In today’s business landscape, organizations are constantly seeking ways to optimize their financial processes, enhance efficiency, and drive cost savings. One area that holds significant potential for improvement is accounts payable. On a high level, the accounts payable process includes receiving and scanning invoices, extraction of the relevant data from scanned invoices, validation, approval, and archival. The second step (extraction) can be complex. Each invoice and receipt look different. The labels are imperfect and inconsistent. The most important pieces of information such as price, vendor name, vendor address, and payment terms are often not explicitly labeled and have to be interpreted based on context. The traditional approach of using human reviewers to extract the data is time-consuming, error-prone, and not scalable.
In this post, we show how to automate the accounts payable process using Amazon Textract for data extraction. We also provide a reference architecture to build an invoice automation pipeline that enables extraction, verification, archival, and intelligent search.
Solution overview
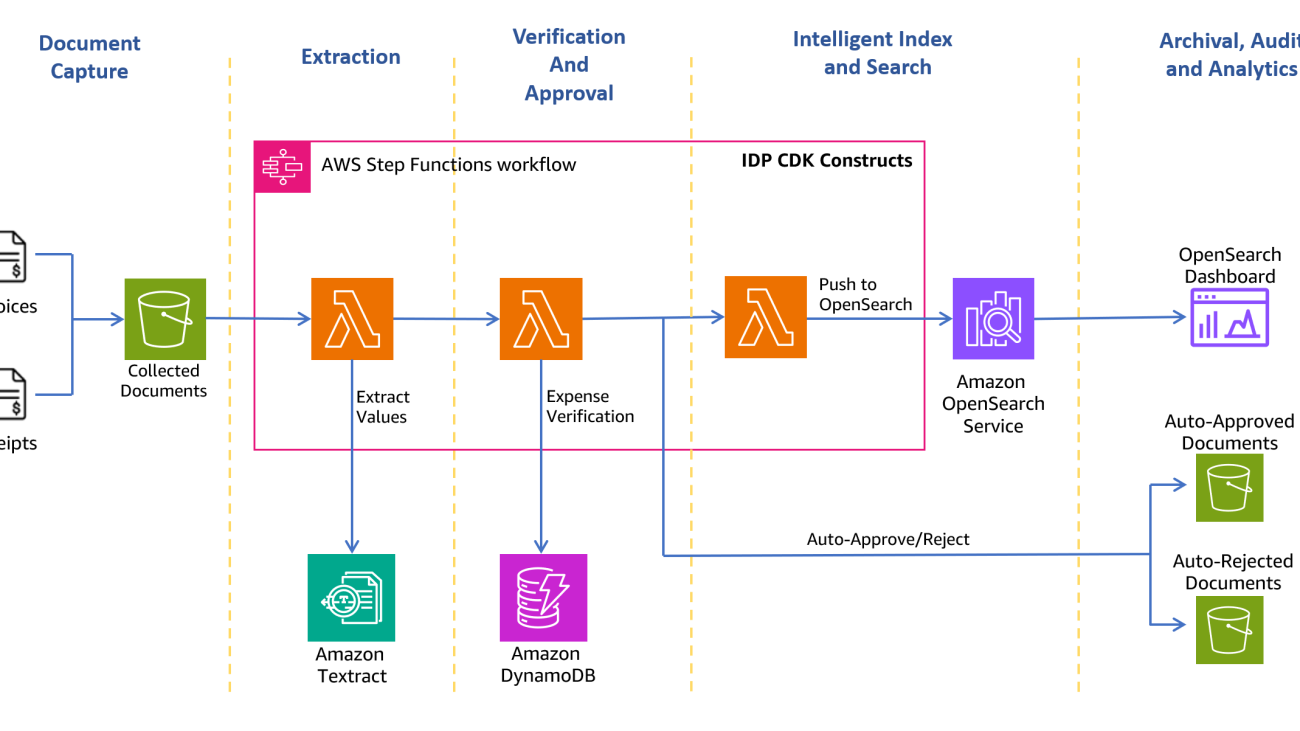
The following architecture diagram shows the stages of a receipt and invoice processing workflow. It starts with a document capture stage to securely collect and store scanned invoices and receipts. The next stage is the extraction phase, where you pass the collected invoices and receipts to the Amazon Textract AnalyzeExpense API to extract financially related relationships between text such as vendor name, invoice receipt date, order date, amount due, amount paid, and so on. In the next stage, you use predefined expense rules to determine if you should automatically approve or reject the receipt. Approved and rejected documents go to their respective folders within the Amazon Simple Storage Service (Amazon S3) bucket. For approved documents, you can search all the extracted fields and values using Amazon OpenSearch Service. You can visualize the indexed metadata using OpenSearch Dashboards. Approved documents are also set up to be moved to Amazon S3 Intelligent-Tiering for long-term retention and archival using S3 lifecycle policies.

