 We’re incorporating generative AI in Maps, to help you discover things to do. Select U.S. Local Guides begin testing the feature this week.Read More
We’re incorporating generative AI in Maps, to help you discover things to do. Select U.S. Local Guides begin testing the feature this week.Read More

We’re incorporating generative AI in Maps, to help you discover things to do. Select U.S. Local Guides begin testing the feature this week.Read More

 We’re expanding Gemini Pro in Bard to all supported languages and bringing text-to-image generation into Bard.Read More
We’re expanding Gemini Pro in Bard to all supported languages and bringing text-to-image generation into Bard.Read More

 We’re rolling out Imagen 2, a major update to our image generation technology. Try it out today in Bard, Image FX, Search and Vertex AI.Read More
We’re rolling out Imagen 2, a major update to our image generation technology. Try it out today in Bard, Image FX, Search and Vertex AI.Read More
 ImageFX, MusicFX and TextFX help you bring your most creative ideas to life with Google’s latest AI capabilities.Read More
ImageFX, MusicFX and TextFX help you bring your most creative ideas to life with Google’s latest AI capabilities.Read More

We’re expanding Gemini Pro in Bard to all supported languages and bringing text-to-image generation into Bard.Read More

GeForce NOW is celebrating its fourth anniversary all month — plus an extra day for leap year — during February’s GFN Thursdays, with 2 new games joining the cloud. Keep an eye out for more new games and other announcements for members to come.

Diablo IV and Overwatch 2 heat up the cloud this GFN Thursday to kick off the anniversary celebrations. They’re the next Activision and Blizzard games to join GeForce NOW as part of the NVIDIA and Microsoft partnership, following Call of Duty.
The titles join the RAGE franchise as part of five new games joining the ever-expanding GeForce NOW library this week.

Follow the #4YearsofGFN celebration and get the latest cloud gaming news on the newly launched GeForce NOW Instagram and Threads channels. Use #GFNShare and tag these accounts for a chance to be featured.

Join the fight to protect the world of Sanctuary in the highly acclaimed online action role-playing game Diablo IV with the power of a GeForce RTX 4080 gaming rig in the cloud. Members can look forward to playing the Steam version, with support for the Battle.net launcher coming soon.
The battle between the High Heavens and Burning Hells rages on as chaos threatens to consume Sanctuary. Create customized characters and choose between five classes: Barbarian, Druid, Necromancer, Rogue and Sorcerer. Each features unique skills and talents to help in battle.
Jump into the dark, thrilling campaign solo or with friends. Explore a shared open world where players can form parties to take down World Bosses, or join the fray in player vs. player zones to test skills against others. Explore and loot over 120 monster-filled dungeons, and clear out Strongholds to use as safe havens for Sanctuary citizens.
Ultimate members can stand triumphant at up to 4K resolution and 120 frames per second with support for NVIDIA DLSS technology and experience the action even on low-powered devices.

Team up and answer the call of heroes in Overwatch 2, streaming today on GeForce NOW. Members can look forward to playing the Steam version, with support for the Battle.net launcher coming soon.
Overwatch 2 features 30+ epic heroes, each with game-changing abilities. Battle across all-new maps and modes in this ultimate team-based game. Lead the charge, ambush enemies or aid allies as one of Overwatch’s distinct heroes. Join the battle across dozens of futuristic maps inspired by real-world locations, and master unique game modes in the always-on, ever-evolving, live game.
Ultimate members can join the action with support for 4K and ultra-low latency. It’s the perfect upgrade for teammates on low-powered devices, ensuring everyone’s playing at heroic quality.

Get ready for action with this week’s five new additions, including the RAGE series:
And check out what’s coming throughout the rest of the month:
In addition to the 20 games announced last month, 14 more joined the GeForce NOW library:
Discussions with Spike Chunsoft have confirmed that the publisher’s games will remain on GeForce NOW. Members can continue to stream these titles from the cloud:
What are you looking forward to streaming? Let us know on X or in the comments below.
Who’s tryna be a hero in the cloud?
—
NVIDIA GeForce NOW (@NVIDIAGFN) January 31, 2024


In the Microsoft Research Podcast series What’s Your Story, Johannes Gehrke explores the who behind the technical and scientific advancements helping to reshape the world. A systems expert whose 10 years with Microsoft spans research and product, Gehrke talks to members of the company’s research community about what motivates their work and how they got where they are today.
Partner Software Architect Ivan Tashev’s expertise in audio signal processing has contributed to the design and study of audio components for Microsoft products such as Kinect, Teams, and HoloLens. In this episode, Tashev discusses how a first-place finish in the Mathematical Olympiad fueled a lifelong passion for shooting film; how a company event showcasing cutting-edge projects precipitated his move from product back to research; and how laser focus on things within his control has helped him find success in 25-plus years with Microsoft.

