Scientists updated the system to accurately measure body fat percentage and create personalized 3D models even if there’s not enough room to take a full-body photo.Read More
Alexa & Friends features Yang Liu, principal applied scientist, Alexa AI
Liu discusses her work in speech recognition and understanding, prosody modeling, summarization, and natural language processing.Read More
How to build highly expressive speech models
New voice for Alexa’s Reading Sidekick feature avoids the instabilities common to models with variable prosody.Read More
Applying PECOS to product retrieval and text autocompletion
Two KDD papers demonstrate the power and flexibility of Amazon’s framework for “extreme multilabel ranking”.Read More
The range of AWS’s speech research is on display at Interspeech
Katrin Kirchhoff, director of speech processing for Amazon Web Services, on the many scientific challenges her teams are tackling.Read More
Allie K. Miller wants to help others understand artificial intelligence
Amazon’s machine learning leader for startups is also working to include more underrepresented groups in the workforce.Read More
Alexandre Bayen is a driving force behind mixed-autonomy traffic
Coordinated automation could improve traffic flow, boost efficiency, and slash emissions. A combination of machine learning, big data, and Amazon Web Services is making this future possible.Read More
How to train large graph neural networks efficiently
New method enables two- to 14-fold speedups over best-performing predecessors.Read More
‘Think a lot, and think big’
How Minghui He turned her Amazon internship into a full-time research scientist role.Read More
Migrate your work to an Amazon SageMaker notebook instance with Amazon Linux 2
Amazon SageMaker notebook instances now support Amazon Linux 2, so you can now create a new Amazon SageMaker notebook instance to start developing your machine learning (ML) models with the latest updates. An obvious question is: what do I need to do to migrate my work from an existing notebook instance that runs on Amazon Linux to a new notebook instance with Amazon Linux 2? In this post, we describe an approach to migrate your work from an existing notebook instance to a new notebook instance.
Solution overview
The following diagram shows an overview of the components in a SageMaker notebook instance and how the migration takes place. Note that this solution isn’t limited to a particular version of an Amazon Linux image in the source and destination instance. Therefore, we denote the notebook instance that has existing work and data as an existing or source instance, and to refer the notebook instance that we migrate existing work and data to as a new or destination instance.
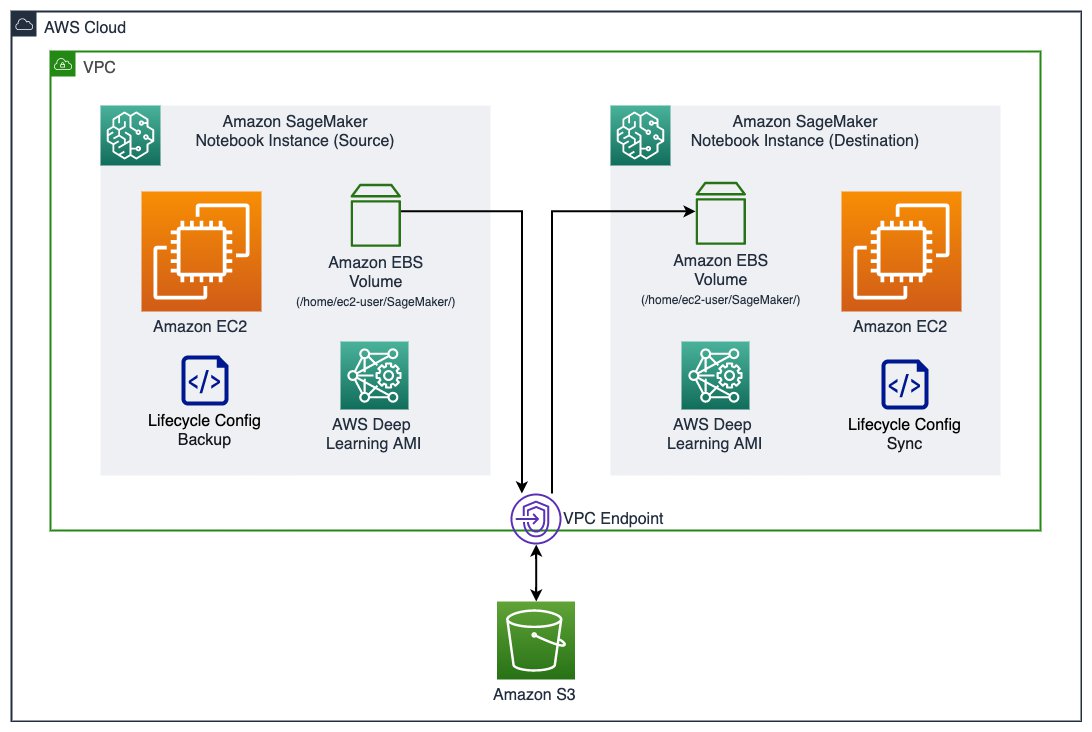
A SageMaker notebook instance consists of an Amazon Elastic Compute Cloud (Amazon EC2) instance with an Amazon Elastic Block Storage (Amazon EBS) volume attached, running an image built on top of the AWS Deep Learning AMI. The EBS volume (attached on /home/ec2-user/SageMaker/) is where you save any code, notebooks, or data persistently inside a notebook instance, and is subject to the migration to a new instance. In this solution, we use an Amazon Simple Storage Service (Amazon S3) bucket to store backup snapshots of an existing EBS volume. We then use lifecycle configurations to create a backup snapshot of the source EBS volume and synchronize a snapshot to the destination instance. You can easily indicate the S3 bucket name and the desired snapshot by tagging the instances.
