Challenge includes benchmark models from Amazon Alexa, which achieve state-of-the-art performance on five of the challenge tasks.Read More

Simplify data management with new APIs in Amazon Personalize
Amazon Personalize now makes it easier to manage your growing item and user catalogs with new APIs to incrementally add items and users in your datasets to create personalized recommendations. With the new putItems and putUsers APIs, you can simplify the process of managing your datasets. You no longer need to upload an entire dataset containing historical records and new records just to include new records in your recommendations. Providing new records to Amazon Personalize when they become available reduces your latency for incorporating new information, ensuring your recommendations remain relevant to your users and item catalog.
Based on over 20 years of personalization experience at Amazon.com, Amazon Personalize enables you to improve customer engagement by powering personalized product and content recommendations and targeted marketing promotions. Amazon Personalize uses machine learning (ML) to create higher-quality recommendations for your websites and applications. You can get started without any prior ML experience and use simple APIs to easily build sophisticated personalization capabilities in just a few clicks. Amazon Personalize processes and examines your data, identifies what is meaningful, and trains and optimizes a personalization model that is customized for your data. All your data is encrypted to be private and secure, and is only used to create recommendations for your users.
This post walks you through the process of incrementally modifying your items and users datasets in Amazon Personalize.
Adding new items and users to your datasets
For this use case, we create a dataset group with an interaction dataset, an item dataset (item metadata) and a user dataset using the Amazon Personalize CLI. For instructions on creating a dataset group, see Getting Started (CLI).
- Create an
Interactionsdataset using the following schema and import data using the interactions-100k.csv data file:
{
"type": "record",
"name": "Interactions",
"namespace": "com.amazonaws.personalize.schema",
"fields": [
{
"name": "USER_ID",
"type": "string"
},
{
"name": "ITEM_ID",
"type": "string"
},
{
"name": "EVENT_TYPE",
"type": [
"string"
]
},
{
"name": "EVENT_VALUE",
"type": [
"null",
"float"
]
},
{
"name": "TIMESTAMP",
"type": "long"
}
]
}
- Create an Items dataset using the following schema and import data using the csv data file:
{
"type": "record",
"name": "Items",
"namespace": "com.amazonaws.personalize.schema",
"fields": [
{
"name": "ITEM_ID",
"type": "string"
},
{
"name": "GENRE",
"type”: "null”
"categorical": true
}
],
"version": "1.0"
}
- Create a Users dataset using the following schema and import data using the csv data file:
{
"type": "record",
"name": "Users",
"namespace": "com.amazonaws.personalize.schema",
"fields": [
{
"name": "USER_ID",
"type": "string"
},
{
"name": "AGE",
"type": "int"
},
{
"name": "GENDER",
"type": "string"
}
],
"version": "1.0"
}
Now that you have created your datasets, you can add data to them in two different ways:
- Using bulk import for item and user datasets from Amazon Simple Storage Service (Amazon S3). (for more information, see Preparing and Importing Data)
- Using the new
putUsersandputItemsYou can incrementally add up to 10 records per call to the user dataset using theputUsersAPI and the items dataset usingputItemsAPI.
For the putUsers call, the Users dataset required schema field (USER_ID) is mapped to the camel case userId. For the putItems call, the Items dataset required schema field (ITEM_ID) is mapped to the camel case itemId.
The following code adds two new users to the Users dataset via the putUsers API:
personalize_events.put_users(
datasetArn="arn:aws:personalize:region:acctID:dataset/crud-test/USERS",
users=[
{
'userId' :"489",
'properties': "{"AGE":"29", "GENDER":F}"
},
{
'userId' : "650",
'properties':"{"AGE":"65", "GENDER"":F}"
}]
)
The following code adds a new item to the Items dataset via the putItems API:
personalize_events.put_items(
datasetArn="arn:aws:personalize:region:acctID:dataset/crud-test/ITEMS",
items=[
{
'itemId' :"432",
'properties': "{"GENRE":"Action"}"
}]
)
An HTTP/1.1 200 response is returned for successful record creation. In cases where your new item or user doesn’t match your dataset’s defined schema, you receive an InvalidInputException detailing the total number of records in your request that don’t match the schema.
For new records created (incrementally or via bulk upload) with the same userId or itemId as a record that already exists in the Users or Items dataset, the most recently created record (ingested by Amazon Personalize) is used in new solutions or solution versions.
Additionally, records added using putUsers or putItems are persisted until your dataset is deleted, so be sure to delete your dataset in the dataset group before importing a refreshed dataset. Amazon Personalize doesn’t replace your catalog or user data management systems.
Incorporating the newly added users and items in recommendations and filters
Now that you’ve added new items and new users to your datasets, incorporating this information into your Amazon Personalize solutions makes sure that recommendations remain timely and relevant for your users. When not using the aws-user-personalization recipe, solution re-training is needed to include these new items in your personalized recommendations.
If you have exploration enabled in an Amazon Personalize recipe, your new items are included in recommendations as soon as your next campaign update is complete. New events generated by your users’ interactions with these items are incorporated when your train a new solution or solution version in this dataset group.
Any filters you created in the dataset group are updated with your new item and user data within 15 minutes from the last dataset import job completion or the last incremental record. This update allows your campaigns to use your most recent data when filtering recommendations for your users.
Summary
Amazon Personalize allows you to easily manage your growing item and user catalogs so your personalized product and content recommendations keep pace with your business and your customers. For more information about optimizing your user experience with Amazon Personalize, see What Is Amazon Personalize?
About the Authors
 Matt Chwastek is a Senior Product Manager for Amazon Personalize. He focuses on delivering products that make it easier to build and use machine learning solutions. In his spare time, he enjoys reading and photography.
Matt Chwastek is a Senior Product Manager for Amazon Personalize. He focuses on delivering products that make it easier to build and use machine learning solutions. In his spare time, he enjoys reading and photography.
 Gaurav Singh Chauhan is a Software Engineer for Amazon Personalize and works on architecting software systems and big data pipelines that serve customers at scale. Gaurav has a B.Tech in Computer Science from IIT Bombay, India. Outside of work, he likes all things outdoors and is an avid runner. In his spare time, he likes reading about and exploring new technologies. He tweets on startups, technology, and India at @bazingaurav.
Gaurav Singh Chauhan is a Software Engineer for Amazon Personalize and works on architecting software systems and big data pipelines that serve customers at scale. Gaurav has a B.Tech in Computer Science from IIT Bombay, India. Outside of work, he likes all things outdoors and is an avid runner. In his spare time, he likes reading about and exploring new technologies. He tweets on startups, technology, and India at @bazingaurav.
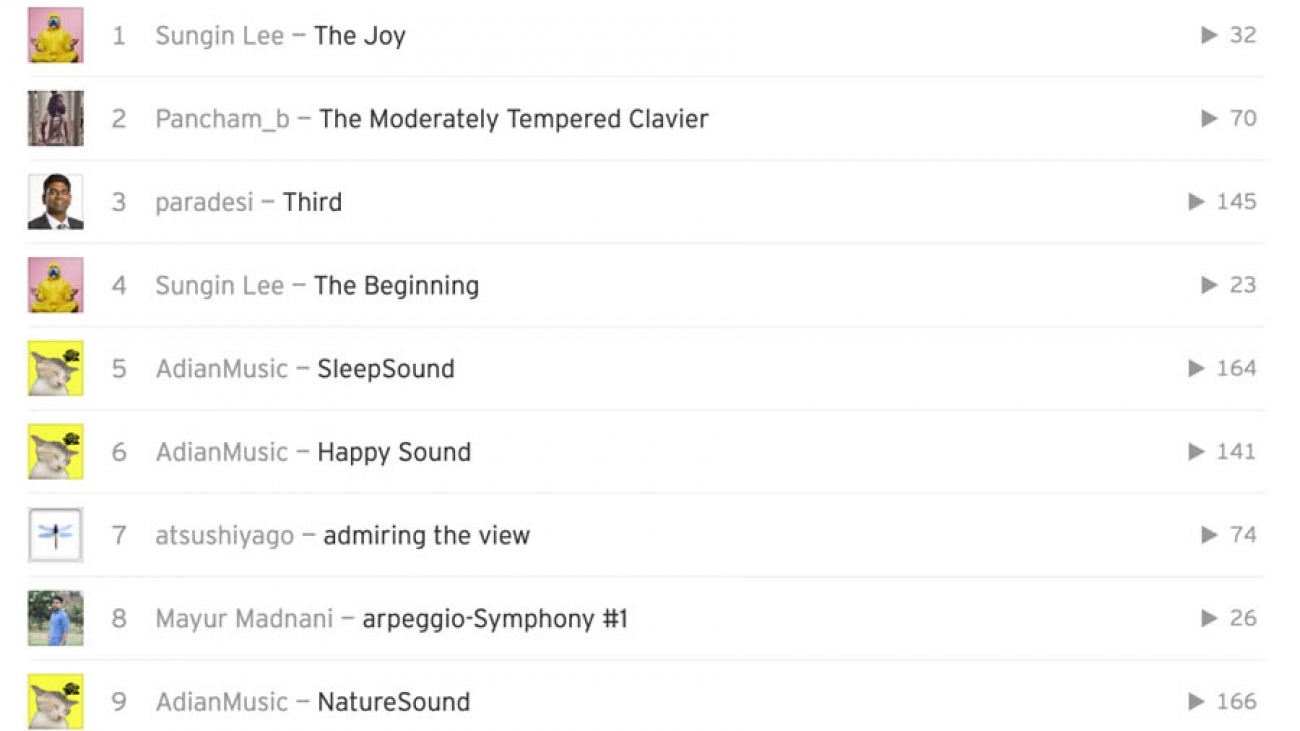
Announcing the winner of the AWS DeepComposer Chartbusters The Sounds of Science challenge
We’re excited to announce the top 10 compositions and the winner of the AWS DeepComposer Chartbusters The Sounds of Science challenge. AWS DeepComposer provides a creative and hands-on experience for learning generative AI and machine learning (ML). Chartbusters is a global monthly challenge where you can use AWS DeepComposer to create original compositions and compete to top the charts and win prizes. To participate in The Sounds of Science, developers composed background music for a video clip using the Autoregressive CNN (AR-CNN) algorithm and edited notes with the newly launched Edit melody feature to better match the provided video.
Top 10 compositions
The high-quality submissions made it challenging for our judges to select the chart-toppers. Our panel of experts—Kesha Williams, Sally Revell, and Prachi Kumar—selected the top 10 ranked compositions by evaluating the quality of the music, creativity, and how well the music matched the video clip.
The winner of The Sounds of Science is… (cue drum roll) Sungin Lee! You can listen to his winning composition and the top 10 compositions on SoundCloud or on the AWS DeepComposer console. The top 10 compositions for the Sounds of Science challenge are:

Sungin will receive an AWS DeepComposer Chartbusters gold record and will tell his story in an upcoming post, right here on the AWS ML blog.
Congratulations, Sungin Lee!
It’s time to move on to the next Chartbusters challenge—Track or Treat, which is Halloween-themed. The challenge launches today and is open until October 23rd, 2020.
About the Author
 Maryam Rezapoor is a Senior Product Manager with AWS AI Ecosystem team. As a former biomedical researcher and entrepreneur, she finds her passion in working backward from customers’ needs to create new impactful solutions. Outside of work, she enjoys hiking, photography, and gardening.
Maryam Rezapoor is a Senior Product Manager with AWS AI Ecosystem team. As a former biomedical researcher and entrepreneur, she finds her passion in working backward from customers’ needs to create new impactful solutions. Outside of work, she enjoys hiking, photography, and gardening.

