

Welcome to Research Focus, a series of blog posts that highlights notable publications, events, code/datasets, new hires and other milestones from across the research community at Microsoft.
NEW RESEARCH
RetroRanker: leveraging reaction changes to improve retrosynthesis prediction through re-ranking
Retrosynthesis is an important task in organic chemistry. It’s designed to propose a list of candidate reactants that are likely to lead to a given product. Recent data-driven approaches to retrosynthesis have achieved promising results. However, they might make predictions based on the training data distribution, a phenomenon known as frequency bias, which can generate lower quality predictions.
In a new paper: RetroRanker: leveraging reaction changes to improve retrosynthesis prediction through re-ranking, researchers from Microsoft and academic colleagues introduce RetroRanker, a ranking model built upon graph neural networks, which is designed to mitigate frequency bias in predictions of existing retrosynthesis models. In order to lower the rankings of chemically unreasonable predictions, RetroRanker incorporates potential reaction changes of each set of predicted reactants in obtaining the given product. The predicted re-ranked results on publicly available retrosynthesis benchmarks show that RetroRanker can improve results on most state-of-the-art models. Preliminary studies also indicate that RetroRanker can enhance the performance of multi-step retrosynthesis.
Spotlight: Microsoft Research Podcast

AI Frontiers: AI for health and the future of research with Peter Lee
Peter Lee, head of Microsoft Research, and Ashley Llorens, AI scientist and engineer, discuss the future of AI research and the potential for GPT-4 as a medical copilot.
NEW RESEARCH
Fine-Tuning Language Models with Advantage-Induced Policy Alignment
Reinforcement learning from human feedback (RLHF) has emerged as a reliable approach to aligning large language models to human preferences. Among the plethora of RLHF techniques, proximal policy optimization (PPO) is one of the most widely used. Yet despite its popularity, PPO may suffer from mode collapse, instability, and poor sample efficiency.
In a new paper: Fine-Tuning Language Models with Advantage-Induced Policy Alignment, researchers from Microsoft show that these issues can be alleviated by a novel algorithm called Advantage-Induced Policy Alignment (APA), which leverages a squared error loss function based on the estimated advantages. This research demonstrates empirically that APA consistently outperforms PPO in language tasks by a large margin, when a separate reward model is employed as the evaluator. In addition, compared with PPO, APA offers a more stable form of control over the deviation from the model’s initial policy, ensuring that the model improves its performance without collapsing to deterministic output. In addition to empirical results, the researchers also provide a theoretical justification supporting the design of their loss function.
NEW RESEARCH
A project-driven distributed energy resource dataset for the U.S. grid
Designing future energy systems to accommodate variable renewable energy and third-party owned devices requires information with high spatial and temporal granularity. Existing public datasets focus on specific resource classes (ex. bulk generators, residential solar, or electric vehicles), and are not useful for informing holistic planning or policy decisions. Further, with the growing presence of distributed energy resources (DERs) located in the distribution grid, datasets and models which focus only on the bulk system will no longer be sufficient.
In a new paper: Towards closing the data gap: A project-driven distributed energy resource dataset for the U.S. Grid, researchers from Microsoft address this modelling need with a project-driven dataset of DERs for the contiguous U.S., generated using only publicly available data. They integrate the resources into a high-resolution test system of the U.S. grid. This model, and the DER dataset, enable planners, operators, and policy makers to pose questions and conduct data-driven analysis of rapid decarbonization pathways for the electricity system. They further pose a set of research questions in their research project database.
NEW RESEARCH
End-to-end Privacy Preserving Training and Inference for Air Pollution Forecasting with Data from Rival Fleets
Privacy-preserving machine learning promises to train machine learning models by combining data spread across multiple data silos. Theoretically, secure multiparty computation (MPC) allows multiple data owners to train models on their joint data without revealing data to each other. However, prior implementations have had limitations affecting accuracy, breadth of supported models, and latency overheads that impact their relevance.
In a new paper: End-to-end Privacy Preserving Training and Inference for Air Pollution Forecasting with Data from Rival Fleets, researchers from Microsoft address the practical problem of secure training and inference of models for urban sensing problems. This includes traffic congestion estimation and air pollution monitoring in large cities, where data can be contributed by rival fleet companies while balancing the latency-accuracy trade-offs using MPC-based techniques.
This work includes a custom ML model that can be efficiently trained with MPC within a desirable latency, and an end-to-end system of private training and inference that provably matches the training accuracy of cleartext ML training. This trained model allows users to make sensitive queries in a privacy-preserving manner while carefully handling potentially invalid queries.