When using the lifecycle configuration, you don’t need to open and be inside a notebook instance to initiate the backup or sync. It allows an administrator to script the migration process for all notebook instances for an organization.
In many cases, your notebook instance could run in an Amazon Virtual Private Cloud (Amazon VPC) and not have a direct internet access. The communication to the S3 bucket goes through an Amazon S3 VPC gateway endpoint.
Prerequisites
To get started with your migration, you need to set up the following prerequisites:
- SageMaker execution roles – The AWS Identity and Access Management (IAM) execution role for the existing instance should have
s3:CreateBucket,s3:GetObject,s3:PutObject, ands3:ListBucketto the bucket for backup. The execution role for the new instance should haves3:GetObject,s3:PutObject, ands3:ListBucketfor the same bucket (required byaws s3 sync). - Networking – If your notebook instances don’t have direct internet access, and are in placed in a VPC, you need the following VPC endpoints attached to the VPC:
- SageMaker notebook instance lifecycle configuration – You need the following lifecycle configuration scripts:
- File system – If you have mounted a file system in
/home/ec2-user/SageMaker/in the source instance either from Amazon Elastic File System (Amazon EFS) or Amazon FSx for Lustre, make sure you unmount it before proceeding. The file system can be simply mounted again onto the new instance and should not be subject to migration, which helps avoid unnecessary overhead. Refer to the relevant instructions to unmount an Amazon EFS file system or FSx for Lustre file system).
Create lifecycle configurations
First, we need to create two lifecycle configurations: one to create backup from the source instance, and another to synchronize a specific backup to a destination instance.
- On the Lifecycle configurations page on the SageMaker console, choose Create configuration.

- For Name, enter a name for the backup.
- On the Start notebook tab in the Scripts section, enter the code from on-start.sh.
- Leave the Create notebook tab empty.
- Choose Create configuration.

You have just created one lifecycle configuration, and are redirected to the list of all your lifecycle configurations. Let’s create our second configuration.
- Choose Create configuration.
- For Name, enter a name for your sync.
- On the Create notebook tab in the Scripts section, enter the code from on-create.sh.
- Leave the Start notebook tab empty.
- Choose Create configuration.
We have created two lifecycle configurations: one for backing up your EBS volume to Amazon S3, and another to synchronize the backup from Amazon S3 to the EBS volume. We need to attach the former to an existing notebook instance, and the latter to a new notebook instance.
Back up an existing notebook instance
You can only attach a lifecycle configuration to an existing notebook instance when it’s stopped. If your instance is still running, stop it before completing the following steps. Also, it will be safer to perform the backup process when all your notebook kernels and processes on the instance are shut down.
