 Learn about the nonprofits joining our newest accelerator focused on generative AI.Read More
Learn about the nonprofits joining our newest accelerator focused on generative AI.Read More

Learn about the nonprofits joining our newest accelerator focused on generative AI.Read More

 We’re sharing a few insights from a survey with nonprofits about how they’re using generative AI.Read More
We’re sharing a few insights from a survey with nonprofits about how they’re using generative AI.Read More

From designing dream cars to customizing clothing, 3D product configurators are ringing in a new era of hyper-personalization that will benefit retailers and consumers.
Developers are delivering innovative virtual product experiences and automated personalization using Universal Scene Description (aka OpenUSD), NVIDIA RTX technologies from NVIDIA Omniverse software development kits (SDKs) and application programming interfaces (APIs), and generative AI from NVIDIA Edify models.
Together, these technologies enable developers to create configurator applications that deliver physically accurate, photoreal digital twins of products, revolutionizing the way brands personalize buyer journeys at unprecedented scale.
For example, Dassault Systèmes’ 3DEXCITE brand is adopting Omniverse Cloud APIs to enable interoperability with generative AI services, such as Shutterstock’s Edify3D or Edify 360, directly inside its web-based application.
By using NVIDIA Edify-powered models, trained by Shutterstock, Dassault Systèmes can generate stunning 3D environments from text prompts to instantly personalize scenes representing physically accurate products. And with Omniverse APIs, the company can supercharge the web-based app with real-time ray-traced rendering.
Many other developers are also building 3D product configurator software and solutions with NVIDIA Omniverse SDKs and APIs.
CGI studio Katana has developed a content creation application, COATCreate, used by manufacturers such as Nissan, that allows marketing assets to be staged and created faster with product digital twins. COATCreate also enables users to view and customize the digital twin while wearing an Apple Vision Pro headset, unlocking real-time ray-traced extended reality experiences.

Brickland, another CGI studio, is developing real-time virtual experiences that allow users to customize clothing by choosing from predefined parameters such as color and material. Through their Digitex initiative, Brickland is expanding into digital textures and allowing consumers to visualize and interact with extreme levels of detail in their 3D assets thanks to RTX real-time rendering
Configit connected its powerful configurator logic tool Configit Ace to Omniverse and OpenUSD by streamlining the management of the complex rules system behind the creation of configurators and combining it with the rendering capabilities of Omniverse and RTX. This allows for rapid creation of articulated product configurators and enables the configurator developers to power real-time ray-traced rendering in their solutions.