IVAN TASHEV: To succeed in Microsoft, you have to be laser focused on what you are doing. This is the thing you can change. Focus on the problems you have to solve, do your job, and be very good at it. Those are the most important rules I have used in my career in Microsoft.
[TEASER ENDS]JOHANNES GEHRKE: Microsoft Research works at the cutting edge. But how much do we know about the people behind the science and technology that we create? This is What’s Your Story, and I’m Johannes Gehrke. In my 10 years with Microsoft, across product and research, I’ve been continuously excited and inspired by the people I work with, and I’m curious about how they became the talented and passionate people they are today. So I sat down with some of them. Now, I’m sharing their stories with you. In this podcast series, you’ll hear from them about how they grew up, the critical choices that shaped their lives, and their advice to others looking to carve a similar path.
[MUSIC FADES]In this episode, I’m talking with Partner Software Architect Ivan Tashev in the anechoic chamber in Building 99 on our Redmond, Washington, campus. Constructed of concrete, rubber, and sound-absorbing panels, making it impervious to outside noise, this chamber has played a significant role in Ivan’s 25 years with Microsoft.
He’s put his expertise in audio processing to work in the space, helping to design and study the audio components of such products as Kinect, Teams, and HoloLens. Here’s my conversation with Ivan, beginning with his childhood in Bulgaria, where he was raised by two history teachers.
IVAN TASHEV: So I’m born in a city called Yambol in Bulgaria, my origin country. The city [was] created 2,000 years B.C. and now sits on the two shores of the river called Tundzha. It always has been an important transportation and agricultural center in the entire region, and I grew up there in a family of two lecturers. My parents were teaching history. And they loved to travel. So everywhere I go, I had two excellent tourist guides with me: “This in this place happened at this and this and this in this year.”
GEHRKE: Were there quizzes afterwards? [LAUGHTER]
TASHEV: But it happened that I was more fond to engineering, technology, math, all of the devices. It just … mechanical things just fascinated me. When I read in a book about the parachutes, I decided that I will have to try this and jump into it from the second floor of a building with an umbrella to see how much it will slow me down. It didn’t.
GEHRKE: And how … did you get hurt?
TASHEV: Oh, I ended with a twisted ankle for quite a while.
GEHRKE: Oh, OK, good. Nothing more … worse. [LAUGHTER] So you were always hands on, that’s what you’re telling me, right? Always the experimenter?
TASHEV: Yep. So I was doing a lot of this stuff, but also I was very strong in math. It happened that I had good teachers in math, and going to those competitions of mathematical Olympiads was something I started since fifth grade. Pretty much every year, they were well organized on school, city, regional level, and I remember how in my sixth grade, I won the first place of a regional Olympiad, and the prize was an 8mm movie camera. That, I would say, changed my life. This is my hobby since then. I have been holding this, a movie camera of several generations, everywhere I go and travel. In Moscow, in Kyiv, in Venice. Everywhere my parents were traveling, I was shooting 8mm films, and I continue this till today. Today, I have much better equipment but also very powerful computers to do the processing. I produce three to five Blu-ray Discs pretty much every year. Performances of the choir or the dancing groups in the Bulgarian Cultural and Heritage Center of Seattle mostly.
GEHRKE: Wow, that’s fascinating. And was that hobby somehow connected to your, you know, entry into, you know, science and then actually doing a PhD and then actually going and, you know, going into audio, audio processing?
TASHEV: The mathematical high school I attended in my … in the city where I’m born was one of the fifth … one of the five strongest in the country, which means first, math every day, two days, twice; physics every day. Around ninth grade, at the end, we finished the entire high school curriculum and started to study differentials and integrals, something which is more towards the university math courses. But this means that I had no problems entering any of the, of the universities with mathematical exams. I didn’t even have to do that because I qualified in one year, my 11th grade, to become member of the Bulgarian national teams in … for the International Math Olympia and for International Physics Olympia. And they actually coincided, so I had to choose one, and I chose physics. And since then, I’m actually saying that math is the language of physics; physics is the language of engineering. And that kind of showed the tendency … so literally, I was 11th grade and I could literally point and choose any of the universities, and I decided to go and study electronic engineering in the Technical University of Sofia.
GEHRKE: And then how did you end up in the US?
TASHEV: So that’s another interesting story. I defended my … graduated from the university, defended my PhD thesis. It was something amazing.
GEHRKE: What was it on, actually?
