
With advances in computing, sophisticated AI models and machine learning are having a profound impact on business and society. Industries can use AI to quickly analyze vast bodies of data, allowing them to derive meaningful insights, make predictions and automate processes for greater efficiency.
In the public sector, government agencies are achieving superior disaster preparedness. Biomedical researchers are bringing novel drugs to market faster. Telecommunications providers are building more energy-efficient networks. Manufacturers are trimming emissions from product design, development and manufacturing processes. Hollywood studios are creating impressive visual effects at a fraction of the cost and time. Robots are being deployed on important missions to help preserve the Earth. And investment advisors are running more trade scenarios to optimize portfolios.
Eighty-two percent of companies surveyed are already using or exploring AI, and 84% report that they’re increasing investments in data and AI initiatives. Any organization that delays AI implementation risks missing out on new efficiency gains and becoming obsolete.
However, AI workloads are computationally demanding, and legacy computing systems are ill-equipped for the development and deployment of AI. CPU-based compute requires linear growth in power input to meet the increased processing needs of AI and data-heavy workloads. If data centers are using carbon-based energy, it’s impossible for enterprises to innovate using AI while controlling greenhouse gas emissions and meeting sustainability commitments. Plus, many countries are introducing tougher regulations to enforce data center carbon reporting.
Accelerated computing — the use of GPUs and special hardware, software and parallel computing techniques — has exponentially improved the performance and energy efficiency of data centers.
Below, read more on how industries are using energy-efficient computing to scale AI, improve products and services, and reduce emissions and operational costs.
The Public Sector Drives Research, Delivers Improved Citizen Services
Data is playing an increasingly important role in government services, including for public health and disease surveillance, scientific research, social security administration, and extreme-weather monitoring and management. These operations require platforms and systems that can handle large volumes of data, provide real-time data access, and ensure data quality and accuracy.
But many government agencies rely on legacy systems that are difficult to maintain, don’t efficiently integrate with modern technologies and consume excessive energy. To handle increasingly demanding workloads while sticking to sustainability goals, government agencies and public organizations must adopt more efficient computing solutions.
The U.S. Department of Energy is making inroads in this endeavor. The department runs the National Energy Research Scientific Computing Center for open science. NERSC develops simulations, data analytics and machine learning solutions to accelerate scientific discovery through computation. Seeking new computing efficiencies, the center measured results across four of its key high performance computing and AI applications. It clocked how fast the applications ran, as well as how much energy they consumed using CPU-only versus GPU-accelerated nodes on Perlmutter, one of the world’s largest supercomputers.
At performance parity, a GPU-accelerated cluster consumes 588 less megawatt hours per month, representing a 5x improvement in energy efficiency. By running the same workload on GPUs rather than CPU-only instances, researchers could save millions of dollars per month. These gains mean that the 8,000+ researchers using NERSC computing infrastructure can perform more experiments on important use cases, like studying subatomic interactions to uncover new green energy sources, developing 3D maps of the universe and bolstering a broad range of innovations in materials science and quantum physics.
Governments help protect citizens from adverse weather events, such as hurricanes, floods, blizzards and heat waves. With GPU deployments, climate models, like the IFS model from the European Centre for Medium-Range Weather Forecasts, can run up to 24x faster while reducing annual energy usage by up to 127 gigawatt hours compared to CPU-only systems. As extreme-weather events occur with greater frequency and, often, with little warning, meteorology centers can use accelerated computing to generate more accurate, timely forecasts that improve readiness and response.
By adopting more efficient computing systems, governments can save costs while equipping researchers with the tools they need for scientific discoveries to improve climate modeling and forecasting, as well as deliver superior services in public health, disaster relief and more.
Drug Discovery Researchers Conduct Virtual Screenings, Generate New Proteins at Light Speed
Drug development has always been a time-consuming process that involves innumerable calculations and thousands of experiments to screen new compounds. To develop novel medications, the binding properties of small molecules must be tested against protein targets, a cumbersome task required for up to billions of compounds — which translates to billions of CPU hours and hundreds of millions of dollars each year.