Join AWS and NVIDIA at GTC, October 5–9
Starting Monday, October 5, 2020, the NVIDIA GPU Technology Conference (GTC) is offering online sessions for you to learn AWS best practices to accomplish your machine learning (ML), virtual workstations, high performance computing (HPC), and internet of things (IoT) goals faster and more easily.
Amazon Elastic Compute Cloud (Amazon EC2) instances powered by NVIDIA GPUs deliver the scalable performance needed for fast ML training, cost-effective ML inference, flexible remote virtual workstations, and powerful HPC computations. At the edge, you can use AWS IoT Greengrass and SageMaker Neo to extend a wide range of AWS Cloud services and ML inference to NVIDIA-based edge devices so the devices can act locally on the data they generate.
AWS is a Global Diamond Sponsor of the conference.
Available sessions
The following sessions are available from AWS:
- As a deep learning developer or data scientist, you can choose from multiple GPU EC2 instance types based on your training and deployment requirements. You can access instances with different GPU memory sizes, NVIDIA GPU architectures, capabilities (precisions, Tensor Cores, NVLink), GPUs per instance, number of vCPUs, system memory, and network bandwidth. We’ll share some guidance on how you can choose the right GPU instance on AWS for your deep learning projects. You’ll get all the information you need to make an informed choice for GPU instance for your training and inference workload.
- Speaker: Shashank Prasanna, Senior Developer Advocate, AI/ML, Amazon Web Services
- Virtual workstations on AWS enable studios, departments, and freelancers to take on bigger projects, work from anywhere, and pay only for what they need. Running on Amazon EC2 G4 instances, virtual workstations employ the power of NVIDIA T4 Tensor Core GPUs and Quadro technology, the visual computing platform trusted by creative and technical professionals. Virtual workstations have become essential to creative professionals seeking cloud solutions that enable remote teams to work more efficiently, and keep creative productions moving forward. Join this session to learn more about how virtual workstations on AWS work, who is using them today, and how to get started.
- Speaker: Haley Kannall, CG Supervisor, Amazon Web Services
- We’ll discuss how we can optimize edge video inferencing performance by leveraging AWS infrastructure and NVIDA Deepstream. We’ll emphasize three major features at the edge: (1) massively deploying trained models to NVIDIA Jetson devices using AWS IoT Greengrass, (2) local communication and control between AWS IoT Greengrass engines and Deepstream applications through MQTT messaging, and (3) uploading inferencing results to the cloud for further analytics.
- Speaker: Yuxin Yang, IoT Architect, Amazon Web Services
- In this presentation, we provide an overview of AWS Wavelength, how it integrates with the Mobile Edge carrier network and improves the performance of Mobile Edge applications. Wavelength Zones are AWS infrastructure deployments that embed AWS compute and storage services within telecommunications providers’ datacenters at the edge of the 5G network, so application traffic can reach application servers running in Wavelength Zones without leaving the mobile providers’ network. Customers with edge data processing needs such as image and video recognition, inference, data aggregation, and responsive analytics can use Wavelength to perform low-latency operations and processing right where their data is generated, reducing the need to move large amounts of data to be processed in centralized locations. We deep dive into these Mobile Edge applications running at the AWS Wavelength Zones using Amazon EC2 G4 instances powered by NVIDIA T4 Tensor Core GPUs.
- Speaker: Sebastian Dreisch, Head of Wavelength GTM, Amazon Web Services
- Development of autonomous driving systems presents a massive computational challenge, including processing petabytes of sensor data, which impacts time to market, scale, and cost, throughout the development cycle. Training, testing, validating, and deploying self-driving systems requires large-scale compute and storage infrastructure to support the end-to-end workflow. AWS offers a highly scalable and reliable solution for AV development including the latest generation GPUs from NVIDIA. By attending this webinar, you will learn about AWS AV solution architectures for data ingest, data management, simulation, and distributed model training, as well as strategies for cost optimization. NVIDIA will share new details about the next generation NVIDIA Ampere (A100) architecture. Attendees will walk away with an understanding of how AWS and NVIDIA can help streamline AV development and reduce IT costs and time-to-market.
- Speakers: Shyam Kumar, Principal HPC Business Development Manager, Amazon Web Services, and Norm Marks, Global Senior Director, Automotive Industry, NVIDIA
- We’re all used to change. In business, change is often predictable—different seasons, large-scale events, and new releases all drive fluctuations we’re used to. But right now, there’s nothing normal about the changes you’re facing. The only constant is uncertainty. And uncertainty is expensive. In the absence of an omniscient crystal ball, the next best thing is cloud and ML. This presentation is going to cover how to deal with the unexpected. Whether it’s rapidly changing traffic, shifting data sources, or model drift, we’ll cover how you can better manage spikes and dips of all sizes and improve predictions with AI to maximize your efficiencies today.
- Speaker: Allie Miller, US Head of ML Business Development for Startups and Venture Capital at AWS, Amazon Web Services
Accelerating Data Science with NVIDIA RAPIDS (Scheduled session ID: A22042)
- Data science workflows have become increasingly computationally intensive in recent years, and GPUs have stepped up to address this challenge. With the RAPIDS suite of open-source software libraries and APIs, data scientists can run end-to-end data science and analytics pipelines entirely on GPUs, allowing organizations to deliver results faster than ever. The AWS Cloud lets you access a large number of powerful NVIDIA GPUs with Amazon EC2 P3 based on V100 GPUs, Amazon EC2 G4 based on T4 GPUs, and upcoming A100-based GPU instances. We’ll go through the end-to-end process of running on RAPIDS on AWS. We’ll start by running RAPIDS libraries on a single GPU instance. Next, we’ll see how you can run large-scale hyperparameter search experiments with RAPIDS and Amazon SageMaker. Finally, we’ll run RAPIDS distributed ML using Dask clusters on Amazon EKS and Amazon ECS.
- Speaker: Shashank Prasanna, Senior Developer Advocate, AI/ML, Amazon Web Services
Interactive Scientific Visualization on AWS with NVIDIA IndeX SDK (On-Demand session ID: A21610)
- Scientific visualization is critical to understanding complex phenomena modeled using HPC simulations. However, it has been challenging to do this effectively due to the inability to visualize large data volumes (> 1 PB) and lack of collaborative workflow solutions. NVIDIA IndeX on AWS, a 3D volumetric interactive visualization toolkit, addresses these problems by providing a scalable scientific visualization solution. NVIDIA IndeX allows you to make real-time modifications and navigate to the most pertinent parts of the data to gather better insights faster. IndeX leverages GPU clusters for scalable, real-time visualization and computing of multi-valued volumetric data together with embedded geometry data. We’ll demonstrate 3D volume rendering at scale on AWS using IndeX.
- Speakers: Karthik Raman, Senior Solutions Architect, HPC, Amazon Web Services, and Dragos Tatulea, Software Engineer, NVIDIA
Conclusion
You can also visit AWS and NVIDIA to learn more or apply for a free trial to use NVIDIA GPU-based Amazon EC2 P3 instances powered by NVIDIA V100 Tensor Core GPUs and Amazon EC2 G4 instances powered by NVIDIA T4 Tensor Core GPUs. Learn more about GTC on the GTC 2020 website. We look forward to seeing you there!
About the Author
 Geoff Murase is a Senior Product Marketing Manager for AWS EC2 accelerated computing instances, helping customers meet their compute needs by providing access to hardware-based compute accelerators such as Graphics Processing Units (GPUs) or Field Programmable Gate Arrays (FPGAs). In his spare time, he enjoys playing basketball and biking with his family.
Geoff Murase is a Senior Product Marketing Manager for AWS EC2 accelerated computing instances, helping customers meet their compute needs by providing access to hardware-based compute accelerators such as Graphics Processing Units (GPUs) or Field Programmable Gate Arrays (FPGAs). In his spare time, he enjoys playing basketball and biking with his family.
Emine Yilmaz: An Amazon Scholar advancing the state of the art in voice shopping
Scientist leads team in London focused on improving voice-shopping experiences with Alexa.Read More
Building an end-to-end intelligent document processing solution using AWS
As organizations grow larger in size, so does the need for having better document processing. In industries such as healthcare, legal, insurance, and banking, the continuous influx of paper-based or PDF documents (like invoices, health charts, and insurance claims) have pushed businesses to consider evolving their document processing capabilities. In such scenarios, businesses and organizations find themselves in a race against time to deploy a sophisticated document analysis pipeline that can handle these documents in an automated and scalable fashion.
You can use Amazon Textract and Amazon Augmented AI (Amazon A2I) to process critical documents and for your NLP-based entity recognition models with Amazon SageMaker Ground Truth, Amazon Comprehend, and Amazon A2I. This post introduces another way to create a retrainable end-to-end document analysis solution with Amazon Textract, Amazon Comprehend, and Amazon A2I.