TASHEV: It was a control system for a telescope. But not just for observation of celestial objects but for tracking and ranging the distance to a satellite. It’s literally one measurement. You shoot with the laser; it goes to the satellite, which is 60 centimeters in diameter; it returns back; and you measure the time with accuracy of 100 picoseconds. And this was part of studying how the Earth rotates, how the satellites move. The data … there were around 44 stations like this in the entire Earth, and the data were public and used by NASA for finalizing the models for the satellites, which later all became GPS; used by Russians to finalize the models for their GLONASS system; used by people who studied the precession and the rotation of the Earth. A lot of interesting PhD theses came from the data from the results of this device, including tides. For example, I found that Balkan Peninsula moves up and down 2 meters every day because of the tides. So the Earth is liquid inside, and there are tides under us in the same way as with the oceans.
GEHRKE: Oh, wow, super interesting. I actually just wanted to come back … so just to get the right kind of comparison for the, for the unit, and so picoseconds, right? Because I know what a nanosecond is because …
TASHEV: Nanoseconds is 1-0 minus ninth; picoseconds is 1-0 minus 12th.
GEHRKE: OK. Good, good. Just to put that in perspective.
TASHEV: Thank you, Johannes. To, to be exact. So this was the, the accuracy. The light goes 30 centimeters for that time. For one nanosecond. And we needed to go way shorter than that. But why this project was so fascinating for me … can you imagine this is 1988—people having Apple II on compatible computers playing with the joystick a very famous game when you have the crosshair in the space and you shoot with laser the satellites.
GEHRKE: [LAUGHS] Absolutely.
TASHEV: And I was sitting behind the ocular and moving a joystick and shooting at real satellites. [LAUGHS]
GEHRKE: Not with the goal to destroy them, of course.
TASHEV: No. The energy of the laser was one joule. You can put your hand in front. But very short and one nanosecond. So it can go and enter and you have the resolution to measure the distance.
GEHRKE: Super, super exciting.
TASHEV: And after that, I became assistant professor in the Technical University of Sofia. How I came to Microsoft is a consequence of that. So I was teaching data and signal processing, and the changes in Europe already started. Think about 1996. And then a friend of mine came back from a scientific institution from the former Eastern Germany, and he basically shared how much money West Germany has poured into the East German economy to change it, to bring it up to the standards, and that … it was, I think, 900 billion Deutsche Marks.
GEHRKE: But this was after the …
TASHEV: After the changes. After, after basically the East and West Germany united. And then this was in the first nine years of the changes. And then we looked at each other in the eyes and said, wait a minute. If you model this as a first-order system, this is the time constant, and the process will finish after two times more of the time constant, and they will need another 900 billion Marks. You cannot imagine how exact became that prediction when East Germany will be on equal economically to the West Germany. But then we looked at each other’s eyes and said, what about Bulgaria? We don’t have West Bulgaria. And then this started to make me think that most probably there will be technical universal software, but in this economical crisis, there will be no money for research, none for development, for building skills, for going to conferences. And then pretty much around the same time, somebody said, hey, you know, Microsoft is coming here to hire. And I sent my résumé knowing that, OK, I’m an assistant professor. I can program. But that actually happened that I can program quite well, implementing all of those control systems for the telescope, etc., etc., and literally …
GEHRKE: And so there was a programming testing as part of the interview?
TASHEV: Oh, the interview questions were three or four people, one hour, asking programming questions. The opening was for a software engineer.
GEHRKE: Like on a whiteboard?
TASHEV: Like on a whiteboard. And then I got an email saying that, Ivan, we liked your performance. We want to bring you to Redmond for further interviews. I flew here in 1997. After the interviews, I returned to my hotel, and the offer was waiting for me on the reception.
GEHRKE: Wow, that’s fast.
TASHEV: So this is how we decided to move here in Redmond, and I started and went through two full shipping cycles of programs.
GEHRKE: So you didn’t start out in MSR (Microsoft Research), right?
TASHEV: Nope.
GEHRKE: Where were you first?
TASHEV: So, actually, I was lucky enough both products were version 1.0. One of them was COM+. This is the transactional server and the COM technology, which is the backbone of Windows.
GEHRKE: Was the component model being used at that point in time?
TASHEV: Component object model. Basically, creating an object, calling … getting the interface, and calling the methods there. And my experience with low-level programming on assembly language and microprocessor actually became here very handy. We shipped this as a part of Windows 2000. And the second product was the Microsoft Application Center 2000, which was, OK, cluster management system.
GEHRKE: But both of them had nothing to do with signal processing, right?
