
Artificial intelligence (AI) is a rapidly evolving field with the potential to improve and transform many aspects of society. In 2023, the pace of adoption of AI technologies has accelerated further with the development of powerful foundation models (FMs) and a resulting advancement in generative AI capabilities.
At Amazon, we have launched multiple generative AI services, such as Amazon Bedrock and Amazon CodeWhisperer, and have made a range of highly capable generative models available through Amazon SageMaker JumpStart. These services are designed to support our customers in unlocking the emerging capabilities of generative AI, including enhanced creativity, personalized and dynamic content creation, and innovative design. They can also enable AI practitioners to make sense of the world as never before—addressing language barriers, climate change, accelerating scientific discoveries, and more.
To realize the full potential of generative AI, however, it’s important to carefully reflect on any potential risks. First and foremost, this benefits the stakeholders of the AI system by promoting responsible and safe development and deployment, and by encouraging the adoption of proactive measures to address potential impact. Consequently, establishing mechanisms to assess and manage risk is an important process for AI practitioners to consider and has become a core component of many emerging AI industry standards (for example, ISO 42001, ISO 23894, and NIST RMF) and legislation (such as EU AI Act).
In this post, we discuss how to assess the potential risk of your AI system.
What are the different levels of risk?
While it might be easier to start looking at an individual machine learning (ML) model and the associated risks in isolation, it’s important to consider the details of the specific application of such a model and the corresponding use case as part of a complete AI system. In fact, a typical AI system is likely to be based on multiple different ML models working together, and an organization might be looking to build multiple different AI systems. Consequently, risks can be evaluated for each use case and at different levels, namely model risk, AI system risk, and enterprise risk.
Enterprise risk encompasses the broad spectrum of risks that an organization may face, including financial, operational, and strategic risks. AI system risk focuses on the impact associated with the implementation and operation of AI systems, whereas ML model risk pertains specifically to the vulnerabilities and uncertainties inherent in ML models.
In this post, we focus on AI system risk, primarily. However, it’s important to note that all different levels of risk management within an organization should be considered and aligned.
How is AI system risk defined?
Risk management in the context of an AI system can be a path to minimize the effect of uncertainty or potential negative impacts, while also providing opportunities to maximize positive impacts. Risk itself is not a potential harm but the effect of uncertainty on objectives. According to the NIST Risk Management Framework (NIST RMF), risk can be estimated as a multiplicative measure of an event’s probability of occurring timed by the magnitudes of the consequences of the corresponding event.

There are two aspects to risk: inherent risk and residual risk. Inherent risk represents the amount of risk the AI system exhibits in absence of mitigations or controls. Residual risk captures the remaining risks after factoring in mitigation strategies.
Always keep in mind that risk assessment is a human-centric activity that requires organization-wide efforts; these efforts range from ensuring all relevant stakeholders are included in the assessment process (such as product, engineering, science, sales, and security teams) to assessing how social perspectives and norms influence the perceived likelihood and consequences of certain events.
Why should your organization care about risk evaluation?
Establishing risk management frameworks for AI systems can benefit society at large by promoting the safe and responsible design, development and operation of AI systems. Risk management frameworks can also benefit organizations through the following:
- Improved decision-making – By understanding the risks associated with AI systems, organizations can make better decisions about how to mitigate those risks and use AI systems in a safe and responsible manner
- Increased compliance planning – A risk assessment framework can help organizations prepare for risk assessment requirements in relevant laws and regulations
- Building trust – By demonstrating that they are taking steps to mitigate the risks of AI systems, organizations can show their customers and stakeholders that they are committed to using AI in a safe and responsible manner
How to assess risk?

