Organizations across industries have a lot of unstructured data that you can evaluate to get entity-based insights. You may also want to add your own entity types unique to your business, like proprietary part codes or industry-specific terms. To create a natural language processing (NLP)-based model, you need to label this data based on your specific entities.
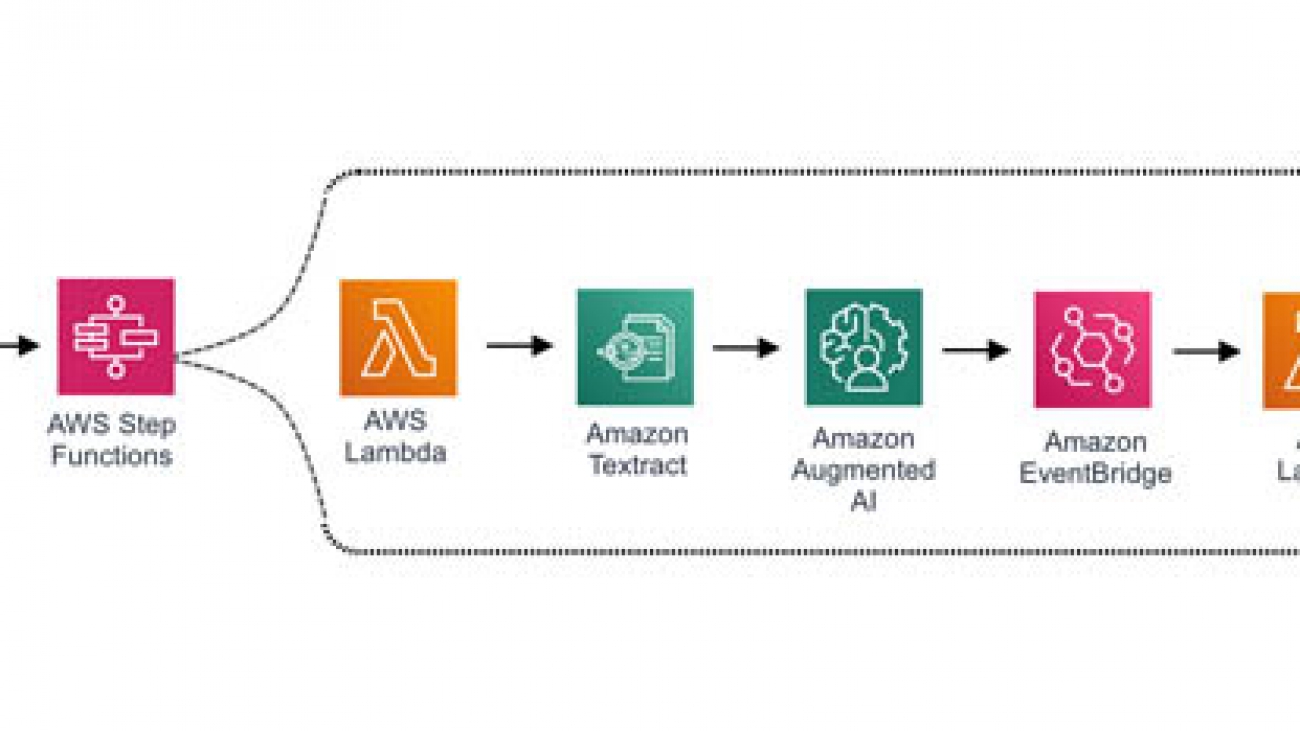
Amazon SageMaker Ground Truth makes it easy to build highly accurate training datasets for machine learning (ML), and Amazon Comprehend lets you train a model without worrying about selecting the right algorithms and parameters for model training. Amazon Augmented AI (Amazon A2I) lets you audit, review, and augment these predicted results.
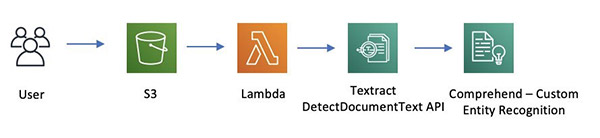
In this post, we cover how to build a labeled dataset of custom entities using the Ground Truth named entity recognition (NER) labeling feature, train a custom entity recognizer using Amazon Comprehend, and review the predictions below a certain confidence threshold from Amazon Comprehend using human reviewers with Amazon A2I.
We walk you through the following steps using this Amazon SageMaker Jupyter notebook:
- Preprocess your input documents.
- Create a Ground Truth NER labeling Job.
- Train an Amazon Comprehend custom entity recognizer model.
- Set up a human review loop for low-confidence detection using Amazon A2I.
Prerequisites
Before you get started, complete the following steps to set up the Jupyter notebook:
- Create a notebook instance in Amazon SageMaker.
Make sure your Amazon SageMaker notebook has the necessary AWS Identity and Access Management (IAM) roles and permissions mentioned in the prerequisite section of the notebook.
- When the notebook is active, choose Open Jupyter.
- On the Jupyter dashboard, choose New, and choose Terminal.
- In the terminal, enter the following code:
cd SageMaker
git clone “https://github.com/aws-samples/augmentedai-comprehendner-groundtruth”
- Open the notebook by choosing SageMakerGT-ComprehendNER-A2I-Notebook.ipynb in the root folder.
