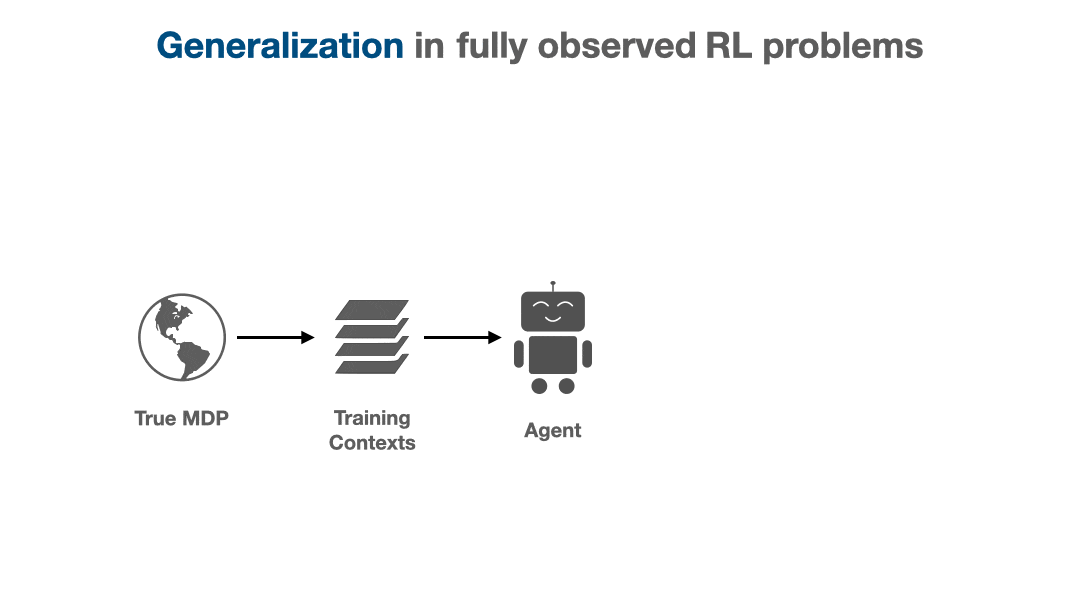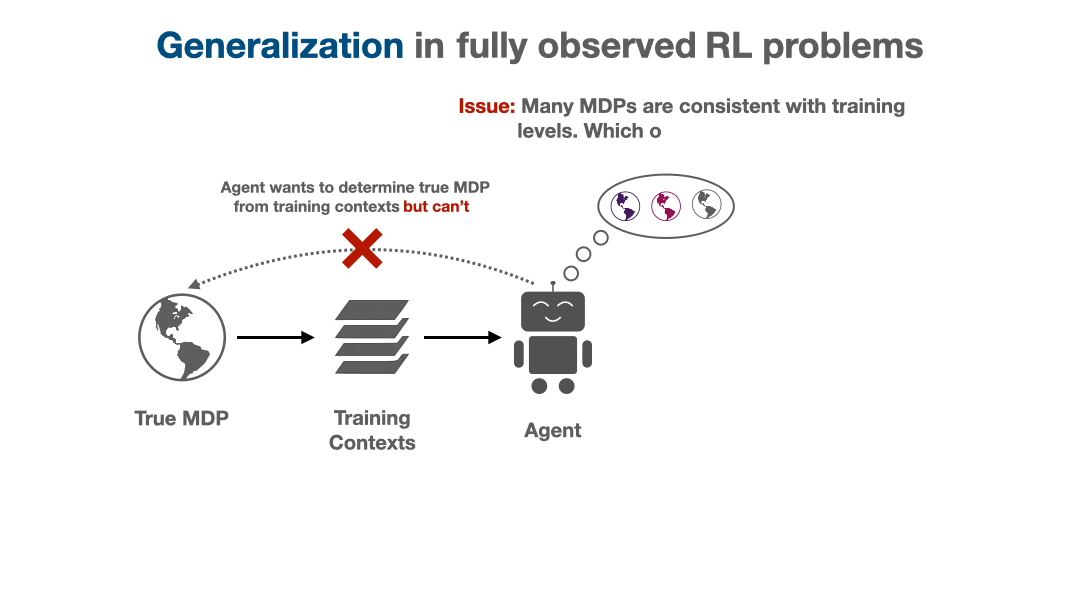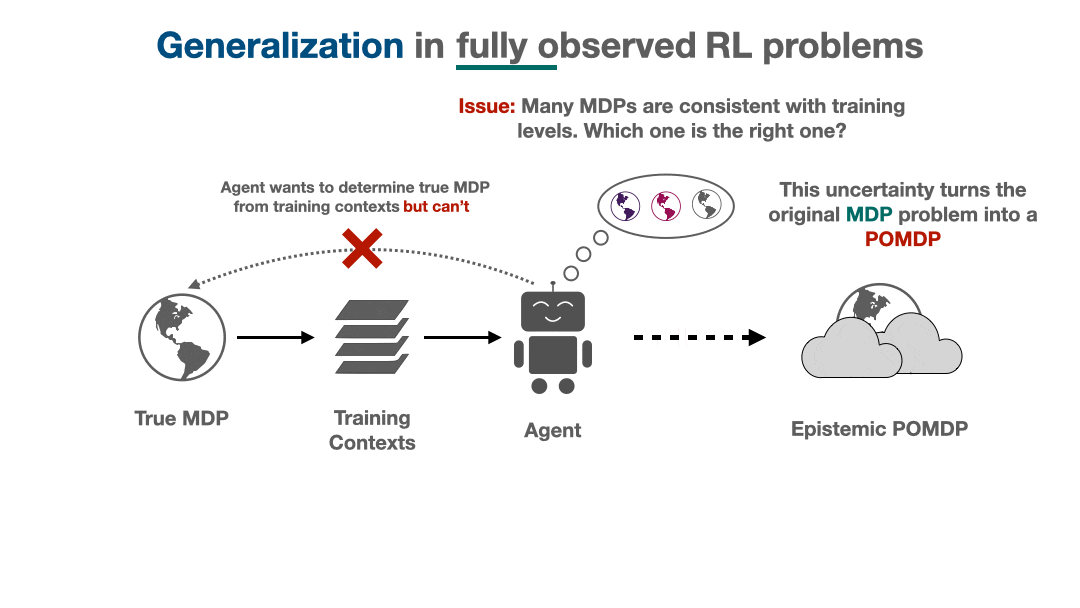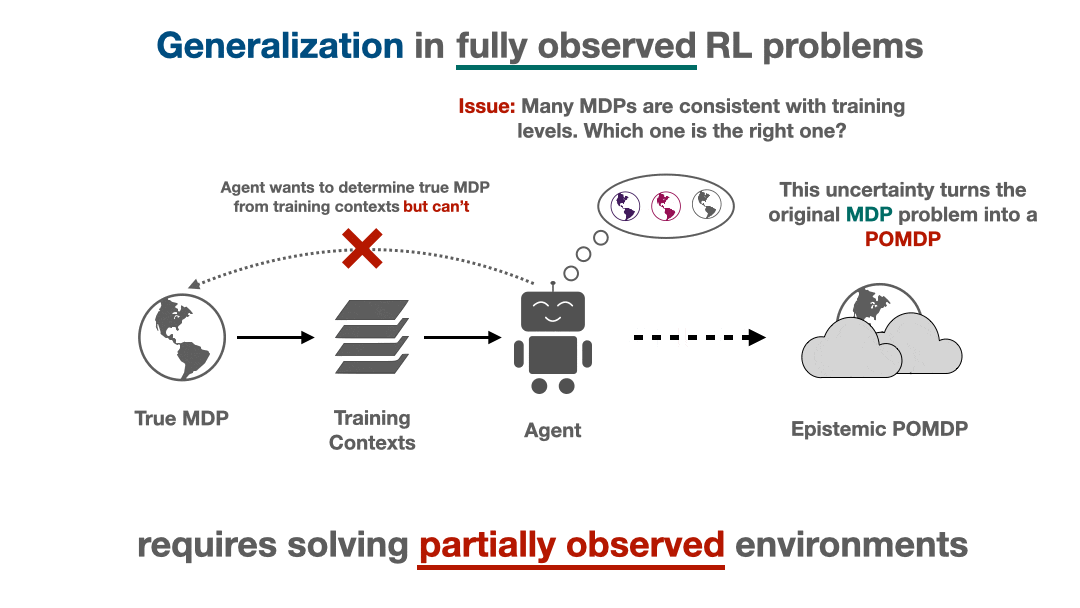
Figure 1: Airmass measurements over Ukraine from February 18, 2022 – March 01, 2022 from the SEVIRI instrument. Data accessed via the EUMETSAT Viewer.
Satellite imagery is a critical source of information during the current invasion of Ukraine. Military strategists, journalists, and researchers use this imagery to make decisions, unveil violations of international agreements, and inform the public of the stark realities of war. With Ukraine experiencing a large amount of cloud cover and attacks often occuring during night-time, many forms of satellite imagery are hindered from seeing the ground. Synthetic aperture radar imagery penetrates cloud cover, but requires special training to interpret. Automating this tedious task would enable real-time insights, but current computer vision methods developed on typical RGB imagery do not properly account for the phenomenology of SAR. This leads to suboptimal performance on this critical modality. Improving the access to and availability of SAR-specific methods, codebases, datasets, and pretrained models will benefit intelligence agencies, researchers, and journalists alike during this critical time for Ukraine.
In this post, we present a baseline method and pretrained models that enable the interchangeable use of RGB and SAR for downstream classification, semantic segmentation, and change detection pipelines.