This solution takes scanned images of physical documents as input and extracts the text using Amazon Textract. It sends the text to be analyzed by a custom entity recognizer trained in Amazon Comprehend. Machine Learning applications such as Amazon Comprehend work really well at scale, and in order to achieve 100% accuracy, you can use human reviewers to review and validate low confidence predictions. Additionally, you can use this human input to improve your underlying machine learning models. This is done by sending the output from Amazon Comprehend to be reviewed by human reviewers using Amazon A2I so that you can feed it back to retrain the models and improve the quality for future iterations. You can also use Amazon A2I to provide human oversight to your machine learning models and randomly send some data for human review to sample the output quality of your custom entity recognizer. This automated pipeline can scale to millions of documents with the help of these services and allow businesses to do more detailed analysis of their documents.
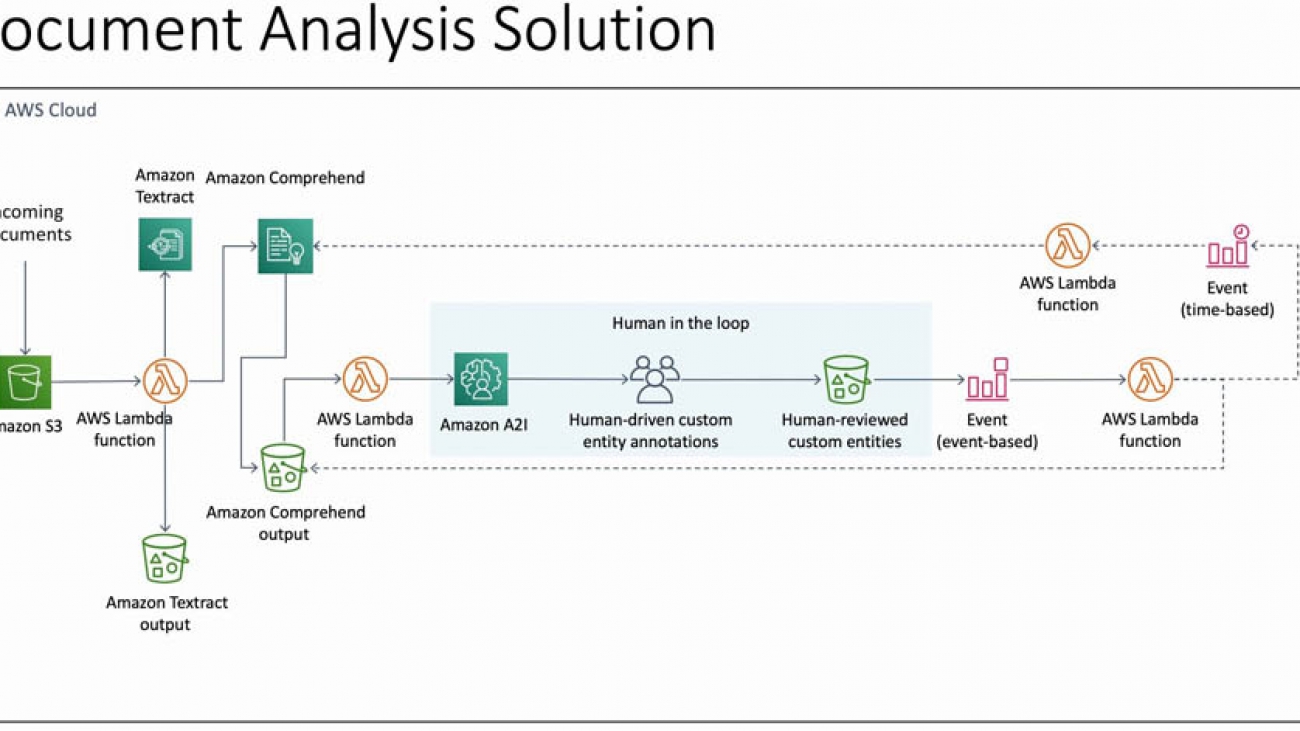
Solution overview
The following diagram illustrates the solution architecture.
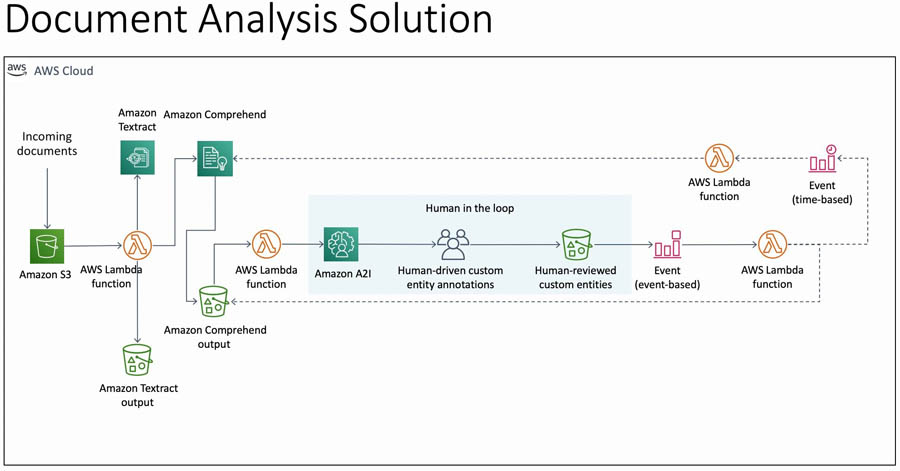
This solution takes images (scanned documents or screenshots or pictures of documents) as input. You can upload these files programmatically or through the AWS Management Console into an Amazon Simple Storage Service (Amazon S3) bucket in the input folder. This action triggers an AWS Lambda function, TextractComprehendLambda, through event notifications.
The TextractComprehendLambda function sends the image to Amazon Textract to extract the text from the image. When it acquires the results, it collates the results and sends the text to the Amazon Comprehend custom entity recognizer. The custom entity recognizer is a pre-trained model that identifies entities in the text that are valuable to your business. This post demonstrates how to do this, in detail, in the following sections.
The custom entity recognizer stores the results in a separate bucket, which acts as a temporary storage for this data. This bucket has another event notification, which triggers the ComprehendA2ILambda function. This Lambda function takes the output from the custom entity recognizer, processes it, and send the results to Amazon A2I by creating a human loop for review and verification.
Amazon A2I starts the human loop, providing reviewers an interface to double-check and correct the results that may not have been identified in the custom entity recognition process. These reviewers submit their responses through the Amazon A2I worker console. When the human loop is complete, Amazon A2I sends an Amazon CloudWatch event, which triggers the HumanReviewCompleted Lambda.
The HumanReviewCompleted function checks if the human reviewers have added any more annotations (because they found more custom entities). If the human reviewers found something that the custom entity recognizer missed, the function creates a new file called updated_entity_list.txt. This file contains all the entities that weren’t present in the previous training dataset.
At the end of each day, a CloudWatch alarm triggers the NewEntityCheck function. This function compares the entity_list.txt file and the updated_entity_list.txt file to check if any new entities were added in the last day. If so, it starts a new Amazon Comprehend custom entity recognizer training job and enables the CloudWatch time-based event trigger that triggers the CERTrainingCompleteCheck function every 15 minutes.
The CERTrainingCompleteCheck function checks if the Amazon Comprehend custom entity recognizer has finished training. If so, the function adds the entries from updated_entity_list.txt to entity_list.txt so it doesn’t train the model again, unless even more entities are found by the human reviewers. It also disables its own CloudWatch time-based event trigger, because it doesn’t need to check the training process until it starts again. The next invocation of the TextractComprehend function uses the new custom entity recognizer, which has learned from the previous reviews of the humans.
All these Lambda functions use AWS Systems Manager Parameter Store for sharing, retaining, and updating the various variables, like which custom entity recognizer is the current one and where all the data is stored.
We demonstrate this solution in the us-east-1 Region but, you can run it in any compatible Region. For more information about availability of services in your Region, see the AWS Region Table.
Prerequisites
This post requires that you have an AWS account with appropriate AWS Identity and Access Management (IAM) permissions to launch the AWS CloudFormation template.
Deploying your solution
To deploy your solution, you complete the following high-level steps:
- Create an S3 bucket.
- Create a custom entity recognizer.
- Create a human review workflow.
- Deploy the CloudFormation stack.
Creating an S3 bucket
You first create the main bucket for this post. You use it to receive the input (the original scans of documents), and store the outputs for each step of the analysis. The Lambda functions pick up the results at the end of each state and collate them for further use and record-keeping. For instructions on creating a bucket, see Create a Bucket.
Capture the name of the S3 bucket and save it to use later in this walkthrough. We refer this bucket as <primary_bucket> in this post. Replace this with the name of your actual bucket as you follow along.
Creating a custom entity recognizer
Amazon Comprehend allows you to bring your own training data, and train custom entity recognition models to customize the entity recognition process to your business-specific use cases. You can do this without having to write any code or have any in-house machine learning (ML) expertise. For this post, we provide a training dataset and document image, but you can use your own datasets when customizing Amazon Comprehend to suit your use case.
- Download the training dataset.
- Locate the bucket you created on the Amazon S3 console.
For this post, we use the bucket textract-comprehend-a2i-data, but you should use the name that you used for <primary_bucket>.
- Open the bucket and choose Create folder.
- For name, enter
comprehend_data.
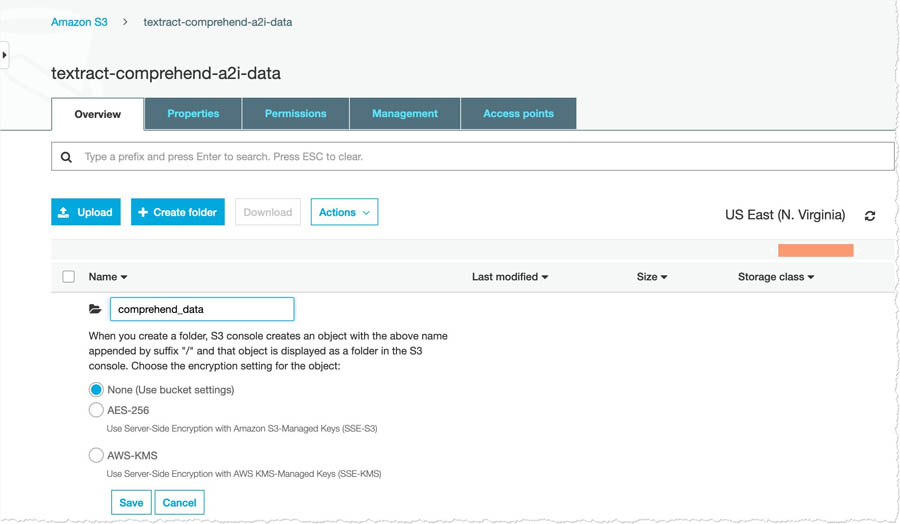
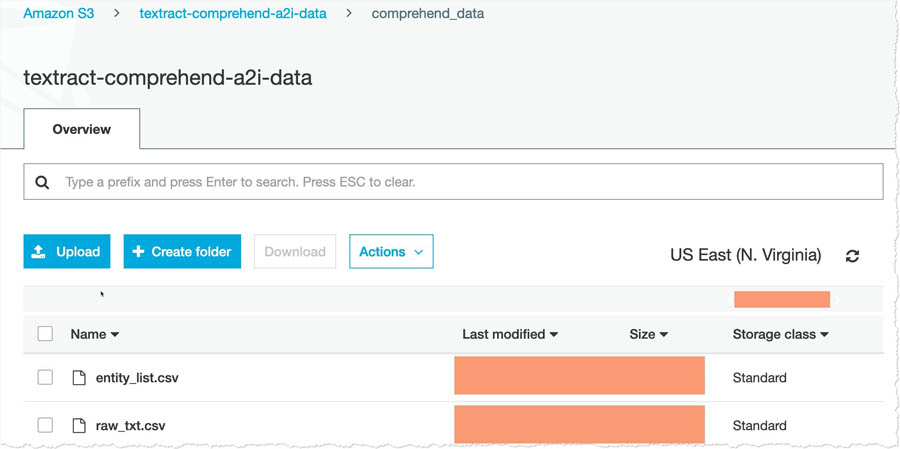
- Uncompress the file you downloaded earlier and upload the files to the
comprehend_datafolder.
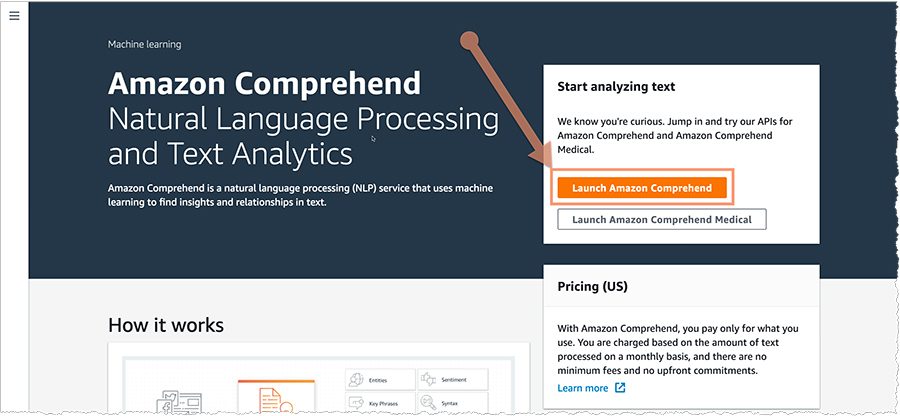
- On the Amazon Comprehend console, click on Launch Amazon Comprehend.
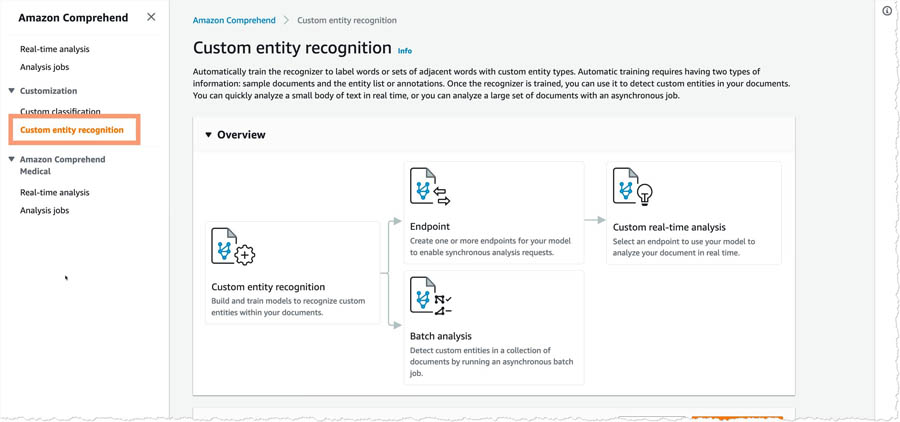
- Under Customization, choose Custom entity recognition.
- Choose Train Recognizer to open the entity recognizer training page.
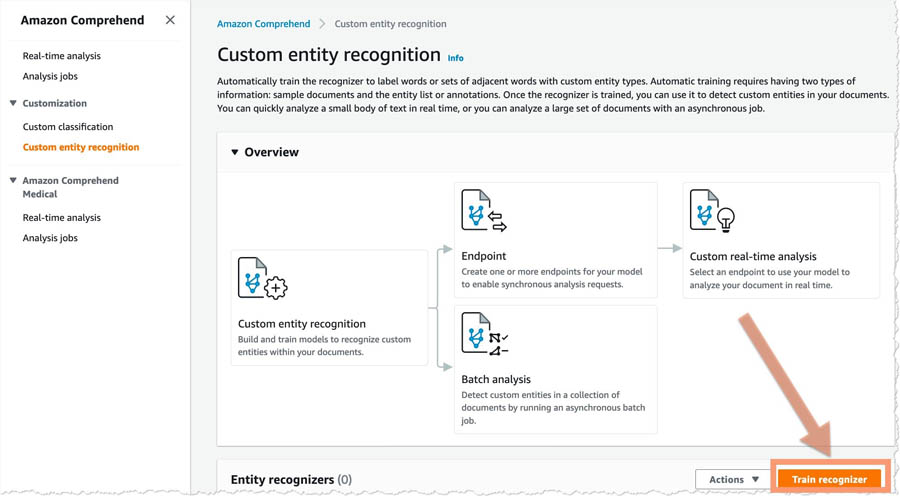
- For Recognizer name, enter a name.
The name that you choose appears in the console hereafter, so something human readable and easily identifiable is ideal.
- For Custom entity types, enter your custom entity type (for this post, we enter
DEVICE).
At the time of this writing, you can have up to 25 entity types per custom entity recognizer in Amazon Comprehend.
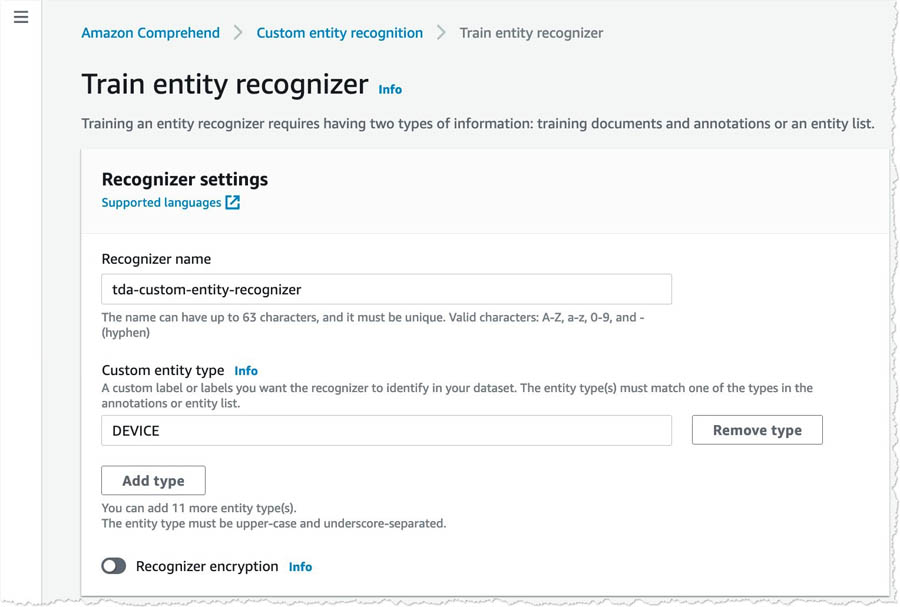
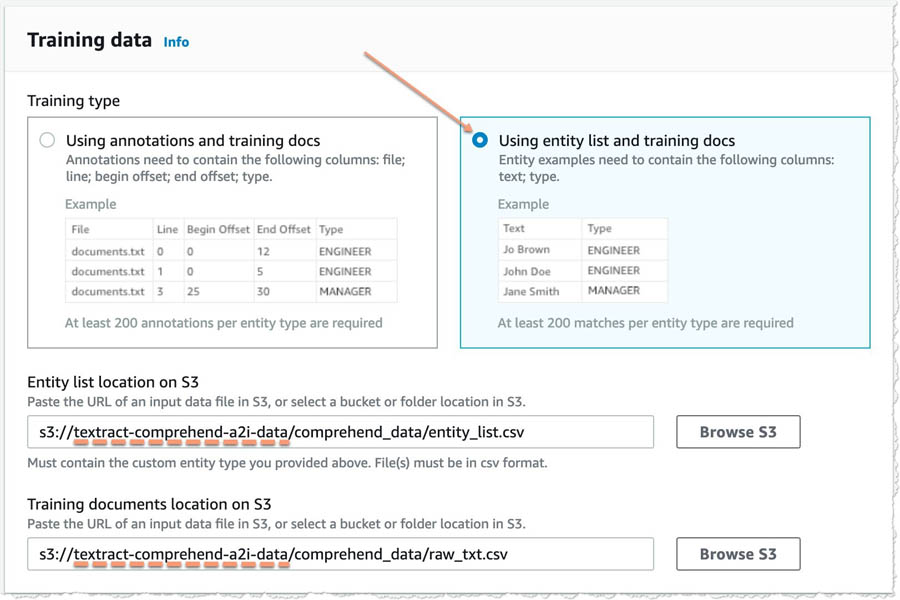
- In the Training data section, select Using entity list and training docs.
- Add the paths to
entity_list.csvandraw_txt.csvfor your <primary_bucket>.
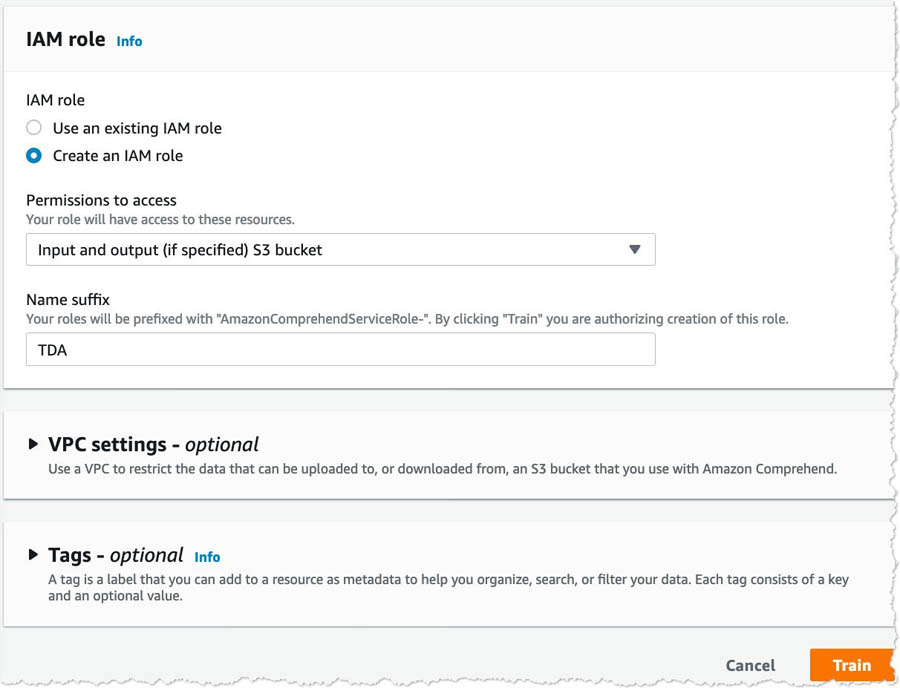
- In the IAM role section, select Create a new role.
- For Name suffix, enter a suffix you can identify later (for this post, we enter
TDA). - Leave the remaining settings as default and choose Train.
- When the training is complete, choose your recognizer and copy the ARN for your custom entity recognizer for future use.
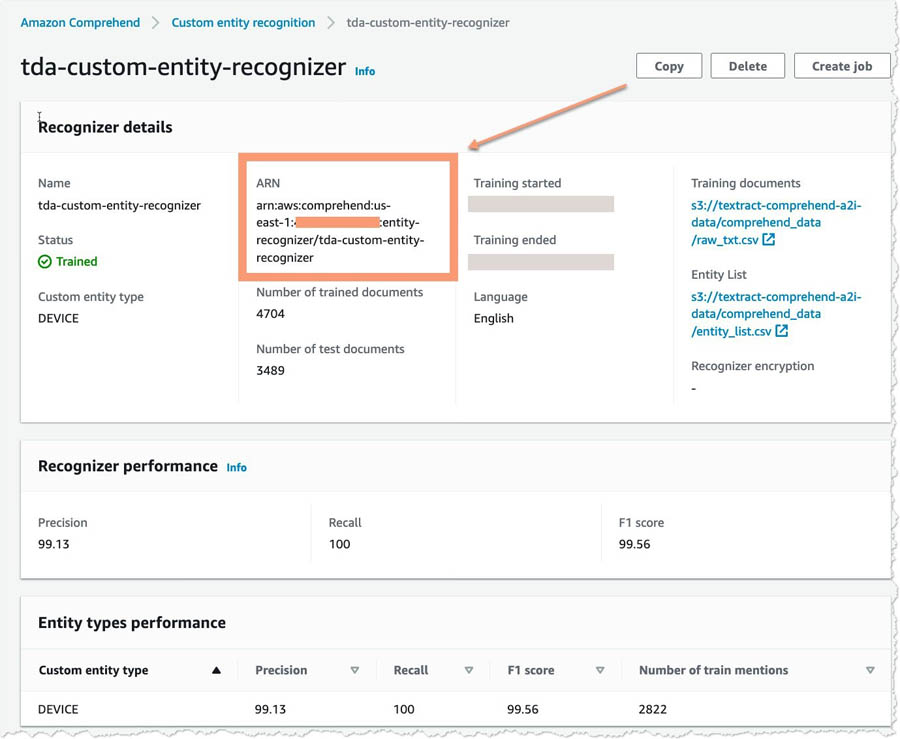
Creating a human review workflow
To create a human review workflow, you need to have three things ready:
- Reviewing workforce – A work team is a group of people that you select to review your documents. You can create a work team from a workforce, which is made up of Amazon Mechanical Turk workers, vendor-managed workers, or your own private workers that you invite to work on your tasks. Whichever workforce type you choose, Amazon A2I takes care of sending tasks to workers. For this post, you create a work team using a private workforce and add yourself to the team to preview the Amazon A2I workflow.
- Worker task template – This is a template that defines what the console looks like to the reviewers.
- S3 bucket – This is where the output of Amazon A2I is stored. You already created a bucket earlier, so this post uses the same bucket.
Creating a workforce
To create and manage your private workforce, you can use the Labeling workforces page on the Amazon SageMaker console. When following the instructions, you can create a private workforce by entering worker emails or importing a pre-existing workforce from an Amazon Cognito user pool.
If you already have a work team, you can use the same work team with Amazon A2I and skip to the following section.
To create your private work team, complete the following steps:
- Navigate to the Labeling workforces page on the Amazon SageMaker console.
- On the Private tab, choose Create private team.
- Choose Invite new workers by email.
- For this post, enter your email address to work on your document processing tasks.
You can enter a list of up to 50 email addresses, separated by commas, into the Email addresses box.
- Enter an organization name and contact email.
- Choose Create private team.
- After you create a private team, choose the team to start adding reviewers to your private workforce.
- On the Workers tab, choose Add workers to team.
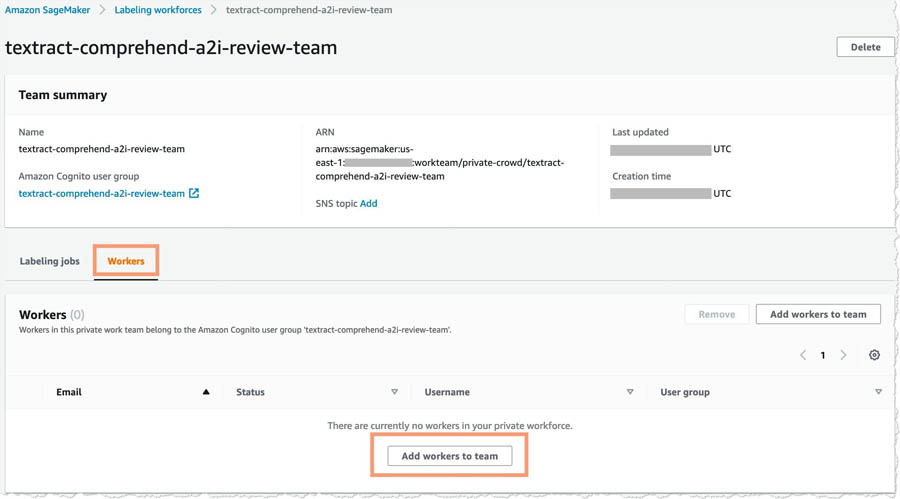
- Enter the email addresses you want to add and choose Invite new workers.
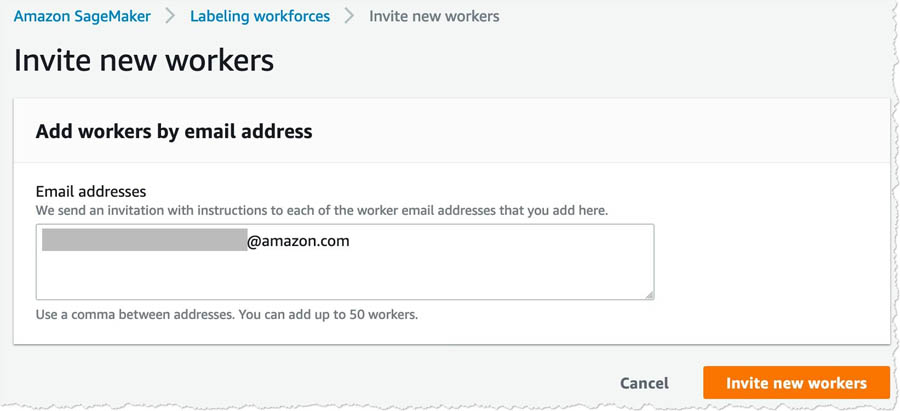
After you add the workers (in this case, yourself), you get an email invitation. The following screenshot shows an example email.