You’re now ready to run the following steps through the notebook cells.
Preprocessing your input documents
For this use case, you’re reviewing at chat messages or several service tickets. You want to know if they’re related to an AWS offering. We use the NER labeling feature in Ground Truth to label a SERVICE or VERSION entity from the input messages. We then train an Amazon Comprehend custom entity recognizer to recognize the entities from text like tweets or ticket comments.
The sample dataset is provided at data/rawinput/aws-service-offerings.txt in the GitHub repo. The following screenshot shows an example of the content.

You preprocess this file to generate the following:
- inputs.csv – You use this file to generate input manifest file for Ground Truth NER labeling.
- Train.csv and test.csv – You use these files as input for training custom entities. You can find these files in the Amazon Simple Storage Service (Amazon S3) bucket.
Refer to Steps 1a and 1b in the notebook for dataset generation.
Creating a Ground Truth NER labeling job
The purpose is to annotate and label sentences within the input document as belonging to a custom entity that we define. In this section, you complete the following steps:
- Create the manifest file that Ground Truth needs.
- Set up a labeling workforce.
- Create your labeling job.
- Start your labeling job and verify its output.
Creating a manifest file
We use the inputs.csv file generated during prepossessing to create a manifest file that the NER labeling feature needs. We generate a manifest file named prefix+-text-input.manifest, which you use for data labeling while creating a Ground Truth job. See the following code:
# Create and upload the input manifest by appending a source tag to each of the lines in the input text file.
# Ground Truth uses the manifest file to determine labeling tasks
manifest_name = prefix + '-text-input.manifest'
# remove existing file with the same name to avoid duplicate entries
!rm *.manifest
s3bucket = s3res.Bucket(BUCKET)
with open(manifest_name, 'w') as f:
for fn in s3bucket.objects.filter(Prefix=prefix +'/input/'):
fn_obj = s3res.Object(BUCKET, fn.key)
for line in fn_obj.get()['Body'].read().splitlines():
f.write('{"source":"' + line.decode('utf-8') +'"}n')
f.close()
s3.upload_file(manifest_name, BUCKET, prefix + "/manifest/" + manifest_name)
The NER labeling job requires its input manifest in the {"source": "embedded text"}. The following screenshot shows the generated input.manifest file from inputs.csv.

Creating a private labeling workforce
With Ground Truth, we use a private workforce to create a labeled dataset.
You create your private workforce on the Amazon SageMaker console. For instructions, see the section Creating a private work team in Developing NER models with Amazon SageMaker Ground Truth and Amazon Comprehend.
Alternatively, follow the steps in the notebook.
For this walkthrough, we use the same private workforce to label and augment low-confidence data using Amazon A2I after custom entity training.
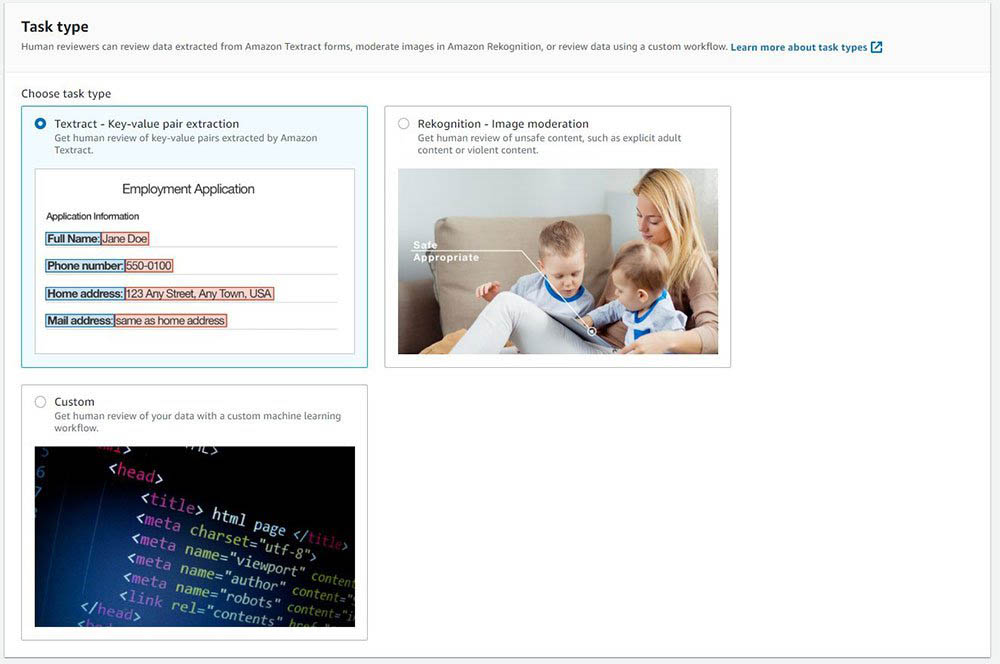
Creating a labeling job
The next step is to create the NER labeling job. This post highlights the key steps. For more information, see Adding a data labeling workflow for named entity recognition with Amazon SageMaker Ground Truth.