TASHEV: Nope. Except there were some load balancing in Application Center. But they had nothing to do with signal processing; just pure programming skills.
GEHRKE: Right.
TASHEV: And then in the year of 2000, there was the first TechFest, and I went to see it and said, wait a minute. There are PhDs in this company and they’re doing this amazing research? My place is here.
GEHRKE: And TechFest, maybe … do you want to explain briefly what TechFest is?
TASHEV: TechFest is an annual event when researchers from Microsoft Research go and show and demonstrate technologies they have created.
GEHRKE: So it used to be, like, in the Microsoft Conference Center.
TASHEV: It used to be in the Microsoft Conference Center …
GEHRKE: Like, a really big two-day event …
TASHEV: … and basically visited by 6, 7,000 Microsoft employees. And usually, Microsoft Research, all of the branches were showing around 150ish demos, and it was amazing. And that was the first such event. Pretty much …
GEHRKE: Oh, the very first time?
TASHEV: The very first TechFest. And pretty much not only me, but the rest of Microsoft Corporation learning that we do have a research organization. In short, in three months, I started in Microsoft Research.
GEHRKE: How did you get a job here then? How did that happen?
TASHEV: So … seriously, visiting TechFest made me to think seriously that I should return back to research, and I opened the career website with potential openings, and there were two suitable for me. One of them was in Rico Malvar’s Signal Processing Group …
GEHRKE: Oh, OK, yeah …
TASHEV: … and the other was in Communication, Collaboration, and Multimedia Group led by Anoop Gupta. So I sent my résumé to both of them. Anoop replied in 15 minutes; next week, I was on informational with him. When Rico replied, I already had an offer from Anoop to join the team. [LAUGHS]
GEHRKE: Got it. And that’s, that’s where your focus on communication came from then?
TASHEV: Yes. So our first project was RingCam.
GEHRKE: OK.
TASHEV: So it’s a 360-camera, eight-element microphone array in the base, and the purpose was to record the meetings, to do a, a meeting diarization, to have a 360 view, but also, based on the signal processing and face detection, to have a speaker view, separate camera for the whiteboard, diarization based on who is speaking based on the direction from the microphone array. Honestly, even today when you read our 2002 paper … Ross Cutler was creator of the 360 camera; I was doing the microphone array. Even today when you read our 2002 paper, you say, wow, that was something super exciting and super advanced.
GEHRKE: And that then you brought it all the way to shipping, right, and it became a Microsoft product?
TASHEV: So yes. At some point, it was actually monitored personally by Bill Gates, and at some point …
GEHRKE: So he was PMing it, basically, or …? [LAUGHS]
TASHEV: He basically was …
GEHRKE: He was just aware of it.
TASHEV: I personally stole the distributed meeting system in Bill Gates’ conference room.
GEHRKE: Wow.
TASHEV: We do have basically 360 images with Bill Gates attending a meeting. But anyway, it was believed that this is something important, and a product team was formed to make it a product. Ross Cutler left Microsoft Research and became architect of that team, and this is what became Microsoft RoundTable device. It was licensed to Polycom, and for many years was sold as Polycom [CX5000].
GEHRKE: Yeah, actually, I remember when I was in many meetings, they used to have exactly that device in the middle, and the nice thing was that even if somebody was remote, right, you could see all the people around the table and you got this, sort of, really nice view of who was next to whom and not sort of the transactional windows that you have right now in Teams. That’s a really interesting view.
TASHEV: So, as you can see, very exciting start. [LAUGHS] But then Anoop went and became Bill Gates’ technical assistant, and the signal processing people from his team were merged with Rico Malvar’s signal processing team, and this is how I continued to work on microphone arrays and the speech enhancement, and this is what I do till today.
GEHRKE: And you mentioned, like, amazing products from Microsoft like Kinect and so on, right. And so you were involved in the, like, audio processing layer of all of those, and they were actually then … part of it was designed here in this room?
TASHEV: Yep.
GEHRKE: So tell me a little bit more about how that happened.
TASHEV: You know, at the time, I was fascinated by a problem which was considered theoretically impossible: multichannel acoustic echo cancellation. There was a paper written in 1998 by the inventor of the acoustic echo cancellation from Bell Labs stating that stereo acoustic echo cancellation is not possible.
GEHRKE: And he proved it, or what does it mean? He just …
TASHEV: It’s very simple. You have two unknowns—the two impulse responses from the left and the right loudspeaker—and one equation; that’s the microphone signal. What I did was to circumvent this. When you start Kinect, you’ll hear some melodic signals, and this is the calibration. At least you know the relation between the two unknowns, and now you have one unknown, which is basically discovered using an adaptive filter, the classic acoustic echo cancellation. So technically, Kinect became the first device ever shipped with surround sound acoustic echo cancellation, the first device ever that could recognize human speech from 4 1/2 meters while the loudspeakers are blasting. And gamers are listening to very loud levels of their loudspeakers.