Highly accurate AI models can now predict protein structures, generate small molecules, predict protein-ligand binding and perform virtual screening.
Researchers at Oak Ridge National Laboratory (ORNL) and Scripps Research have shown that screening a dataset of billions of compounds against a protein, which has traditionally taken years, can now be completed in just hours with accelerated computing. By running AutoDock, a molecular-modeling simulation software, on a supercomputer with more than 27,000 NVIDIA GPUs, ORNL screened more than 25,000 molecules per second and evaluated the docking of 1 billion compounds in less than 12 hours. This is a speedup of more than 50x compared with running AutoDock on CPUs.
Iambic, an AI platform for drug discovery, has developed an approach combining quantum chemistry and AI that calculates quantum-accurate molecular-binding energies and forces at a fraction of the computational expense of traditional methods. These energies and forces can power molecular-dynamics simulations at unprecedented speed and accuracy. With its OrbNet model, Iambic uses a graph transformer to power quantum-mechanical operators that represent chemical structures. The company is using the technology to identify drug molecules that could deactivate proteins linked to certain cancer types.
As the number of new drug approvals declines and research and development and computing costs rise, optimizing drug discovery with accelerated computing can help control energy expenditures while creating a far-reaching impact on medical research, treatments and patient outcomes.
Telcos Scale Network Capacity
To connect their subscribers, telecommunications companies send data across sprawling networks of cell towers, fiber-optic cables and wireless signals. In the U.S., AT&T’s network connects more than 100 million users from the Aleutian Islands in Alaska to the Florida Keys, processing 500 petabytes of data per day. As telcos add compute-intensive workloads like AI and user plane function (UPF) to process and route data over 5G networks, power consumption costs are skyrocketing.
AT&T processes trillions of data rows to support field technician dispatch operations, generate performance reports and power mobile connectivity. To process data faster, AT&T tested the NVIDIA RAPIDS Accelerator for Apache Spark. By spreading work across nodes in a cluster, the software processed 2.8 trillion rows of information — a month’s worth of mobile data — in just five hours. That’s 3.3x faster at 60% lower cost than any prior test.
Other telcos are saving energy by offloading networking and security tasks to SmartNICs and data processing units (DPUs) to reduce server power consumption. Ericsson, a leading telecommunications equipment manufacturer, tested a 5G UPF on servers with and without network offload to an NVIDIA ConnectX-6 Dx NIC. At maximum network traffic, the network offloading provided 23% power savings. The study also found that CPU micro-sleeps and frequency scaling — allowing CPUs to sleep and slow their clock frequencies during low workload levels — saved more than 10% of power per CPU.
Hardware-accelerated networking offloads like these allow telco operators to increase network capacity without a proportional increase in energy consumption, ensuring that networks can scale to handle increased demand and conserve energy during times of low use. By adopting energy-efficient accelerated computing, telco operators can reduce their carbon footprint, improve scalability and lower operational costs.
Manufacturing and Product Design Teams Achieve Faster, Cleaner Simulations
Many industries rely on computational fluid dynamics during design and engineering processes to model fluid flows, combustion, heat transfer and aeroacoustics. The aerospace and automotive industries use CFD to model vehicle aerodynamics, and the energy and environmental industries use it to optimize fluid-particle refining systems and model reactions, wind-farm air flow and hydro-plant water flow.
Traditional CFD methods are compute-intensive, using nearly 25 billion CPU core hours annually, and consume massive amounts of energy. This is a major obstacle for industrial companies looking to reduce carbon emissions and achieve net zero. Parallel computing with GPUs is making a difference.
