Building foundation models (FMs) requires building, maintaining, and optimizing large clusters to train models with tens to hundreds of billions of parameters on vast amounts of data. Creating a resilient environment that can handle failures and environmental changes without losing days or weeks of model training progress is an operational challenge that requires you to implement cluster scaling, proactive health monitoring, job checkpointing, and capabilities to automatically resume training should failures or issues arise.
We are excited to share that Amazon SageMaker HyperPod is now generally available to enable training foundation models with thousands of accelerators up to 40% faster by providing a highly resilient training environment while eliminating the undifferentiated heavy lifting involved in operating large-scale training clusters. With SageMaker HyperPod, machine learning (ML) practitioners can train FMs for weeks and months without disruption, and without having to deal with hardware failure issues.
Customers such as Stability AI use SageMaker HyperPod to train their foundation models, including Stable Diffusion.
“As the leading open source generative AI company, our goal is to maximize the accessibility of modern AI. We are building foundation models with tens of billions of parameters, which require the infrastructure to scale training performance optimally. With SageMaker HyperPod’s managed infrastructure and optimization libraries, we can reduce training time and costs by over 50%. It makes our model training more resilient and performant to build state-of-the-art models faster.”
– Emad Mostaque, Stability AI Founder and CEO.
To make the full cycle of developing FMs resilient to hardware failures, SageMaker HyperPod helps you create clusters, monitor cluster health, repair and replace faulty nodes on the fly, save frequent checkpoints, and automatically resume training without losing progress. In addition, SageMaker HyperPod is preconfigured with Amazon SageMaker distributed training libraries, including the SageMaker data parallelism library (SMDDP) and SageMaker model parallelism library (SMP), to improve FM training performance by making it straightforward to split training data and models into smaller chunks and processing them in parallel across the cluster nodes, while fully utilizing the cluster’s compute and network infrastructure. SageMaker HyperPod integrates the Slurm Workload Manager for cluster and training job orchestration.
Slurm Workload Manager overview
Slurm, formerly known as the Simple Linux Utility for Resource Management, is a job scheduler for running jobs on a distributed computing cluster. It also provides a framework for running parallel jobs using the NVIDIA Collective Communications Library (NCCL) or Message Passing Interface (MPI) standards. Slurm is a popular open source cluster resource management system used widely by high performance computing (HPC) and generative AI and FM training workloads. SageMaker HyperPod provides a straightforward way to get up and running with a Slurm cluster in a matter of minutes.
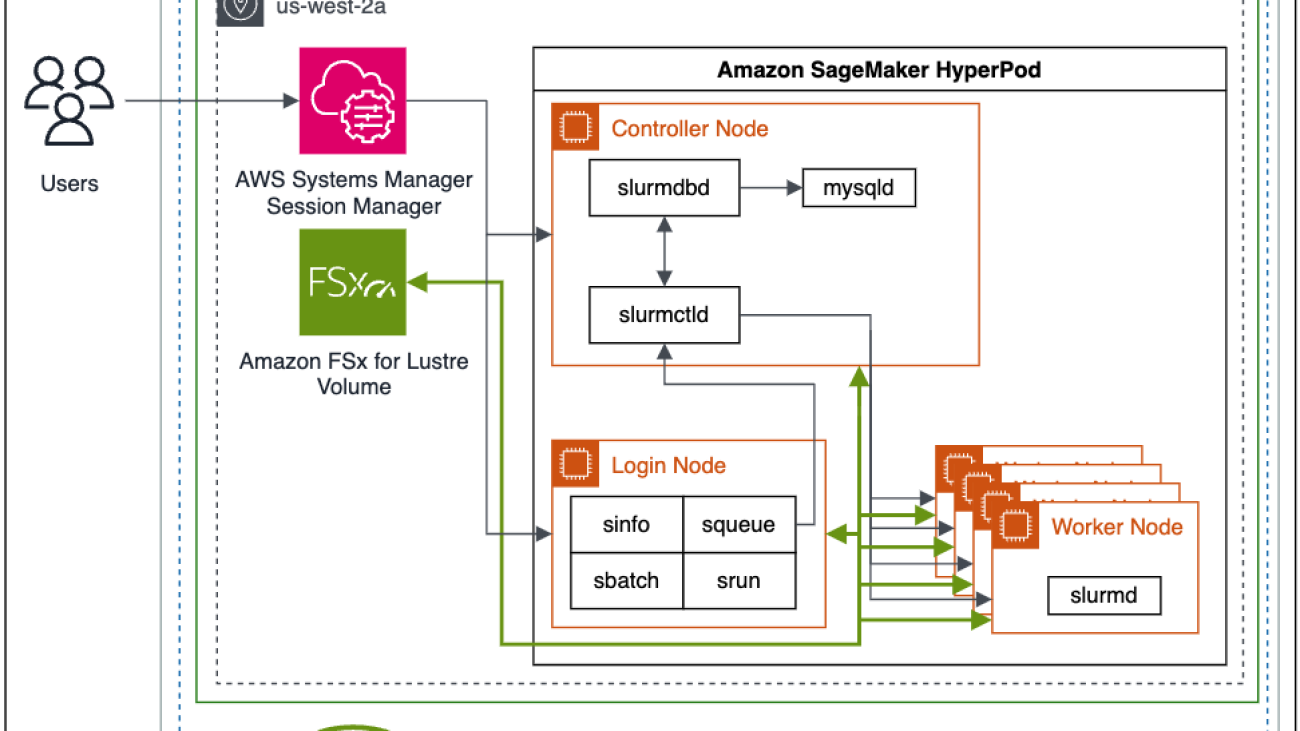
The following is a high-level architectural diagram of how users interact with SageMaker HyperPod and how the various cluster components interact with each other and other AWS services, such as Amazon FSx for Lustre and Amazon Simple Storage Service (Amazon S3).

