This post is co-written with Marc Neumann, Amor Steinberg and Marinus Krommenhoek from BMW Group.
The BMW Group – headquartered in Munich, Germany – is driven by 149,000 employees worldwide and manufactures in over 30 production and assembly facilities across 15 countries. Today, the BMW Group is the world’s leading manufacturer of premium automobiles and motorcycles, and provider of premium financial and mobility services. The BMW Group sets trends in production technology and sustainability as an innovation leader with an intelligent material mix, a technological shift towards digitalization, and resource-efficient production.
In an increasingly digital and rapidly changing world, BMW Group’s business and product development strategies rely heavily on data-driven decision-making. With that, the need for data scientists and machine learning (ML) engineers has grown significantly. These skilled professionals are tasked with building and deploying models that improve the quality and efficiency of BMW’s business processes and enable informed leadership decisions.
Data scientists and ML engineers require capable tooling and sufficient compute for their work. Therefore, BMW established a centralized ML/deep learning infrastructure on premises several years ago and continuously upgraded it. To pave the way for the growth of AI, BMW Group needed to make a leap regarding scalability and elasticity while reducing operational overhead, software licensing, and hardware management.
In this post, we will talk about how BMW Group, in collaboration with AWS Professional Services, built its Jupyter Managed (JuMa) service to address these challenges. JuMa is a service of BMW Group’s AI platform for its data analysts, ML engineers, and data scientists that provides a user-friendly workspace with an integrated development environment (IDE). It is powered by Amazon SageMaker Studio and provides JupyterLab for Python and Posit Workbench for R. This offering enables BMW ML engineers to perform code-centric data analytics and ML, increases developer productivity by providing self-service capability and infrastructure automation, and tightly integrates with BMW’s centralized IT tooling landscape.
JuMa is now available to all data scientists, ML engineers, and data analysts at BMW Group. The service streamlines ML development and production workflows (MLOps) across BMW by providing a cost-efficient and scalable development environment that facilitates seamless collaboration between data science and engineering teams worldwide. This results in faster experimentation and shorter idea validation cycles. Moreover, the JuMa infrastructure, which is based on AWS serverless and managed services, helps reduce operational overhead for DevOps teams and allows them to focus on enabling use cases and accelerating AI innovation at BMW Group.
Challenges of growing an on-premises AI platform
Prior to introducing the JuMa service, BMW teams worldwide were using two on-premises platforms that provided teams JupyterHub and RStudio environments. These platforms were too limited regarding CPU, GPU, and memory to allow the scalability of AI at BMW Group. Scaling these platforms with managing more on-premises hardware, more software licenses, and support fees would require significant up-front investments and high efforts for its maintenance. To add to this, limited self-service capabilities were available, requiring high operational effort for its DevOps teams. More importantly, the use of these platforms was misaligned with BMW Group’s IT cloud-first strategy. For example, teams using these platforms missed an easy migration of their AI/ML prototypes to the industrialization of the solution running on AWS. In contrast, the data science and analytics teams already using AWS directly for experimentation needed to also take care of building and operating their AWS infrastructure while ensuring compliance with BMW Group’s internal policies, local laws, and regulations. This included a range of configuration and governance activities from ordering AWS accounts, limiting internet access, using allowed listed packages to keeping their Docker images up to date.
Overview of solution
JuMa is a fully managed multi-tenant, security hardened AI platform service built on AWS with SageMaker Studio at the core. By relying on AWS serverless and managed services as the main building blocks of the infrastructure, the JuMa DevOps team doesn’t need to worry about patching servers, upgrading storage, or managing any other infrastructure components. The service handles all those processes automatically, providing a powerful technical platform that is generally up to date and ready to use.
JuMa users can effortlessly order a workspace via a self-service portal to create a secure and isolated development and experimentation environment for their teams. After a JuMa workspace is provisioned, the users can launch JupyterLab or Posit workbench environments in SageMaker Studio with just a few clicks and start the development immediately, using the tools and frameworks they are most familiar with. JuMa is tightly integrated with a range of BMW Central IT services, including identity and access management, roles and rights management, BMW Cloud Data Hub (BMW’s data lake on AWS) and on-premises databases. The latter helps AI/ML teams seamlessly access required data, given they are authorized to do so, without needing to build data pipelines. Furthermore, the notebooks can be integrated into the corporate Git repositories to collaborate using version control.