Ansys, an engineering simulation company, is speeding up CFD physics models with GPUs to help customers drastically reduce emissions while improving the aerodynamics of vehicles. To measure computing efficiency, the company ran the benchmark DrivAer model, used for optimizing vehicle geometry, on different CPU and GPU configurations using its Fluent fluid-simulation software. Results showed that a single GPU achieved more than 5x greater performance than a cluster with 80 CPU cores. With eight GPUs, the simulation experienced more than a 30x speedup. And a server with six GPUs reduced power consumption 4x compared with a high performance computing CPU cluster delivering the same performance.
CPFD offers GPU parallelization for Barracuda Virtual Reactor, a physics-based engineering software package capable of predicting fluid, particulate-solid, thermal and chemically reacting behavior in fluidized bed reactors and other fluid-particle systems.
Using CPFD’s Barracuda software, green energy supplier ThermoChem Recovery International (TRI) developed technology that converts municipal solid waste and woody biomass into jet fuel. Since its partnership with CPFD began 14 years ago, TRI has benefitted from 1,500x model speedups as CPFD moved its code from CPU hardware to full GPU parallelization. With these exponential speedups, models that would’ve previously taken years to run can now be completed in a day or less, saving millions of dollars in data center infrastructure and energy costs.
With GPU parallelization and energy-efficient architectures, industrial design processes that rely on CFD can benefit from dramatically faster simulations while achieving significant energy savings.
Media and Entertainment Boost Rendering
Rendering visual effects (VFX) and stylized animations consumes nearly 10 billion CPU core hours per year in the media and entertainment industry. A single animated film can require over 50,000 CPU cores working for more than 300 million hours. Enabling this necessitates a large space for data centers, climate control and computing — all of which result in substantial expenditures and a sizable carbon footprint.
Accelerated computing offers a more energy-efficient way to produce VFX and animation, enabling studios to iterate faster and compress production times.
Studios like Wylie Co., known for visuals in the Oscar-winning film Dune and in HBO and Netflix features, are adopting GPU-powered rendering to improve performance and save energy. After migrating to GPU rendering, Wylie Co. realized a 24x performance boost over CPUs.
Image Engine, a VFX company involved in creating Marvel Entertainment movies and Star Wars-based television shows, observed a 25x performance improvement by using GPUs for rendering.
GPUs can increase performance up to 46x while reducing energy consumption by 10x and capital expenses by 6x. With accelerated computing, the media and entertainment industry has the potential to save a staggering $900 million in hardware acquisition costs worldwide and conserve 215 gigawatt hours of energy that would have been consumed by CPU-based render farms. Such a shift would lead to substantial cost savings and significant reductions in the industry’s environmental impact.
Robotics Developers Extend Battery Life for Important Missions
With edge AI and supercomputing now available using compact modules, demand for robots is surging for use in factory logistics, sales showrooms, urban delivery services and even ocean exploration. Mobile robot shipments are expected to climb from 549,000 units last year to 3 million by 2030, with revenue forecast to jump from more than $24 billion to $111 billion in the same period, according to ABI Research.
Most robots are battery-operated and rely on an array of lidar sensors and cameras for navigation. Robots communicate with edge servers or clouds for mission dispatch and require high throughput due to diverse sets of camera sensors as well as low latency for real-time decision-making. These factors necessitate energy-efficient onboard computing.
Accelerated edge computing can be optimized to decode images, process video and analyze lidar data to enable robot navigation of unstructured environments. This allows developers to build and deploy more energy-efficient machines that can remain in service for longer without needing to charge.
The Woods Hole Oceanographic Institution Autonomous Robotics and Perception Laboratory (WARPLab) and MIT are using the NVIDIA Jetson Orin platform for energy-efficient edge AI and robotics to power an autonomous underwater vehicle to study coral reefs.