- On the Amazon SageMaker console, under Ground Truth, choose Labeling jobs.
- Choose Create labeling job.
- For Job name, enter a job name.
- For Input dataset location, enter the Amazon S3 location of the input manifest file you created (
s3://bucket//path-to-your-manifest.json).
- For Output Dataset Location, enter a S3 bucket with an output prefix (for example,
s3://bucket-name/output).
- For IAM role, choose Create a new Role.
- Select Any S3 Bucket.
- Choose Create.
- For Task category, choose Text.
- Select Named entity recognition.

- Choose Next.
- For Worker type, select Private.
- In Private Teams, select the team you created.
- In the Named Entity Recognition Labeling Tool section, for Enter a brief description of the task, enter
Highlight the word or group of words and select the corresponding most appropriate label from the right.
- In the Instructions box, enter
Your labeling will be used to train an ML model for predictions. Please think carefully on the most appropriate label for the word selection. Remember to label at least 200 annotations per label type.
- Choose Bold Italics.
- In the Labels section, enter the label names you want to display to your workforce.
- Choose Create.
Starting your labeling job
Your workforce (or you, if you chose yourself as your workforce) received an email with login instructions.
- Choose the URL provided and enter your user name and password.
You are directed to the labeling task UI.
- Complete the labeling task by choosing labels for groups of words.
- Choose Submit.

- After you label all the entries, the UI automatically exits.
- To check your job’s status, on the Amazon SageMaker console, under Ground Truth, choose Labeling jobs.
- Wait until the job status shows as
Complete.

Verifying annotation outputs
To verify your annotation outputs, open your S3 bucket and locate <S3 Bucket Name>/output/<labeling-job-name>/manifests/output/output.manifest. You can review the manifest file that Ground Truth created. The following screenshot shows an example of the entries you see.

Training a custom entity model
We now use the annotated dataset or output.manifest Ground Truth created to train a custom entity recognizer. This section walks you through the steps in the notebook.
Processing the annotated dataset
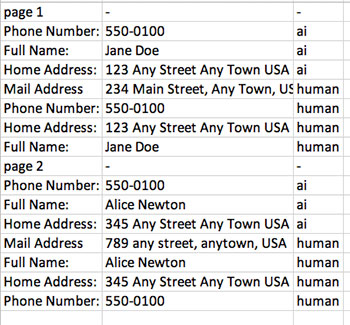
You can provide labels for Amazon Comprehend custom entities through an entity list or annotations. In this post, we use annotations generated using Ground Truth labeling jobs. You need to convert the annotated output.manifest file to the following CSV format:
File, Line, Begin Offset, End Offset, Type
documents.txt, 0, 0, 11, VERSION
Run the following code in the notebook to generate the annotations.csv file:
# Read the output manifest json and convert into a csv format as expected by Amazon Comprehend Custom Entity Recognizer
import json
import csv
# this will be the file that will be written by the format conversion code block below
csvout = 'annotations.csv'
with open(csvout, 'w', encoding="utf-8") as nf:
csv_writer = csv.writer(nf)
csv_writer.writerow(["File", "Line", "Begin Offset", "End Offset", "Type"])
with open("data/groundtruth/output.manifest", "r") as fr:
for num, line in enumerate(fr.readlines()):
lj = json.loads(line)
#print(str(lj))
if lj and labeling_job_name in lj:
for ent in lj[labeling_job_name]['annotations']['entities']:
csv_writer.writerow([fntrain,num,ent['startOffset'],ent['endOffset'],ent['label'].upper()])
fr.close()
nf.close()
s3_annot_key = "output/" + labeling_job_name + "/comprehend/" + csvout
upload_to_s3(s3_annot_key, csvout)
The following screenshot shows the contents of the file.

Setting up a custom entity recognizer
This post uses the API, but you can optionally create the recognizer and batch analysis job on the Amazon Comprehend console. For instructions, see Build a custom entity recognizer using Amazon Comprehend.
- Enter the following code. For
s3_train_channel, use the train.csv file you generated in preprocessing step for training the recognizer. For s3_annot_channel, use annotations.csv as a label to train your custom entity recognizer.
custom_entity_request = {
"Documents": {
"S3Uri": s3_train_channel
},
"Annotations": {
"S3Uri": s3_annot_channel
},
"EntityTypes": [
{
"Type": "SERVICE"
},
{
"Type": "VERSION"
}
]
}
- Create the entity recognizer using CreateEntityRecognizer The entity recognizer is trained with the minimum required number of training samples to generate some low confidence predictions required for our Amazon A2I workflow. See the following code:
import datetime
id = str(datetime.datetime.now().strftime("%s"))
create_custom_entity_response = comprehend.create_entity_recognizer(
RecognizerName = prefix + "-CER",
DataAccessRoleArn = role,
InputDataConfig = custom_entity_request,
LanguageCode = "en"
)
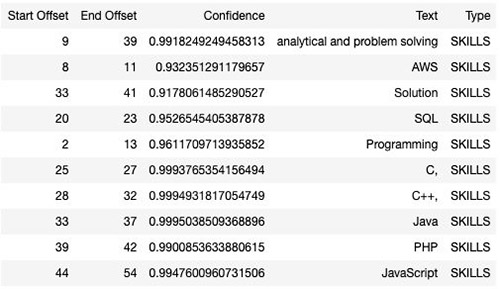
When the entity recognizer job is complete, it creates a recognizer with a performance score. As mentioned earlier we trained the entity recognizer with a minimum number of training samples to generate low confidence predictions we need to trigger the Amazon A2I human loop. You can find these metrics on the Amazon Comprehend console. See the following screenshot.