WPP has developed a content engine that harnesses OpenUSD and AI to enable creative teams to produce high-quality commercial content faster, more efficiently and at scale while remaining aligned with a client’s brand.
Media.Monks has developed an AI-centric professional managed service that leverages Omniverse called Monks.Flow, which helps brands virtually explore different customizable product designs and unlock scale and hyper-personalization across any customer journey.
Accenture Song, the world’s largest tech-powered creative group, is using Omniverse SDKs to generate marketing content for Defender vehicles. Using it with the Edify-powered generative AI microservice, Accenture Song is enabling the creation of cinematic 3D environments via conversational prompts.
Forecasts indicate that consumer purchases, including high-value items like vehicles and luxury goods, will increasingly take place online in the coming decade. 3D product digital twins and automated personalization with generative AI serve as invaluable tools for brands to showcase their products and enhance customer engagement in the changing retail landscape.
3D configurators provide tangible benefits for businesses, including increased average selling prices, reduced return rates and stronger brand loyalty. Once a digital twin is built, it can serve many purposes and be updated to meet shifting consumer preferences with minimal time, cost and effort.
The process of creating a 3D product configurator begins with harnessing OpenUSD’s powerful composition engine and interoperability. These features enable developers to create dynamic, interactive experiences that accurately reflect the nuances of each product.
Teams can also integrate generative AI technologies into OpenUSD-based product configurators using NVIDIA Omniverse APIs to enhance the realism and customization options available to users. By leveraging AI, configurators can intelligently adapt to user inputs, offering personalized recommendations and dynamically adjusting product configurations in real time. And with NVIDIA Graphics Delivery Network , high-quality, real-time viewports can be embedded into web applications so consumers can browse products in full fidelity, on nearly any device.
The possibilities for 3D product configurators are virtually limitless, applicable across a wide range of industries and use cases.
To start, get NVIDIA Omniverse and follow along with a tutorial series.
In software engineering, there is a direct correlation between team performance and building robust, stable applications. The data community aims to adopt the rigorous engineering principles commonly used in software development into their own practices, which includes systematic approaches to design, development, testing, and maintenance. This requires carefully combining applications and metrics to provide complete awareness, accuracy, and control. It means evaluating all aspects of a team’s performance, with a focus on continuous improvement, and it applies just as much to mainframe as it does to distributed and cloud environments—maybe more.
This is achieved through practices like infrastructure as code (IaC) for deployments, automated testing, application observability, and complete application lifecycle ownership. Through years of research, the DevOps Research and Assessment (DORA) team has identified four key metrics that indicate the performance of a software development team:
These metrics provide a quantitative way to measure the effectiveness and efficiency of DevOps practices. Although much of the focus around analysis of DevOps is on distributed and cloud technologies, the mainframe still maintains a unique and powerful position, and it can use the DORA 4 metrics to further its reputation as the engine of commerce.
This blog post discusses how BMC Software added AWS Generative AI capabilities to its product BMC AMI zAdviser Enterprise. The zAdviser uses Amazon Bedrock to provide summarization, analysis, and recommendations for improvement based on the DORA metrics data.
Tracking DORA 4 metrics means putting the numbers together and placing them on a dashboard. However, measuring productivity is essentially measuring the performance of individuals, which can make them feel scrutinized. This situation might necessitate a shift in organizational culture to focus on collective achievements and emphasize that automation tools enhance the developer experience.
It’s also vital to avoid focusing on irrelevant metrics or excessively tracking data. The essence of DORA metrics is to distill information into a core set of key performance indicators (KPIs) for evaluation. Mean time to restore (MTTR) is often the simplest KPI to track—most organizations use tools like BMC Helix ITSM or others that record events and issue tracking.
Capturing lead time for changes and change failure rate can be more challenging, especially on mainframes. Lead time for changes and change failure rate KPIs aggregate data from code commits, log files, and automated test results. Using a Git-based SCM pulls these insight together seamlessly. Mainframe teams using BMC’s Git-based DevOps platform, AMI DevX ,can collect this data as easily as distributed teams can.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon via a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsible AI.
BMC AMI zAdviser Enterprise provides a wide range of DevOps KPIs to optimize mainframe development and enable teams to proactvely identify and resolve issues. Using machine learning, AMI zAdviser monitors mainframe build, test and deploy functions across DevOps tool chains and then offers AI-led recommendations for continuous improvement. In addition to capturing and reporting on development KPIs, zAdviser captures data on how the BMC DevX products are adopted and used. This includes the number of programs that were debugged, the outcome of testing efforts using the DevX testing tools, and many other data points. These additional data points can provide deeper insight into the development KPIs, including the DORA metrics, and may be used in future generative AI efforts with Amazon Bedrock.
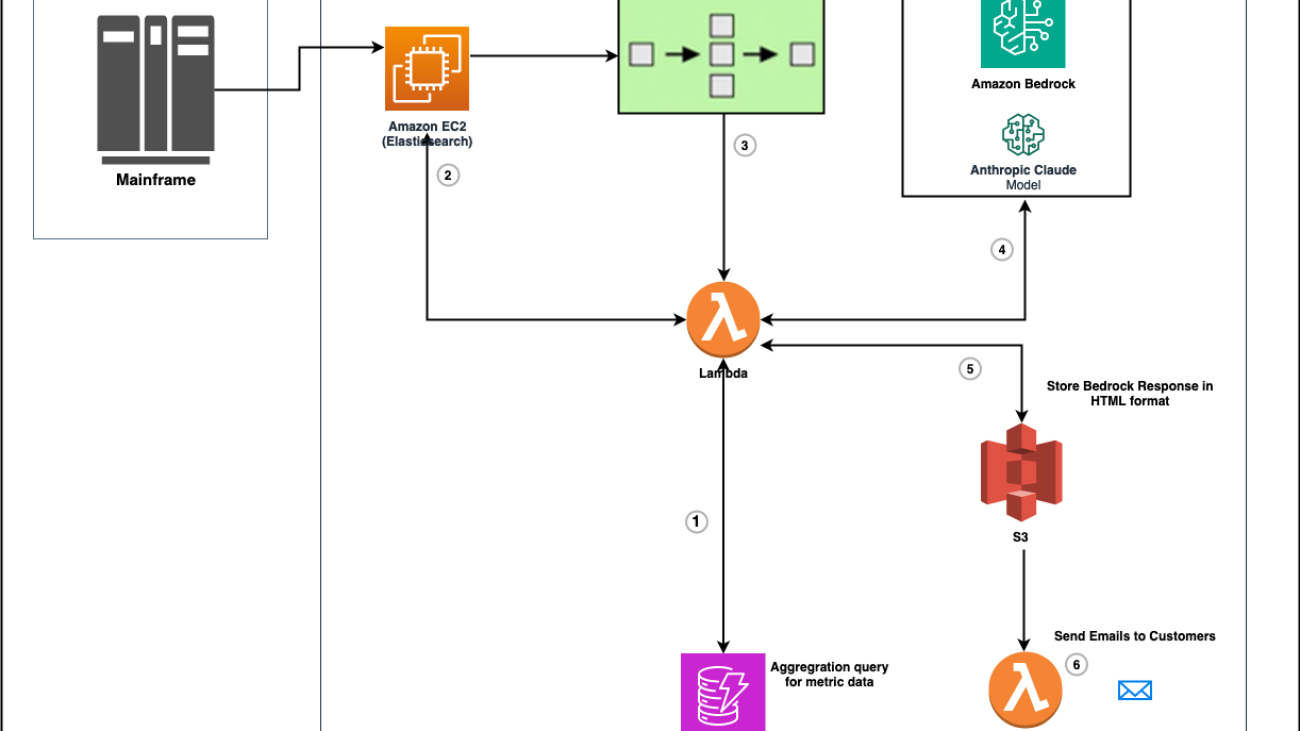
The following architecture diagram shows the final implementation of zAdviser Enterprise utilizing generative AI to provide summarization, analysis, and recommendations for improvement based on the DORA metrics KPI data.

The solution workflow includes the following steps:
The following screenshot shows the LLM summarization of DORA metrics generated using Amazon Bedrock and sent as an email to the customer, with a PDF attachment that contains the DORA metrics KPI dashboard report by zAdviser.