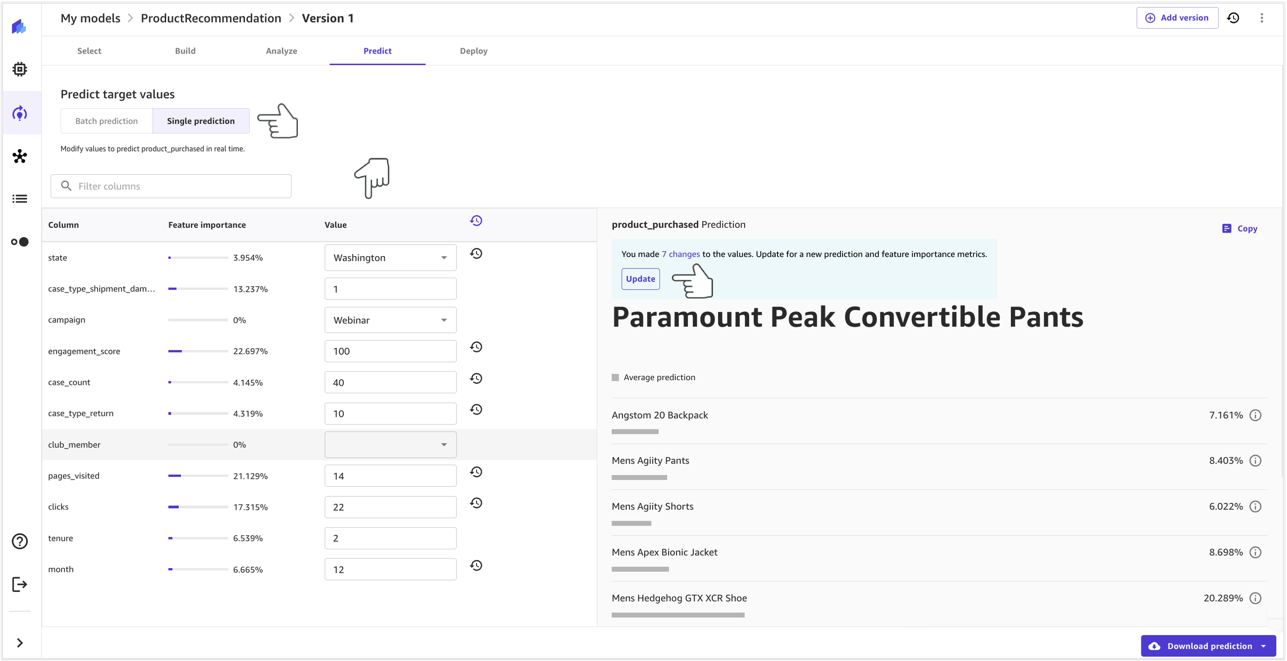
As a first step, an organization should consider describing the AI use case that needs to be assessed and identify all relevant stakeholders. A use case is a specific scenario or situation that describes how users interact with an AI system to achieve a particular goal. When creating a use case description, it can be helpful to specify the business problem being solved, list the stakeholders involved, characterize the workflow, and provide details regarding key inputs and outputs of the system.
When it comes to stakeholders, it’s easy to overlook some. The following figure is a good starting point to map out AI stakeholder roles.
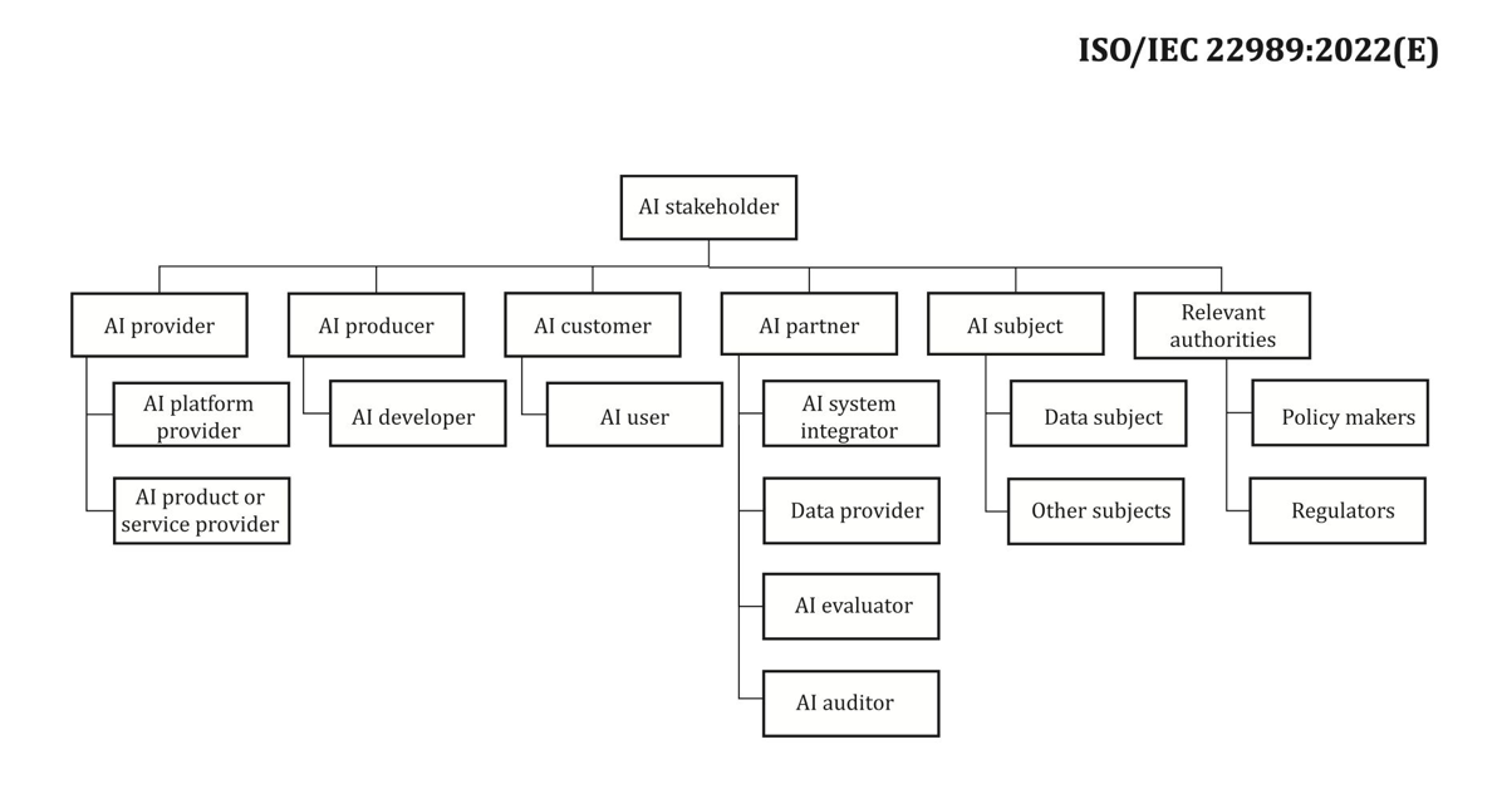