NEW RESEARCH
ASL Citizen – A Community-Sourced Dataset for Advancing Isolated Sign Language Recognition
About 70 million deaf people worldwide use a sign language as their primary language, and at least 71 countries mandate the provision of services in sign language. Nonetheless, most existing information resources (like search engines or news sites) are written, and do not offer equitable access. Intelligent sign language systems could help expand access, but development has been impeded by a severe lack of appropriate data.
To help advance the state of sign language modeling, a team at Microsoft collaborated with colleagues at multiple institutions to create ASL Citizen, the first crowdsourced isolated sign language dataset. It contains about 84,000 videos of 2,700 distinct signs from American Sign Language (ASL), making it the largest isolated sign language recognition (ISLR) dataset available. Unlike prior datasets, it features everyday signers in everyday recording scenarios, and was collected with Deaf community involvement, consent, and compensation. The dataset improves state-of-the-art performance in single-sign recognition from about 30% accuracy to 63% accuracy, over a large vocabulary and tested on participants unseen in training.
This dataset is released alongside a new paper: ASL Citizen: A Community-Sourced Dataset for Advancing Isolated Sign Language Recognition, which reframes ISLR as a dictionary retrieval task and establishes state-of-the-art baselines. Code and a searchable dictionary view of the crowdsourced dataset are also provided.
NEW RESOURCE
MABIM: Multi-agent Benchmark for Inventory Management
Multi-agent reinforcement learning (MARL) empowers multiple agents to accomplish shared objectives through collaboration and competition in specific environments. This approach has applications in diverse fields such as robotics, autonomous driving, gaming, economics, finance, and healthcare. The success of reinforcement learning algorithms depends on a variety of interactive learning environments. These environments enable agents to optimize decision-making strategies across numerous complex scenarios. Despite the emergence of various learning environments in the MARL domain, there remains a shortage of environments that address multiple challenges while offering flexible customization and expansion.
To tackle various MARL challenges, researchers from Microsoft recently released a versatile learning environment: Multi-agent Benchmark for Inventory Management (MABIM). Based on inventory management problems found in operations research, MABIM establishes a MARL benchmark evaluation framework that supports multi-echelon, multi-product inventory networks. This framework allows for the customization of diverse environments, simulating an array of challenging scenarios.
MABIM comprises 51 challenging tasks and includes features such as high operational efficiency, a Gym standard interface, comprehensive strategy visualization tools, and real-data-based capabilities to facilitate MARL research. Initial experiments using MABIM have revealed intriguing findings. For example, as the number of agents increases, the Independent Proximal Policy Optimization (IPPO) algorithm experiences difficulty training and the QTRAN algorithm becomes unstable. IPPO displays short-sighted behavior in resource-limited competitive environments, adopting long-term unprofitable strategies to evade immediate losses. Pure MARL algorithms have difficulty learning effective upstream and downstream strategies in environments that necessitate cooperation. In non-stationary environments, MARL strategies outperform conventional operations research algorithms.
NEW RESEARCH
NUWA-XL: Diffusion over Diffusion for eXtremely Long Video Generation
Recently, visual synthesis has attracted a great deal of interest in the field of generative models. Existing work has demonstrated the ability to generate high-quality images. However, videos in real applications are more challenging than images due to their length. A feature film typically runs more than 90 minutes. Cartoons often run for 30 minutes. Even for short video applications like TikTok, the recommended length is 21 to 34 seconds.
In a recent paper: NUWA-XL: Diffusion over Diffusion for eXtremely Long Video Generation researchers from Microsoft propose a novel architecture for extremely long video generation. Most current work generates long videos segment-by-segment sequentially, which normally leads to the gap between training on short videos and inferring long videos, and the sequential generation is inefficient. Instead, this new approach adopts a coarse-to-fine process, in which the video can be generated in parallel at the same granularity. A global diffusion model is applied to generate the keyframes across the entire time range, and then local diffusion models recursively fill in the content between nearby frames. This simple yet effective strategy allows direct training on long videos to reduce the training-inference gap, and makes it possible to generate all segments in parallel.
The post Research Focus: Week of July 17, 2023 appeared first on Microsoft Research.