In this solution, you don’t need to worry about your data being exposed on the internet when sent to an AI client. The API call to Amazon Bedrock doesn’t contain any personally identifiable information (PII) or any data that could identify a customer. The only data transmitted consists of numerical values in the form of the DORA metric KPIs and instructions for the generative AI’s operations. Importantly, the generative AI client does not retain, learn from, or cache this data.
The zAdviser engineering team was successful in rapidly implementing this feature within a short time span. The rapid progress was facilitated by zAdviser’s substantial investment in AWS services and, importantly, the ease of using Amazon Bedrock via API calls. This underscores the transformative power of generative AI technology embodied in the Amazon Bedrock API. This API, equipped with the industry-specific knowledge repository zAdviser Enterprise and customized with continuously collected organization-specific DevOps metrics, demonstrates the potential of AI in this field.
Generative AI has the potential to lower the barrier to entry to build AI-driven organizations. Large language models (LLMs) in particular can bring tremendous value to enterprises seeking to explore and use unstructured data. Beyond chatbots, LLMs can be used in a variety of tasks, such as classification, editing, and summarization.
This post discussed the transformational impact of generative AI technology in the form of Amazon Bedrock APIs equipped with the industry-specific knowledge that BMC zAdviser possesses, tailored with organization-specific DevOps metrics collected on an ongoing basis.
Check out the BMC website to learn more and set up a demo.
 Sunil Bemarkar is a Sr. Partner Solutions Architect at Amazon Web Services. He works with various Independent Software Vendors (ISVs) and Strategic customers across industries to accelerate their digital transformation journey and cloud adoption.
Sunil Bemarkar is a Sr. Partner Solutions Architect at Amazon Web Services. He works with various Independent Software Vendors (ISVs) and Strategic customers across industries to accelerate their digital transformation journey and cloud adoption.
 Vij Balakrishna is a Senior Partner Development manager at Amazon Web Services. She helps independent software vendors (ISVs) across industries to accelerate their digital transformation journey.
Vij Balakrishna is a Senior Partner Development manager at Amazon Web Services. She helps independent software vendors (ISVs) across industries to accelerate their digital transformation journey.
 Spencer Hallman is the Lead Product Manager for the BMC AMI zAdviser Enterprise. Previously, he was the Product Manager for BMC AMI Strobe and BMC AMI Ops Automation for Batch Thruput. Prior to Product Management, Spencer was the Subject Matter Expert for Mainframe Performance. His diverse experience over the years has also included programming on multiple platforms and languages as well as working in the Operations Research field. He has a Master of Business Administration with a concentration in Operations Research from Temple University and a Bachelor of Science in Computer Science from the University of Vermont. He lives in Devon, PA and when he’s not attending virtual meetings, enjoys walking his dogs, riding his bike and spending time with his family.
Spencer Hallman is the Lead Product Manager for the BMC AMI zAdviser Enterprise. Previously, he was the Product Manager for BMC AMI Strobe and BMC AMI Ops Automation for Batch Thruput. Prior to Product Management, Spencer was the Subject Matter Expert for Mainframe Performance. His diverse experience over the years has also included programming on multiple platforms and languages as well as working in the Operations Research field. He has a Master of Business Administration with a concentration in Operations Research from Temple University and a Bachelor of Science in Computer Science from the University of Vermont. He lives in Devon, PA and when he’s not attending virtual meetings, enjoys walking his dogs, riding his bike and spending time with his family.

Amazon Titan lmage Generator G1 is a cutting-edge text-to-image model, available via Amazon Bedrock, that is able to understand prompts describing multiple objects in various contexts and captures these relevant details in the images it generates. It is available in US East (N. Virginia) and US West (Oregon) AWS Regions and can perform advanced image editing tasks such as smart cropping, in-painting, and background changes. However, users would like to adapt the model to unique characteristics in custom datasets that the model is not already trained on. Custom datasets can include highly proprietary data that is consistent with your brand guidelines or specific styles such as a previous campaign. To address these use cases and generate fully personalized images, you can fine-tune Amazon Titan Image Generator with your own data using custom models for Amazon Bedrock.
From generating images to editing them, text-to-image models have broad applications across industries. They can enhance employee creativity and provide the ability to imagine new possibilities simply with textual descriptions. For example, it can aid design and floor planning for architects and allow faster innovation by providing the ability to visualize various designs without the manual process of creating them. Similarly, it can aid in design across various industries such as manufacturing, fashion design in retail, and game design by streamlining the generation of graphics and illustrations. Text-to-image models also enhance your customer experience by allowing for personalized advertising as well as interactive and immersive visual chatbots in media and entertainment use cases.
In this post, we guide you through the process of fine-tuning the Amazon Titan Image Generator model to learn two new categories: Ron the dog and Smila the cat, our favorite pets. We discuss how to prepare your data for the model fine-tuning task and how to create a model customization job in Amazon Bedrock. Finally, we show you how to test and deploy your fine-tuned model with Provisioned Throughput.
 |
 |
| Ron the dog | Smila the cat |
Foundation models are trained on large amounts of data, so it is possible that your model will work well enough out of the box. That’s why it’s good practice to check if you actually need to fine-tune your model for your use case or if prompt engineering is sufficient. Let’s try to generate some images of Ron the dog and Smila the cat with the base Amazon Titan Image Generator model, as shown in the following screenshots.


As expected, the out-of-the-box model does not know Ron and Smila yet, and the generated outputs show different dogs and cats. With some prompt engineering, we can provide more details to get closer to the look of our favorite pets.


Although the generated images are more similar to Ron and Smila, we see that the model is not able to reproduce the full likeness of them. Let’s now start a fine-tuning job with the photos from Ron and Smila to get consistent, personalized outputs.
Amazon Bedrock provides you with a serverless experience for fine-tuning your Amazon Titan Image Generator model. You only need to prepare your data and select your hyperparameters, and AWS will handle the heavy lifting for you.
When you use the Amazon Titan Image Generator model to fine-tune, a copy of this model is created in the AWS model development account, owned and managed by AWS, and a model customization job is created. This job then accesses the fine-tuning data from a VPC and the amazon Titan model has its weights updated. The new model is then saved to an Amazon Simple Storage Service (Amazon S3) located in the same model development account as the pre-trained model. It can now be used for inference only by your account and is not shared with any other AWS account. When running inference, you access this model via a provisioned capacity compute or directly, using batch inference for Amazon Bedrock. Independently from the inference modality chosen, your data remains in your account and is not copied to any AWS owned account or used to improve the Amazon Titan Image Generator model.
The following diagram illustrates this workflow.