- Create a batch entity detection analysis job to detect entities over a large number of documents.
Use the Amazon Comprehend StartEntitiesDetectionJob operation to detect custom entities in your documents. For instructions on creating an endpoint for real-time analysis using your custom entity recognizer, see Announcing the launch of Amazon Comprehend custom entity recognition real-time endpoints.
To use the EntityRecognizerArn for custom entity recognition, you must provide access to the recognizer to detect the custom entity. This ARN is supplied by the response to the CreateEntityRecognizer operation.
- Run the custom entity detection job to get predictions on the test dataset you created during the preprocessing step by running the following cell in the notebook:
s3_test_channel = 's3://{}/{}'.format(BUCKET, s3_test_key) s3_output_test_data = 's3://{}/{}'.format(BUCKET, "output/testresults/")
test_response = comprehend.start_entities_detection_job( InputDataConfig={
'S3Uri': s3_test_channel,
'InputFormat': 'ONE_DOC_PER_LINE'
},
OutputDataConfig={'S3Uri': s3_output_test_data
},
DataAccessRoleArn=role,
JobName='a2i-comprehend-gt-blog',
EntityRecognizerArn=jobArn,
LanguageCode='en')
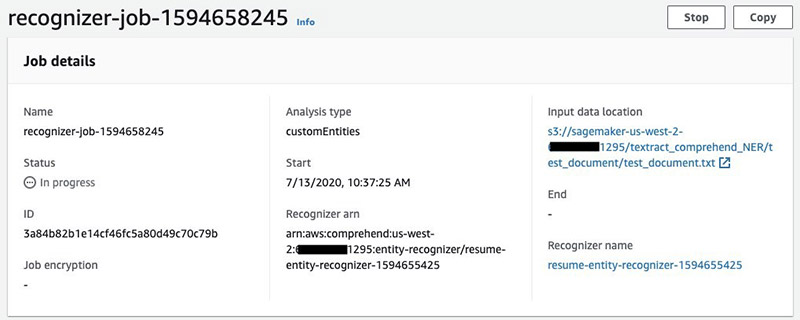
The following screenshot shows the test results.

Setting up a human review loop
In this section, you set up a human review loop for low-confidence detections in Amazon A2I. It includes the following steps:
- Choose your workforce.
- Create a human task UI.
- Create a worker task template creator function.
- Create the flow definition.
- Check the human loop status and wait for reviewers to complete the task.
Choosing your workforce
For this post, we use the private workforce we created for the Ground Truth labeling jobs. Use the workforce ARN to set up the workforce for Amazon A2I.
Creating a human task UI
Create a human task UI resource with a UI template in liquid HTML. This template is used whenever a human loop is required.
The following example code is compatible with Amazon Comprehend entity detection:
template = """
<script src="https://assets.crowd.aws/crowd-html-elements.js"></script>
<style>
.highlight {
background-color: yellow;
}
</style>
<crowd-entity-annotation
name="crowd-entity-annotation"
header="Highlight parts of the text below"
labels="[{'label': 'service', 'fullDisplayName': 'Service'}, {'label': 'version', 'fullDisplayName': 'Version'}]"
text="{{ task.input.originalText }}"
>
<full-instructions header="Named entity recognition instructions">
<ol>
<li><strong>Read</strong> the text carefully.</li>
<li><strong>Highlight</strong> words, phrases, or sections of the text.</li>
<li><strong>Choose</strong> the label that best matches what you have highlighted.</li>
<li>To <strong>change</strong> a label, choose highlighted text and select a new label.</li>
<li>To <strong>remove</strong> a label from highlighted text, choose the X next to the abbreviated label name on the highlighted text.</li>
<li>You can select all of a previously highlighted text, but not a portion of it.</li>
</ol>
</full-instructions>
<short-instructions>
Select the word or words in the displayed text corresponding to the entity, label it and click submit
</short-instructions>
<div id="recognizedEntities" style="margin-top: 20px">
<h3>Label the Entity below in the text above</h3>
<p>{{ task.input.entities }}</p>
</div>
</crowd-entity-annotation>
<script>
function highlight(text) {
var inputText = document.getElementById("inputText");
var innerHTML = inputText.innerHTML;
var index = innerHTML.indexOf(text);
if (index >= 0) {
innerHTML = innerHTML.substring(0,index) + "<span class='highlight'>" + innerHTML.substring(index,index+text.length) + "</span>" + innerHTML.substring(index + text.length);
inputText.innerHTML = innerHTML;
}
}
document.addEventListener('all-crowd-elements-ready', () => {
document
.querySelector('crowd-entity-annotation')
.shadowRoot
.querySelector('crowd-form')
.form
.appendChild(recognizedEntities);
});
</script>
"""
Creating a worker task template creator function
This function is a higher-level abstraction on the Amazon SageMaker package’s method to create the worker task template, which we use to create a human review workflow. See the following code:
def create_task_ui():
'''
Creates a Human Task UI resource.