 Today we’re publishing information on Google’s AI Red Team for the first time
Today we’re publishing information on Google’s AI Red Team for the first time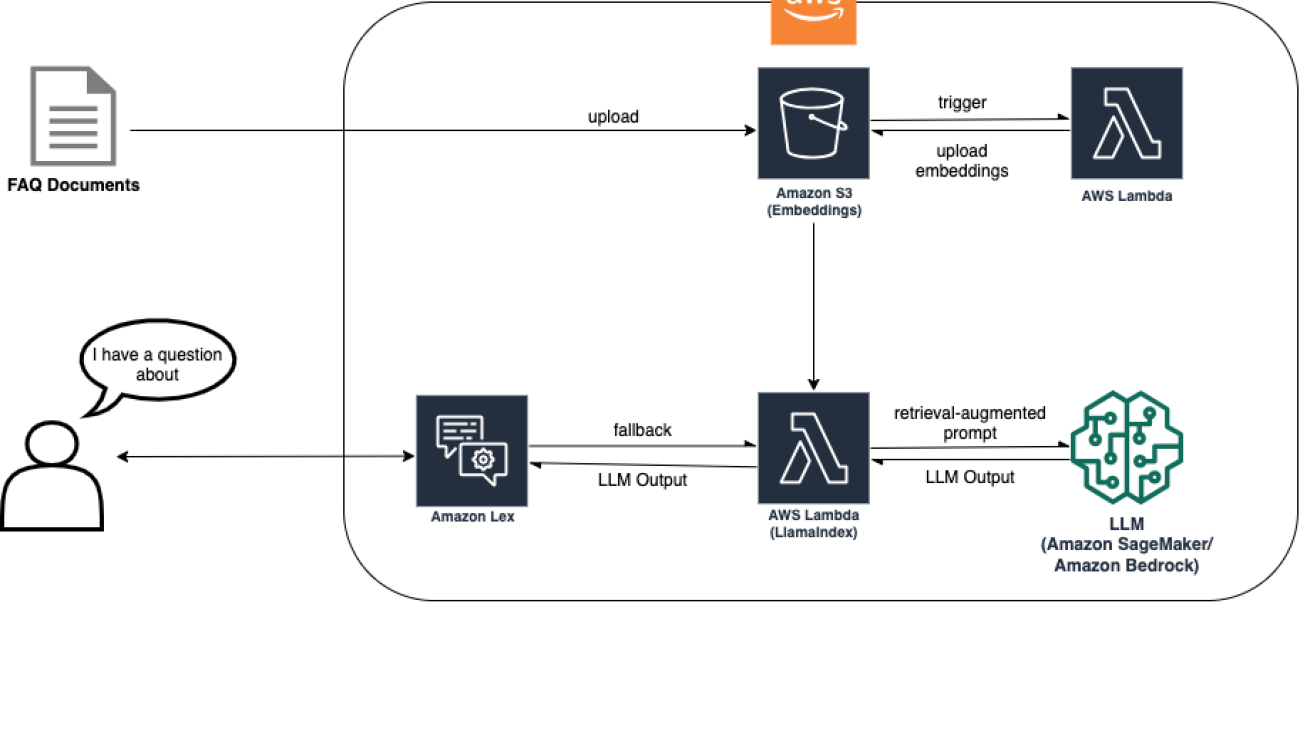
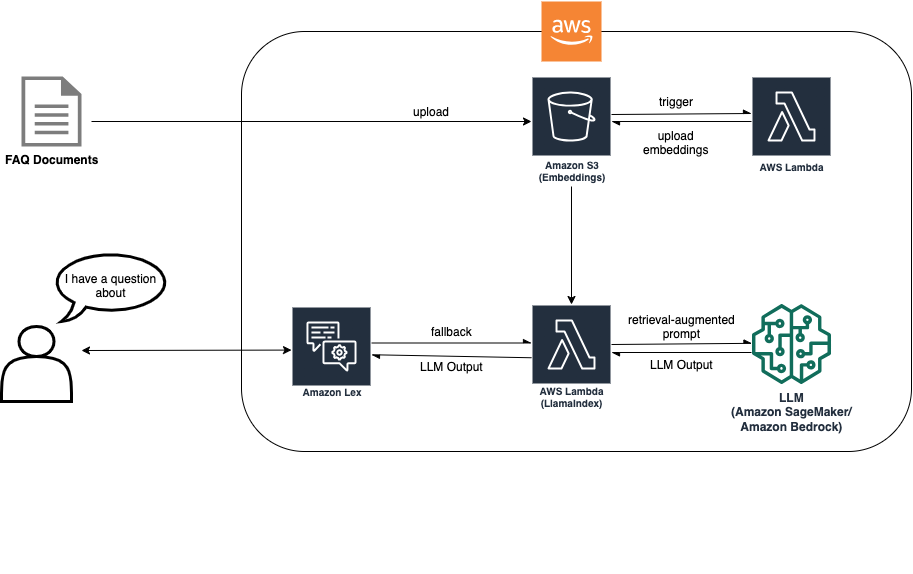

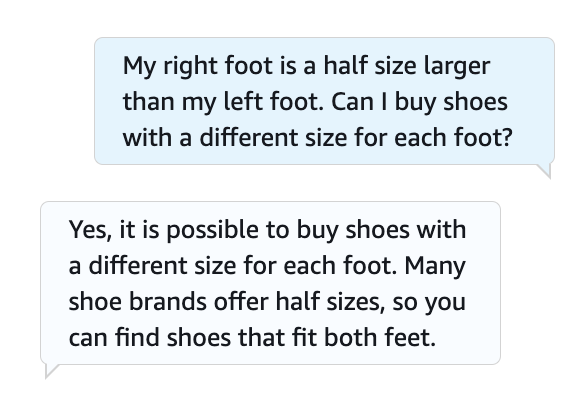
 Max Henkel-Wallace is a Software Development Engineer at AWS Lex. He enjoys working leveraging technology to maximize customer success. Outside of work he is passionate about cooking, spending time with friends, and backpacking.
