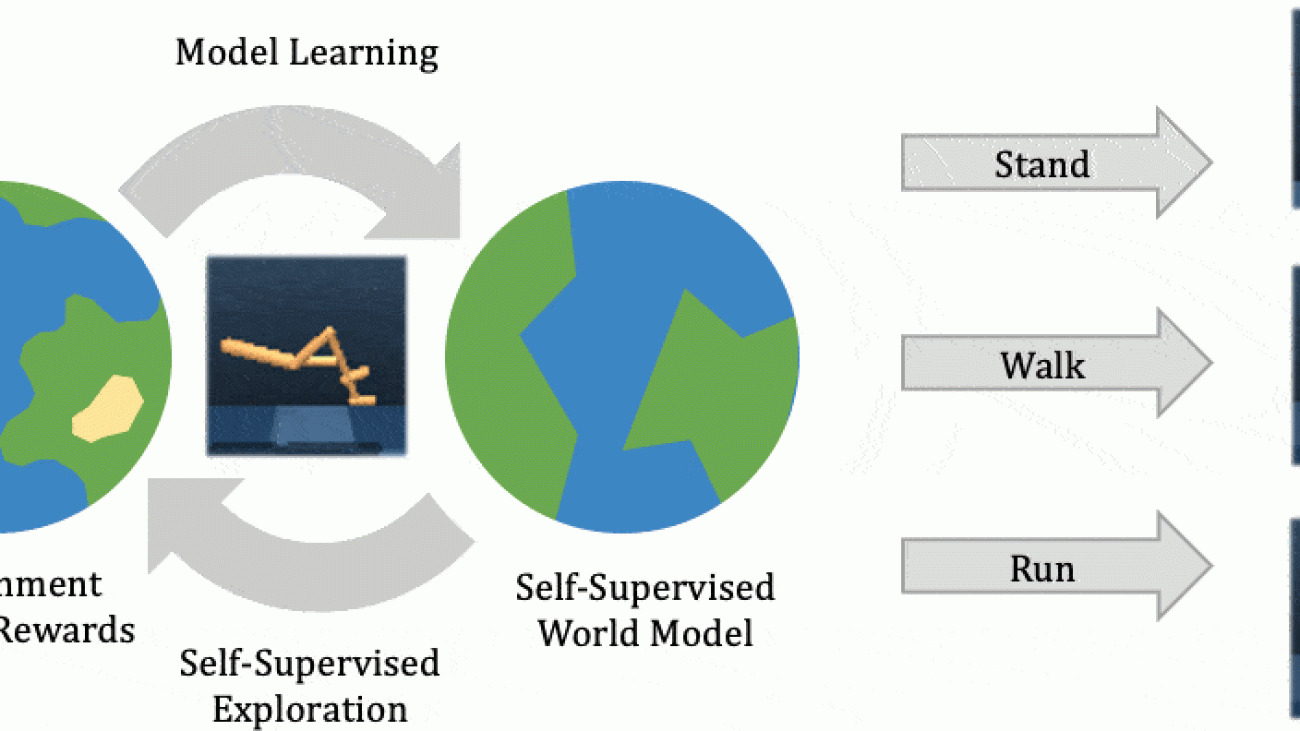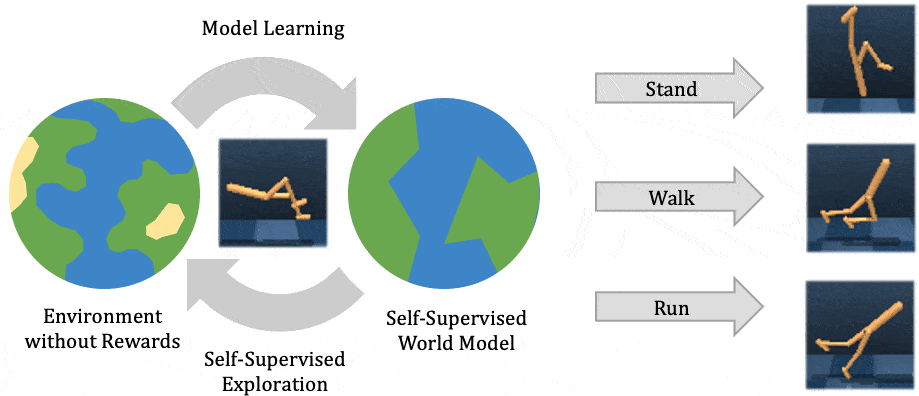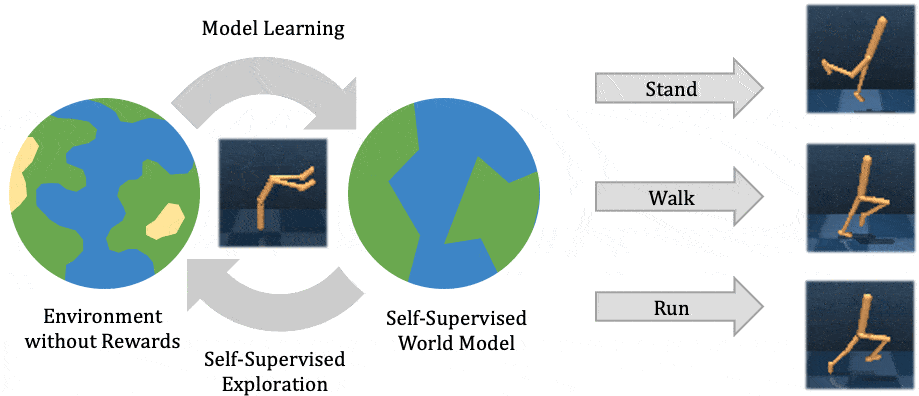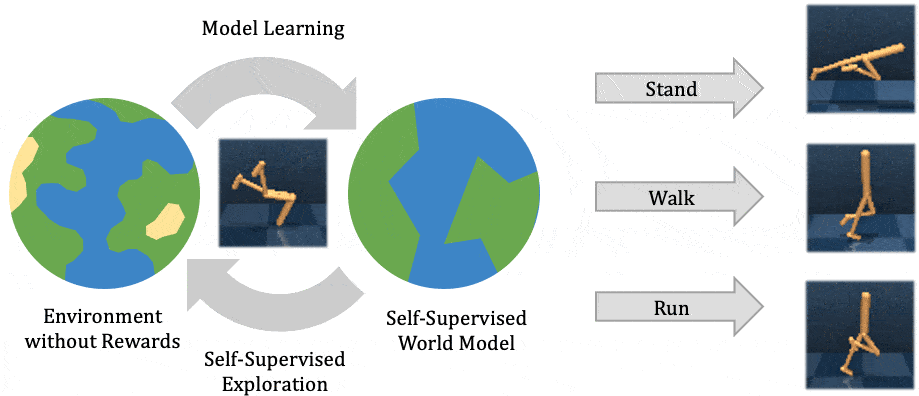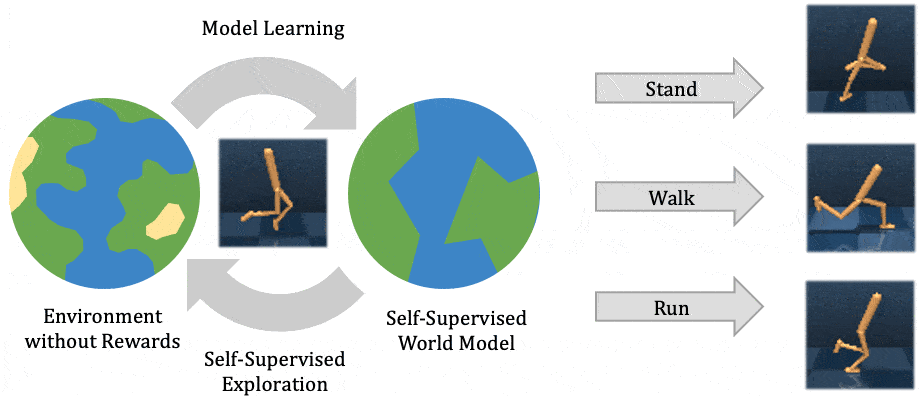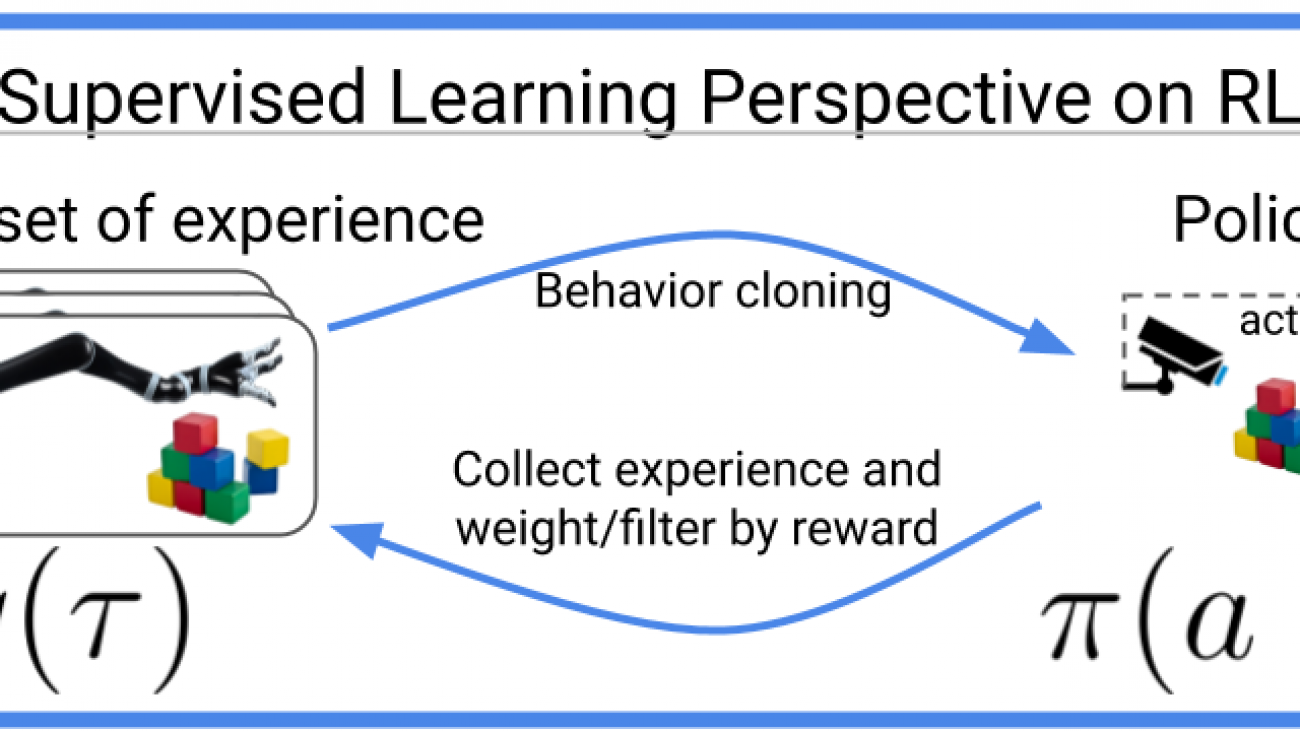
The two most common perspectives on Reinforcement learning (RL) are optimization and dynamic programming. Methods that compute the gradients of the non-differentiable expected reward objective, such as the REINFORCE trick are commonly grouped into the optimization perspective, whereas methods that employ TD-learning or Q-learning are dynamic programming methods. While these methods have shown considerable success in recent years, these methods are still quite challenging to apply to new problems. In contrast deep supervised learning has been extremely successful and we may hence ask: Can we use supervised learning to perform RL?
In this blog post we discuss a mental model for RL, based on the idea that RL can be viewed as doing supervised learning on the “good data”. What makes RL challenging is that, unless you’re doing imitation learning, actually acquiring that “good data” is quite challenging. Therefore, RL might be viewed as a joint optimization problem over both the policy and the data. Seen from this supervised learning perspective, many RL algorithms can be viewed as alternating between finding good data and doing supervised learning on that data. It turns out that finding “good data” is much easier in the multi-task setting, or settings that can be converted to a different problem for which obtaining “good data” is easy. In fact, we will discuss how techniques such as hindsight relabeling and inverse RL can be viewed as optimizing data.