Source: “Information technology – Artificial intelligence – Artificial intelligence concepts and terminology”.
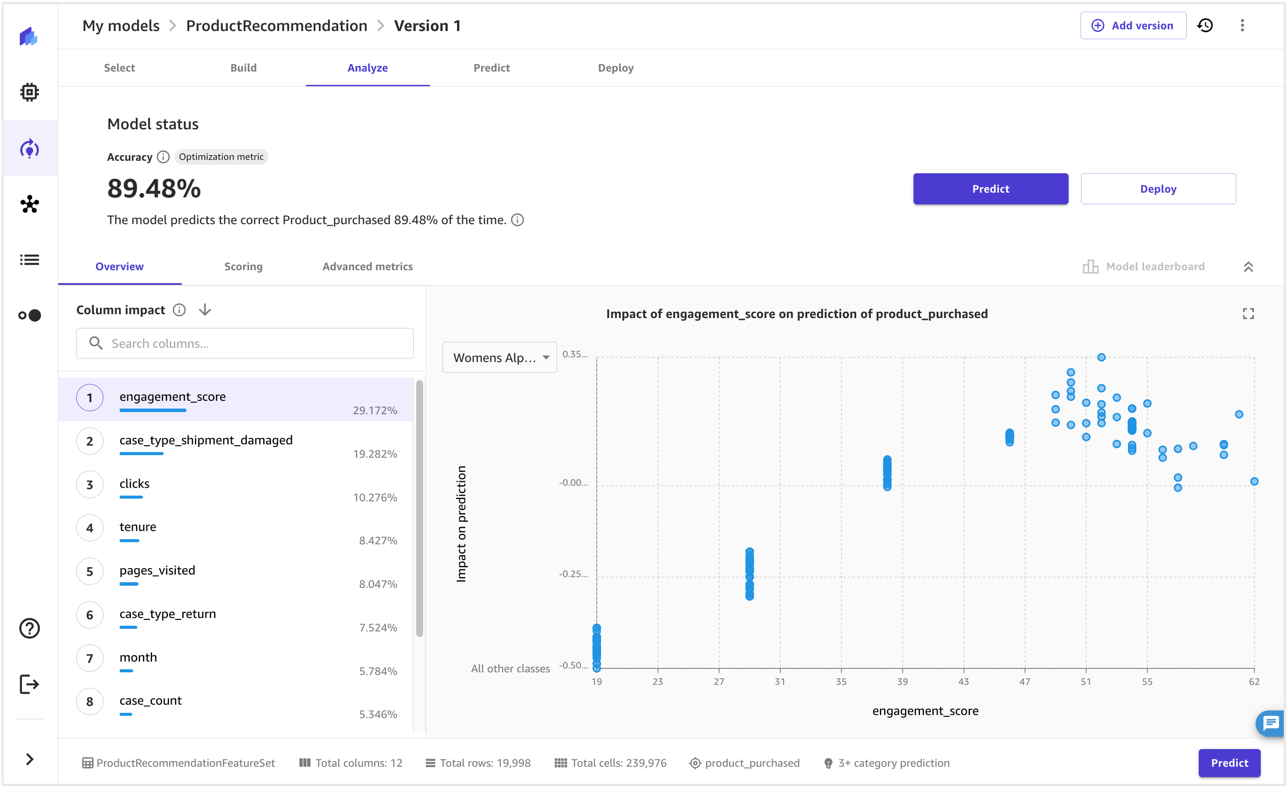
An important next step of the AI system risk assessment is to identify potentially harmful events associated with the use case. In considering these events, it can be helpful to reflect on different dimensions of responsible AI, such as fairness and robustness, for example. Different stakeholders might be affected to different degrees along different dimensions. For example, a low robustness risk for an end-user could be the result of an AI system exhibiting minor disruptions, whereas a low fairness risk could be caused by an AI system producing negligibly different outputs for different demographic groups.