The solution abstracts away all technical complexities associated with AWS account management, configuration, and customization for AI/ML teams, allowing them to fully focus on AI innovation. The platform ensures that the workspace configuration meets BMW’s security and compliance requirements out of the box.
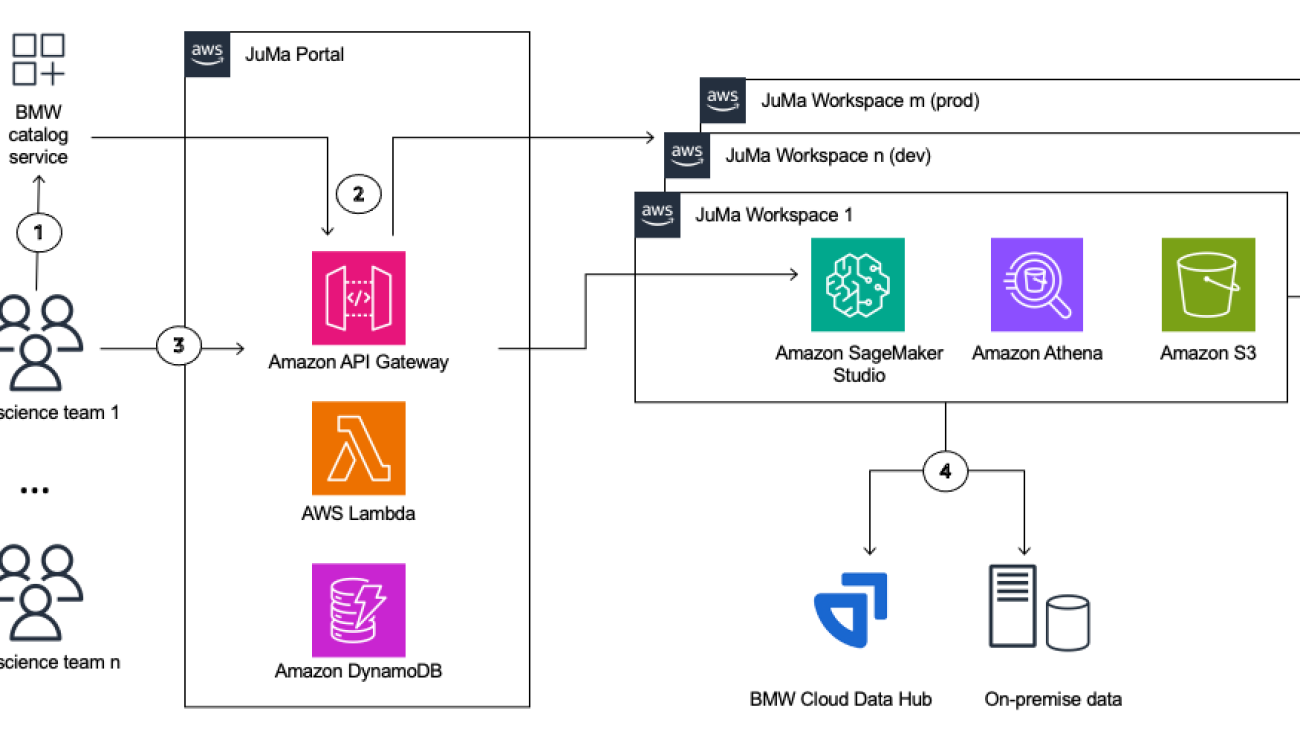
The following diagram describes the high-level context view of the architecture.

User journey
BMW AI/ML team members can order their JuMa workspace using BMW’s standard catalog service. After approval by the line manager, the ordered JuMa workspace is provisioned by the platform fully automatedly. The workspace provisioning workflow includes the following steps (as numbered in the architecture diagram).
- A data scientist team orders a new JuMa workspace in BMW’s Catalog. JuMa automatically provisions a new AWS account for the workspace. This ensures full isolation between the workspaces following the federated model account structure mentioned in SageMaker Studio Administration Best Practices.