Slurm jobs are submitted by commands on the command line. The commands to run Slurm jobs are srun and sbatch. The srun command runs the training job in interactive and blocking mode, and sbatch runs in batch processing and non-blocking mode. srun is mostly used to run immediate jobs, while sbatch can be used for later runs of jobs.
For information on additional Slurm commands and configuration, refer to the Slurm Workload Manager documentation.
Auto-resume and healing capabilities
One of the new features with SageMaker HyperPod is the ability to have auto-resume on your jobs. Previously, when a worker node failed during a training or fine-tuning job run, it was up to the user to check on the job status, restart the job from the latest checkpoint, and continue to monitor the job throughout the entire run. With training jobs or fine-tuning jobs needing to run for days, weeks, or even months at a time, this becomes costly due to the extra administrative overhead of the user needing to spend cycles to monitor and maintain the job in the event that a node crashes, as well as the cost of idle time of expensive accelerated compute instances.
SageMaker HyperPod addresses job resiliency by using automated health checks, node replacement, and job recovery. Slurm jobs in SageMaker HyperPod are monitored using a SageMaker custom Slurm plugin using the SPANK framework. When a training job fails, SageMaker HyperPod will inspect the cluster health through a suite of health checks. If a faulty node is found in the cluster, the SageMaker HyperPod will automatically remove the node from the cluster, replace it with a healthy node, and restart the training job. When using checkpointing in training jobs, any interrupted or failed job can resume from the latest checkpoint.
Solution overview
To deploy your SageMaker HyperPod, you first prepare your environment by configuring your Amazon Virtual Private Cloud (Amazon VPC) network and security groups, deploying supporting services such as FSx for Lustre in your VPC, and publishing your Slurm lifecycle scripts to an S3 bucket. You then deploy and configure your SageMaker HyperPod and connect to the head node to start your training jobs.
Prerequisites
Before you create your SageMaker HyperPod, you first need to configure your VPC, create an FSx for Lustre file system, and establish an S3 bucket with your desired cluster lifecycle scripts. You also need the latest version of the AWS Command Line Interface (AWS CLI) and the CLI plugin installed for AWS Session Manager, a capability of AWS Systems Manager.
SageMaker HyperPod is fully integrated with your VPC. For information about creating a new VPC, see Create a default VPC or Create a VPC. To allow a seamless connection with the highest performance between resources, you should create all your resources in the same Region and Availability Zone, as well as ensure the associated security group rules allow connection between cluster resources.
Next, you create an FSx for Lustre file system. This will serve as the high-performance file system for use throughout our model training. Make sure that the FSx for Lustre and cluster security groups allows inbound and outbound communication between cluster resources and the FSx for Lustre file system.
To set up your cluster lifecycle scripts, which are run when events such as a new cluster instance occur, you create an S3 bucket and then copy and optionally customize the default lifecycle scripts. For this example, we store all the lifecycle scripts in a bucket prefix of lifecycle-scripts.
