, Machine Learning Infrastructure, and Cloud Infrastructure. You can find him on LinkedIn.
Jad Chamoun is a Director of Core Engineering at Forethought. His team focuses on platform engineering covering Data Engineering, Machine Learning Infrastructure, and Cloud Infrastructure. You can find him on LinkedIn.
 Salina Wu is a Sr. Machine Learning Infrastructure engineer at Forethought.ai. She works closely with the Machine Learning team to build and maintain their end-to-end training, serving, and data infrastructures. She is particularly motivated by introducing new ways to improve efficiency and reduce cost across the ML space. When not at work, Salina enjoys surfing, pottery, and being in nature.
Salina Wu is a Sr. Machine Learning Infrastructure engineer at Forethought.ai. She works closely with the Machine Learning team to build and maintain their end-to-end training, serving, and data infrastructures. She is particularly motivated by introducing new ways to improve efficiency and reduce cost across the ML space. When not at work, Salina enjoys surfing, pottery, and being in nature.
 James Park is a Solutions Architect at Amazon Web Services. He works with Amazon.com to design, build, and deploy technology solutions on AWS, and has a particular interest in AI and machine learning. In h is spare time he enjoys seeking out new cultures, new experiences, and staying up to date with the latest technology trends.You can find him on LinkedIn.
James Park is a Solutions Architect at Amazon Web Services. He works with Amazon.com to design, build, and deploy technology solutions on AWS, and has a particular interest in AI and machine learning. In h is spare time he enjoys seeking out new cultures, new experiences, and staying up to date with the latest technology trends.You can find him on LinkedIn.
 Sunil Padmanabhan is a Startup Solutions Architect at AWS. As a former startup founder and CTO, he is passionate about machine learning and focuses on helping startups leverage AI/ML for their business outcomes and design and deploy ML/AI solutions at scale.
Sunil Padmanabhan is a Startup Solutions Architect at AWS. As a former startup founder and CTO, he is passionate about machine learning and focuses on helping startups leverage AI/ML for their business outcomes and design and deploy ML/AI solutions at scale.
 Dhawal Patel is a Principal Machine Learning Architect at AWS. He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing, and Artificial Intelligence. He focuses on Deep learning including NLP and Computer Vision domains. He helps customers achieve high performance model inference on SageMaker.
Dhawal Patel is a Principal Machine Learning Architect at AWS. He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing, and Artificial Intelligence. He focuses on Deep learning including NLP and Computer Vision domains. He helps customers achieve high performance model inference on SageMaker.