The AUV, named CUREE, for Curious Underwater Robot for Ecosystem Exploration, gathers visual, audio and other environmental data to help understand the human impact on reefs and sea life. With 25% of the vehicle’s power needed for data collection, energy efficiency is a must. With Jetson Orin, CUREE constructs 3D models of reefs, tracks marine organisms and plant life, and autonomously navigates and gathers data. The AUV’s onboard energy-efficient computing also powers convolutional neural networks that enhance underwater vision by reducing backscatter and correcting colors. This enables CUREE to transmit clear images to scientists, facilitating fish detection and reef analysis.
Driverless smart tractors with energy-efficient edge computing are now available to help farmers with automation and data analysis. The Founder Series MK-V tractors, designed by NVIDIA Inception member Monarch Tractor, combine electrification, automation and data analysis to help farmers reduce their carbon footprint, improve field safety and streamline farming operations. Using onboard AI video analytics, the tractor can traverse rows of crops, enabling it to navigate even in remote areas without connectivity or GPS.
The MK-V tractor produces zero emissions and is estimated to save farmers $2,600 annually compared to diesel tractors. The tractor’s AI data analysis advises farmers on how to reduce the use of expensive, harmful herbicides that deplete the soil. Decreasing the volume of chemicals is a win all around, empowering farmers to protect the quality of soil, reduce herbicide expenditures and deliver more naturally cultivated produce to consumers.
As energy-efficient edge computing becomes more accessible to enable AI, expect to see growing use cases for mobile robots that can navigate complex environments, make split-second decisions, interact with humans and safely perform difficult tasks with precision.
Financial Services Use Data to Inform Investment Decisions
Financial services is an incredibly data-intensive industry. Bankers and asset managers pursuing the best results for investors rely on AI algorithms to churn through terabytes of unstructured data from economic indicators, earnings reports, news articles, and disparate environmental, social and governance metrics to generate market insight that inform investments. Plus, financial services companies must comb through network data and transactions to prevent fraud and protect accounts.
NVIDIA and Dell Technologies are optimizing computing for financial workloads to achieve higher throughput, speed and capacity with greater energy efficiency. The Strategic Technology Analysis Center, an organization dedicated to technology discovery and assessment in the finance industry, recently tested the STAC-A2 benchmark tests on several computing stacks comprising CPU-only infrastructure and GPU-based infrastructure. The STAC-A2 benchmark is designed by quants and technologists to measure the performance, scalability, quality and resource efficiency of technology stacks running market-risk analysis for derivatives.
When testing the STAC-A2 options pricing benchmark, the Dell PowerEdge server with NVIDIA GPUs performed 16x faster and 3x more energy efficiently than a CPU-only system for the same workload. This enables investment advisors to integrate larger bodies of data into derivatives risk-analysis calculations, enabling more data-driven decisions without increasing computing time or energy requirements.
PayPal, which was looking to deploy a new fraud-detection system to operate 24/7, worldwide and in real time to protect customer transactions, realized CPU-only servers couldn’t meet such computing requirements. Using NVIDIA GPUs for inference, PayPal improved real-time fraud detection by 10% and lowered server energy consumption by nearly 8x.
With accelerated computing, financial services organizations can run more iterations of investment scenarios, improve risk assessments and make more informed decisions for better investment results. Accelerated computing is the foundation for improving data throughput, reducing latency and optimizing energy usage to lower operating costs and achieve emissions goals.
An AI Future With Energy-Efficient Computing
With energy-efficient computing, enterprises can reduce data center costs and their carbon footprint while scaling AI initiatives and data workloads to stay competitive.
The NVIDIA accelerated computing platform offers a comprehensive suite of energy-efficient hardware and software to help enterprises use AI to drive innovation and efficiency without the need for equivalent growth in energy consumption.
With more than 100 frameworks, pretrained models and development tools optimized for GPUs, NVIDIA AI Enterprise accelerates the entire AI journey, from data preparation and model training to inference and scalable deployment. By getting their AI into production faster, businesses can significantly reduce overall power consumption.