Returns:
struct: HumanTaskUiArn
'''
response = sagemaker.create_human_task_ui(
HumanTaskUiName=taskUIName,
UiTemplate={'Content': template})
return response
# Task UI name - this value is unique per account and region. You can also provide your own value here.
taskUIName = prefix + '-ui'
# Create task UI
humanTaskUiResponse = create_task_ui()
humanTaskUiArn = humanTaskUiResponse['HumanTaskUiArn']
print(humanTaskUiArn)
Creating the flow definition
Flow definitions allow you to specify the following:
- The workforce that your tasks are sent to
- The instructions that your workforce receives
This post uses the API, but you can optionally create this workflow definition on the Amazon A2I console.
For more information, see Create a Flow Definition.
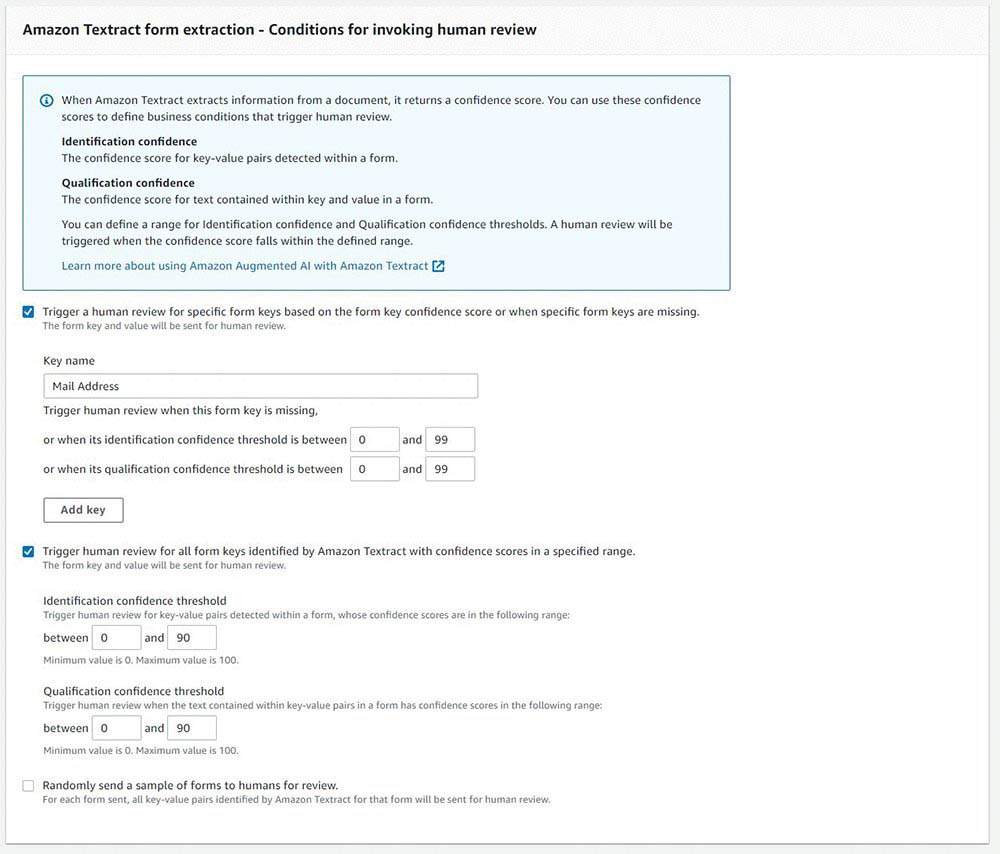
To set up the condition to trigger the human loop review, enter the following code (you can change the value of the CONFIDENCE_SCORE_THRESHOLD based on what confidence level you want to trigger the human review):
human_loops_started = []
import json
CONFIDENCE_SCORE_THRESHOLD = 90
for line in data:
print("Line is: " + str(line))
begin_offset=line['BEGIN_OFFSET']
end_offset=line['END_OFFSET']
if(line['CONFIDENCE_SCORE'] < CONFIDENCE_SCORE_THRESHOLD):
humanLoopName = str(uuid.uuid4())
human_loop_input = {}
human_loop_input['labels'] = line['ENTITY']
human_loop_input['entities']= line['ENTITY']
human_loop_input['originalText'] = line['ORIGINAL_TEXT']
start_loop_response = a2i_runtime_client.start_human_loop(
HumanLoopName=humanLoopName,
FlowDefinitionArn=flowDefinitionArn,
HumanLoopInput={
"InputContent": json.dumps(human_loop_input)
}
)
print(human_loop_input)
human_loops_started.append(humanLoopName)
print(f'Score is less than the threshold of {CONFIDENCE_SCORE_THRESHOLD}')
print(f'Starting human loop with name: {humanLoopName} n')
else:
print('No human loop created. n')
Checking the human loop status and waiting for reviewers to complete the task
To define a function that allows you to check the human loop’s status, enter the following code:
completed_human_loops = []
for human_loop_name in human_loops_started:
resp = a2i_runtime_client.describe_human_loop(HumanLoopName=human_loop_name)
print(f'HumanLoop Name: {human_loop_name}')
print(f'HumanLoop Status: {resp["HumanLoopStatus"]}')
print(f'HumanLoop Output Destination: {resp["HumanLoopOutput"]}')
print('n')
if resp["HumanLoopStatus"] == "Completed":
completed_human_loops.append(resp)
Navigate to the private workforce portal that’s provided as the output of cell 2 from the previous step in the notebook. See the following code:
workteamName = WORKTEAM_ARN[WORKTEAM_ARN.rfind('/') + 1:]
print("Navigate to the private worker portal and do the tasks. Make sure you've invited yourself to your workteam!")