Your data used for fine-tuning including prompts, as well as the custom models, remain private in your AWS account. They are not shared or used for model training or service improvements, and aren’t shared with third-party model providers. All the data used for fine-tuning is encrypted in transit and at rest. The data remains in the same Region where the API call is processed. You can also use AWS PrivateLink to create a private connection between the AWS account where your data resides and the VPC.
Before you can create a model customization job, you need to prepare your training dataset. The format of your training dataset depends on the type of customization job you are creating (fine-tuning or continued pre-training) and the modality of your data (text-to-text, text-to-image, or image-to-embedding). For the Amazon Titan Image Generator model, you need to provide the images that you want to use for the fine-tuning and a caption for each image. Amazon Bedrock expects your images to be stored on Amazon S3 and the pairs of images and captions to be provided in a JSONL format with multiple JSON lines.
Each JSON line is a sample containing an image-ref, the S3 URI for an image, and a caption that includes a textual prompt for the image. Your images must be in JPEG or PNG format. The following code shows an example of the format:
{"image-ref": "s3://bucket/path/to/image001.png", "caption": "<prompt text>"}
{"image-ref": "s3://bucket/path/to/image002.png", "caption": "<prompt text>"}
{"image-ref": "s3://bucket/path/to/image003.png", "caption": "<prompt text>"}
Because “Ron” and “Smila” are names that could also be used in other contexts, such as a person’s name, we add the identifiers “Ron the dog” and “Smila the cat” when creating the prompt to fine-tune our model. Although it’s not a requirement for the fine-tuning workflow, this additional information provides more contextual clarity for the model when it is being customized for the new classes and will avoid the confusion of ‘“Ron the dog” with a person called Ron and “Smila the cat” with the city Smila in Ukraine. Using this logic, the following images show a sample of our training dataset.
 |
 |
 |
| Ron the dog laying on a white dog bed | Ron the dog sitting on a tile floor | Ron the dog laying on a car seat |
 |
 |
 |
| Smila the cat lying on a couch | Smila the cat staring at the camera laying on a couch | Smila the cat laying in a pet carrier |
When transforming our data to the format expected by the customization job, we get the following sample structure:
{"image-ref": "<S3_BUCKET_URL>/ron_01.jpg", "caption": "Ron the dog laying on a white dog bed"}
{"image-ref": "<S3_BUCKET_URL>/ron_02.jpg", "caption": "Ron the dog sitting on a tile floor"}
{"image-ref": "<S3_BUCKET_URL>/ron_03.jpg", "caption": "Ron the dog laying on a car seat"}
{"image-ref": "<S3_BUCKET_URL>/smila_01.jpg", "caption": "Smila the cat lying on a couch"}
{"image-ref": "<S3_BUCKET_URL>/smila_02.jpg", "caption": "Smila the cat sitting next to the window next to a statue cat"}
{"image-ref": "<S3_BUCKET_URL>/smila_03.jpg", "caption": "Smila the cat lying on a pet carrier"}
After we have created our JSONL file, we need to store it on an S3 bucket to start our customization job. Amazon Titan Image Generator G1 fine-tuning jobs will work with 5–10,000 images. For the example discussed in this post, we use 60 images: 30 of Ron the dog and 30 of Smila the cat. In general, providing more varieties of the style or class you are trying to learn will improve the accuracy of your fine-tuned model. However, the more images you use for fine-tuning, the more time will be required for the fine-tuning job to complete. The number of images used also influence the pricing of your fine-tuned job. Refer to Amazon Bedrock Pricing for more information.
Now that we have our training data ready, we can begin a new customization job. This process can be done both via the Amazon Bedrock console or APIs. To use the Amazon Bedrock console, complete the following steps:

| Number of images provided | 8 | 32 | 64 | 1,000 | 10,000 |
| Number of steps recommended | 1,000 | 4,000 | 8,000 | 10,000 | 12,000 |
If the results of your fine-tuning job are not satisfactory, consider increasing the number of steps if you don’t observe any signs of the style in generated images, and decreasing the number of steps if you observe the style in the generated images but with artifacts or blurriness. If the fine-tuned model fails to learn the unique style in your dataset even after 40,000 steps, consider increasing the batch size or the learning rate.
This authorization enables Amazon Bedrock to retrieve input and validation datasets from your designated bucket and store validation outputs seamlessly in your S3 bucket.

With the correct configurations set, Amazon Bedrock will now train your custom model.
After you create custom model, Provisioned Throughput allows you to allocate a predetermined, fixed rate of processing capacity to the custom model. This allocation provides a consistent level of performance and capacity for handling workloads, which results in better performance in production workloads. The second advantage of Provisioned Throughput is cost control, because standard token-based pricing with on-demand inference mode can be difficult to predict at large scales.
When the fine tuning of your model is complete, this model will appear on the Custom models’ page on the Amazon Bedrock console.
To purchase Provisioned Throughput, select the custom model that you just fine-tuned and choose Purchase Provisioned Throughput.

This prepopulates the selected model for which you want to purchase Provisioned Throughput. For testing your fine-tuned model before deployment, set model units to a value of 1 and set the commitment term to No commitment. This quickly lets you start testing your models with your custom prompts and check if the training is adequate. Moreover, when new fine-tuned models and new versions are available, you can update the Provisioned Throughput as long as you update it with other versions of the same model.

For our task of customizing the model on Ron the dog and Smila the cat, experiments showed that the best hyperparameters were 5,000 steps with a batch size of 8 and a learning rate of 1e-5.
The following are some examples of the images generated by the customized model.
 |
 |
 |
| Ron the dog wearing a superhero cape | Ron the dog on the moon | Ron the dog in a swimming pool with sunglasses |
 |
 |
 |
| Smila the cat on the snow | Smila the cat in black and white staring at the camera | Smila the cat wearing a Christmas hat |
In this post, we discussed when to use fine-tuning instead of engineering your prompts for better-quality image generation. We showed how to fine-tune the Amazon Titan Image Generator model and deploy the custom model on Amazon Bedrock. We also provided general guidelines on how to prepare your data for fine-tuning and set optimal hyperparameters for more accurate model customization.
As a next step, you can adapt the following example to your use case to generate hyper-personalized images using Amazon Titan Image Generator.
 Maira Ladeira Tanke is a Senior Generative AI Data Scientist at AWS. With a background in machine learning, she has over 10 years of experience architecting and building AI applications with customers across industries. As a technical lead, she helps customers accelerate their achievement of business value through generative AI solutions on Amazon Bedrock. In her free time, Maira enjoys traveling, playing with her cat Smila, and spending time with her family someplace warm.
Maira Ladeira Tanke is a Senior Generative AI Data Scientist at AWS. With a background in machine learning, she has over 10 years of experience architecting and building AI applications with customers across industries. As a technical lead, she helps customers accelerate their achievement of business value through generative AI solutions on Amazon Bedrock. In her free time, Maira enjoys traveling, playing with her cat Smila, and spending time with her family someplace warm.
 Dani Mitchell is an AI/ML Specialist Solutions Architect at Amazon Web Services. He is focused on computer vision use cases and helping customers across EMEA accelerate their ML journey.
Dani Mitchell is an AI/ML Specialist Solutions Architect at Amazon Web Services. He is focused on computer vision use cases and helping customers across EMEA accelerate their ML journey.
 Bharathi Srinivasan is a Data Scientist at AWS Professional Services, where she loves to build cool things on Amazon Bedrock. She is passionate about driving business value from machine learning applications, with a focus on responsible AI. Outside of building new AI experiences for customers, Bharathi loves to write science fiction and challenge herself with endurance sports.
Bharathi Srinivasan is a Data Scientist at AWS Professional Services, where she loves to build cool things on Amazon Bedrock. She is passionate about driving business value from machine learning applications, with a focus on responsible AI. Outside of building new AI experiences for customers, Bharathi loves to write science fiction and challenge herself with endurance sports.
 Achin Jain is an Applied Scientist with the Amazon Artificial General Intelligence (AGI) team. He has expertise in text-to-image models and is focused on building the Amazon Titan Image Generator.
Achin Jain is an Applied Scientist with the Amazon Artificial General Intelligence (AGI) team. He has expertise in text-to-image models and is focused on building the Amazon Titan Image Generator.