The following sections take you through the process of creating the solution.
Prerequisites
To deploy this solution, you must have the following:
- An AWS account.
- An AWS Cloud9 environment. AWS Cloud9 is a cloud-based integrated development environment (IDE) that lets you write, run, and debug your code with just a browser. It includes a code editor, debugger, and terminal.
To create the AWS Cloud9 environment, provide a name and description. Keep everything else as default. Choose the IDE link on the AWS Cloud9 console to navigate to IDE. You’re now ready to use the AWS Cloud9 environment.
Deploy the solution
To set up the solution, you use the AWS Cloud Development Kit (AWS CDK) to deploy an AWS CloudFormation stack.
- In your AWS Cloud9 IDE terminal, clone the GitHub repository and install the dependencies. Run the following commands to deploy the
InvoiceProcessorstack:
The deployment takes around 25 minutes with the default configuration settings from the GitHub repo. Additional output information is also available on the AWS CloudFormation console.
- After the AWS CDK deployment is complete, create expense validation rules in an Amazon DynamoDB table. You can use the same AWS Cloud9 terminal to run the following commands:
- In the S3 bucket that starts with
invoiceprocessorworkflow-invoiceprocessorbucketf1-*, create an uploads folder.
In Amazon Cognito, you should already have an existing user pool called OpenSearchResourcesCognitoUserPool*. We use this user pool to create a new user.
- On the Amazon Cognito console, navigate to the user pool
OpenSearchResourcesCognitoUserPool*. - Create a new Amazon Cognito user.
- Provide a user name and password of your choice and note them for later use.
- Upload the documents random_invoice1 and random_invoice2 to the S3
uploadsfolder to start the workflows.
Now let’s dive into each of the document processing steps.
Document Capture
Customers handle invoices and receipts in a multitude of formats from different vendors. These documents are received through channels like hard copies, scanned copies uploaded to file storage, or shared storage devices. In the document capture stage, you store all scanned copies of receipts and invoices in a highly scalable storage such as in an S3 bucket.

Extraction
The next stage is the extraction phase, where you pass the collected invoices and receipts to the Amazon Textract AnalyzeExpense API to extract financially related relationships between text such as Vendor Name, Invoice Receipt Date, Order Date, Amount Due/Paid, etc.
AnalyzeExpense is an API dedicated to processing invoice and receipts documents. It is available both as a synchronous or asynchronous API. The synchronous API allows you to send images in bytes format, and the asynchronous API allows you to send files in JPG, PNG, TIFF, and PDF formats. The AnalyzeExpense API response consists of three distinct sections:
- Summary fields – This section includes both normalized keys and the explicitly mentioned keys along with their values.
AnalyzeExpensenormalizes the keys for contact-related information such as vendor name and vendor address, tax ID-related keys such as tax payer ID, payment-related keys such as amount due and discount, and general keys such as invoice ID, delivery date, and account number. Keys that are not normalized still appear in the summary fields as key-value pairs. For a complete list of supported expense fields, refer to Analyzing Invoices and Receipts. - Line items – This section includes normalized line item keys such as item description, unit price, quantity, and product code.
- OCR block – The block contains the raw text extract from the invoice page. The raw text extract can be used for postprocessing and identifying information that is not covered as part of the summary and line item fields.
This post uses the Amazon Textract IDP CDK constructs (AWS CDK components to define infrastructure for intelligent document processing (IDP) workflows), which allows you to build use case-specific, customizable IDP workflows. The constructs and samples are a collection of components to enable definition of IDP processes on AWS and published to GitHub. The main concepts used are the AWS CDK constructs, the actual AWS CDK stacks, and AWS Step Functions.
The following figure shows the Step Functions workflow.