First, you download the sample lifecycle scripts from the GitHub repo. You should customize these to suit your desired cluster behaviors.
Next, create an S3 bucket to store the customized lifecycle scripts.
Next, copy the default lifecycle scripts from your local directory to your desired bucket and prefix using aws s3 sync:
Finally, to set up the client for simplified connection to the cluster’s head node, you should install or update the AWS CLI and install the AWS Session Manager CLI plugin to allow interactive terminal connections to administer the cluster and run training jobs.
You can create a SageMaker HyperPod cluster with either available on-demand resources or by requesting a capacity reservation with SageMaker. To create a capacity reservation, you create a quota increase request to reserve specific compute instance types and capacity allocation on the Service Quotas dashboard.
Set up your training cluster
To create your SageMaker HyperPod cluster, complete the following steps:
- On the SageMaker console, choose Cluster management under HyperPod Clusters in the navigation pane.
- Choose Create a cluster.

- Provider a cluster name and optionally any tags to apply to cluster resources, then choose Next.
- Select Create instance group and specify the instance group name, instance type needed, quantity of instances desired, and the S3 bucket and prefix path where you copied your cluster lifecycle scripts previously.
It’s recommended to have different instance groups for the controller nodes used to administer the cluster and submit jobs and the worker nodes used to run training jobs using accelerated compute instances. You can optionally configure an additional instance group for login nodes.