print('https://' + sagemaker.describe_workteam(WorkteamName=workteamName)['Workteam']['SubDomain'])
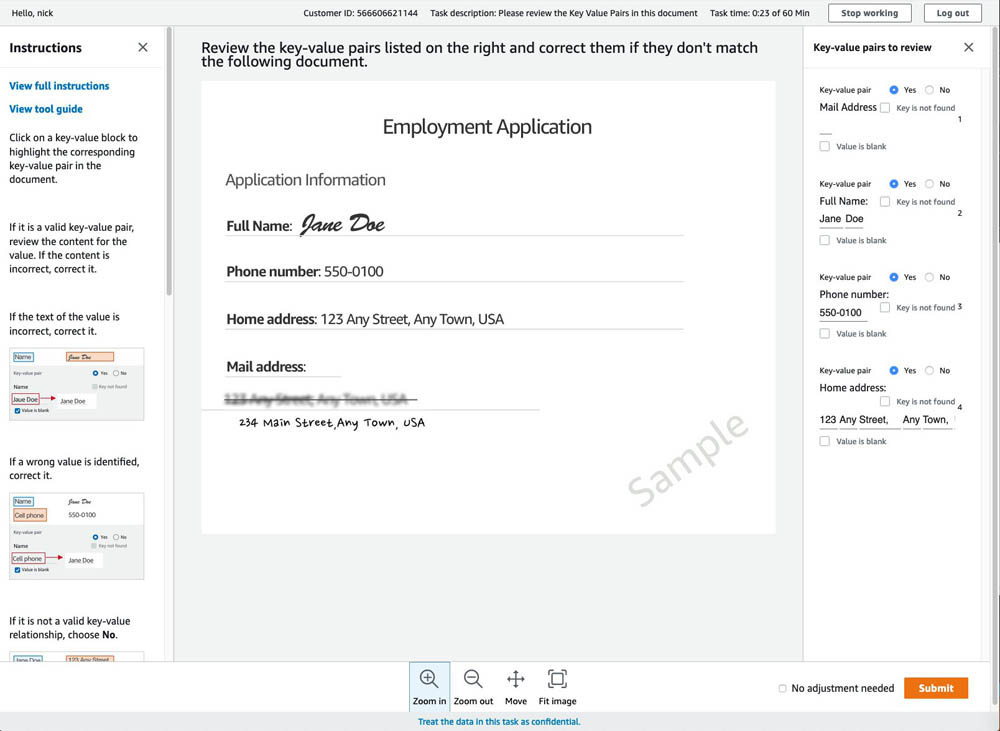
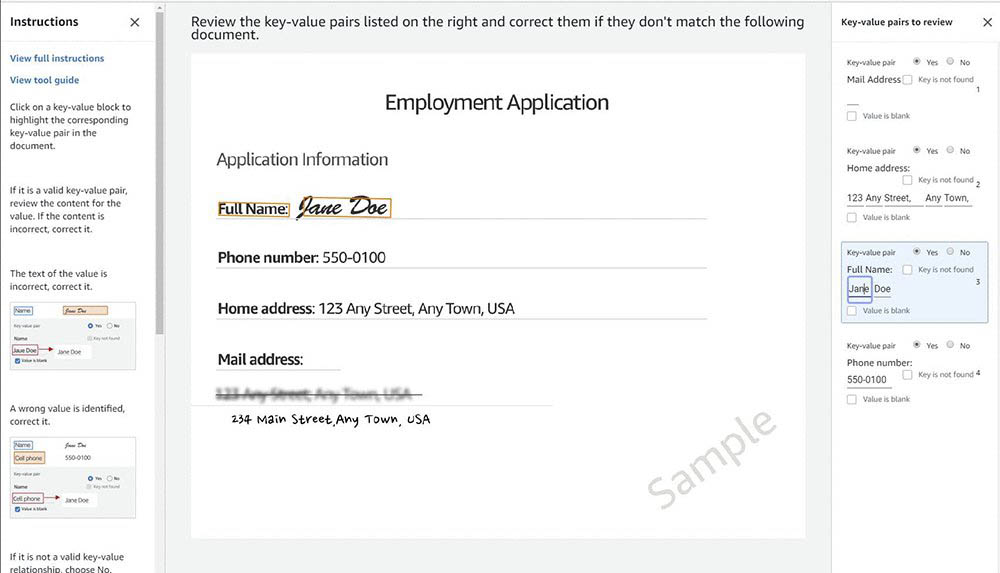
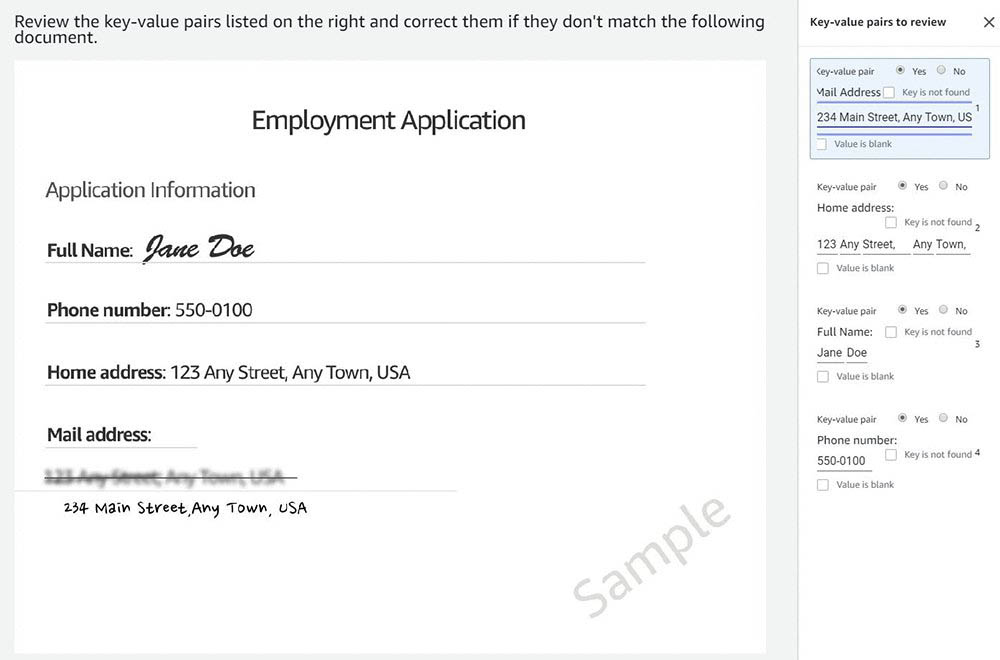
The UI template is similar to the Ground Truth NER labeling feature. Amazon A2I displays the entity identified from the input text (this is a low-confidence prediction). The human worker can then update or validate the entity labeling as required and choose Submit.

This action generates an updated annotation with offsets and entities as highlighted by the human reviewer.
Cleaning up
To avoid incurring future charges, stop and delete resources such as the Amazon SageMaker notebook instance, Amazon Comprehend custom entity recognizer, and the model artifacts in Amazon S3 when not in use.
Conclusion
This post demonstrated how to create annotations for an Amazon Comprehend custom entity recognition using Ground Truth NER. We used Amazon A2I to augment the low-confidence predictions from Amazon Comprehend.
You can use the annotations that Amazon A2I generated to update the annotations file you created and incrementally train the custom recognizer to improve the model’s accuracy.
For video presentations, sample Jupyter notebooks, or more information about use cases like document processing, content moderation, sentiment analysis, text translation, and more, see Amazon Augmented AI Resources. We’re interested in how you want to extend this solution for your use case and welcome your feedback.
About the Authors
 Mona Mona is an AI/ML Specialist Solutions Architect based out of Arlington, VA. She works with World Wide Public Sector team and helps customers adopt machine learning on a large scale. She is passionate about NLP and ML Explainability areas in AI/ML.