The extraction workflow includes the following steps:
- InvoiceProcessor-Decider – An AWS Lambda function that verifies if the input document format is supported by Amazon Textract. For more details about supported formats, refer to Input Documents.
- DocumentSplitter – A Lambda function that generates 2,500-page (max) chunks from documents and can process large multi-page documents.
- Map State – A Lambda function that processes each chunk in parallel.
- TextractAsync – This task calls Amazon Textract using the asynchronous API following best practices with Amazon Simple Notification Service (Amazon SNS) notifications and uses
OutputConfigto store the Amazon Textract JSON output to the S3 bucket you created earlier. It consists of two Lambda functions: one to submit the document for processing and one that is triggered on the SNS notification. - TextractAsyncToJSON2 – Because the
TextractAsynctask can produce multiple paginated output files, theTextractAsyncToJSON2process combines them into one JSON file.
We discuss the details of the next three steps in the following sections.
Verification and approval
For the verification stage, the SetMetaData Lambda function verifies whether the uploaded file is a valid expense as per the rules configured previously in DynamoDB table. For this post, you use the following sample rules:
- Verification is successful if
INVOICE_RECEIPT_IDis present and matches the regex(?i)[0-9]{3}[a-z]{3}[0-9]{3}$and ifPO_NUMBERis present and matches the regex(?i)[a-z0-9]+$ - Verification is un-successful if either
PO_NUMBERorINVOICE_RECEIPT_IDis incorrect or missing in the document.
After the files are processed, the expense verification function moves the input files to either approved or declined folders in the same S3 bucket.

For the purposes of this solution, we use DynamoDB to store the expense validation rules. However, you can modify this solution to integrate with your own or commercial expense validation or management solutions.
Intelligent index and search
With the OpenSearchPushInvoke Lambda function, the extracted expense metadata is pushed to an OpenSearch Service index and is available for search.
The final TaskOpenSearchMapping step clears the context, which otherwise could exceed the Step Functions quota of maximum input or output size for a task, state, or workflow run.
After the OpenSearch Service index is created, you can search for keywords from the extracted text via OpenSearch Dashboards.

Archival, audit, and analytics
To manage the lifecycle and archival of invoices and receipts, you can configure S3 lifecycle rules to transition S3 objects from Standard to Intelligent-Tiering storage classes. S3 Intelligent-Tiering monitors access patterns and automatically moves objects to the Infrequent Access tier when they haven’t been accessed for 30 consecutive days. After 90 days of no access, the objects are moved to the Archive Instant Access tier without performance impact or operational overhead.
For auditing and analytics, this solution uses OpenSearch Service for running analytics on invoice requests. OpenSearch Service enables you to effortlessly ingest, secure, search, aggregate, view, and analyze data for a number of use cases, such as log analytics, application search, enterprise search, and more.
Log in to OpenSearch Dashboards and navigate to Stack Management, Saved objects, then choose Import. Choose the invoices.ndjson file from the cloned repository and choose Import. This prepopulates indexes and builds the visualization.

Refresh the page and navigate to Home, Dashboard, and open Invoices. You can now select and apply filters and expand the time window to explore past invoices.