GEHRKE: So maybe just tell the audience a little bit, what does it mean to do acoustic echo cancellation? What is it actually good for, and what does it do?
TASHEV: So in general, speech enhancement is removing unwanted noises and sounds from the desired signal. Some of them we don’t know anything about, which is the surrounding noise. For some of them, we have a pretty good understanding. This is the sound from our own loudspeakers. So you send the signal to the loudspeakers and then try to estimate on the fly how much of it is captured by the microphone and subtract this estimation, and this is called acoustic echo cancellation. This is part of every single speakerphone. This is one of the oldest applications of the adaptive filtering.
GEHRKE: So would the right way to think about this is that noise cancellation is cancelling unwanted noise from the outside?
TASHEV: Unknown noises …
GEHRKE: … whereas acoustic echo cancellation is cancelling the own noise that actually comes …
TASHEV: … which we know about.
GEHRKE: Right, OK.
TASHEV: And that was an amazing work, but … it also started actually in TechFest. I designed this surround sound echo cancellation, and my target was … at the time, we had Windows Media Center. It was a device designed to stay in the media room and controlling all of those loudspeakers. And I made sure to bring all of the VPs of Windows and Windows Media Center, and then I noticed that I started repeatedly to see some faces which I didn’t invite—I didn’t know—but they came over and over and over. And after the meeting, after TechFest, a person called me and said, “Look, we are working on a thing which your technology fits very well,” and this is how I started to work for Kinect. And in the process of the work, I had to go and talk with industrial designers because of the design of the microphones, with electrical designers because of the circuitry and the requirements for identical microphone channels, and with the software team, which had to implement my algorithms, and this … actually, at some point, I had an office in their building and was literally embedded working with them day and night, especially at the end of the shipping cycle, of the shipping cycle when the device had to go out.
GEHRKE: And this was not a time when you could go, like, in the device and, you know, update software on the device or anything. The device would go out as is, right?
TASHEV: Actually, this was one of the first devices like that.
GEHRKE: Oh, it could?
TASHEV: Yup.
GEHRKE: Wow, I didn’t know that.
TASHEV: Already Kinects were manufactured. They are boxed; they are already distributed to the, to the stores. But there was a deadline when we had to provide the image when you connected Kinect to your Xbox and it has to be uploaded.
GEHRKE: But, no, I get that. But then once it was actually connected to the Xbox, you could still update the firmware on the …
TASHEV: Yes, yes.
GEHRKE: Oh, wow. That’s, that’s really cool. OK.
TASHEV: But it also has a deadline. So that was amazing. Literally left us, all of us, breathless. There are plenty of serious technological challenges to overcome. A lot of firsts as a technology is, basically, was brought to this device to make sure … and this is the audio. And next to us were the video people and the gaming people and the designers, and everybody was excited to be working like hell so we can basically bring this to the customers.
GEHRKE: Wow, that’s super exciting. I mean even just being involved in … I think that’s one of the really big things that is so much fun here at Microsoft, right, that you can get whatever you do in the hands of, you know, millions—if not hundreds of millions—of people, right. Coming, coming back to, you know, your work now in, in audio signal processing, and that whole field is also being revolutionized like many other fields right now with AI, right.
TASHEV: Absolutely.
GEHRKE: Photography, one of the other fields that you’re very passionate about, is also being revolutionized with AI, of course.
TASHEV: Also revolutionized.
GEHRKE: You know, in, in terms of changes that you’ve made in your career, how do you deal with such changes, and what were … you know, this is something where you have been an expert in a certain class of algorithms, and now suddenly it says there’s this completely new technology coming along, and we need to shift. How are you dealing with this? How did you deal with this, personally?
TASHEV: Let me put it in …
GEHRKE: In some sense, you’re becoming a little bit of a dinosaur in a little bit while …
TASHEV: Oh, not at all.
GEHRKE: That’s what I’m saying.
TASHEV: I wouldn’t be in research! [LAUGHS]
GEHRKE: Exactly. How did you overcome that?
TASHEV: So, first, each one of us was working and trying to produce better and better technology, and at the time, the signal processing, speech enhancement, most of the audio processing was based on statistical signal processing. You build statistical models, distributions, hidden Markov models, and get …
GEHRKE: Like speech recognition.