With the NVIDIA RAPIDS Accelerator for Apache Spark, which is included with NVIDIA AI Enterprise, data analytics workloads can be completed 6x faster, translating to 5x savings on infrastructure and 6x less power used for the same amount of work. For a typical enterprise, this means 10 gigawatt hours less energy consumed compared with running jobs without GPU acceleration.
NVIDIA BlueField DPUs bring greater energy efficiency to data centers by offloading and accelerating data processing, networking and security tasks from the main CPU infrastructure. By maximizing performance per watt, they can help enterprises slash server power consumption by up to 30%, saving millions in data center costs.
As businesses shift to a new paradigm of AI-driven results, energy-efficient accelerated computing is helping organizations deliver on the promise of AI while controlling costs, maintaining sustainable practices and ensuring they can keep up with the pace of innovation.
Learn how accelerated computing can help organizations achieve both AI goals and carbon-footprint objectives.













 Posted by Dustin Zelle – Software Engineer, Research and Arno Eigenwillig – Software Engineer, CoreML
Posted by Dustin Zelle – Software Engineer, Research and Arno Eigenwillig – Software Engineer, CoreML

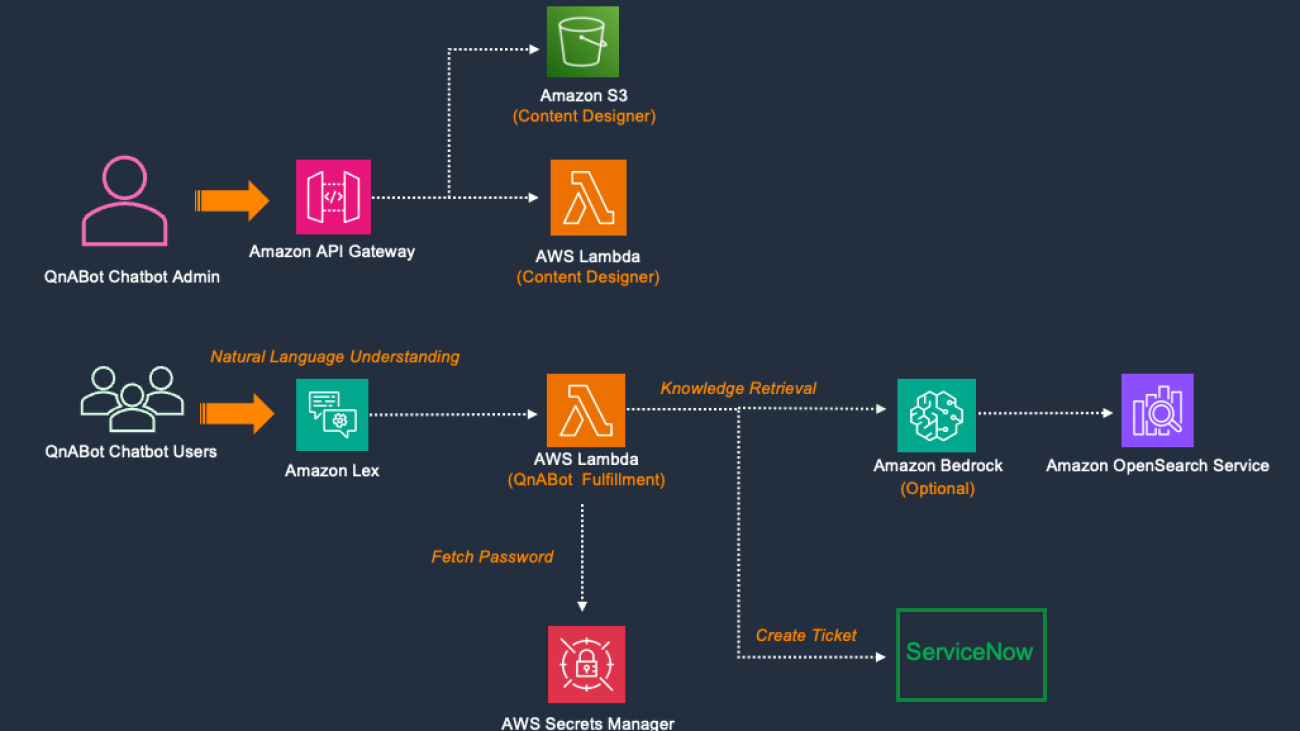




























 Sujatha Dantuluri is a Senior Solutions Architect in the US federal civilian team at AWS. She has over 20 years of experience supporting commercial and federal government. She works closely with customers in building and architecting mission-critical solutions. She has also contributed to IEEE standards.