- On the Notebook instances page on the SageMaker console, choose your instance to see its detailed information.
- Choose Stop to stop the instance.
The instance may take a minute or two to transition to the Stopped state.
- After the instance stops, choose Edit.
- In Additional configuration, for Lifecycle configuration, choose backup-ebs.
- Choose Update notebook instance.
You can monitor the instance details while it’s being updated.
We need to tag the instance to provide the lifecycle configuration script where the backup S3 bucket is.
- In the Tags section, choose Edit.
- Add a tag with the key ebs-backup-bucket, which matches what the lifecycle configuration script expects.
- The value is a bucket of your choice, for example sagemaker-ebs-backup-<region>-<account_id>.
Make sure the attached execution role allows sufficient permission to perform aws s3 sync to the bucket.
- Choose Save.
You should see the following tag details.

- Choose Start at the top of the page to start the instance.
When the instance is starting, on-start.sh from the backup-ebs lifecycle configuration begins, and starts the backup process to create a complete snapshot of /home/ec2-user/SageMaker/ in s3://<ebs-backup-bucket>/<source-instance-name>_<snapshot-timestamp>/. The length of the backup process depends on the total size of your data in the volume.
The backup process is run with a nohup in the background during the instance startup. This means that there is no guarantee that when the instance becomes InService, the backup process is complete. To know when the backup is complete, you should see the file /home/ec2-user/SageMaker/BACKUP_COMPLETE created, and you should see the same in s3://<ebs-backup-bucket>/<source-instance-name>_<snapshot-timestamp>/.
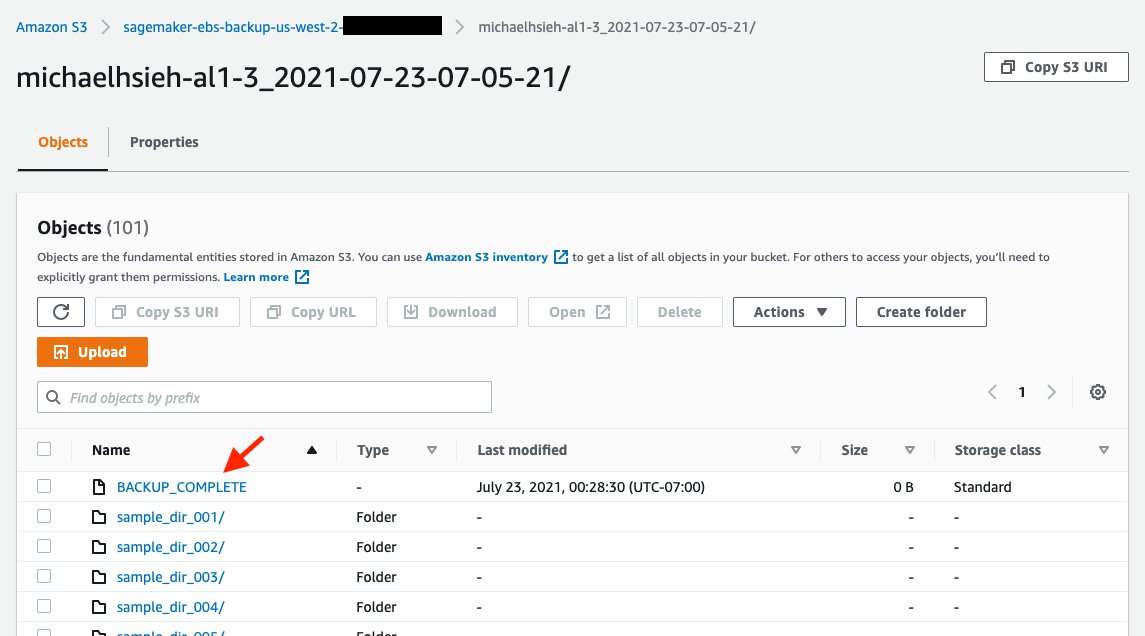
Synchronize from a snapshot to a new instance
When the backup is complete, you can create a new instance and download the backup snapshot with the following steps:
- On the SageMaker console, on the Notebook instances page, create a new instance.