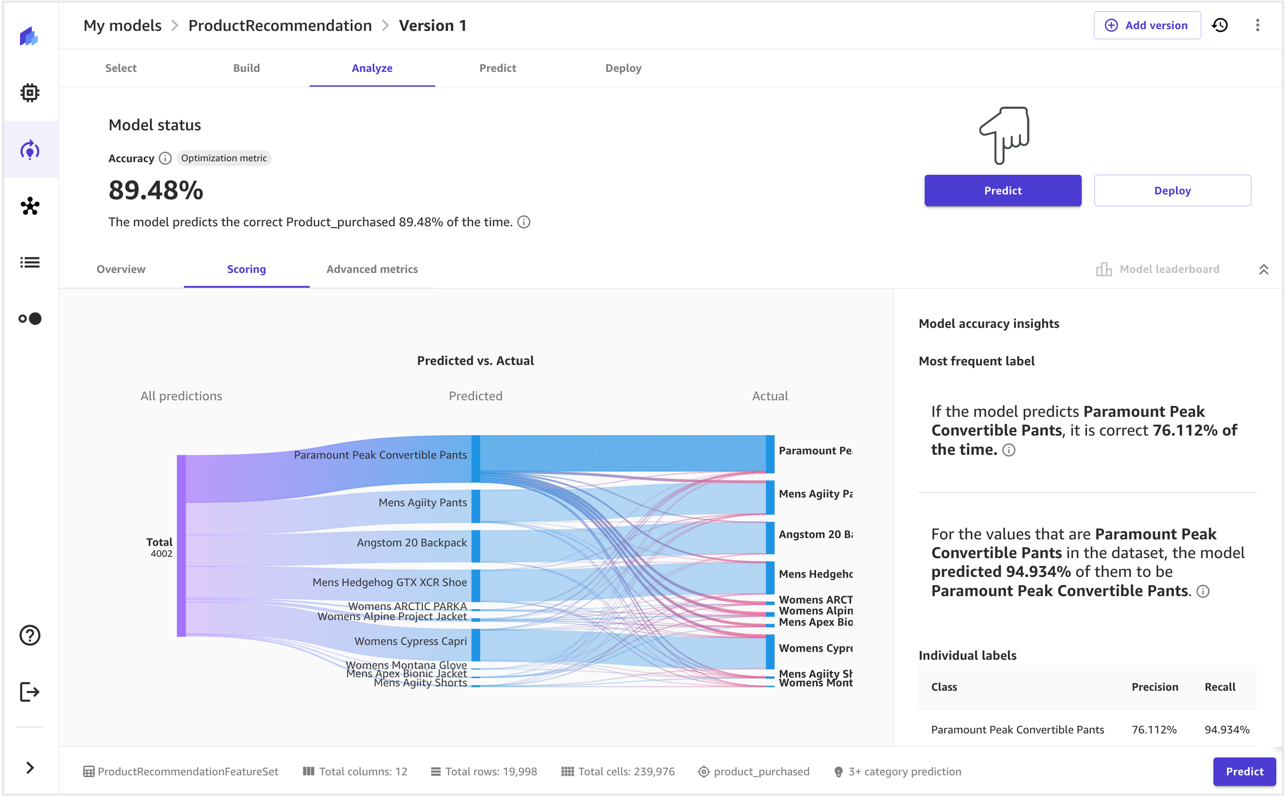
To estimate the risk of an event, you can use a likelihood scale in combination with a severity scale to measure the probability of occurrence as well as the degree of consequences. A helpful starting point when developing these scales might be the NIST RMF, which suggests using qualitative nonnumerical categories ranging from very low to very high risk or semi-quantitative assessments principles, such as scales (such as 1–10), bins, or otherwise representative numbers. After you have defined the likelihood and severity scales for all relevant dimensions, you can use a risk matrix scheme to quantify the overall risk per stakeholders along each relevant dimension. The following figure shows an example risk matrix.