Mona Mona is an AI/ML Specialist Solutions Architect based out of Arlington, VA. She works with World Wide Public Sector team and helps customers adopt machine learning on a large scale. She is passionate about NLP and ML Explainability areas in AI/ML.
 Prem Ranga is an Enterprise Solutions Architect based out of Houston, Texas. He is part of the Machine Learning Technical Field Community and loves working with customers on their ML and AI journey. Prem is passionate about robotics, is an Autonomous Vehicles researcher, and also built the Alexa-controlled Beer Pours in Houston and other locations.
Prem Ranga is an Enterprise Solutions Architect based out of Houston, Texas. He is part of the Machine Learning Technical Field Community and loves working with customers on their ML and AI journey. Prem is passionate about robotics, is an Autonomous Vehicles researcher, and also built the Alexa-controlled Beer Pours in Houston and other locations.
Read More

 Olivier Cruchant is a Machine Learning Specialist Solution Architect at AWS, based in Lyon, France. Olivier helps French customers – from small startups to large enterprises – develop and deploy production-grade machine learning applications. In his spare time, he enjoys reading research papers and exploring the wilderness with friends and family.
Olivier Cruchant is a Machine Learning Specialist Solution Architect at AWS, based in Lyon, France. Olivier helps French customers – from small startups to large enterprises – develop and deploy production-grade machine learning applications. In his spare time, he enjoys reading research papers and exploring the wilderness with friends and family. Samuel Descroix is head manager of the Geographic and Analytic Data department at SNCF Réseau. He is in charge of all project teams and infrastructures. To be able to answer to all new use cases, he is constantly looking for most innovative and most relevant solutions to manage growing volumes and needs of complex analysis.