- In Additional configuration, for Lifecycle configuration, choose sync-from-s3.

- Make sure that Volume size in GB is equal to or greater than that of the source instance.
- For Platform identifier, choose notebook-al2-v1 if you’re migrating to an instance with Amazon Linux 2.
- Use an IAM execution role that has sufficient permission to perform
aws s3 syncfrom the backup bucketebs-backup-bucket. - Choose the other options according to your needs or based on the source instance.
- If you need to host this instance in a VPC and with Direct internet access disabled, you need to follow the prerequisites to attach the S3 VPC endpoint and SageMaker API VPC endpoint to your VPC.
- Add the following two tags. The keys have to match what is expected in the lifecycle configuration script.
- Key:
ebs-backup-bucket, value:<ebs-backup-bucket>. - Key:
backup-snapshot, value:<source-instance-name>_<snapshot-timestamp>.
- Key:
- Choose Create notebook instance.

When your new instance starts, on-create.sh in the sync-from-s3 lifecycle configuration performs aws s3 sync to get the snapshot indicated in the tags from s3://<ebs-backup-bucket>/<source-instance-name>_<snapshot-timestamp>/ down to /home/ec2-user/SageMaker/. Again, the length of the sync process depends on the total size of your data in the volume.
The sync process is run with a nohup in the background during the instance creation. This means that there is no guarantee that when the instance becomes InService, the sync process is complete. To know when the backup is complete, you should see the file /home/ec2-user/SageMaker/SYNC_COMPLETE created in the new instance.
Considerations
Consider the following when performing the backup and sync operations:
- You can expect the time to back up and sync to be approximately the same. The time for backup and sync depends on the size of
/home/ec2-user/SageMaker/. If it takes 5 minutes for you to back up a source instance, you can expect 5 minutes for the sync. - If you no longer need to create a snapshot for a source instance, consider detaching the lifecycle configuration from the instance. Because the backup script is attached to the Start notebook tab in a lifecycle configuration, the script runs every time you start the source instance. You can detach a lifecycle configuration by following the same steps we showed to back up an existing notebook instance, but in Additional configuration, for Lifecycle configuration, choose No configuration.
- For security purposes, you should limit the bucket access within the policy of the attached execution role. Because both the source and destination instances are dedicated to the same data scientist, you can allow access to a specific S3 bucket in the IAM execution role (see Add Additional Amazon S3 Permissions to an SageMaker Execution Role) and attach the role to both source and destination instances for a data scientist. For more about data protection see Data Protection in Amazon SageMaker.
When migrating from Amazon Linux to Amazon Linux 2 in a SageMaker notebook instance, there are significant conda kernel changes, as described in the announcement. You should take actions to adopt your code and notebooks that depend on kernels that are no longer supported in Amazon Linux 2.
Conclusion
In this post, we shared a solution to create an EBS volume backup from an existing SageMaker notebook instance and synchronize the backup to a new notebook instance. This helps you migrate your work on an existing notebook instance to a new instance with Amazon Linux 2, as we announced the support of Amazon Linux 2 in SageMaker notebook instances. We walked you through the steps on the SageMaker console, and also discussed some considerations when performing the steps in this post. Now you should be able to continue your ML development in a notebook instance with Amazon Linux 2 and regular updates and patches. Happy coding!
About the Author
 Michael Hsieh is a Senior AI/ML Specialist Solutions Architect. He works with customers to advance their ML journey with a combination of AWS ML offerings and his ML domain knowledge. As a Seattle transplant, he loves exploring the great mother nature the region has to offer, such as the hiking trails, scenery kayaking in the SLU, and the sunset at the Shilshole Bay.
Michael Hsieh is a Senior AI/ML Specialist Solutions Architect. He works with customers to advance their ML journey with a combination of AWS ML offerings and his ML domain knowledge. As a Seattle transplant, he loves exploring the great mother nature the region has to offer, such as the hiking trails, scenery kayaking in the SLU, and the sunset at the Shilshole Bay.