TASHEV: … certain improvements. Yep. And all of us started to sense that this set of tools we have started to saturate. And it was simple. We use the simple models we can derive. Let’s say speech is Gaussian distribution; noise is Gaussian distribution. You derive the suppression rule. But this is simplifying the reality. If you apply a more precise model of the speech signal distribution, then you cannot derive easily the suppression rule, for example, in the case of noise suppression. And it was literally hanging in the air that we have to find a way, a way to learn from data. And I have several papers, actually before the neural networks start to appear, that let’s get a big dataset and learn from the data this suppression rule.
GEHRKE: So a more data-driven approach already.
TASHEV: Data-driven approach. I have several papers from that, and by the way, they were not quite well accepted by my audio processing community. All of them are published on bordering conferences, not in the core conferences. I got those papers rejected. But then appeared neural networks. Not that they were something new. We had neural networks in ’80s, and they didn’t work well. The new … the miracle was that now we had an algorithm which allows us to train them. Literally, next year after the work of Geoff Hinton was published in the Implementation of Deep Learning, several things happened. At first, my colleagues in the speech research group started to do neural network–based speech recognition, and I, in my audio group, started to do neural network–based speech enhancement. This is the year of 2013 or 2014. We had the speech, neural network–based speech enhancement algorithm surpassing the existing statistical signal processing algorithm literally instantly. It was big. It was heavy. But better.
GEHRKE: When did the first of these ship? What … can you tell any interesting ship stories about this?
TASHEV: The first neural network–based speech enhancement algorithm was shipped in 2020 in Teams.
GEHRKE: OK, OK.
TASHEV: We had to work with that team for quite a while. Actually, four years took us to work with Teams to find … you see, here in the research, industrial research lab we have a little bit different perspective. It’s not just to make it work; it’s not just to make it a technology. That technology has to be shippable. It has to meet a lot of other requirements and limitations in memory and in CPU and in reliability. It’s one thing to publish a paper with very cool results with your limited dataset and completely different to throw this algorithm in the wild, where it can face everything. And this is why it cost us around four years before to ship the first prototype in Teams.
GEHRKE: That, that makes sense. And I think a lot of the infrastructure was also not there at that point in time early on, right, in terms of, you know, how do you upload a model to the client, even in terms of all the model profiling, you know, neural architecture search, quantization, and other tooling that now exists where you can take a model …
TASHEV: That’s correct.
GEHRKE: … and squeeze it on the right kind of computation for the …
TASHEV: That’s correct. And …
GEHRKE: So you did all of that manually, I guess, at that point in time.
TASHEV: Initially, yes. But new architectures arrived. The cloud. Wow, it was a savior. You can press a button; you can get a hundred or thousand machines. You can run in parallel multiple architectures. You can really select the optimal from every single standpoint. Actually, what we did is we ended up with a set of speech enhancement algorithms. Given computing power, we can tell you what is the best architecture for this, or if you want to hit up this improvement, I can tell you how much CPU you will need for that.
GEHRKE: Got it.
TASHEV: But that tradeoff is also something very typical for industrial research lab and not very well understood in academia.
GEHRKE: Makes sense. Let me, let me switch gears one last time, namely, I mean, you have made quite a few changes in your career, you know, throughout, right. You started as an assistant professor and then became, sort of, a core developer, then, you know, were a member of a signal processing group and now you’re, sort of, driving a lot of the audio processing research for the company. How do you deal with this change, and do you have any advice for our listeners on how to, you know, keep your career going, especially as the rate of change seems to be accelerating all the time?
TASHEV: So for 25 years in Microsoft Corporation, I have learned several rules I follow. The first is dealing with ambiguity. It is not just change in the technology but changes in the … of the teams and organizations, etc., etc. Simply put, there are things you cannot change. There are things you cannot hide. Just accept them and go on. And here comes the second rule. To succeed in Microsoft, you have to be laser focused on what you are doing. This is the thing you can change. Focus on the problems you have to solve, do your job, and be very good at it. This is the most important … those are the two most important rules I have used in my career in Microsoft.
GEHRKE: OK, super, super interesting, Ivan. Thank you very much for this amazing conversation.
TASHEV: Thank you for the invitation, Johannes.
GEHRKE: To learn more about Ivan’s work or to see photos of Ivan pursuing his passion for shooting film and video, visit aka.ms/ResearcherStories (opens in new tab).
The post What’s Your Story: Ivan Tashev appeared first on Microsoft Research.