Samuel Descroix is head manager of the Geographic and Analytic Data department at SNCF Réseau. He is in charge of all project teams and infrastructures. To be able to answer to all new use cases, he is constantly looking for most innovative and most relevant solutions to manage growing volumes and needs of complex analysis. Alain Rivero is Project Manager in the Technology and Digital Transformation (TTD) department within the General Industrial and Engineering Department of SNCF Réseau. He manages projects implementing in-depth learning solutions to detect defects on rolling stock and tracks to increase traffic safety and guide decision-making within maintenance teams. His research focuses on image processing methods, supervised and unsupervised learning and their applications.
Alain Rivero is Project Manager in the Technology and Digital Transformation (TTD) department within the General Industrial and Engineering Department of SNCF Réseau. He manages projects implementing in-depth learning solutions to detect defects on rolling stock and tracks to increase traffic safety and guide decision-making within maintenance teams. His research focuses on image processing methods, supervised and unsupervised learning and their applications. Pierre-Yves Bonnefoy is data architect at Olexya, currently working for SNCF Réseau IT department. One of his main assignments is to provide environments and sets of datas for Data Scientists and Data Analysts to work on complex analysis, and to help them with software solutions. Thanks to his large range of skills in development and system architecture, he accelerated the deployment of the project on Sagemaker instances, rationalization of costs and optimization of performance.
Pierre-Yves Bonnefoy is data architect at Olexya, currently working for SNCF Réseau IT department. One of his main assignments is to provide environments and sets of datas for Data Scientists and Data Analysts to work on complex analysis, and to help them with software solutions. Thanks to his large range of skills in development and system architecture, he accelerated the deployment of the project on Sagemaker instances, rationalization of costs and optimization of performance. Emeric Chaize is certified Solution Architect in Olexya, currently working for SNCF Réseau IT department. He is in charge of Data Migration Project for IT Data Departement, with the responsabilty of covering all needs and usages of the company in data analysis. He defines and plans deployment of all the needed infrastructure for projects and Data Scientists.
Emeric Chaize is certified Solution Architect in Olexya, currently working for SNCF Réseau IT department. He is in charge of Data Migration Project for IT Data Departement, with the responsabilty of covering all needs and usages of the company in data analysis. He defines and plans deployment of all the needed infrastructure for projects and Data Scientists.















 As a Solutions Architect at AWS supporting our Public Sector customers, Raj excites customers by showing them the art of the possible of what they can build on AWS and helps accelerate their innovation. Raj loves solving puzzles, mentoring, and supporting hackathons and seeing amazing ideas come to life.
As a Solutions Architect at AWS supporting our Public Sector customers, Raj excites customers by showing them the art of the possible of what they can build on AWS and helps accelerate their innovation. Raj loves solving puzzles, mentoring, and supporting hackathons and seeing amazing ideas come to life.



















 Nicholas Nelson is an AWS Solutions Architect for Strategic Accounts based out of Seattle, Washington. His interests and experience include Computer Vision, Serverless Technology, and Construction Technology. Outside of work, you can find Nicholas out cycling, paddle boarding, or grilling!
Nicholas Nelson is an AWS Solutions Architect for Strategic Accounts based out of Seattle, Washington. His interests and experience include Computer Vision, Serverless Technology, and Construction Technology. Outside of work, you can find Nicholas out cycling, paddle boarding, or grilling! Kashif Imran is a Principal Solutions Architect at Amazon Web Services. He works with some of the largest AWS customers who are taking advantage of AI/ML to solve complex business problems. He provides technical guidance and design advice to implement computer vision applications at scale. His expertise spans application architecture, serverless, containers, NoSQL and machine learning.
Kashif Imran is a Principal Solutions Architect at Amazon Web Services. He works with some of the largest AWS customers who are taking advantage of AI/ML to solve complex business problems. He provides technical guidance and design advice to implement computer vision applications at scale. His expertise spans application architecture, serverless, containers, NoSQL and machine learning. Anuj Gupta is Senior Product Manager for Amazon Augmented AI. He focuses on delivering products that make it easier for customers to adopt machine learning. In his spare time, he enjoys road trips and watching Formula 1.
Anuj Gupta is Senior Product Manager for Amazon Augmented AI. He focuses on delivering products that make it easier for customers to adopt machine learning. In his spare time, he enjoys road trips and watching Formula 1.








 Yuan Jiang is a Solution Architect with a focus on machine learning. He is a member of the Amazon Computer Vision Hero program.
Yuan Jiang is a Solution Architect with a focus on machine learning. He is a member of the Amazon Computer Vision Hero program. Sonali Sahu is a Solution Architect and a member of Amazon Machine Learning Technical Field Community. She is also a member of the Amazon Computer Vision Hero program.
Sonali Sahu is a Solution Architect and a member of Amazon Machine Learning Technical Field Community. She is also a member of the Amazon Computer Vision Hero program.