- JuMa configures a workspace (which is a Sagemaker domain) that only allows predefined Amazon SageMaker features required for experimentation and development, specific custom kernels, and lifecycle configurations. It also sets up the required subnets and security groups that ensure the notebooks run in a secure environment.
- After the workspaces are provisioned, the authorized users log in to the JuMa portal and access the SageMaker Studio IDE within their workspace using a SageMaker pre-signed URL. Users can choose between opening a SageMaker Studio private space or a shared space. Shared spaces encourage collaboration between different members of a team that can work in parallel on the same notebooks, whereas private spaces allow for a development environment for solitary workloads.
- Using the BMW data portal, users can request access to on-premises databases or data stored in BMW’s Cloud Data Hub, making it available in their workspace for development and experimentation, from data preparation and analysis to model training and validation.
After an AI model is developed and validated in JuMa, AI teams can use the MLOPs service of the BMW AI platform to deploy it to production quickly and effortlessly. This service provides users with a production-grade ML infrastructure and pipelines on AWS using SageMaker, which can be set up in minutes with just a few clicks. Users simply need to host their model on the provisioned infrastructure and customize the pipeline to meet their specific use case needs. In this way, the AI platform covers the entire AI lifecycle at BMW Group.
JuMa features
Following best practice architecting on AWS, the JuMa service was designed and implemented according to the AWS Well-Architected Framework. Architectural decisions of each Well-Architected pillar are described in detail in the following sections.
Security and compliance
To assure full isolation between the tenants, each workspace receives its own AWS account, where the authorized users can jointly collaborate on analytics tasks as well as on developing and experimenting with AI/ML models. The JuMa portal itself enforces isolation at runtime using policy-based isolation with AWS Identity and Access Management (IAM) and the JuMa user’s context. For more information about this strategy, refer to Run-time, policy-based isolation with IAM.
Data scientists can only access their domain through the BMW network via pre-signed URLs generated by the portal. Direct internet access is disabled within their domain. Their Sagemaker domain privileges are built using Amazon SageMaker Role Manager personas to ensure least privilege access to AWS services needed for the development such as SageMaker, Amazon Athena, Amazon Simple Storage Service (Amazon S3), and AWS Glue. This role implements ML guardrails (such as those described in Governance and control), including enforcement of ML training to occur in either Amazon Virtual Private Cloud (Amazon VPC) or without internet and allowing only the use of JuMa’s custom vetted and up-to-date SageMaker images.
Because JuMa is designed for development, experimentation, and ad-hoc analysis, it implements retention policies to remove data after 30 days. To access data whenever needed and store it for long term, JuMa seamlessly integrates with the BMW Cloud Data Hub and BMW on-premises databases.
Finally, JuMa supports multiple Regions to comply to special local legal situations which, for example, require it to process data locally to enable BMW’s data sovereignty.
Operational excellence
Both the JuMa platform backend and workspaces are implemented with AWS serverless and managed services. Using those services helps minimize the effort of the BMW platform team maintaining and operating the end-to-end solution, striving to be a no-ops service. Both the workspace and portal are monitored using Amazon CloudWatch logs, metrics, and alarms to check key performance indicators (KPIs) and proactively notify the platform team of any issues. Additionally, the AWS X-Ray distributed tracing system is used to trace requests throughout multiple components and annotate CloudWatch logs with workspace-relevant context.
All changes to the JuMa infrastructure are managed and implemented through automation using infrastructure as code (IaC). This helps reduce manual efforts and human errors, increase consistency, and ensure reproducible and version-controlled changes across both JuMa platform backend workspaces. Specifically, all workspaces are provisioned and updated through an onboarding process built on top of AWS Step Functions, AWS CodeBuild, and Terraform. Therefore, no manual configuration is required to onboard new workspaces to the JuMa platform.
Cost optimization
By using AWS serverless services, JuMa ensures on-demand scalability, pre-approved instance sizes, and a pay-as-you-go model for the resources used during the development and experimentation activities per the AI/ML teams’ needs. To further optimize costs, the JuMa platform monitors and identifies idle resources within SageMaker Studio and shuts them down automatically to prevent expenses for non-utilized resources.