 Google Health is investing in groundbreaking health tech research, apprenticeships and upskilling in the South Yorkshire region.Read More
Google Health is investing in groundbreaking health tech research, apprenticeships and upskilling in the South Yorkshire region.Read More
Greetings to the PyTorch community! Here is a quick update on PyTorch docs.
In November 2023, we successfully conducted a PyTorch Docathon, a community event where PyTorch community members gathered together to improve PyTorch documentation and tutorials. This event saw a global participation of contributors who dedicated their time and effort to enhance our docs. We extend our sincere gratitude to everyone involved.
A key accomplishment of the Docathon was the comprehensive work carried out on docstrings. Our community contributors meticulously reviewed and improved the docstrings based on the provided tasks.
In addition to that, we’ve added three new tutorials that showcase real-world applications of PyTorch. We are particularly proud that two of these tutorials were contributed by PyTorch ecosystem partners.
Here is the new tutorials for you to explore:
We’re planning more community events this year, so stay tuned!
And finally, we just published new 2.2 PyTorch documentation and tutorials. Check it out!
Best regards,
The PyTorch Team
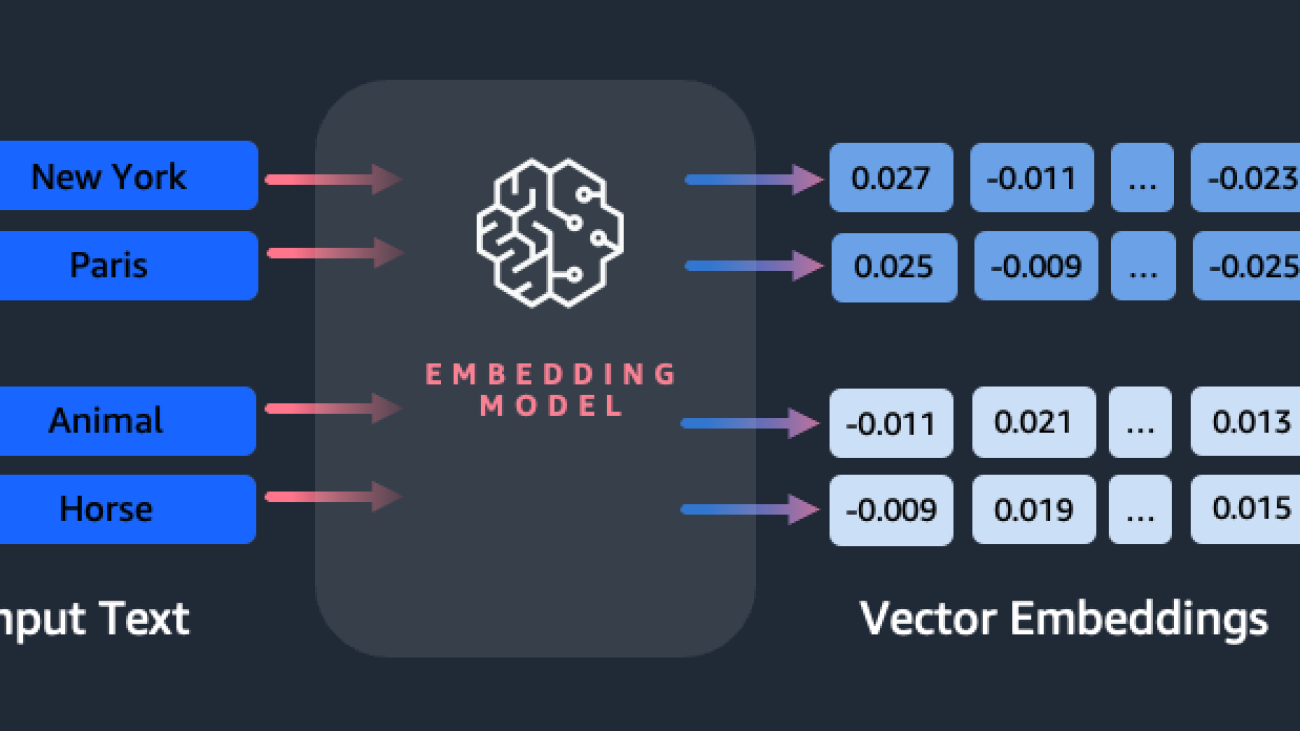
Embeddings play a key role in natural language processing (NLP) and machine learning (ML). Text embedding refers to the process of transforming text into numerical representations that reside in a high-dimensional vector space. This technique is achieved through the use of ML algorithms that enable the understanding of the meaning and context of data (semantic relationships) and the learning of complex relationships and patterns within the data (syntactic relationships). You can use the resulting vector representations for a wide range of applications, such as information retrieval, text classification, natural language processing, and many others.
Amazon Titan Text Embeddings is a text embeddings model that converts natural language text—consisting of single words, phrases, or even large documents—into numerical representations that can be used to power use cases such as search, personalization, and clustering based on semantic similarity.
In this post, we discuss the Amazon Titan Text Embeddings model, its features, and example use cases.
Some key concepts include:
There are multiple techniques to convert a sentence into a vector. One popular method is using word embeddings algorithms, such as Word2Vec, GloVe, or FastText, and then aggregating the word embeddings to form a sentence-level vector representation.
Another common approach is to use large language models (LLMs), like BERT or GPT, which can provide contextualized embeddings for entire sentences. These models are based on deep learning architectures such as Transformers, which can capture the contextual information and relationships between words in a sentence more effectively.