It’s official: NVIDIA delivered the world’s fastest platform in industry-standard tests for inference on generative AI.
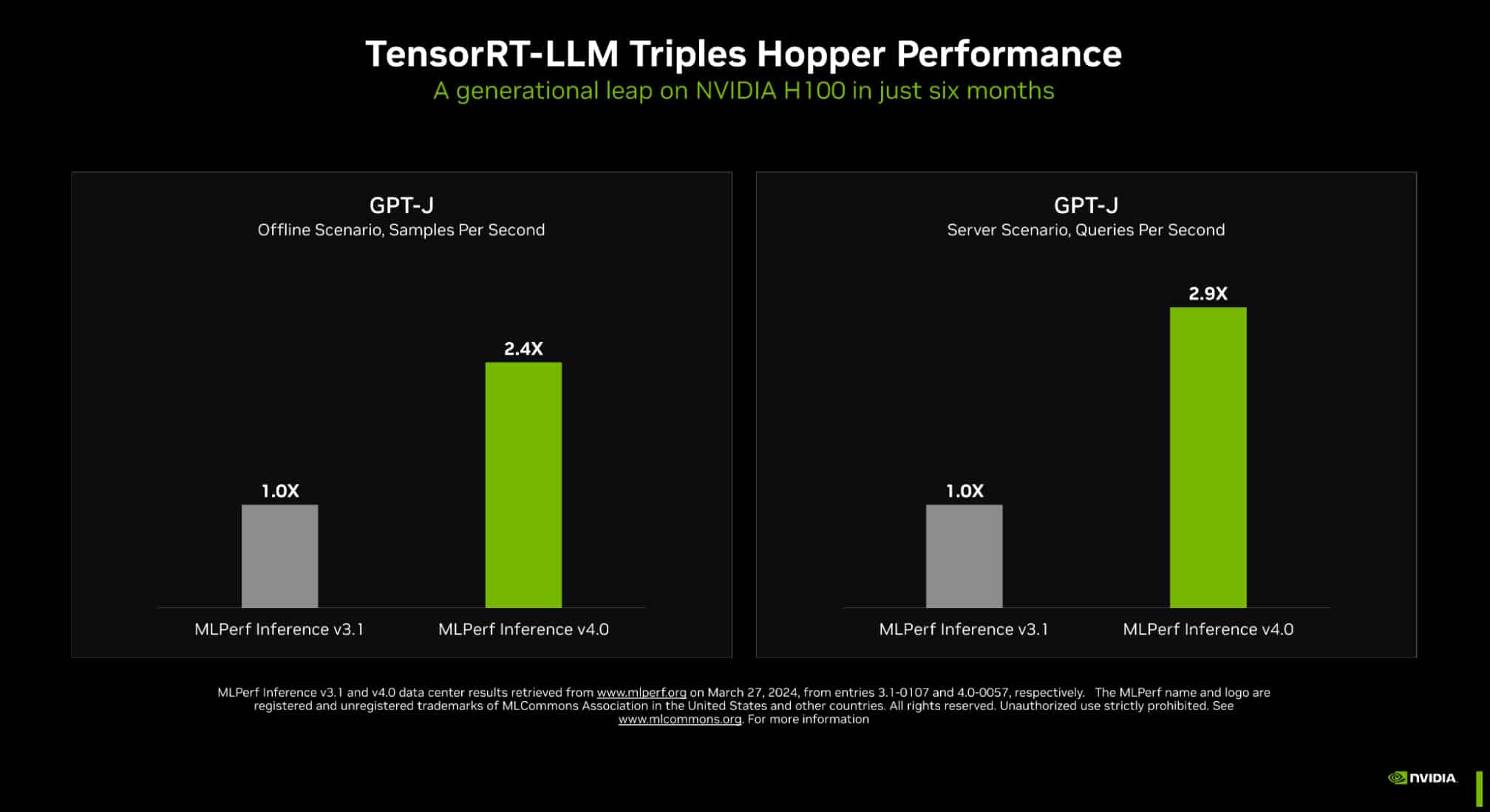
In the latest MLPerf benchmarks, NVIDIA TensorRT-LLM — software that speeds and simplifies the complex job of inference on large language models — boosted the performance of NVIDIA Hopper architecture GPUs on the GPT-J LLM nearly 3x over their results just six months ago.
The dramatic speedup demonstrates the power of NVIDIA’s full-stack platform of chips, systems and software to handle the demanding requirements of running generative AI.
Leading companies are using TensorRT-LLM to optimize their models. And NVIDIA NIM — a set of inference microservices that includes inferencing engines like TensorRT-LLM — makes it easier than ever for businesses to deploy NVIDIA’s inference platform.
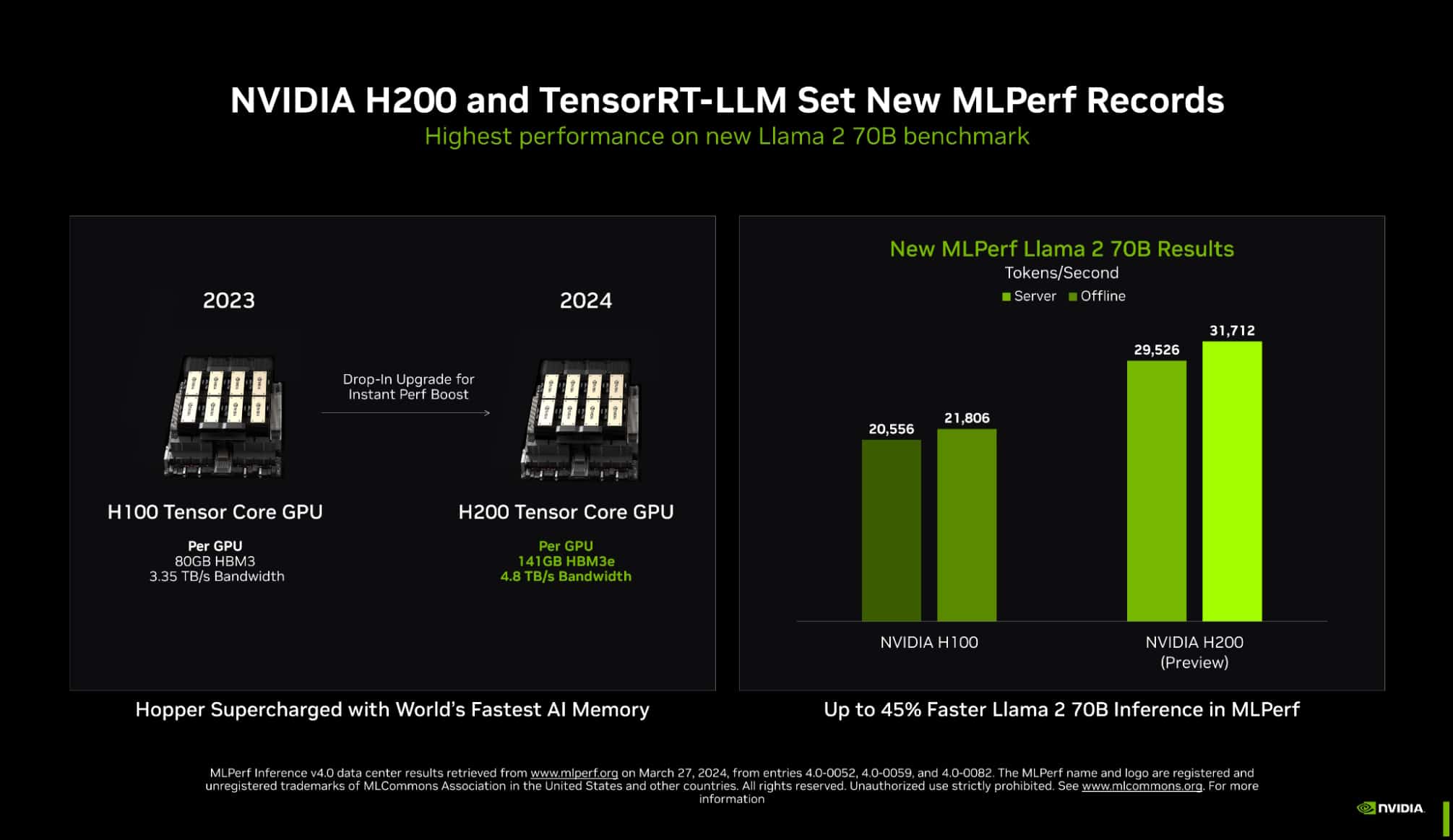
TensorRT-LLM running on NVIDIA H200 Tensor Core GPUs — the latest, memory-enhanced Hopper GPUs — delivered the fastest performance running inference in MLPerf’s biggest test of generative AI to date.
The new benchmark uses the largest version of Llama 2, a state-of-the-art large language model packing 70 billion parameters. The model is more than 10x larger than the GPT-J LLM first used in the September benchmarks.
The memory-enhanced H200 GPUs, in their MLPerf debut, used TensorRT-LLM to produce up to 31,000 tokens/second, a record on MLPerf’s Llama 2 benchmark.
The H200 GPU results include up to 14% gains from a custom thermal solution. It’s one example of innovations beyond standard air cooling that systems builders are applying to their NVIDIA MGX designs to take the performance of Hopper GPUs to new heights.
NVIDIA is shipping H200 GPUs today. They’ll be available soon from nearly 20 leading system builders and cloud service providers.
H200 GPUs pack 141GB of HBM3e running at 4.8TB/s. That’s 76% more memory flying 43% faster compared to H100 GPUs. These accelerators plug into the same boards and systems and use the same software as H100 GPUs.
With HBM3e memory, a single H200 GPU can run an entire Llama 2 70B model with the highest throughput, simplifying and speeding inference.
Even more memory — up to 624GB of fast memory, including 144GB of HBM3e — is packed in NVIDIA GH200 Superchips, which combine on one module a Hopper architecture GPU and a power-efficient NVIDIA Grace CPU. NVIDIA accelerators are the first to use HBM3e memory technology.
With nearly 5 TB/second memory bandwidth, GH200 Superchips delivered standout performance, including on memory-intensive MLPerf tests such as recommender systems.
On a per-accelerator basis, Hopper GPUs swept every test of AI inference in the latest round of the MLPerf industry benchmarks.