- You first create the controller instance group, which will include the cluster head node.
- For this instance group’s AWS Identity and Access Management (IAM) role, choose Create a new role and specify any S3 buckets you would like the cluster instances in the instance group to have access to.
The generated role will be granted read-only access to the specified buckets by default.
- Choose Create role.
- Enter the script name to be run on each instance creation in the on-create script prompt. In this example, the on-create script is called
on_create.sh.
- Choose Save.
- Choose Create instance group to create your worker instance group.
- Provide all the requested details, including instance type and quantity desired.
This example uses four ml.trn1.32xl accelerated instances to perform our training job. You can use the same IAM role as before or customize the role for the worker instances. Similarly, you can use different on-create lifecycle scripts for this worker instance group than the previous instance group.

- Choose Next to proceed.
- Choose the desired VPC, subnet, and security groups for your cluster instances.
We host the cluster instances in a single Availability Zone and subnet to ensure low latency.
Note that if you’ll be accessing S3 data frequently, it’s recommended to create a VPC endpoint that is associated with the private subnet’s routing table to reduce any potential data transfer costs.
- Choose Next.

- Review the cluster details summary, then choose Submit.
Alternatively, to create your SageMaker HyperPod using the AWS CLI, first customize the JSON parameters used to create the cluster:
Then use the following command to create the cluster using the provided inputs:
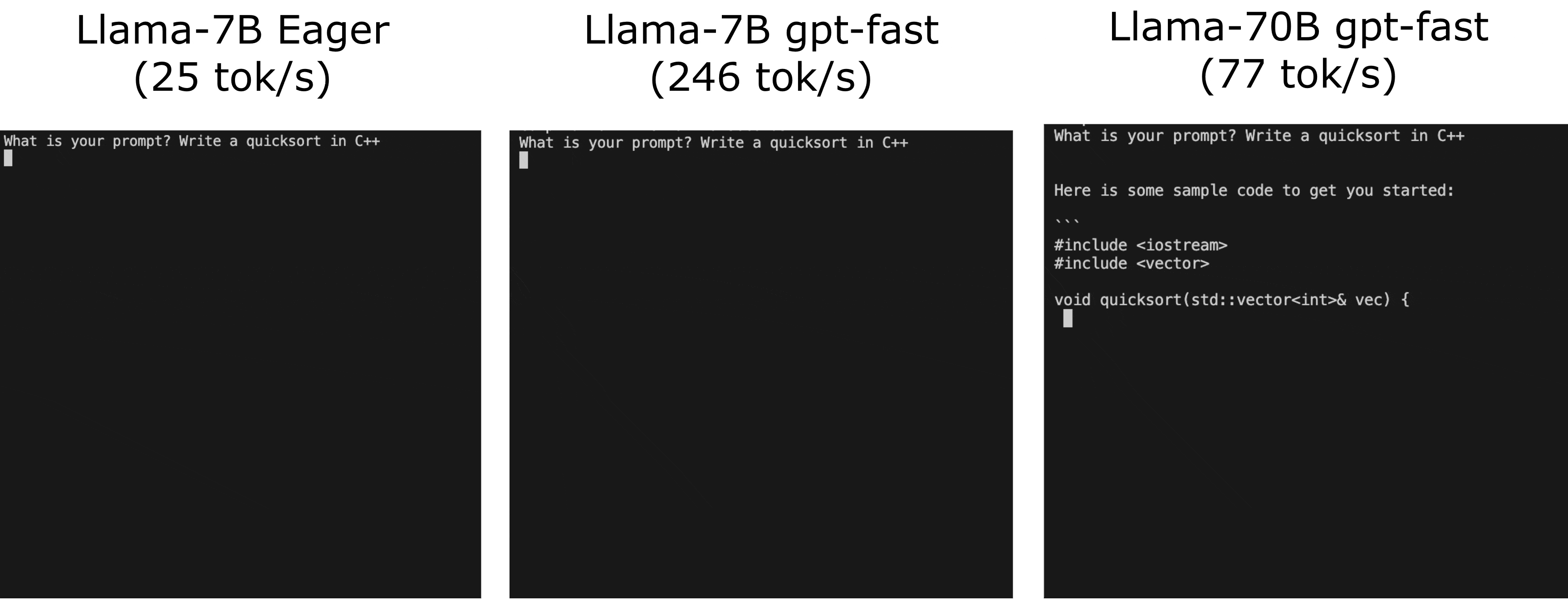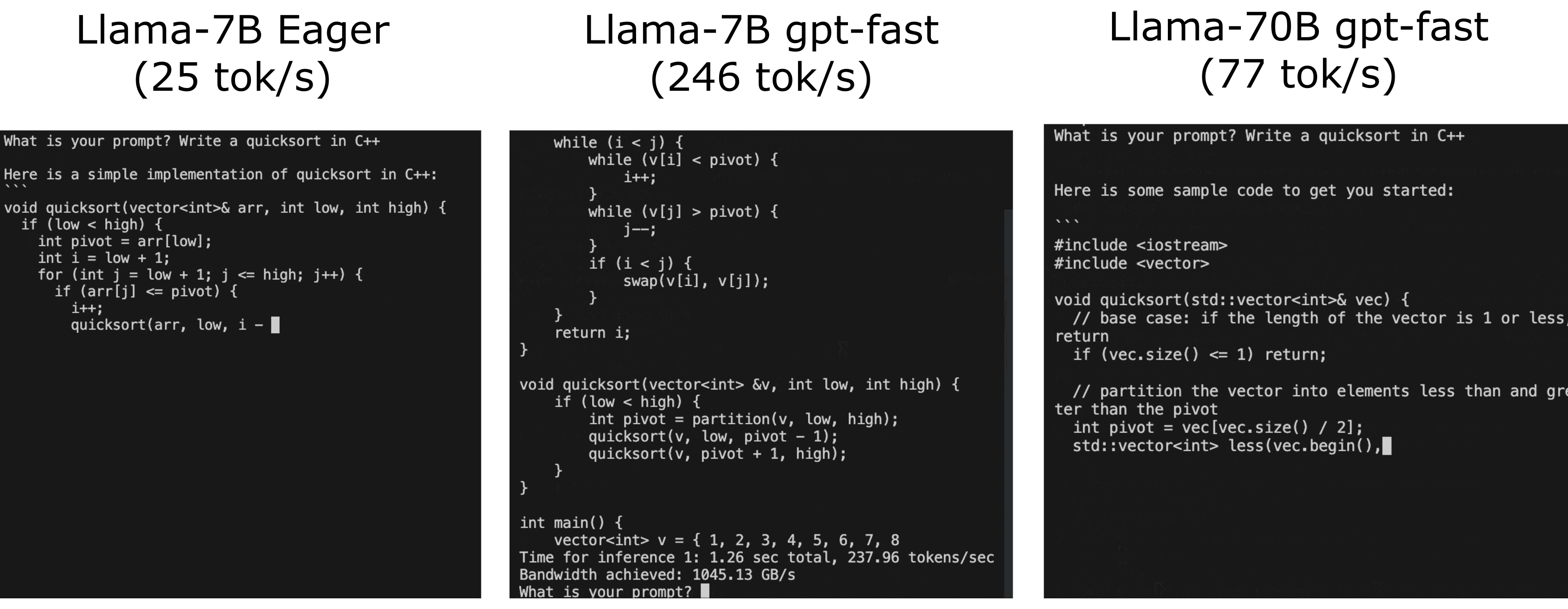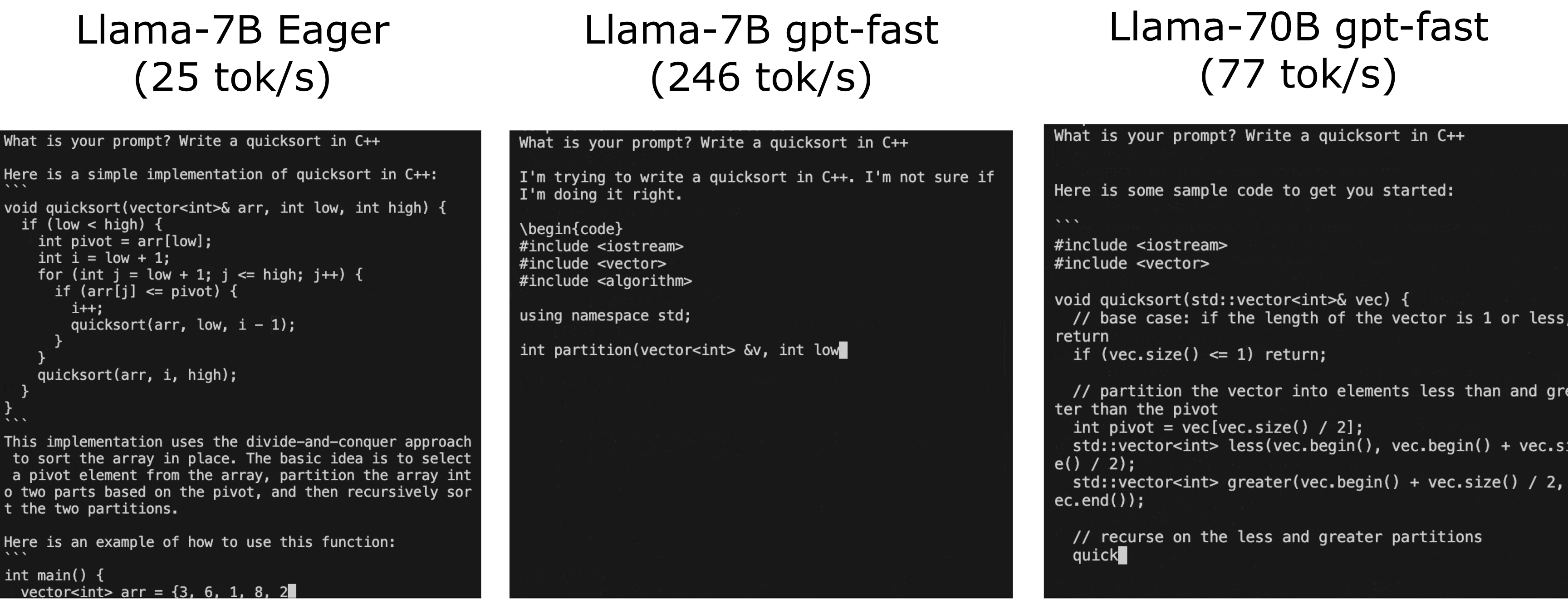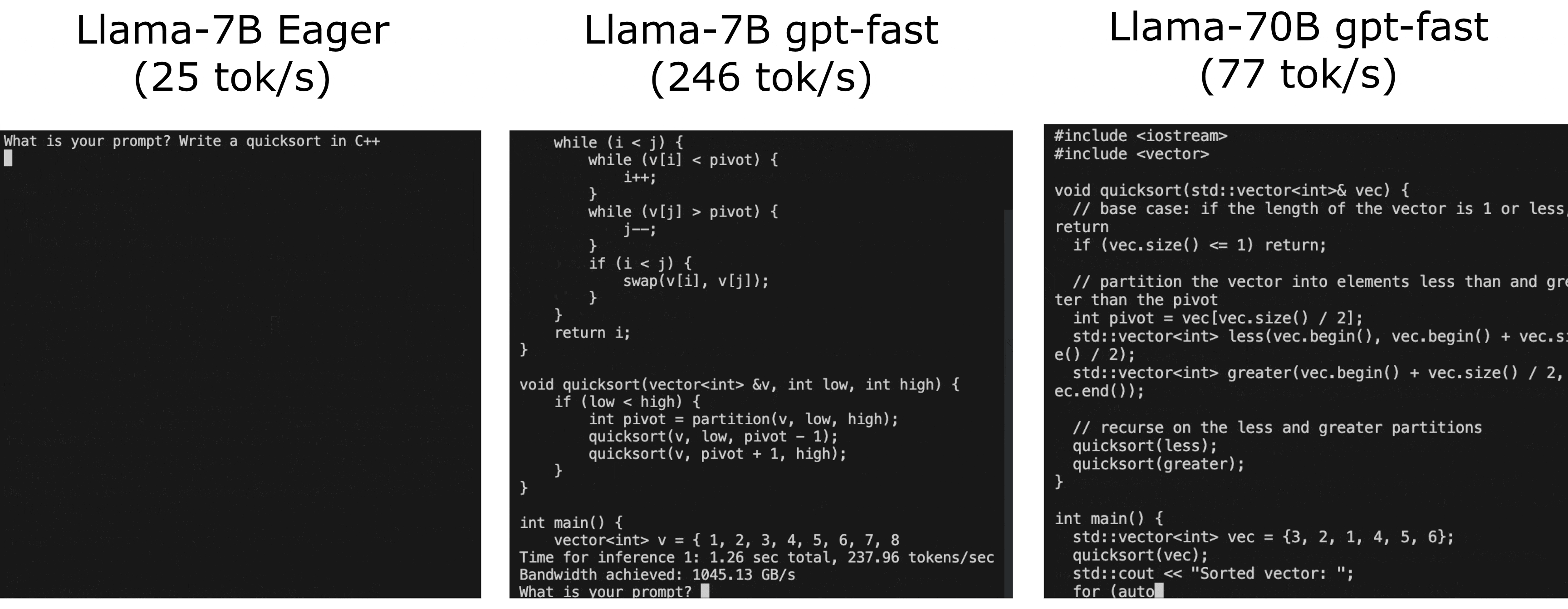
Run your first training job with Llama 2
Note that use of the Llama 2 model is governed by the Meta license. To download the model weights and tokenizer, visit the website and accept the license before requesting access on Meta’s Hugging Face website.
After the cluster is running, login with Session Manager using the cluster id, instance group name, and instance id. Use the following command to view your cluster details:
Make note of the cluster ID included within the cluster ARN in the response.
Use the following command to retrieve the instance group name and instance ID needed to login to the cluster.
Make note of the InstanceGroupName and the InstanceId in the response as these will be used to connect to the instance with Session Manager.
Now you use Session Manager to log in to the head node, or one of the login nodes, and run your training job:
Next, we’re going to prepare the environment and download Llama 2 and the RedPajama dataset. For full code and a step-by-step walkthrough of this, follow the instructions on the AWSome Distributed Training GitHub repo.