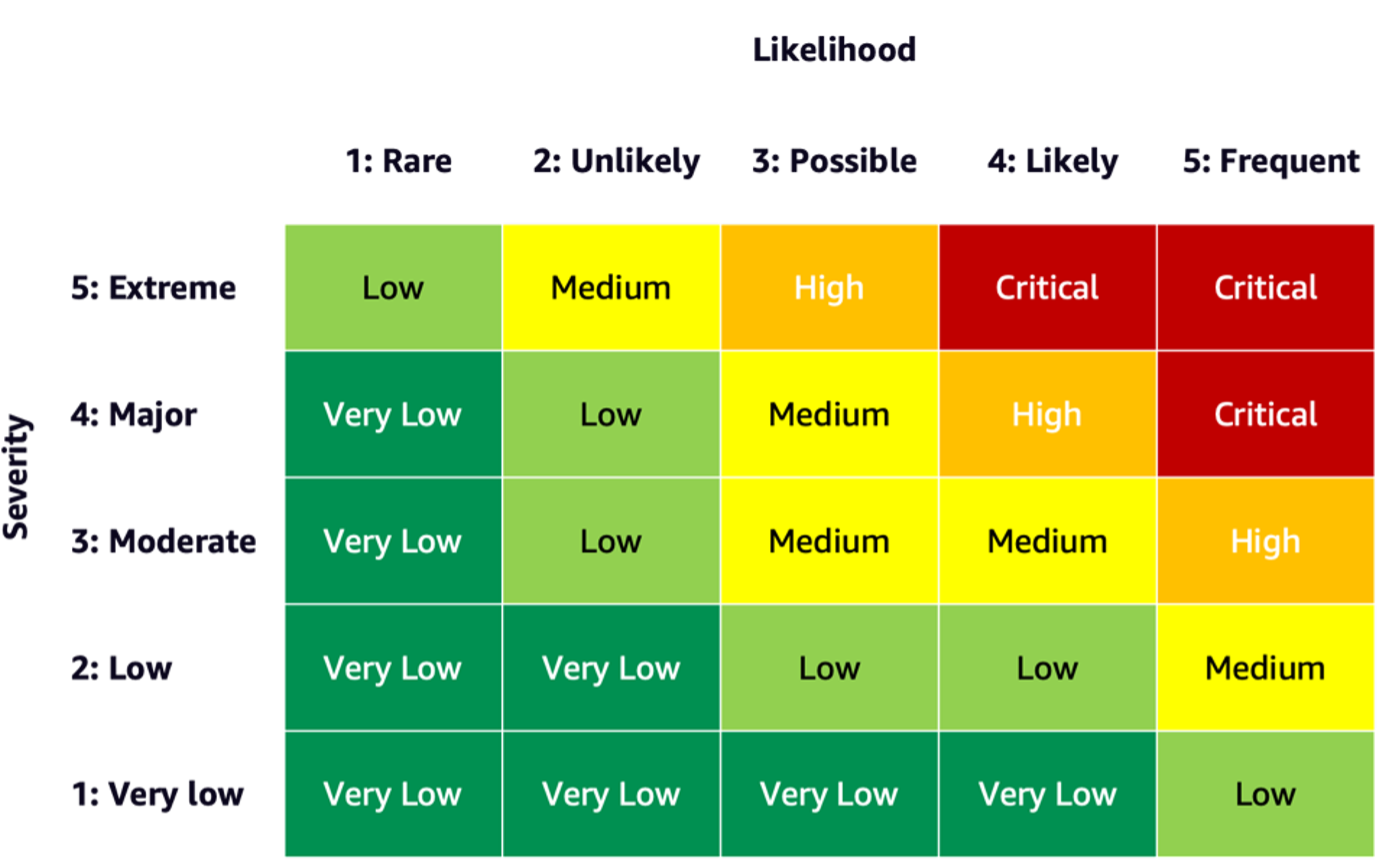
Using this risk matrix, we can consider an event with low severity and rare likelihood of occurring as very low risk. Keep in mind that the initial assessment will be an estimate of inherent risk, and risk mitigation strategies can help lower the risk levels further. The process can then be repeated to generate a rating for any remaining residual risk per event. If there are multiple events identified along the same dimension, it can be helpful to pick the highest risk level among all to create a final assessment summary.
Using the final assessment summary, organizations will have to define what risk levels are acceptable for their AI systems as well as consider relevant regulations and policies.
AWS commitment
Through engagements with the White House and UN, among others, we are committed to sharing our knowledge and expertise to advance the responsible and secure use of AI. Along these lines, Amazon’s Adam Selipsky recently represented AWS at the AI Safety Summit with heads of state and industry leaders in attendance, further demonstrating our dedication to collaborating on the responsible advancement of artificial intelligence.
Conclusion
As AI continues to advance, risk assessment is becoming increasingly important and useful for organizations looking to build and deploy AI responsibly. By establishing a risk assessment framework and risk mitigation plan, organizations can reduce the risk of potential AI-related incidents and earn trust with their customers, as well as reap benefits such as improved reliability, improved fairness for different demographics, and more.