The benchmarks cover today’s most popular AI workloads and scenarios, including generative AI, recommendation systems, natural language processing, speech and computer vision. NVIDIA was the only company to submit results on every workload in the latest round and every round since MLPerf’s data center inference benchmarks began in October 2020.
Continued performance gains translate into lower costs for inference, a large and growing part of the daily work for the millions of NVIDIA GPUs deployed worldwide.
Pushing the boundaries of what’s possible, NVIDIA demonstrated three innovative techniques in a special section of the benchmarks called the open division, created for testing advanced AI methods.
NVIDIA engineers used a technique called structured sparsity — a way of reducing calculations, first introduced with NVIDIA A100 Tensor Core GPUs — to deliver up to 33% speedups on inference with Llama 2.
A second open division test found inference speedups of up to 40% using pruning, a way of simplifying an AI model — in this case, an LLM — to increase inference throughput.
Finally, an optimization called DeepCache reduced the math required for inference with the Stable Diffusion XL model, accelerating performance by a whopping 74%.
All these results were run on NVIDIA H100 Tensor Core GPUs.
MLPerf’s tests are transparent and objective, so users can rely on the results to make informed buying decisions.
NVIDIA’s partners participate in MLPerf because they know it’s a valuable tool for customers evaluating AI systems and services. Partners submitting results on the NVIDIA AI platform in this round included ASUS, Cisco, Dell Technologies, Fujitsu, GIGABYTE, Google, Hewlett Packard Enterprise, Lenovo, Microsoft Azure, Oracle, QCT, Supermicro, VMware (recently acquired by Broadcom) and Wiwynn.
All the software NVIDIA used in the tests is available in the MLPerf repository. These optimizations are continuously folded into containers available on NGC, NVIDIA’s software hub for GPU applications, as well as NVIDIA AI Enterprise — a secure, supported platform that includes NIM inference microservices.
The use cases, model sizes and datasets for generative AI continue to expand. That’s why MLPerf continues to evolve, adding real-world tests with popular models like Llama 2 70B and Stable Diffusion XL.
Keeping pace with the explosion in LLM model sizes, NVIDIA founder and CEO Jensen Huang announced last week at GTC that the NVIDIA Blackwell architecture GPUs will deliver new levels of performance required for the multitrillion-parameter AI models.
Inference for large language models is difficult, requiring both expertise and the full-stack architecture NVIDIA demonstrated on MLPerf with Hopper architecture GPUs and TensorRT-LLM. There’s much more to come.
Learn more about MLPerf benchmarks and the technical details of this inference round.
Addressing the challenges associated with generating consistent, transparent, and accurate carbon measurements.Read More