Follow the steps detailed in the 2.test_cases/8.neuronx-nemo-megatron/README.md file. After following the steps to prepare the environment, prepare the model, download and tokenize the dataset, and pre-compile the model, you should edit the 6.pretrain-model.sh script and the sbatch job submission command to include a parameter that will allow you to take advantage of the auto-resume feature of SageMaker HyperPod.
Edit the sbatch line to look like the following:
After submitting the job, you will get a JobID that you can use to check the job status using the following code:
Additionally, you can monitor the job by following the job output log using the following code:
Clean up
To delete your SageMaker HyperPod cluster, either use the SageMaker console or the following AWS CLI command:
Conclusion
This post showed you how to prepare your AWS environment, deploy your first SageMaker HyperPod cluster, and train a 7-billion parameter Llama 2 model. SageMaker HyperPod is generally available today in the Americas (N. Virginia, Ohio, and Oregon), Asia Pacific (Singapore, Sydney, and Tokyo), and Europe (Frankfurt, Ireland, and Stockholm) Regions. They can be deployed via the SageMaker console, AWS CLI, and AWS SDKs, and they support the p4d, p4de, p5, trn1, inf2, g5, c5, c5n, m5, and t3 instance families.
To learn more about SageMaker HyperPod, visit Amazon SageMaker HyperPod.
About the authors
 Brad Doran is a Senior Technical Account Manager at Amazon Web Services, focused on generative AI. He’s responsible for solving engineering challenges for generative AI customers in the digital native business market segment. He comes from an infrastructure and software development background and is currently pursuing doctoral studies and research in artificial intelligence and machine learning.