Vector embeddings are fundamental for LLMs to understand the semantic degrees of language, and also enable LLMs to perform well on downstream NLP tasks like sentiment analysis, named entity recognition, and text classification.
In addition to semantic search, you can use embeddings to augment your prompts for more accurate results through Retrieval Augmented Generation (RAG)—but in order to use them, you’ll need to store them in a database with vector capabilities.

The Amazon Titan Text Embeddings model is optimized for text retrieval to enable RAG use cases. It enables you to first convert your text data into numerical representations or vectors, and then use those vectors to accurately search for relevant passages from a vector database, allowing you to make the most of your proprietary data in combination with other foundation models.
Because Amazon Titan Text Embeddings is a managed model on Amazon Bedrock, it’s offered as an entirely serverless experience. You can use it via either the Amazon Bedrock REST API or the AWS SDK. The required parameters are the text that you would like to generate the embeddings of and the modelID parameter, which represents the name of the Amazon Titan Text Embeddings model. The following code is an example using the AWS SDK for Python (Boto3):
The output will look something like the following:
Refer to Amazon Bedrock boto3 Setup for more details on how to install the required packages, connect to Amazon Bedrock, and invoke models.
With Amazon Titan Text Embeddings, you can input up to 8,000 tokens, making it well suited to work with single words, phrases, or entire documents based on your use case. Amazon Titan returns output vectors of dimension 1536, giving it a high degree of accuracy, while also optimizing for low-latency, cost-effective results.
Amazon Titan Text Embeddings supports creating and querying embeddings for text in over 25 different languages. This means you can apply the model to your use cases without needing to create and maintain separate models for each language you want to support.
Having a single embeddings model trained on many languages provides the following key benefits:
As of this writing, the following languages are supported:
LangChain is a popular open source framework for working with generative AI models and supporting technologies. It includes a BedrockEmbeddings client that conveniently wraps the Boto3 SDK with an abstraction layer. The BedrockEmbeddings client allows you to work with text and embeddings directly, without knowing the details of the JSON request or response structures. The following is a simple example:
You can also use LangChain’s BedrockEmbeddings client alongside the Amazon Bedrock LLM client to simplify implementing RAG, semantic search, and other embeddings-related patterns.
Although RAG is currently the most popular use case for working with embeddings, there are many other use cases where embeddings can be applied. The following are some additional scenarios where you can use embeddings to solve specific problems, either on their own or in cooperation with an LLM:
In our example on GitHub, we demonstrate a simple embeddings search application with Amazon Titan Text Embeddings, LangChain, and Streamlit.
The example matches a user’s query to the closest entries in an in-memory vector database. We then display those matches directly in the user interface. This can be useful if you want to troubleshoot a RAG application, or directly evaluate an embeddings model.
For simplicity, we use the in-memory FAISS database to store and search for embeddings vectors. In a real-world scenario at scale, you will likely want to use a persistent data store like the vector engine for Amazon OpenSearch Serverless or the pgvector extension for PostgreSQL.
Try a few prompts from the web application in different languages, such as the following:
Note that even though the source material was in English, the queries in other languages were matched with relevant entries.
The text generation capabilities of foundation models are very exciting, but it’s important to remember that understanding text, finding relevant content from a body of knowledge, and making connections between passages are crucial to achieving the full value of generative AI. We will continue to see new and interesting use cases for embeddings emerge over the next years as these models continue to improve.
You can find additional examples of embeddings as notebooks or demo applications in the following workshops:
 Jason Stehle is a Senior Solutions Architect at AWS, based in the New England area. He works with customers to align AWS capabilities with their greatest business challenges. Outside of work, he spends his time building things and watching comic book movies with his family.
Jason Stehle is a Senior Solutions Architect at AWS, based in the New England area. He works with customers to align AWS capabilities with their greatest business challenges. Outside of work, he spends his time building things and watching comic book movies with his family.
 Nitin Eusebius is a Sr. Enterprise Solutions Architect at AWS, experienced in Software Engineering, Enterprise Architecture, and AI/ML. He is deeply passionate about exploring the possibilities of generative AI. He collaborates with customers to help them build well-architected applications on the AWS platform, and is dedicated to solving technology challenges and assisting with their cloud journey.
Nitin Eusebius is a Sr. Enterprise Solutions Architect at AWS, experienced in Software Engineering, Enterprise Architecture, and AI/ML. He is deeply passionate about exploring the possibilities of generative AI. He collaborates with customers to help them build well-architected applications on the AWS platform, and is dedicated to solving technology challenges and assisting with their cloud journey.
 Raj Pathak is a Principal Solutions Architect and Technical Advisor to large Fortune 50 companies and mid-sized financial services institutions (FSI) across Canada and the United States. He specializes in machine learning applications such as generative AI, natural language processing, intelligent document processing, and MLOps.
Raj Pathak is a Principal Solutions Architect and Technical Advisor to large Fortune 50 companies and mid-sized financial services institutions (FSI) across Canada and the United States. He specializes in machine learning applications such as generative AI, natural language processing, intelligent document processing, and MLOps.
 Mani Khanuja is a Tech Lead – Generative AI Specialists, author of the book – Applied Machine Learning and High Performance Computing on AWS, and a member of the Board of Directors for Women in Manufacturing Education Foundation Board. She leads machine learning (ML) projects in various domains such as computer vision, natural language processing and generative AI. She helps customers to build, train and deploy large machine learning models at scale. She speaks in internal and external conferences such re:Invent, Women in Manufacturing West, YouTube webinars and GHC 23. In her free time, she likes to go for long runs along the beach.
Mani Khanuja is a Tech Lead – Generative AI Specialists, author of the book – Applied Machine Learning and High Performance Computing on AWS, and a member of the Board of Directors for Women in Manufacturing Education Foundation Board. She leads machine learning (ML) projects in various domains such as computer vision, natural language processing and generative AI. She helps customers to build, train and deploy large machine learning models at scale. She speaks in internal and external conferences such re:Invent, Women in Manufacturing West, YouTube webinars and GHC 23. In her free time, she likes to go for long runs along the beach.
 Mark Roy is a Principal Machine Learning Architect for AWS, helping customers design and build AI/ML solutions. Mark’s work covers a wide range of ML use cases, with a primary interest in computer vision, deep learning, and scaling ML across the enterprise. He has helped companies in many industries, including insurance, financial services, media and entertainment, healthcare, utilities, and manufacturing. Mark holds six AWS Certifications, including the ML Specialty Certification. Prior to joining AWS, Mark was an architect, developer, and technology leader for over 25 years, including 19 years in financial services.
Mark Roy is a Principal Machine Learning Architect for AWS, helping customers design and build AI/ML solutions. Mark’s work covers a wide range of ML use cases, with a primary interest in computer vision, deep learning, and scaling ML across the enterprise. He has helped companies in many industries, including insurance, financial services, media and entertainment, healthcare, utilities, and manufacturing. Mark holds six AWS Certifications, including the ML Specialty Certification. Prior to joining AWS, Mark was an architect, developer, and technology leader for over 25 years, including 19 years in financial services.