After you choose the link and change your password, you’re registered as a verified worker for this team. Your one-person team is now ready to review.
- Choose the link for Labeling Portal Sign-in URL and log in using the credentials generated in the previous step.
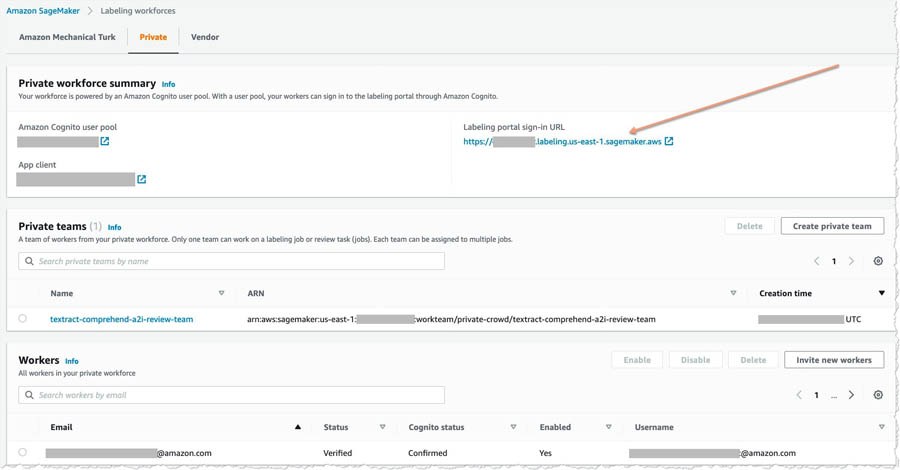
You should see a page similar to the following screenshot.
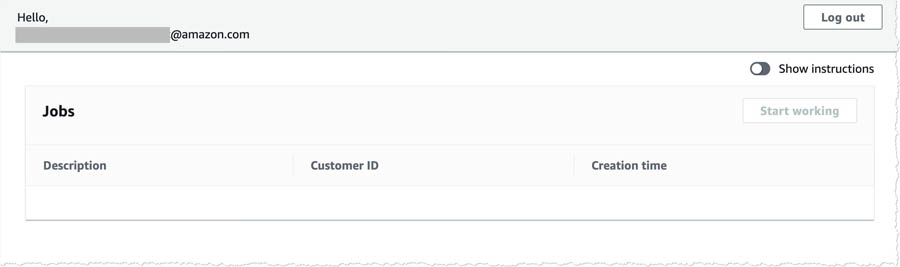
This is the Amazon A2I worker portal.
Creating a worker task template
You can use a worker template to customize the interface and instructions that your workers see when working on your tasks. To create a worker task template, complete the following steps:
- Navigate to the Worker task templates page on the Amazon SageMaker console.
For this post, we use Region us-east-1. For availability details for Amazon A2I and Amazon Translate in your preferred Region, see the AWS Region Table.
- Choose Create template.
- For Template name, enter
translate-a2i-template.
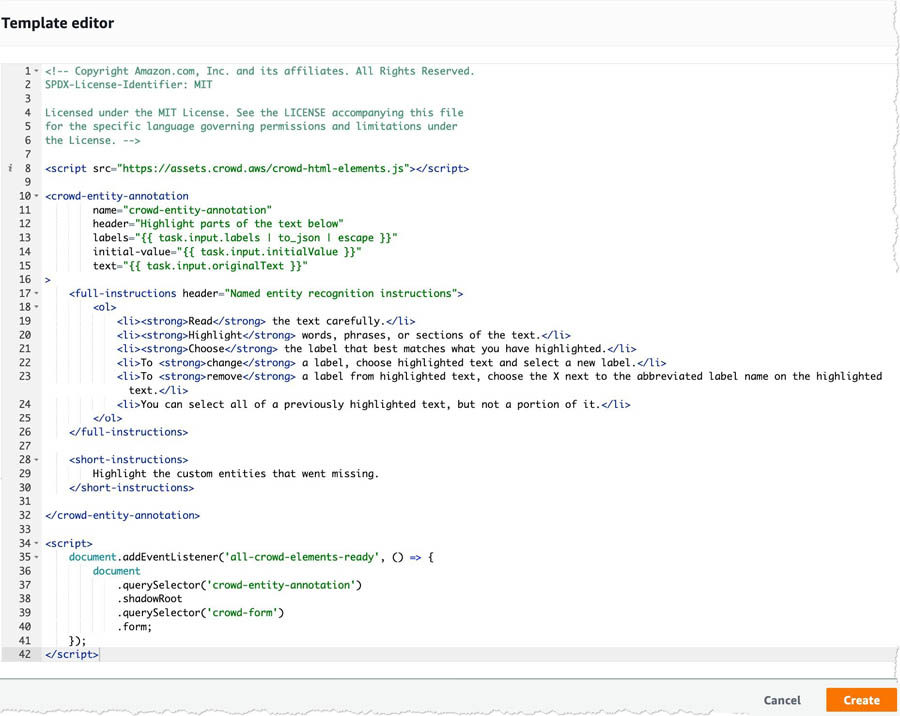
- In the Template editor field, enter the code from the following task-template.html.zip file:
<!-- Copyright Amazon.com, Inc. and its affiliates. All Rights Reserved.
SPDX-License-Identifier: MIT
Licensed under the MIT License. See the LICENSE accompanying this file
for the specific language governing permissions and limitations under
the License. -->
<script src="https://assets.crowd.aws/crowd-html-elements.js"></script>
<crowd-entity-annotation
name="crowd-entity-annotation"
header="Highlight parts of the text below"
labels="{{ task.input.labels | to_json | escape }}"
initial-value="{{ task.input.initialValue }}"
text="{{ task.input.originalText }}"
>
<full-instructions header="Named entity recognition instructions">
<ol>
<li><strong>Read</strong> the text carefully.</li>
<li><strong>Highlight</strong> words, phrases, or sections of the text.</li>
<li><strong>Choose</strong> the label that best matches what you have highlighted.</li>
<li>To <strong>change</strong> a label, choose highlighted text and select a new label.</li>
<li>To <strong>remove</strong> a label from highlighted text, choose the X next to the abbreviated label name on the highlighted text.</li>
<li>You can select all of a previously highlighted text, but not a portion of it.</li>
</ol>
</full-instructions>
<short-instructions>
Highlight the custom entities that went missing.
</short-instructions>
</crowd-entity-annotation>
<script>
document.addEventListener('all-crowd-elements-ready', () => {
document
.querySelector('crowd-entity-annotation')
.shadowRoot
.querySelector('crowd-form')
.form;
});
</script>
- Choose Create
Creating a human review workflow
Human review workflows allow human reviewers to audit the custom entities that are detected using Amazon Comprehend on an ongoing basis. To create a human review workflow, complete the following steps:
- Navigate to the Human review workflow page the Amazon SageMaker console.
- Choose Create human review workflow.
- In the Workflow settings section, for Name, enter a unique workflow name.
- For S3 bucket, enter the S3 bucket where you want to store the human review results.
For this post, we use the same bucket that we created earlier, but add the suffix /a2i-raw-output. For example, if you created a bucket called textract-comprehend-a2i-data, enter the path s3://textract-comprehend-a2i-data/a2i-raw-output. This subfolder contains the edits that the reviewers make in all the human review workflow jobs that are created for Amazon Comprehend custom entity recognition. (Replace the bucket name with the value of <primary_bucket>.)
- For IAM role, choose Create a new role from the drop-down menu.
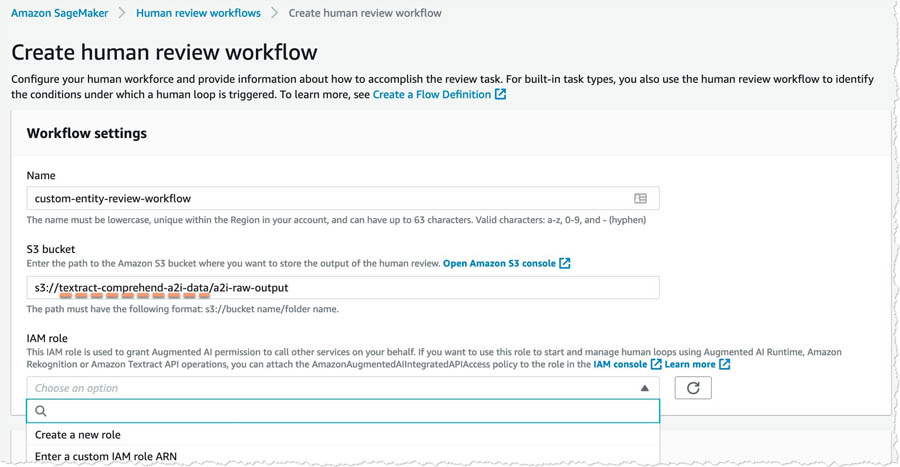
Amazon A2I can create a role automatically for you.
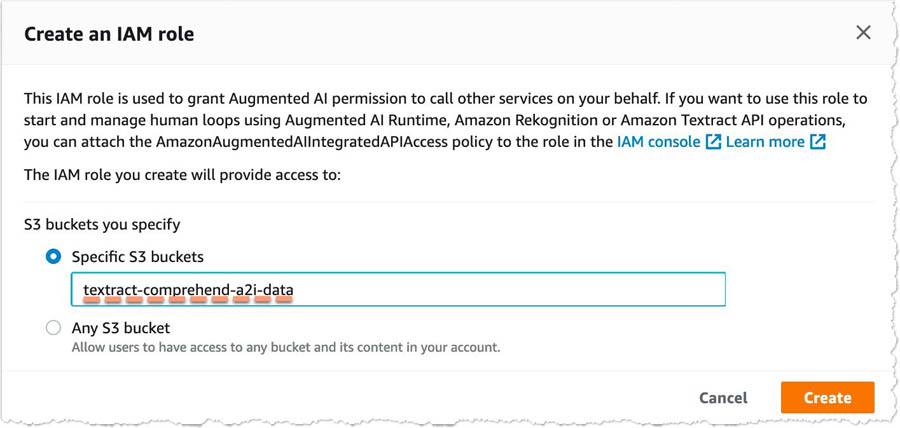
- For S3 buckets you specify, select Specific S3 buckets.
- Enter the name of the S3 bucket you created earlier (<primary_bucket>).
- Choose Create.
You see a confirmation when role creation is complete and your role is now pre-populated in the IAM role drop-down menu.