Go ahead and get started on your journey of developing a risk assessment framework in your organization and share your thoughts in the comments.
Also check out an overview of generative AI risks published on Amazon Science: Responsible AI in the generative era, and explore the range of AWS services that can support you on your risk assessment and mitigation journey: Amazon SageMaker Clarify, Amazon SageMaker Model Monitor, AWS CloudTrail, as well as the model governance framework.
About the Authors
 Mia C. Mayer is an Applied Scientist and ML educator at AWS Machine Learning University; where she researches and teaches safety, explainability and fairness of Machine Learning and AI systems. Throughout her career, Mia established several university outreach programs, acted as a guest lecturer and keynote speaker, and presented at numerous large learning conferences. She also helps internal teams and AWS customers get started on their responsible AI journey.
Mia C. Mayer is an Applied Scientist and ML educator at AWS Machine Learning University; where she researches and teaches safety, explainability and fairness of Machine Learning and AI systems. Throughout her career, Mia established several university outreach programs, acted as a guest lecturer and keynote speaker, and presented at numerous large learning conferences. She also helps internal teams and AWS customers get started on their responsible AI journey.
 Denis V. Batalov is a 17-year Amazon veteran and a PhD in Machine Learning, Denis worked on such exciting projects as Search Inside the Book, Amazon Mobile apps and Kindle Direct Publishing. Since 2013 he has helped AWS customers adopt AI/ML technology as a Solutions Architect. Currently, Denis is a Worldwide Tech Leader for AI/ML responsible for the functioning of AWS ML Specialist Solutions Architects globally. Denis is a frequent public speaker, you can follow him on Twitter @dbatalov.
Denis V. Batalov is a 17-year Amazon veteran and a PhD in Machine Learning, Denis worked on such exciting projects as Search Inside the Book, Amazon Mobile apps and Kindle Direct Publishing. Since 2013 he has helped AWS customers adopt AI/ML technology as a Solutions Architect. Currently, Denis is a Worldwide Tech Leader for AI/ML responsible for the functioning of AWS ML Specialist Solutions Architects globally. Denis is a frequent public speaker, you can follow him on Twitter @dbatalov.
 Dr. Sara Liu is a Senior Technical Program Manager with the AWS Responsible AI team. She works with a team of scientists, dataset leads, ML engineers, researchers, as well as other cross-functional teams to raise the responsible AI bar across AWS AI services. Her current projects involve developing AI service cards, conducting risk assessments for responsible AI, creating high-quality evaluation datasets, and implementing quality programs. She also helps internal teams and customers meet evolving AI industry standards.
Dr. Sara Liu is a Senior Technical Program Manager with the AWS Responsible AI team. She works with a team of scientists, dataset leads, ML engineers, researchers, as well as other cross-functional teams to raise the responsible AI bar across AWS AI services. Her current projects involve developing AI service cards, conducting risk assessments for responsible AI, creating high-quality evaluation datasets, and implementing quality programs. She also helps internal teams and customers meet evolving AI industry standards.













 Chetan Kapoor is the Director of Product Management for the Amazon EC2 Accelerated Computing Portfolio.
Chetan Kapoor is the Director of Product Management for the Amazon EC2 Accelerated Computing Portfolio.









 Rishabh Ray Chaudhury is a Senior Product Manager with Amazon SageMaker, focusing on Machine Learning inference. He is passionate about innovating and building new experiences for Machine Learning customers on AWS to help scale their workloads. In his spare time, he enjoys traveling and cooking. You can find him on
Rishabh Ray Chaudhury is a Senior Product Manager with Amazon SageMaker, focusing on Machine Learning inference. He is passionate about innovating and building new experiences for Machine Learning customers on AWS to help scale their workloads. In his spare time, he enjoys traveling and cooking. You can find him on 
 Jian Sheng is a Software Development Engineer at Amazon Web Services who has worked on several key aspects of machine learning systems. He has been a key contributor to the SageMaker Neo service, focusing on deep learning compilation and framework runtime optimization. Recently, he has directed his efforts and contributed to optimizing the machine learning system for large model inference.
Jian Sheng is a Software Development Engineer at Amazon Web Services who has worked on several key aspects of machine learning systems. He has been a key contributor to the SageMaker Neo service, focusing on deep learning compilation and framework runtime optimization. Recently, he has directed his efforts and contributed to optimizing the machine learning system for large model inference. Harish Tummalacherla is Software Engineer with Deep Learning Performance team at SageMaker. He works on performance engineering for serving large language models efficiently on SageMaker. In his spare time, he enjoys running, cycling and ski mountaineering.