Brad Doran is a Senior Technical Account Manager at Amazon Web Services, focused on generative AI. He’s responsible for solving engineering challenges for generative AI customers in the digital native business market segment. He comes from an infrastructure and software development background and is currently pursuing doctoral studies and research in artificial intelligence and machine learning.
 Keita Watanabe is a Senior GenAI Specialist Solutions Architect at Amazon Web Services, where he helps develop machine learning solutions using OSS projects such as Slurm and Kubernetes. His background is in machine learning research and development. Prior to joining AWS, Keita worked in the ecommerce industry as a research scientist developing image retrieval systems for product search. Keita holds a PhD in Science from the University of Tokyo.
Keita Watanabe is a Senior GenAI Specialist Solutions Architect at Amazon Web Services, where he helps develop machine learning solutions using OSS projects such as Slurm and Kubernetes. His background is in machine learning research and development. Prior to joining AWS, Keita worked in the ecommerce industry as a research scientist developing image retrieval systems for product search. Keita holds a PhD in Science from the University of Tokyo.
 Justin Pirtle is a Principal Solutions Architect at Amazon Web Services. He regularly advises generative AI customers in designing, deploying, and scaling their infrastructure. He is a regular speaker at AWS conferences, including re:Invent, as well as other AWS events. Justin holds a bachelor’s degree in Management Information Systems from the University of Texas at Austin and a master’s degree in Software Engineering from Seattle University.
Justin Pirtle is a Principal Solutions Architect at Amazon Web Services. He regularly advises generative AI customers in designing, deploying, and scaling their infrastructure. He is a regular speaker at AWS conferences, including re:Invent, as well as other AWS events. Justin holds a bachelor’s degree in Management Information Systems from the University of Texas at Austin and a master’s degree in Software Engineering from Seattle University.










 Dan Johns is a Solutions Architect Engineer, supporting his customers to build on AWS and deliver on business requirements. Away from professional life, he loves reading, spending time with his family and automating tasks within their home.
Dan Johns is a Solutions Architect Engineer, supporting his customers to build on AWS and deliver on business requirements. Away from professional life, he loves reading, spending time with his family and automating tasks within their home.
 Ram Vegiraju is a ML Architect with the SageMaker Service team. He focuses on helping customers build and optimize their AI/ML solutions on Amazon SageMaker. In his spare time, he loves traveling and writing.
Ram Vegiraju is a ML Architect with the SageMaker Service team. He focuses on helping customers build and optimize their AI/ML solutions on Amazon SageMaker. In his spare time, he loves traveling and writing. Tomer Shenhar is a Product Manager at AWS. He specializes in responsible AI, driven by a passion to develop ethically sound and transparent AI solutions
Tomer Shenhar is a Product Manager at AWS. He specializes in responsible AI, driven by a passion to develop ethically sound and transparent AI solutions
 Michael Diamond is the head of product for SageMaker Clarify. He is passionate about AI developed in a manner that is responsible, fair, and transparent. When not working, he loves biking and basketball.
Michael Diamond is the head of product for SageMaker Clarify. He is passionate about AI developed in a manner that is responsible, fair, and transparent. When not working, he loves biking and basketball.



 NVIDIA GeForce NOW (@NVIDIAGFN)
NVIDIA GeForce NOW (@NVIDIAGFN) 






























 Dr. Changsha Ma is an AI/ML Specialist at AWS. She is a technologist with a PhD in Computer Science, a master’s degree in Education Psychology, and years of experience in data science and independent consulting in AI/ML. She is passionate about researching methodological approaches for machine and human intelligence. Outside of work, she loves hiking, cooking, hunting food, and spending time with friends and families.
Dr. Changsha Ma is an AI/ML Specialist at AWS. She is a technologist with a PhD in Computer Science, a master’s degree in Education Psychology, and years of experience in data science and independent consulting in AI/ML. She is passionate about researching methodological approaches for machine and human intelligence. Outside of work, she loves hiking, cooking, hunting food, and spending time with friends and families. Ajjay Govindaram is a Senior Solutions Architect at AWS. He works with strategic customers who are using AI/ML to solve complex business problems. His experience lies in providing technical direction as well as design assistance for modest to large-scale AI/ML application deployments. His knowledge ranges from application architecture to big data, analytics, and machine learning. He enjoys listening to music while resting, experiencing the outdoors, and spending time with his loved ones.