Sustainability
JuMa replaces BMW’s two on-premises platforms for analytics and deep learning workloads that consume a considerable amount of electricity and produce CO2 emissions even when not in use. By migrating AI/ML workloads from on premises to AWS, BMW will slash its environmental impact by decommissioning the on-premises platforms.
Furthermore, the mechanism for auto shutdown of idle resources, data retention polices, and the workspace usage reports to its owners implemented in JuMa help further minimize the environmental footprint of running AI/ML workloads on AWS.
Performance efficiency
By using SageMaker Studio, BMW teams benefit from an easy adoption of the latest SageMaker features that can help accelerate their experimentation. For example, they can use Amazon SageMaker JumpStart capabilities to use the latest pre-trained, open source models. Additionally, it helps reduce AI/ML team efforts moving from experimentation to solution industrialization, because the development environment provides the same AWS core services but restricted to development capabilities.
Reliability
SageMaker Studio domains are deployed in a VPC-only mode to manage internet access and only allow access to intended AWS services. The network is deployed in two Availability Zones to protect against a single point of failure, achieving greater resiliency and availability of the platform to its users.
Changes to JuMa workspaces are automatically deployed and tested to development and integration environments, using IaC and CI/CD pipelines, before upgrading customer environments.
Finally, data stored in Amazon Elastic File System (Amazon EFS) for SageMaker Studio domains is kept after volumes are deleted for backup purposes.
Conclusion
In this post, we described how BMW Group in collaboration with AWS ProServe developed a fully managed AI platform service on AWS using SageMaker Studio and other AWS serverless and managed services.
With JuMa, BMW’s AI/ML teams are empowered to unlock new business value by accelerating experimentation as well as time-to-market for disruptive AI solutions. Furthermore, by migrating from its on-premises platform, BMW can reduce the overall operational efforts and costs while also increasing sustainability and the overall security posture.
To learn more about running your AI/ML experimentation and development workloads on AWS, visit Amazon SageMaker Studio.
About the Authors
 Marc Neumann is the head of the central AI Platform at BMP Group. He is responsible for developing and implementing strategies to use AI technology for business value creation across the BMW Group. His primary goal is to ensure that the use of AI is sustainable and scalable, meaning it can be consistently applied across the organization to drive long-term growth and innovation. Through his leadership, Neumann aims to position the BMW Group as a leader in AI-driven innovation and value creation in the automotive industry and beyond.
Marc Neumann is the head of the central AI Platform at BMP Group. He is responsible for developing and implementing strategies to use AI technology for business value creation across the BMW Group. His primary goal is to ensure that the use of AI is sustainable and scalable, meaning it can be consistently applied across the organization to drive long-term growth and innovation. Through his leadership, Neumann aims to position the BMW Group as a leader in AI-driven innovation and value creation in the automotive industry and beyond.
 Amor Steinberg is a Machine Learning Engineer at BMW Group and the service lead of Jupyter Managed, a new service that aims to provide a code-centric analytics and machine learning workbench for engineers and data scientists at the BMW Group. His past experience as a DevOps Engineer at financial institutions enabled him to gather a unique understanding of the challenges that faces banks in the European Union and keep the balance between striving for technological innovation, complying with laws and regulations, and maximizing security for customers.
Amor Steinberg is a Machine Learning Engineer at BMW Group and the service lead of Jupyter Managed, a new service that aims to provide a code-centric analytics and machine learning workbench for engineers and data scientists at the BMW Group. His past experience as a DevOps Engineer at financial institutions enabled him to gather a unique understanding of the challenges that faces banks in the European Union and keep the balance between striving for technological innovation, complying with laws and regulations, and maximizing security for customers.
 Marinus Krommenhoek is a Senior Cloud Solution Architect and a Software Developer at BMW Group. He is enthusiastic about modernizing the IT landscape with state-of-the-art services that add high value and are easy to maintain and operate. Marinus is a big advocate of microservices, serverless architectures, and agile working. He has a record of working with distributed teams across the globe within large enterprises.