Harish Tummalacherla is Software Engineer with Deep Learning Performance team at SageMaker. He works on performance engineering for serving large language models efficiently on SageMaker. In his spare time, he enjoys running, cycling and ski mountaineering.
























 Ajjay Govindaram is a Senior Solutions Architect at AWS. He works with strategic customers who are using AI/ML to solve complex business problems. His experience lies in providing technical direction as well as design assistance for modest to large-scale AI/ML application deployments. His knowledge ranges from application architecture to big data, analytics, and machine learning. He enjoys listening to music while resting, experiencing the outdoors, and spending time with his loved ones.
Ajjay Govindaram is a Senior Solutions Architect at AWS. He works with strategic customers who are using AI/ML to solve complex business problems. His experience lies in providing technical direction as well as design assistance for modest to large-scale AI/ML application deployments. His knowledge ranges from application architecture to big data, analytics, and machine learning. He enjoys listening to music while resting, experiencing the outdoors, and spending time with his loved ones. Nikita Ivkin is a Senior Applied Scientist at Amazon SageMaker Data Wrangler with interests in machine learning and data cleaning algorithms.
Nikita Ivkin is a Senior Applied Scientist at Amazon SageMaker Data Wrangler with interests in machine learning and data cleaning algorithms.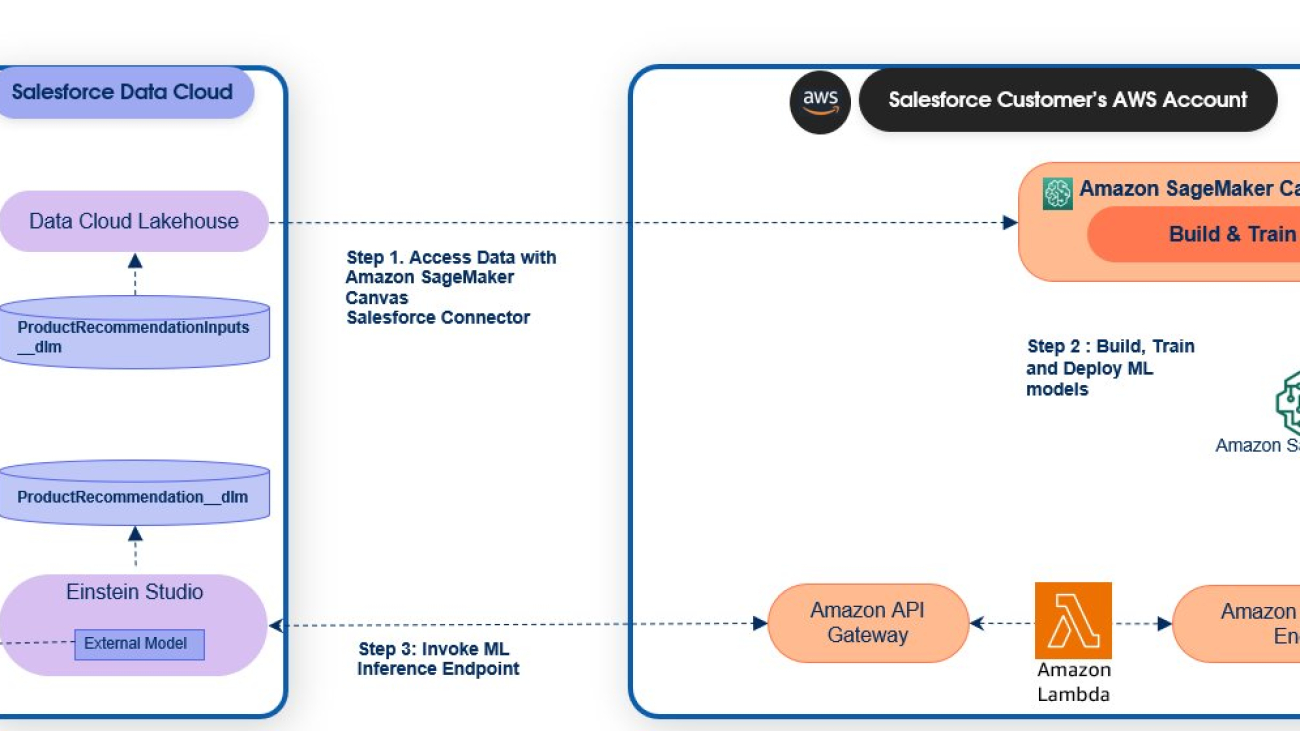
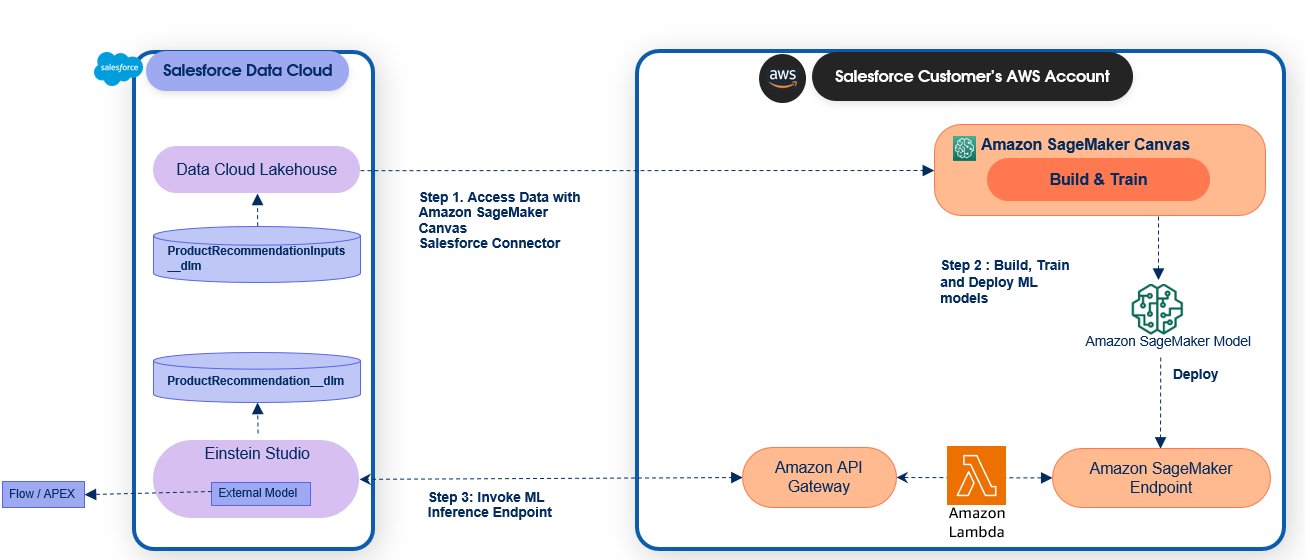
 Daryl Martis is the Director of Product for Einstein Studio at Salesforce Data Cloud. He has over 10 years of experience in planning, building, launching, and managing world-class solutions for enterprise customers, including AI/ML and cloud solutions. He has previously worked in the financial services industry in New York City. Follow him on
Daryl Martis is the Director of Product for Einstein Studio at Salesforce Data Cloud. He has over 10 years of experience in planning, building, launching, and managing world-class solutions for enterprise customers, including AI/ML and cloud solutions. He has previously worked in the financial services industry in New York City. Follow him on  Rachna Chadha is a Principal Solutions Architect AI/ML in Strategic Accounts at AWS. Rachna is an optimist who believes that ethical and responsible use of AI can improve society in the future and bring economic and social prosperity. In her spare time, Rachna likes spending time with her family, hiking, and listening to music.