Sujatha Dantuluri is a Senior Solutions Architect in the US federal civilian team at AWS. She has over 20 years of experience supporting commercial and federal government. She works closely with customers in building and architecting mission-critical solutions. She has also contributed to IEEE standards. Maia Haile is a Solutions Architect at Amazon Web Services based in the Washington, D.C. area. In that role, she helps public sector customers achieve their mission objectives with well-architected solutions on AWS. She has 5 years of experience spanning nonprofit healthcare, media and entertainment, and retail. Her passion is using AI and ML to help public sector customers achieve their business and technical goals.
Maia Haile is a Solutions Architect at Amazon Web Services based in the Washington, D.C. area. In that role, she helps public sector customers achieve their mission objectives with well-architected solutions on AWS. She has 5 years of experience spanning nonprofit healthcare, media and entertainment, and retail. Her passion is using AI and ML to help public sector customers achieve their business and technical goals.
 Zack Peterson is a data scientist in AWS Professional Services. He has been hands on delivering machine learning solutions to customers for many years and has a master’s degree in Economics.
Zack Peterson is a data scientist in AWS Professional Services. He has been hands on delivering machine learning solutions to customers for many years and has a master’s degree in Economics. Dr. Adewale Akinfaderin is a senior data scientist in Healthcare and Life Sciences at AWS. His expertise is in reproducible and end-to-end AI/ML methods, practical implementations, and helping global healthcare customers formulate and develop scalable solutions to interdisciplinary problems. He has two graduate degrees in Physics and a doctorate degree in Engineering.
Dr. Adewale Akinfaderin is a senior data scientist in Healthcare and Life Sciences at AWS. His expertise is in reproducible and end-to-end AI/ML methods, practical implementations, and helping global healthcare customers formulate and develop scalable solutions to interdisciplinary problems. He has two graduate degrees in Physics and a doctorate degree in Engineering. Ekta Walia Bhullar, PhD, is a senior AI/ML consultant with the AWS Healthcare and Life Sciences (HCLS) Professional Services business unit. She has extensive experience in the application of AI/ML within the healthcare domain, especially in radiology. Outside of work, when not discussing AI in radiology, she likes to run and hike.
Ekta Walia Bhullar, PhD, is a senior AI/ML consultant with the AWS Healthcare and Life Sciences (HCLS) Professional Services business unit. She has extensive experience in the application of AI/ML within the healthcare domain, especially in radiology. Outside of work, when not discussing AI in radiology, she likes to run and hike. Han Man is a Senior Data Science & Machine Learning Manager with AWS Professional Services based in San Diego, CA. He has a PhD in Engineering from Northwestern University and has several years of experience as a management consultant advising clients in manufacturing, financial services, and energy. Today, he is passionately working with key customers from a variety of industry verticals to develop and implement ML and generative AI solutions on AWS.
Han Man is a Senior Data Science & Machine Learning Manager with AWS Professional Services based in San Diego, CA. He has a PhD in Engineering from Northwestern University and has several years of experience as a management consultant advising clients in manufacturing, financial services, and energy. Today, he is passionately working with key customers from a variety of industry verticals to develop and implement ML and generative AI solutions on AWS.