Marinus Krommenhoek is a Senior Cloud Solution Architect and a Software Developer at BMW Group. He is enthusiastic about modernizing the IT landscape with state-of-the-art services that add high value and are easy to maintain and operate. Marinus is a big advocate of microservices, serverless architectures, and agile working. He has a record of working with distributed teams across the globe within large enterprises.
 Nicolas Jacob Baer is a Principal Cloud Application Architect at AWS ProServe with a strong focus on data engineering and machine learning, based in Switzerland. He works closely with enterprise customers to design data platforms and build advanced analytics and ML use cases.
Nicolas Jacob Baer is a Principal Cloud Application Architect at AWS ProServe with a strong focus on data engineering and machine learning, based in Switzerland. He works closely with enterprise customers to design data platforms and build advanced analytics and ML use cases.
 Joaquin Rinaudo is a Principal Security Architect at AWS ProServe. He is passionate about building solutions that help developers improve their software quality. Prior to AWS, he worked across multiple domains in the security industry, from mobile security to cloud and compliance-related topics. In his free time, Joaquin enjoys spending time with family and reading science-fiction novels.
Joaquin Rinaudo is a Principal Security Architect at AWS ProServe. He is passionate about building solutions that help developers improve their software quality. Prior to AWS, he worked across multiple domains in the security industry, from mobile security to cloud and compliance-related topics. In his free time, Joaquin enjoys spending time with family and reading science-fiction novels.
 Shukhrat Khodjaev is a Senior Global Engagement Manager at AWS ProServe. He specializes in delivering impactful big data and AI/ML solutions that enable AWS customers to maximize their business value through data utilization.
Shukhrat Khodjaev is a Senior Global Engagement Manager at AWS ProServe. He specializes in delivering impactful big data and AI/ML solutions that enable AWS customers to maximize their business value through data utilization.
Read More









 Bratin Saha is the Vice President of Artificial Intelligence and Machine Learning at AWS.
Bratin Saha is the Vice President of Artificial Intelligence and Machine Learning at AWS.


 Anuradha Durfee is a Senior Product Manager on the Amazon Lex team and has more than 7 years of experience in conversational AI. She is fascinated by voice user interfaces and making technology more accessible through intuitive design.
Anuradha Durfee is a Senior Product Manager on the Amazon Lex team and has more than 7 years of experience in conversational AI. She is fascinated by voice user interfaces and making technology more accessible through intuitive design. Sandeep Srinivasan is a Senior Product Manager on the Amazon Lex team. As a keen observer of human behavior, he is passionate about customer experience. He spends his waking hours at the intersection of people, technology, and the future.
Sandeep Srinivasan is a Senior Product Manager on the Amazon Lex team. As a keen observer of human behavior, he is passionate about customer experience. He spends his waking hours at the intersection of people, technology, and the future.
 Sumit Kumar is a Principal Product Manager, Technical at AWS AI Language Services team. He has 10 years of product management experience across a variety of domains and is passionate about AI/ML. Outside of work, Sumit loves to travel and enjoys playing cricket and Lawn-Tennis.
Sumit Kumar is a Principal Product Manager, Technical at AWS AI Language Services team. He has 10 years of product management experience across a variety of domains and is passionate about AI/ML. Outside of work, Sumit loves to travel and enjoys playing cricket and Lawn-Tennis. Vivek Singh is a Senior Manager, Product Management at AWS AI Language Services team. He leads the Amazon Transcribe product team. Prior to joining AWS, he held product management roles across various other Amazon organizations such as consumer payments and retail. Vivek lives in Seattle, WA and enjoys running, and hiking.
Vivek Singh is a Senior Manager, Product Management at AWS AI Language Services team. He leads the Amazon Transcribe product team. Prior to joining AWS, he held product management roles across various other Amazon organizations such as consumer payments and retail. Vivek lives in Seattle, WA and enjoys running, and hiking.

 Jingwen Hu is a Senior Technical Product Manager working with AWS AI/ML on the Amazon Personalize team. In her spare time, she enjoys traveling and exploring local food.