Max Henkel-Wallace is a Software Development Engineer at AWS Lex. He enjoys working leveraging technology to maximize customer success. Outside of work he is passionate about cooking, spending time with friends, and backpacking. Song Feng is a Senior Applied Scientist at AWS AI Labs, specializing in Natural Language Processing and Artificial Intelligence. Her research explores various aspects of these fields including document-grounded dialogue modeling, reasoning for task-oriented dialogues, and interactive text generation using multimodal data.
Song Feng is a Senior Applied Scientist at AWS AI Labs, specializing in Natural Language Processing and Artificial Intelligence. Her research explores various aspects of these fields including document-grounded dialogue modeling, reasoning for task-oriented dialogues, and interactive text generation using multimodal data. Saket Saurabh is an engineer with AWS Lex team. He works on improving Lex developer experience to help developers build more human-like chat bots. Outside of work, he enjoys traveling, discovering diverse cuisines, and learn about different cultures.
Saket Saurabh is an engineer with AWS Lex team. He works on improving Lex developer experience to help developers build more human-like chat bots. Outside of work, he enjoys traveling, discovering diverse cuisines, and learn about different cultures.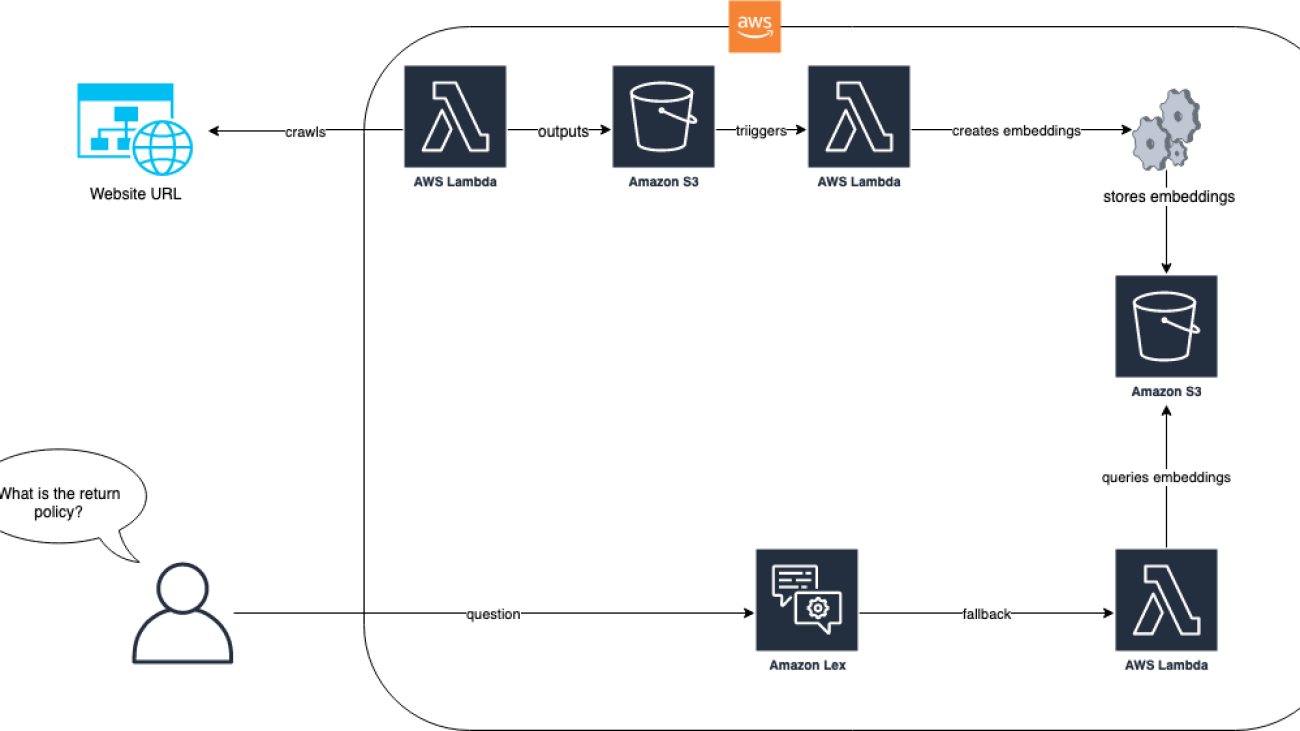


 John Baker is a Principal SDE at AWS where he works on Natural Language Processing, Large Language Models and other ML/AI related projects. He has been with Amazon for 9+ years and has worked across AWS, Alexa and Amazon.com. In his spare time, John enjoys skiing and other outdoor activities throughout the Pacific Northwest.
