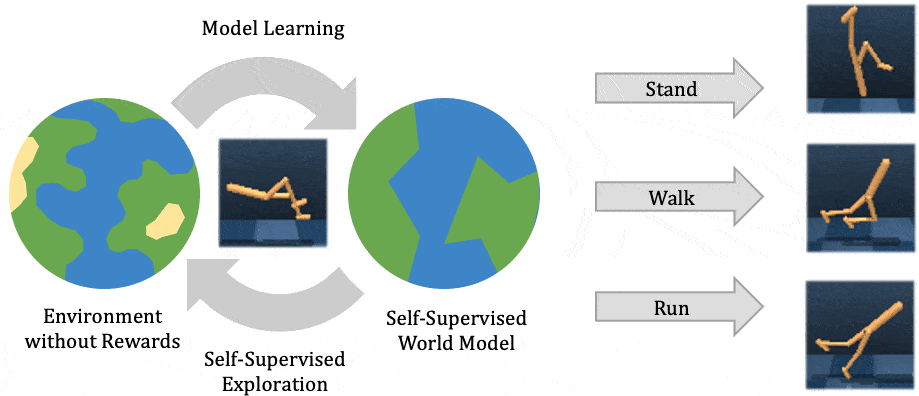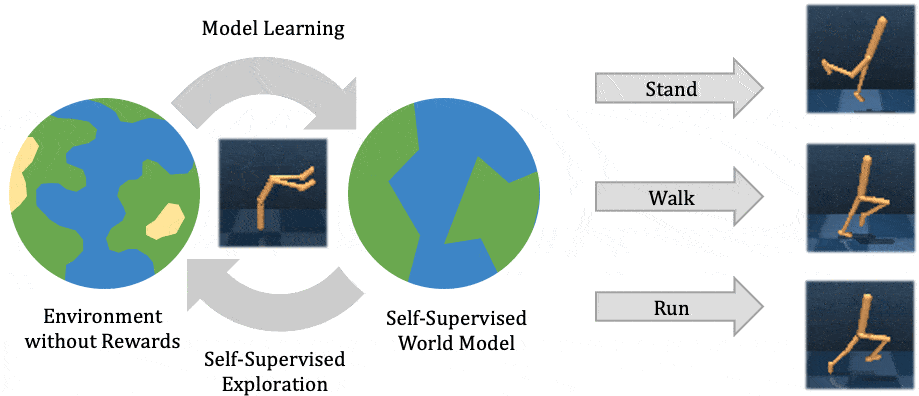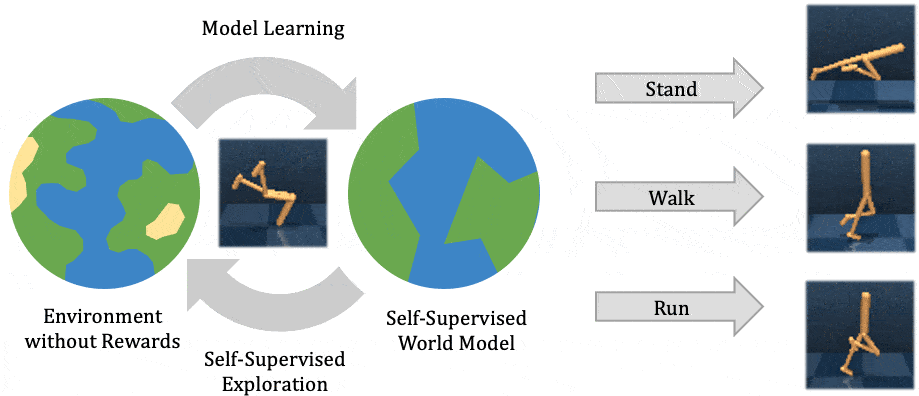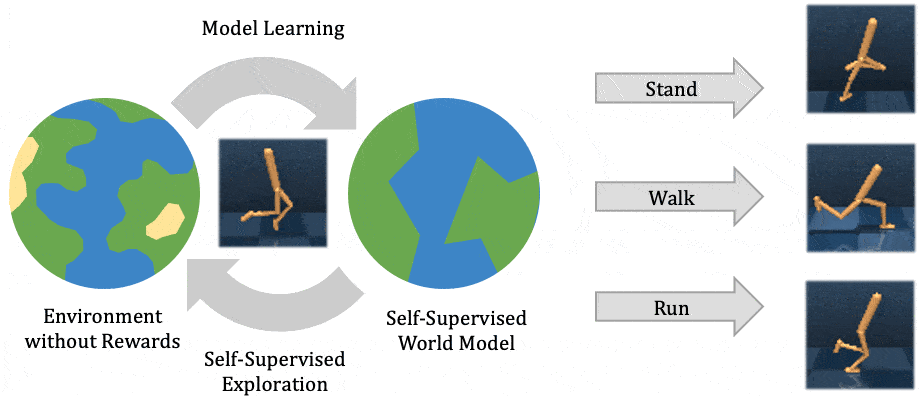
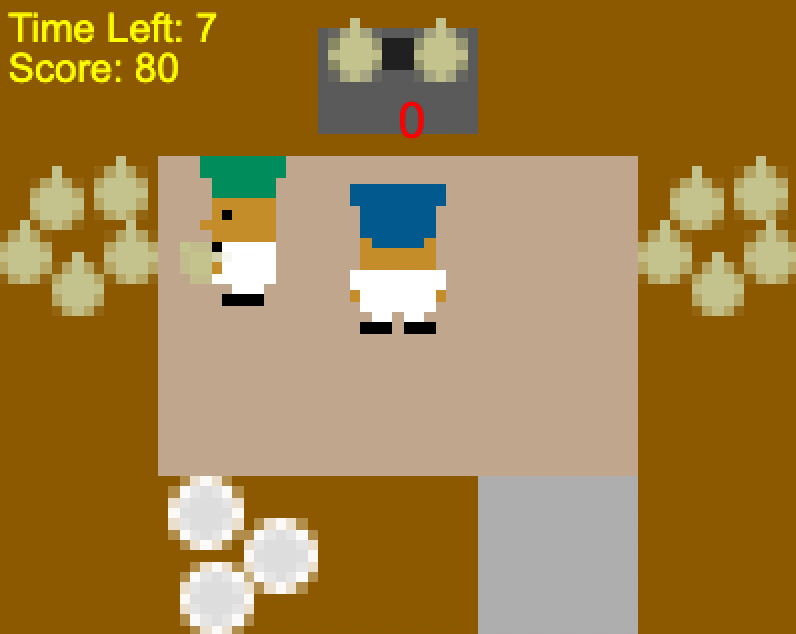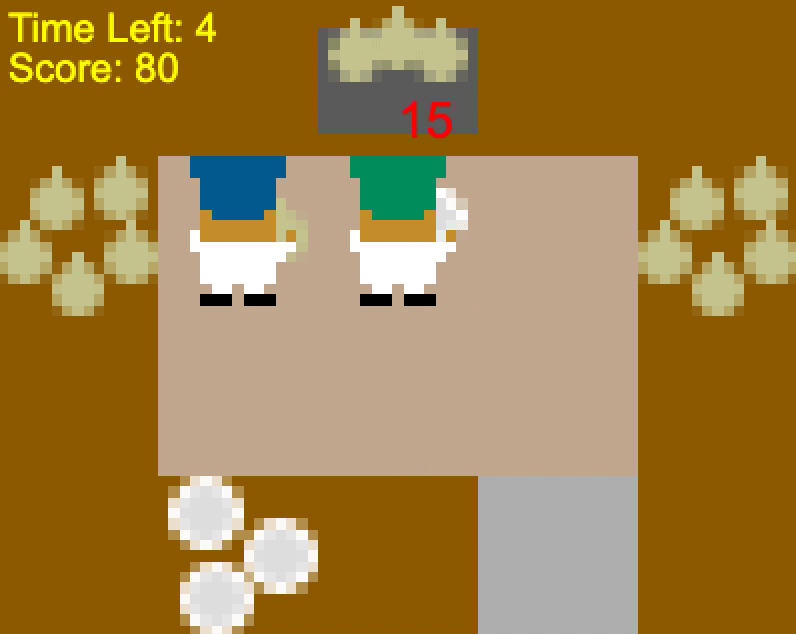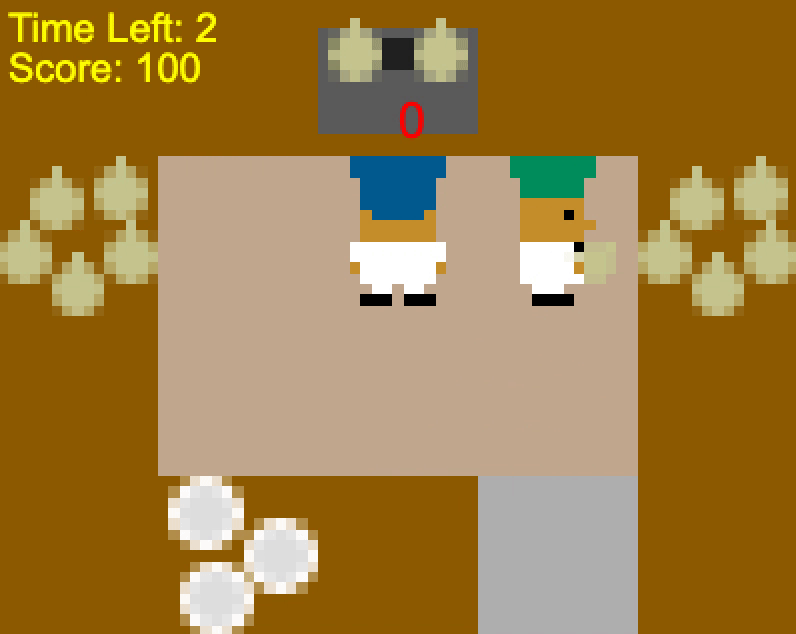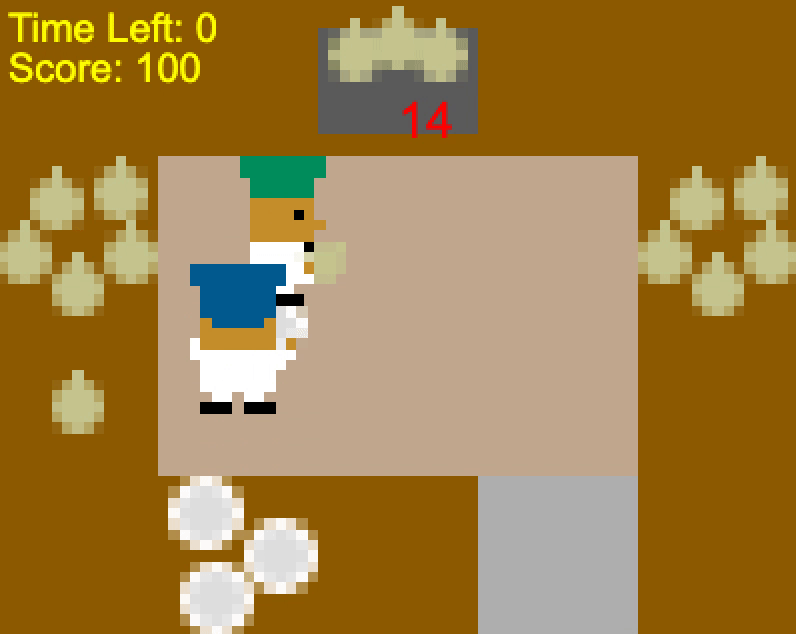
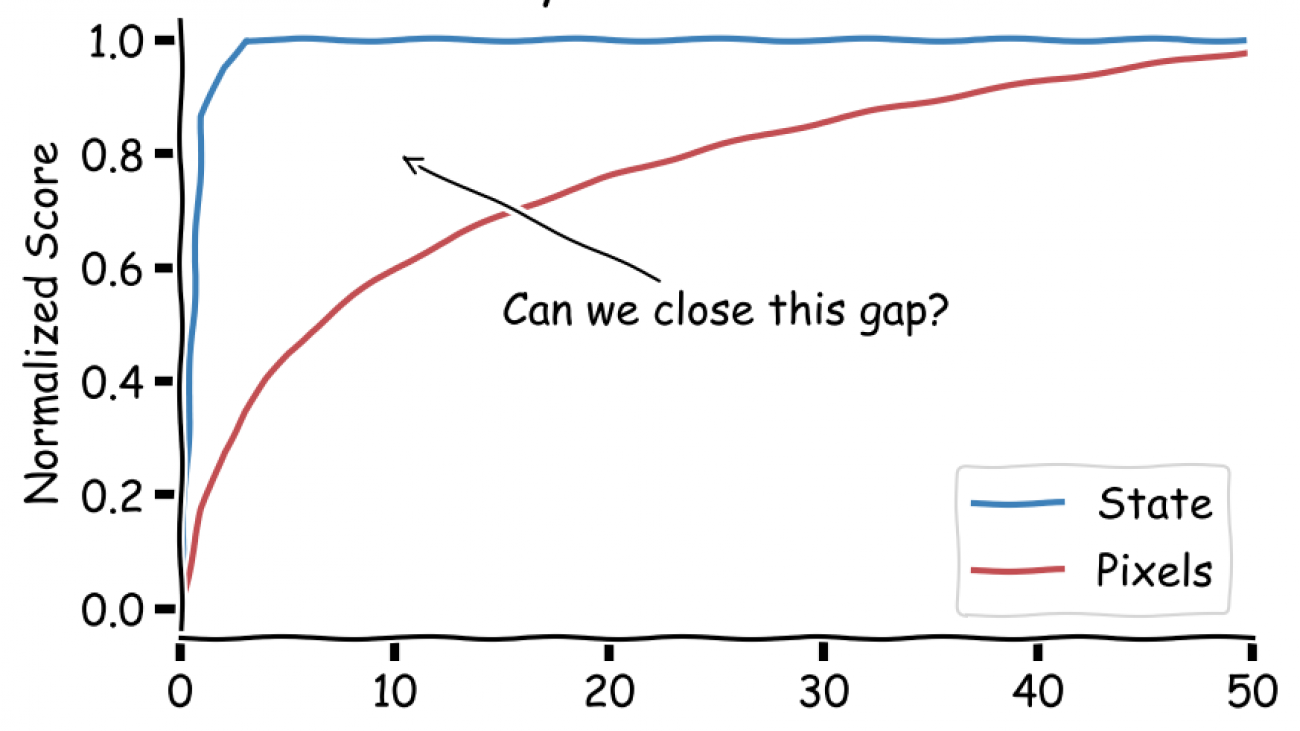
Our method learns complex behaviors by training offline from prior datasets
(expert demonstrations, data from previous experiments, or random exploration
data) and then fine-tuning quickly with online interaction.
Robots trained with reinforcement learning (RL) have the potential to be used