Editor’s note: This post is part of the AI Decoded series, which demystifies AI by making the technology more accessible, and which showcases new hardware, software, tools and accelerations for RTX PC users.
As generative AI advances and becomes widespread across industries, the importance of running generative AI applications on local PCs and workstations grows. Local inference gives consumers reduced latency, eliminates their dependency on the network and enables more control over their data.
NVIDIA GeForce and NVIDIA RTX GPUs feature Tensor Cores, dedicated AI hardware accelerators that provide the horsepower to run generative AI locally.
Stable Video Diffusion is now optimized for the NVIDIA TensorRT software development kit, which unlocks the highest-performance generative AI on the more than 100 million Windows PCs and workstations powered by RTX GPUs.
Now, the TensorRT extension for the popular Stable Diffusion WebUI by Automatic1111 is adding support for ControlNets, tools that give users more control to refine generative outputs by adding other images as guidance.
TensorRT acceleration can be put to the test in the new UL Procyon AI Image Generation benchmark, which internal tests have shown accurately replicates real-world performance. It delivered speedups of 50% on a GeForce RTX 4080 SUPER GPU compared with the fastest non-TensorRT implementation.
TensorRT enables developers to access the hardware that provides fully optimized AI experiences. AI performance typically doubles compared with running the application on other frameworks.
It also accelerates the most popular generative AI models, like Stable Diffusion and SDXL. Stable Video Diffusion, Stability AI’s image-to-video generative AI model, experiences a 40% speedup with TensorRT.
The optimized Stable Video Diffusion 1.1 Image-to-Video model can be downloaded on Hugging Face.
Plus, the TensorRT extension for Stable Diffusion WebUI boosts performance by up to 2x — significantly streamlining Stable Diffusion workflows.
With the extension’s latest update, TensorRT optimizations extend to ControlNets — a set of AI models that help guide a diffusion model’s output by adding extra conditions. With TensorRT, ControlNets are 40% faster.
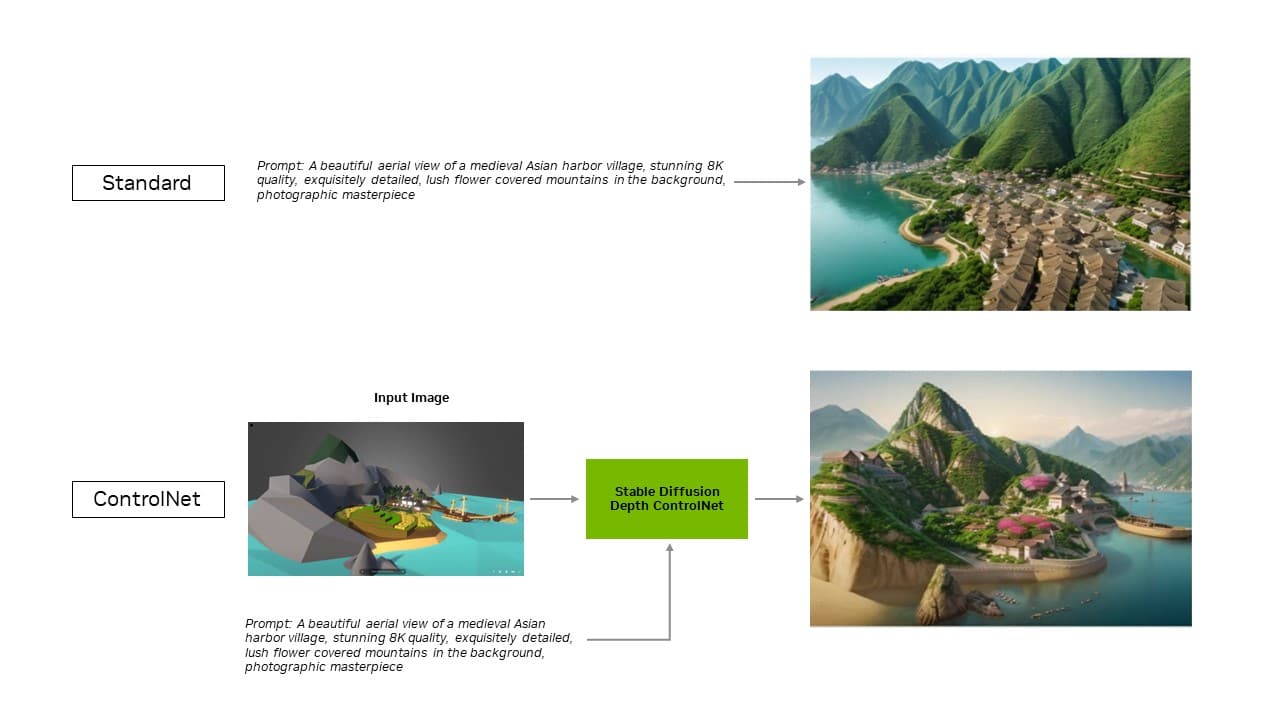
Users can guide aspects of the output to match an input image, which gives them more control over the final image. They can also use multiple ControlNets together for even greater control. A ControlNet can be a depth map, edge map, normal map or keypoint detection model, among others.
Download the TensorRT extension for Stable Diffusion Web UI on GitHub today.
Blackmagic Design adopted NVIDIA TensorRT acceleration in update 18.6 of DaVinci Resolve. Its AI tools, like Magic Mask, Speed Warp and Super Scale, run more than 50% faster and up to 2.3x faster on RTX GPUs compared with Macs.
In addition, with TensorRT integration, Topaz Labs saw an up to 60% performance increase in its Photo AI and Video AI apps — such as photo denoising, sharpening, photo super resolution, video slow motion, video super resolution, video stabilization and more — all running on RTX.
Combining Tensor Cores with TensorRT software brings unmatched generative AI performance to local PCs and workstations. And by running locally, several advantages are unlocked:
What TensorRT brings to deep learning, NVIDIA TensorRT-LLM brings to the latest LLMs.
TensorRT-LLM, an open-source library that accelerates and optimizes LLM inference, includes out-of-the-box support for popular community models, including Phi-2, Llama2, Gemma, Mistral and Code Llama. Anyone — from developers and creators to enterprise employees and casual users — can experiment with TensorRT-LLM-optimized models in the NVIDIA AI Foundation models. Plus, with the NVIDIA ChatRTX tech demo, users can see the performance of various models running locally on a Windows PC. ChatRTX is built on TensorRT-LLM for optimized performance on RTX GPUs.
NVIDIA is collaborating with the open-source community to develop native TensorRT-LLM connectors to popular application frameworks, including LlamaIndex and LangChain.
These innovations make it easy for developers to use TensorRT-LLM with their applications and experience the best LLM performance with RTX.
Get weekly updates directly in your inbox by subscribing to the AI Decoded newsletter.