- For Task type, select Custom.
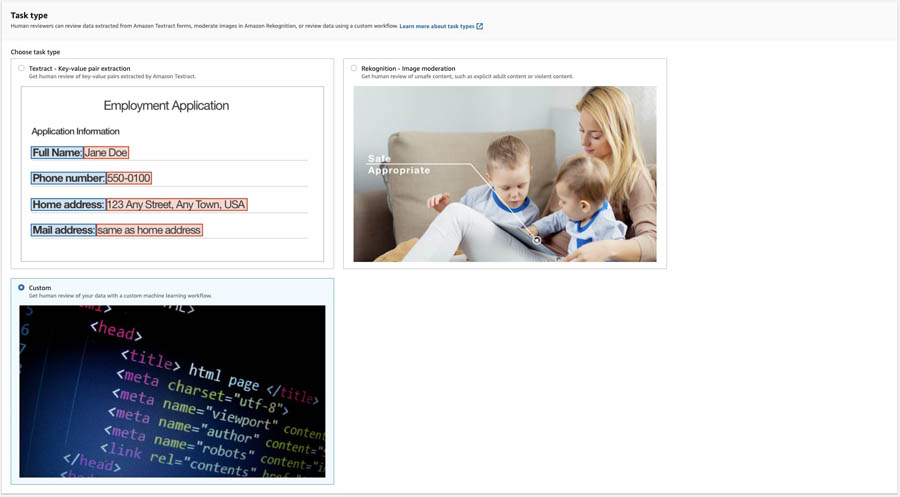
- In the Worker task template section, for Template, choose custom-entity-review-template.
- For Task description, add a description that briefly describes the task for your workers.
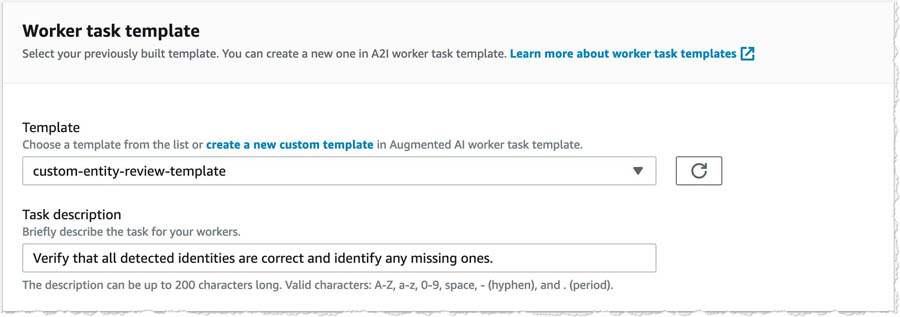
- In the Workers section, select
- For Private teams, choose textract-comprehend-a2i-review-team.
- Choose Create.
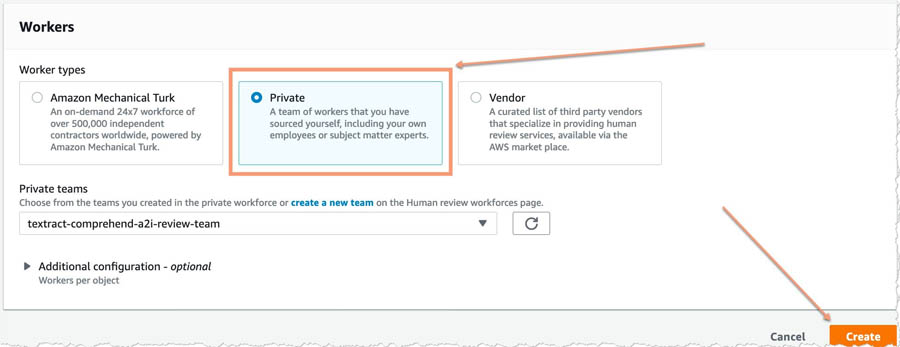
You see a confirmation when human review workflow creation is complete.
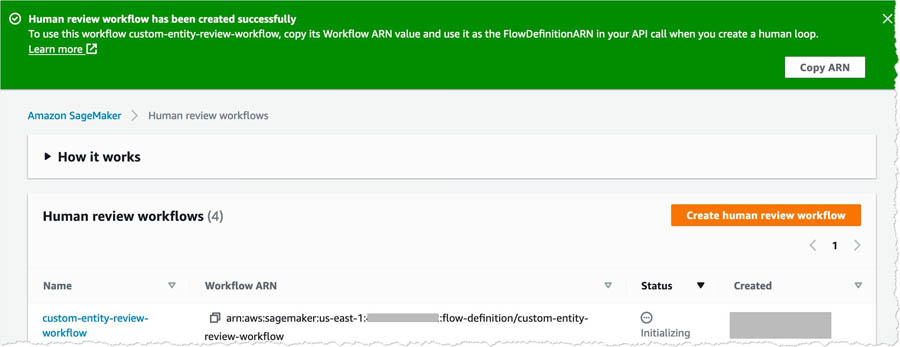
Copy the workflow ARN and save it somewhere. You need this in the upcoming steps. You also need to keep the Amazon A2I Worker Portal (created earlier) open and ready after this step.
Deploying the CloudFormation stack
Launch the following CloudFormation stack to deploy the stack required for running the entire flow:
![]()
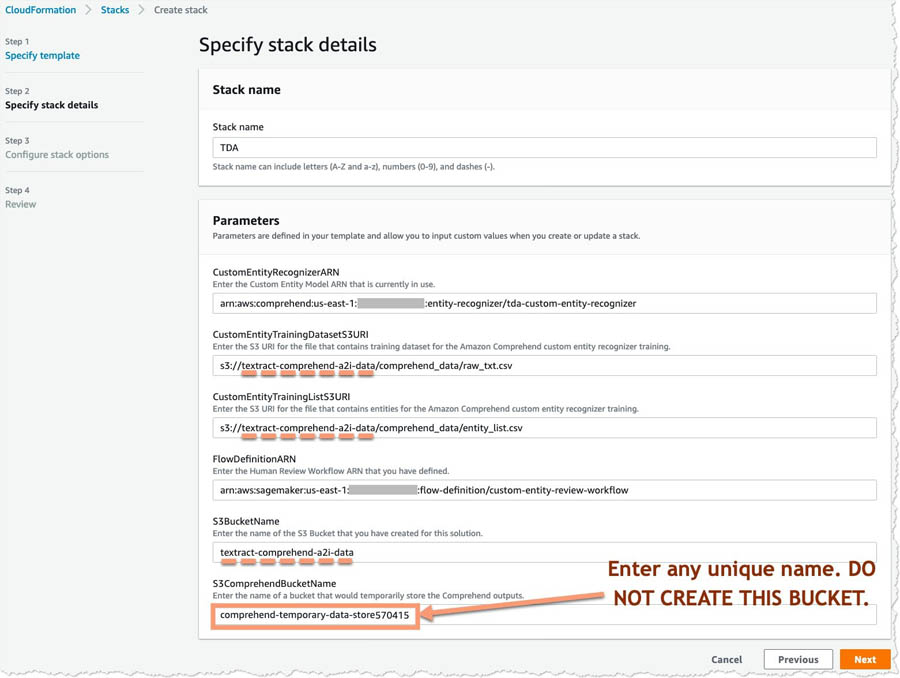
This creates the remaining elements for running your human review workflow for the custom entity recognizer. When creating the stack, enter the following values:
- CustomEntityRecognizerARN – The ARN for the custom entity recognizer.
- CustomEntityTrainingDatasetS3URI – The path to the training dataset that you used for creating the custom entity recognizer.
- CustomEntityTrainingListS3URI – The path to the entity list that you used for training the custom entity recognizer.
- FlowDefinitionARN – The ARN of the human review workflow.
- S3BucketName – The name of the bucket you created.
- S3ComprehendBucketName – A random name that must be unique so the template can create an empty S3 bucket to store temporary output from Amazon Comprehend in. You don’t need to create this bucket—the Cloudformation template does that for you, just provide a unique name here.
Choose the defaults of the stack deployment wizard. On the Review page, in the Capabilities and transforms section, select the three check-boxes and choose Create stack.
![]()
You need to confirm that the stack was deployed successfully on your account. You can do so by navigating to the AWS CloudFormation console and looking for the stack name TDA.