across a huge variety of challenging real world problems. To apply RL to a new
problem, you typically set up the environment, define a reward function, and
train the robot to solve the task by allowing it to explore the new environment
from scratch. While this may eventually work, these “online” RL methods are
data hungry and repeating this data inefficient process for every new problem
makes it difficult to apply online RL to real world robotics problems. What if
instead of repeating the data collection and learning process from scratch
every time, we were able to reuse data across multiple problems or experiments?
By doing so, we could greatly reduce the burden of data collection with every
new problem that is encountered. With hundreds to thousands of robot
experiments being constantly run, it is of crucial importance to devise an RL
paradigm that can effectively use the large amount of already available data
while still continuing to improve behavior on new tasks.
The first step towards moving RL towards a data driven paradigm is to consider
the general idea of offline (batch) RL. Offline RL considers the problem of
learning optimal policies from arbitrary off-policy data, without any further
exploration. This is able to eliminate the data collection problem in RL, and
incorporate data from arbitrary sources including other robots or
teleoperation. However, depending on the quality of available data and the
problem being tackled, we will often need to augment offline training with
targeted online improvement. This problem setting actually has unique
challenges of its own. In this blog post, we discuss how we can move RL from
training from scratch with every new problem to a paradigm which is able to
reuse prior data effectively, with some offline training followed by online
finetuning.