Jingwen Hu is a Senior Technical Product Manager working with AWS AI/ML on the Amazon Personalize team. In her spare time, she enjoys traveling and exploring local food. Pranav Agarwal is a Senior Software Engineer with AWS AI/ML and works on architecting software systems and building AI-powered recommender systems at scale. Outside of work, he enjoys reading, running, and ice-skating.
Pranav Agarwal is a Senior Software Engineer with AWS AI/ML and works on architecting software systems and building AI-powered recommender systems at scale. Outside of work, he enjoys reading, running, and ice-skating. Rishabh Agrawal is a Senior Software Engineer working on AI services at AWS. In his spare time, he enjoys hiking, traveling, and reading.
Rishabh Agrawal is a Senior Software Engineer working on AI services at AWS. In his spare time, he enjoys hiking, traveling, and reading. Ashish Lal is a Senior Product Marketing Manager who leads product marketing for AI services at AWS. He has 9 years of marketing experience and has led the product marketing effort for intelligent document processing. He got his master’s in Business Administration at the University of Washington.
Ashish Lal is a Senior Product Marketing Manager who leads product marketing for AI services at AWS. He has 9 years of marketing experience and has led the product marketing effort for intelligent document processing. He got his master’s in Business Administration at the University of Washington.
 Shreeya Sharma is a Sr. Technical Product Manager working with AWS AI/ML on Amazon Personalize. She has a background in computer science engineering, technology consulting, and data analytics. In her spare time, she enjoys traveling, performing theatre, and trying out new adventures.
Shreeya Sharma is a Sr. Technical Product Manager working with AWS AI/ML on Amazon Personalize. She has a background in computer science engineering, technology consulting, and data analytics. In her spare time, she enjoys traveling, performing theatre, and trying out new adventures. Pranesh Anubhav is a Senior Software Engineer for Amazon Personalize. He is passionate about designing machine learning systems to serve customers at scale. Outside of his work, he loves playing soccer and is an avid follower of Real Madrid.
Pranesh Anubhav is a Senior Software Engineer for Amazon Personalize. He is passionate about designing machine learning systems to serve customers at scale. Outside of his work, he loves playing soccer and is an avid follower of Real Madrid. Aniket Deshmukh is an Applied Scientist in AWS AI labs supporting Amazon Personalize. Aniket works in the general area of recommendation systems, contextual bandits, and multi-modal deep learning.
Aniket Deshmukh is an Applied Scientist in AWS AI labs supporting Amazon Personalize. Aniket works in the general area of recommendation systems, contextual bandits, and multi-modal deep learning.


 Dhaval Shah is a Senior Solutions Architect at AWS, specializing in Machine Learning. With a strong focus on digital native businesses, he empowers customers to leverage AWS and drive their business growth. As an ML enthusiast, Dhaval is driven by his passion for creating impactful solutions that bring positive change. In his leisure time, he indulges in his love for travel and cherishes quality moments with his family.
Dhaval Shah is a Senior Solutions Architect at AWS, specializing in Machine Learning. With a strong focus on digital native businesses, he empowers customers to leverage AWS and drive their business growth. As an ML enthusiast, Dhaval is driven by his passion for creating impactful solutions that bring positive change. In his leisure time, he indulges in his love for travel and cherishes quality moments with his family. Doug Tiffan is the Head of World Wide Solution Strategy for Fashion & Apparel at AWS. In his role, Doug works with Fashion & Apparel executives to understand their goals and align with them on the best solutions. Doug has over 30 years of experience in retail, holding several merchandising and technology leadership roles. Doug holds a BBA from Texas A&M University and is based in Houston, Texas.
Doug Tiffan is the Head of World Wide Solution Strategy for Fashion & Apparel at AWS. In his role, Doug works with Fashion & Apparel executives to understand their goals and align with them on the best solutions. Doug has over 30 years of experience in retail, holding several merchandising and technology leadership roles. Doug holds a BBA from Texas A&M University and is based in Houston, Texas. Nikhil Sharma is a Solutions Architecture Leader at Amazon Web Services (AWS) where he and his team of Solutions Architects help AWS customers solve critical business challenges using AWS cloud technologies and services.