Rachna Chadha is a Principal Solutions Architect AI/ML in Strategic Accounts at AWS. Rachna is an optimist who believes that ethical and responsible use of AI can improve society in the future and bring economic and social prosperity. In her spare time, Rachna likes spending time with her family, hiking, and listening to music. Ife Stewart is a Principal Solutions Architect in the Strategic ISV segment at AWS. She has been engaged with Salesforce Data Cloud over the last 2 years to help build integrated customer experiences across Salesforce and AWS. Ife has over 10 years of experience in technology. She is an advocate for diversity and inclusion in the technology field.
Ife Stewart is a Principal Solutions Architect in the Strategic ISV segment at AWS. She has been engaged with Salesforce Data Cloud over the last 2 years to help build integrated customer experiences across Salesforce and AWS. Ife has over 10 years of experience in technology. She is an advocate for diversity and inclusion in the technology field. Ravi Bhattiprolu is a Sr. Partner Solutions Architect at AWS. Ravi works with strategic partners, Salesforce and Tableau, to deliver innovative and well-architected products and solutions that help joint customers realize their business objectives.
Ravi Bhattiprolu is a Sr. Partner Solutions Architect at AWS. Ravi works with strategic partners, Salesforce and Tableau, to deliver innovative and well-architected products and solutions that help joint customers realize their business objectives. Miriam Lebowitz is a Solutions Architect in the Strategic ISV segment at AWS. She is engaged with teams across Salesforce, including Salesforce Data Cloud, and specializes in data analytics. Outside of work, she enjoys baking, traveling, and spending quality time with friends and family.
Miriam Lebowitz is a Solutions Architect in the Strategic ISV segment at AWS. She is engaged with teams across Salesforce, including Salesforce Data Cloud, and specializes in data analytics. Outside of work, she enjoys baking, traveling, and spending quality time with friends and family.