When the status of the stack changes to CREATE_COMPLETE, you have successfully deployed the document analysis solution to your account.
Testing the solution
You can now test the end-to-end flow of this solution. To test each component, you complete the following high-level steps:
- Upload a file.
- Verify the Amazon Comprehend job status.
- Review the worker portal.
- Verify the changes were recorded.
Uploading a file
In real-world situations, when businesses receive a physical document, they scan, photocopy, email, or upload it to some form of an image-based format for safe-keeping as a backup mechanism. The following is the sample document we use in this post.

To upload the file, complete the following steps:
- Download the image.
- On the Amazon S3 console, navigate to your <primary_bucket>.
- Choose Create folder.
- For Name, enter
input. - Choose Save.
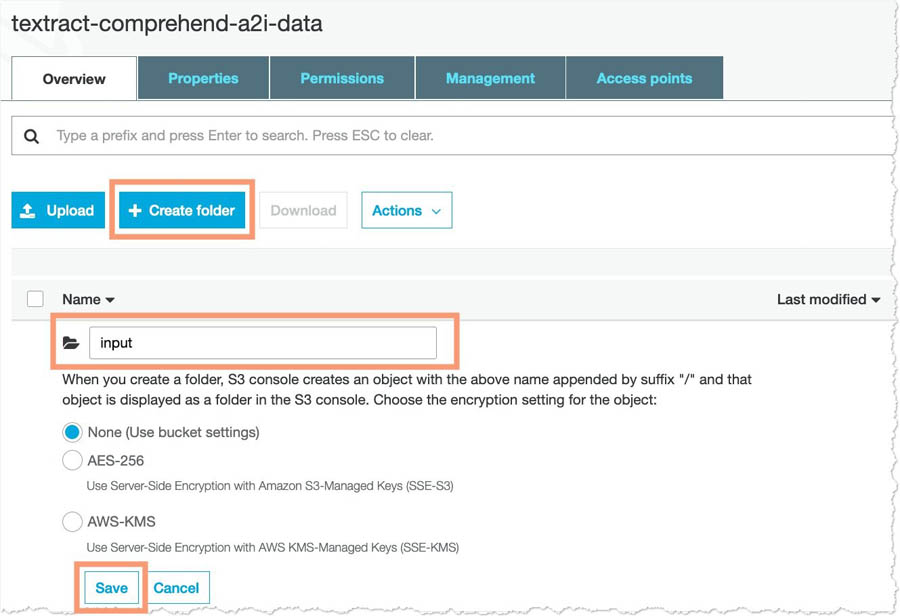
- Upload the image you downloaded into this folder.
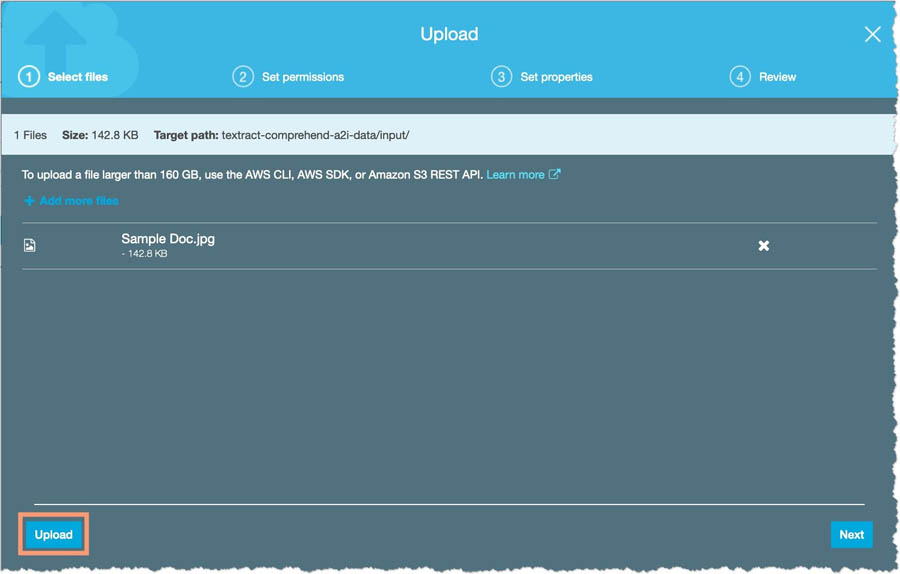
This upload triggers the TextractComprehendA2ILambda function, which sends the uploaded image to Amazon Textract and sends the response received from Amazon Comprehend.
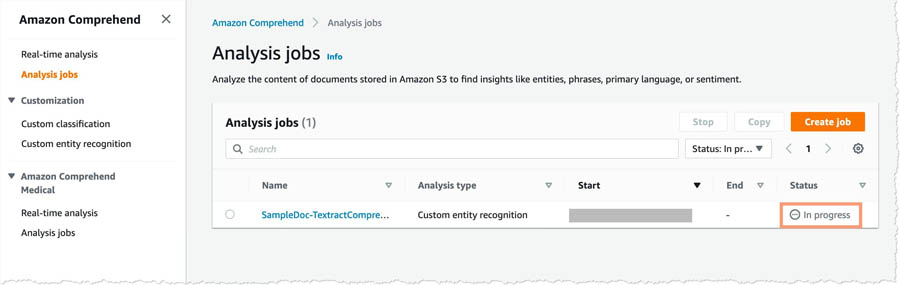
Verifying Amazon Comprehend job status
You can now verify that the Amazon Comprehend job is working.
- On the Amazon Comprehend console, choose Analysis jobs.
- Verify that your job is in status
In progress.
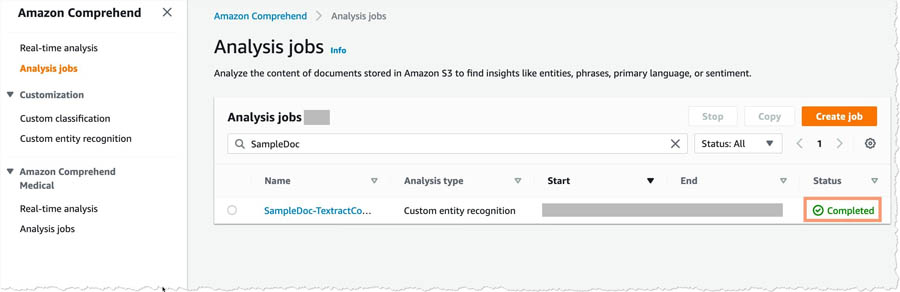
When the status switches to Completed, you can proceed to the next step.
Reviewing the worker portal
You can now test out the human review worker portal.
- Navigate to the Amazon A2I worker portal that you created.
You should have a new job waiting to be processed.
- Select the job and choose Start working.
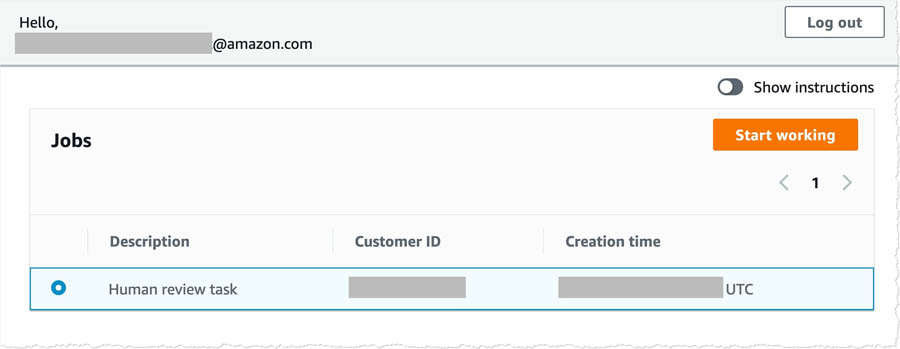
You’re redirected to the review screen.
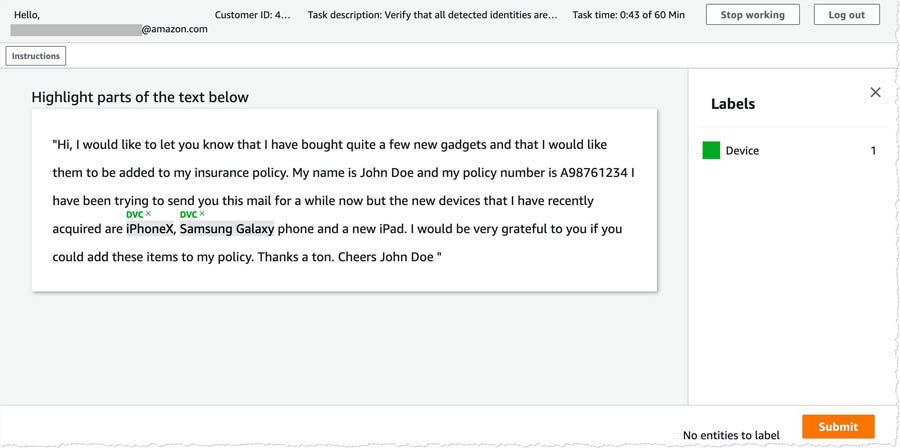
- Tag any new entities that the algorithm missed.
- When you’re finished, choose Submit.
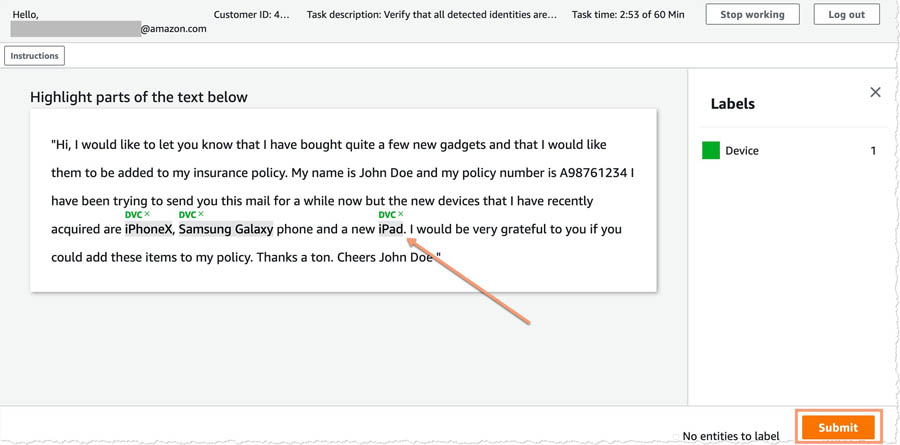
Verify that the changes were recorded
Now that you have added your inputs in the A2I console, the HumanWorkflowCompleted Lambda function adds the identified entities to the already existing file and stores it in a separate entity list in the S3 bucket. You can verify that this has happened by navigating to <primary_bucket> on the Amazon S3 console.
In the folder comprehend_data, you should see a new file called updated_entity_list.csv.
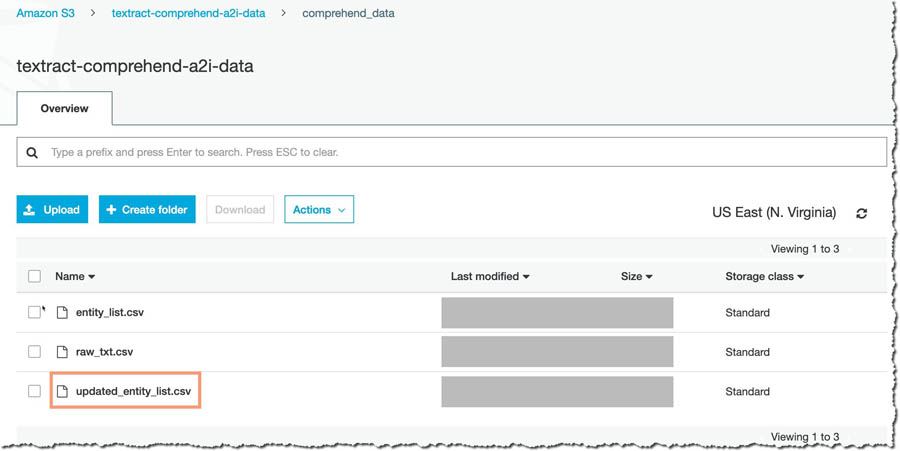
The NewEntityCheck Lambda function uses this file at the end of each day to compare against the original entity_list.csv file. If new entities are in the updated_entity_list.csv file, the model is retrained and replaces the older custom entity recognition model.
This allows the Amazon Comprehend custom entity recognition model to improve continuously by incorporating the feedback received from human reviewers through Amazon A2I. Over time, this can reduce the need for reviewers and manual intervention by analyzing documents in a more intelligent and sophisticated manner.
Cost
With this solution, you can now process scanned and physical documents at scale and do ML-powered analysis on them. The cost to run this example is less than $5.00. For more information about exact costs, see Amazon Textract pricing, Amazon Comprehend pricing, and Amazon A2I pricing.
Cleaning up
To avoid incurring future charges, delete the resources when not in use.
Conclusion
This post demonstrated how you can build an end-to-end document analysis solution for analyzing scanned images of documents using Amazon Textract, Amazon Comprehend, and Amazon A2I. This allows you to create review workflows for the critical documents you need to analyze using your own private workforce, and provides increased accuracy and context.
This solution also demonstrated how you can improve your Amazon Comprehend custom entity recognizer over time by retraining the models on the newer entities that the reviewers identify.
For the code used in this walkthrough, see the GitHub repo. For information about adding another review layer for Amazon Textract using Amazon A2I, see Using Amazon Textract with Amazon Augmented AI for processing critical documents.
About the Author
 Purnesh Tripathi is a Solutions Architect at Amazon Web Services. He has been a data scientist in his previous life, and is passionate about the benefits that Machine Learning and Artificial Intelligence bring to a business. He works with small and medium businesses, and startups in New Zealand to help them innovate faster using AWS.
Purnesh Tripathi is a Solutions Architect at Amazon Web Services. He has been a data scientist in his previous life, and is passionate about the benefits that Machine Learning and Artificial Intelligence bring to a business. He works with small and medium businesses, and startups in New Zealand to help them innovate faster using AWS.
Creating a multi-department enterprise search using custom attributes in Amazon Kendra
An enterprise typically houses multiple departments such as engineering, finance, legal, and marketing, creating a growing number of documents and content that employees need to access. Creating a search experience that intuitively delivers the right information according to an employee’s role, and the department is critical to driving productivity and ensuring security.
Amazon Kendra is a highly accurate and easy-to-use enterprise search service powered by machine learning. Amazon Kendra delivers powerful natural language search capabilities to your websites and applications. These capabilities help your end-users easily find the information they need within the vast amount of content spread across your company.
With Amazon Kendra, you can index the content from multiple departments and data sources into one Amazon Kendra index. To tailor the search experience by user role and department, you can add metadata to your documents and FAQs using Kendra’s built-in attributes and custom attributes and apply user context filters.
For search queries issued from a specific department’s webpage, you can set Kendra to only return content from that department filtered by the employee’s access level. For example, an associate role may only access a subset of restricted documents. In contrast, the department manager might have access to all the documents.
This post provides a solution to indexing content from multiple departments into one Amazon Kendra index. To manage content access, the organization can create restrictions based on an employee’s role and department or provide page-level filtering of search results. It demonstrates how content is filtered based on the web page location and individual user groups.
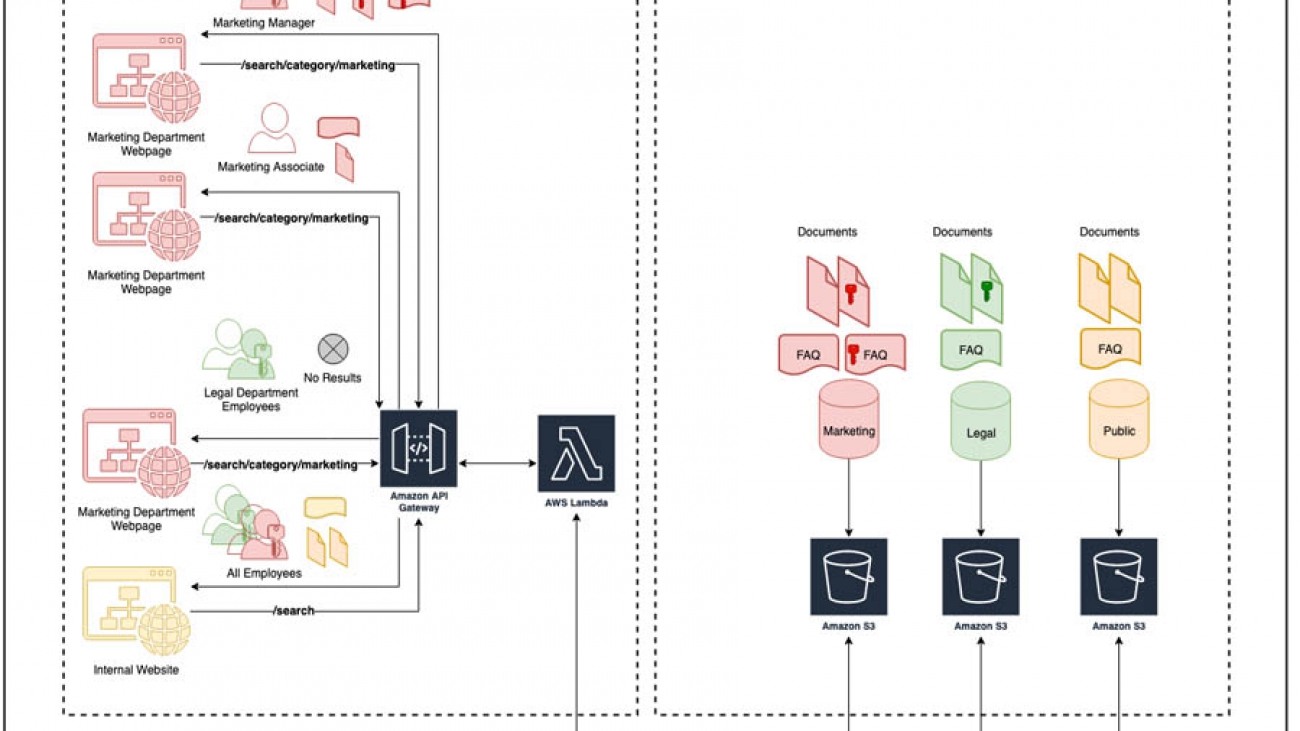
Solution architecture
The following architecture is comprised of two primary components: document ingestion into Amazon Kendra and document query using Amazon API Gateway.

The preceding diagram depicts a fictitious enterprise environment with two departments: Marketing and Legal. Each department has its own webpage on their internal website. Every department has two employee groups: associates and managers. Managers are entitled to see all the documents, but associates can only see a subset.
When employees from Marketing issue a search query on their department page, they only see the documents they are entitled to within their department (pink documents without the key). In contrast, the Marketing Manager sees all Marketing documents (all pink documents).
When employees from Legal search on a Marketing department page, they don’t see any documents. When all employees search on the internal website’s main page, they see the public documents common to all departments (yellow).
The following table shows the types of documents an employee gets for the various query combinations of webpage, department, and access roles.

Ingesting documents into Amazon Kendra
The document ingestion step consists of ingesting content and metadata from different departments’ specific S3 buckets, indexed by Amazon Kendra. Content can comprise structured data like FAQs and unstructured content like HTML, Microsoft PowerPoint, Microsoft Word, plain text, and PDF documents. For ingesting FAQ documents into Amazon Kendra, you can provide the questions, answers, and optional custom and access control attributes either in a CSV or JSON format.
You can add metadata to your documents and FAQs using the built-in attributes in Amazon Kendra, custom attributes, and user context filters. You can filter content using a combination of these custom attributes and user context filters. For this post, we index each document and FAQ with:
- Built-in attribute
_categoryto represent the web page. - User context filter attribute for the employee access level.
- Custom attribute
departmentrepresenting the employee department.
The following code is an example of the FAQ document for the Marketing webpage:
{
"SchemaVersion": 1,
"FaqDocuments": [{
"Question": "What is the reimbursement policy for business related expenses?",
"Answer": "All expenses must be submitted within 2 weeks.",
"Attributes": {
"_category": "page_marketing",
"department": "marketing"
},
"AccessControlList": [{
"Name": "associate",
"Type": "GROUP",
"Access": "ALLOW"
},{
"Name": "manager",
"Type": "GROUP",
"Access": "ALLOW"
}
]
},
{
"Question": "What are the manager guidelines for employee promotions ?",
"Answer": "Guidelines for employee promotions can be found on the manager portal.",
"Attributes": {
"_category": "page_marketing",
"department": "marketing"
},
"AccessControlList": [{
"Name": "manager",
"Type": "GROUP",
"Access": "ALLOW"
}]
}
]
}
The following code is an example of the metadata document for the Legal webpage:
{
"DocumentId": "doc1",
"Title": "What is the immigration policy?",
"ContentType": "PLAIN_TEXT",
"Attributes": {
"_category": "page_legal",
"department": "legal"
},
"AccessControlList": [
{
"Name": "associate",
"Type": "GROUP",
"Access": "ALLOW"
}
]
}Document search by department
The search capability is exposed to the client application using an API Gateway endpoint. The API accepts an optional path parameter for the webpage on which the query was issued. If the query comes from the Marketing-specific page, the query looks like /search/dept/marketing. For a comprehensive website search covering all the departments, you will leave out the path parameter. The query looks like /search. Every API request also has two header values: EMP_ROLE, representing the employee access level, and EMP_DEPT, representing the department name. In this post, we don’t describe how to authenticate users. We assume that you populate these two header values after authenticating the user with Amazon Cognito or your custom solutions.
The AWS Lambda function that serves the API Gateway parses the path parameters and headers and issues an Amazon Kendra query call with AttributeFilters set to the category name from the path parameter (if present), the employee access level, and department from the headers. Amazon Kendra returns the FAQs and documents for that particular category and filters them by the employee access level and department. The Lambda function constructs a response with these search results and sends the FAQ and document search results back to the client application.
Deploying the AWS CloudFormation template
- You can deploy this architecture using the provided AWS CloudFormation template in
us-east-1. Please click to get started.
![]()
- Choose Next.
- Provide a stack name and choose Next.
- In the Capabilities and transforms section, select all three check-boxes to provide acknowledgment to AWS CloudFormation to create IAM resources and expand the template.

- Choose Create stack.
This process might take 15 minutes or more to complete and creates the following resources:
- An Amazon Kendra index
- Three S3 buckets representing the departments: Legal, Marketing, and Public
- Three Amazon Kendra data sources that connect to the S3 buckets
- A Lambda function and an API Gateway endpoint that is called by the client application
After the CloudFormation template finishes deploying the above infrastructure, you will see the following Outputs.

API Key and Usage Plan
- The KendraQueryAPI will require an API key. The CloudFormation output
ApiGWKeyrefers to the name of the API key. Currently, this API key is associated with a usage plan that allows 2000 requests per month. - Click the link in the Value column corresponding to the Key
ApiGWKey. This will open the API Keys section of the API Gateway console. - Click Show next to the API key.
- Copy the API key. We will use this when testing the API.