John Baker is a Principal SDE at AWS where he works on Natural Language Processing, Large Language Models and other ML/AI related projects. He has been with Amazon for 9+ years and has worked across AWS, Alexa and Amazon.com. In his spare time, John enjoys skiing and other outdoor activities throughout the Pacific Northwest.


























 June Won is a product manager with SageMaker JumpStart. He focuses on making foundation models easily discoverable and usable to help customers build generative AI applications. His experience at Amazon also includes mobile shopping application and last mile delivery.
June Won is a product manager with SageMaker JumpStart. He focuses on making foundation models easily discoverable and usable to help customers build generative AI applications. His experience at Amazon also includes mobile shopping application and last mile delivery. Dr. Vivek Madan is an Applied Scientist with the Amazon SageMaker JumpStart team. He got his PhD from University of Illinois at Urbana-Champaign and was a Post Doctoral Researcher at Georgia Tech. He is an active researcher in machine learning and algorithm design and has published papers in EMNLP, ICLR, COLT, FOCS, and SODA conferences.
Dr. Vivek Madan is an Applied Scientist with the Amazon SageMaker JumpStart team. He got his PhD from University of Illinois at Urbana-Champaign and was a Post Doctoral Researcher at Georgia Tech. He is an active researcher in machine learning and algorithm design and has published papers in EMNLP, ICLR, COLT, FOCS, and SODA conferences. Dr. Kyle Ulrich is an Applied Scientist with the Amazon SageMaker JumpStart team. His research interests include scalable machine learning algorithms, computer vision, time series, Bayesian non-parametrics, and Gaussian processes. His PhD is from Duke University and he has published papers in NeurIPS, Cell, and Neuron.
Dr. Kyle Ulrich is an Applied Scientist with the Amazon SageMaker JumpStart team. His research interests include scalable machine learning algorithms, computer vision, time series, Bayesian non-parametrics, and Gaussian processes. His PhD is from Duke University and he has published papers in NeurIPS, Cell, and Neuron. Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker JumpStart and helps develop machine learning algorithms. He got his PhD from University of Illinois Urbana-Champaign. He is an active researcher in machine learning and statistical inference, and has published many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.
Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker JumpStart and helps develop machine learning algorithms. He got his PhD from University of Illinois Urbana-Champaign. He is an active researcher in machine learning and statistical inference, and has published many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences. Sundar Ranganathan is the Global Head of GenAI/Frameworks GTM Specialists at AWS. He focuses on developing GTM strategy for large language models, GenAI, and large-scale ML workloads across AWS services like Amazon EC2, EKS, EFA, AWS Batch, and Amazon SageMaker. His experience includes leadership roles in product management and product development at NetApp, Micron Technology, Qualcomm, and Mentor Graphics.
Sundar Ranganathan is the Global Head of GenAI/Frameworks GTM Specialists at AWS. He focuses on developing GTM strategy for large language models, GenAI, and large-scale ML workloads across AWS services like Amazon EC2, EKS, EFA, AWS Batch, and Amazon SageMaker. His experience includes leadership roles in product management and product development at NetApp, Micron Technology, Qualcomm, and Mentor Graphics.