Ajjay Govindaram is a Senior Solutions Architect at AWS. He works with strategic customers who are using AI/ML to solve complex business problems. His experience lies in providing technical direction as well as design assistance for modest to large-scale AI/ML application deployments. His knowledge ranges from application architecture to big data, analytics, and machine learning. He enjoys listening to music while resting, experiencing the outdoors, and spending time with his loved ones. Huong Nguyen is a Sr. Product Manager at AWS. She is leading the ML data preparation for SageMaker Canvas and SageMaker Data Wrangler, with 15 years of experience building customer-centric and data-driven products.
Huong Nguyen is a Sr. Product Manager at AWS. She is leading the ML data preparation for SageMaker Canvas and SageMaker Data Wrangler, with 15 years of experience building customer-centric and data-driven products.













 Dr. Sokratis Kartakis is a Principal Machine Learning and Operations Specialist Solutions Architect for Amazon Web Services. Sokratis focuses on enabling enterprise customers to industrialize their Machine Learning (ML) and generative AI solutions by exploiting AWS services and shaping their operating model, i.e. MLOps/FMOps/LLMOps foundations, and transformation roadmap leveraging best development practices. He has spent 15+ years on inventing, designing, leading, and implementing innovative end-to-end production-level ML and AI solutions in the domains of energy, retail, health, finance, motorsports etc.
Dr. Sokratis Kartakis is a Principal Machine Learning and Operations Specialist Solutions Architect for Amazon Web Services. Sokratis focuses on enabling enterprise customers to industrialize their Machine Learning (ML) and generative AI solutions by exploiting AWS services and shaping their operating model, i.e. MLOps/FMOps/LLMOps foundations, and transformation roadmap leveraging best development practices. He has spent 15+ years on inventing, designing, leading, and implementing innovative end-to-end production-level ML and AI solutions in the domains of energy, retail, health, finance, motorsports etc. Jagdeep Singh Soni is a Senior Partner Solutions Architect at AWS based in Netherlands. He uses his passion for DevOps, GenAI and builder tools to help both system integrators and technology partners. Jagdeep applies his application development and architecture background to drive innovation within his team and promote new technologies.
Jagdeep Singh Soni is a Senior Partner Solutions Architect at AWS based in Netherlands. He uses his passion for DevOps, GenAI and builder tools to help both system integrators and technology partners. Jagdeep applies his application development and architecture background to drive innovation within his team and promote new technologies. Dr. Riccardo Gatti is a Senior Startup Solution Architect based in Italy. He is a technical advisor for customers, helping them growing their business by selecting the right tools and technologies to innovate, scale fast and go global in minutes. He has always been passionate about machine learning and generative AI, having studied and applied these technologies across different domains throughout his working career. He is host and editor for the AWS Italian podcast “Casa Startup”, dedicated to stories of startup founders and new technological trends.
Dr. Riccardo Gatti is a Senior Startup Solution Architect based in Italy. He is a technical advisor for customers, helping them growing their business by selecting the right tools and technologies to innovate, scale fast and go global in minutes. He has always been passionate about machine learning and generative AI, having studied and applied these technologies across different domains throughout his working career. He is host and editor for the AWS Italian podcast “Casa Startup”, dedicated to stories of startup founders and new technological trends.



 K Lokesh Kumar Reddy is a Senior engineer in the Amazon Applied AI team. He is focused on efficient ML training techniques and building tools to improve conversational AI systems. In his spare time he enjoys seeking out new cultures, new experiences, and staying up to date with the latest technology trends.
K Lokesh Kumar Reddy is a Senior engineer in the Amazon Applied AI team. He is focused on efficient ML training techniques and building tools to improve conversational AI systems. In his spare time he enjoys seeking out new cultures, new experiences, and staying up to date with the latest technology trends. Abhishek Dan is a senior Dev Manager in the Amazon Applied AI team and works on machine learning and conversational AI systems. He is passionate about AI technologies and works in the intersection of Science and Engineering in advancing the capabilities of AI systems to create more intuitive and seamless human-computer interactions. He is currently building applications on large language models to drive efficiency and CX improvements for Amazon.
Abhishek Dan is a senior Dev Manager in the Amazon Applied AI team and works on machine learning and conversational AI systems. He is passionate about AI technologies and works in the intersection of Science and Engineering in advancing the capabilities of AI systems to create more intuitive and seamless human-computer interactions. He is currently building applications on large language models to drive efficiency and CX improvements for Amazon.