Nikhil Sharma is a Solutions Architecture Leader at Amazon Web Services (AWS) where he and his team of Solutions Architects help AWS customers solve critical business challenges using AWS cloud technologies and services. Kevin Bell is a Sr. Solutions Architect at AWS based in Seattle. He has been building things in the cloud for about 10 years. You can find him online as @bellkev on GitHub.
Kevin Bell is a Sr. Solutions Architect at AWS based in Seattle. He has been building things in the cloud for about 10 years. You can find him online as @bellkev on GitHub. Nipun Chagari is a Principal Solutions Architect based in the Bay Area, CA. Nipun is passionate about helping customers adopt Serverless technology to modernize applications and achieve their business objectives. His recent focus has been on assisting organizations in adopting modern technologies to enable digital transformation. Apart from work, Nipun finds joy in playing volleyball, cooking and traveling with his family.
Nipun Chagari is a Principal Solutions Architect based in the Bay Area, CA. Nipun is passionate about helping customers adopt Serverless technology to modernize applications and achieve their business objectives. His recent focus has been on assisting organizations in adopting modern technologies to enable digital transformation. Apart from work, Nipun finds joy in playing volleyball, cooking and traveling with his family. Marshall Bunch is a Solutions Architect at AWS helping North American customers design secure, scalable and cost-effective workloads in the cloud. His passion lies in solving age-old business problems where data and the newest technologies enable novel solutions. Beyond his professional pursuits, Marshall enjoys hiking and camping in Colorado’s beautiful Rocky Mountains.
Marshall Bunch is a Solutions Architect at AWS helping North American customers design secure, scalable and cost-effective workloads in the cloud. His passion lies in solving age-old business problems where data and the newest technologies enable novel solutions. Beyond his professional pursuits, Marshall enjoys hiking and camping in Colorado’s beautiful Rocky Mountains. Altaaf Dawoodjee is a Solutions Architect Leader that supports AdTech customers in the Digital Native Business (DNB) segment at Amazon Web Service (AWS). He has over 20 years of experience in Technology and has deep expertise in Analytics. He is passionate about helping drive successful business outcomes for his customers leveraging the AWS cloud.
Altaaf Dawoodjee is a Solutions Architect Leader that supports AdTech customers in the Digital Native Business (DNB) segment at Amazon Web Service (AWS). He has over 20 years of experience in Technology and has deep expertise in Analytics. He is passionate about helping drive successful business outcomes for his customers leveraging the AWS cloud. Scott Bell is a dynamic leader and innovator with 25+ years of technology management experience. He is passionate about leading and developing teams in providing technology to meet the challenges of global users and businesses. He has extensive experience in leading technology teams which provide global technology solutions supporting 35+ languages. He is also passionate about the way the AI and Generative AI transform businesses and the way they support customer’s current unmet needs.
Scott Bell is a dynamic leader and innovator with 25+ years of technology management experience. He is passionate about leading and developing teams in providing technology to meet the challenges of global users and businesses. He has extensive experience in leading technology teams which provide global technology solutions supporting 35+ languages. He is also passionate about the way the AI and Generative AI transform businesses and the way they support customer’s current unmet needs. Sachin Shetti is a Principal Customer Solution Manager at AWS. He is passionate about helping enterprises succeed and realize significant benefits from cloud adoption, driving everything from basic migration to large-scale cloud transformation across people, processes, and technology. Prior to joining AWS, Sachin worked as a software developer for over 12 years and held multiple senior leadership positions leading technology delivery and transformation in healthcare, financial services, retail, and insurance. He has an Executive MBA and a Bachelor’s degree in Mechanical Engineering.
Sachin Shetti is a Principal Customer Solution Manager at AWS. He is passionate about helping enterprises succeed and realize significant benefits from cloud adoption, driving everything from basic migration to large-scale cloud transformation across people, processes, and technology. Prior to joining AWS, Sachin worked as a software developer for over 12 years and held multiple senior leadership positions leading technology delivery and transformation in healthcare, financial services, retail, and insurance. He has an Executive MBA and a Bachelor’s degree in Mechanical Engineering.