- You can manage the usage plan by following the instructions on, Create, configure, and test usage plans with the API Gateway console.
- You can also add fine-grained authentication and authorization to your APIs. For more information on securing your APIs, you can follow instructions on Controlling and managing access to a REST API in API Gateway.
Uploading sample documents and FAQ
Add your documents and FAQs file to their corresponding S3 buckets. We’ve also provided you with some sample document files and sample FAQs file to download.
Upload all the document files whose file name prefix corresponds to the S3 buckets created as part of the CloudFormation. For example, all Marketing documents and their corresponding metadata files go into the kendra-blog-data-source-marketing-[STACK_NAME] bucket. Upload the FAQ document into to the kendra-blog-faqs-[STACK_NAME]bucket.
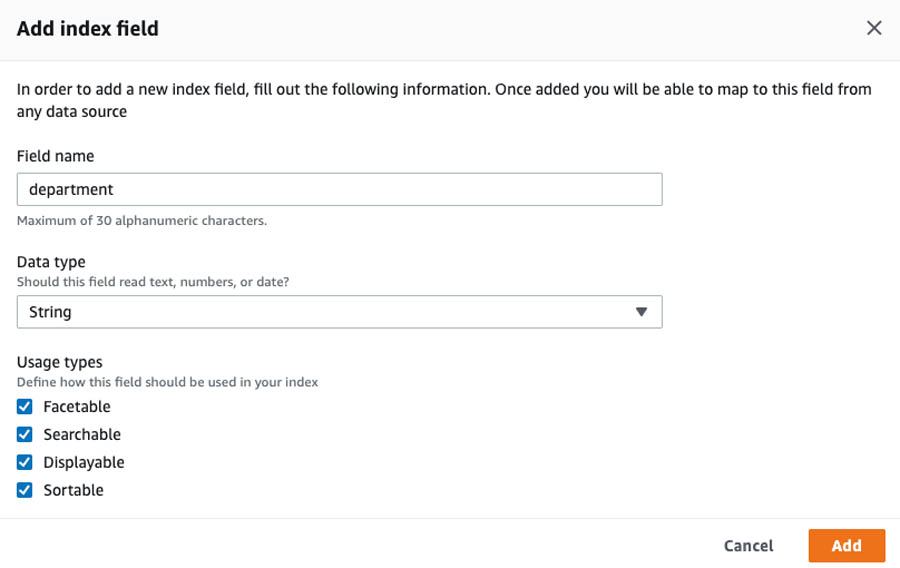
Creating the facet definition for custom attributes
In this step, you add a facet definition to the index.
- On the Amazon Kendra console, choose the index created in the previous step.
- Choose Facet definition.
- Choose the Add
- For Field name, enter
department. - For Data type, choose String.
- For Usage types, select Facetable, Searchable, Displayable, and Sortable.
- Choose Add.
- On the Amazon Kendra console, choose the newly created index.
- Choose Data sources.
- Sync
kendra-blog-data-source-legal-[STACK_NAME],kendra-blog-data-source-marketing-[STACK_NAME], andkendra-blog-data-source-public-[STACK_NAME]by selecting the data source name and choosing Sync now. You can sync multiple data sources simultaneously.
This should start the indexing process of the documents in the S3 buckets.
Adding FAQ documents
After you create your index, you can add your FAQ data.
- On the Amazon Kendra console, choose the new index.
- Choose FAQs.
- Choose Add FAQ.
- For FAQ name, enter a name, such as
demo-faqs-with-metadata. - For FAQ file format, choose JSON file.
- For S3, browse Amazon S3 to find
kendra-blog-faqs-[STACK_NAME], and choose thefaqs.jsonfile. - For IAM role, choose Create a new role to allow Amazon Kendra to access your S3 bucket.
- For Role name, enter a name, such as
AmazonKendra-blog-faq-role. - Choose Add.

Testing the solution
You can test the various combinations of page and user-level attributes on the API Gateway console. You can refer to Test a method with API Gateway console to learn about how to test your API using the API Gateway console.
The following screenshot is an example of testing the scenario where an associate from the Marketing department searches on the department-specific page.
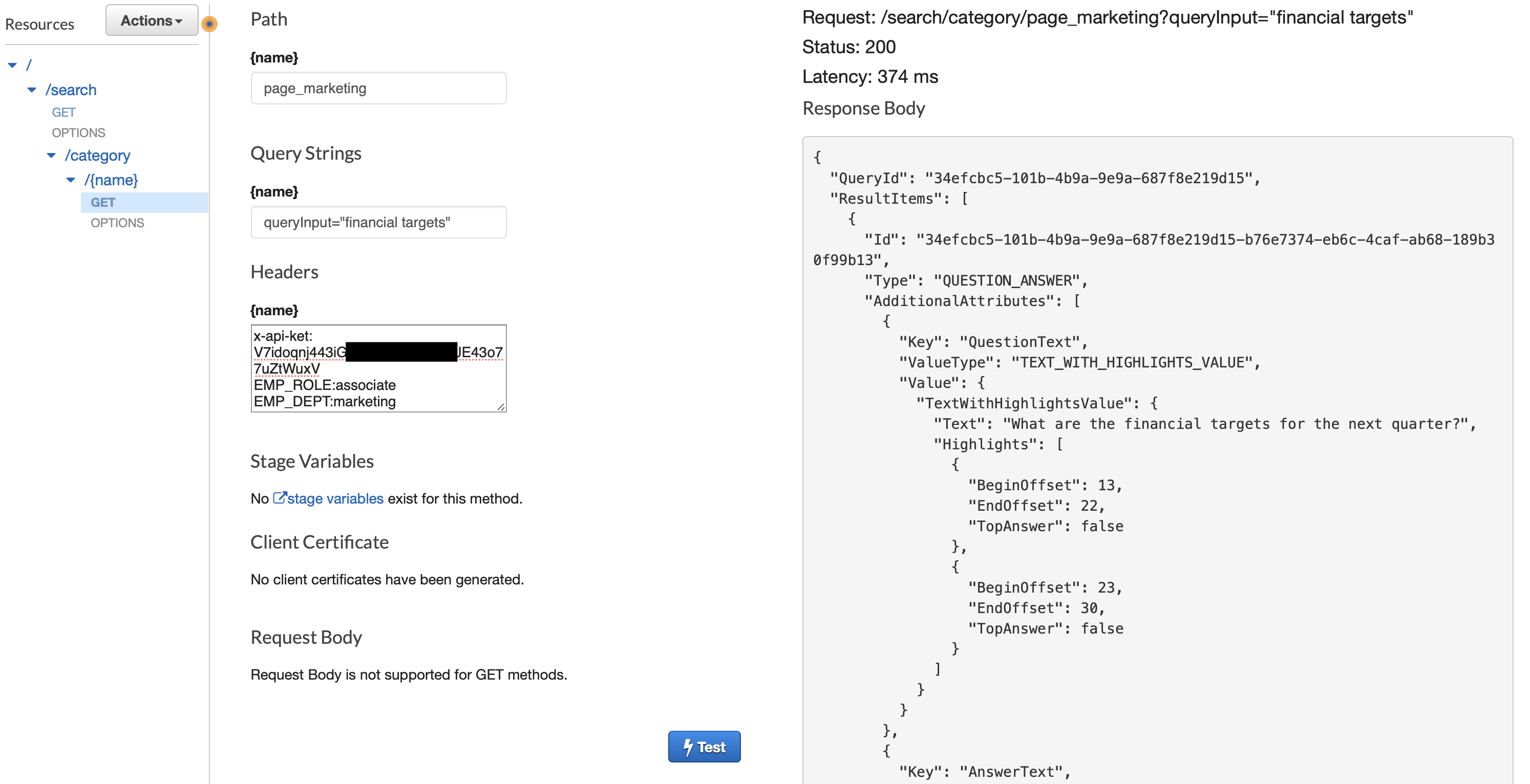
You will have to pass the following parameters while testing the above scenario.
- Path:
page_marketing - Query String:
queryInput="financial targets" - Headers:
x-api-key: << Your API Key copied earlier from the CloudFormation step >>EMP_ROLE:associateEMP_DEPT:marketing
You will see a JSON response with a FAQ result matching the above conditions.
…
"DocumentExcerpt": {"Text": "Please work with your manager to understand the goals for your department.",
…
You can keep the queryInput="financial targets" but change the EMP_ROLE from associate to manager, and you should see a different answer.
…
"DocumentExcerpt": { "Text": "The plan is achieve 2x the sales in the next quarter.",
….
Cleaning up
To remove all resources created throughout this process and prevent additional costs, complete the following steps:
- Delete all the files from the S3 buckets.
- On the AWS CloudFormation console, delete the stack you created. This removes the resources the CloudFormation template created.
Conclusion
In this post, you learned how to use Amazon Kendra to deploy a cognitive search service across multiple departments in your organization and filter documents using custom attributes and user context filters. To enable, Amazon Kendra you don’t need to have any previous ML or AI experience. Use Amazon Kendra to provide your employees with faster access to information that is spread across your organization.
About the Authors
 Shanthan Kesharaju is a Senior Architect in the AWS ProServe team. He helps our customers with AI/ML strategy, architecture, and develop products with a purpose. Shanthan has an MBA in Marketing from Duke University and an MS in Management Information Systems from Oklahoma State University.
Shanthan Kesharaju is a Senior Architect in the AWS ProServe team. He helps our customers with AI/ML strategy, architecture, and develop products with a purpose. Shanthan has an MBA in Marketing from Duke University and an MS in Management Information Systems from Oklahoma State University.
 Marty Jiang is a Conversational AI Consultant with AWS Professional Services. Outside of work, he loves spending time outdoors with his family and exploring new technologies.
Marty Jiang is a Conversational AI Consultant with AWS Professional Services. Outside of work, he loves spending time outdoors with his family and exploring new technologies.

Getting started with AWS DeepRacer community races
AWS DeepRacer allows you to get hands-on with machine learning (ML) through a fully autonomous 1/18th scale race car driven by reinforcement learning, a 3D racing simulator on the AWS DeepRacer console, a global racing league, and hundreds of customer-initiated community races.
With AWS DeepRacer community races, you can create your own race and invite your friends and colleagues to compete. The AWS DeepRacer console now supports object avoidance and head-to-bot races in addition to time trial racing formats, enabling racers at all skill levels to engage and learn about ML and challenge their friends. There’s never been a better time to get rolling with AWS DeepRacer!
The Accenture Grand Prix
We have worked with partners all over the world to bring ML to their employees and customers by enabling them to host their own races. One of these partners, Accenture, has been hosting its own internal AWS DeepRacer event since 2019. Accenture enables customers all over the world to build artificial intelligence (AI) and ML-powered solutions through their team of more than 8,000 AWS-trained technologists. They’re always looking for new and engaging ways to develop their teams with hands-on training.
In November 2019, Accenture launched their own internal AWS DeepRacer League. The Accenture league was planned to run throughout 2020, spanning 30 global locations in 17 countries, with a physical and virtual track at each location, for their employees to compete for the title of Accenture AWS DeepRacer Champion. At the start of their league season, Accenture hosted some in-person local events, which were well-attended and received, but as the COVID-19 pandemic unfolded, Accenture pivoted to all virtual events. This was made possible with AWS DeepRacer community races. Accenture quickly set up and customized races with the ability to select, date, time, track, and invite participants.
This fall, Accenture takes their racing to a new level with their 2-month-long finals championship, the Accenture Grand Prix. This event takes advantage of the latest update to community races as of October 1, 2020: the addition of object avoidance and head-to-bot racing formats. In object avoidance races, you use sensors to detect and avoid obstacles placed on the track. In head-to-bot, you race against another AWS DeepRacer bot on the same track and try to avoid it while still turning in the best lap time. You can use visual information to sense and avoid objects being approached on the track.
Amanda Jensen, Associate Director in the Accenture AWS Business Group, is heading up the Accenture Grand Prix. Making sure their employees are trained with the right skills is crucial to their business of helping other organizations unlock the advantages of ML.
“The skills most relevant are a combination of basic cloud skills as well as programming, including languages such as Python and R, statistics and regression, and data science,” Jensen says. “One of the largest obstacles in training for employees staffed on non-AI or ML projects is the opportunity to apply or grow skills in a setting where they can visualize how data science works. Applying algorithms on paper or reading about them isn’t the same.”
That’s where AWS DeepRacer comes in. It’s a great way for teams to get started in ML training, see it come to life, and enable team building. AWS DeepRacer makes the experience of learning fun and accessible.
“One of our team members mentioned that before getting hands-on with DeepRacer, she didn’t have any background in ML,” Jensen says. “The console, models, and training module for AWS DeepRacer made it easy to visualize the steps and understand how the model was being trained in the background without getting too deep into the complicated mathematics. With the added bonus of having the physical car, she was able to actually see in real time the changes, failures, and successes of the model.”
Jensen also sees the added head-to-bot format as a key new feature to elevate the AWS DeepRacer competition experience.
“In our global competition last year, it quickly became apparent that the competition between the locations was really the driving force behind the engagement,” Jensen says. “People wanted their office location to be on the board. This will bring that level of competition to the individual races and get people enthusiastic.”
Starting your own race
Whether or not you have competed in races before, creating and hosting a community race may be what you’re looking for to get you started with AWS DeepRacer and ML. Anyone can start a community race for free and invite participants to join.
With community races, you can select your own track, race date, time, and who you want to invite to participate. Hosting your own race provides an opportunity for you to build your own community and provide team-building events for friends and work colleagues. Community races are another exciting way AWS DeepRacer provides an opportunity for you to compete, meet fellow enthusiasts, and get started with ML!

In this section, we walk you through setting up your own community race. All you need to do is sign up for an AWS account (if you don’t already have one) and go to the AWS DeepRacer console.
- On the AWS DeepRacer console, choose Community races.
- Choose Create a race.
- For Choose race type, select the type of race you want. For this post, we select Time Trial.
- For Name of the racing event, enter a name for your race.
- For Race dates, enter the start and end dates for your race.

In the Race customization section, you can optionally customize your race details with track and evaluation criteria.
- For Competition tracks, select your track. For this post, we select Cumulo Turnpike.
- Customize the remaining race track options as desired.
- Choose Next.

- Review your race settings and choose Submit.
An invitation page and link is generated for you to copy and send out to your friends and colleagues you want to invite to compete in your race.