In the latest episode of NVIDIA’s AI Podcast, Viome Chief Technology Officer Guru Banavar spoke with host Noah Kravitz about how AI and RNA sequencing are revolutionizing personalized healthcare. The startup aims to tackle the root causes of chronic diseases by delving deep into microbiomes and gene expression.
With a comprehensive testing kit, Viome translates biological data into practical dietary recommendations. Viome is forging ahead with professional healthcare solutions, such as early detection tests for diseases, and integrating state-of-the-art technology with traditional medical practices for a holistic approach to wellness.
2:00: Introduction to Viome and the science of nutrigenomics
4:25: The significance of RNA over DNA in health analysis
7:40: The crucial role of the microbiome in understanding chronic diseases
12:50: From sample collection to personalized nutrition recommendations
17:35: Viome’s expansion into professional healthcare solutions and early disease detection

The future of healthcare is software-defined and AI-enabled. Around 700 FDA-cleared, AI-enabled medical devices are now on the market — more than 10x the number available in 2020.
Many of the innovators behind this boom announced their latest AI-powered solutions at NVIDIA GTC, a global conference that last week attracted more than 16,000 business leaders, developers and researchers in Silicon Valley — and many more online.
Designed to make healthcare more efficient and help improve patient outcomes, these new technologies include foundation models to accelerate ultrasound analysis, augmented and virtual reality solutions for cardiac imaging, and generative AI software to support surgeons.
Medical devices have long been hardware-centric, relying on intricate designs and precise engineering. They’re now shifting to be software-defined, meaning they can be enhanced over time through software updates — the same way that smartphones can be upgraded with new apps and features for years before a user upgrades to a new device.
This new approach, supported by NVIDIA’s domain-specific platforms for real-time accelerated computing, is taking center stage because of its potential to transform patient care, increase efficiencies, enhance the clinician experience and drive better outcomes.
Leading medtech companies such as GE Healthcare are using NVIDIA technology to develop, fine-tune and deploy AI for software-defined medical imaging applications.
GE Healthcare announced at GTC that it used NVIDIA tools including the TensorRT software development kit to develop and optimize SonoSAMTrack, a recent research foundation model that delineates and tracks organs, structures or lesions across medical images with just a few clicks. The research model has the potential to simplify and speed up ultrasound analysis for healthcare professionals.
With the NVIDIA IGX edge computing platform and NVIDIA Holoscan medical-grade edge AI platform, medical device companies are accelerating the development and deployment of AI-powered innovation in the operating room.
Johnson & Johnson MedTech is working with NVIDIA to test new AI capabilities for the company’s connected digital ecosystem for surgery. It aims to enable open innovation and accelerate the delivery of real-time insights at scale to support medical professionals before, during and after procedures.
Paris-based robotic surgery company Moon Surgical is using Holoscan and IGX to power its Maestro System, which is used in laparoscopy, a technique where surgeons operate through small incisions with an internal camera and instruments.
Maestro’s ScoPilot enables surgeons to control a laparoscope without taking their hands off other surgical tools during an operation. To date, it’s been used to treat over 200 patients successfully.
Moon Surgical and NVIDIA are also collaborating to bring generative AI features to the operating room using Maestro and Holoscan.
A growing number of medtech companies and solution providers is making it easier for customers to adopt NVIDIA’s edge AI platforms to enhance and accelerate healthcare.
Arrow Electronics is delivering IGX as a subscription-like platform-as-a-service for industrial and medical customers. Customers who have adopted Arrow’s business model to accelerate application deployment include Kaliber AI, a company developing AI tools to assist minimally invasive surgery. At GTC, Kaliber showcased AI-generated insights for surgeons and a large language model to respond to patient questions.
Global visualization leader Barco is adopting Holoscan and IGX to build a turnkey surgical AI platform for customers seeking an off-the-shelf offering that allows them to focus their engineering resources on application development. The company is working with SoftAcuity on two Holoscan-based products that will include generative AI voice control and AI-powered data analytics.
And Magic Leap has integrated Holoscan in its extended reality software stack, enhancing the capabilities of customers like Medical iSight — a software developer building real-time, intraoperative support for minimally invasive treatments of stroke and neurovascular conditions.
Learn more about NVIDIA-accelerated medtech.
Get started on NVIDIA NGC or visit ai.nvidia.com to experiment with more than two dozen healthcare microservices.