 Davide Gallitelli is a Senior Specialist Solutions Architect for AI/ML. He is based in Brussels and works closely with customers all around the globe that are looking to adopt Low-Code/No-Code Machine Learning technologies, and Generative AI. He has been a developer since he was very young, starting to code at the age of 7. He started learning AI/ML at university, and has fallen in love with it since then.
Davide Gallitelli is a Senior Specialist Solutions Architect for AI/ML. He is based in Brussels and works closely with customers all around the globe that are looking to adopt Low-Code/No-Code Machine Learning technologies, and Generative AI. He has been a developer since he was very young, starting to code at the age of 7. He started learning AI/ML at university, and has fallen in love with it since then.
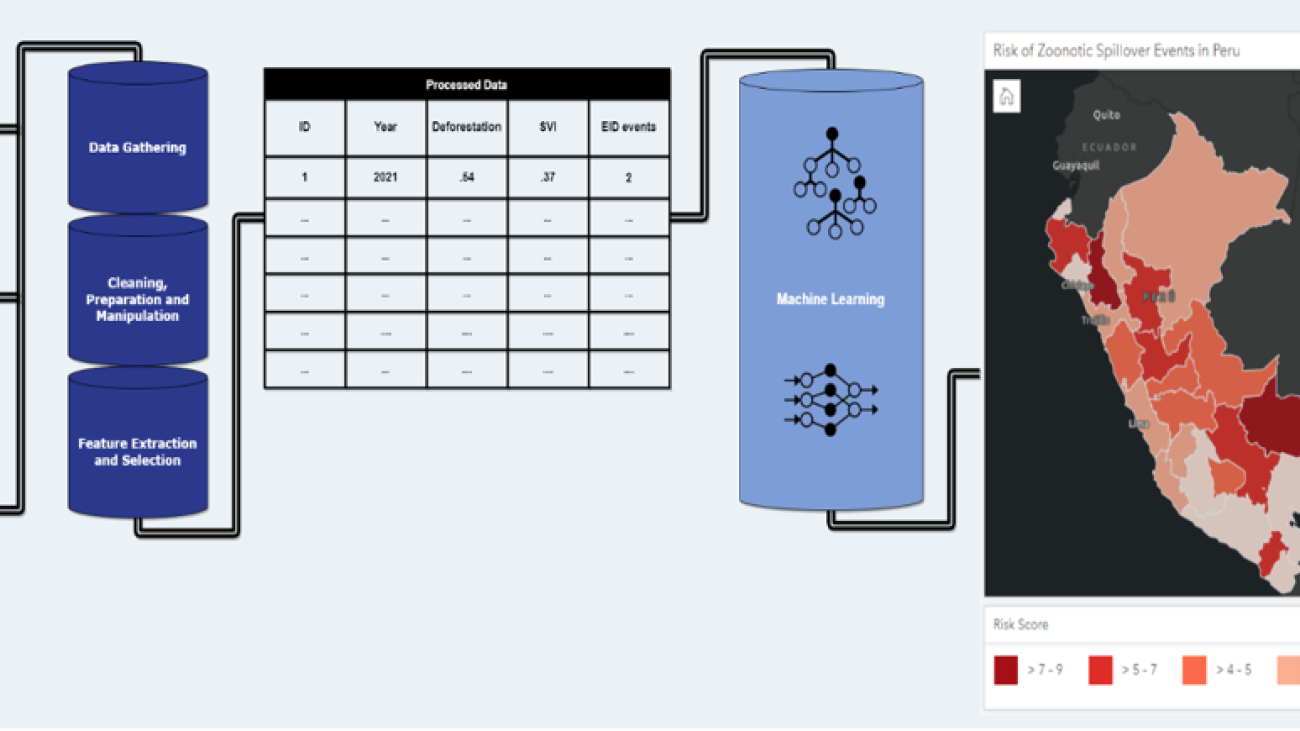




 Ajay K Gupta is Co-Founder and CEO of HSR.health, a firm that disrupts and innovates health risk analytics through geospatial tech and AI techniques to predict the spread and severity of disease. And provides these insights to industry, governments, and the health sector so they can anticipate, mitigate, and take advantage of future risks. Outside of work, you can find Ajay behind the mic bursting eardrums while belting out his favorite pop music tunes from U2, Sting, George Michael, or Imagine Dragons.