Now that the race is created, you’re ready to host your own event. Make sure that everyone you invited takes the proper training to build, train, and evaluate their model before the race. When everyone is ready, you’re all set to start racing with your friends!
Who can host an event?
Community races are hosted by all kinds of people and groups, from large companies like Accenture to ML enthusiasts who want to test their skills.
Juv Chan, a community hero for AWS DeepRacer, recently hosted his own event. “I was the main organizer for the AWS DeepRacer Beginner Challenge virtual community race, which started on April 3, 2020, and ended May 31, 2020,” Chan says. “It was the first community race that was organized exclusively for the DeepRacer beginner community globally.”
After Chan decided he wanted to get more beginner-level developers involved in racing and learning ML, he set out to create his own event through the AWS DeepRacer console.
“My first experience on setting up a new community race in the AWS DeepRacer console was easy, fast, and straightforward” Chan says. “I was able to create my first community race in less than 3 minutes when I had all the necessary requirements and details to create the race. I would recommend new users who want to create a new community race to create a mock race in advance to get familiar with all the required details and limitations. It’s possible to edit race details after creating the event too.”
After you set up the race, you need to invite other developers to create an account, train models, and compete in your race. Chan worked with AWS and the AWS ML community to convince racers to join the fun.
“Getting beginner racers to participate was my next challenge,” Chan says. “I worked with AWS and AWS Machine Learning Community Heroes to create a community race event landing page and step-by-step race guide blog post on how to get started and participate the race. I have promoted the events through various AWS, autonomous driving, reinforcement learning, and relevant AI user groups and social media channels in different regions globally. I also created a survey to get feedback from the communities.”
Overall, Chan had a great experience hosting the race. For more information about his experiences and best-kept secrets, see Train a Viable Model in 45 minutes for AWS DeepRacer Beginner Challenge Virtual Community Race 2020.
Join the race to win glory and prizes!
As you can see, there are plenty of ways to compete against your fellow racers right now! If you think you’re ready to create your own community race and invite fellow racers to create a model and compete, it’s easy to get started.
If you’re new to AWS DeepRacer but still want to compete, you can create your own model on the console and submit it compete in the AWS DeepRacer Virtual Circuit, where you can compete in time trial, object avoidance, and head-to-head racing formats. Hundreds of developers have extended their ML journey by competing in the Virtual Circuit races in 2020.
For more information about an AWS DeepRacer competition from earlier in the year, check out the AWS DeepRacer League F1 ProAm event. You can also learn more about AWS DeepRacer in upcoming AWS Summit Online events. Sign in to the AWS DeepRacer console now to learn more, start your ML journey, and get rolling with AWS DeepRacer!
About the Author
 Dan McCorriston is a Senior Product Marketing Manager for AWS Machine Learning. He is passionate about technology, collaborating with developers, and creating new methods of expanding technology education. Out of the office he likes to hike, cook and spend time with his family.
Dan McCorriston is a Senior Product Marketing Manager for AWS Machine Learning. He is passionate about technology, collaborating with developers, and creating new methods of expanding technology education. Out of the office he likes to hike, cook and spend time with his family.
Onboarding Amazon SageMaker Studio with AWS SSO and Okta Universal Directory
In 2019, AWS announced Amazon SageMaker Studio, a unified integrated development environment (IDE) for machine learning (ML) development. You can write code, track experiments, visualize data, and perform debugging and monitoring within a single, integrated visual interface.
Amazon SageMaker Studio supports a single sign-on experience with AWS Single Sign-On (AWS SSO) authentication. External identity provider (IdP) such as Azure Active Directory and Okta Universal Directory can be integrated with AWS SSO to be the source of truth for Amazon SageMaker Studio. Users are given access to Amazon SageMaker Studio via a unique login URL that directly opens Amazon SageMaker Studio, and they can sign-in with their existing corporate credentials. Administrators can continue to manage users and groups in their existing identity systems which can then be synchronized with AWS SSO. For instance, AWS SSO enables administrators to connect their on-premises Active Directory (AD) or their AWS Managed Microsoft AD directory, as well as other Supported Identity Providers. For more information, see The Next Evolution in AWS Single Sign-On and Single Sign-On between Okta Universal Directory and AWS.
In this post, we walk you through setting up SSO with Amazon SageMaker Studio and enabling SSO with Okta Universal Directory. I also demonstrate the SSO experience for system administrators and Amazon SageMaker Studio users.
Prerequisites
To use the same Okta user login for Amazon SageMaker Studio, you need to set up AWS SSO and connect to Okta Universal Directory. The high-level steps are as follows:
- Enable AWS SSO on the AWS Management Console. Create this AWS SSO account in the same AWS Region as Amazon SageMaker Studio.
- Add AWS SSO as an application Okta users can connect to.
- Configure the mutual agreement between AWS SSO and Okta, download IdP metadata in Okta, and configure an external IdP in AWS SSO.
- Enable identity synchronization between Okta and AWS SSO.
For instructions, see Single Sign-On between Okta Universal Directory and AWS.
This setup makes sure that when a new account is added to Okta and connected to the AWS SSO, a corresponding AWS SSO user is created automatically.
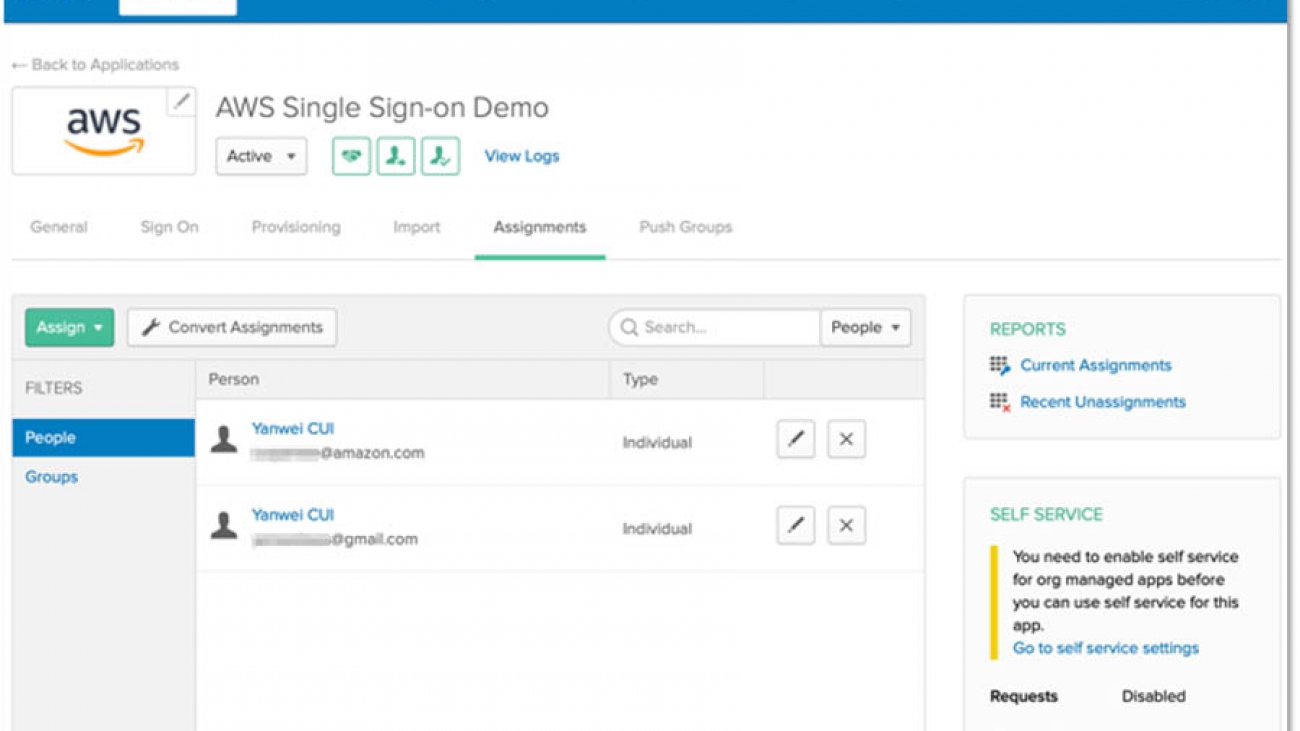
After you complete these steps, you can see the users assigned on the Okta console.

You can also see the users on the AWS SSO console, on the Users page.

Creating Amazon SageMaker Studio with AWS SSO authentication
We now need to create Amazon SageMaker Studio with AWS SSO as the authentication method. Complete the following steps:
- On the Amazon SageMaker console, choose Amazon SageMaker Studio.
- Select Standard setup.
- For Authentication method, select AWS Single Sign-On (SSO).
- For Permission, choose the Amazon SageMaker execution role.
If you don’t have this role already, choose Create role. Amazon SageMaker creates a new AWS Identity and Access Management (IAM) role with the AmazonSageMakerFullAccess policy attached.
- Optionally, you can specify other settings such as notebook sharing configuration, networking and storage, and tags.

- Choose Submit to create Amazon SageMaker Studio.
A few moments after initialization, the Amazon SageMaker Studio Control Panel appears.
- Choose Assign users.

The Assign users page contains a list of all the users from AWS SSO (synchronised from your Okta Universal Directory).
- Select the users that are authorized to access Amazon SageMaker Studio.
- Choose Assign users.

You can now see these users listed on the Amazon SageMaker Studio Control Panel.

On the AWS SSO console, under Applications, you can see the detailed information about the newly created Amazon SageMaker Studio.

In addition, you can view the assigned users.
Amazon SageMaker Studio also automatically creates a user profile with the domain execution role for each SSO user. A user profile represents a single user within a domain, and is the main way to reference a user for the purposes of sharing, reporting, and other user-oriented features such as allowed instance types. You can use the UpdateUserProfile API to associate a different role for a user, allowing fine-grained permission control so the user can pass this associated IAM role when creating a training job, hyperparameter tuning job, or a model. For more information about available Amazon SageMaker SDK API references, see Amazon SageMaker API Reference.
Using Amazon SageMaker Studio via SSO
As a user, you can start in one of three ways:
- Start from the Okta user portal page, select AWS SSO application, and choose Amazon SageMaker Studio
- Start from the AWS SSO user portal (the URL is on the AWS SSO Settings page), redirect to Okta login page, choose Amazon SageMaker Studio
- Bookmark the Amazon SageMaker Studio address (the URL is on the Amazon SageMaker Studio page), the page redirects automatically to Okta login page
For this post, we start in the AWS SSO user portal and are redirected to the Okta login page.

After you log in, you see an application named Amazon SageMaker Studio.

When you choose the application, the Amazon SageMaker Studio welcome page launches.

Now data scientists and ML builders can rely on this web-based IDE and use Amazon SageMaker to quickly and easily build and train ML models, and directly deploy them into a production-ready hosted environment. To learn more about the key features of Amazon SageMaker Studio, see Amazon SageMaker Studio Tour.
Conclusion
In this post, I showed how you can take advantage of the new AWS SSO capabilities to use Okta identities to open Amazon SageMaker Studio. Administrators can now use a single source of truth to manage their users, and users no longer need to manage an additional identity and password to sign in to their AWS accounts and applications.
AWS SSO with Okta is free to use and available in all Regions where AWS SSO is available. Amazon SageMaker Studio is now generally available in US East (Ohio), US East (N. Virginia), US West (Oregon), EU (Ireland) and China (Beijing and Ningxia), with additional Regions coming soon. Please read the product documentation to learn more.
About the Author
 Yanwei Cui, PhD, is a Machine Learning Specialist Solution Architect at AWS. He started machine learning research at IRISA (Research Institute of Computer Science and Random Systems), and has several years of experience building artificial intelligence powered industrial applications in computer vision, natural language processing and online user behavior prediction. At AWS, he shares the domain expertise and helps customers to unlock business potentials, and to drive actionable outcomes with machine learning at scale. Outside of work, he enjoys reading and traveling.
Yanwei Cui, PhD, is a Machine Learning Specialist Solution Architect at AWS. He started machine learning research at IRISA (Research Institute of Computer Science and Random Systems), and has several years of experience building artificial intelligence powered industrial applications in computer vision, natural language processing and online user behavior prediction. At AWS, he shares the domain expertise and helps customers to unlock business potentials, and to drive actionable outcomes with machine learning at scale. Outside of work, he enjoys reading and traveling.
Halloween-themed AWS DeepComposer Chartbusters Challenge: Track or Treat
We are back with a spooktacular AWS DeepComposer Chartbusters challenge, Track or Treat! In this challenge, you can interactively collaborate with the ghost in the machine (learning) and compose spooky music! Chartbusters is a global monthly challenge where you can use AWS DeepComposer to create original compositions on the console using machine learning techniques, compete to top the charts, and win prizes. This challenge launches today and participants can submit their compositions until October 23, 2020.
Participation is easy: you can generate spooky compositions using one of the supported generative AI techniques and models on the AWS DeepComposer console. You can add or remove notes and interactively collaborate with AI using the Edit melody feature, and can include spooky instruments in your composition.
How to compete
To participate in Track or Treat, just do the following:
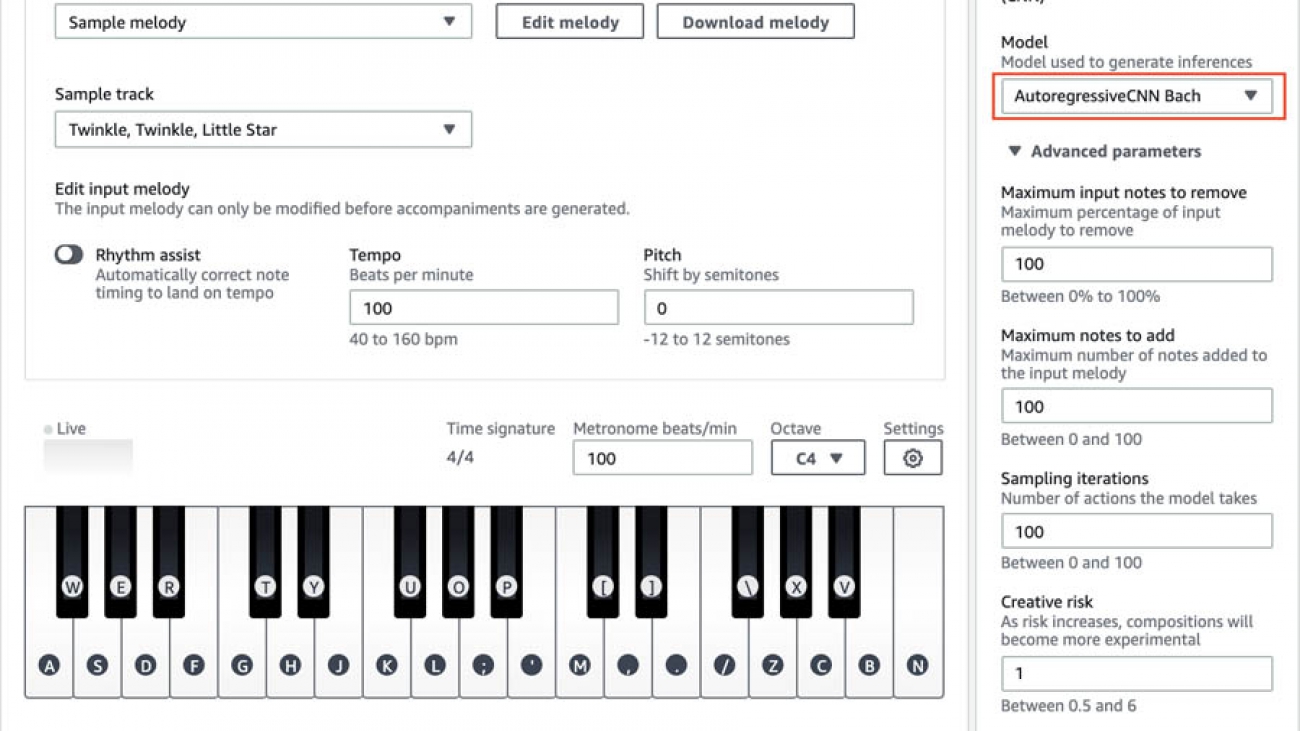
- Go to AWS DeepComposer Music Studio and create a melody with the keyboard, import a melody, or choose a sample melody on the console.
- Under Generative AI technique, for Model parameters, choose Autoregressive.
- For Model, choose Autoregressive CNN Bach.
You have four advanced parameters that you can choose to adjust: Maximum notes to add, Maximum notes to remove, Sampling iterations, and Creative risk.
- After adjusting the values to your liking, choose Enhance input melody.

- Choose Edit melody to add or remove notes.
- You can also change the note duration and pitch.

- When finished, choose Apply changes.

- Repeat these steps until you’re satisfied with the generated music.
- To add accompaniments to your melody, switch the Generative AI technique to Generative Adversarial Networks, then choose Generate composition.
- Choose the right arrow next to an accompaniment track (green bar).
- For Instrument type, choose Spooky.

- When you’re happy with your composition, choose Download composition.
You can choose to post-process your composition; however, one of the judging criteria is how close your final submission is to the track generated using AWS DeepComposer.

- In the navigation pane, choose Chartbusters.
- Choose Submit a composition.
- Select Import a post-processed audio track and upload your composition.
- Provide a track name for your composition and choose Submit.

AWS DeepComposer then submits your composition to the Track or Treat playlist on SoundCloud.
Conclusion
You’ve successfully submitted your composition to the AWS DeepComposer Chartbusters challenge Track or Treat. Now you can invite your friends and family to listen to your creation on SoundCloud, vote for their favorite, and join the fun by participating in the competition.
Although you don’t need a physical keyboard to compete, you can buy the AWS DeepComposer keyboard for $99.00 to enhance your music generation experience. To learn more about the different generative AI techniques supported by AWS DeepComposer, check out the learning capsules available on the AWS DeepComposer console.
About the Author
Maryam Rezapoor is a Senior Product Manager with AWS AI Ecosystem team. As a former biomedical researcher and entrepreneur, she finds her passion in working backward from customers’ needs to create new impactful solutions. Outside of work, she enjoys hiking, photography, and gardening.