Clean up
When you’re finished evaluating Amazon Textract for processing receipts and invoices, we recommend cleaning up any resources that you might have created. Complete the following steps:
- Delete all content from the S3 bucket
invoiceprocessorworkflow-invoiceprocessorbucketf1-*. - In AWS Cloud9, run the following commands to delete Amazon Cognito resources and CloudFormation stacks:
- Delete the AWS Cloud9 environment that you created from the AWS Cloud9 console.
Conclusion
In this post, we provided an overview of how we can build an invoice automation pipeline using Amazon Textract for data extraction and create a workflow for validation, archival, and search. We provided code samples on how to use the AnalyzeExpense API for extraction of critical fields from an invoice.
To get started, sign in to the Amazon Textract console to try this feature. To learn more about Amazon Textract capabilities, refer to the Amazon Textract Developer Guide or Textract Resources. To learn more about IDP, refer to the IDP with AWS AI services Part 1 and Part 2 posts.
About the Authors
 Sushant Pradhan is a Sr. Solutions Architect at Amazon Web Services, helping enterprise customers. His interests and experience include containers, serverless technology, and DevOps. In his spare time, Sushant enjoys spending time outdoors with his family.
Sushant Pradhan is a Sr. Solutions Architect at Amazon Web Services, helping enterprise customers. His interests and experience include containers, serverless technology, and DevOps. In his spare time, Sushant enjoys spending time outdoors with his family.
 Shibin Michaelraj is a Sr. Product Manager with the AWS Textract team. He is focused on building AI/ML-based products for AWS customers.
Shibin Michaelraj is a Sr. Product Manager with the AWS Textract team. He is focused on building AI/ML-based products for AWS customers.
 Suprakash Dutta is a Sr. Solutions Architect at Amazon Web Services. He focuses on digital transformation strategy, application modernization and migration, data analytics, and machine learning. He is part of the AI/ML community at AWS and designs intelligent document processing solutions.
Suprakash Dutta is a Sr. Solutions Architect at Amazon Web Services. He focuses on digital transformation strategy, application modernization and migration, data analytics, and machine learning. He is part of the AI/ML community at AWS and designs intelligent document processing solutions.
 Maran Chandrasekaran is a Senior Solutions Architect at Amazon Web Services, working with our enterprise customers. Outside of work, he loves to travel and ride his motorcycle in Texas Hill Country.
Maran Chandrasekaran is a Senior Solutions Architect at Amazon Web Services, working with our enterprise customers. Outside of work, he loves to travel and ride his motorcycle in Texas Hill Country.
















 Ulrich Hinze is a Solutions Architect at AWS. He partners with software companies to architect and implement cloud-based solutions on AWS. Before joining AWS, he worked for AWS customers and partners in software engineering, consulting, and architecture roles for 8+ years.
Ulrich Hinze is a Solutions Architect at AWS. He partners with software companies to architect and implement cloud-based solutions on AWS. Before joining AWS, he worked for AWS customers and partners in software engineering, consulting, and architecture roles for 8+ years. Aris Tsakpinis is a Specialist Solutions Architect for AI & Machine Learning with a special focus on natural language processing (NLP), large language models (LLMs), and generative AI. In his free time he is pursuing a PhD in ML Engineering at University of Regensburg, focussing on applied NLP in the science domain.
Aris Tsakpinis is a Specialist Solutions Architect for AI & Machine Learning with a special focus on natural language processing (NLP), large language models (LLMs), and generative AI. In his free time he is pursuing a PhD in ML Engineering at University of Regensburg, focussing on applied NLP in the science domain. Matt Middleton is the Senior Product Partner Ecosystem Manager at Contentful. He runs the strategy and operations of Contentful’s Technology Partner Program. Matt’s background includes eCommerce, enterprise search, personalization, and marketing automation.
Matt Middleton is the Senior Product Partner Ecosystem Manager at Contentful. He runs the strategy and operations of Contentful’s Technology Partner Program. Matt’s background includes eCommerce, enterprise search, personalization, and marketing automation.