Ajay K Gupta is Co-Founder and CEO of HSR.health, a firm that disrupts and innovates health risk analytics through geospatial tech and AI techniques to predict the spread and severity of disease. And provides these insights to industry, governments, and the health sector so they can anticipate, mitigate, and take advantage of future risks. Outside of work, you can find Ajay behind the mic bursting eardrums while belting out his favorite pop music tunes from U2, Sting, George Michael, or Imagine Dragons. Jean Felipe Teotonio is a driven physician and passionate expert in healthcare quality and infectious disease epidemiology, Jean Felipe leads the HSR.health public health team. He works towards the shared goal of improving public health by reducing the global burden of disease by leveraging GeoAI approaches to develop solutions for the greatest health challenges of our time. Outside of work, his hobbies include reading sci fi books, hiking, the English premier league, and playing bass guitar.
Jean Felipe Teotonio is a driven physician and passionate expert in healthcare quality and infectious disease epidemiology, Jean Felipe leads the HSR.health public health team. He works towards the shared goal of improving public health by reducing the global burden of disease by leveraging GeoAI approaches to develop solutions for the greatest health challenges of our time. Outside of work, his hobbies include reading sci fi books, hiking, the English premier league, and playing bass guitar. Paul A Churchyard, CTO and Chief Geospatial Engineer for HSR.health, uses his broad technical skills and expertise to build the core infrastructure for the firm as well as its patented and proprietary GeoMD Platform. Additionally, he and the data science team incorporate geospatial analytics and AI/ML techniques into all health risk indices HSR.health produces. Outside of work, Paul is a self-taught DJ and loves snow.
Paul A Churchyard, CTO and Chief Geospatial Engineer for HSR.health, uses his broad technical skills and expertise to build the core infrastructure for the firm as well as its patented and proprietary GeoMD Platform. Additionally, he and the data science team incorporate geospatial analytics and AI/ML techniques into all health risk indices HSR.health produces. Outside of work, Paul is a self-taught DJ and loves snow. Janosch Woschitz is a Senior Solutions Architect at AWS, specializing in geospatial AI/ML. With over 15 years of experience, he supports customers globally in leveraging AI and ML for innovative solutions that capitalize on geospatial data. His expertise spans machine learning, data engineering, and scalable distributed systems, augmented by a strong background in software engineering and industry expertise in complex domains such as autonomous driving.
Janosch Woschitz is a Senior Solutions Architect at AWS, specializing in geospatial AI/ML. With over 15 years of experience, he supports customers globally in leveraging AI and ML for innovative solutions that capitalize on geospatial data. His expertise spans machine learning, data engineering, and scalable distributed systems, augmented by a strong background in software engineering and industry expertise in complex domains such as autonomous driving. Emmett Nelson is an Account Executive at AWS supporting Nonprofit Research customers across the Healthcare & Life Sciences, Earth / Environmental Sciences, and Education verticals. His primary focus is enabling use cases across analytics, AI/ML, high performance computing (HPC), genomics, and medical imaging. Emmett joined AWS in 2020 and is based in Austin, TX.
Emmett Nelson is an Account Executive at AWS supporting Nonprofit Research customers across the Healthcare & Life Sciences, Earth / Environmental Sciences, and Education verticals. His primary focus is enabling use cases across analytics, AI/ML, high performance computing (HPC), genomics, and medical imaging. Emmett joined AWS in 2020 and is based in Austin, TX.